
工业设备故障处置知识图谱构建与应用研究
2023-12-27 14:53瞿智豪胡建鹏黄子麒
计算机工程与应用 2023年24期
瞿智豪,胡建鹏,黄子麒,张 庚
上海工程技术大学 电子电气工程学院,上海 201620
工业生产设备的故障处置,主要依靠维修人员和专家现场排查,并根据自己的经验和知识进行故障处置[1],这种方法效率较低。工厂的设备故障处置记录中记录了每次设备故障处置的设备、人员、故障的原因、处置过程等信息,蕴含大量的知识和经验,但这些记录大多以非结构化的形式表达,无法快速准确地从中获取到所需的内容,从而使这些记录的价值无法充分发挥。以及通过对设备故障处置记录文本中蕴含的知识和经验的挖掘[2],构造工业设备故障维修处置知识图谱,可以有效解决上述问题。
知识图谱(knowledge graph,KG)[3]是谷歌公司(Google)在2012 年正式提出的。本质上说,知识图谱就是表示实体之间关系的语义网络。知识图谱通过命名实体识别[4-6]、实体间关系抽取[7-9]等技术,将真实世界中的广阔自然语言文本中的实体、关系以节点和边的形式,以<头实体-关系-尾实体>的三元组形式构建结构化的语义知识网络,并可以以图的形式展现出来。知识图谱相关技术赋予了机器理解世界知识的能力。
当前,在工业设备故障处置领域,曹现刚等[10]在煤矿装备维护领域提出了自顶向下构建知识图谱的方法,但没有提出具体的实验内容;韩涛等[11]在航空发动机故障知识图谱的构建中提出了一种融合字、词序列信息的Lattice Transformer-CRF 实体抽取方法,效果有一定提升,但是准确率提升只有0.52%;郭榕等[1]利用TextCNN、LR-CNN 和BiGRU-Attention 等深度学习模型进行电网故障处置文本的知识抽取,相较于BiLSTM-CRF 模型,准确率只提升了1.9%;聂同攀等[12]利用BiLSTM网络对飞机电源故障排故手册进行知识抽取并构造知识图谱,并将其应用于排故搜索和问答中;李新琴等[2]采用BiLSTMCRF模型对高铁信号设备故障文本进行实体抽取,但并未对比其他模型,只说明该模型有可用性。目前利用知识图谱技术辅助设备故障处置已有不少落地实践,取得了一定的效果,但大多数还存在以下不足:
(1)训练基于深度学习的实体抽取模型前,需要对训练文本中的实体进行标注,在现有研究中都是采用人工标注的方式,这样做耗时耗力。(2)现有研究中,现有的实体抽取方法应用在工业设备故障处置文本中的效果不够好,准确率还不够高,少数对现有模型的改进提升效果不够明显。(3)在应用方面,工厂中将多模态信息和知识图谱融合的应用实践较少,需要进一步研究。
为解决上述问题,本文以某工厂生产执行系统(manufacturing execution system,MES)中的生产设备故障处置记录为数据源,利用爬取的网络数据、MES相关数据、外部知识库和工厂内多模态信息等多源信息,分别提出一种基于外部知识实现对设备故障处置实体的半自动标注方法,减少人工标注成本;提出一种融入词性和词边界信息的设备故障处置文本实体抽取方法,提升该领域实体抽取性能;最后利用工业设备故障处置知识图谱提出一种设备故障处置的智能推荐方法流程。
1 设备故障处置知识图谱构建流程
