
基于遗传算法优化支持向量机的震级预测模型研究
2023-12-25 06:30张小涛张新东王晨晖
河北地质大学学报 2023年6期
张小涛, 张新东, 王晨晖
1. 河北红山巨厚沉积与地震灾害国家野外科学观测研究站, 河北 邢台 054000; 2. 邢台地震监测中心站, 河北 邢台 054000; 3. 河北省地震局, 河北 石家庄 050021
0 引言
由于地震孕灾因子较多, 导致震级与影响因子的非线性关系十分复杂, 很难用直观数学式表达这种不确定关系。 传统的定量分析比较依靠主观判断, 修正权值依赖专家经验, 导致震级预测效果精度不高。 近年来, 许多研究人员运用BP 神经网络[1]、 灰色系统[2]等人工智能算法对震级开展预测工作, 取得了一定效果, 但模糊函数的主观经验和BP 神经网络局部极值等问题仍然存在。
当前随着机器学习的不断发展, 支持向量机在处理小样本非线性问题表现出良好性能, 并迅速应用于震级预测方面。 朱景宝等[3]选取12 个P 波特征参数作为输入, 震级为输出, 利用SVM 实现地震震级的预测。 宋晋东等[4]选取12 个P 波特征参数作为模型输入参数, 构建支持向量机的高速铁路地震预警震级预测模型; 吴芳等[5]将地震活动周期值作为参数应用于最小二乘支持向量机预测中; 武安绪等[6]引入非线性回归算法优化了SVM 震级预测模型。 但对于支持向量机的参数优化一直没有较好的解决方法。 遗传算法利用遗传变异思想, 能够初始参数组合寻找到全局最优, 不易陷入局部极值, 马创等[7]和谷艳昌等[8]均运用遗传算法确定了支持向量机的最优参数。此外, 影响因子之间的重复信息加大了模型运算量,而主成分分析法可以有效降低指标维度, 提高模型运行效率。 基于此, 本文建立了基于PCA 和GA 优化的SVM 模型, 试图为地震预测提供参考。
