
基于AM-YOLOX的草莓病虫害检测算法研究
2024-01-01 08:27项新建王科宇郑永平胡万里
实验室研究与探索 2023年10期
项新建, 王科宇, 丁 祎, 郑永平, 胡万里
(1.浙江科技学院自动化与电气工程学院,杭州 310023;2.正阳科技股份有限公司,浙江 永康 321300)
0 引言
草莓是多年生草本植物,原产于南美,不仅鲜美多汁、营养丰富,具有很高的经济价值[1],已成为我国广泛栽培的重要经济作物之一。至2021年,我国已拥有草莓播种面积139 970 ha,产量368.25 万t,占全球的比重达37.23%,是全球最大的草莓生产与消费国。
在长期实践中发现,由于草莓生长过程中,环境温暖湿润,植株矮小,茎、叶、果实接近地面等特点,极易受到各种病虫害。常见的病虫害有草莓角斑病、草莓炭疽病、花枯病、叶斑病、草莓果实白粉病、草莓叶片白粉病和灰霉病等。灰霉病是在温室和露地栽培中均而普遍感染的病害,使草莓减产率达到20% ~30%,严重情况下可达50%以上。除此之外,还会引起采后草莓果实腐烂,造成草莓种植户的巨大经济损失[2]。草莓病虫害种类繁多,造成的经济损失大。对草莓生长过程中可能发生的病虫害进行精准的识别与预防,对草莓生产具有十分重要的意义。
目前图像识别与机器学习方法在病虫害识别领域中广泛应用,能在一定程度上代替传统的肉眼识别,可提高病虫害检测的效率[3]。牛冲等[4]基于图像灰度直方图特征,选用支持向量机(Support Vector Machin,SVM)分类器对草莓病虫害图像进行分类,分类正确率可达90%以上。Habib等[5]提出基于视觉技术的木瓜病害疾病检测与分类,利用K-means 聚类算法和SVM建立模型分类,准确率达95.2%。Prajapati 等[6]基于HSV颜色空间,通过用K-means聚类方法对水稻病害进行分类,准确率可达到96.71%。胡永强等[7]结合分类器学习以及稀疏思想,运用AdaBoost 算法对颜色、形状和纹理特征进行特征融合,识别准确率最高可达92.4%。以上均为基于图像识别与机器学习方法的病虫害识别方法,由于检测目标形状、光照条件以及检测背景的多样性和复杂性,特征提取的鲁棒性不够理想。
随着深度学习的快速发展,成为图像识别领域又一新的技术手段,具有识别速度快、准确率高等优势[8]。深度学习的植物病虫害目标识别方式,不仅能快速识别病虫害的类别,还能准确定位病斑、害虫在图像中的位置,进一步促进了智慧农业的发展。深度学习的植物病虫害目标检测算法主要以“你只看一次”[9](You only look once,YOLO)算法系列为核心的单阶段算法[10]以及以区域卷积神经网络算法(Region-CNN,RCNN)[11]为核心的双阶段算法为主。
