
基于常规测井资料的储层流体识别
2023-12-25 06:30许鉴源赵军龙黄千玲
河北地质大学学报 2023年6期
许鉴源, 赵军龙, 白 倩, 黄千玲
1. 西安石油大学 地球科学与工程学院, 陕西 西安 710065; 2. 陕西省油气成藏地质学重点实验室, 陕西 西安 710065
0 引言
测井流体识别是以测井资料为主要依据, 对储集层岩性、 物性及储层流体情况进行有效的刻画研究。目前, 岩性测井系列(自然电位、 自然伽马)、 孔隙度测井系列(声波、 密度、 中子)、 电阻率系列(双侧向、 微电阻率、 方位电阻率及阵列感应) 以及工程测井系列(井径、 井斜方位) 是致密砂岩储层主要的测井识别系列[1], 由于地下地质对象的隐蔽性和复杂性, 以及地球物理测井(测井) 资料信息的处理及解释是以岩石物理机理模型为基础, 需要许多先验条件, 这些测井方法虽然各有所长, 但在实际情况中单独使用某类测井方法会造成解释结果的多解性及不确定性问题, 难以准确识别出地层的流体性质[2,3]。 传统的岩心观测法因有限的岩心, 而仅能反映井眼附近区域的流体分布情况, 但该方法识别效果较为准确。虽然目前储层流体是可以通过新的特殊测井方法获得较为准确的识别, 但受限于成本及特殊测井方法在老井中采集资料困难等原因, 导致特殊测井方法没有大规模普及使用, 因此主要识别流体的测井方法还是依赖于常规测井资料[4]。 其中曲线重叠法和流体识别因子交会图法是流体识别工作中应用比较多的两种能对储层流体进行直观快速识别的定性方法, 任培罡等[5]基于双孔隙度重叠法, 构建了流体识别因子—孔隙度交会图进行流体识别取得了不错的应用效果。
随着物探智能化水平的提高发展, 将机器学习的算法与测井响应特征研究综合起来, 进行海量测井数据的加工、 挖掘和利用, 最终完成测井解释取得了较好的效果[6]。 赵倩[7]建立了以流体特征作为参数的决策树模型, 并与传统地球物理图版结合有效解决了图版法的不确定性问题; 廖广志等[8]对压汞毛管压力数据使用主成分分析、 灰色关联分析、 智能聚类和因子分析等数据挖掘算法进行深度分析, 对比预测结果和测井解释反映的孔渗特征发现两者一致性较高;易军等[9]以鄂尔多斯盆地致密砂岩储层为研究对象,提出一种基于改进 ADASYN (Adaptive Synthetic Sampling Technique) 数据增强的致密砂岩储层流体识别集成学习方法, 提出的方法的试气平均准确率为91.1%; 何健等[10]为了提高储层流体识别的精度与可靠性, 选择随机森林算法结合地震资料识别储层流体, 该算法减弱了单一流体识别因子所引起的多解性; 罗刚等[11]针对储集层流体识别任务, 采用卷积神经网络和长短期记忆网络分别表征测井曲线时序特征以及多条测井曲线之间的相互关联关系, 克服了储层流体识别任务中的各种问题。
