
融合剪枝和多语微调的黏着语命名实体识别
2023-12-27 14:53罗凯昂哈里旦木阿布都克里木阿布都克力木阿布力孜郭文强
计算机工程与应用 2023年24期
罗凯昂,哈里旦木·阿布都克里木,刘 畅,阿布都克力木·阿布力孜,郭文强
新疆财经大学 信息管理学院,乌鲁木齐 830012
随着“一带一路”的发展,多语言信息处理已经成为了推进新疆与丝绸之路经济带沿线国家区域合作的重要技术支持。命名实体识别(named entity recognition,NER)是自然语言处理任务中的一项重要且基础的任务,其目的是从结构化文本数据中提取出特定类型的命名实体,在自然语言处理下游任务中起着关键作用,如信息检索、问答系统、文本摘要等。在我国新疆地区,低资源黏着语NER 面临着3 个挑战:(1)维吾尔语和哈萨克语等黏着语存在形态丰富的特点,导致严重的数据稀疏问题;(2)缺少标注数据;(3)现有研究主要集中在维吾尔语和哈萨克语,很少考虑到柯尔克孜语等其他低资源黏着语。因此,区别于英汉等大规模主流语言,低资源黏着语NER 更多地考虑迁移学习方法,通过语言间的相似性学习有效的特征,提高模型的实体边界识别及类别识别性能[1-2]。
多语言预训练模型共享多语言参数,包含多语言特征,是处理多语言NER 任务的有效方法。大量研究通过将数据增强、对抗学习、迁移学习、动态微调策略等方法与多语言预训练模型相结合,在英汉等主流语言中取得了良好的效果[3-5]。然而,以往的研究存在一定的局限性:(1)主要集中在高资源语言领域或印欧语系,并没有充分考虑多语言预训练模型在低资源黏着语NER的性能;(2)低资源语言迁移实验没有考虑迁移语料规模大小的影响,未能有效缓解标记数据匮乏问题;(3)主流的多语言预训练模型存在参数规模和词表大等特点,导致推理速度慢、对算力要求较高等问题。
针对以上问题,本文提出低资源黏着语NER的CINO新版本:CINO-Agglu。该模型通过对多语言预训练模型CINO-large进行词表剪枝得到,其中剪枝所需的语料库由2 部分构成:(1)NER 语料;(2)自主构建的维吾尔语和哈萨克语语料(维哈语料)。通过将CINO-Agglu与多语言微调策略相结合,对五种低资源黏着语(维吾尔语、哈萨克语、柯尔克孜语、乌兹别克语、塔塔尔语)进行实验。
本文的主要贡献如下:(1)提出了低资源黏着语NER轻量化模型CINO-Agglu;(2)对五种低资源黏着语进行了充分的实验,并且得到了与前人不同的结论:多语微调显著优于单语微调,但过大规模的迁移语料会降低模型性能;(3)通过对比CINO-Agglu和其他多语言预训练模型的性能,分析了模型之间的优劣。
1 相关工作
1.1 低资源黏着语NER
相较于英汉等高资源语言,低资源黏着语NER 研究起步较晚[6],主要以维吾尔语和哈萨克语为研究对象。最早是基于规则和统计的方法,艾斯卡尔·肉孜等[7]提出基于条件随机场(conditional random field,CRF)的维吾尔语人名识别模型;麦合甫热提[8]利用句子中语法语义知识,解决了维吾尔语机构识别中结构复杂、长度极其不固定、实体机构嵌套等问题;买合木提·买买提等[9]通过CRF 与规则相结合,引入常用地名词典、地名特征词、地名词缀等特征,在维吾尔语地名识别任务上取得良好效果。在深度学习领域,Bharadwaj 等[10]在维吾尔语和乌兹别克语NER 任务中加入语音特征,提高了LSTM-CRF的统计效率;Feng等[11]将多层次跨语言知识作为注意力机制加入Bi-LSTM-CRF中,通过双语词典同时捕获乌兹别克语和汉语等语言的词汇语义;Xie等[12]提出了一种基于双语单词嵌入的翻译方法,提高了维吾尔语NER的性能;王路路等[13]提出基于半监督Bi-LSTMCRF的维吾尔语NER方法;Haisa等[14]提出WSGGA,融合Word2vec、门控图神经网络(graph-gated neural network,GGNN)、注意力机制、CRF,深入提取哈萨克语形态和语义特征。