李颀等[12]提出基于改进SSD 的果面缺陷冬枣实时检测方法,对4 类冬枣的整体检测精准性达到91.89%。晁晓菲等[13]以YOLOv4 网络为基础,经过对主干网络、颈部、边界框损失函数等改造、创新,在对苹果叶片病害的检测中,检测精确度达到88.2%。骆润玫等[14]提出基于YOLOv5-C 目标检测网络的复杂背景广佛手病虫害识别方法,检测准确率为93%,召回率为88.99%。宋中山等[15]在自然场景下柑橘叶片病害检测和识别技术,提出基于二值化的Faster RCNN 区域检测神经网络模型,总平均准确率为87.5%。殷献博等[16]根据不同卷积层提取特征的特点与不同注意力机制的作用,提出基于多注意力机制改进的YOLOX-Nano的柑橘梢期长势智能识别模型,平均准确率为88.07%。以上方法说明利用深度学习识别植物病虫害具有可行性,并且可靠性高。
YOLO系列网络是单阶段算法中最为常见的一种目标检测模型,YOLOX-s 是其优秀代表,具有检测精度高、推理速度快等特点。自然环境下拍摄的草莓病虫害图像背景复杂,病虫害种类多,且相互之间差异性较小,易造成病虫害目标的误检与漏检。为提高草莓病虫害的识别准确率,本文提出了一种基于AMYOLOX(Attention Mechanism-YOLOX)的草莓病虫害检测算法,以YOLOX-s 算法作为基础的网络模型,进行相关研究改进。
(1)使网络模型能更高效地学习和融合图像的特征。通过多注意力机制引入来提升网络的性能。结合不同的注意力机制模块的不同的特点,对网络的不同地方进行改进,使其到达模型性能的最大化。
(2)针对部分病虫害较小,易导致病虫害定位不准确,引入CIoU损失函数作为边界框回归损失,不仅能提高目标框回归的稳定性,还能使损失函数收敛速度更快。
(3)草莓病虫害所处环境背景相对复杂,在训练阶段,使用Mosaic 和Mixup 算法进行数据增强,丰富了检测物体的背景,使得网络面对复杂环境有更好的鲁棒性。
1 YOLOX-s神经网络介绍
YOLOX是一种高性能检测器,YOLOX 创新在于使用Decoupled Head、SIMOTA 等方式,使其检测性能达到了新的高度。该网络共分为主干特征提取网络(Backbone)、特征金字塔网络(Neck)和目标检测头(Head)。其中Backbone 网络用于图像特征的提取、Neck网络用于多尺度特征的融合,Head 网络进行图片的识别和定位。
Backbone 即主干特征提取网络,采用的是CSPDarknet网络,结构如图1 所示。
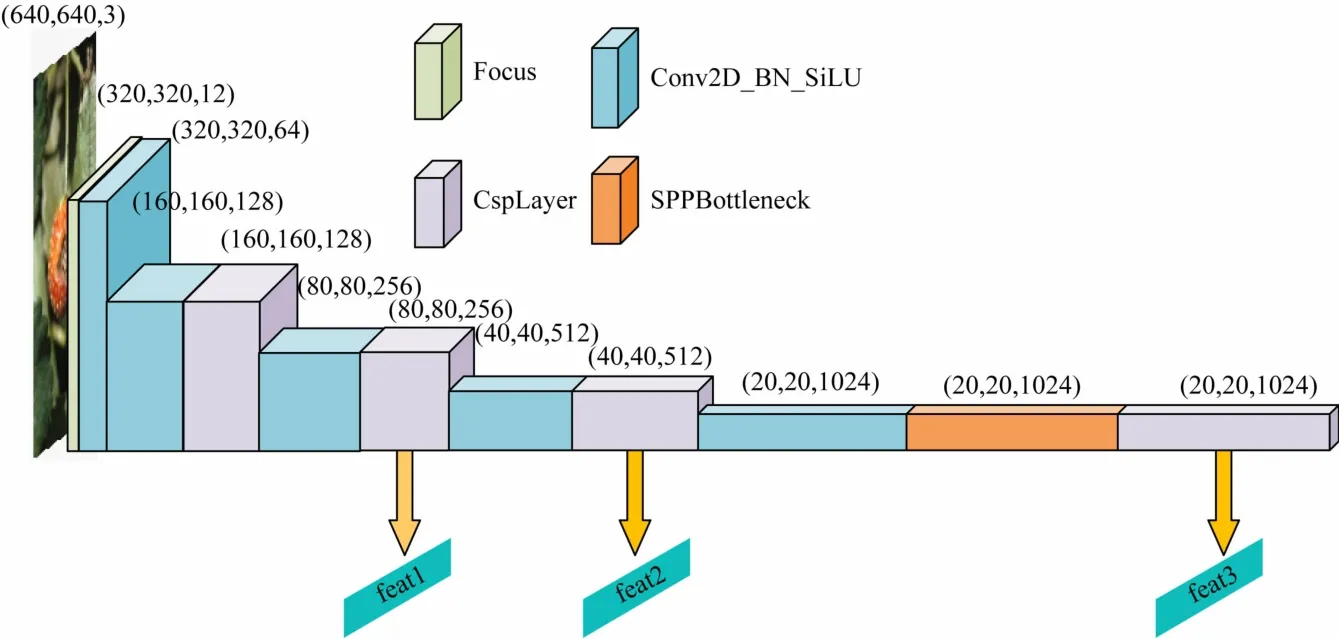
图1 Backbone结构
