
一种改进CycleGAN 的素描头像彩色化算法
2024-01-01 00:00:00廖振林国军黄丹胡鑫游松兰江海周旭金若水
宜宾学院学报 2024年6期


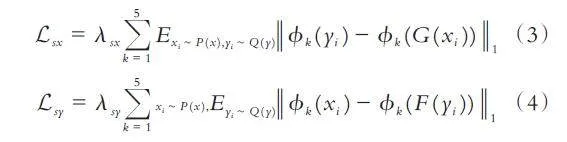
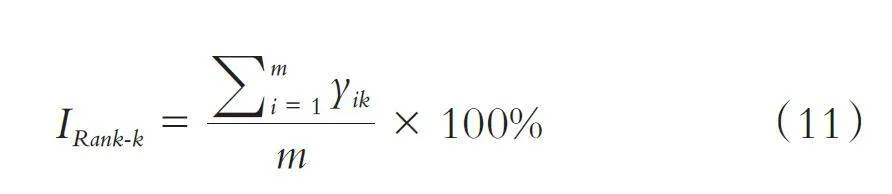
摘 要:针对现阶段由素描头像生成的彩色头像图像清晰度低、人脸识别率不高和视觉质量不佳等问题,提出一种改进CycleGAN 的素描头像彩色化算法:对U-Net 自编码器的第一个特征提取模块进行优化,设计一种多尺度自注意力机制特征提取模块,从多个尺度提取输入图像以减少输入图像的细节信息丢失,将提取的特征用通道堆叠的方式进行特征融合,对融合的特征嵌入SENet 自注意力机制,以引导模型对特征重点区域的关注度,最后再降低融合特征的通道维数;对生成头像与真实头像添加L1像素损失和感知损失,以进一步提升生成头像的质量. 实验结果表明:较基础模型CycleGAN 生成的彩色头像,在CUHK 数据集FID 值降低了22.23、Rank-1 值提高了16%,在AR 数据集FID 值降低了15.34、Rank-1 值提高了9.3%.
关键词:CycleGAN;多尺度特征提取;SENet;监督学习;L1像素损失;感知损失
中图分类号:TP391.41
DOI: 10.19504/j.cnki.issn1671-5365.2024.06.04
随着经济社会的飞速发展,人们越来越重视公共安全. 当前常用的生物识别特征有人脸、指纹、DNA 和声音等,人脸相较于其它生物特征具有更直观、更容易获取等突出特点,被广泛应用在公共安全领域. 素描头像在刑事侦查领域有着广泛应用,但素描头像主要体现人脸的边缘信息和轮廓信息,与真实人脸差异较大. 因此,将素描头像转换成彩色头像,能更好地协助警方初步锁定犯罪嫌疑人身份.
素描头像的彩色化是人脸头像合成的一个分支. 人脸头像的合成主要有两种方法: 传统的合成方法和深度学习的方法. (1)传统的合成方法有基于数据驱动的方法和基于模型驱动的方法. 基于数据驱动的方法主要有基于子空间学习的局部线性嵌入(Locally Linear Embeding, LLE)法[1]和基于马尔可夫随机场(Markov Random Field, MRF)法[2]. 数据驱动的方法合成的人脸头像,一些重要的人脸特征(如眼镜)可能会缺失在合成的人脸头像中[3],且合成的人脸头像也较模糊. 基于模型驱动的方法,如Chang 等人提出的基于贝叶斯学习的方法[4],它能学到彩色头像与素描头像转换的映射关系,但合成的素描头像在某些地方会丢失素描风格. (2)深度学习的方法有基于卷积神经网络的方法和基于生成对抗网络(Generating Adversarial Networks, GAN)[5]的方法. Zhang 等人[6]提出了一种由6 个卷积层组成的神经网络,该网络实现了彩色头像到素描头像端到端的非线性映射,但合成的素描头像出现了模糊和失真. 自GAN 的概念被提出以后,越来越多的生成对抗模型不断涌现出来,极大地促进了图像跨域转换的发展. Isola 等人[7]提出了Pix2Pix,通过分割的语义标签或图像的边缘完成图像的转换,转换图像的质量得到了显著提升,但该模型需要配对的图像进行训练,模型的使用场合受到了限制. Zhu 等人[8]提出了CycleGAN,该模型包含两个生成对抗网络的循环重建,相较于其它模型而言能更好地保持输入图像的结构,由于它是无监督学习的模型,因此无需配对的数据集就可以完成图像的跨域转换.Anoosheh 等人[9]提出了ComboGAN,其生成器由多个编码器和多个解码器组成,域编码器将输入图像映射到公共空间,域解码器将映射到共空间的特征向量解码实现图像的跨域转换. Heusel 等人[10]提出了BicycleGAN,该模型可以通过一次训练实现向多个域转换的效果.
