
分组自注意力机制的多层级三维点云分类方法
2023-12-27 14:53何春秀荆现文何永宁
计算机工程与应用 2023年24期
何春秀,荆现文,何永宁
1.湖北师范大学 城市与环境学院,湖北 黄石 435002
2.广西壮族自治区自然资源信息中心,南宁 530021
大规模城市场景的点云数据通常由街景激光雷达扫描、无人机航测等方式生成,这些数据对于自动驾驶、机器人导航、城市场景3D 建模等都有着重要的作用[1]。点云分类是将具有相同属性或者相同语义信息的点云分配到相同的点云集[2]。由于点云数据具有体量大、分布散乱且无序、旋转不变性等特点,与图像分类相比,点云数据的分类难度要大很多[3]。
传统的点云分类方法大多是根据三维点云的空间形状特征、激光反射强度、点云颜色等特征信息进行特征工程设计和构建相应的分类模型[4],这些方法需要依赖人工设计特征,普适性较差。近年来,点云数据量急剧增长,传统的分类方法已经无法满足大规模数据处理的要求,而深度学习因GPU的强大计算能力,逐渐成为主流的分类方法。目前基于深度学习的点云分类方法主要分为基于规则表示的点云分类方法和基于原始点云的分类方法[5]。基于规则表示的点云分类方法是将点云进行体素化或者进行多视图转换后再利用卷积神经网络进行分类,如Maturana等[6]根据点云体素化规则提出了VoxNet 网络结构;Wu 等[7]提出的3D ShapeNet 神经网络结构;以及Klokov 等[8]利用KD-Tree 对海量的点云数据进行组织管理所提出的KD-Net 神经网络结构,这些方法虽然一定程度上解决了点云数据的无序性、非结构性等问题,但是在将点云转为体素网格的过程中损失了大量的点云信息,并且计算量开销巨大。而基于原始点云的分类方法是直接读取原始的点云数据进行分类,不需要进行多余的转换,从而可以最大程度保留点云的原始特征信息,如Qi 等提出的利用多层感知机(MultiLayer Perceptrons,MLP)结构对点云数据进行特征提取的PointNet[9]和PointNet++[10]神经网络结构,成为了基于该方法的开创性网络结构;Yu 等[11]受到BERT[12]启发,以Transformer 网络模型为核心提出了一种掩码建模的方式对点云数据进行有效的特征提取;王利媛等[13]以Transformer 为核心,并引入了PointConv 点卷积算子提高了点云分类的精度;王江安等[14]利用动态图卷积网络的方式对点云数据进行分类。
虽然这些方法在特定的点云数据集上都能够取得不错的结果,但在面对大规模体量的点云数据分类的时候,同样会遇到运算效率低、运算开销大等问题,这使得目前点云分类网络结构大多应用于较小区域范围内,仅适用于元素单一、点云数量较少的数据集,无法满足场景元素更为复杂、点云数量更多的大规模城市场景数据集的分类需求。
为了解决以上提出的大规模点云数据的采样效率和分类精度等问题,本文从采样算法和神经网络模型的构建两方面设计点云分类方法。首先,本文在点云输入采样阶段采用了一种基于KD-Tree 结构的局部自适应随机采样算法。该算法采样效率高,运行时间短,不仅可以对不同密度的点云数据进行局部自适应采样,采样后还能够保证点云数据的实际特征,除此之外,还可以加快模型的收敛,并提高模型的鲁棒性。然后,本文在分类特征提取上,引入自注意力机制模块,以该模块为核心,设计了一种多层级分组自注意力机制的神经网络模型。该模型首先将点云数据进行多层级划分,随后针对每个层级的点云数据再进行分组,最后对每组的点云数据进行特征提取,这样能够减少计算复杂度,且可以增加单次输入的点云数量,将不同层级分组提取到的特征数据进行融合,可以有效提高分类精度。此外,本文还设计了一个跳跃连接模块,将部分丢失的点云特征信息重新利用。最后在SensatUrban大规模城市场景的点云数据集上进行实验,结果表明,本文提出的方法不仅可以提高点云的分类精度,还能够减少模型的计算复杂度。