其中包含了神经网络组件(Conv BN SiLU,CBS)、Focus结构、神经网络架构(Cross Stage Partial,CSP)和空间金字塔池化(Spatial Pyramid Pooling,SPP)结构。CBS结构由Conv +BN +SiLU 组成;CSP 结构借鉴了CSPNet的网络结构,由卷积层和X个残差组件拼接组成;Focus结构如图2 所示。
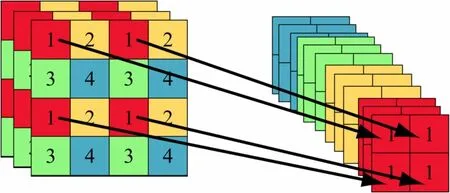
图2 Focus结构
具体操作是在一张图片中每隔一个像素拿到一个值,获得4 个独立的特征层,将4 个独立的特征层进行堆叠,此时W、H信息就集中到了通道信息,输入通道扩充了4 倍;SPP 结构如图3 所示,其通过pooling 将不同尺度的特征融合到一起,实现数据的多尺度输入。
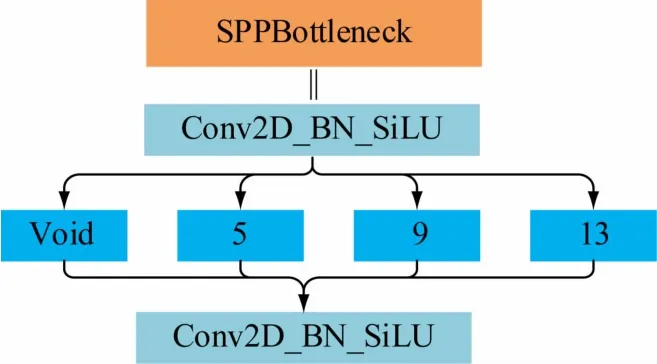
图3 SPP结构
Neck 采用路径聚合特征金字塔网络(Path Aggregation Feature Pyramid Network,PAFPN)结构进行融合。通过上采样方式进行传递融合,通过下采样融合方式得到预测的特征图,输出3 个特征层组成的元组结果。
Head采用分类和回归分开处理,并在预测时再整合的策略。这种策略不仅能够提高检测性能,还可提升收敛速度。此外还采用了anchor free、Multi positives等方式,这些方式都能提升模型的速度、性能以及识别精度。
2 模型与算法的改进
2.1 多注意力机制融合
神经网络中,注意力机制的作用是能在众多的输入信息中,聚焦对当前任务更为关键的信息。这与人类视觉注意力机制非常相似,通过扫描全局图像,获得重点信息,并对获得的重点信息进行重点关注,得到更多与检测目标相关的细节,使任务处理的效率和准确性提高,实现网络性能的提升。面对自然环境中草莓病虫害图像背景复杂,病虫害种类多,且相互之间差异较小,易造成病虫害目标的误检与漏检,通过多注意力机制的引入能提升网络的性能。不同的注意力机制有着不同的特点,结合注意力机制的特点,对网络不同地方进行改进,使其到达模型性能的最大化。本文将选用3 种注意力机制对网络改进,分别使用坐标注意力机制[17](Coordinate Attention,CA)对Focus 模块进行改进;通道注意力机制[18](Squeeze-and-excitation attention,SE)对SPP 模块进行改进;卷积块注意机制[19](Convoluional Block Attention Module,CBAM)对PAFPN结构进行改进。