1 基本原理
1.1 主成分分析法
主成分分析(PCA) 是对提出的所有变量, 将重复的变量删去多余, 建立尽可能少的新变量, 使得这些新变量是两两不相关的, 而且这些新变量反映的信息尽可能保持原信息, 从而到达降维目的, 其降维原理[9-11]主要如下: 设(X1,X2…,Xn) 是X的n个向量, 每个向量包含m维变量,X可表示为:
接着计算X的协方差阵, 利用下式:
求出协方差阵的相关系数阵, 根据相关系数阵的特征值λ1≥λ2≥…λm≥0, 可以得到第i个主成分的贡献率为λi/P, 其中i=1, 2, 3, …m,P =前q个主成分的累计贡献率为
1.2 支持向量机
支持向量机是一种处理非线性问题的机器学习方法[12-14], 其主要步骤如下:
其中:w可变权值,b为偏置值, 且w和ϕ(Xi)均为n维向量。 引入ξ和ξ*作为松弛变量, 从而建立约束函数为:
其中C为惩罚函数, 用于调整超出松弛变量的惩罚程度。 然后运用拉格朗日乘子法对(4) 进行求解,得到函数:
其中:ai、、ri和都为Lagrange 乘子。 式(5) 分别对w和b求偏导并置零, 反代回式 (5)中, 就可以得到上述问题的对偶问题, 使用二次规划优化算法计算得到参数ai和对应的最优乘子, 同时构造得到预测函数:
其中:、ai为拉普拉斯算子,b为偏置值,ϕ(Xi)Tϕ(Xi) 为核函数。
综上, 本文利用主成分分析法对震级影响指标进行降维处理, 然后将新生成的主成分映射到支持向量机的特征空间, 从而建立地震震级预测模型。