就素描头像的彩色化任务而言,转换前后头像的结构基本保持一致,故本文选用CycleGAN 作为基础模型. 然而,CycleGAN 的生成器在对输入图像进行特征提取时采取单一尺度的卷积核,无法充分提取输入图像的细节信息,故本文提出了一种多尺度自注意力机制特征提取模块. 此外,彩色头像含有丰富的细节、纹理和色彩等信息,本文将Cycle⁃GAN 转为监督学习模型,通过添加L1 像素损失和感知损失来约束生成头像和真实头像的相似度,从而引导模型生成更加真实的彩色头像.
1 本文方法
1.1 模型的整体网络框架
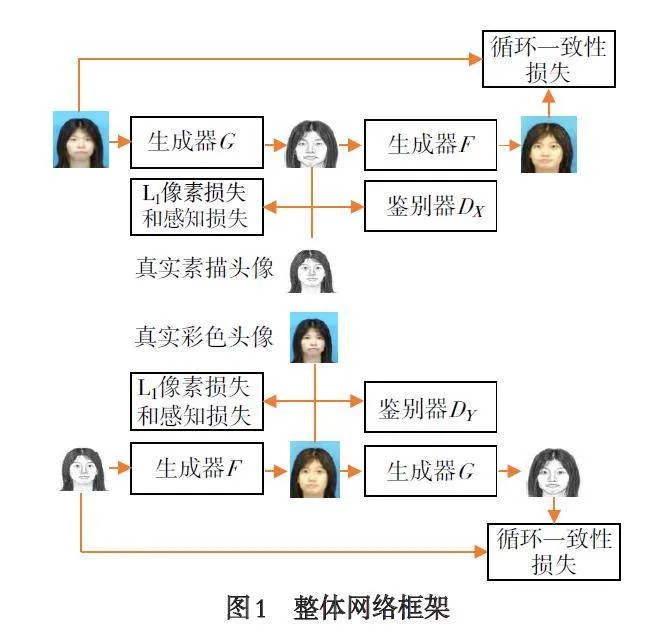
模型的整体网络框架见图1. 为便于描述,用X表示真实的彩色头像组成的集合,设真实的彩色头像满足的分布为P (x );用Y 表示真实的素描头像组成的集合,设真实的素描头像满足的分布为Q (y ).生成器G 将彩色头像xi 转换为素描头像yi_fake,生成器F 在将转化的素描头像yi_fake 转为循环的彩色头像rec_xi. 生成器F 将素描头像yi 转换为彩色头像xi_fake,生成器G 在将转化的彩色头像xi_fake 转为循环的素描头像rec_yi. 鉴别器DY 鉴别真实的彩色头像和转换的彩色头像xi_fake,鉴别器DX 鉴别真实的素描头像和转换的素描头像yi_fake.
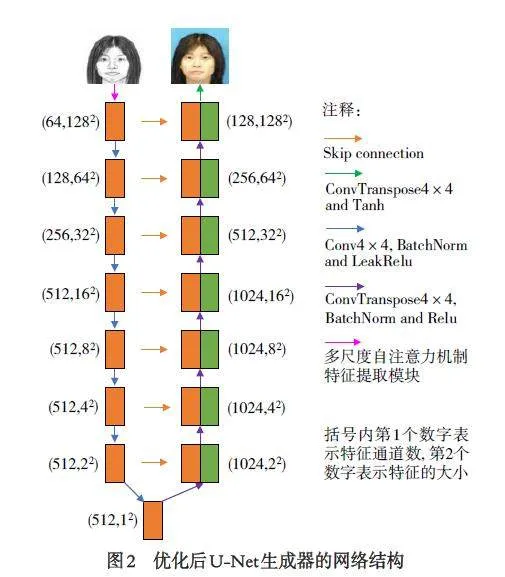
1.2 U⁃Net 生成器优化
U⁃Net 生成器[11]由编码器、解码器和跳层连接三部分组成. 编码器与解码器之间的跳层连接,能使生成头像更好地保留输入头像的结构信息[12].U⁃Net 生成器在对输入图像进行特征提取时采取单一尺度的卷积核,无法充分地提取输入图像的细节信息. 为此,本文对U⁃Net 生成器的第一个特征提取模块进行了优化设计,设计了一种多尺度自注意力机制特征提取模块. 优化后的U⁃Net 生成器的网络结构如图2 所示.