知识图谱主要有两种构建方法,分别是自顶向下和自底向上的方法[13]。自底向上的方法是首先抽取出数据源中的实体和实体间关系,通过归纳知识抽取结果,将模式层抽象出来,最后形成知识图谱;自顶向下的方法先定义实体类型和实体间关系,把知识图谱模式层构建出来,然后对数据源进行知识抽取,并按照构建好的模式层将知识储存到数据库完成知识图谱的构建。两种方法适用于不同类的知识图谱构建,通用知识图谱[14-15]的构建涉及的知识面广,包含的实体类型和实体间的关系较为复杂,所以适用于自底向上的方式;而在构建领域知识图谱[16-17]时,由于其所涉及知识范围较为明确,专业性强,实体类型和关系在该领域较为固定,因此领域知识图谱的构建多使用自顶向下的构建方式。本文构建的设备故障处置知识图谱属于领域知识图谱,故使用自顶向下的构建方式。自顶向下构建知识图谱的流程如图1所示。
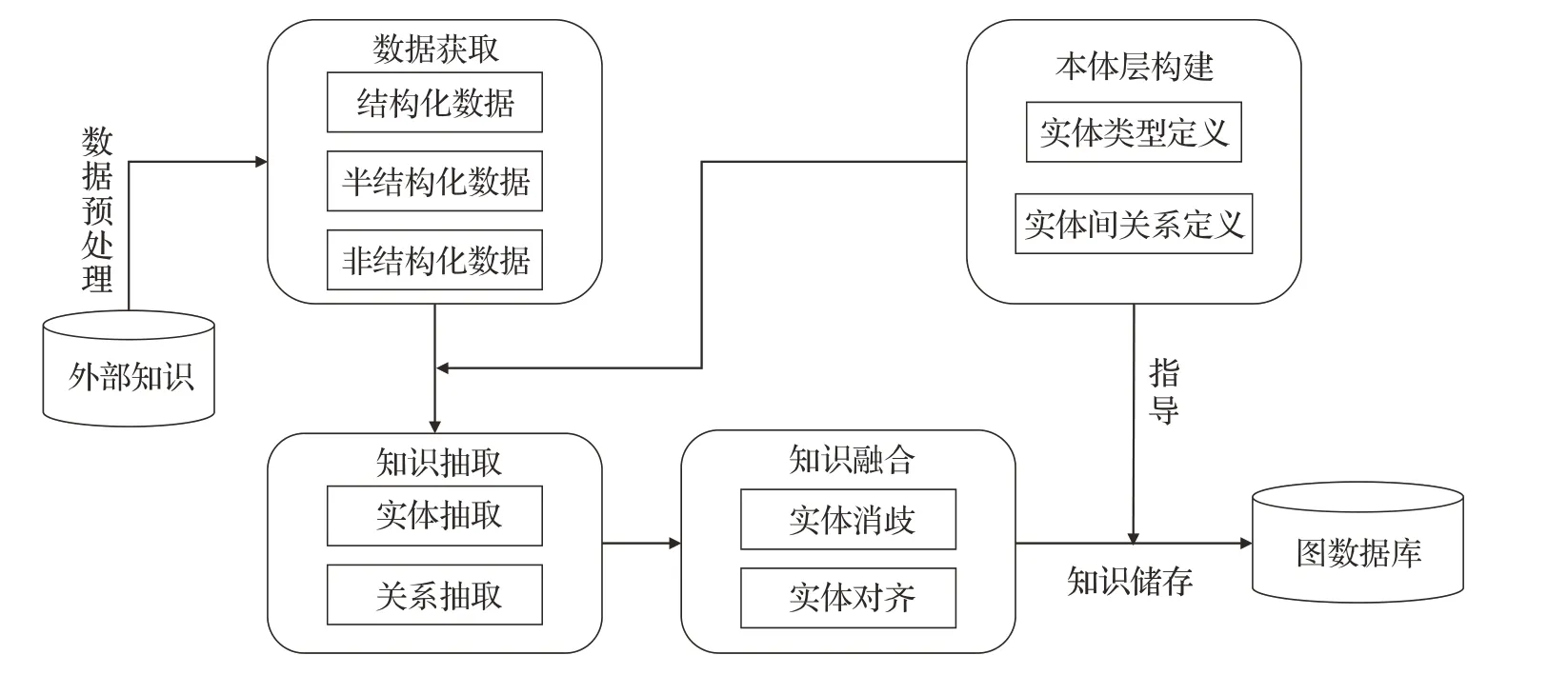
图1 知识图谱构建流程Fig.1 Construction process of knowledge graph
本文设备故障处置知识图谱的构建分为两层,即模式层的构建和数据层的构建。首先,要获取到构建设备故障处置知识图谱的数据源,其中包含有结构化数据、半结构化数据和非结构化数据,同时,根据获取到的数据,在领域专家的指导下,完成知识图谱模式层的构建;在进行知识抽取前,在设备资料和义原等外部知识的指导下完成对待抽取数据的半自动化标注以减轻人力和时间的消耗;利用基于模板以及基于深度学习的方法进行实体和实体间关系抽取,完成知识抽取即数据层的构建;之后,将实体和实体间关系按照本体层的模式存入Neo4j图数据库[18]中并可视化以及完成相关应用。
2 基于外部知识库的设备故障处置实体半自动标注
在领域专家的指导下,通过对获取的设备故障处置记录分析后,确定了领域实体类型为人员、设备、故障描述、故障部件、维修动作和维修部件以及它们之间的关系,其中人员和设备有字典匹配,无需标注。
领域内的实体、属性和它们之间的关系如图2所示。

图2 知识图谱实体、属性和关系Fig.2 Entity,property and relationship of knowledge graph
由于设备故障处置领域的文本专业性强,如果依靠纯人工进行标注,需要大量人力和时间成本,且人工标注难免出现标注错误和漏标。基于以上原因,对实体进行高效又准确的自动或半自动标注是亟需解决的问题。
在通用领域,可以利用开源的分词工具将通用领域的文本中的词语按词性划分开,只需少量人工复核即可完成实体自动标注;在其他专业领域如医疗、金融等,因为其涉及知识面较为统一,有质量较高的专业名词库,以此可以作为实体词典进行自动标注;但在本文的工业设备故障处置领域,由于细分领域很多,且即使是同一领域,不同的企业使用的设备也不尽相同,没有相关的知识库可以用于实体标注,利用开源的分词工具无法很好地识别设备故障维修领域的实体。本章基于外部知识提出了一种可以应用于工业设备故障处置领域实现半自动实体标注的方法。
2.1 外部知识库
本文所述外部知识包括从网页爬取的相关设备的技术资料和知网(HowNet)义原知识库。从网页爬取的相关设备的技术资料可以帮助构建初始的设备部件词典,义原(Sememe)作为语言学中最小的不可再分的语义单位[19],可以将设备部件的语义归为最基础的几类,从而帮助判断设备部件词。
