
电网多源故障用电信息采集智能融合技术研究
2023-12-25 07:28彭葛桦
自动化仪表 2023年12期
彭葛桦
(1.国网江西省电力有限公司培训中心,江西 南昌 330006;2.江西电力职业技术学院供用电工程学院,江西 南昌 330032)
0 引言
随着智能电网规模的扩大和输出负荷量的提升[1],在运行过程中,电网难免会发生故障,如输电电线故障、变压器故障、母线故障等。这些故障发生后,电力系统中的负荷分布、线损情况等均会发生变化[2-3]。这会对用电信息的判断造成较大影响,使电力系统无法精准掌握用电需求,导致用电规划的合理性降低。因此,电力系统进行终端用电规划的关键在于有效地采集和管理电网故障下的用电信息[4]。数据融合是1种常用的信息处理方法。数据融合是将采集的多源信息进行联合处理[5],以获取更为全面、完整的信息。由于电力系统结构复杂,运行数据具有动态变化特性,并且电力系统在故障情况下所产生的信息具有一定的随机性和变化性[6],导致用电信息的融合效果较差。为实现信息的智能融合,文献[7]利用深度反向传播(back propagation,BP)神经网络的非线性学习能力,实现信息智能融合。但是在应用过程中,如果存在较多动态数据,则其融合误差较大。为实现多源数据的融合、避免发生数据之间的冲突,文献[8]基于差异信息量,提出相关多源数据融合方法,以实现多源数据的精准融合。但是该方法在应用过程中难以对数据中的异常数据进行处理。
为此,本文基于数据驱动、采用用电信息采集智能融合技术对电网多源故障展开研究。数据驱动是通过计算或者互联网等相关软件技术,对海量数据进行处理,以完成数据的整合和提炼。数据驱动在整合过程中以启发式规则为依据,能够建立数据之间的关联。其具有显著的自动化特点[9]。通过数据驱动对数据进行处理,能提升原始信息涵盖的内容,并且保证数据的融合质量。
1 多源故障用电信息采集智能融合
1.1 用电信息采集智能融合技术框架
本文针对电网多源故障用电信息的特点和采集需求,提出基于数据驱动的电网多源故障用电信息采集智能融合技术。电网多源故障用电信息采集智能融合技术框架如图1所示。

图1 电网多源故障用电信息采集智能融合技术框架
由图1可知,电网多源故障用电信息采集智能融合技术以数据驱动技术为核心,构建多源用电信息融合框架。该框架整体包含在线运行机制和离线运行机制这2个部分。
①在线运行机制。在线运行机制的主要作用是通过相关智能算法对用电数据实施分类,并完成特征提取。该机制能够结合多源数据的特性,较好地完成数据处理。
②离线运行机制。离线运行机制对应数据驱动引擎的模型操作策略调整功能。其主要是依据数据驱动实现多源数据的融合,并且对融合结果进行评价;依据评价结果调整融合策略,以确保最佳的融合效果。
1.2 数据驱动的在线运行机制
1.2.1 多源用电信息分类
电网中智能终端的用电信息在采集和传输过程中,会存在数据部分丢失或者损坏的情况[10]。除此之外,终端用户的用电习惯等存在一定差异。用电采集过程中,获取的数据有静态和动态这2种,并且数据的分布呈现不平衡状态。因此,在进行多源用电信息融合时,需先通过在线机制对用电信息进行分类处理。本文将先验知识和深度玻尔兹曼机(deep Boltzmann machine,DBM)相结合,形成基于先验知识和DBM的采样模型,并依据该模型完成多源用电信息分类。多源用电信息分类模型结构如图2所示。

