
基于特征融合和注意力机制的物体6D姿态估计算法
2023-12-30 05:26:10高维东刘贤梅
计算机技术与发展 2023年12期
高维东,林 琳,刘贤梅,赵 娅
(东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
基于视觉的物体6D姿态估计从图像中检测目标物体,并估计其相对相机的位置姿态和旋转姿态,是视觉三维感知的核心问题之一,主要应用于增强现实、自动驾驶和智能机器人抓取等领域。真实场景的复杂背景、目标物体的弱纹理和小体积特性、物体间的相互遮挡,均给物体6D姿态估计带来巨大挑战。
基于深度学习的物体6D姿态估计根据输入的不同分为基于RGB图像的物体6D姿态估计和基于RGBD图像的物体6D姿态估计,后者利用深度信息的几何特征消除物体比例歧义和区分相似物体,在精度上有显著优势。由于RGB图像和D图像属于不同模态,因此如何充分利用两种不同模态数据进行物体6D姿态估计是一个值得研究的问题。
根据RGB图像和D图像使用方式的不同,基于RGBD图像的物体6D姿态估计分为级联的方法和融合的方法。早期工作多采用级联设计发挥RGB图像与D图像的优势。PoseCNN[1]和SSD-6D[2]先使用CNN从RGB图像提取姿态语义特征,预测物体初始姿态,再对D图像使用迭代最近点算法(Iterative Closest Point,ICP)完成姿态优化。然而,ICP优化姿态比较耗时,无法满足对实时性有需求的应用,同时,D图像中的几何特征未得到充分使用。融合的方法将具有互补特性的RGB图像和D图像融合,姿态特征的语义信息表达能力更强,物体6D姿态估计精度更高、遮挡鲁棒性更强。根据融合阶段的不同,分为输入融合、输出融合和过程融合。
输入融合将RGB图像与D图像进行简单地拼接操作,组成四通道图像后送入到CNN中同时提取外观特征和几何特征,具有充分利用数据的原始信息和计算量要求低的优点。iPose(instance-aware pose estimation)[3]使用RGBD图像编解码网络将物体像素映射到三维物体表面,计算物体6D姿态。然而由于两种数据的异构性,因此仅使用一个主干网络很难同时有效提取目标物体的外观特征和几何特征,并且,基于D图像的CNN特征提取存在“投影分解”问题。在D图像中,物理世界投影的三维结构通过一维的深度值及图像的二维像素坐标保持,CNN中调整大小、翻转和池化等操作会破坏深度值和二维像素坐标的联系,影响物体几何特征的提取。
点云的几何特征较D图像更加丰富,所以输出融合和过程融合中均先将D图像转换为点云,再使用两个独立的主干网络分别提取RGB图像的外观特征和点云的几何特征。
输出融合将两个主干网络的决策输出融合,再预测物体姿态,是一种模块化、灵活性高的方法。DenseFusion[4]、基于特征融合的6D目标位姿估计算法[5]和PVN3D[6]等先分别提取密集的外观特征和几何特征,然后将两种特征拼接融合,最后进行姿态估计。由于卷积运算的感受野有限,上述输出融合的算法难以编码目标物体区域的长程依赖关系,导致姿态语义特征缺乏目标物体的全局特征信息。基于位置依赖的密集融合的6D位姿估计方法[7]通过编码像素间的位置关系构建目标物体的长程依赖关系,增强算法辨识遮挡物的能力。但是输出融合忽略了中间层不同特征的互补作用,如相似外观的不同物体可以通过几何特征分辨,因物体表面反射引起的深度缺失可以通过外观特征补充。