Ayifu 等[15]提出基于BiGRU-CNN-CRF的混合神经网络模型,在维吾尔语、哈萨克语、柯尔克孜语NER 取得良好的鲁棒性。随着预训练模型的出现,Akhmed-Zaki 等[16]首次将BERT 应用于哈萨克语NER;孔祥鹏等[17]提出TBIBC 维吾尔语NER 模型,由中文BERT、IDCNN、CRF、BiGRU 四个模块组成,将中文信息迁移到维吾尔语上,显著提升了维吾尔语NER性能;Muller等[18]提出了语言预训练时的“脚本差异”问题,并通过mBERT 与“音译”相结合的方法解决了这一问题;Lei等[19]提出CLTP,通过减少训练阶段引入的噪声来最大化地利用哈萨克语等语言的未标记数据。
1.2 多语言预训练模型
近几年,多语言预训练模型成为低资源语言主要处理方法。mBERT[20]是最早出现的多语言预训练模型,是BERT的多语言版本,在多语言迁移任务表现良好,应用广泛。Baumann等[21]使用mBERT对英德两种语言进行NER任务,通过与英德单语预训练模型比较,证明了多语言预训练模型具有很强的泛化能力;Wu 等[22]提出跨语言NER新方法:UniTrans。该方法通过对标注数据进行数据增强和知识提取,在西班牙语、荷兰语、英语、德语、挪威语等五种语言中均取得了最优值;Muller 等[18]对mBERT 中“看不见的语言(即没有参与预训练的语言)”进行零样本迁移学习,根据结果将语言划分为“硬语言”“中性语言”“简单语言”,其中使用mBERT直接对“硬语言”进行微调的结果较差,而“中性语言”微调效果能达到一般基线模型水平,“简单语言”则有良好的微调结果;Chen等[4]提出对抗学习框架AdvPicker,通过对抗训练学习源语言数据中的实体邻域知识,在英德等主流语言上表现出良好的迁移性能;Li等[23]提出基于知识蒸馏和多任务学习的MTMT(multiple-task and multipleteacher model),充分考虑不同任务之间的迁移性;Galperin等[24]提出基于UMLS(unified medical language system)词典和文档流水线的跨语言框架,不依赖于实体的任何描述性文本;Stollenwerk[5]引入了自适应微调,提出提前停止、自定义学习率、动态调整训练次数的微调策略,在英语、瑞典语、西班牙语NER 任务中,性能、稳定性、效率都得到了改进;XLM(cross-lingual language model pretraining)[25]在BERT 的基础上加入翻译语言模型(translation language modeling,TLM)预训练任务,弥补了低资源语言数据短缺问题,但对于双语句对要求较高。XLM-R[26]是RoBERTa[27]的多语言版本,相比于mBERT,使用更大的架构和更大规模的语料库,在多数下游任务上显著优于mBERT。Chen 等[28]提出基于XLM-R架构的SixT+,该模型在机器翻译和跨语言文本生成等任务上具有强大的迁移能力;为了最大化多语言多粒度文本之间的相互信息,InFoXLM[29]引入了信息理论;XLM-Align[30]在处理句对时引入了去噪机制,提高了不同数据集的跨语言可移植性;CINO[31]在XLM-R的基础上进行二次预训练,充分学习了中国少数民族语言特征。
1.3 预训练模型剪枝
