
基于自然语言处理技术的知识图谱构造方法研究
2023-12-22 09:29马永强
集宁师范学院学报 2023年5期
孙 伟 李 一 马永强
(集宁师范学院 计算机与大数据学院,内蒙古 乌兰察布 012000)
1 引言
智慧旅游可以为我区旅游高质量发展提供强有力的抓手。智慧旅游从游客出发,通过大数据技术融合旅游业上下游产业数据为用户提供个性化的旅行线路推荐、旅游产品预订支付和回顾评价;智慧旅游还可以通过旅游舆情监控和数据分析,挖掘旅游热点和游客兴趣点,引导旅游企业策划对应的旅游产品,制定对应的营销主题,从而推动旅游行业的产品创新和营销创新。个性化旅游推荐是智慧旅游的重要应用场景,但传统的个性化旅游推荐算法存在数据稀疏和冷启动等问题。知识图谱是结构化的语义知识库,以符号形式描述物理世界中的概念及其相互关系。知识图谱技术为解决传统旅游推荐中存在的问题提供了新的可能。知识图谱可以通过实体之间的语意信息有效地解决传统个性化推荐算法中存在的数据稀疏和冷启动等问题,为游客提供精准的个性化旅游线路推荐服务,提升旅游体验和旅游品质;同时建设旅游知识图谱还能融合旅游产业数据为智慧旅游平台提供数据基础,助力我区旅游产业高质量发展。
2 旅游知识图谱构造思路
知识图谱构造的主要任务包括:数据采集、命名实体识别、关系抽取数据融合等任务。本研究从主流旅游网站上通过网络爬虫获取内蒙古旅游景点的基本信息、游客游记以及游客评论信息作为研究数据来源。首先,项目组对原始数据进行数据清洗形成原始语料。然后,从原始语料识别命名实体。之后,从标注实体信息的语料中抽取实体之间的关系。最后,构建和表示内蒙古旅游知识图谱。内蒙古旅游知识图谱包括:景点知识图谱和旅行知识图谱,前者以实体为中心,体现了旅游景点的静态特征(如位置、面积、项目等),数据为形如“实体—关系—实体”或者“实体—关系—属性”的实体三元组;后者以事务为中心,反映了游客在旅行中的行为(如时间、景点、活动等),数据为形如“时间—景点—活动”的事务三元组。将景点知识图谱和旅行知识图谱进行融合,存储在图数据库中。内蒙古旅游知识图谱的构建及融合过程如图1 所示:
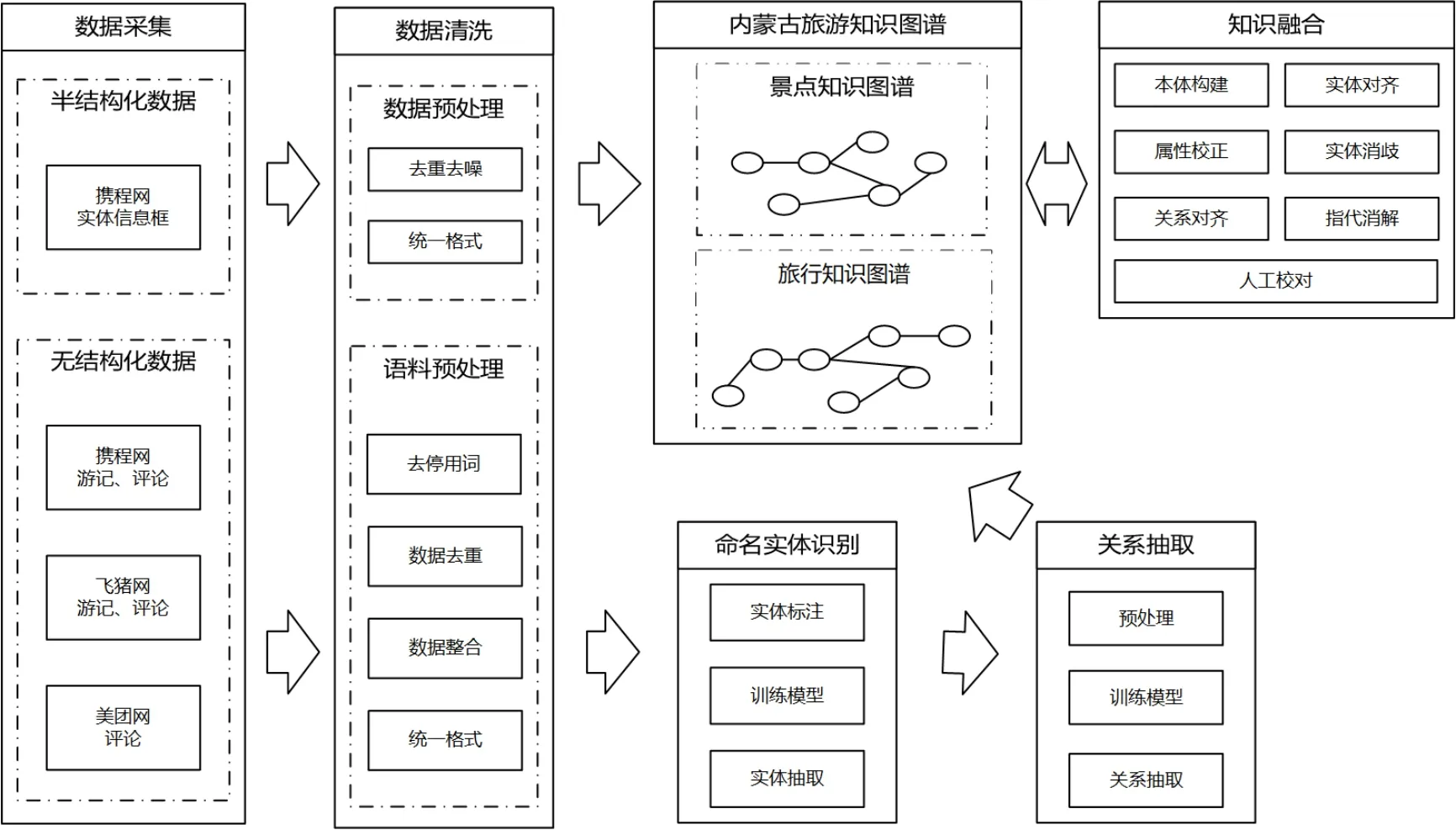
图1 知识图谱构造及融合过程研究框架图
3 数据准备