2 地震震级预测
支持向量机(SVM) 参数优化方法已发展众多,其中遗传算法汲取生物学遗传变异思想[15-17], 可以快速有效地遍历所有的参数组合, 不已陷入局部极值, 从而寻优得到SVM 最优参数组合。
基于PCA-GA-SVM 的地震震级预测模型构建流程图如图1 所示, 具体步骤如下:
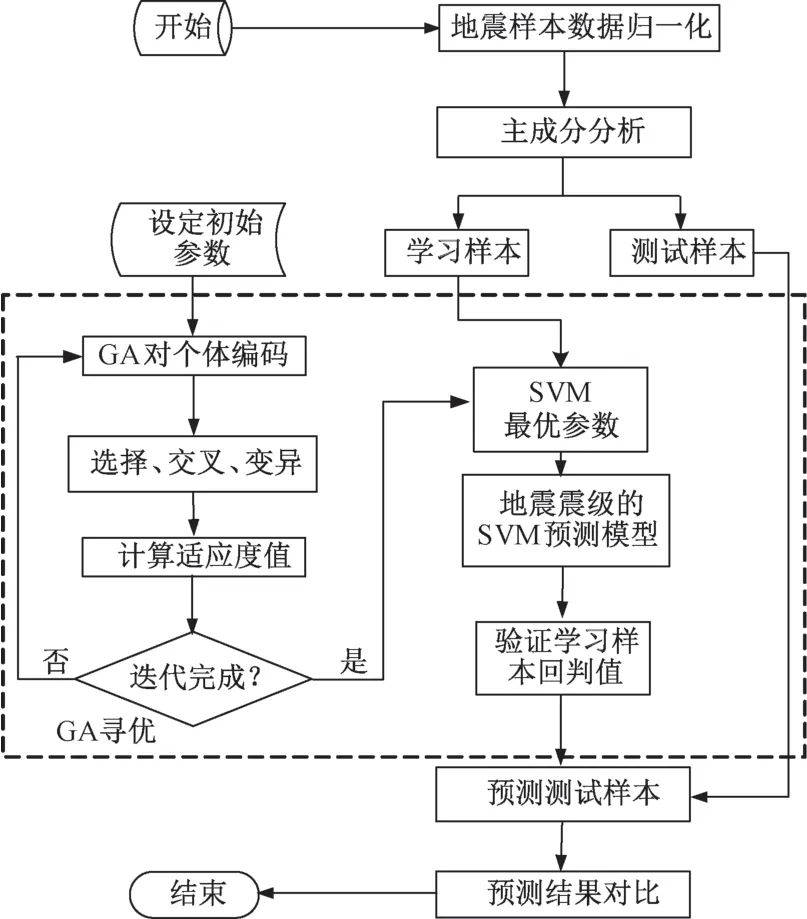
图1 基于PCA-GA-SVM 的地震震级预测模型构建流程图Fig.1 The flow chart for earthquake magnitude prediction model based on PCA-GA-SVM
1) 按式(7) 对7 个影响因子数据进行归一化处理。
式中,Xi和分别对应第i个地震样本数据和其相应的归一化数据;Xmin和Xmax分别为各个影响因子的最小值和最大值。
2) 利用PCA 对归一化原始数据进行降维处理,形成新的主成分, 以新生成的主成分作为输入变量。
3) 利用GA 寻求SVM 最优参数, 构建基于遗传算法优化支持向量机的地震震级预测模型。
4) 将建立的PCA-GA-SVM 模型应用于地震震级测试样本, 实现地震震级预测。
2.1 数据来源
本文利用文献[18]中地震样本数据进行模型建立和预测, 以中国云南滇西南地区的17 个地震资料作为样本来源(见表1), 判断基于遗传算法优化支持向量机(PCA-GA-SVM) 模型的地震震级预测效果,计算时随机选取10 个地震数据作为训练样本, 其他7个作为测试样本, 对预测结果和真实结果进行分析,从而检验模型的预测效能。
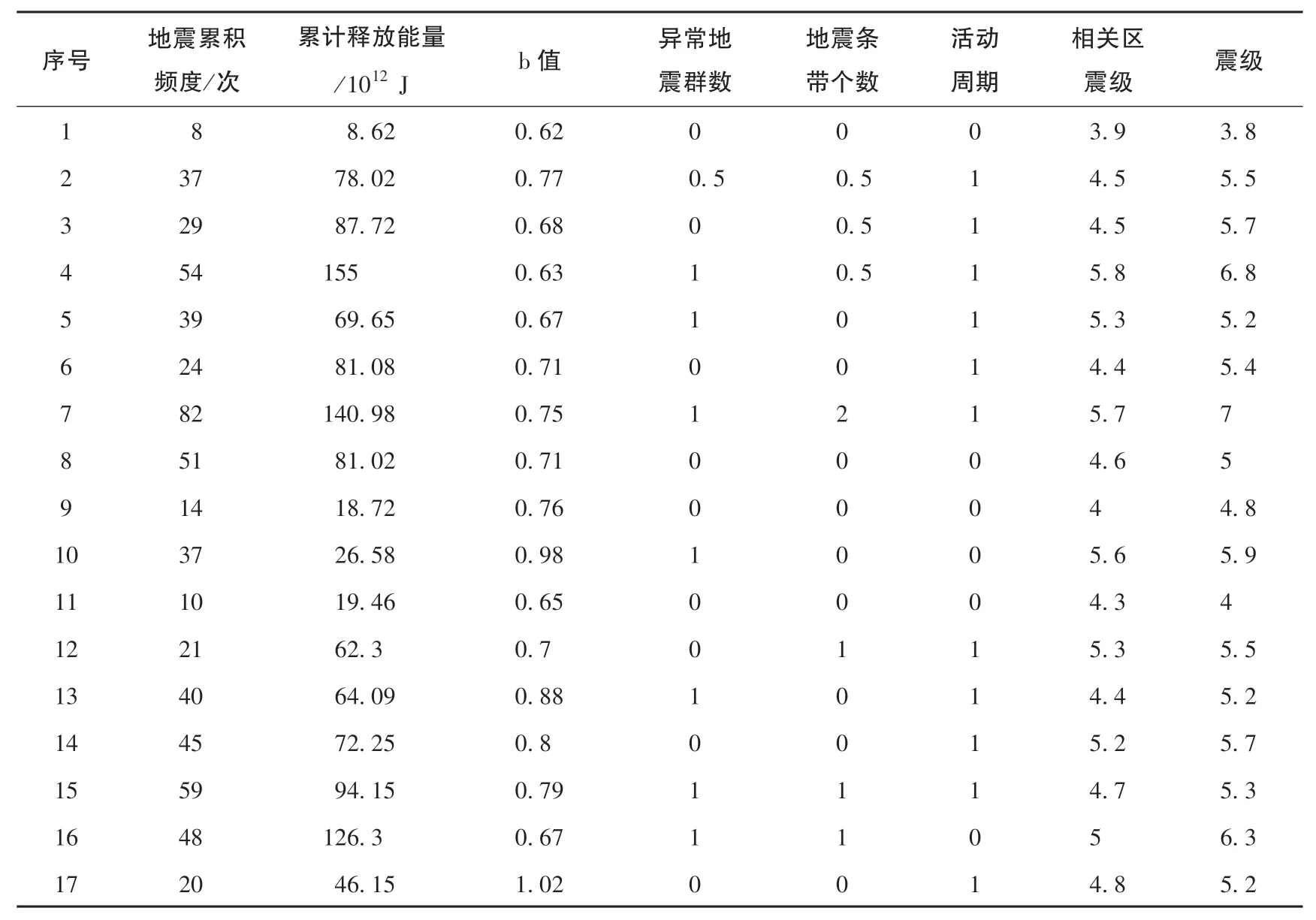