预训练模型具有强大的性能,然而较高的计算资源需求限制了下游任务等方面的应用。因此,模型压缩是重要的研究方向。模型剪枝为模型压缩常用方法之一,能够有效快速并且充分轻量化模型。Abdaoui等[32]重构15种语言的词表,并重建嵌入层,从而完成了对mBERT的剪枝,剪枝后的模型参数量大幅减少,在大量任务中基本保持原有的性能。Lagunas 等[33]提出块剪枝(block pruning),从块的角度大幅度压缩模型。Yang 等[34]提出预训练模型剪枝工具:TextPruner,并通过对CINO-large进行词表剪枝操作,得到CINO-large-V2。剪枝后的模型规模、词表大小、推理时间分别减少25%、50%、20%。并且,在藏语文本分类(Tibetan news classification corpus,TNCC)任务中,CINO-large-V2的精确度为71.0%,超过了原始模型CINO-large的68.6%。因此,预训练模型剪枝能够兼顾模型轻量化和处理特定任务的性能。
2 CINO-Agglu与微调策略
本文提出一种CINO轻量化黏着语版本CINO-Agglu,如图1 所示,使用CINO-Agglu 处理低资源黏着语NER任务分为剪枝和微调两部分。首先使用爬虫工具构建维哈语料;然后在CINO的基础上,用剪枝工具TextPruner,根据维哈语料和NER语料出现的token进行剪枝,得到CINO-Agglu;最后,采用多种不同语言组合的微调方法,以寻找最佳微调策略。
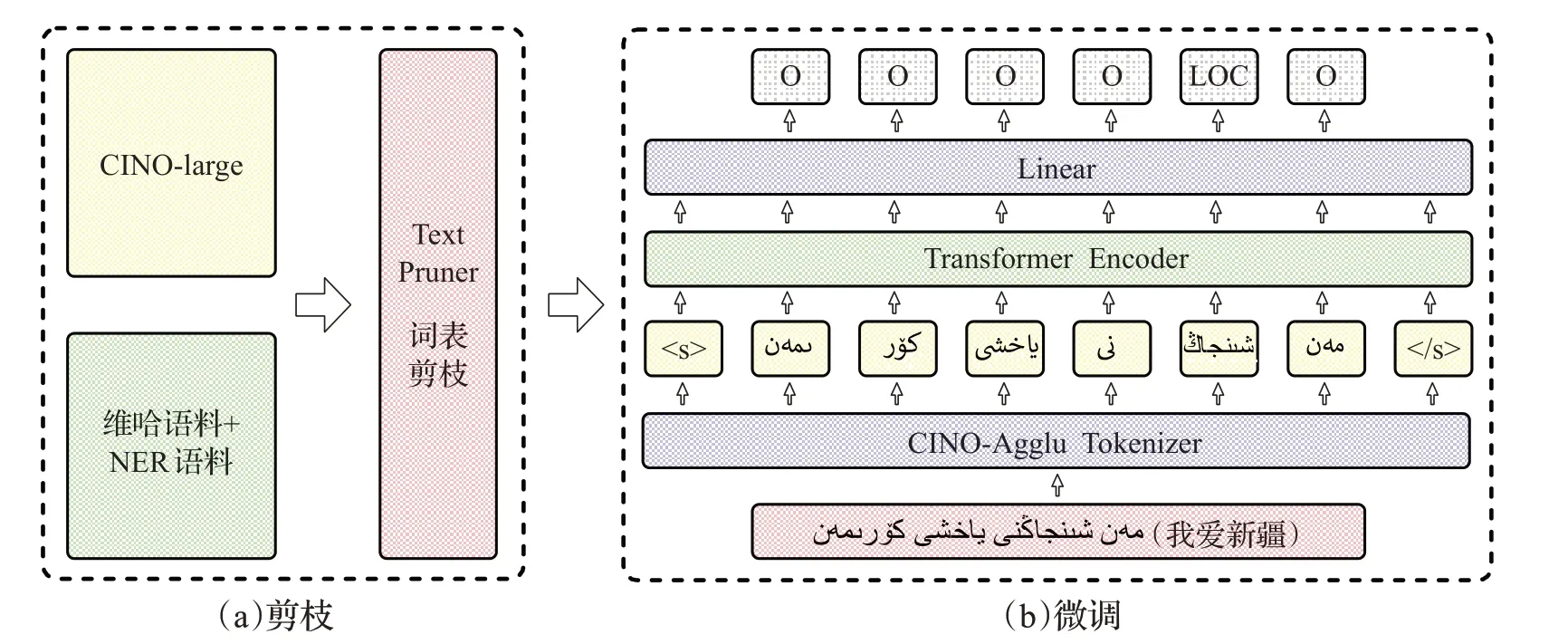
图1 CINO-Agglu模型NER流程图Fig.1 CINO-Agglu NER process
2.1 原模型及剪枝语料
为了有效处理低资源黏着语NER 任务,本文选择中国少数民族语言模型CINO-large 作为剪枝原模型。传统的词表剪枝仅仅使用特定任务语料,但本文为了保留原模型更多的词表数目、提高剪枝后模型的泛化能力、更好处理低资源黏着语NER任务,对词表剪枝语料进行扩充,主要由两部分组成:(1)NER任务中的五种低资源黏着语语料;(2)维哈语料。其中,维哈语料为自主构建,语料来源于中国维吾尔语广播网、中国哈萨克语广播网、天山网等多个网站,并进行了数据清洗工作。两种语言书写形式均为阿拉伯文字,其中维吾尔语语料大小为287 MB,哈萨克语为184 MB,共计471 MB。
2.2 剪枝策略
模型剪枝工具选择TextPruner。该工具具有功能通用、灵活便捷、运行高效的特点,包括Transformer剪枝、词表剪枝、流水线剪枝三种方法。TextPruner 主要根据神经元重要度移除注意力头或前馈神经网络中的神经元,达到轻量化模型的目的。重要度的计算方法为:
S(θ)表示重要度得分。损失函数LKL(x)采用Kullback-Leibler 散度来衡量输出变化。绝对值内的表达式是LKL(x)在θ=0 的一阶泰勒损失。θ是输入的神经元序列,即注意力头的输出。TextPruner 将重要度得分最低的神经元依次剪枝,即不断抛弃敏感度低的神经元。
对于低资源黏着语,预训练模型CINO包含冗余的词表,但仅需要保留与本文NER任务相关的部分,就能够达到减小模型体积和提升训练速度的目的。整个词表剪枝流程分为3 步:(1)读取输入语料并对其进行标记;(2)识别语料中的token是否出现在词表中;(3)未出现的token将从原模型词表中删除,与此同时,对词嵌入层进行剪枝。在词表剪枝过程中,设置token 剪枝阈值为1,以保留所有剪枝语料中出现的token。整个剪枝过程大约耗时20 min,CINO-Agglu保留了原始模型架构,由24个Transformer层组合而成,注意力头数为16,隐藏层向量长度为1 024。
2.3 微调策略
使用CINO-Agglu 进行NER 任务,如图1(b)所示,首先,将句子传入Tokenizer层,得到句子的token表示,句子开头与结尾使用特殊标记;然后,每个token表示会被单独输入到Transformer 层进行特征提取,得到上下文语义表示。最后,经过线性分类层,对每个token进行是否为实体的判断,并输出对应的实体类别。