1 方法设计
1.1 模型结构
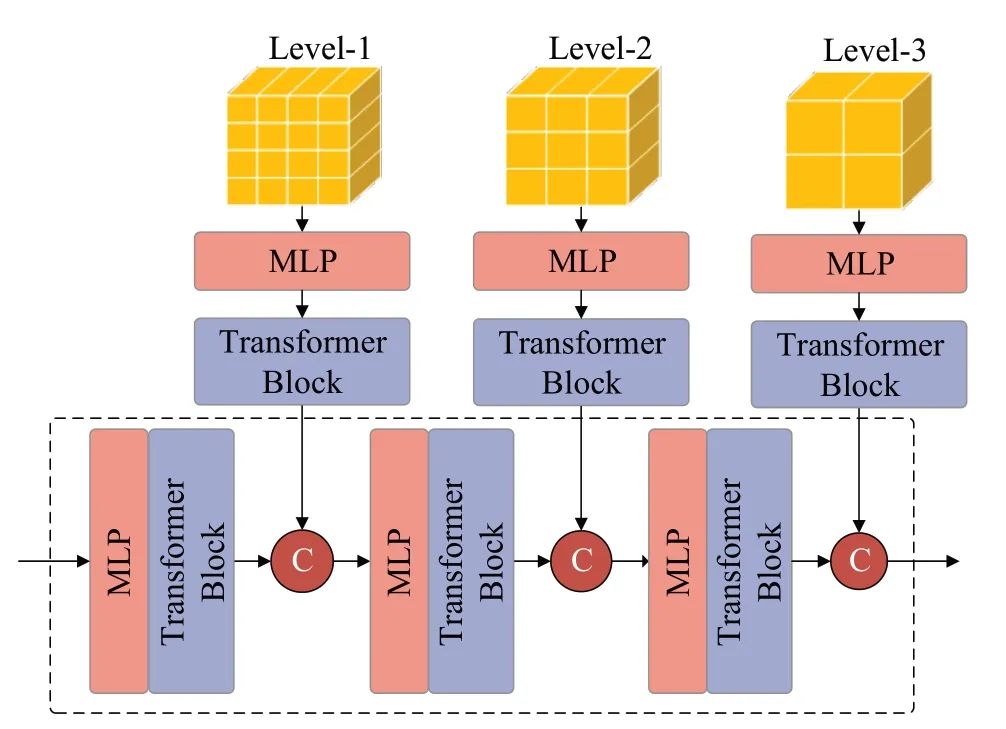
本文基于自注意力机制提出一种多层级分组网络模型MHGA-Net(muilt-hierachical group attention network,MHGA-Net),网络模型结构如图1 所示。该网络模型主要由以下模块构成:自适应随机采样模块(adaptive random sampling module)、多层级分组模块(multi-layer group module)、自注意力机制模块(self-attention module)、跳跃连接模块(jump concat module)。其中,自适应随机采样模块位于模型的最前端,该模块使用了基于KDTree结构的局部自适应随机采样算法,将采样后的点云作为训练数据传入模型中参与训练;多层级分组模块将输入数据划分为3个层级,按照相同数量及最近距离原则进行划分;自注意力机制模块在标准的Transformer[15]上改进而来,该模块从三个层级分别提取特征,再将提取到的多层级特征信息进行融合,经过一个最大池化操作,进入跳跃连接模块;跳跃连接模块是将前面的多层级特征信息分别与上采样过程中提取到的特征信息进行融合,最后将融合结果输入多层感知机(multi-layer perceptron,MLP),最后实现点云数据分类。以下将分别对上述主要模块进行详细介绍。
1.2 自适应随机采样模块
大规模城市场景的点云数据体量十分庞大,单个点云数据文件通常包含上千万个点数据,导致训练无法一次性加载,因此在训练之前通常需要对数据进行预处理操作以减少数据加载时间。为了在训练过程中能够对局部点云数据进行快速检索读取,预处理中通常使用以下两种算法对点云数据进行采样:最远点采样算法和随机采样算法。
最远点采样算法(farthest point sampling,FPS)[16]是一种较为常用的点云采样算法,在各类点云分类任务及点云数据处理中都用所应用,如:PointNet[9]和PointNet++[10]网络。该算法通过迭代采样与已采样点集合的最远点,直至达到需要采样的点数为止,采样的点云数据分布均匀、能够很好地表达全局的每一个点云数据。但是,由于采用了反复迭代并计算最远点的距离,因此最远点采样算法存在计算效率较低、耗时严重的问题。
随机采样算法则是从点云数据中随机选取一点作为中心点,向外进行随机采样,与最远点采样算法相比,随机采样算法执行效率大大提高。但是,传统的随机采样算法获取到的点云数据缺乏规律性,并且有采样密度分布不均匀的问题,限制了采样点云对总体特征的代表性。为了利用随机采样算法的高效性,同时克服上述问题,本文在传统随机采样算法基础上设计了自适应随机采样算法(adaptive random sampling,ARS)。
本文设计的自适应随机采样算法,是在KD-Tree结构的基础上进行自适应的采样。其中,KD-Tree(Kdimensional tree)是一种用于高效地组织多维数据的数据结构,通常用于范围查询和最近邻搜索等应用中[17]。其主要特性包括数据点在树中的递归分割,每个节点代表一个数据点或数据点集合,以及在每个层级交替使用不同维度进行分割。这种结构使得KD-Tree 能够快速地定位、检索和过滤多维数据,尤其在高维数据集上表现出色。
本文设计的自适应随机采样算法的优势在于能够充分发挥KD-Tree 算法快速搜索的效率。通过设计KD-Tree的构建和搜索过程,采样算法可以以较低的时间复杂度实现高效的采样操作,这种设计不仅提供了高效的采样性能,还能够在处理多维数据时保持良好的数据分布。因此,对于有着实时快速采样需求的点云分类任务来说,基于KD-Tree的采样算法设计非常适用且优势显著。