表1 地震样本原始数据Table 1 Raw data of seismic sample
其中地震累积频度是指半年内发生3 级以上地震次数, 累计释放能量是指半年内能量释放积累值,b值为震级和频度关系式中的比例系数。 活动周期中的0 表示该区域断裂带不处于活动周期, 1 表示该区域断裂带处于活动周期。
2.2 主成分分析
利用主成分分析(PCA) 对归一化地震样本数据进行处理, 得到相关系数阵见表2, 可看出地震累积频度、 累计释放能量、 异常地震群数和地震条带个数四者存在正相关关系。 各主成分贡献率如表3 所示,前四个累计贡献率为88.6%, 基本能够反应原来7 个变量所携带的信息, 由成分得分系数矩阵可以得到前4 个主成分表达式如式(8) 所示。 新生成的4 个主成分作为模型输入, 剔除了冗余信息, 同时降低了输入维度, 提高了运行效率。
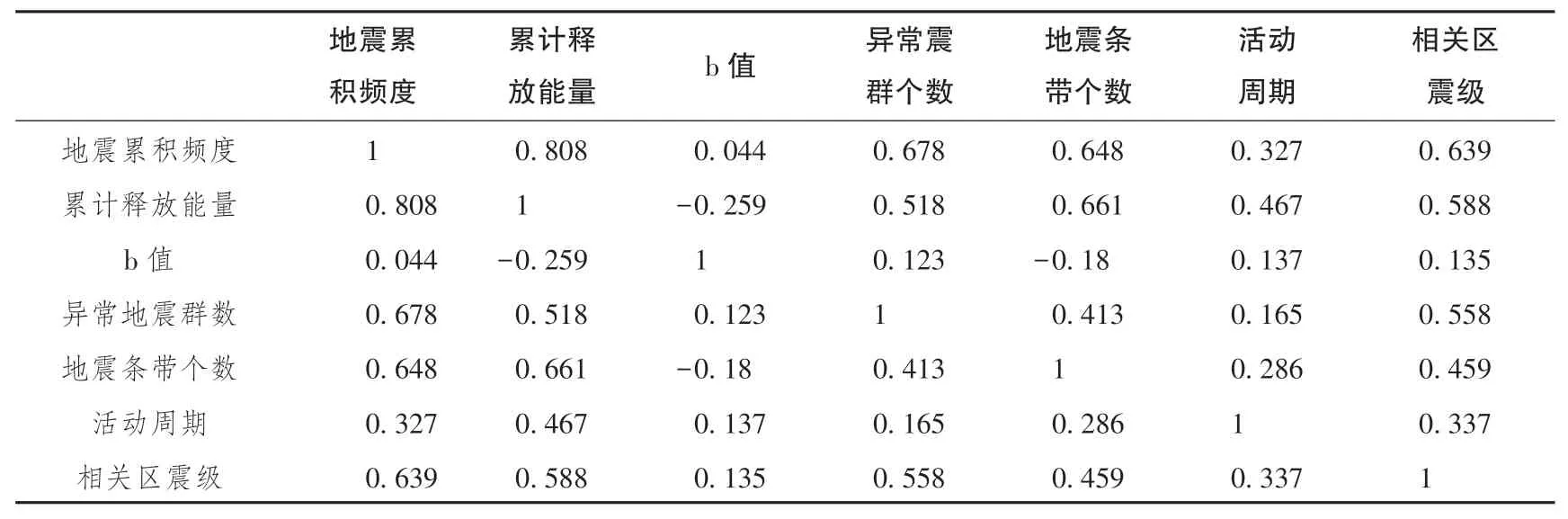
表2 相关系数阵Table 2 Correlation coefficient matrix
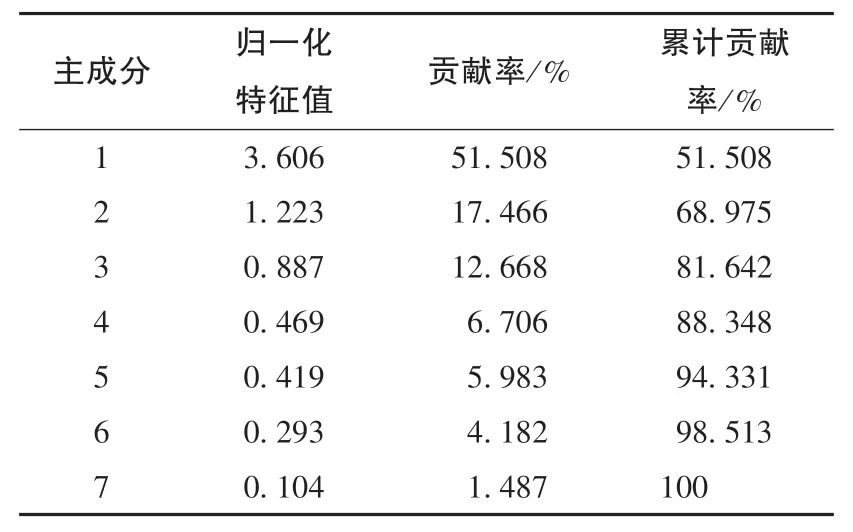
表3 归一化特征值、 贡献率和累计贡献率Table 3 Normalized eigenvalue, contribution rate,and cumulative contribution rate
3 模型建立
预测模型建立时选取径向基函数为SVM 的核函数, 用MATLAB 语言编写GA 优化SVM 参数程序,初始种群个数为30, 遗传代数为100。 GA 寻优过程如图2 所示, 得到最优参数C=3.157,g=6.362。 利用建立好的SVM 模型对学习样本进行回判检验, 回判结果如图3 所示。