图2 为CINO-Agglu 的Transformer Encoder 结 构,它由24个叠加的Transformer Encoder层组成。每一个Transformer Encoder 层由多头注意力机制(multi-head attention),归一化(add&normalize),前馈层(feed forward)构成。多头注意力机制能够获得更加全面的语义信息,如公式(3)和(4)所示:
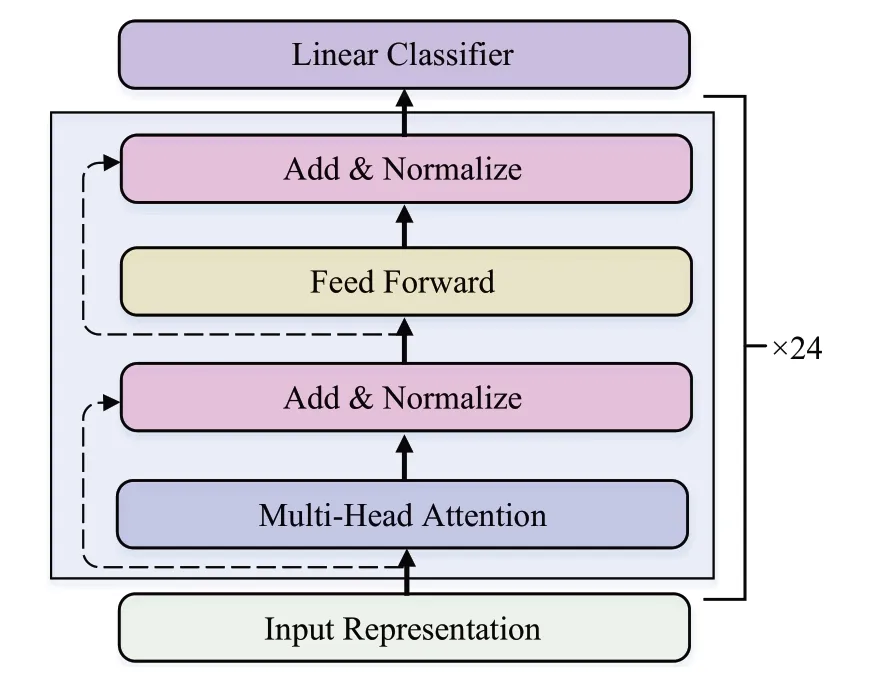
图2 Transformer Encoder的结构Fig.2 Structure of Transformer Encoder
其中,Q、K、V代表输入向量的线性映射矩阵。headi表示第i个注意力头输出的向量,Concat 表示拼接函数,它将16个注意力头输出的向量进行拼接,W为参数矩阵。之后多头注意力机制和归一化层通过残差进行连接,提高计算效率并缓解梯度爆炸或梯度消失问题。前馈层用于综合所有信息,计算方法如公式(5)所示:
该过程经过了两次线性变换,其中W1、W2、b1、b2为权重矩阵和偏置矩阵。与多头注意力层相同,前馈层也会进行残差连接并进行归一化处理。通过多层的Transformer Encoder层传递,最后通过线性分类层输出实体类别。
与Mueller 等[3]方法类似,本文选择单语、多语微调两种策略,测试CINO-Agglu 及其他多语言预训练模型在五种低资源黏着语的NER 性能。其中,单语微调是对单一语言进行模型训练并测试;多语微调则是将五种低资源黏着语合并,进行模型训练,并使用训练完毕的模型,测试每种参与训练语言NER的F1值。
此外,为充分考虑不同语言组合对单一语言测试效果的影响,本文以维吾尔语为例,同时加入了“维吾尔语+高资源黏着语”和“维吾尔语+其他低资源多语+高资源黏着语”两种多语微调策略。具体来说,“维吾尔语+高资源黏着语”微调是将维吾尔语和与其相近的两种高资源黏着语:阿塞拜疆语和土耳其语共同作为微调数据集,“维吾尔语+其他低资源多语+高资源黏着语”微调是将维吾尔语、其他四种低资源黏着语、两种高资源黏着语共同作为微调数据集。
3 实验准备
3.1 NER数据集
Wikiann[35]是一个公开的NER 数据集,支持28 种语言,文本主要来源于Wikipedia。Wikiann 以IOB2 的格式,对文章的LOC(地点)、PRE(人物)、ORG(机构)进行了标注。本文所使用的语言除了五种低资源黏着语外,还使用了两种高资源黏着语:阿塞拜疆语和土耳其语,做进一步验证。表1 分别给出了本文所使用低资源和高资源黏着语训练集数据大小。

表1 训练数据量Table 1 Amount of training data
3.2 评价指标
因为NER 任务是对实体边界和实体类别的识别,所以本文使用F1 值作为NER 的评价指标。F1 值兼顾了精确率(precision)和召回率(recall),如公式(6)所示:
3.3 实验设置
本文使用Hugging Face[36]提供的多语言预训练模型及训练框架。硬件方面选择RTX 3090 显卡,CUDA版本为11.3,Python 版本为3.8,PyTorch 版本为1.10.0。在训练过程中,批次大小设置为30,使用学习衰减策略,初始学习率为5×10-5,权重衰减值为0.01,Attention Dropout 为0.1,损失函数选择交叉熵损失函数,优化器选择AdamW,β1=0.9,β2=0.999,ε=1×10-8,训练轮数为50。
3.4 基线模型