算法的具体方法流程如下:
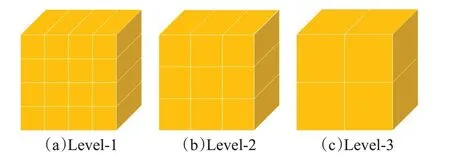
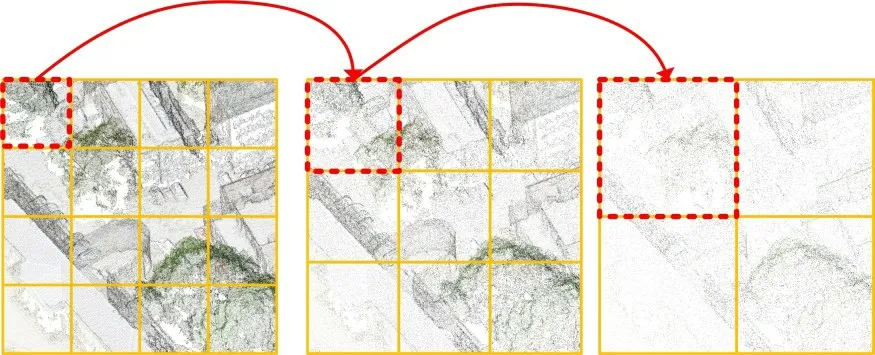
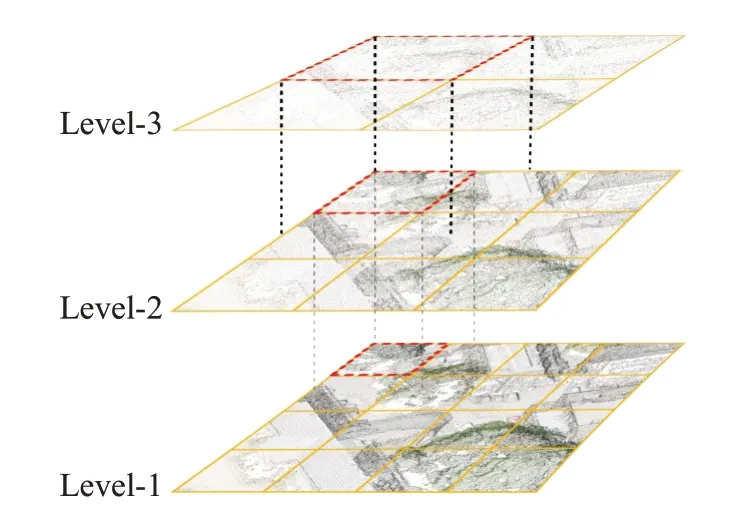
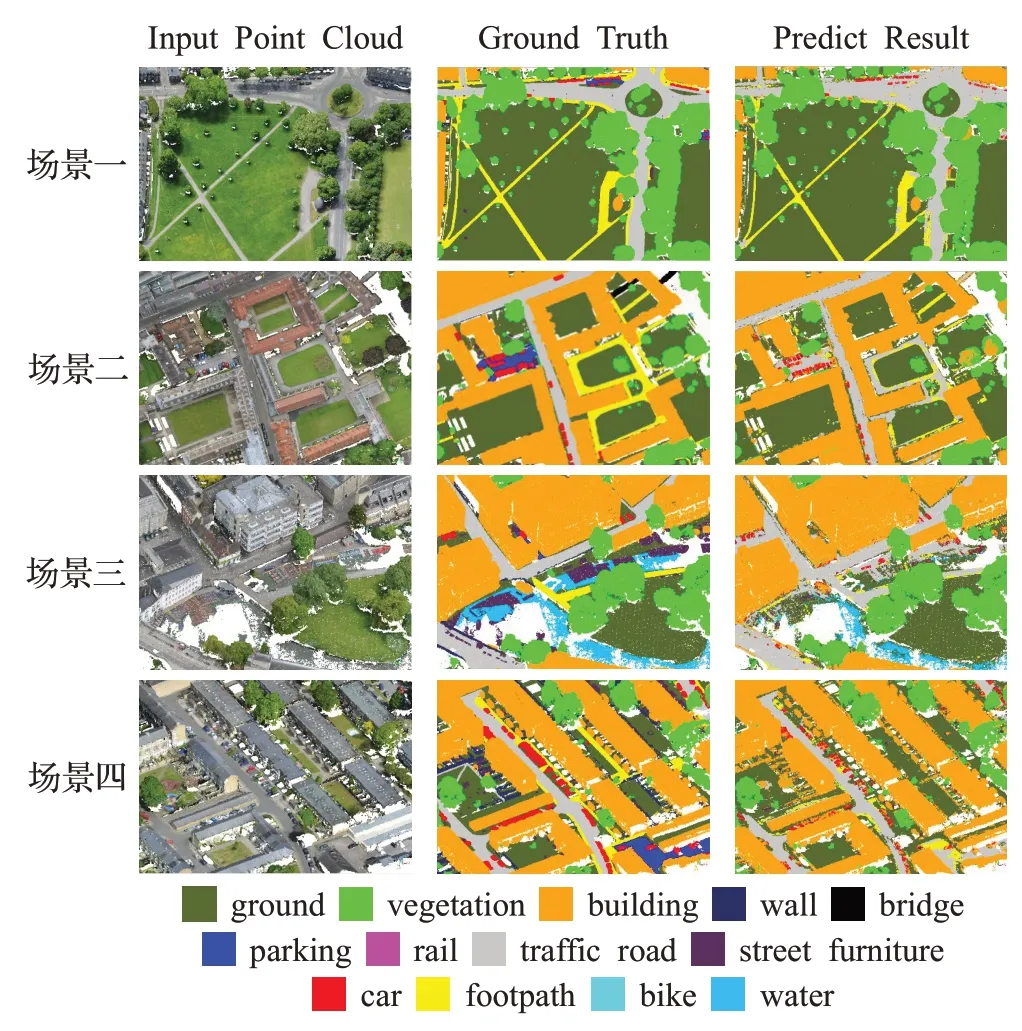
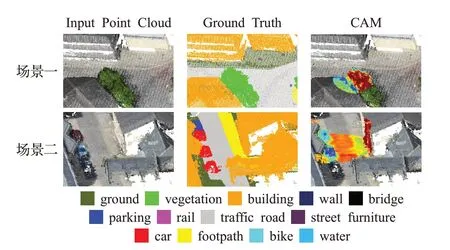
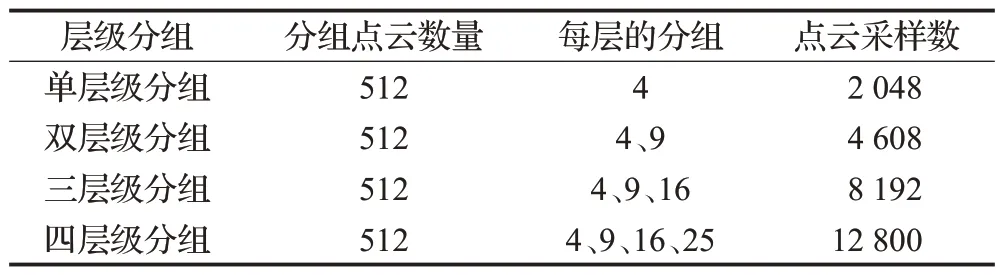
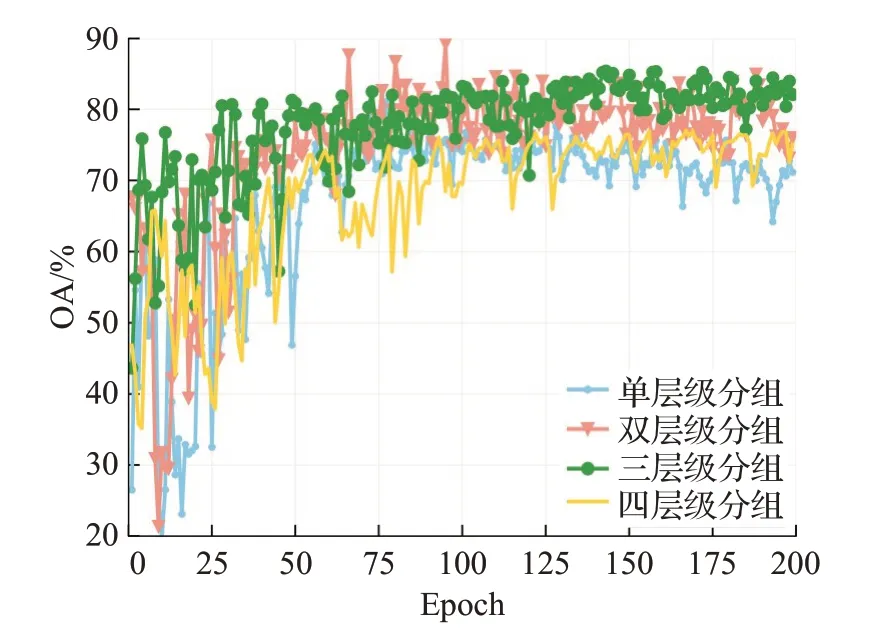
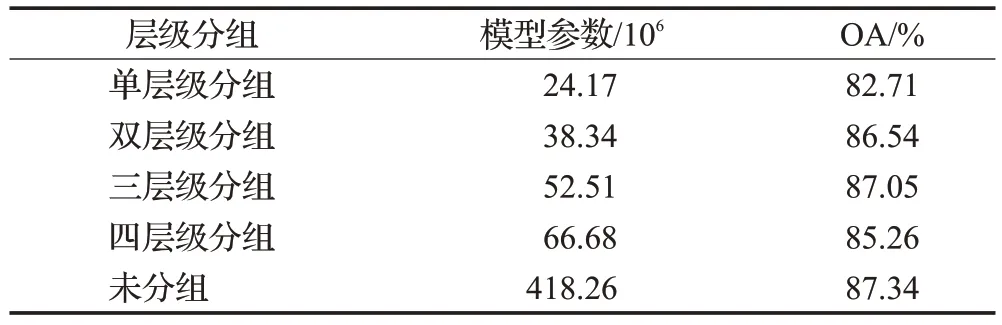
(1)首先,设置KD-Tree的搜索半径为R,采样的点云总数为N。通过对半径R内的点云进行搜索,将搜索得到的点云个数M和N进行对比,如果M (2)然后,使用迭代的方式进行重复上述步骤,直到采样后的点云数量总数M′小于N为止。 (3)最后,将当前抽稀后的点云数量M′和N进行差值计算,得到ΔN,然后M′中距离中心点最远的点为中心点,以ΔN为检索总数进行二次检索,当两次检索后的点云相加总量为N,则完成自适应随机采样算法。 自适应随机采样算法过程示意如图2 所示,从图2(a)和图2(b)可以看出,自适应随机采样算法在采样过程中根据实际的点云数量情况进行抽稀,这是为了保证最终的点云数量与设定的保持一致;从图2(b)和图2(c)可以看出,本文的采样算法在不增加抽稀后点云数量的情况下,扩大了采样的范围,这可以提高采样对整体特征的代表性。 图2 自适应随机采样算法过程Fig.2 Adaptive random sampling algorithm process 受Vision Transformer[18]启发,在计算机视觉中使用Transformer模块进行特征提取,可以将图像划分成16×16的模块,每个模块类似自然语言处理(natural language processing,NLP)中的一个个单词。本文借鉴了这种设计思路,并结合PointNet++[10]中的点云分组概念以及Swin-Transformer[19]模型的层级设计思路,在本文的研究中,将点云数据划分为多个分组,并且在分组的基础之上引入了层级的概念,保留不同层级的点云信息。对于分组数量的选择,涉及到平衡计算复杂度和特征提取能力的问题。本文多层级分组的组数设计见2.4节不同层级分组对比消融实验。 多层级分组模块按照每组相同点云量为原则对输入的点云数据进行分组。本文分三个层级,如图3 所示。分别为第一层级(Level-1)16 组点云、第二层级(Level-2)9 组点云、第三层级(Level-3)4 组点云。为了满足本文分组原则,需要对Level-2和Level-3两组点云数据进行抽稀。抽稀后,3个层级的每一组点云数量相等,均为原始点云数量的1/16。 图3 多层级分组点云示意Fig.3 Schematic diagram of multi-level grouping point cloud 多层级分组模块在进行特征提取的过程中,随着层级的变化,在一个分组内的点云覆盖范围也跟着扩大,覆盖比例从开始输入数据的1/16范围扩大到了1/4的覆盖范围,特征提取的感受范围也跟着扩大,如图4 所示。可见,多层级的策略能够融合不同层级的点云特征信息,从而增强了点云特征的相关性。 图4 多层级分组的点云感受范围示意Fig.4 Schematic diagram of perception range of multi-level grouping point cloud 根据自注意力机制的复杂度计算公式[19],原始未分组的Transformer计算复杂度为: 其中,公式(1)的h、w和C分别为输入Transformer 模块的数据高度、数据宽度和数据通道数。 