图2 遗传算法寻优Fig.2 Genetic algorithm optimization
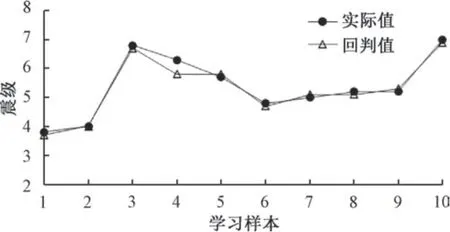
图3 学习样本回判结果Fig.3 Learning sample feedback results
从图3 回判结果看出, 基于遗传算法优化支持向量机(PCA-GA-SVM) 模型的回判值与实际值一致性较高, 模型对学习样本有良好的回判效果, 其中样本4 误差较大, 主要是同类级地震样本个数较少, 造成机器学习出现偏差, 总体上该模型对测试样本的预测具可靠性较高。
为进一步判断预测效能, 将基于遗传算法优化支持向量机 (PCA-GA-SVM) 模型的测试样本, 使用GA-SVM、 GA-BP、 PCA-GA-BP 三种模型的计算了预测结果, 分析不同模型的预测效能, 四种模型的预测结果见表4 和图4。
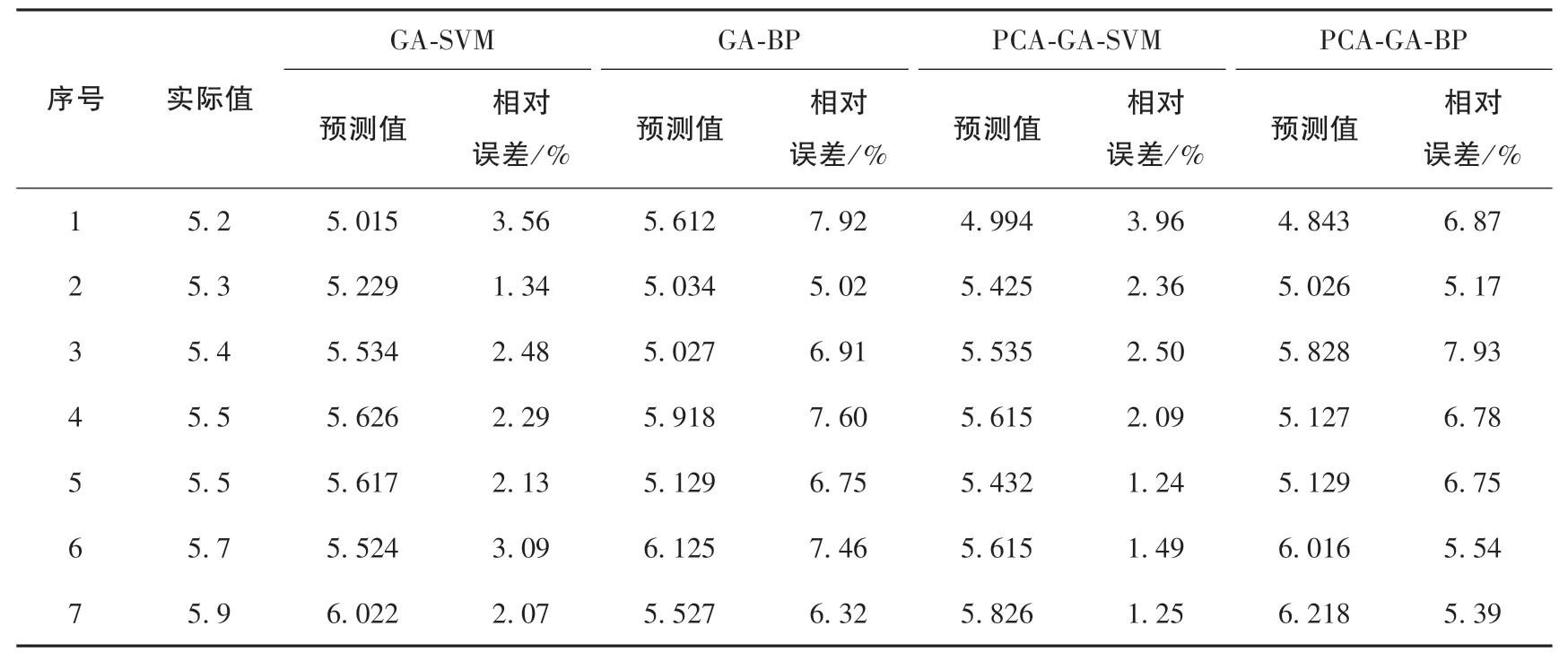
表4 四种模型预测结果Table 4 Prediction results of four models
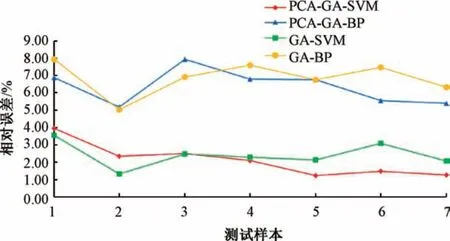
图4 四种模型预测结果相对误差Fig.4 Relative error of prediction results of four models