(1)CA对Focus模块进行改进。CA注意力机制是Hou 等[17]提出的一种新注意力机制。其结构如图4 所示。

图4 CA结构图
CA注意力机制为避免2D全局池化引入,使得位置信息丢失,将通道注意力分解为2 个并行的一维特征编码过程,分别沿2 个空间方向聚合特征,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,来提升对感兴趣目标的表示能力。
CA注意力机制的特点在于能获取通道信息和方向相关的位置信息,能很好地定位和识别图中的信息。Focus模块是对输入图片进行切片,不会有任何信息的丢失,只是将H、W(高、宽)信息集中到通道空间,使其输入通道扩充为原图的4 倍,对图中位置信息和特征信息就显得十分重要。在Focus 模块后添加CA 注意力机制,结构如图5 所示,能够使其更好地对图片信息进行保存。
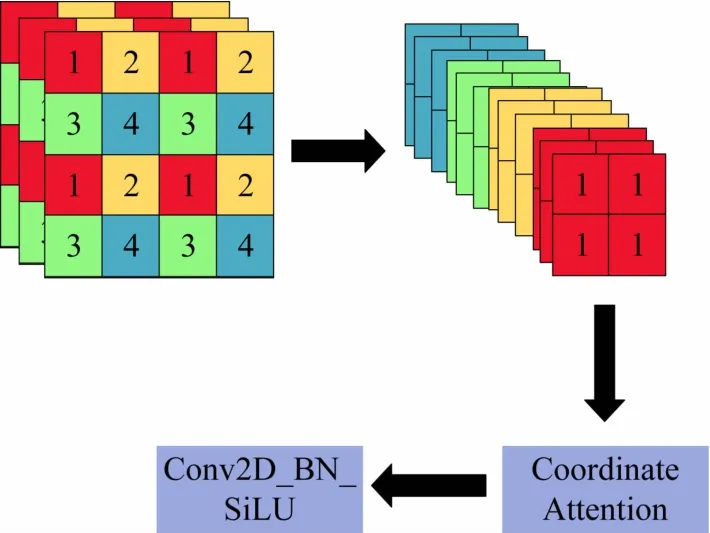
图5 CA添加位置
(2)SE对SPP模块进行改进。SE 注意力机制是由Hu等[18]提出的一种注意力机制,结构如图6 所示。
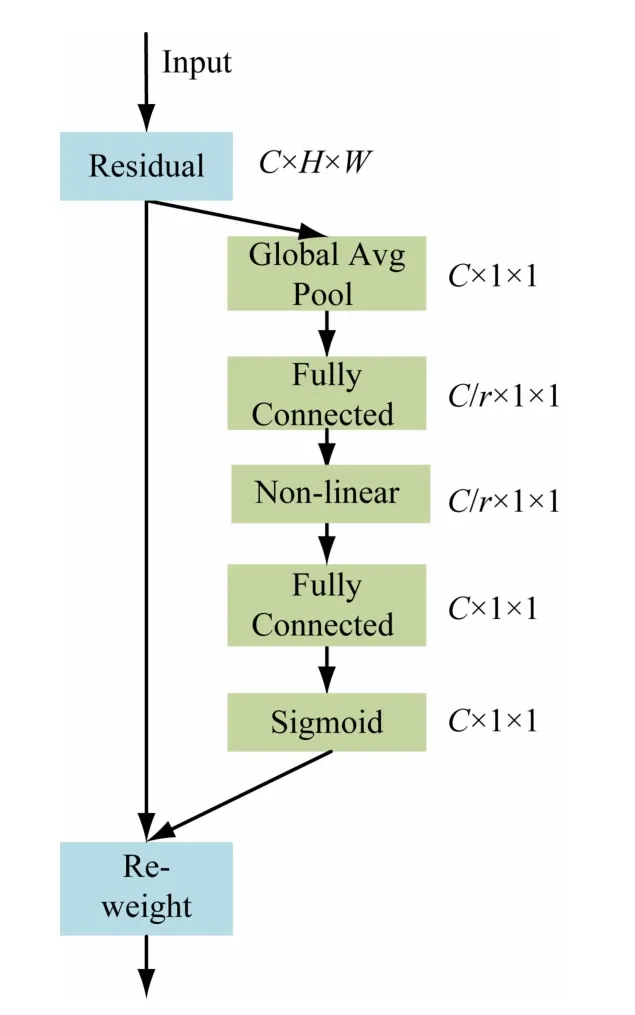
图6 SE结构图
其包括1 个全局平均池化层,2 个全连接层和1个激活函数。输入一张C×H×W(通道×高×宽)的特征图,经过一次的全局平均池化层,得到C×1 ×1的特征图,再经过用2 个全连接层和1 个激活函数进行非线性处理得到C×1 ×1 的特征图,将原始C×H×W的特征图和C×1 ×1 的特征图进行全乘操作,得到不同通道重要性不一样的特征图。
SE注意力机制能将全局信息压缩为通道权重,可很好地确定不同通道间的重要性,SPP 通过不同池化核大小的最大池化进行特征提取,提高网络的感受野,结合SE注意力机制的特点和SPP 模块的作用,决定在SPP模块后添加SE注意力机制,如图7 所示。

图7 SE添加位置
拼接后的通道将重新分配通道权重,确定通道重要性,能带来更多有利于识别任务的特征通道的权重得以增加,其他特征通道的权重得以抑制,使得网络模型更加关注目标的特征信息,提高网络模型的识别性能。
(3)CBAM 对PAFPN 结构进行改进。CBAM 注意力机制是Woo等[19]提出的一种轻量而有效的注意力机制,如图8 所示。

图8 CBAM整体结构
不同于传统单模块的注意力机制,仅使用通道注意力机制或者是仅使用空间注意力机制,它可在通道和空间维度上进行作用。其包含2 种类型的注意力机制,分别是通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spartial Attention Module,SAM)结构分别如图9 和图10 所示。