经过三个层级的分组后,整体的复杂度计算公式为: 对比公式(1)和(2)可知,Ω′≪Ω,即:多层级分组点云算法能够显著减轻Transformer 模块的计算复杂度,从而大幅提高计算效率。 图5是本文设计的多层级机制特性分析示意图,图中可以看出不同层级之间的分组数量不同,并且每个层级的分组点云数据覆盖的范围也不同。通过这种设计,能够使得自注意力机制模块在计算注意力的时候让更远距离的点云参与进来,进而更好地获取不同点云之间的关联性,最终提高模型的泛化能力。 图5 多层级分组机制特性分析示意Fig.5 Schematic analysis of characteristics of multi-level grouping mechanism 本文的自注意力机制模块是以标准的Transformer[15]为核心,对其进行改进调整以适应本文的设定。该模块的处理流程如图6所示,该模块首先利用MLP进行处理,这里的MLP 使用的是1D 卷积,然后使用Leaky ReLu激活函数[20]进行特征激活,最后进入核心的自注意力机制模块。该部分为了兼顾计算效率和精度要求,使用4头自注意力,整个自注意力模块一共重复6 次(N=6)。图中红色圆形“C”作用与图1 一致,将前后特征进行融合连接,再输入到下一步进行标准化处理(图6的Norm层),Norm层使用的是Layer Normal[21]方法。随后以同样的方式进行MLP 模块处理并做连接,最后再做一次标准化操作即可完成一次自注意力机制模块的特征提取。 图6 点云数据应用于自注意力机制模块示意Fig.6 Schematic diagram of applying point cloud data to self-attention mechanism module 特别注意的是图6中的位置编码(positional encoding)部分使用的是相对于采样中心点的相对位置信息,是一个三维的坐标信息,用向量表示。在Transformer中,位置编码是一种向量表示,用于将序列中每个元素的位置信息编码为一个固定长度的向量,这些向量随后与输入序列的元素向量相加,使得Transformer 能够区分不同位置的元素。 由于网络在进行特征提取的过程中会不断地减小空间大小,同时增加特征维度的深度,所以会丢失部分低维度的特征信息,在丢失的低维度信息中,无法避免会将一些有明显表现的特征信息丢失,如:上下文的相关性、点云的颜色信息等。受U-Net[22]网络模型的启发,同时也为了能够将这些在采样过程中丢失的低维度特征信息重新利用,以便辅助网络达到更好的分类效果,设计了跳跃连接模块,该模块具体流程设计如图7所示。 图7 跳跃连接模块Fig.7 Jump connection module 如图7 所示,该模块的上半部分其实是将图1 的多层级分组模块进行了一个翻转,放到了上半部分。跳跃连接模块将Level-1 和Level-2 以及Level-3 提取的特征信息分别在跳跃连接模块中的不同部分进行连接融合操作,目的是将网络模型在前期提取的特征信息重新还原回来,以防止有用信息丢失。 为了说明不同层级提取的特征信息对模型分类的结果起到了正向的积极作用,将不同层级的特征结果进行可视化分析,如图8所示。选取了三个层级(Level-1、Level-2、Level-3),每个层级又选取了三个不同区域(区域a、区域b、区域c)的点云数据进行可视化。图中不同层级对比发现,Level-1的特征信息更加明显,更好地保留了物体形状特征;随着层级的增加,到Level-3,可以发现基本分不清楚特征信息,说明这些特征信息表现就越抽象。