过程融合在整个特征提取过程中进行融合,姿态特征的语义信息表达能力强。FFB6D(Full Flow Bidirectional Fusion Network for 6D Pose Estimation)[8]在RGB图像和点云特征提取网络之间构建双向融合模块作为两个网络的通信桥梁,实现外观特征与几何特征的过程融合。然而FFB6D仍存在以下问题:(1)RGB图像特征提取网络的首个卷积块仅负责通道调整,未抑制复杂背景;(2)FFB6D的RGB图像特征提取网络分支为编解码结构,输出的姿态语义特征缺乏目标物体的细节外观特征;(3)上下文信息存储了目标物体可见区域与遮挡区域的联系,FFB6D使用池化金字塔模块(Pyramid Pooling Module,PPM)[9]同等程度地增添全局上下文信息和区域上下文信息,然而由于目标物体的大小不同、遮挡情况不同,因此这些上下文信息的重要程度也应是不同的;(4)解码器将编码器学到的低分辨率的姿态语义特征上采样至像素空间,FFB6D易将表面相似的物体误判为目标物体。这都导致了复杂背景下弱纹理小物体6D姿态估计精度较低和遮挡场景下算法鲁棒性差。
针对上述问题,该文在FFB6D基础上,提出了一种基于特征融合和注意力机制的物体6D姿态估计算法,主要工作如下:(1)在RGB图像特征提取网络的首个卷积块中添加卷积注意力模块(Convolutional Block Attention Module,CBAM)[10],抑制复杂背景,增强目标物体区域的显著度;(2)使用跳跃连接将编码阶段的细节外观特征拼接融合到解码阶段的姿态语义特征,考虑到浅层特征中存在一定的干扰特征,在跳跃连接中使用CBAM过滤干扰特征,增强颜色、纹理等细节外观特征;(3)在PPM的末端拼接通道注意力模块(Channel Attention Module,CAM)[10],自适应地学习不同区域和不同尺度上下文信息的重要程度,提升遮挡鲁棒性;(4)在RGB图像特征提取网络的末端添加CBAM,从通道域和空间域分别增强相似表面特征的区分度,从而降低相似物体对物体6D姿态估计的干扰。
1 基于特征融合和注意力机制的物体6D姿态估计算法
基于特征融合和注意力机制的物体6D姿态估计架构图如图1所示,分别输入RGB图像和D图像,主干网络由RGB图像特征提取网络和点云特征提取网络并联而成,双向融合模块实现外观特征与几何特征的交互融合,将提取的密集姿态特征输入到3D关键点检测模块和语义分割模块,回归每一个点到3D关键点的偏移,并为3D关键点投票,确定3D关键点,最后使用最小二乘拟合算法计算物体6D姿态。

图1 基于特征融合和注意力机制的物体6D姿态估计网络架构
相较FFB6D网络,文中算法在负责通道调整的的卷积块后添加CBAM,实现复杂背景过滤和目标物体区域显著度增强;在RGB图像特征提取网络上构建基于CBAM的跳跃连接,充分利用姿态语义特征的同时最大限度地保留目标物体的颜色、纹理等细节外观特征;在PPM后添加CAM,通过对每个通道的特征进行权重分配来学习不同通道间特征的相关性,加强重要特征上下文信息的权重;在RGB图像特征提取网络的末端添加CBAM,进一步增大相似表面特征的区分度。
1.1 基于CBAM的复杂背景过滤模块