图2 多源用电信息分类模型结构
图2所示的多源用电信息分类模型以从电网侧采集到的原始用电数据为基础,在完成对数据的初步筛选后,对其中的小样本数据执行采样以及复制这2种处理。在此基础上,模型通过DBM网络对小样本数据执行解耦和编码处理,从而建立编码数据集。复制处理主要是通过DBM网络对新数据进行编码处理后,对该数据和原始数据进行纵向拼接操作,以获取用电的扩充数据[11]。本文依据该数据进行极限学习机网络的训练,以实现用电数据的分类处理。
本文设原始数据为D=[d1,d2,…,d48]∈R1×48、第i个采集点采集的用电数据为di、数据行向之间的相关系数矩阵为R、DBM网络的可视层节点数量为48。本文对D进行筛选处理,在获取其中的小样本数据后,将获取的采样数据用Ds表示。D和Ds通过DBM网络进行训练学习后,输出分别为Dt和Dst。两者具有相同的维度,并且耦合度较低。采用纵向拼接的方式对两者进行处理,可获取D的采样数据结果DST。
(1)
多源用电信息分类详细步骤如下。
①在获取D的训练样本后对样本实施归一化处理,得到其中的小样本数据。
②将小样本数据输入DBM网络,通过该网络的学习和训练,输出用于测试的数据DS。依据该数据进行极限学习机网络的训练,可实现用电数据分类,并形成静态数据集和动态数据集。
1.2.2 多源数据特征提取
通过上述步骤完成多源用电信息的分类处理后,本文对静态和动态这2种数据集进行特征提取。本文通过数据驱动的互信息原理完成特征提取。
互信息用于描述2个随机变量之间的相关性。本文令X、Y分别表示静态数据集和动态数据集。两者之间的互信息计算式为:
(2)
式中:p(x,y)为X和Y之间的联合概率密度函数;p(x)和p(y)均为边缘概率密度函数,分别对应X和Y。
本文基于互信息提取X和Y的特征量。提取结果为:
(3)
式中:X0为初始特征量;X′为维度为m的特征量。
依据式(3)即可获取最大化的互信息结果,从而在保证类别不发生变化的基础上完成特征选择。本文为保证互信息的最大化,采用分解的方式对多维互信息进行处理,以形成一维互信息。I(X,Y)的计算式为:
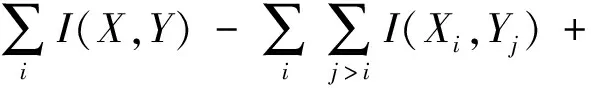
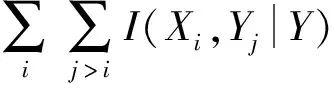
(4)
式中:Xi与Yj为X和Y数据集的已选特征。
本文在式(2)~式(4)的基础上,实现用电信息特征集的快速提取。
初始变量选择为:
(5)
第二变量选择为:

(6)
依据式(5)和式(6)即可完成剩余变量的选择。每次选择依据互信息最大的原则进行下一个特征的选择;在进行选择时,设定阈值N。当循环次数达到该阈值时选择停止。通过本文技术获取的特征集具有特征信息完整、特征的类别不会发生改变的优点。
1.3 用电信息融合处理
本文通过1.2节完成多源用电信息特征集提取后,依据数据驱动技术,通过离线机制获取特征集,从而进行用电信息的一致性融合。
用电信息的采集是通过多源采集方式完成的。该方式采集的信息具有明显的冗余特点[12]。因此,提取的特征集也存在一定的冗余特征。本文为保证较好的用电信息融合效果,对提取的特征集进行汇总,使其均位于源节点内,并通过卡尔曼滤波算法对特征集中的冗余特征进行处理,在此基础上完成用电数据的一致性融合。用电数据的融合方法结构如图3所示。
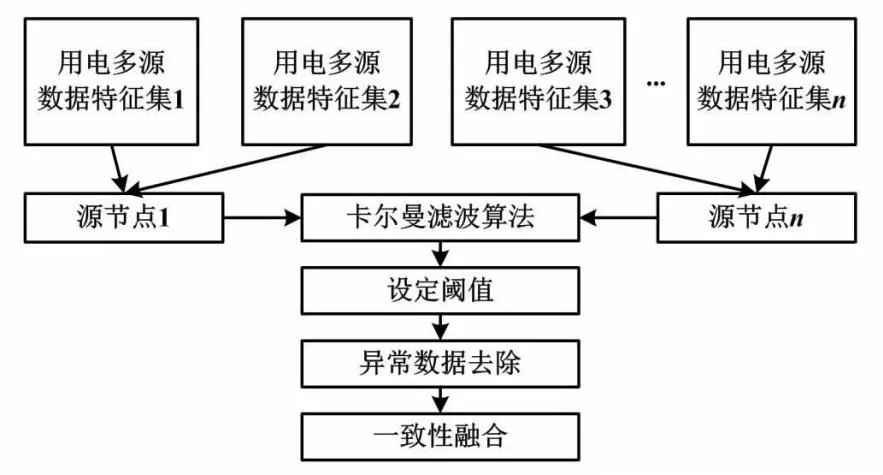
图3 用电数据的融合方法结构
本文将提取的多源特征集均汇集至源节点,采用卡尔曼滤波方法去除特征集中的冗余信息。以X′类特征集为例,使用卡尔曼滤波对特征集进行处理时,在(t+1)时刻的滤波计算式为:
xt+1=Ftxt+Γtwt
(7)
式中:Ft为卡尔曼滤波系数;Γt为Ft的加权平均值;wt为权重比例。