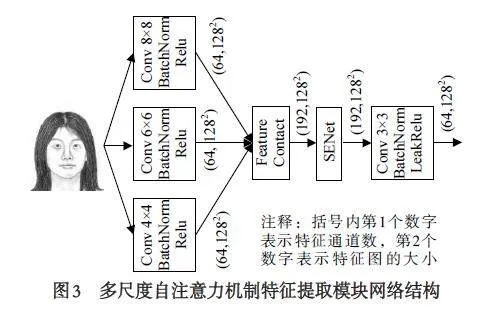
多尺度自注意力机制特征提取模块的网络结构如图3 所示,该模块有3 个特征提取分支,自下向上分别为第一特征提取分支、第二特征提取分支和第三特征提取分支. 输入头像经三个特征提取后,再采用通道连接的方式进行特征融合,为提高模型对融合后特征重点区域的关注度嵌入自注意力机制(Squeeze-and-Excitation Networks, SENet)[13],最后再降低特征的通道维数.
1.3 鉴别器结构
鉴别器采用PatchGAN[7]的鉴别器,整个网络由5 个卷积层组成,第1 个卷积层由卷积和LeakRelu 激活函数组成,中间的3 个卷积层都是由卷积、批量归一化(BatchNorm)和LeakRelu 激活函数组成,最后一个卷积层由一个卷积组成. 输入图像被映射为一个30×30 的矩阵,矩阵中的每个数值对应输入图像中某一区域为真实图像的概率.
普通GAN 的鉴别器将输入图像映射成一个值,该值是对整幅图像进行评价. 相较而言,PatchGAN的鉴别器能更好地对生成图像的细节信息进行约束,从而提高生成图像的质量.
1.4 损失函数
(1)生成头像与真实头像的L1 像素损失
由于L1 距离约束能使模型生成更加清晰的图像[7],为提高生成头像的质量,对生成头像与真实头像添加了L1 像素损失,L1 像素损失的计算式为:
Lxy = λxyExi ∼ P (x)||G(x "i ) - yi|| 1 (1)
Lyx = λyx Eyi ∼ Q (y )||F (y "i ) - xi ||1 (2)
式中λxy 和λyx 为权重系数.
(2)生成头像与真实头像感知损失. 虽然添加L1像素损失可以改善生成图像的质量,但不能很好地对生成头像的细节、纹理和色彩等信息进行约束. 为此,对生成头像与真实头像添加感知损失. 本文采用在ImageNet 数据集[10]上预训练好的VGG-19[14]网络作为特征提取网络,输出特征提取网络的relu1_1、relu2_1、relu3_1、relu4_1、relu5_1 层提取的特征,ϕ1 () 表示relu1_1 输出的特征,ϕ2 () 表示relu2_1 输出的特征,以此类推. 生成头像与真实头像的感知损失为:
式中λsx 和λsy 为权重系数.
(3)生成对抗损失. 采用最小二乘损失作为GAN 的对抗损失能使模型的训练过程更加稳定[15],因此,模型的生成对抗损失为:
Lc_GAN (G,F,D )= LGAN (G,DY,X,Y ) + LGAN (F,DX,Y,X )= Exi ∼ P (x )[ log (D )] Y (xi )+Eyi ∼ Q (x )[ log (1 - D )] Y (F (yi ))+Eyi ∼ Q(x )[ log (D )] X (yi )+Exi ∼P ( x )[log (1 -DX (G( xi )))] (5)
(4)循环一致性损失. 输入头像与循环头像应尽可能一致. 因此,循环一致性损失为:
Lcyc = λcyc Eyi ∼ Q (x )||G(F (y "i )) - yi|| 1 (6)
Lcxc = λcxc Exi ∼ P (x )||F (G(x "i )) - xi ||1 (7)
式中λcyc 和λcxc 为权重系数.