CBAM是一种轻量级的混合注意力模块,由CAM和空间注意力模块(Spatial Attention Module,SAM)串联而成,在通道域和空间域专注于物体6D姿态估计任务相关特征,如图2“Convolutional Block Attention Module”部分所示。对于输入特征图(F∈RC×H×W),其中C,H,W分别为特征图的通道数、高和宽,首先对特征图进行空间域的全局最大池化和全局均值池化,将池化后的结果送入到共享权重的MLP(Multi-Layer Perception),相加MLP得到的两个结果后再经过Sigmoid激活函数得到通道注意力权重(Mc),最后将F与Mc相乘,获得通道注意力调整后的特征图(F');对F'进行通道域的全局最大池化和全局均值池化,拼接池化生成的两个特征图,再经过卷积和Sigmoid,获得空间注意力权重(Ms),最后将F'与Ms相乘,获得空间注意力调整后的特征图(F'')。通道注意力和空间注意力计算过程如公式(1)和(2)。

图2 基于CBAM的复杂背景过滤模块
Mc=σ(MLP(AvgPool(F))+
MLP(MaxPool(F)))
(1)
Ms=σ(f7×7[AvgPool(F);MaxPool(F)])
(2)
其中,MLP为共享权重的多层感知机,σ为Sigmoid激活函数,f为卷积操作,“;”表示串行联结。
考虑到FFB6D的点云特征提取网络的预处理层为全连接层,无法使用CBAM抑制复杂背景,因此该文仅在RGB图像特征提取网络添加基于CBAM的复杂背景过滤模块,其具体流程如图2所示。首先使用Conv调整输入图像的尺寸和通道数,使其可传入到基于ResNet34的编码器,再使用CBAM抑制干扰特征,增强目标物体区域的显著度。
1.2 基于CBAM的跳跃连接
跳跃连接是一种常用于弥补编解码结构细节特征缺失的技术,如点云分割网络(RandLA-Net[11])。该网络通过跳跃连接将线、角、面等细节几何特征拼接到深层语义特征,使其具备高判别性。FFB6D的点云特征提取网络分支由RandLA-Net主干部分构成。然而,FFB6D的RGB图像特征提取网络分支并未采用跳跃连接,因此其输出的特征缺乏目标物体的细节外观特征。
该文使用类激活映射可视化FFB6D特征层,如图3所示。图3(a)框内为目标物体driller,分析图3(b)至图3(d)可知,除目标物体所在区域,其他区域仍存在高亮。这表明RGB图像编码器输出的特征仍存在干扰特征,因此若直接在FFB6D的RGB图像特征提取网络分支上构建跳跃连接,引入目标物体细节外观特征的同时,干扰特征也被引入。

图3 FFB6D的RGB图像特征提取网络分支的特征映射图
受启发于上述观察分析,该文提出了基于CBAM的跳跃连接,首先将编码阶段输出的特征传入到CBAM,在CBAM抑制干扰特征后,跳跃连接再将处理后的特征传入到解码阶段,与解码阶段输出的特征进行拼接融合,实现空间信息补充、细节外观特征与姿态语义特征的融合。
1.3 基于CAM的PPM
上下文信息存储了目标物体可见区域与遮挡区域的联系,针对性地增添上下文信息可更好地保留目标物体姿态特征。
基于CAM的PPM具体流程如图4所示。左侧模块为PPM,该结构先将特征图划分为1×1,2×2,3×3,6×6的子区域,然后分别在子区域内全局平均池化,从而获得不同尺度和不同区域的上下文信息,再使用1×1卷积对四个池化后的特征图进行降维,然后将四个结果分别上采样至原始特征图的尺寸,最后与原始特征图进行拼接。然而由于目标物体的大小不同、遮挡情况不同,PPM这种同等程度地增添不同尺度和不同区域上下文信息的方式难以针对性地应对遮挡问题。图4右侧模块为CAM,CAM是CBAM的通道注意力模块,通过全局最大池化和全局平均池化获取PPM输出特征图的判别性特征和全局上下文特征,以此选取并增强含有重要区域上下文信息的特征通道,从而针对性地解决遮挡问题,使得算法更好地摒弃遮挡区域的干扰特征,保留目标物体姿态语义特征,提升遮挡鲁棒性。