本文选择mBERT、XLM-R、InfoXLM、XLM-Align、CINO 多语言预训练模型作为基线模型,图3 为其关系图。mBERT在BERT的掩码语言模型(masked language modeling,MLM)基础上,提出了多语言掩码语言模型(multilingual masked language modeling,MMLM);之后的XLM-R 结合了mBERT、XLM[25]、RoBERTa 三者优势;InfoXLM、XLM-Align、CINO 均是在XLM-R 的基础上,通过提出新的预训练方法或二次预训练得到;最后的CINO-V2通过对CINO进行剪枝所得。
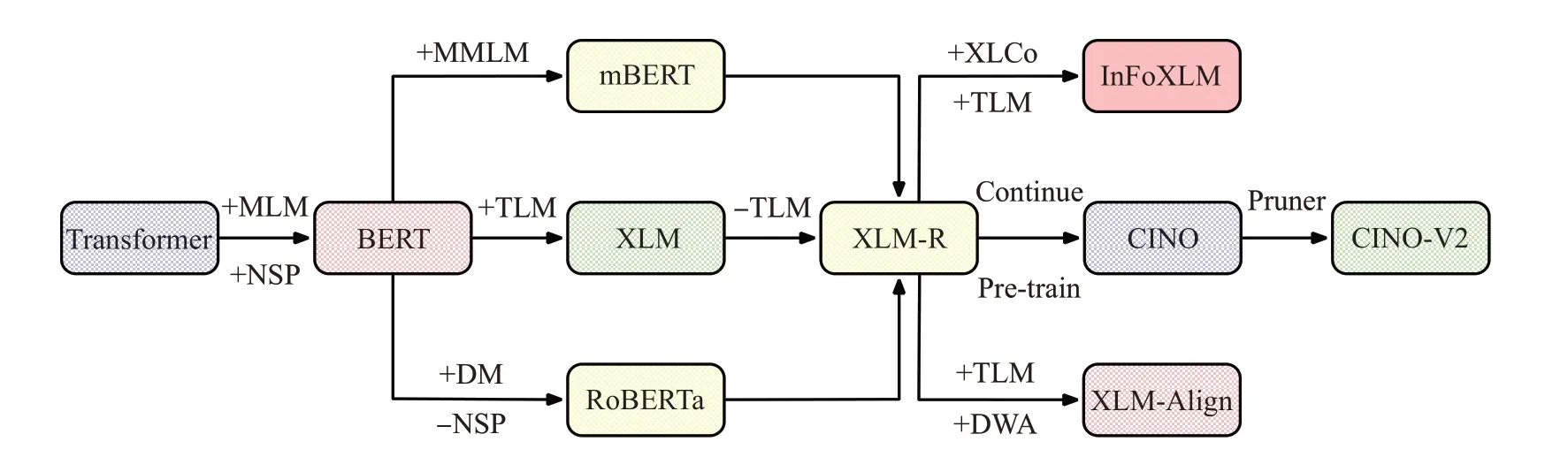
图3 多语言预训练模型的关系Fig.3 Relationship of multilingual pretrained model
3.4.1 mBERT
mBERT[20]是预训练模型BERT的多语言版本,沿用了BERT 的Transformer Encoder 架构,MLM 和下一个句子预测(next sentence prediction,NSP)预训练任务。mBERT 是最早出现的多语言预训练模型,并且在多语言迁移任务表现良好。
3.4.2 XLM-R
XLM-R[26]以Roberta架构为主,在MMLM中加入了动态掩码(dynamic masking,DM)机制,去除了NSP 任务,保留了XLM的语言抽样分布等特征,并且拥有更大的预训练数据。该模型在多语言推理、多语言问答、NER任务上分别提升14.6%、13%、2.4%。
3.4.3 InfoXLM
InfoXLM[29]是基于XLM-R 框架的多语言预训练模型,它以信息理论框架为基础,提出新的多语言预训练任务:跨语言对比学习(cross-lingual contrastive learning,XLCo),以最大化利用平行语料之间的信息。该模型在跨语语言推理、跨语语言问答、多语言句子检索任务中,相较于XLM-R和mBERT等模型,测试结果明显提升。
3.4.4 XLM-Align
XLM-Align[30]在XLM-R基础上,提出了新的多语言预训练任务:去噪单词对齐(denoising word alignment,DWA)。XLM-Align通过结合MMLM、TLM、DWA三种预训练任务,从而提高了模型迁移能力。在XTREME多语言任务基准上,XLM-Align 的平均F1 值为68.9%,超过了mBERT的63.19%和XLM-R的66.49%。
3.4.5 CINO
CINO[31]是哈工大讯飞实验室提出的中国少数民族语言预训练模型,分为V1和V2两个版本。其中,V1版本(默认为CINO)基于多语言预训练模型XLM-R,在国内多种少数民族语言语料上进行了二次预训练,因此支持XLM-R中的所有语言再加上二次预训练的少数民族语言,提高了对少数民族语言的理解能力,其large版本在朝鲜语文本分类任务上取得了最优值;V2版本在V1版本的基础之上,针对模型词表进行剪枝,在减少模型体积的同时,保留甚至进一步提高了模型处理少数民族语言的能力,其large 版本在藏语文本分类和中国少数民族语言分类任务上优于CINO的V1版本和XLM-R。
4 实验结果及分析
基于多语言预训练模型的NER已经有了一定的发展,但存在两点不足:(1)多语言预训练模型存在算力要求高等问题;(2)模型在低资源任务表现仍有较大提升空间。因此,本文对多语言模型CINO使用进行轻量化处理,得到CINO-Agglu。同时,从同语族的语言出发,对低资源黏着语NER 做了充分实验,并讨论了不同规模语言之间的迁移学习效果。
4.1 高资源多语言微调
在高资源多语言NER 方面,以Mueller 等[3]工作为例,基于mBERT对英语、德语、荷兰语、西班牙语等四种主流语言进行命名实体识别任务,如表2所示。
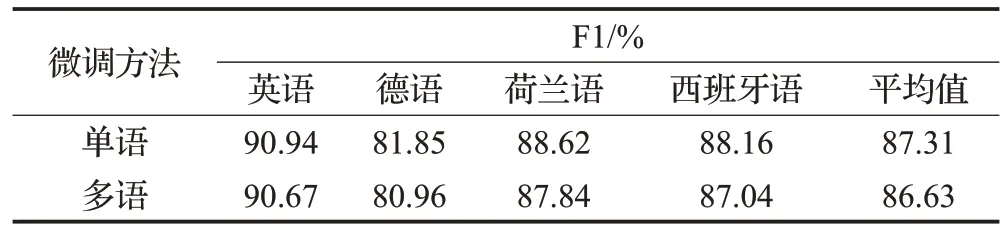
表2 高资源语言实验结果Table 2 High-resource language experiment results