考虑到机器学习算法中的随机森林算法引入了随机性不容易过拟合、 能够有效的在大数据集上运行及训练速度快等特点, 魏佳明和韩家新[12]利用随机森林算法预测储层孔隙度; 任雄风等[13]利用随机森林算法预测浊积岩储层厚度; 李文斌等[14]使用随机森林回归分析预测了岩体结构面粗糙度系数; 王民等[15]建立了基于随机森林算法的岩相识别模型,有效解决了岩相类别不均衡的分类问题, 确定了有利岩相分布, 为后续 “甜点” 提供支持; 聂云丽等[16]采用随机森林机器学习方法结合多元信息,避免了单颗决策树过拟合的缺陷, 有效完成页岩气“甜点” 预测。 本文在前人研究成果的基础上, 针对鄂尔多斯盆地M 区块长3 储集层开展流体识别研究,基于收集到的研究区测井资料、 地质资料进行流体预测, 以提高流体性质识别的准确性。
1 流体识别方法与应用效果
前人对于利用常规测井资料识别流体性质提出了许多方法, 如测井参数曲线重叠法中的双孔隙度曲线重叠法、 三孔隙度曲线重叠法和径向电阻率比较法,交会图法中的电阻率—孔隙度交会图、 电阻率—声波时差交会图、 Hingle 图版等流体定性识别方法。 定量评价有基于阿尔奇公式的计算方法、 基于Biot-Gassmann 理论的定量计算方法、 利用ΔlgR 计算公式判别含油气性等。
1.1 径向电阻率测井响应特征
径向电阻率法是直观定性识别油层的重要方法,泥浆侵入使得井眼附近的岩层电阻率发生变化, 从电阻率径向变化特征将泥浆侵入造成径向电阻率不同的情况分为两类(以淡水泥浆为背景): 一是增阻侵入, 当地层中原有流体的电阻率比较低时, 电阻率较高的泥浆滤液侵入后造成侵入带岩石的电阻率升高, 表现为Rxo〉Rt, 即当深探测电阻率低于浅探测电阻率时, 判别此处为地层水矿化度较高的水层;二是减阻侵入, 当地层中原有流体的电阻率比较高时, 泥浆滤液侵入后造成侵入带岩石的电阻率降低,表现为Rxo〈Rt, 即当深探测电阻率高于浅探测电阻率时, 判别此处为地层水矿化度不高的油层。 将电阻率特征法识别流体性质应用于本研究区储层, 其结果与试油结论对比见图1, 针对本地区五口井使用电阻率特征法开展流体性质识别, 识别效果均表现较差。