图9 通道注意力模块

图10 空间注意力模块
CBAM注意力机制由输入、通道注意力模块、空间注意力模块和输出组成。先进行通道注意力模块的处理和空间注意力模块的处理。具体步骤:当一张大小为C×H×W中间特征图F输入CBAM 注意力模块,通过通道注意力模块生成一维通道注意力MC,将一维通道注意力MC与输入的原始特征图像F相乘,获得通道注意力调整后的特征图F',F'作为空间注意力模块的输入,通过空间注意力模块生成二维空间注意力Ms,将二维空间注意力Ms与特征图F'相乘得到CBAM注意力机制的最后输出结果F″。
CBAM注意力机制沿着2 个独立的维度完成通道信息和空间信息的融合,完成自适应的特征优化,PAFPN可将深层特征层具有的更强的语义信息传递到浅层特征层,还可将浅层特征层具有的更强的定位信息传递到深层特征层,有效加强网络的特征融合能力,结合CBAM的特点和PAFPN的作用,将CBAM 加入PAFPN网络之中,如图11 所示,提升目标特征的权重,让网络更加关注待检测目标,以提高检测效果,解决复杂环境背景下容易错漏检。
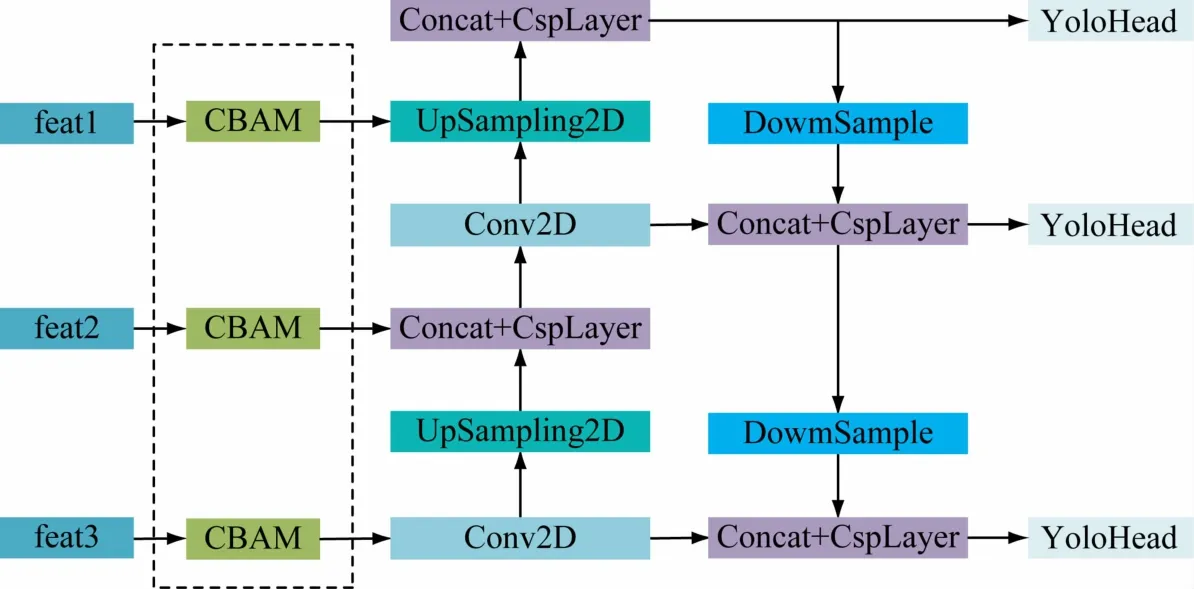
图11 CBAM添加位置
2.2 引入新损失函数
损失函数(Loss function)是编译一个神经网络模型的要素之一,用来评价模型的预测值与其真实值差异的程度。YOLOX 中损失函数由Reg、Obj 和Cls 组成。其中Reg是特征点的回归参数判断、Obj 是特征点是否包含物体判断、Cls 是特征点包含的物体的种类。损失函数
式中,Reg中的IoU损失函数[20]是包括预测框与真实框之间交集和并集的比值,即:
式中:A为检测框;B为真实框。当IoU 值越小,预测框和真实框的重叠程度越高。反之,则重叠程度越低。在草莓病虫害预测中,因为部分病虫害较小,可能会遇到预测框与真实框完全不重叠的状态,导致部分病虫害的定位不准确。针对IoU无法对预测框和真实框不重合的状态以及IoU值无法反映预测框与真实框之间的距离问题。采用CIoU损失函数[21]作为边界框回归损失,CIoU是IoU的改进版(见图12),它考虑了目标框回归三要素(重叠面积、中心点距离和长宽比),不仅能提高目标框回归的稳定性,还能使损失函数收敛速度更快,在优化网络误差方面也显得更加合理灵活,其中α作为协调比例参数:
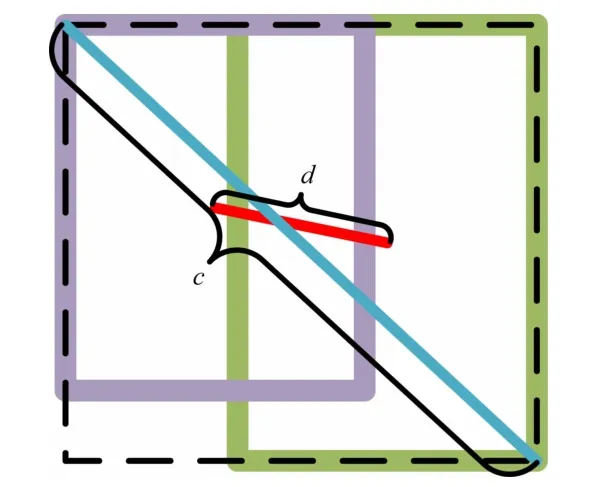
图12 CIoU相关图示
ν用于衡量框的长宽比一致性参数:
式中:w、h分别为预测框的宽和高;wgt、hgt分别为目标框的宽和高,CIoU计算方式:
式中:b、bgt分别为预测框和真实框的中心点;ρ 为两点欧式距离(即为图12 中d);c为能够同时包含两框最小矩形封闭区域对角线距离。
3 实验结果与分析
3.1 实验数据集
草莓病虫害数据集使用的是由某计算机科学与工程系AI实验室的成员收集[22],该数据集包含了2 500张草莓疾病的图像,7 种不同类型的病虫害。病虫害类别包括草莓角斑病、草莓炭疽病、花枯病、叶斑病、草莓果实白粉病、草莓叶片白粉病和灰霉病。数据从不同自然光照条件下的温室中采集,以确保环境的多样性。本文从中筛选部分图像,并对部分不清晰的标注进行重新调整。由于数据集中各类病虫害数量不均衡,为保证各种病虫害的数量均衡,通过水平翻转、等比例缩放、随机裁剪与填充、随机亮度和垂直翻转等进行数据扩充。进行预处理后的数据集共3 806 张,具体分类见表1,符合网络训练需求。为保证数据集的独立性,对数据集按照8∶1∶1的比例切分为训练集、验证集和测试集。
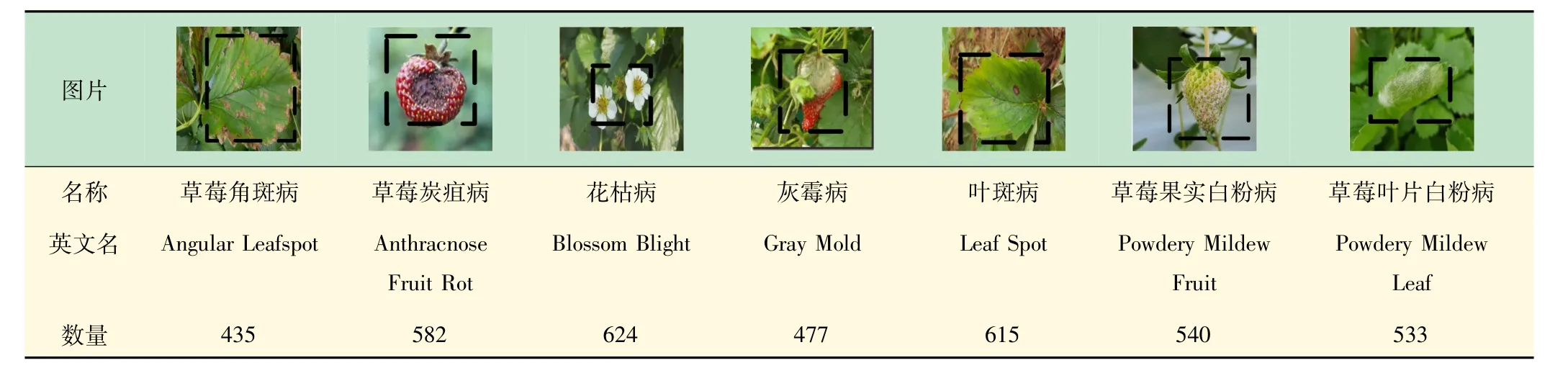
表1 数据集分类
3.2 实验平台及参数配置
试验是在Linux操作系统下,基于GPU、Pytorch和CUDA框架完成的,参数具体见表2。

表2 实验训练环境配置
3.3 模型训练
(1)数据增强。Mosaic数据增强是一种对图像进行增强的方式,在后续深度学习算法中被广泛使用的一种数据增强方法,能弥补训练数据集的不足。Mosaic数据增强是将4 张图片进行随机裁剪,再拼接到一张图上作为训练数据,其效果如图13 所示,其极大丰富了检测物体的背景。该算法能够较大程度提升模型的鲁棒性。

图13 Mosaic数据增强
Mixup数据增强是一种混类增强的算法,效果如图14 所示,可将不同类之间的图像进行混合,扩充训练数据集。假设batchx1是一个batch样本,batchy1是该batch样本对应的标签;batchx2是一个batch 样本,batchy2是该batch样本对应的标签,λ是由参数为α和β的贝塔分布计算出来的混合系数,由此可得:

图14 Mixup数据增强
(2)训练参数。本文在进行模型训练时,使用COCO进行预训练数据集进行迁移学习训练,以此来解决草莓病虫害数据量不够。在模型时输入的图片大小为640 ×640,采用sgd优化器,学习率调整方式为余弦退火衰减,迭代次数共100,训练批次大小为32,学习率为0.001,采取冻结训练方法,以提高训练效率,加速收敛,前50 轮为冻结训练,后50 轮为解冻训练,其中训练的前50%用Mosaic和Mixup数据增强算法。在这样训练策略下,不仅数据增强合成的图像能增强模型对局部特征的学习能力,提高整个模型的泛化能力,数据集也能更专注原始图片,使得模型能很好地学习到目标的总体特征。