HowNet 是最著名的义原知识库,它构建出了一套包含约2 000 个义原的体系。除外部知识库外,本节方法还利用了词性和依存句法等多源信息,本文使用语言技术平台(language technology platform,LTP)进行词性和依存句法的分析[20]。
2.2 设备部件实体半自动标注
设备部件实体半自动化标注的核心,是要构造设备部件实体词典。以本文所获取的石墨散热膜生产故障维修记录的设备故障、维修部件实体为例,下面介绍本方法。
通过获取的相关设备的技术资料,可以得到某设备各模块的介绍和各模块功能,从中可以获取一些该设备的部件名称,将其作为初始设备部件词典。以某厂商石墨化炉为例,从该设备技术资料中可以得到设备部件初始词典{炉体,内胆,电极法兰口,红外测温孔,出气口,炉盖,进气口,坩埚,感应器,刚玉,铜管,谐振电容器,红外测温仪,直连式机械泵,带充气电磁真空阀,真空蝶阀,隔膜阀,管道,控温仪,真空泵,机柜}。
将该词典的每个词都进行义原查询,得到初始义原类型表为{用具,部件,工具,设施,传送},此外,考虑到设备部件词多为“名词+词缀”的形式,如“隔膜阀”为“隔膜+阀”的形式,因此依照初始设备部件词典,建立初始设备词缀字典{器,仪,阀,泵}。
得到了初始设备部件词典、初始义原类型表和初始词缀字典后,将初始词典加入到LTP 分词中,对输入的原始文本进行分词和词性标注,将属于初始设备部件词典的词直接标注为设备部件,将词缀字前是名词的词提取出来进行人工核验,如果该词加词缀字是设备部件,则将其加入到设备部件词典中;选取分词结果为名词的词进行义源搜索,对义原属于义原类型表的词标注为设备部件实体并加入到设备部件词典中,对有义原但义原不在初始义原类型表中的词核查,是设备部件则将其义原补充到义原类型表中,并将该词加入到设备部件词典中,并将新得到的设备部件词的词缀更新到设备词缀字典中,方法流程如图3所示。
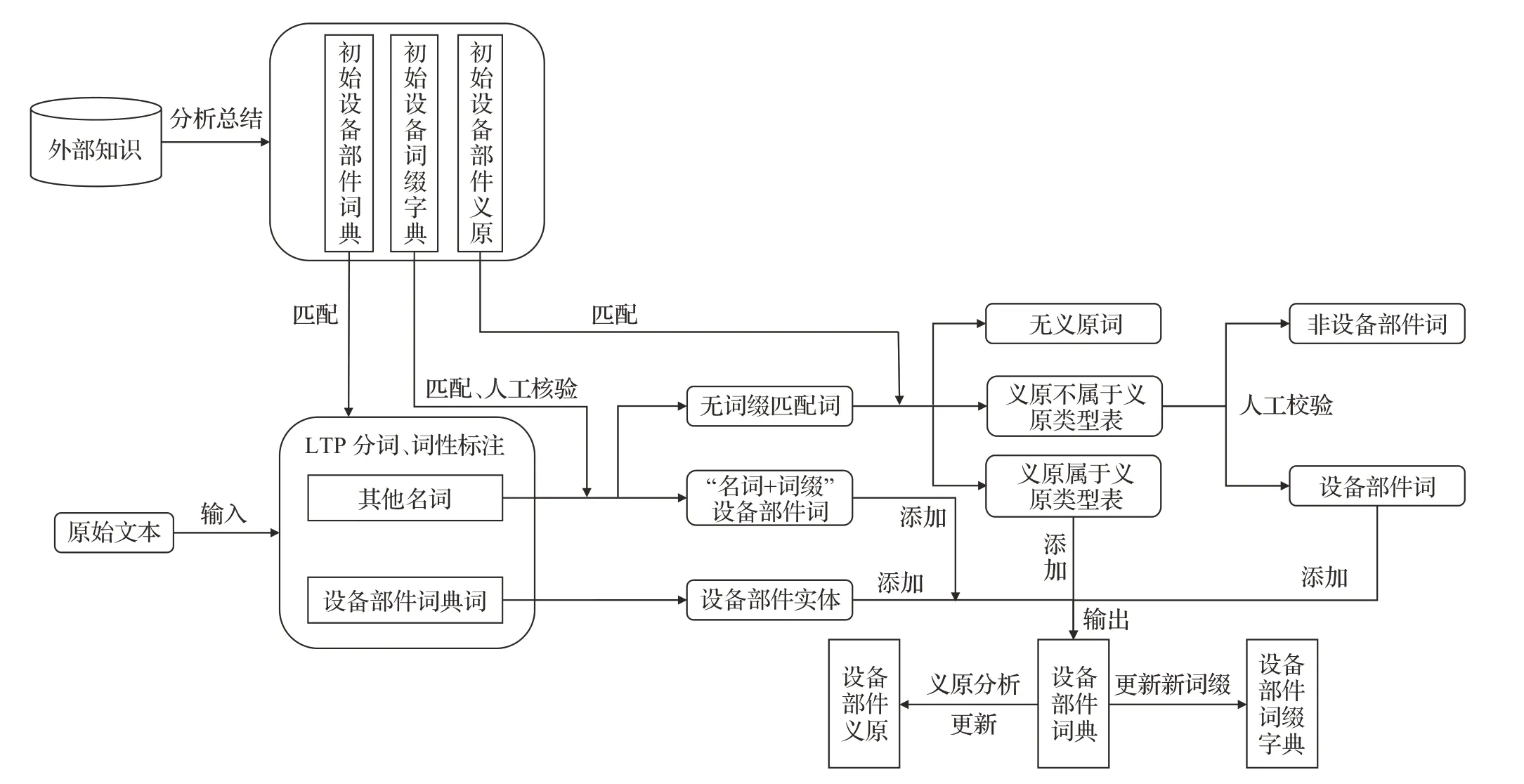
图3 设备部件实体半自动标注方法Fig.3 Semi-automatic marking method of equipment partentity
2.3 故障描述、维修动作实体的自动化标注
故障描述是对故障设备部件故障原因的描述,一般是动词和动补短语,维修动作这是维修员对故障的部件进行维修的动作,绝大多数都是动词。图4所示是对故障描述和维修动作实体进行半自动化标注的方法流程。
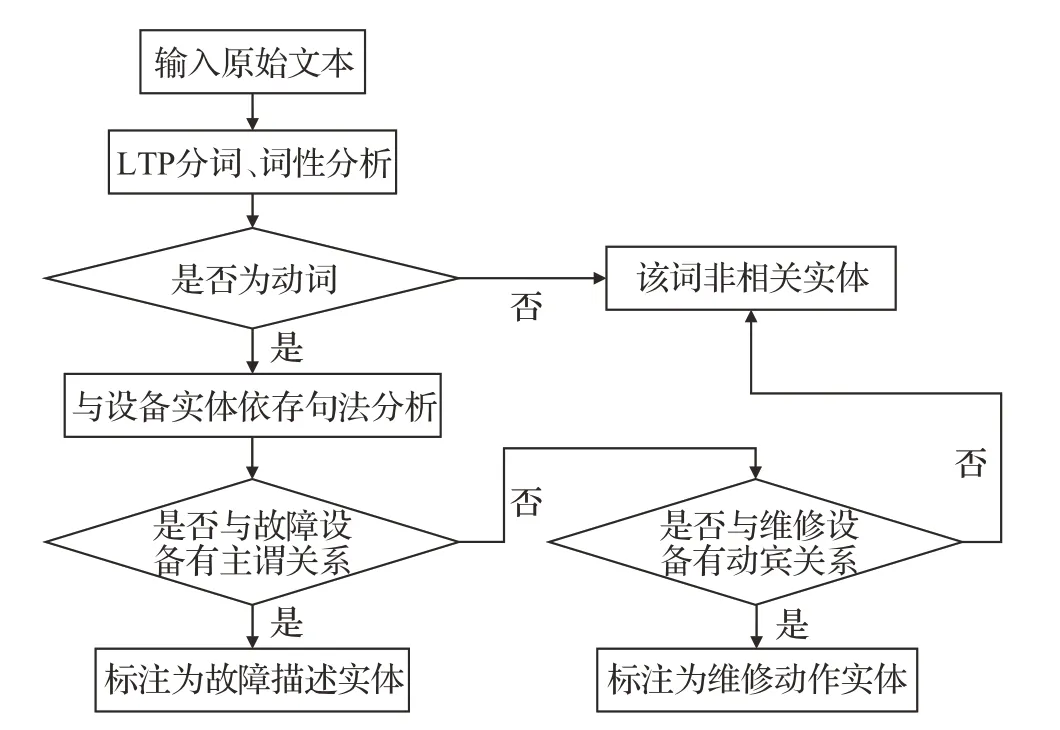
图4 故障描述和维修动作实体半自动化标注流程Fig.4 Semi-automatic marking flow of fault description and maintenance action entity
首先利用分词工具将文本分词并标注词性,将识别出的动词与标注好的故障部件和维修部件做依存句法分析,如果该词与故障部件是主谓关系(SBV)则该词为故障描述实体,并将该词与后面紧邻的词做依存句法分析,如果关系是动补结构(CMP)则将该词与后面紧邻的词一起标记为故障描述实体;如果该词与维修部件有动宾关系(VOB),则将该词标记为维修动作实体。
3 融入词性和词边界信息的设备故障处置文本实体抽取方法