(5)本体映射损失. 对于真实的彩色头像xi,通过生成器F 转换后应与xi 尽可能一致. 同理,对于真实的素描头像yi,通过生成器G 转换后也应与yi 尽可能一致. 因此,本体映射损失为:
Lyc = λyc Eyi ∼ Q (x )||G(y"i ) - yi ||1 (8)
Lxc = λxc Exi ∼ P (x )||F (x "i ) - xi ||1 (9)
式中λyc 和λxc 为权重系数.
(6)总损失函数. 综上,模型的总损失函数为:
Ltotal = Lc_GAN + Lcyc + Lcxc + Lyx + Lxy+Lyc + Lxc + Lsx + Lsy (10)
2 实验设置、结果与分析
为验证素描头像彩色化任务的有效性,将本文模型与Pix2Pix、CycleGAN、BicycleGAN 和Combo⁃GAN 模型进行了对比实验.
2.1 数据集介绍
本文选取CUHK 数据集和AR 数据集进行实验验证. CUHK 数据集总共有188 对素描头像,训练集有88 对素描头像,测试集有100 对素描头像. AR 数据集总共有123 对素描头像,训练集有80 对素描头像,实验时将以上图像裁剪后调整到256×256.
2.2 实验设置
(1)实验环境. 实验在Windows 10 的环境下进行,CPU 为Intel®Core™ i7-4770,GPU 为NVIDIAGeForce RTX 3060(显存12 GB),采用pytorch 的框架进行实验.
(2)实验参数. 两个数据集训练时,批大小均设置为1,均迭代200 轮,在前100 轮时学习率均设置为0.0002,在后100 轮学习率从0.0002 线性衰减到0. 在CUHK 数据集训练时损失函数中的参数取值为:λcyc和λcxc 均为5,λyc 和λxc 均为0.5,λxy 和λyx 为1,λsx 和λsy均为0.2. 在AR 数据集训练时损失函数中的参数取值为:λcyc 和λcxc 均为5,λyc 和λxc 均为0.5,λxy 和λyx 均为1,λsx 和λsy 均为0.5.
2.3 实验结果评估
(1)定性实验评估. 各模型在CUHK 数据集和AR 数据集生成的彩色头像见图4,图中上面两行为各模型在CUHK 数据集生成的彩色头像,下面两行为各模型在AR 数据集生成的彩色头像. 由图4 可知,本文模型生成的彩色头像与真实的彩色图像更相似、视觉质量更佳.
(2)定量实验评估. FID(Fréchet Inception Dis⁃tance)[16]用于评估生成图像和真实图像相似度,其值越小表明生成图像与真实图像越相似. Rank-k[17]是人脸识别的一个评价指标,表示在人脸库中与输入人脸最相似前k 张人脸图像中找到正确人脸的概率. 设素描头像和真实的彩色头像均为m 张,且素描头像和真实的彩色头像一一对应,真实的彩色头像组成人脸库;对于每张输入素描头像,采用Dlib[18]库中的人脸识别模型提取输入图像与人脸库中的图像,进而得到每张图像的特征向量;然后比对输入图像的特征向量与人脸库中每张图像的特征向量,得到与人脸库中每张图像的相似度;若与输入图像最相似的前k 个人脸中,找到与之对应的真实的彩色头像则yik 记为1,否则yik 记为0,则Rank⁃k 值计算如下:
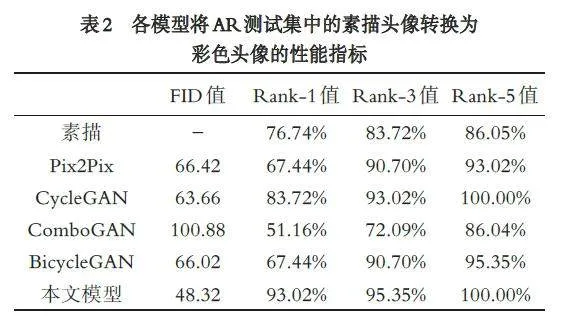
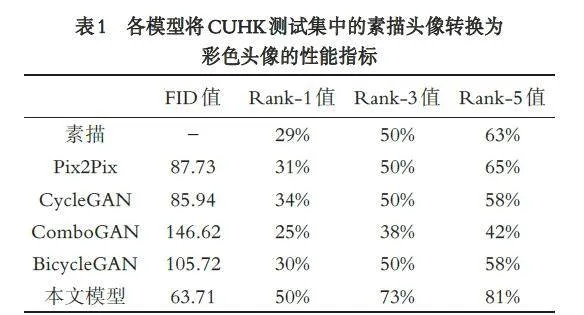
各模型将CUHK 测试集中的素描头像和AR 测试集中的素描头像,转换成彩色头像的性能指标分别见表1 和表2. 由表1 和表2 可知,本文模型转换的彩色人脸头像的FID 值最小,Rank-1、Rank-3 和Rank-5 的值均最大,即本文模型转换的彩色头像与真实的彩色头像更相似、人脸识别率更优.