(8)
式中:E为最优期望函数;γ为所有用电信息特征之和。
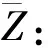
(9)
式中:n为特征数量。
本文采用εq和ξ(z)表示用电数据集合中的任意误差和标准差。
(10)
(11)
依据εq和ζ(z)的计算结果即可获取用电信息特征数据的分布规律,从而可在融合过程中删除其中异常特征数据,并进行一致性融合。此时,每个源节点的测量值满足正态分布规律。本文在融合过程中引入融合节点支持程度理念。如果节点p对节点q的支持程度用Ψqp表示,则有:
(12)
式中:ξqp为节点p和节点q之间的标准差。
以此确定的融合节点之间的支持度关系矩阵ΨN×N为:
(13)
本文依据融合节点之间的ΨN×N结果实现用电信息的一致性特征描述,从而完成用电信息融合。
2 测试分析
为验证基于数据驱动的电网多源故障用电信息采集智能融合技术的应用效果,本文选择某电力企业采集的电网侧420个用电终端的数据作为试验测试数据。该数据的采集时间间隔为0.5 h、连续采集时间为7 d。该数据中包含用电终端的动态和静态2种数据。
试验参数设定如下:DBM网络隐含层节点数量为30个;分类器的节点数量为60个;学习率为0.001。
为验证本文技术对于多源用电信息的分类效果,本文采用戴维森堡丁指数(Davies-Bouldin index,DBI)作为评价指标。该指标可以反映数据之间的的紧密程度。其取值范围为[0,1]。数值越小,表示聚类效果越好。DBI的计算式为:
(14)

在不同的数据维度下,本文依据式(14)计算应用本文技术后的DBI指标测试结果。
通电信息分类性能测试结果如表1所示。

表1 通电信息分类性能测试结果
由表1可知:在不同的数据维度下,随着数据数量的逐渐增加,通过本文技术进行用电信息分类后,DBI的测试结果均在0.017及以下。因此,本文技术具有较好的用电数据分类性能,能够可靠完成用电数据的分类。
为了进一步分析本文技术的数据分类效果,测试采用本文技术对采集的用电信息进行分类处理后,获取数据的分类结果。该结果通过二维空间进行呈现。用电信息分类结果如图4所示。
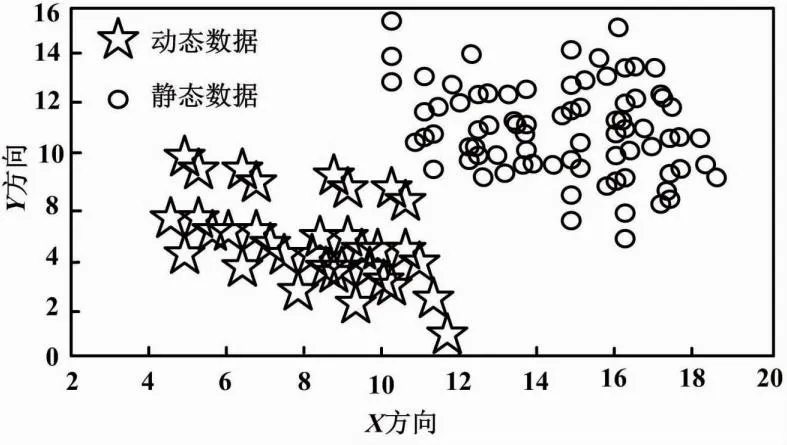
图4 用电信息分类结果
由图4可知:应用本文技术后,能够在二维空间内对动态数据和静态数据进行有效分类,并且类别之间的界线显著,没有发生重叠以及错误分类情况。因此,本文技术的用电数据分类效果良好。
本文技术在进行用电数据融合的过程中,对数据进行异常数据处理。处理效果直接影响数据的融合结果。因此,本文将变异系数λ作为测试指标,以衡量经本文技术处理后数据的离散程度。λ的计算式为:
(15)