通过对比四种语言进行单语微调和多语微调的结果,四种语言的多语微调结果总是低于单语微调,平均每种语言降低0.7 个百分点。总体上,在高资源语言NER任务中,单语微调优于多语微调。
4.2 低资源多语言微调
在低资源多语言NER 方面,实验结果如表3 所示,具体分析如下:
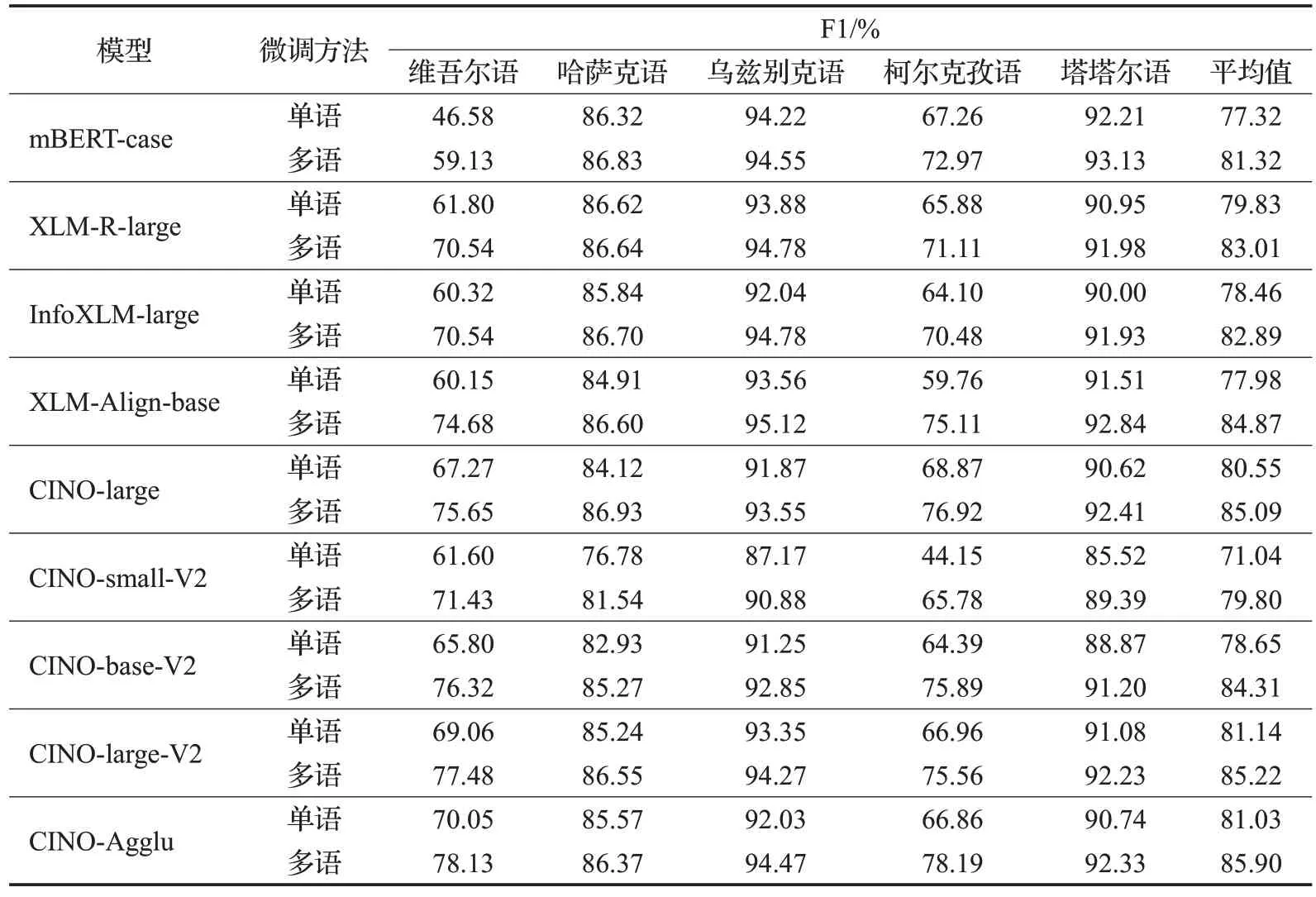
表3 低资源语言实验结果Table 3 Low-resource language experiment results
(1)总体来看,本文剪枝后的模型F1 值相比CINOlarge有一定的提升,优于基线模型。Pruner去除了词表不相关的token,使得模型的预测结果在更为精确的范围内。相比于V2版本,Agglu版本更多采用相近语言作为剪枝语料,提高剪枝效率。
(2)多语微调优于单语微调,平均F1值提升4~7个百分点,这与高资源语言实验结论相反。在维吾尔语、柯尔克孜语这两个极度稀缺训练数据的语言中提升尤为明显(该两种语言训练数据为100),平均F1值分别提升10和8个百分点。在哈萨克语、乌兹别克语和柯尔克孜语上,平均F1值分别提升了0.88、1.3、1.2个百分点。因此,多语言微调对低资源黏着语NER 是十分有效的,模型学习到的多语实体信息有利于提升单语实体识别能力。
(3)XLM-R 架构优于mBERT 架构。基于XLM-R架构的模型(XLM-R、InfoXLM、XLM-Align和CINO)在单语和多语微调方面均优于mBERT。XLM-R 架构采用更多的多语言训练数据,更大的模型架构并且通过SPM(sentence piece model)获得更大的多语言词表,更充分地学习多语言特征。
(4)InfoXLM-large相比XLM-R无明显优势。InfoXLMlarge 在单语微调表现低于XLM-R,在多语微调方面表现与XLM-R持平。InfoXLM-large使用的XLCo和TLM预训练任务对于目标语言相关的双语平行语料要求较高,其中使用的英语-土耳其语双语仅使用0.34 GB,占比0.8%,无法充分发挥XLCo和TLM任务优势。
(5)XLM-Align在乌兹别克语和塔塔尔语上取得了最优值,F1值分别为95.12%和92.84%。值得注意的是:XLM-Align多语微调相较于单语微调的提升非常显著,在维吾尔语和柯尔克孜语这两个极度稀缺训练数据的语言上,分别提升14.53和15.35个百分点;在哈萨克语、乌兹别克语、塔塔尔语上分别提升1.69、1.56、1.33 个百分点。XLM-Align平均值提升为6.89个百分点,是本文所使用五个模型中提升幅度最大的模型,这与Chi 等[30]实验结果相似:XLM-Align 在NER 和词性标注等多语言结构预测任务上取得良好的效果,DWA 任务能够大幅度提高模型多语言迁移的能力。
(6)在所有基线模型中,CINO-large-V2取得最好的效果,在维吾尔语和柯尔克孜语上取得了最优值,F1值分别为77.48%和75.56%,并且在平均F1值上也取得最优值85.22%。继续预训练方法有助于让模型迁移到目标语言领域。
4.3 不同规模语言之间的迁移
在不同资源规模的多语言NER 方面,额外考虑加入同语族高资源黏着语:阿塞拜疆语和土耳其语,进行训练。以维吾尔语为例,分别加入其他低资源黏着语、高资源黏着语、随机高资源语言3 100个数据(与低资源黏着语数据量保持一致)、其他低资源黏着语+高资源黏着语,实验结果如图4所示。与4.2节结论一致,加入不同规模的高资源语言均可以提高模型在低资源单语NER的性能,这说明同一语系的语言在语法结构、实体字词均具很好的同源性,所以迁移效果更佳。加入3 100个高资源语言数据的表现低于加入低资源黏着语的表现,说明在同一语系下,语言种类的选择对于迁移效果有较大的影响。加入全部的高资源语料得到的F1值低于加入部分高资源语料的情况,与此同时加入所有语料效果低于只加入低资源黏着语效果,说明过大的迁移语料规模可能会损害迁移效果。原因可能是模型在适当的迁移语料规模条件下,充分利用多语言共享参数并且学习了更多的相似实体从而提高性能;但在过大的迁移语料规模的条件下,容易受到噪声的影响。