本文提出一种将词性和词边界信息融入字嵌入的实体抽取方法,本文模型的输入是设备故障处置记录文本,之后的字嵌入中利用基于BERT(bidirectional encoder representation from transformers)[21]预训练模型获取文本字向量,并通过对文本中的词语分析和定义生成出融合了字所在词的词性信息和词边界位置信息的词性向量,将其与字向量进行拼接输入模型训练,通过双向长短时记忆网络(bidirectional long short-term memory,BiLSTM)学习字嵌入的上下文等特征,最后利用条件随机场(conditional random field,CRF)对整个标注序列的联合概率分布进行序列标注,从而预测实体的类型和位置信息[22-23]。相比与其他方法,本方法在输入模型训练时就对文本中各字词包括上下文信息、词性信息、词边界位置信息有充分表达,这些特征是设备故障处置文本中字词语义的重要组成部分。
如图5所示,为本文实体抽取模型示意图。
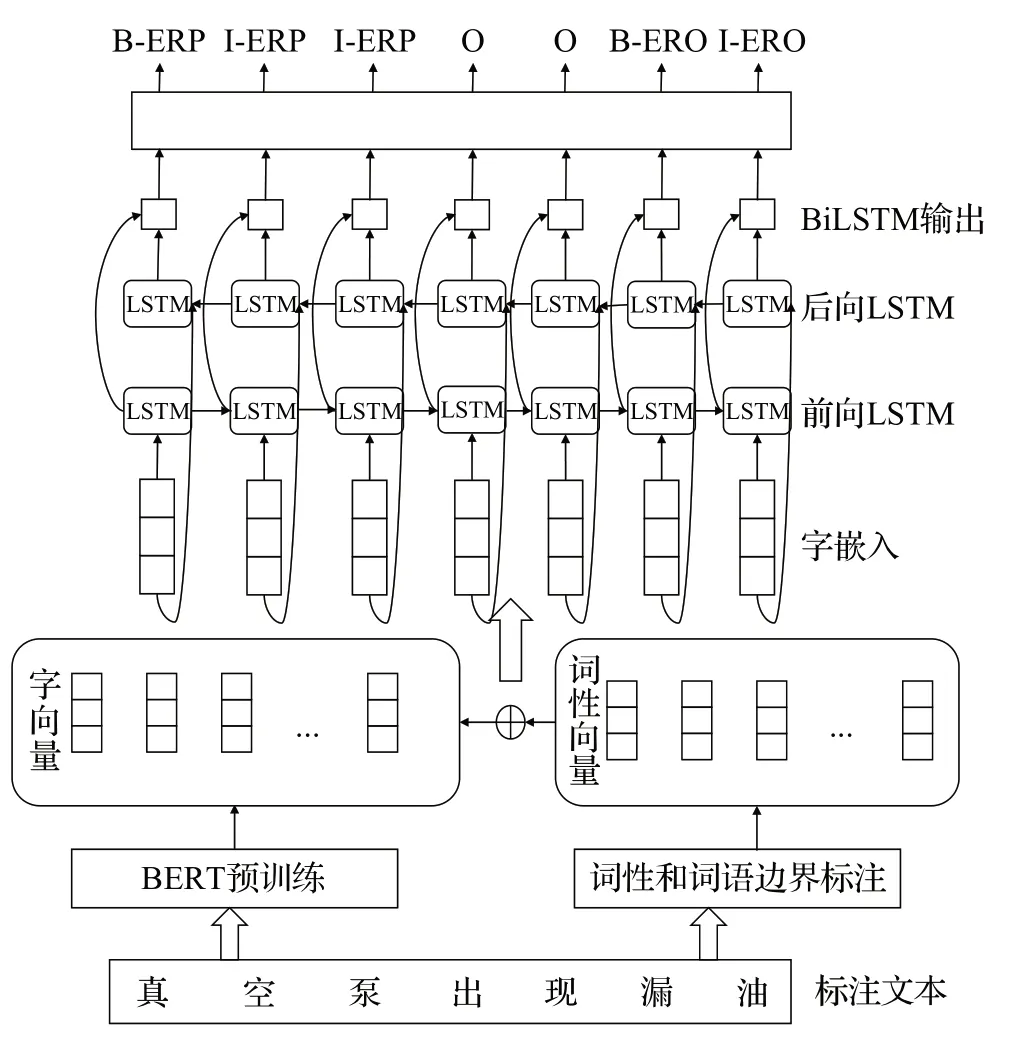
图5 实体抽取模型示意图Fig.5 Schematic diagram of entity extraction model
3.1 字嵌入层
3.1.1 BERT预训练模型
BERT 是2018 年由谷歌提出的一种双向上下文特征编码的预训练模型,结构如图6所示,BERT由输入层(E1,E2,…,En)、编码层Transformer编码器(图中的Trm)和输出层(T1,T2,…,Tn)构成。BERT的输入(E1,E2,…,En),它是三种嵌入的和,即对字/词的嵌入、字/词所在句子的嵌入,和字/词所在句中位置的嵌入。输入(E1,E2,…,En)经Transformer编码器处理后的向量又进入另一方向的Transformer 处理,最终得到BERT 字向量(T1,T2,…,Tn)。
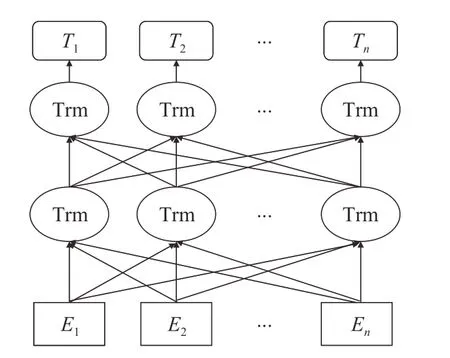
图6 BERT结构Fig.6 Structure of BERT
3.1.2 词性信息和词边界信息
在只使用BERT输出字向量作为字嵌入输入时,很多识别错误的原因是实体的位置信息识别错误,以及实体的类型识别错误。如图7所示。

图7 BERT识别错误情况Fig.7 Identifies error conditions of BERT
通过基于外部知识库的实体标注,可以利用相关信息扩充实体字嵌入时的语义信息,从而可能一定程度上解决这个问题。本文将词性向量融入到字嵌入中,本文词性向量定义为融合词性与词边界位置信息的向量。
词性一般有动词、名词、形容词、副词等类别,但是在设备故障处置领域,除了故障描述和维修动作实体,绝大多数实体都是属于名词,如果单纯将名词作为词性特征向量输入到字嵌入中,会丢失掉很多语义信息,因此,本文将人员类实体定义为姓名词(nn),将设备实体定义为设备名词(en),将故障部件和维修部件等名词性实体按照实体半自动标注时生成的设备部件词缀字典{灯,管,泵,盒,阀,表,轴,门,机,膜,器,杆,炉,仪,罐,板,缸,刀,闸,柜,垫,柜,带},将设备部件实体分为以上23种和无词缀设备共24 种词性,加上姓名词和设备名词共26种词性。