λ的数值越大,表示数据的离散程度越高,说明数据特征处理效果越差。其取值范围在0~1之间。
依据式(15)计算本文技术应用前后在不同的数据残差率下的λ计算结果。异常数据处理效果测试结果如表2所示。
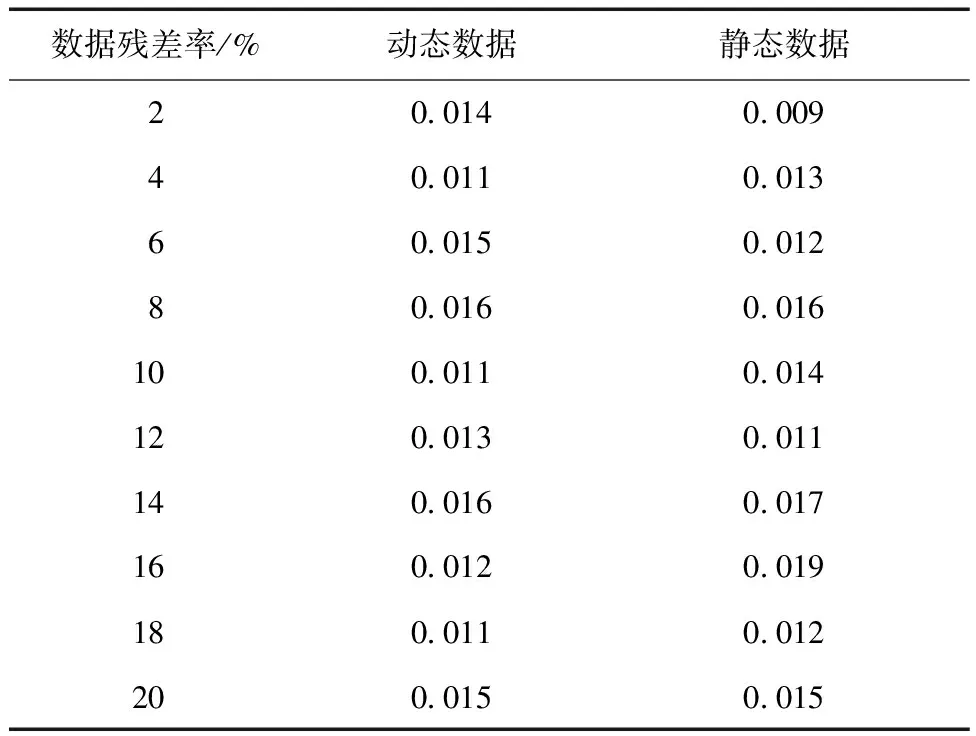
表2 异常数据处理效果测试结果
由表2可知:随着数据残差率的逐渐增加,本文技术对动态数据和静态数据进行异常处理后,λ的计算结果均在0.020以下。其中,最大值为0.019。这是由于本文技术在进行异常用电数据处理时,依据用电数据集合中的任意误差和标准差完成数据处理。这样可保证较好的处理效果。
为验证本文技术的应用性,测试采用本文技术对用电信息进行融合处理后,依据处理后的用电信息对电网正常运行和故障运行这2种情况下的用电需求进行预测,并获取其分析结果。
用户用电需求预测结果如图5所示。由图5可知:随着用电用户数量的逐渐增加,在电网正常运行和故障运行这2种情况下,均可依据本文的用电信息融合结果完成用电需求的预测,并且预测结果与实际需求结果吻合程度较高。这为电网的能源规划提供可靠依据。
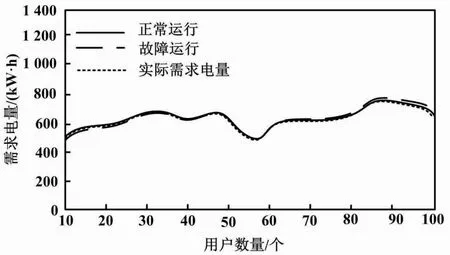
图5 用户用电需求预测结果
为进一步验证本文技术的应用性,测试根据本文技术的用电信息融合结果,对异常用电进行识别,从而获取电网中异常用电的识别结果。异常用电识别结果如图6所示。
由图6可知:依据本文技术融合的用电信息,能够完成终端用户用电量的统计,并且获取统计结果中的异常用电结果。凌晨5:00属于用电低谷时刻,但却产生较大的用电量。18:00属于用电高峰时刻,却出现用电量下降情况。因此可判定这2个时刻属于异常用电时刻,从而实现对异常用电的识别。该结果证明本文技术具有较好的应用性。融合后用电信息能够为电网的用电规划以及窃电监测提供可靠依据。
3 结论
电网的用电信息对于电网用电规划、窃电监测、用电需求预测等均具有重要意义。用电信息在采集过程中具有显著的时间序列特征,并且会受到电网运行状态的影响。因此,本文提出基于数据驱动的电网多源故障用电信息采集智能融合技术。本文对该技术的应用效果展开相关测试。测试结果显示:本文所研究的融合技术具有较好的用电信息融合效果,并且在融合过程中能够有效处理信息中的冗余数据和异常数据;依据融合后的用电信息可精准预测用户的用电需求以及识别异常用电行为,应用性良好。
猜你喜欢
经营者(2023年10期)2023-11-02
数学大王·趣味逻辑(2021年11期)2021-12-03
数学小灵通(1-2年级)(2021年4期)2021-06-09
中国化肥信息(2021年12期)2021-04-19
中学生数理化·中考版(2020年12期)2021-01-18
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
小学生必读(中年级版)(2018年10期)2019-01-04
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
河南电力(2016年5期)2016-02-06