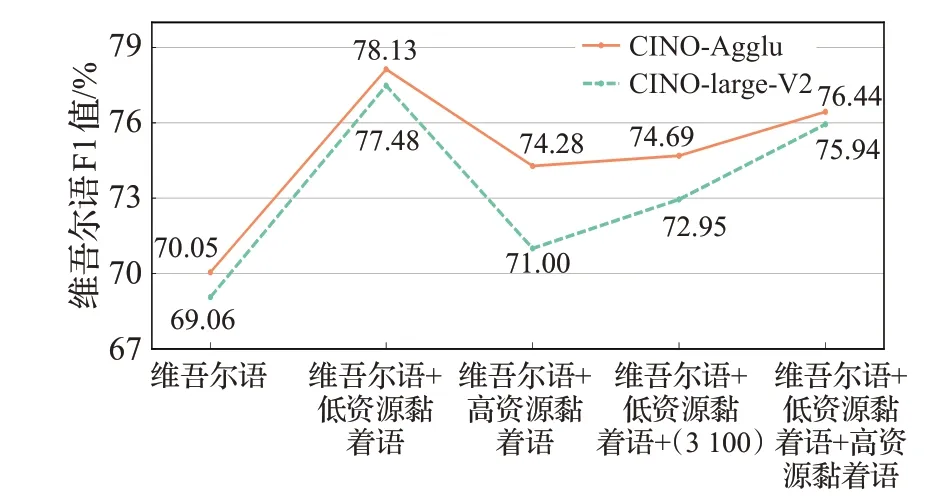
图4 不同规模语言组合下的维吾尔语NER结果Fig.4 Uyghur NER results under different quantity language combinations
为进一步探究迁移语料规模对NER 的影响,本文使用两种高资源黏着语:阿塞拜疆语、土耳其语,通过加入不同比例的高资源黏着语训练数据,观察维吾尔语F1 值。实验结果如图5 所示,随着迁移语料规模的增加,维吾尔语F1 值会得到一定提升,并达到一个峰值,之后逐渐下降。这表明语言特定参数确实存在于多语言模型中,过大的训练数据会对低资源语言产生负迁移(negative transfer,NT)。
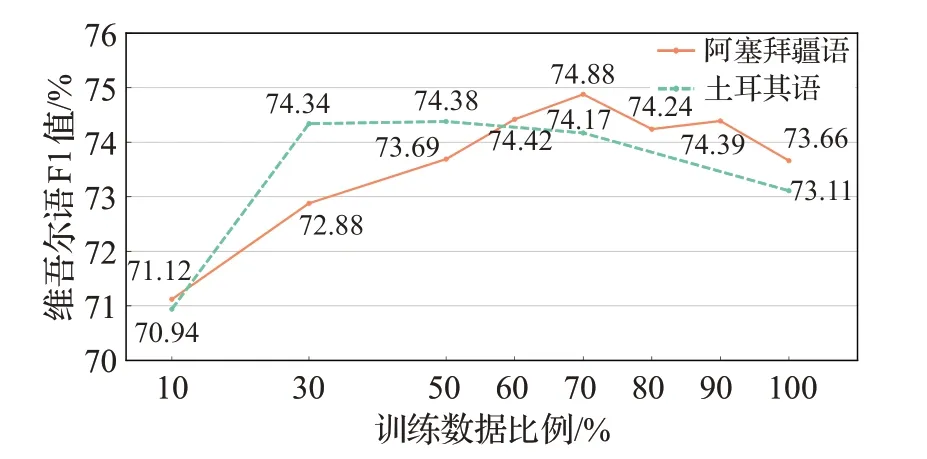
图5 不同比例训练数据下的维吾尔语NER结果Fig.5 Uyghur NER results under different proportions of training data
由上可知,在低资源跨语言NER中,加入同语系的语料可以有效提升模型性能,但是过大规模的语料会产生负迁移。针对低资源负迁移问题,主要有以下缓解方法:(1)控制迁移数据规模是一个简单且有效的办法,但是会造成迁移语料的浪费;(2)使用元学习方法改善多语言模型参数[37],提升模型在目标语言中的性能;(3)提高训练数据质量[38],低噪声的数据是迁移学习中的关键因素。
4.4 剪枝性能
如表4 所示,CINO-Agglu 参数量为3.26×108,词表大小仅为2.2×104,相较于原始模型,其参数量减少了44%,词表大小减少了92%,推理速度提升了38%,大幅降低了模型体积,加快了模型计算速度。在性能方面,CINO-Agglu 的平均F1 值相较于剪枝前增加了0.93 个百分点,有一定提升。CINO-Agllu 与CINO-large-V2 均是对CINO-large进行词表剪枝得到,不同之处在于,V2版本支持中文及少数民族语言,而Agglu版本仅支持本文NER任务中的黏着语。结果显示,Agglu版本性能优于V2 版本,说明更有针对性的词表剪枝策略能够提高跨语言预训练模型处理特定任务的能力。

表4 模型剪枝对比Table 4 Model pruner comparison
此外,本文也在CINO-large 的基础上进行了Transformer 和Pipeline 两种剪枝策略。其中,Transformer 剪枝根据神经元的重要度得分,对得分低的神经元进行剪枝,Transformer剪枝并不会减少词表大小;Pipeline剪枝则是Transformer 剪枝和词表剪枝的结合。通过Transformer 剪枝后的模型仅有12 层,每层注意力头数目为8,模型体积和推理时间都有一定幅度降低,平均F1 值为83.27%;通过Pipeline 剪枝后的模型仍为12 层、每层注意力头数目为8,词表大小为22 000,参数量和推理时间也得到大幅度削减,平均F1 值为82.1%。由此可见,这两种剪枝策略,尤其是Pipeline剪枝策略,虽然实现了模型轻量化,但是这种改变模型架构的剪枝策略带给了模型较多性能上的损失。
4.5 词表阈值分析