词边界信息即实体词中某字所在词的位置的信息,对词边界信息的表达一般有BIOES 和BIOS 等标注法,如实体“热电偶”中热为词首字表示为B,电为词中间字表示为I,偶为词尾字表示为E,单字实体的词边界信息表示为S,非实体字表示为O,即BIEOS标注法,而BIOS标注法则是将实体词中除词首字以外的字标注为I。在分析文本时发现,有些处于实体词尾的字在其他实体中处于词中的位置,而采用BIOES标注法会对这样的情况造成一定的混淆,因此本文对于词边界信息的描述,采用BIOS标注法,即定义词首字B、词中间字I,单字实体为S,非实体为O。
3.1.3 字嵌入
在进行字嵌入时,词性信息和词边界信息会转化为词性向量。在字嵌入中融合词性和词边界信息后,可以表达更完整的语义信息,能够补充一些语义缺失,进一步提升实体抽取效果。
定义字嵌入向量为X,定义融合词性信息和词边界信息的词性向量为N=(n1,n2,…,n30),N是一个30 维的向量,n1到n26表示某字的词性信息,将定义的26种词性每一种定义为1 维,如某字所在词属于某种词性,则将该词性所在维定义为1,其余维定义为0;n27到n30表示某字的词边界信息,按BIOS 的顺序定义n27到n30,当某字属于某词边界位置则将该维定为1,其他维为0,例如“真空泵”中的“真”的词性向量N=(0,0,1,0,…,n26,1,0,0,0)。将词性向量与BERT 预训练的字向量T=(T1,T2,…,Tn)与N=(n1,n2,…,n30)拼接,即得到最终的字嵌入:
X作为BiLSTM-CRF层的输入进行进一步训练。
3.2 BiLSTM-CRF层
BiLSTM 由前向和后向的LSTM[24]组成,双向的LSTM能够充分学习文中字两个方向的上下文关系,CRF[25]利用具有大量特征的观测序列,通过计算整个标注序列的联合概率分布进行序列标注,从而预测实体位置。
LSTM 包括输入门、遗忘门和输出门,以此来控制长短时记忆,遗忘掉不重要的长时间记忆,从而解决RNN的长依赖问题。单个LSTM的网络结构如图8所示。
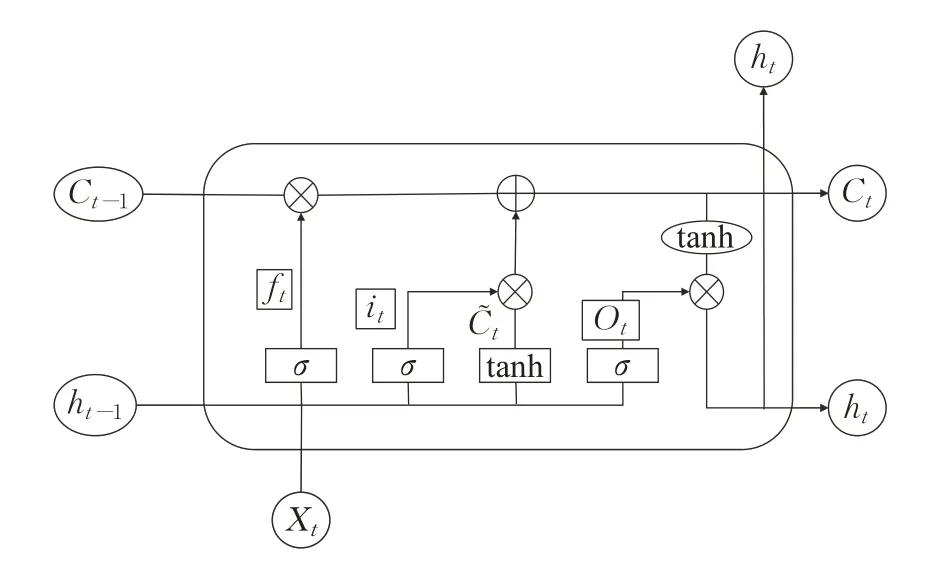
图8 LSTM结构Fig.8 Structure of LSTM
i、f、o分别为输入门、遗忘门和输出门的输出,h和C分别是LSTM 的输出和神经细胞状态,X为输入的字嵌入向量,σ为sigmoid激活函数。由图可知,细胞状态C直接在链上作少量的线性计算,信息在上面流转保持不变会很容易。遗忘、记忆和输出都由上一时刻的Ht-1和当前输出Xt经计算得到的ft、it、ot得出。按公式(2)~(7)可以计算出三个门的输出以及候选细胞信息。
式(2)至(7)中Wf、Wi、Wo表示各门的权重矩阵,bf、bi、bo为三个门的偏置矩阵。
BiLSTM 拥有前向和后向两个特征输出信息hb和hf,通过将hb和hf拼接得到BiLSTM的输出的结合了上下文语义特征的H:
对于输入的句子,实体标注应考虑句子中目标词与其上下文标签之间的联系,然后采用全局最优思想实现标签序列预测。CRF是一种判别概率模型,它关注句子的整体位置,可以依据目标观测序列对其最有可能的输出标注序列进行预测[23],
对于一个输入序列X={x1,x2,…,xn},其标签预测序列为Y={y1,y2,…,yn},由BiLSTM 输出的分数矩阵为P=(pij)n*k,其中n表示字符个数,k为输出标签的数量pij为句中i字符是j标签的非归一化概率。打分函数s(X,y)为:
式中,A=(aij)k+2其中为转移得分矩阵,aij表示标签i到标签j的转移得分。y0和yn表示开始和结束的标记。定义X为输入,Y为预测标签,p(y|x,ω)为CRF 估计X对应的Y的结果:
其中,φ(x,y)表示特征向量,ω为参数向量,Z(ω,x)为对所有可能的y的概率的和。训练集(Y,X)={xi,yi}(i=1,2,…,n)通过最大化条件似然实现模型的训练,给定输入序列x和参数ω,经过上述训练,得到模型的标签预测序列y*:
4 实验分析
本文中,深度学习模型的性能评价指标采用准确率P、召回率R和F1分数,计算公式如式(12)~(14):
其中,Nc表示识别出正确实体的个数,Nr表示识别出的实体数,N表示实体总数。一般来说,准确率和召回率是相互影响的,准确率上升时,召回率会下降,反之亦然,因此引入评价分数F1才能更好评价模型性能,F1值越高模型性能越好。
4.1 设备故障处置实体半自动标注示例
利用本文提出方法,经过6 次迭代后,设备部件词典无法再更新新的实体词,最后一次更新的设备部件词典中共有501 个词,经过专业人员的核对,除去因人员录入记录时的输入错误,词典中属于相关生产设备的部件有451 个,将词典纠正后,即得到了最终的设备部件词典。表1所示为每次迭代所得设备部件词数。

表1 历次迭代设备部件词数Table 1 Words of equipment parts in previous iterations
以此为基础,利用正则匹配对源文本中的故障部件和维修部件进行实体标注,并对未在词典中的实体进行补充标注,同时将人工标注的实体也添加到相应词典中,以便以后使用。以本文为例,以本方法得到的设备部件词典占实体总数的48.6%,用于对设备部件实体的标注中,减少了近一半的人力消耗,并且在故障描述和维修动作的实体标注中也节省了大部分人力标注成本。
4.2 实体抽取模型验证
4.2.1 实验参数设置
实验前,将实验文本将4 430 条设备故障维修记录文本按7∶2∶1的比例划分训练集、测试集和验证集。实体抽取任务采用BIOS 标注法,维修领域实体抽取的数据集使用处理后的设备故障维修记录。数据使用BIOS序列标注法按本文提出半自动标注方法对实验数据进行标注,具体标签如表2 所示。表3 为实验环境及配置。实验参数设置如表4所示。
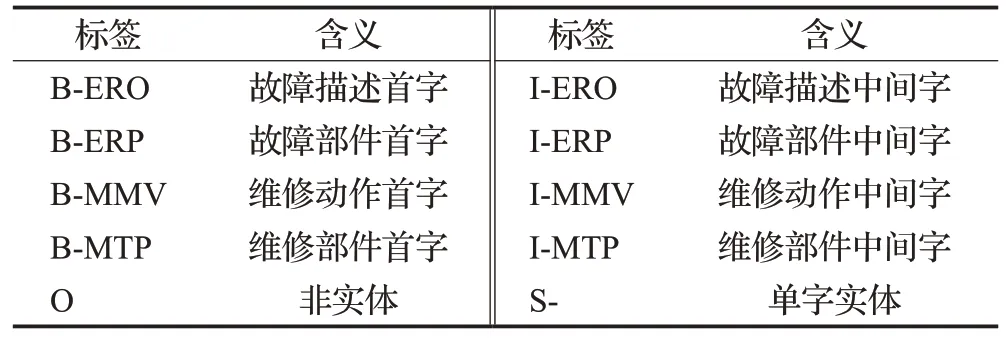
表2 数据标签及含义Table 2 Labels and its meanings

表3 实验环境及配置Table 3 Experimental environment and configuration

表4 实验参数设置Table 4 Experimental parameter settings
4.2.2 实验与分析
本文在自构设备故障维修数据集上,分别采用融入词性和词边界信息的Part-Pos-BERT-BiLSTM-CRF、BERT-BiLSTM-CRF、Part-Pos-Word2Vec-BiLSTM-CRF,以及只在词嵌入中加入词性信息和只加入词边界位置信息的Part-BERT-BiLSTM-CRF 和Pos-BERT-BiLSTMCRF进行性能对比,实验结果如表5所示。
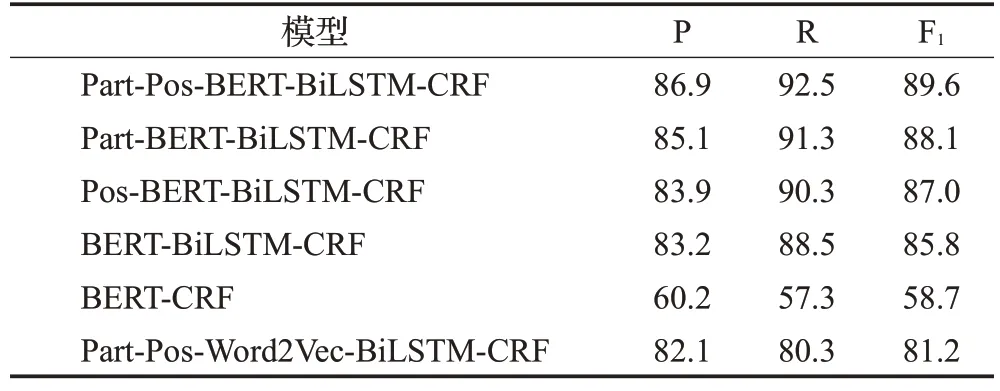