由此,设计了跳跃连接模块,将低层级的点云特征信息重新利用,有助于点云的分类精度的提高。 图8 不同层级的特征信息可视化Fig.8 Visualization of feature information at different levels 为了验证以上构建的网络模型的有效性,本文采用大规模城市场景的点云数据集SenSatUrban[1]进行实验,对地物分类识别效果采用准确率(accuracy)指标衡量,对整体分类效果采用总体准确率(overall accuracy,OA)和平均交并比(mean intersection over union,mIoU)作为评价指标,其中mIoU 通过计算语义类别交并比的平均值获得[23],网络最优结果采用加粗字体。 SenSatUrban数据集由牛津大学团队通过无人机航拍后进行重建密集匹配生成,数据包含了6个维度的信息(XYZ三维坐标和RGB颜色信息),点云总数约30亿个,共分为13个类别:地面(ground)、植被(vegetation)、建筑物(building)、墙(wall)、桥梁(bridge)、停车场(parking)、铁轨(rail)、交通道路(traffic road)、街道设施(street furniture)、汽车(car)、人行道(footpath)、自行车(bike)、水(water)[1]。采集的场景是来自于英国的伯明翰、剑桥、约克,覆盖面积达7.6 km2。SensatUrban 数据集的类别分布并不均匀,其中地面、植被、建筑三种主要类型占总数据量的80%以上,而桥梁、铁轨、自行车、水系存量极少。这种不均匀性也是大型城市场景点云的一个主要特点,这给训练带来了极大的难度。为了更好地进行训练,本实验对数据集进行了重新调整和划分,并将样本较少的分类数据进行了数据增强。 在本文的实验中,使用的计算环境为Centos7+CUDA11.0+Python3.7+Pytorch1.11.0,硬件设备为Intel Core i9-9920X+NVIDIA 2080TI×4+128 GB 内存。模型中使用的超参数设置:批次大小为8,网络模型的初始学习率设置为0.001,学习率衰减率设置为0.9,使用了Adam优化器,迭代次数为200次。 为了验证自适应随机采样算法(adaptive random sampling,ARS)的执行效率,本文设计了三组不同点云数量情况下的实验,将本文算法与最常用的最远点采样算法(farthest point sampling,FPS)进行比较。实验结果如表1 所示,从表中可以得知,自适应随机采样算法的执行效率要远远优于最远点采样算法,总耗时仅为后者的3%~5%。 表1 算法执行效率对比Table 1 Comparison of algorithm execution efficiency 单位:s 为了验证自适应随机采样算法在MHGA-Net 中的有效性,本文设计了一组对照实验:MHGA-Net+最远点采样算法和MHGA-Net+自适应随机采样算法,对比自适应随机采样算法和最远点采样算法有多少优势的提升。实验结果如表2,表中列出对照实验的13个分类的准确率以及OA和mIoU。在表2中Ours(FPS)表示MHGANet+最远点采样算法;Ours(ARS)表示MHGA-Net+自适应随机采样算法。从表2 可以看出,Ours(ARS)的mIoU 和OA 均高于Ours(FPS),在植被、建筑物、墙、停车场、汽车等分类的准确率上也高于Ours(FPS),即使在部分类别上没有高于最远点采样算法,但相差很近,这说明了所设计的MHGA-Net+自适应随机采样算法是有效的,对比最常用的最远点采样算法有一定优势。 