由表4 和图4 可以看出, 当以原始数据作为模型输入时, GA-SVM 和GA-BP 两种模型预测结果的平均相对误差分别为2.42%、 6.85%。 当以主成分数据作为模型输入时, PCA-GA-SVM、 PCA-GA-BP 两种模型预测结果的平均相对误差分别为2.13%、 6.35%, 表明SVM 的预测精度较高, 且优于BP 神经网络模型的预测精度。 另一方面, 无论是将原始数据还是提取的主成分作为模型输入, SVM 均有很高的预测效果, 再次佐证了SVM 在震级预测中的有效性。 同时在PCA降低数据维度、 剔除冗余信息、 提高模型预测效率的情况下, 两种模型的预测精度分别提高0.29%和0.50%。
4 结论
本文针对震级与其影响指标之间复杂的非线性关系, 建立了基于PCA-GA-SVM 的地震震级预测模型,并以中国云南滇西南地区的17 个地震资料作为样本对模型性能进行了验证, PCA 模型可将变量参数维度由7 维降至4 维, 剔除了原参数变量间的冗余信息,提高了模型运行效率, 预测平均相对误差为2.13%,结果表明该模型方法具有良好的预测效果, 可为地震预测提供可靠参考依据。
猜你喜欢
自然灾害学报(2022年2期)2022-05-10
新高考·高一数学(2022年3期)2022-04-28
奥秘(创新大赛)(2021年3期)2021-05-15
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
山西地震(2020年1期)2020-04-08
石油地球物理勘探(2017年2期)2017-11-23
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
高中生学习·高三版(2016年9期)2016-05-14
智能系统学报(2015年4期)2015-12-27