表5 不同模型结果对比Table 5 Comparison of results of different models 单位:%
从实验结果可以看出,本文提出的融入词性和词边界信息的BERT-BiLSTM-CRF(Part-Pos-BERT-BiLSTMCRF)模型在三项性能指标中都取得了最好的效果。通过对比Part-Pos-BERT-BiLSTM-CRF与Part-Pos-Word2Vec-BiLSTM-CRF 的结果发现,BERT 预训练模型在生成字向量阶段就考虑到了双向的上下文语义信息,比传统的Word2Vec 更好;在词嵌入中只融入词性信息或只融入词边界信息的模型性能指标也比基准的BERT-BiLSTM-CRF 模型更好,但是不如同时融入词性和词边界信息的Part-Pos-BERT-BiLSTM-CRF模型。实验结果说明,在工业设备故障处置领域,在字嵌入时融合词性和词边界信息等多源信息,使其蕴含丰富的语义信息,对模型性能的提升有所帮助,相比BERT-BiLSTM-CRF模型,本文模型在F1上提升了3.8个百分点。
图9 为本文模型、BERT-BiLSTM-CRF 模型及Part-Pos-Word2Vec-BiLSTM-CRF 模型训练时F1性能指标曲线,横坐标为迭代次数,纵坐标为F1值。
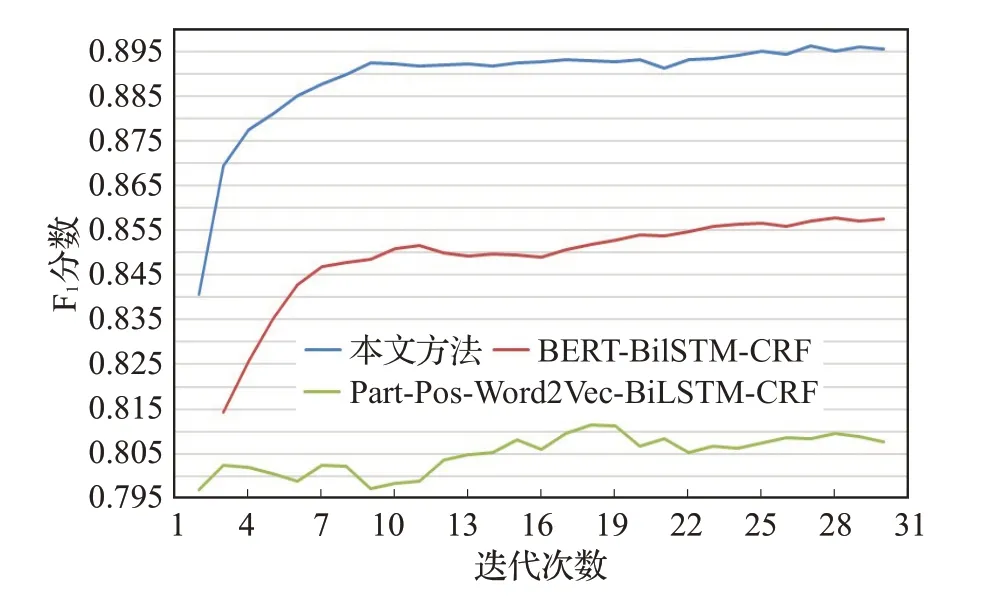
图9 各模型训练F1性能指标曲线Fig.9 Performance index curve of F1 of each model
从图9 可以看出,本文模型相较于BERT-BiLSTMCRF,在F1分数上,本文模型在迭代到第8次后,就以达到较高性能,上升曲线变得平稳,而BERT-BiLSTM-CRF模型则在第20 次迭代后F1分数才开始变得平稳,说明在字嵌入中融入了词性和词边界信息后,模型能够用更少的迭代次数便得到较好的结果。
4.3 知识图谱可视化
经过知识抽取,从近30 万字的设备故障处置记录中,抽取出总计22 709个实体,7种关系共31 010条实体间关系。将各实体、实体间关系列到一张Excel表格中,并将其导入Neo4j中,并以图的形式呈现。如图10所示为部分知识图谱可视化。
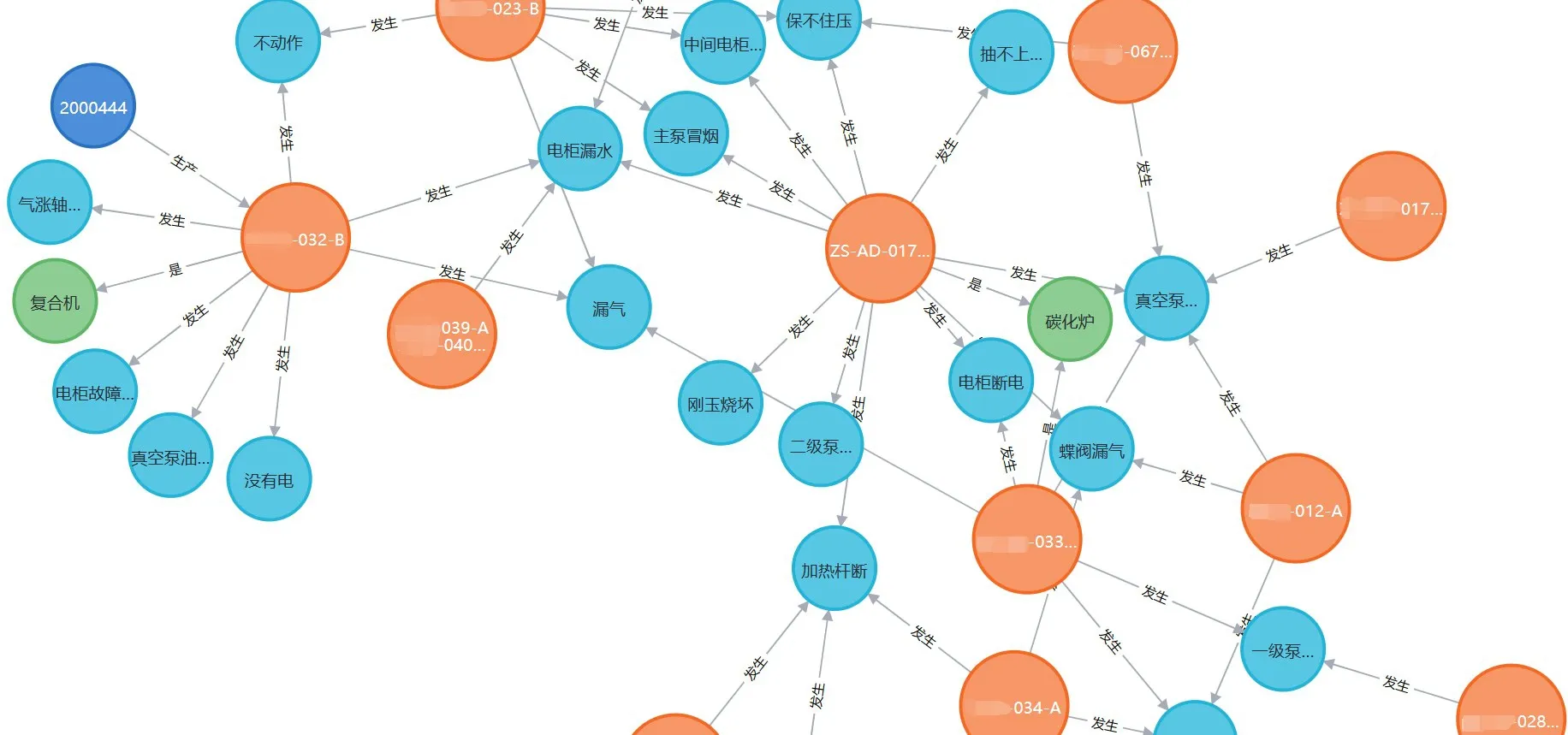
图10 知识图谱可视化Fig.10 Visualization of knowledge graph
5 知识图谱应用
工业设备故障处置知识图谱中记录了大量的设备故障的状态以及对该故障处置,利用知识图谱可以辅助工作人员快速完成故障的诊断和维修,从而提高设备故障处置效率。
通过对设备故障处置记录的分析,很多故障是可以通过感官和传感器信息等多模态信息获知的,基于深度学习的方法判断设备是否发生可由视觉等感官上可判断的故障已经较为成熟[26-27]。
图11 所示为设备故障处置的智能推荐方法流程,该方法首先通过获取工厂内的图像、声音以及安装在工厂和生产设备的各种传感器信息,当设备发生故障时,通过实时获取的图像和声音信息经过训练好的深度学习网络判断设备是否发生可由视觉等感官上可判断的故障,传感器信息通过判断是否属于预先设定的正常生产的阈值内,得到检测结果并报警到专业人员,同时系统为专业人员推荐最可能的故障部件,经确认是某部件发生故障后,为人员推荐以往处置经验与维修方法,并推荐相应的应维修的设备部件从而实现故障快速响应和故障处置方案自动推荐;如查询无结果,则说明没有以往的相关处置经验和记录。无论知识图谱中是否有相关处置经验和记录,在工作人员完成故障处置后,都将该次处置过程记录下来,经过知识抽取与储存等处理后,更新到知识图谱中,以便后续更好地完成故障处置推荐工作。