图4 基于CAM的PPM
1.4 基于CBAM的特征增强模块
基于CBAM的跳跃连接将编码器每一阶段的细节外观特征传送到解码器,实现外观细节特征与姿态语义特征的融合。然而当复杂背景或遮挡物和目标物体表面相似时,由于CBAM的特征分辨能力有限,基于CBAM的跳跃连接易将外观相似的背景或遮挡物的细节外观特征误判为目标物体特征,将其传送至解码器特征层,从而导致背景或遮挡物误判为目标物体。
该文在RGB图像特征提取网络的末端添加CBAM,在深层姿态语义特征充分融合细节外观特征后,CBAM结合深层语义特征的判别性,辨别外观相似的干扰特征,实现相似表面干扰特征的抑制,从而提升物体姿态估计精度。
1.5 损失函数
文中算法的目标是训练一个3D关键点检测模块,用于预测点到3D关键点的偏移,以及一个语义分割模块和中心点投票模块,用于实例级的语义分割。因此,该文使用一个多任务损失函数实现网络的学习,第一部分是关键点损失(Lkeypoint),第二部分是语义分割损失(Lsemantic),第三部分是中心点损失(Lcenter),整体的损失函数为L。
(3)
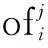
(4)
其中,γ是注意力参数,用于控制容易分类和难分类样本的权重,ci是预测的第i个点属于目标物体类别的置信度,l是真实类别的one-hot表达。
(5)
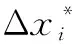
(6)
其中,λ1,λ2,λ3为平衡参数。
2 实验及结果分析
2.1 物体6D姿态数据集
LINEMOD数据集[12]由13类大小不同的家居用品组成,包括ape,duck和benchvise等,每个家居用品图像集包含约1 400张实拍图像。每张实拍图像均包含物体特性、环境等方面的影响因素,如弱纹理的目标物体、复杂背景等,但不包含遮挡。大多数工作中,LINEMOD数据集中15%的图像作为训练集,其余85%作为测试集。
Occlusion LINEMOD数据集[13]以LINEMOD数据集的benchvise图像集为基础,补充标注了含遮挡的ape,can,cat,driller,duck,eggbox,glue,holepuncher等8类目标物体的6D姿态,共1 214张,用于弥补LINEMOD数据集缺乏目标物体被遮挡情况图像的问题。Occlusion LINEMOD数据集用于测试在LINEMOD数据集上训练的模型,检验模型面对遮挡时的性能。
由于仅使用LINEMOD数据集15%的实拍图像难以训练一个精度高、遮挡鲁棒性强的模型。因此,该文使用PVN3D的图像合成策略扩容LINEMOD数据集,分别合成70 000张无遮挡单目标物体图像和10 000张含遮挡单目标物体图像,两部分合成图像及LINEMOD数据集15%的实拍图像共同构成训练集。为检验模型性能,该文使用LINEMOD数据集的85%实拍图像检验模型在复杂背景中的性能和Occlusion LINEMOD数据集的全部实拍图像检验模型在遮挡场景中的性能。
2.2 评价指标
该文分别使用ADD(-S)(average distance to the 3D(symmetric)model)[1]和FPS(Frames Per Second)对文中算法的精度和速度进行评价。
ADD(-S)是一种三维空间度量标准,其中ADD针对非旋转对称的物体,ADD -S针对旋转对称物体,计算通过预测姿态和真值姿态转换的模型顶点之间的平均距离,当距离小于阈值时,姿态估计正确。最常用的阈值为模型直径的10%,记作ADD(-S)-0.1d。平均距离计算公式如式(7)和式(8)。