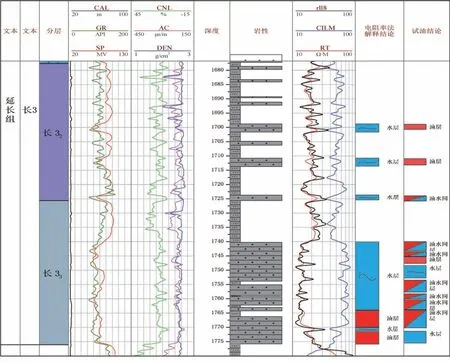
图1 DG-02 井电阻率特征法识别流体性质成果图Fig.1 Results of resistivity characterisation of well DG-02 to identify fluid properties
造成深浅探测电阻率差异识别流体类型效果较差的现象是由于低孔低渗砂岩储层流体的测井响应特征差异不明显、 研究区储层是低电阻率油层, 造成电性曲线划分油水层困难, 甚至无法划分出油层和水层。
1.2 自然伽马相对值与视地层水电阻率交会图法
用于表示地层的测井参数和其他参数之间关系的图即为交会图。 交会图的可应用场景丰富, 如收集资料时可以检查测井曲线质量, 进行测井资料预处理时的曲线校正, 测井解释过程的鉴别地层矿物成分、 识别地层孔隙流体类型、 评价地层等, 因此交会图成为了测井分析工作者实用、 强劲的工具。
研究区块地质构造复杂, 油水层测井响应特征不明显, 难以准确区分流体性质。 在前人研究的基础上, 结合当前区块储层特征与四性关系使用交会图版开展流体性质识别。 交会图图版是用来表示给定岩性的两种测井参数关系的解释图版, 它们是根据测井响应关系建立的解释图版, 是测井解释与数据处理的依据。 由于经研究区块的油层中泥质含量较大,ΔGR可以反映地层中泥质含量,Rwa囊括了储层孔隙空间、 电阻率、 油层和水层的“线索”, 所以建立Rwa-ΔGR交会图来反映地层流体情况, 见下图2。 其中,

图2 Rwa-ΔGR 交会图Fig.2 Rwa-ΔGR meeting plates
式中:ΔGR-自然伽马相对值, API;GR-自然伽马实测值, API;GRmax-自然伽马最大值, API;GRmin-自然伽马最小值, API;Rwa-视地层水电阻率,Ω·m;φ-孔隙度,%;Rt-原状地层电阻率, Ω·m。
油层的视地层水电阻率Rwa为高值, 且油层Rwa远大于水层, 因此油层和水层可以准确划分出来。 大部分油层与油水有明显界限能够较好的区分, 但有一小部分油层与油水同层相互重叠, 不易区分。 大部分水层与油水同层交织在一起, 无法准确划分出界线,由交会图可得下表所示的流体性质识别的划分依据如下表1。

表1 流体性质划分依据表Table 1 Table of fluid properties classification basis
1.3 饱和度解释模型