表2 与不同方法实验对比Table 2 Comparison with experiments using different methods 单位:% 为了进一步说明Ours(ARS)相对Ours(FPS)有其优势性,给出了两个模型训练过程曲线图,如图9所示,图9(a)是模型训练过程的精度曲线走势图,图9(b)是模型训练过程的损失结果曲线走势图,通过这两幅图可以看出,Ours(ARS)在训练过程中更容易达到拟合状态,最终得到的训练精度也比Ours(FPS)更高;在训练过程中,Ours(ARS)损失的结果也会下降更快,损失结果也更低。 图9 模型训练过程Fig.9 Model training process 为了验证本文构建的多层级分组网络MHGA-Net的有效性,本文设计了4 组与主流网络模型的对比实验。选取的网络模型有:Qi等[10]提出的PointNet++经典网络模型,其模型算法简单高效,并且能够无需投影转换直接对原始点云进行分类;Guo等[24]提出的PCT点云分类模型,该模型是以Transformer 为核心骨干的网络模型,模型特征提取能力强;Hu 等[25]提出的RandL-Net网络模型,该模型是一种基于随机采样算法的大型城市场景点云分类算法;Thomas等[26]提出的KPConv网络模型,该模型算法是一种新颖、高效和灵活的点云卷积方式,提高了点云分类的精度。 实验结果如表2所示,表中列出对照实验的13个分类的准确率以及OA和mIoU。从表中可以看出,本文提出的方法mIoU最高,达到了46.51%,比PointNet++经典网络模型提高了8.17个百分点。对地面(ground)、植被(vegetation)、建筑(building)三类主要地物类型的预测结果较优,分类准确率均达到84%以上,除植被分类准确率略低于RandL-Net模型外,本文方法对三类主要地物的准确率均高于其他几种方法。但在样本较少的类型中分类效果较差,如:停车场(parking)、人行道(footpath)、交通道路(traffic road),这也是所有参加对照的网络模型共同存在的问题。 为了更直观地展示本文Ours(ARS)方法的效果,选取了四个不同场景的预测结果将其可视化,可视化结果如图10 所示。图10 第一列为输入的点云数据,第二列为标记真值,第三列为预测结果。从图中可以看出,本文提出的方法能够准确预测大部分的地面、植被、建筑类型,这与表2准确率结果是一致的。但是对场景中占较少数量的类别的识别存在一定偏差,如场景二中,停车场的区域(蓝色区域)未能准确分类。本文分析是因为停车场的区域和地面以及交通道路分类上存在一定重合,所以会对模型分类造成一定困难。此外,从图中还发现,大型城市场景点云数据中还存在着不少的空洞区域(图中白色区域),如场景三结果中左下角的大块白色区域,该区域为河流,但是原始场景数据里面没有这部分点云数据,原因是无人机在航空拍摄后的内业工作中未能生成这部分点云数据,因此导致这里点云数据的丢失,对模型预测结果也有一定影响。 图10 分类结果可视化Fig.10 Visualization of classification results 为了直观展示本文方法在特征提取上的有效性,帮助理解和解释本文网络模型的效果,使用类激活图(class activation map,CAM)[27]可视化方法对主干网络结构提取后的特征进行可视化分析。CAM是可解释性深度学习的一种方法,用于判断训练过程中不同分类的特征权重是否正确归类。本文采用梯度加权的类别激活图(gradient-weight class activation mapping,Grad-CAM)[28]方法,对随机采样的部分点云进行特征图可视化效果展示,如图11所示,分为两个场景。图中第一列为输入的原始点云数据,第二列为真实的标记图,第三列为对输入数据进行随机采样后的类激活图。本文使用了热力图的可视化方法,图中颜色越红表明梯度值越大,而颜色越接近蓝色表明梯度值越小,所以从颜色上可判断不同分类的特征权重是否正确归类。 