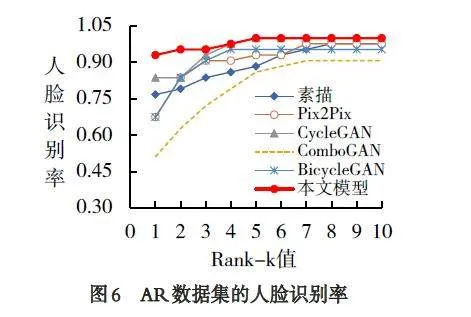
各模型将CUHK 测试集中的素描头像转换为彩色头像的人脸识别率和素描头像的人脸识别率见图5,将AR 测试集中的素描头像转换为彩色头像的人脸识别率和素描头像的人脸识别率见图6. 由图5和图6 可知,本文模型转换的彩色头像的人脸识别率曲线位于其它模型的上方,进一步说明本文模型转换的彩色头像的人脸识别率更优.
2.4 消融实验
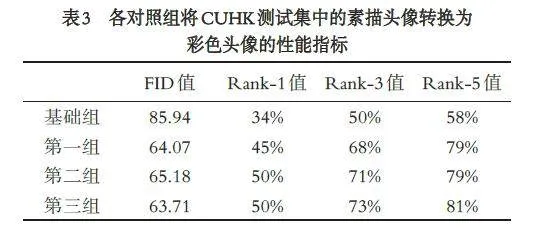
为探索多尺度自注意力机制特征提取模块、L1像素损失和感知损失对素描头像彩色化任务的有效性,在CUHK 数据集上做了消融实验. 基础组为CycleGAN,第一组为对U⁃Net 生成器的第一个特征提取模块进行了优化设计,即采取了多尺度自注意力机制特征提取模块提取输入图像,第二组为在第一组的基础上添加L1 像素损失,第三组为在第二组的基础上添加感知损失. 各对照组将CUHK 测试集中的素描头像转换为彩色头像的性能指标见表3.由表3 可知,多尺度自注意力机制特征提取模块可以降低彩色头像的FID 值,且能提高彩色头像的人脸识别率,L1 像素损失虽然使彩色头像的FID 值有轻微增大,但人脸识别率有明显提高;感知损失可以降低彩色头像的FID 值和提高彩色头像的人脸识别率.
3 结语
本文提出了一种素描头像彩色化算法首先,设计一种多尺度自注意力机制特征提取模块,实现对输入图像多尺度特征提取,同时通过添加SENet 注意力机制的方式来提高模型对感兴趣区域的关注度然后,添加生成头像与真实头像L1 像素损失和感知损失,以提高转换头像的质量实验结果表明:本文模型转换的彩色头像较其它模型转换的彩色头像,视觉质量更佳、与真实的彩色头像更相似和人脸识别率也更优.
参考文献:
[1] LIU Q, TANG X, JIN H, et al. A nonlinear approach forface sketch synthesis and recognition[C]//IEEE ComputerSociety Conference on Computer Vision and Pattern Recog⁃nition. San Diego: IEEE, 2005. doi:10.1109/CVPR.2005.39.