地层的含油气性是岩层含油(气) 饱和度定量描述, 含油饱和度是表征储层含油性好坏的重要参数。饱和度是储层定量评价、 区分流体性质, 划分油水层等过程的重要指标。 一般情况下含油饱和度与含水饱和度是互补关系(Sw+So= 1), 因此确定了含水饱和度也就知道了含油饱和度, 由此对储集层含油水性质做出评价。
众多学者采用了体积模型与电阻率并联概念及Archie 公式, 建立了不同的解释模型, 得出的不同泥质砂岩电阻率和含水饱和度公式如下表2 所示。

表2 常用饱和度计算公式Table 2 Common saturation calculation formulae
本研究区层段流体类型主要分为三类: 油层、 油水同层、 水层。 水层:Sw〉70%; 油水同层: 70%〉Sw〉50%; 油层:Sw〈50%, 应用Archie 公式, 并且参考同一地理位置、 类型相差不大油藏的经验公式对本区含油饱和度进行计算, 划分油水层成果如图3 所示,结果符合率约为72.95%。
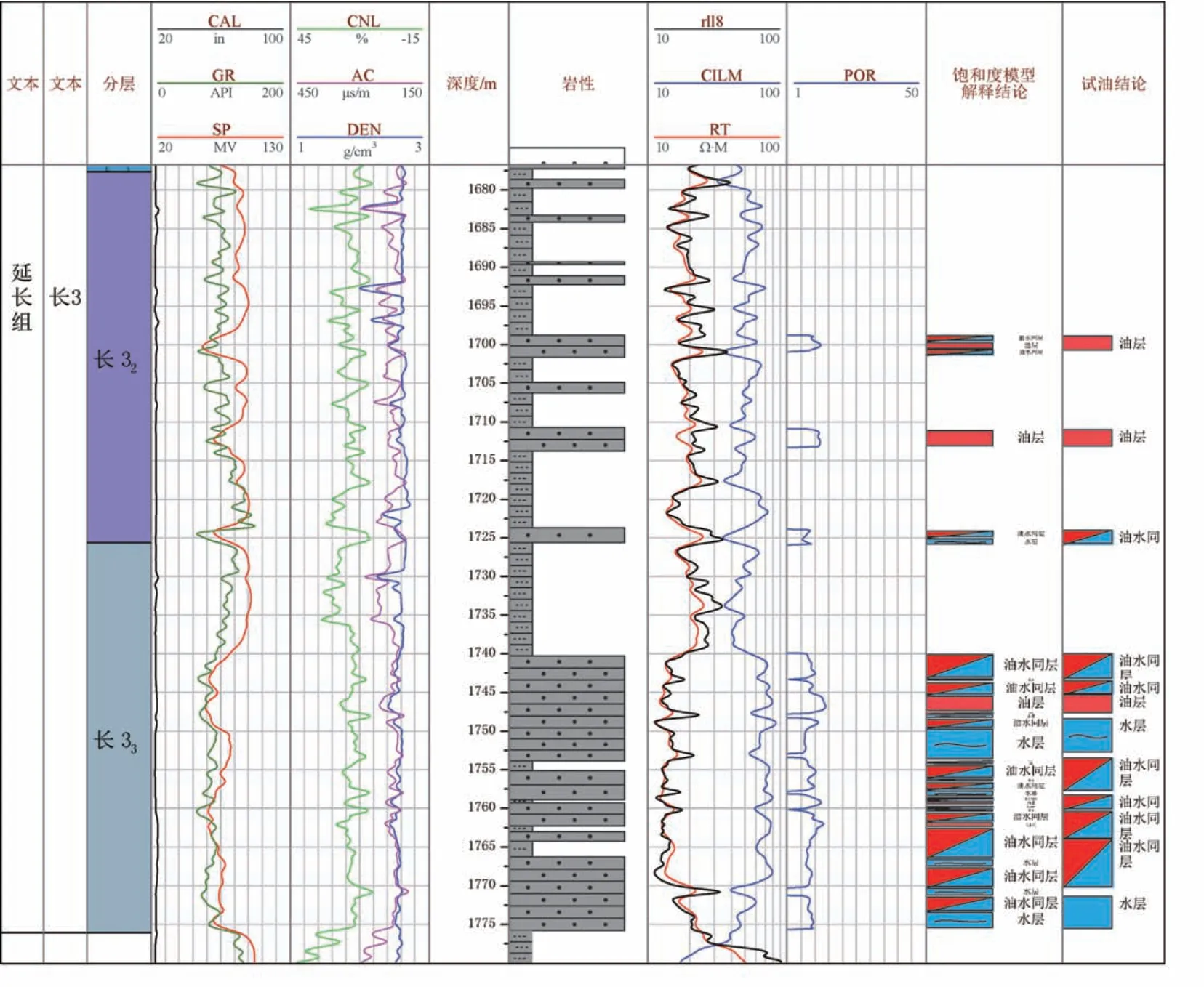
图3 DG-02 井饱和度结论划分流体性质成果图Fig.3 Map of the results of the classification of fluid properties by saturation conclusion for well DG-02
2 基于随机森林的流体识别技术构建
2.1 随机森林基本原理
随机森林算法的基本单元是决策树, 通过集成学习的思路将众多弱决策树结合汇集成“森林”, 并对Bagging 算法进行了改进[17]。 相比于传统决策树在选择划分n个属性是在当前结点的属性集合中选择一个最优属性; 随机森林是对基决策树的每个结点都会先从该结点的属性集合中随机选择一个包含m个属性的子集, 再从m个属性的子集中选择一个最优属性进行划分[18]。
为了减少训练样本规模不同造成的影响, 随机森林采用的是自助采样法为基础的 “自助法”(boostrap) 重采样技术, 即对给定包含n个样本的数据集K进行采样产生数据集K’, 每次随机从K中挑选一个样本放入K’ 中, 然后再将该样本重新放回原始数据集K中, 因此下一次采样过程中该样本仍然有几率被抽中[19]。 这样进行n次有放回采样后就得到了包含n个样本的数据集K’。 样本在n次采样过程中始终不被采到的概率为取极限得到:
即通过自助法重采样技术初始数据及K中约有36.8%的样本未出现在采样数据集K’ 中, 这些数据被称为袋外数据[20]。 基于自助法生成的k个决策树即为森林。
另外随机森林的优势包括以下几方面: 一是人为干扰较少。 随机森林算法在构建流体识别因子的过程中能够自动依据测井数据的样本特点来确定分裂特征, 不需要人为干预对数据进行预处理, 从而减少了人为干扰。 二是它可以处理大量的输入变数; 三是特征属性突出。 随机森林算法在随机选取特征属性进行分裂的过程中, 可以通过比较训练集中各特征属性之间的属性值大小建立相互的影响关系, 再通过该关系衡量特征属性的“价值”, 进而为研究人员利用何种特征属性进行流体识别提供参考依据。
2.2 随机森林识别流体的关键技术构建
随机森林是用bootstrap 方法构建k个不同的训练数据集, 对于每个训练集, 构造一颗决策树, 对于每一个节点, 随机选择m个特征, 决策树上每个节点的决定都是基于这些特征确定的。 根据这m个特征, 计算其最佳的分裂方式。 最终决策一般通过投票来获得, 投票最多的为预测结果[21]。 随机森林模型识别流体性质的流程图见图4。
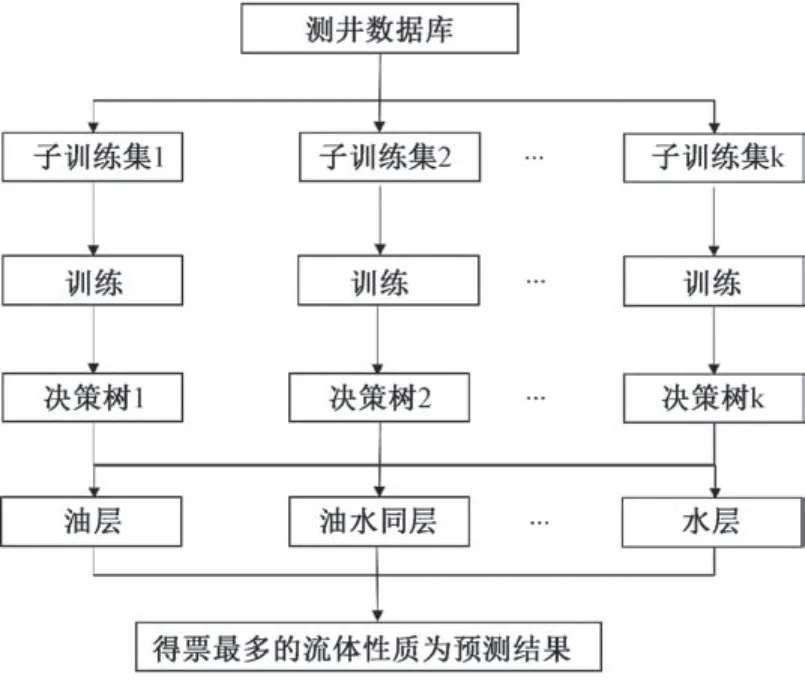
图4 随机森林算法流程图Fig.4 Flow chart of the random forest algorithm
2.3 识别效果分析
基于收集到的测井资料, 将与流体类型具有较高相关关系的自然伽马(GR)、 自然电位(SP)、 地层真电阻率(Rt)、 声波(AC)、 密度(DEN)、 中感应电阻率(RILM) 作为流体识别的特征参数, 试油结论视为真值(1 代表油层, 2 代表油水同层, 3 代表水层), 在Python 环境下构建基于随机森林算法的流体识别模型, 修改模型各参数配置。
对于本模型参与训练的输入特征曲线重要度如图5 所示, 自然伽马的权重影响因子为7.8%, 自然电位的权重影响因子为15.5%, 地层真电阻率的权重影响因子为35.4%, 声波的权重影响因子为14.9%, 密度测井的权重影响因子为9.8%, 中感应电阻率的权重影响因子为16.6%。 因此可见, 地层真电阻率是流体识别的最重要的影响因素, 余下测井曲线数据对随机森林识别流体模型的重要性从大到小依次为: 中感应电阻率、 自然电位、 声波、 密度测井、 自然伽马。地层真电阻率与中感应电阻率是评价储层含油性的指标, 声波时差与密度测井代表着孔隙空间, 自然电位与自然伽马则是反映了岩性, 其重要度与实际情况基本一致, 该结果提示在判别流体类型时应该多注意对地层电阻率以及自然电位和声波测井数据的收集与关注。