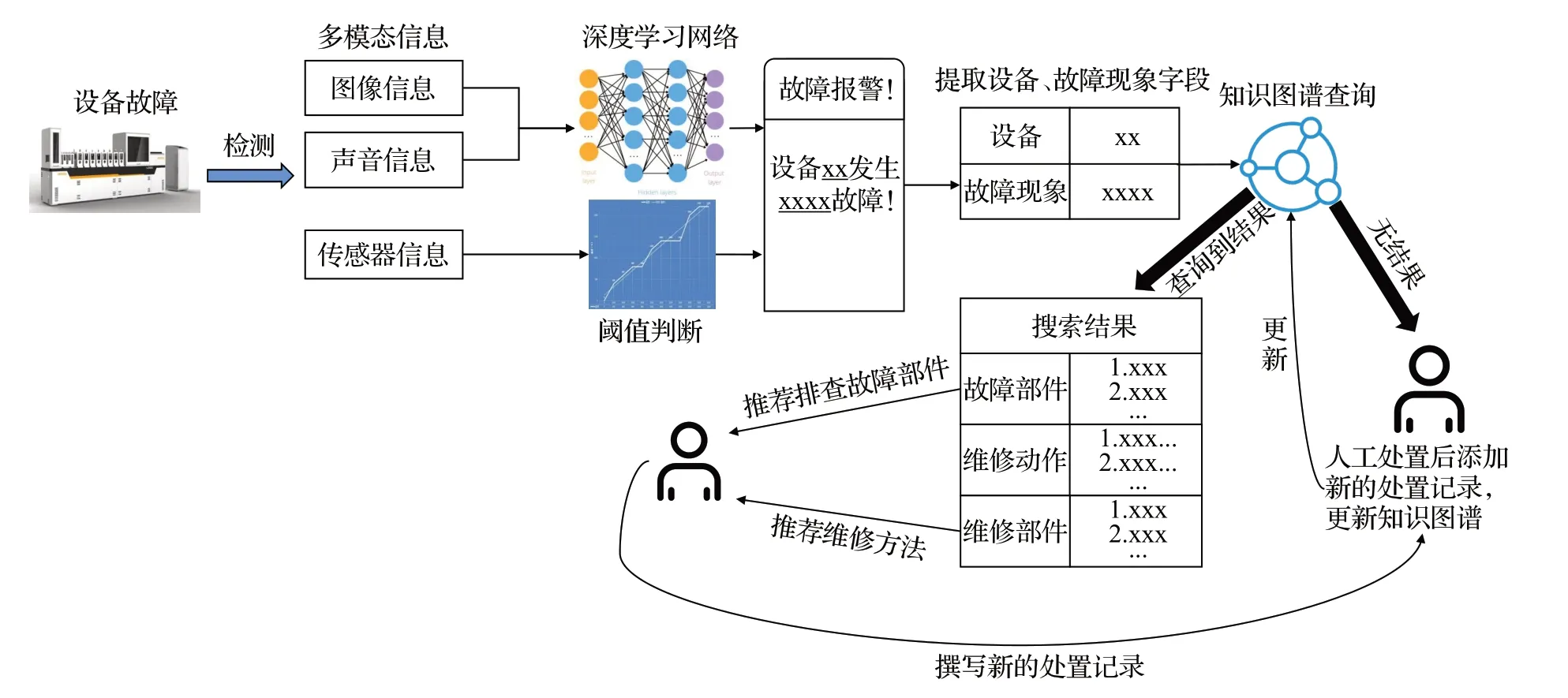
图11 设备故障处置的智能推荐方法流程Fig.11 Flow of intelligent recommendation method for equipment fault disposal
依照此流程,基于构建的工业设备故障处置知识图谱,搭建工业设备故障处置智能推荐系统。例如,如图12所示为识别出发生电柜漏水。

图12 漏水故障Fig.12 Water leakage
系统识别到故障描述为漏水并传入系统,系统搜寻出与漏水相关的故障部件、故障原因及故障发生的次数。按照系统推荐的故障部件,工作人员优先排查相关部件是否发生故障,经人员分析后,最多选择可能的三种故障作为搜索对象,选择后,系统会将相应维修部件和方法推荐给工作人员,同时还显示记录中的维修人员以备工作人员咨询。最后经维修人员进一步判定,并借鉴知识图谱中相应的维修方式完成维修。同时将该次故障处置记录到系统中,经过对新增的故障处置记录中的实体进行抽取,更新到知识图谱中,以备后用。
6 结束语
本文针对工业界利用知识图谱技术辅助设备故障处置现有的解决方案存在的不足,利用多源信息,提出了一种基于外部知识库的设备故障处置领域实体半自动标注方法,在设备部件实体上可以节省近一半人力,在维修动作和故障描述实体上只需要少量人工核对和补充即可完成实体标注;提出一种融入词性和词边界信息的设备故障处置文本实体抽取方法,该方法以BERTBiLSTM-CRF模型为基础,在字嵌入时融入了字所在词的词性信息和词边界信息,相比其他方法,本文方法语义表达更完整,模型识别的准确率、召回率和F1值均有一定提升,且模型利用更少的迭代次数就能获得较高的模型性能;完成相关工作后,将知识图谱储存到Neo4j中可视化;在知识图谱应用上,提出了基于构建的知识图谱的多模态信息融合的设备故障处置的智能推荐方法并构建了工业设备故障处置智能推荐系统。但工业设备故障处置知识图谱的构建和应用是一个需要不断完善的工作,在以下几个方面还需要进一步的研究。
半自动化实体标注方法还需要继续完善以获得更好的准确率和召回率;本文提出的融入词性和词边界信息的实体抽取模型准确率还不够高,需要进一步改进模型以提升性能;知识图谱需要在实践中不断研究挖掘更多的应用场景和实现相关知识系统的落地。
猜你喜欢
少先队活动(2020年12期)2021-01-14
文苑(2019年24期)2020-01-06
制造技术与机床(2018年9期)2018-09-19
疯狂英语(双语世界)(2017年3期)2018-01-19
海外华文教育(2017年6期)2017-08-07
疯狂英语(双语世界)(2017年1期)2017-07-01
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
水电站机电技术(2016年1期)2016-02-28
当代修辞学(2013年4期)2013-01-23