训练过程的loss曲线如图15 所示,横、纵坐标分别为epoch和loss值。算法在起始阶段损失函数下降较快;在20 个epoch 后,损失函数趋于平缓;在第50个epoch,损失函数呈断崖式下跌,是因为后50 轮为解冻训练,模型的主干不被冻结,特征提取网络也得到训练;是因为关闭了Mosaic 数据增强和Mixup 数据增强引入真实的样本,防止数据过度增强,使网络得到良好的训练。
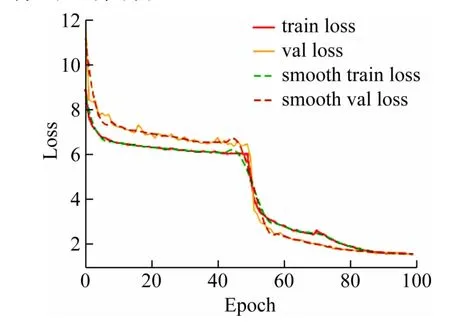
图15 Loss曲线
3.4 评价指标
针对模型目标检测与分类任务,本研究使用召回率(Recall)、准确率(Precision)、平均准确率(Average precision,AP)、平均精度均值(Mean of average precision,mAP)和F1分数作为网络模型的评价指标。其公式如下:
式中:TP为正确检测出的样本数量;FP为误检的样本数量;FN为漏检的样本数量;AP(i)为第i类病虫害的AP值;NC为类别数量。
3.5 结果及分析
(1)消融实验。为更好地理解AM-YOLOX 算法中各改进对检测效果的影响,本研究进行了一系列消融试验。在训练参数相同条件下,采用YOLOX-s作为基础对比网络,消融实验结果见表3。
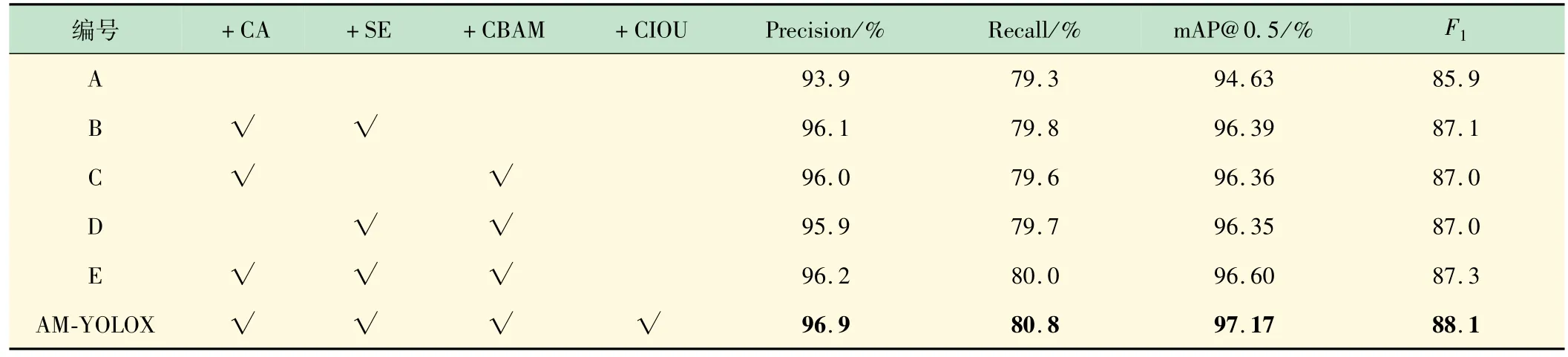
表3 消融试验结果
表3 中实验A为基础的YOLOX-s网络结构,实验E为在YOLOX-s基础上融合3 种注意力机制,实验B、C、D相比较实验E 分别减少一种注意力机制。实验结果表明,实验B、C、D 均不如实验E,当所有注意力全都加入时,效果最好。相比于原始YOLOX-s 算法,mAP 提升1.97%,Precision 提升2.3%,Recall 提升0.7%。说明不同注意力机制,在网络的不同位置,加入多种不同的注意力机制,能使网络模型更高效地学习特征图的特征。AM-YOLOX 在实验E 的基础上采用CloU损失函数作为边界回归损失,相比于实验E中使用IOU 作为边界框回归损失,mAP 提升了0.57%,Precision 提升0.7%,Recall 提升0.8%,说明,采用CIoU损失函数作为边界框回归损失,能提高目标框回归的稳定性。
通过消融实验,再次证明了每个改进策略均能提高网络模型的性能。本文所提出的AM-YOLOX 网络模型相比于原始的YOLOX-s网络模型,具有更好的识别性能,mAP提高了2.54%,Precision提升3%,Recall提升1.5%,F1分数提高了2.2。改进前后各类具体AP值提升具体值如图16 所示。(2)对比实验。为进一步证明本文所提的AMYOLOX的有效性以及优越性,在实验环境和模型参数设置不变的条件下,选择目前目标检测领域主流方法SSD、Faster-RCNN、YOLOv3、YOLOv5-s 与本文方法进行比较,以Precision、Recall、mAP、F1作为评价指标,结果见表4。