[2] WANG X, TANG X. Face photo-sketch synthesis and rec⁃ognition[J]. IEEE Transactions on Pattern Analysis and MachineIntelligence, 2008, 31(11): 1955-1967. doi: 10.1109/TPAMI.2008.222.
[3] 孙锐,孙琦景,单晓全,等. 基于多残差动态融合生成对抗网络的人脸素描-照片合成方法[J]. 模式识别与人工智能,2022,35(3):207-222.
[4] CHANG L, ZHOU M, DENG X, et al. Face sketch synthe⁃sis via multivariate output regression[C]//JACKO J A.Human-Computer Interaction. Berlin Heidelberg: Springer,2011: 555-561. doi:10.1007/978-3-642-21602-2_60.
[5] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, etal. Generative adversarial nets[C]//Proceedings of the 27th In⁃ternational Conference on Neural Information Processing Sys⁃tems. Cambridge: MIT Press, 2014: 2672-2680.
[6] ZHANG D, LIN L, CHEN T, et al. Content-adaptivesketch portrait generation by decompositional representationlearning[J]. IEEE Transactions on Image Processing, 2017, 26(1): 328-339. doi:10.1109/TIP.2016.2623485.
[7] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image trans⁃lation with conditional adversarial networks[C]//IEEE Con⁃ference on Computer Vision and Pattern Recognition. Hono⁃lulu: IEEE, 2017: 5967-5976. doi:10.1109/CVPR.2017.632.
[8] ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-toimagetranslation using cycle-consistent adversarial networks[C]//IEEE International Conference on Computer Vision.Venice: IEEE, 2017: 2242-2251. doi: 10.1109/ICCV.2017.244.
[9] ANOOSHEH A, AGUSTSSON E, TIMOFTE R, et al.ComboGAN: Unrestrained scalability for image domain trans⁃lation[C]//IEEE Conference on Computer Vision and Pat⁃tern Recognition Workshops. Salt Lake City: IEEE, 2018:896-8967. doi:10.1109/CVPRW.2018.00122.
[10] HEUSEL M, RAMSAUER H, UNTERTHINER T, et al.GANs trained by a two time-scale update rule converge to alocal nash equilibrium[C]//Advances in Neural InformationProcessing Systems. Red Hook: Curran Associates Inc., 2017:6629-6640. doi:10.48550/arXiv.1706.08500.
[11] RONNEBERGER O, FISCHER P, BROX T. U-net:Convolutional networks for biomedical image segmentation[C]//Medical Image Computing and Computer-Assisted In⁃tervention. Munich: Springer, 2015: 234-241. doi: 10.1007/978-3-319-24574-4_28.
[12] 陈金龙,刘雄飞,詹曙. 基于无监督生成对抗网络的人脸素描图像真实化[J]. 计算机工程与科学,2021,43(1): 125-133.
[13] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//IEEE/CVF Conference on Computer Vision and PatternRecognition. Salt Lake City: IEEE, 2018: 7132-7141. doi:10.1109/CVPR.2018.00745.
[14] SIMONYAN K, ZISSERMAN A. Very deep convolutionalnetworks for large-scale image recognition[J]. 2014-09-04.arXiv:1409.1556.
[15] MAO X, LI Q, XIE H, et al. Least squares generative adver⁃sarial networks[C]//IEEE International Conference on Com⁃puter Vision. Venice: IEEE, 2017: 2813-2821. doi: 10.1109/ICCV.2017.304.
[16] CRESWELL A, WHITE T, DUMOULIN V, et al. Generativeadversarial networks: An overview[J]. IEEE Signal ProcessingMagazine, 2018, 35(1): 53-65.doi:10.1109/MSP.2017.2765202.
[17] FANG H, COSTEN N. From rank-n to rank-1 face recog⁃nition based on motion similarity[C]//British Machine VisionConference. London: 2009: 1-11. https://www.researchgate.net/publication/221259929_From_Rank-N_to_Rank-1_Face_Recognition_Based_on_Motion_Similarity.
[18] KING D E. Dlib-ml: A machine learning toolkit[J]. TheJournal of Machine Learning Research, 2009(10): 1755-1758. https://dl.acm.org/citation.cfm?id=1755843.
【编校:王露】
基金项目:四川省科技厅项目“基于慢性帕金森病猕猴模型的运动皮层神经元编码规律研究”(2022YFSY0056)