词表阈值是词表剪枝中重要参数之一。如果剪枝语料中token出现的次数小于设定阈值,该token将从原模型词表中删除。本文进一步研究了不同词表阈值对剪枝模型性能的影响,如图6 所示,横轴为词表阈值大小,柱状图和折线图分别代表词表阈值所对应剪枝后模型的词表大小和五种低资源黏着语NER 平均F1 值,随着阈值的增大,低频出现的token将会被删除,从而带来词表大小和F1值的一定幅度减少。因此,去除部分较低频率出现的token也会降低模型处理NER任务的能力。
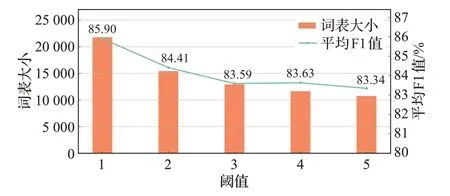
图6 不同词表阈值结果Fig.6 Different vocabulary threshold results
4.6 模型层数
为了进一步研究模型架构对CINO-Agglu 处理低资源黏着语NER 的影响,如表5 所示。本文通过改变CINO-Agglu的Transformer层数,分别对6、12、18、24、30层的CINO-Agglu 模型进行实验。由结果可知,CINOAgglu 每增加6 层,模型将多出约75 000 000 的参数量,训练时间也随之延长,24个Transformer层的CINO-Agglu取得最优平均F1值,但与18和30层的平均NER结果差距不大。综合模型性能和轻量化角度,本文选择24 层作为CINO-Agglu的层数。
4.7 消融实验
消融实验结果如表6 所示。仅使用低资源黏着语NER 剪枝语料能够保留模型大部分性能,平均F1 值为84.22%;去除NER语料(即仅使用维哈语料),则会有大幅度降低,平均F1 值为68.45%;维吾尔语NER 取得良好效果,但哈萨克语有较大损失,主要原因在于本文构建的哈萨克语剪枝语料使用阿拉伯文字,而哈萨克语NER 数据集使用西里尔文字。添加额外语料能够提高模型的泛化能力,与此同时减少剪枝错误移除token 的现象,提高剪枝后模型的性能。

表6 消融实验Table 6 Ablation experiment
4.8 案例研究
为了进一步研究多语微调策略的有效性,本文以维吾尔语为例进行案例研究。表7 展示了使用维吾尔语单语微调和低资源多语微调的三个案例。虽然两种微调策略均可正确识别实体边界,但是单语微调却存在较多人名和地名实体识别错误问题。相近语种之间存在大量相似命名实体,因此多语微调策略可以从相近语种学习到目标语言的命名实体类别等方面特征,从而增强实体识别能力。

表7 两种微调策略的NER结果Table 7 Results of two fine tune strategies for NER
5 结论与展望
本文提出一种轻量化多语言预训练语言模型CINOAgglu。该模型使用的多语言剪枝方法能够大幅度降低模型算力需求。同时,通过多语言微调,进一步提高了F1值。在未来的工作中,将从以下四个方面开展研究:
(1)充分考虑黏着语嵌套命名实体[39-40]的情况。
(2)对阿拉伯和西里尔两种文字进行规范化处理,缓和黏着语中的文字差异现象所导致的模型性能下降问题。
(3)深入挖掘多语言预训练模型潜能,包括加入基于词典和知识蒸馏等方法提取多语言特征等方面,并根据模型架构进一步高效轻量化模型。
(4)使用数据增强方法对低资源语言训练资源进行扩充,进一步缓解数据稀缺问题。主要包括基于形态规律[41]、机器翻译[42]、生成式[43-44]的数据增强。
猜你喜欢
英语世界(2021年13期)2021-01-12
电线电缆(2018年2期)2018-05-19
家庭影院技术(2017年10期)2017-11-23
自动化学报(2017年4期)2017-06-15
国家图书馆学刊(2016年2期)2016-10-09
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年4期)2015-07-18
语言与翻译(2014年3期)2014-07-12
教育科学论坛(2014年8期)2014-03-01
图书馆建设(2012年3期)2012-10-23