图11 类激活图可视化分析Fig.11 Visualization analysis of class activation map 图11 的场景一中当前提取类别为植被,类激活图中深红色表明网络在该区域的特征梯度较大,因此侧重将该区域的点云数据归类为植被,这与真实标记数据和输入的点云数据是一致的。图11的场景二中当前提取类别为建筑物,类激活图中深红色区域是网络模型中梯度值最大、最有可能被判断为建筑物的区域,其与真实标记数据、输入的点云数据在这一区域的类别也相一致。从这两组不同分类的类激活图可以看出,本文Ours(ARS)方法在点云的分类上表现出了较好的分类可靠性,能够将点云数据进行正确有效的分类。 由公式(1)和(2)可知,自注意力模块的计算复杂度和传入的向量宽度、高度以及通道数有关。本文设计的多层级分组从公式计算结果上看,的确能够有效地降低模块的计算复杂度,但是分组数量的选择需要在计算复杂度和特征提取能力两个方面取得平衡。为了说明本文为何选择分为三个层级分组,即Level-1、Level-2、Level-3,本文设计了不同层级分组对比的消融实验。 实验分类设计参数如表3所示。表3中一共有4组实验,分别是:单层级分组、双层级分组、三层级分组、四层级分组,划分层级后的单组点云数量都是512,并根据不同层级划分每个层级中的分组数量,单层级可以划分为4组点云,最高的四层级可以划分成25组点云。点云采样数应根据层级设计中的最高层分组数量与每组点云数量相乘得到,如:单层级只有一层所以最高层就是第一层,因此单层级的点云采样数就等于4乘以512,最终就需要采样2 048个点云数据;四层级设计最高层级是第四层,第四层的分组数是25,因此四层级的点云采样数就等于25乘以512,最终就需要采样12 800个点云数据。 表3 多层级分组实验对比参数设计Table 3 Design of comparative parameters for multi-level experiments 实验结果曲线图如图12所示,图中展示了4种不同层级的点云训练结果曲线。从图中可以看出绿色的三层级和粉色的双层级取得的结果最好,这是因为双层级和三层级的划分较为合理,能够更好地平衡计算量和模型性能。而四层级的划分层级过多,单层级的划分层级过少,所以两种层级的取得结果都不如双层级和三层级。通过对比双层级和三层级可以看出,双层级在末尾端抖动较为厉害,并且整体的验证精度曲线结果要比三层级的略低一些。通过此实验可以看出,合理的层级划分应该取三组层级,所以本文选择了三层级分组,三组层级能够对计算复杂度以及模型精度有一个更好的平衡。 图12 不同层级训练曲线Fig.12 Training curves at different levels 为了探究不同层级分组对网络模型性能的影响,进行了对比分析如表4所示。随着层级分组的增加,模型参数也会随之增加,模型的精度也得到了提高,但当层级分组来到四层级分组时,模型的精度结果则出现了下降。经分析,出现下降的原因可能是四个层级分组的时候,4个层级分组最大的分组数达到了25组,分组过多,从而导致采样的点云数量较为分散,影响了每个分组之间的相互特征关联,无法考虑到全局的特征信息,出现了精度不增反降的结果。综上,本文的层级分组决定采用3个层级分组,可以达到最优平衡。 表4 不同层级分组的网络模型性能对比Table 4 Performance comparison of network models with different levels of grouping 特别说明的是,表4 中,也将分组结果和未分组的实验结果进行对比,实验结果证明分组的方法在提升运行效率的同时,也降低了分类精度,分类精度与三层级分组的相比降低了0.29 个百分点。