表4 对比试验结果
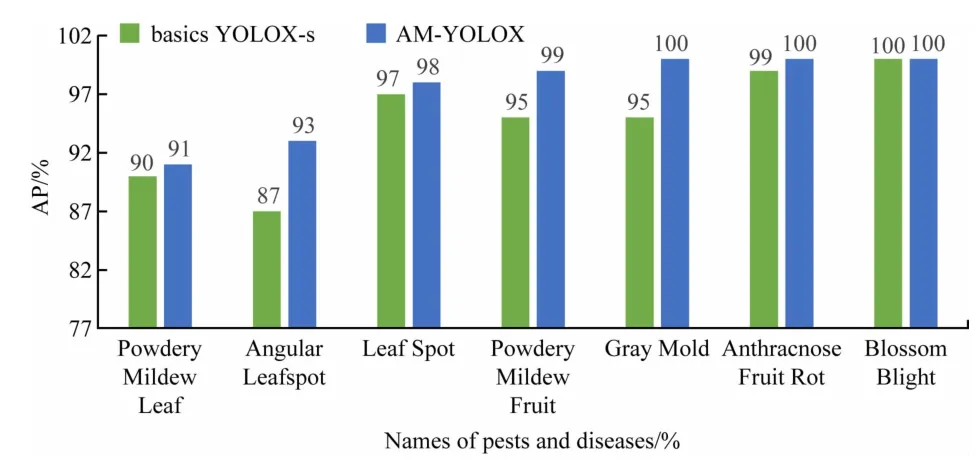
图16 改进后各类AP值
由表4 中数据可知,AM-YOLOX 的Precision、Recall、mAP、F1分数为表中其他测试算法中最高。在检测精度方面,AM-YOLOX 与同为单阶段算法的SSD、YOLOV3、YOLOV5-s 算法相比,Precision 分别提升了4.8%、17%和14.9%,mAP 分别提升了4.36%、16.73%和14.74%,F1分数分别提升了8.1、18.3 和11.8,而且与经典两阶段目标检测算法Faster R-CNN相比较,Precision 提升了5.1%,mAP 提升了4.41%,F1分数提升了6.8,算法性能展现出了较大的优势。自然环境下的草莓病虫害,图像背景复杂,病斑的面积较小,易产生漏检。而AM-YOLOX 在召回率上,相比较于SSD、Faster-RCNN、YOLOv3、YOLOv5-s,分别提升了10%、7.8%、18.7%和9.3%,本文所提网络模型综合性能更优,更适合完成在自然环境下对草莓病虫害的识别任务。
4 结语
本文针对草莓病虫害检测任务提出了一种基于AM-YOLOX的算法架构。为实现草莓病虫害的精准定位和识别,在网络的不同位置加入不同注意力机制,并引入了CIoU边框回归损失函数,在训练阶段,使用Mosaic和Mixup算法进行数据增强,来应对复杂环境背景,以获得较好的鲁棒性。实验结果表明,AMYOLOX模型相较于原模型以及其他主流算法,有着更高的分类置信度,更高的准确率、召回率。该模型的检测精度及定位精度更加优异,能最大程度地避免病虫害的误检和漏检,满足草莓病虫害检测的需求。
未来将考虑如何在保证较高准确率前提下,进一步提高推理速度,并将其部署在移动端,构建成为草莓虫害识别系统,促进智慧农业的发展。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
今日农业(2021年7期)2021-11-27
今日农业(2021年12期)2021-10-14
中老年保健(2021年5期)2021-08-24
阅读与作文(小学高年级版)(2017年10期)2017-10-11
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
农村百事通(2009年4期)2009-03-02