(7)

(8)
其中,x1和x2表示最接近点对。
ADD(-S)精度计算公式如式(9)。
(9)
其中,Numpre表示正确姿态估计的数量,NumGT表示测试集图像的数量。
FPS是一种算法推理速度度量标准,指物体6D姿态估计算法每秒处理图像的帧数。
2.3 实验设置
实验使用基于NVIDIA GTX 2080Ti GPU的服务器,深度学习框架为PyTorch 1.6,编程语言为python 3.6。
关键点方面,使用SIFT算法检测物体的2D关键点,然后将其提升至3D空间,最后使用最远点采样算法选择3D关键点的前8个为物体关键点[7]。
在模型训练过程中,初始学习率设置为0.000 01,batchsize设置为2,epoch设置为25,γ设置为2,λ1,λ3设置为1,λ2设置为2,使用Adam优化器,采用循环学习率更新策略(Cyclical Learning Rates,CyclicLR)。
2.4 实验结果分析
2.4.1 复杂背景中弱纹理物体6D姿态估计
为验证算法在复杂背景下的优越性,以ADD(-S)-0.1d为指标,将文中算法与物体6D姿态估计领域中的不同算法进行对比,包括DeepIM(Deep Iterative Matching for 6D Pose Estimation)[14],PVNet(Pixel-wise Voting Network)[15],CDPN(Coordinates-based Disentangled Pose Network)[16],DPOD(6D Pose Object Detector and Refiner)[17],DenseFusion[4],文献[18],G2L-Net(Global to Local Network)[19],PVN3D[6]和FFB6D[8]。表1为对比结果。

表1 在LINEMOD数据集上各算法对比 %
分析表1发现,文中算法平均ADD(-S)为99.8%,相较FFB6D,平均精度提高了0.1百分点,其中弱纹理小物体ape和duck的ADD -0.1d分别提高了0.5百分点和0.1百分点,验证该算法可提升弱纹理小物体在复杂背景中的6D姿态估计精度。
2.4.2 推理速度分析
由表1可知,文中算法的推理速度为12 FPS,其中数据前向传播65 ms,姿态计算18 ms,满足智能机械人抓取和增强现实等应用实时性的基本需求。
对比表1中基于不同输入的算法推理速度,除DeepIM算法外,其余基于RGB图像的物体6D姿态估计算法的推理速度普遍快于基于RGBD图像的算法,这是由于基于RGB图像的算法仅需从RGB图像提取姿态特征,因此推理速度较快。DeepIM推理速度较慢的原因是,在预测目标物体初始6D姿态后,算法再迭代优化目标物体6D姿态,这极大增加了算法每帧图像的处理时间。
分析基于RGBD图像的物体6D姿态估计算法的推理速度。(1)DenseFusion和文献[18]的网络结构相似,均先借助一个语义分割网络分割出目标物体区域,然后分别从RGB图像和点云的目标物体区域中提取外观特征和几何特征,最后融合两种模态的特征,因此二者推理速度一致;(2)G2L-Net放弃使用推理速度较慢的语义分割网络,使用推理速度快的目标检测网络YOLO v3标注目标物体区域,在定位目标物体点云时,使用3D球形范围搜索替代较慢的矩形范围搜索,因此其推理速度得到提升;(3)上述三种算法的点云特征提取网络分支的输入为目标物体区域的点云,而PVN3D输入的点云为整个场景的点云,因此推理速度较慢;(4)FFB6D将PVN3D的点云提取网络替换为更加轻量级的RandLA-Net,推理速度得到提升;(5)文中算法基于FFB6D,添加注意力机制和特征融合模块,速度略有下降。