但是不得不提的是精度虽然有所降低,但是模型参数却是大大减少。模型参数的大小对模型训练有很大的影响,因此,本文在牺牲少量精度(下降0.29个百分点)的情况下,选择提高模型的运行效率。 为了说明本文为什么在Transformer 模块中设计了6 个Block,而不是其他数量,本文设计了以下4 组实验来论证,4 组实验的Block 数量分别设置为2、4、6、8,取得的实验结果如表5所示。表中GFLOPs指Giga Floating Point Operations Per Second,每秒千兆次浮点运算数,GFLOPs意为计算量,是用来衡量算法或模型复杂度的常用指标之一,数值越大表示计算复杂度越高。特别需要说明的是,为了更加准确地反映自注意力机制的消融实验对比,表中的GFLOPs仅仅是不同Block数量的自注意力机制模块计算复杂度,并不是整个网络的计算复杂度。 表5 不同Block取值的实验结果Table 5 Experimental results of different block values 通过对表5进行分析可知,虽然Block数量取8个的时候,在OA能够达到最高的87.52%,但mIoU并不是最高的,相反当Block 取值为6 的时候,mIoU 最高,虽然OA 指标并不是最高的,但计算复杂度是可以接受的。而从OA和mIoU的指标增长趋势可以看出,当Block取值为6 的时候,计算复杂度和各种模型指标最为平衡。实验证明,Block的数量并不是越多越好,而是需要综合考虑计算性能和分类精度,越多的Block能够带来更好的分类精度,但是也会随着带来巨大的计算消耗。因此,本文在考虑Block数量设计的时候,也需要将计算性能和分类精度同时兼顾,做到精度和性能平衡,所以本文选择了6个Block。 针对大规模城市场景点云分类任务存在的模型训练困难、分类准确率低等问题,本文设计了一种基于多层级分组注意力的网络模型(MHGA-Net),该网络模型利用多层级分组的方式对输入的点云数据进行多层级分组和特征信息提取,显著减少了特征提取的计算复杂度;同时在处理大场景的城市点云数据过程中,设计了一种自适应随机采样算法,确保了采样效率的同时能够采样更多的点云数据。利用SensatUrban数据集进行实验,结果表明:本文提出的MHGA-Net+自适应随机采样算法与其他方法相比有着较优的分类准确率结果,但在样本数量不均匀的情况下,也存在和其他方法共同的问题,即对点云样本较少的类型分类准确度仍然不高。总体而言,本文提出的MHGA-Net+自适应随机采样算法网络模型能够高效地处理大型城市场景的点云分类任务,取得了较好的分类效果,对实际的点云分类工作有着一定的研究意义和应用价值。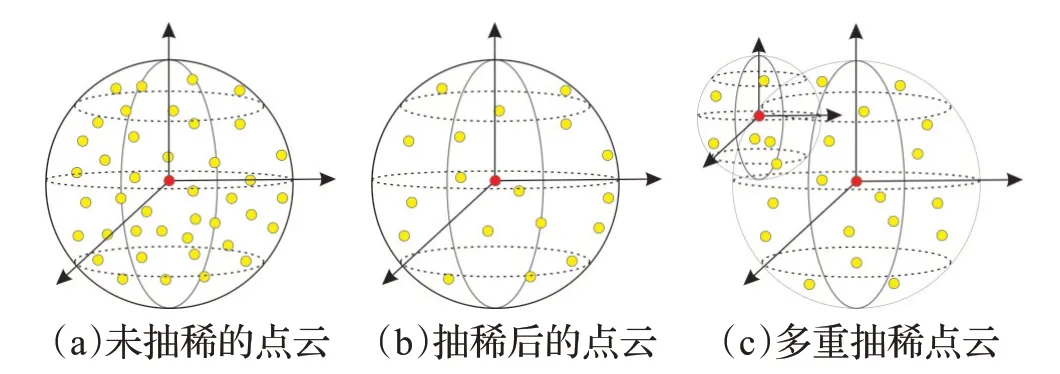
1.3 多层级分组模块
1.4 自注意力机制模块

1.5 跳跃连接模块

2 实验分析
2.1 数据与环境
2.2 数据采样算法分析



2.3 本文方法与其他方法对比分析
2.4 不同层级分组对比消融实验
2.5 注意力机制消融实验

3 结论
猜你喜欢
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
廉政瞭望(2019年5期)2019-06-10
小学生学习指导(低年级)(2019年3期)2019-04-22
中国惯性技术学报(2019年6期)2019-03-04
小学生学习指导(低年级)(2018年9期)2018-09-26
小学生导刊(低年级)(2017年1期)2017-06-12
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
系统工程与电子技术(2016年2期)2016-04-16
火控雷达技术(2016年3期)2016-02-06