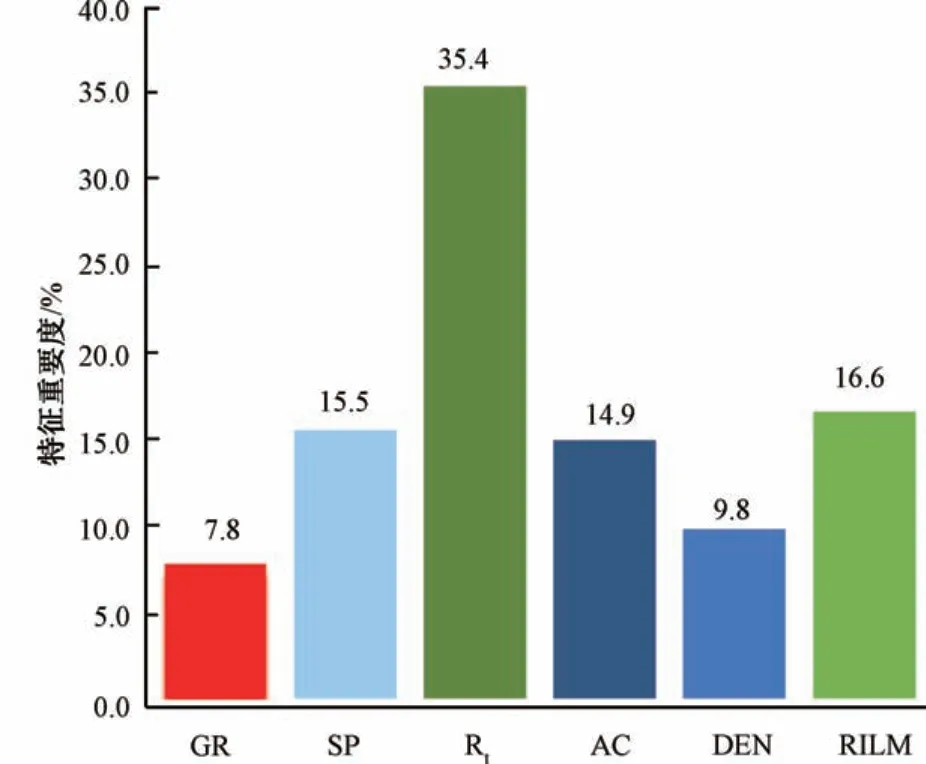
图5 输入特征重要性分析图Fig.5 Input feature importance analysis diagram
检验随机森林模型识别效果如图6, “1” 代表油层, “2” 代表油水同层, “3” 代表水层。 图中绿色为实际试油结论, 红色为随机森林模型预测储层油水情况。 预测结果与试油结论基本一致, 预测成功率较高, 模型正确率达90.47%。
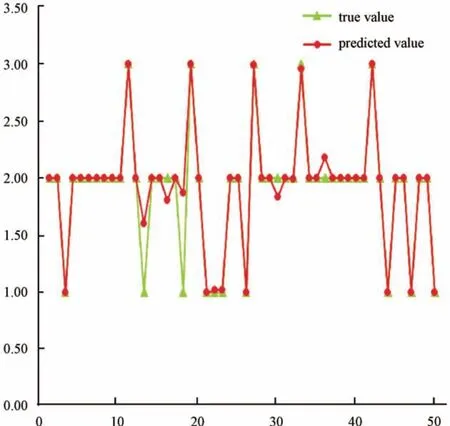
图6 随机森林模型检测图Fig.6 Random forest model detection map
3 结论
1) 常用流体识别方法在M 区块长3 低孔低渗储集层中并未取得较好识别效果, 可能是由于研究区储层包含低电阻率油层, 且径向电阻率曲线对比法识别流体性质仅关注了电阻率特征单一因素, 无法满足日趋复杂的实际流体情况, 导致应用效果差。 交会图版法可以基本准确识别出油层与水层差别, 但对于区分性质接近的水层与油水同层还需要进一步研究。
2) 基于常规测井数据对M 油田低孔低渗储层使用随机森林方法进行流体识别, 相较于径向电阻率法与交会图版法等传统地球物理解释方法无法融汇多信息的欠缺, 随机森林方法规避了只分析单一信息的的不足, 结果更加真实可靠, 准确率高, 且方法简便易于操作, 在研究区内取得了较好的识别效果。
3) 运用随机森林算法识别流体性质, 只是智能算法与地球物理科学结合解决地质问题中的一种方面, 但这一方法的实现为进一步针对低孔低渗储层特性实现智能算法解决其他地质问题提供了思路。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23
测井技术(2022年3期)2022-11-25
中国煤层气(2021年5期)2021-03-02
石油化工应用(2020年2期)2020-03-18
当代水产(2019年1期)2019-05-16
经济技术协作信息(2018年22期)2019-01-19
太空探索(2016年9期)2016-07-12
中国煤层气(2015年4期)2015-08-22
中国质量与标准导报(2015年2期)2015-02-28
石油地质与工程(2014年5期)2014-02-28