2.4.3 遮挡场景中弱纹理物体6D姿态估计
为验证算法在遮挡场景中的优越性,以ADD(-S)-0.1d为指标,将文中算法与物体6D姿态估计领域中的不同算法进行对比,包括文献[20],HybridPose[21],文献[22],PVN3D[6]和FFB6D[8]。表2为对比结果。

表2 在Occlusion LINEMOD数据集上各算法对比 %
分析表2发现,文中算法平均ADD(-S)为73.4%,相较FFB6D,平均精度提高了7.8百分点,达到了最高精度,且多种弱纹理物体精度均有提升,其中ape,cat,duck等弱纹理小物体的ADD -0.1d分别提升8百分点、9百分点和11.5百分点,验证该算法较好地缓解了遮挡对弱纹理小物体精度的损害。
在Occlusion LINEMOD数据集上,分析了遮挡与精度的关系,如图5所示。相较FFB6D,在不同遮挡情况,文中算法的物体6D姿态估计精度均有提升,尤其在20%到30%遮挡区间,文中算法展现了良好的遮挡鲁棒性,图5也直观地反映了文中算法遮挡鲁棒性的提升。

图5 遮挡与精度关系
2.5 消融实验
为验证基于CBAM的复杂背景过滤模块、基于CBAM的跳跃连接、基于CAM的PPM及基于CBAM的特征增强模块对实验结果的影响,设计了消融实验,逐步消除四个模块与FFB6D进行对比,根据模块添加数量由多到少分别命名为模型1~模型4。实验在LINEMOD数据集和Occlusion LINEMOD数据集上进行验证。消融结果见表3。
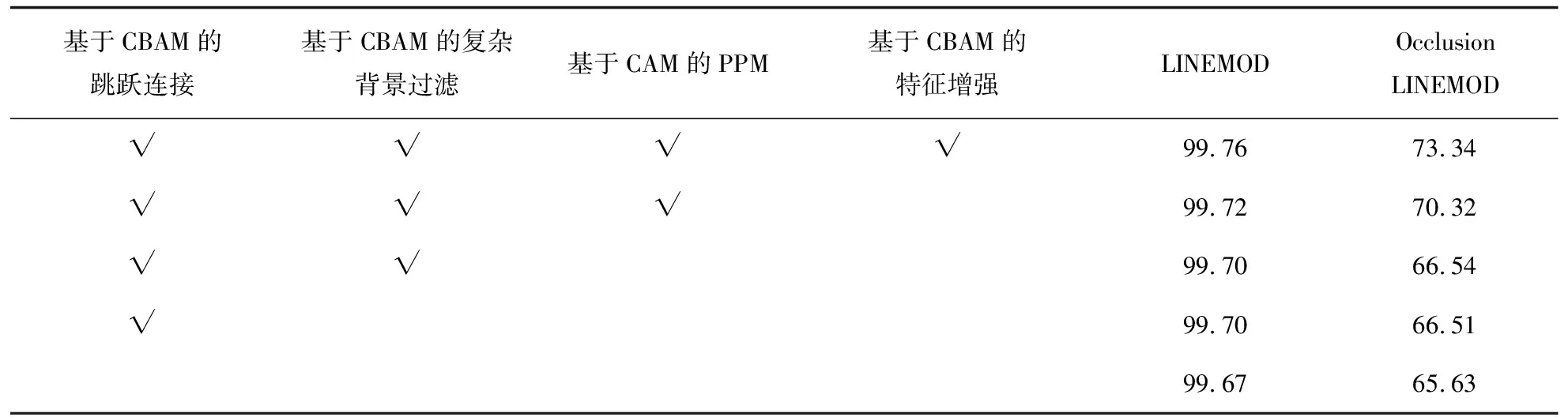
表3 消融实验结果 %
从表3可以发现,在Occlusion LINEMOD数据集上,模型1(文中模型)的平均精度为73.34%,相较FFB6D提升了7.71百分点,表现出较优的遮挡鲁棒性,验证了该文对算法遮挡鲁棒性差的原因分析,也证明了所提出措施的可行性。值得注意的是,基于CBAM的跳跃连接、基于CAM的PPM和基于CBAM的特征增强模块效果显著,具体分析如下。
(1)基于CBAM的跳跃连接对复杂背景中弱纹理物体6D姿态估计精度提升贡献较大,在LINEMOD数据集上,模型4相较FFB6D提升了0.03百分点。究其原因,FFB6D网络采用编解码结构,编码阶段使用卷积网络进行连续多次下采样,使得模型丢失大量颜色、纹理等细节特征,而解码阶段仅对深层姿态语义特征进行上采样,导致解码阶段的特征几乎不含细节特征。然而,目标物体处于不同的6D姿态时,其所呈现外观也有所不同,因此在姿态语义特征中引入颜色、纹理等细节特征可指导算法更好地估计目标物体6D姿态。
(2)基于CAM的PPM对算法的遮挡鲁棒性贡献最大,在Occlusion LINEMOD数据集上,模型2相较模型3提升了3.78百分点。基于CAM的PPM根据目标物体的大小和遮挡情况,自动获取每个特征通道的重要程度,加强含有重要区域上下文信息的特征通道的权重,使算法更好地应对多变的遮挡情况。
(3)基于CBAM的特征增强模块对复杂背景中弱纹理物体6D姿态估计精度提升贡献最大,在LINEMOD数据集上,模型1(文中模型)相较模型2提升了0.04百分点;对遮挡场景中物体6D姿态估计贡献较大,在Occlusion LINEMOD数据集上,模型1(文中模型)相较模型2提升了3.02百分点。受限于CBAM的特征分辨能力,基于CBAM的跳跃连接将表面外观相似的干扰特征误判为目标物体特征并将其与深层语义特征融合,因此,进一步抑制复杂背景和遮挡物的干扰特征是有必要的。基于CBAM的特征增强模块添加在RGB图像特征提取网络末端,结合深层姿态语义特征,从通道域和空间域分辨并抑制相似外观的干扰特征,从而提升物体6D姿态估计精度。
实验使用类激活映射分别在FFB6D、基于特征融合和注意力机制的物体6D姿态估计网络的第一层、第五层和第九层进行特征可视化,如图6、图7和图8所示。

图6 第一层特征映射图

图7 第五层特征映射图

图8 第九层特征映射图
结合图6发现,图6(b)相较图6(a)特征图更清晰,混影减少,这说明基于CBAM的复杂背景过滤模块可实现复杂背景的过滤与目标物体区域的增强。结合图7发现,图7(a)特征图虽保留了较多特征,但噪音较多,图7(b)特征图的噪音几乎都被去除,这说明基于CAM的PPM有助于保留姿态语义特征。结合图8发现,图8(a)特征图在目标物体区域和遮挡区域均存在高亮凸起,图8(b)特征图仅在目标物体区域存在高亮凸起,这说明基于CBAM的特征增强模块可抑制外观相似物体的干扰。
2.6 实验结果可视化
该文选取FFB6D姿态预测失败的Occlusion LINEMOD数据集的部分图像,图9(a)白框内为目标物体,其类别分别是ape,cat,driller,glue,holepuncher等。首先,使用文中算法计算物体6D姿态,再结合物体的三维模型,将其重投影至原图像,其投影结果用白色表示,如图9(b)所示。由图9可知,遮挡场景中,无论是小物体cat,duck还是大物体driller,glue和holepuncher,算法仍可准确地预测姿态,也验证该算法有较好的遮挡鲁棒性。

图9 部分实验结果可视化
3 结束语
针对物体6D姿态估计易受真实场景的复杂背景、目标物体的弱纹理和小体积特性、物体间相互的遮挡影响,使用基于CBAM的复杂背景过滤模块提升目标物体在复杂背景中的显著度;使用基于CBAM的跳跃连接对深层姿态语义特征进行颜色、纹理等细节外观特征补充;使用基于CAM的PPM和基于CBAM的特征增强模块突出目标物体未被遮挡区域,提升遮挡鲁棒性。实验结果表明,该算法在几乎不增加网络负担的情况下,在LINEMOD数据集上,平均ADD(-S)-0.1d提高了0.1百分点,在Occlusion LINEMOD数据集上,平均ADD(-S)-0.1d提高了7.8百分点,提升了算法的遮挡鲁棒性。由于增强现实和智能机器人抓取等领域的应用多部署在存储空间小和算力低的设备,因此,优化模型体积和提升推理速度是下一步的研究重点。
猜你喜欢
学生天地(2020年3期)2020-08-25 09:04:16
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2018年19期)2018-11-14 02:37:08
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
自动化学报(2017年11期)2017-04-04 02:52:58
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
噪声与振动控制(2015年4期)2015-01-01 07:08:21
外语学刊(2011年1期)2011-01-22 03:38:33