数据采集主要通过网络爬虫工具从主流旅游网站获取内蒙古旅游景点的基本信息、游客游记以及游客评论信息。数据采集分为半结构化数据采集和无结构化采集。半结构化数据采集的数据源是携程网旅游实体页面中的旅游实体信息框、旅游实体详情栏、酒店房型价格框等半结构数据,抽取出来的半结构化数据经过去重噪、统一格式后映射为高质量的RDF 三元组文件。无结构化数据采集的数据源是携程网、飞猪网、美团等在线旅游网站的游记和评论数据。被抽取出的无结构信息经过去停用词、数据去重、数据整合、统一格式后形成原始语料数据。下面以半结构化数据采集过程为例说明数据采集过程,具体流程如图2 所示:

图2 数据采集过程图
4 命名实体识别
命名实体识别的任务是从原始语料中标注景点、游客、活动等实体信息,采取的标注方法是 BIO标注,将文本中的每个元素标注为“B-X”、“I-X”或者“O”,其中“B-X”表示某类命名实体的开始位置,“I-X”表示某类命名实体中间某一个位置,“O”表示该元素不属于一个实体。例如一条原始语料句子为“我喜欢在内蒙古的草原上骑马”,对其中的每个字都行进BIO 标注,标注结果为[我_O,喜_O,欢_O,在_O,内_ B-Loc,蒙_ I- Loc,古_ I- Loc,的_O,草_ B-Scenic,原_ I- Scenic,上_O,骑_ B- Activities,马_I- Activities]
命名实体识别的任务是从原始语料中标注景点、游客、活动等实体信息,采用目前比较流行的BERT+BiLSTM+CRF 作为命名实体识别模型,该方案有较高的识别准确性,可以为后续的工作提供有力的保障。命名实体识别任务主要分为三个步骤:第一步是词嵌入,使用BERT 模型进行预训练获得原始语料的词向量;第二步是特征编码,使用BiLSTM 网络对词向量做变换,得到每一个词属于不同标签的概率;第三步是解码过程,使用CRF 模型通过转移矩阵结合上下文信息得到词性标注序列。命名实体识别研究方法框架如图3 所示:

图3 命名实体识别研究方法框架图
对于任意标签序列y=y1,y2,…,yt,标签序列分数公式为:
对于任意标签序列y=y1,y2,…,yt,标签序列概率公式为:
正确标注序列最大对数似然概率公式可以表示为:
命名实体识别公式可以表示为:
5 关系抽取
关系抽取任务可以看作一个多分类任务,实现对景点、时间、活动等实体之间的关系进行抽取。关系抽取首先需要将标记过实体的语料处理为<实体 1,实体 2,句子>的结构,然后通过模型计算出两个实体间可能性最大的关系类型作为两个实体之间的关系。例如,一条文本语料<乌兰察布市,四子王旗,四子王旗是乌兰察布市面积最大的旗县>,对其进行关系抽取后,结果是实体乌兰察布市与实体四子王旗之间的关系为包含。
关系抽取采用BERT+BiGRU+Attention 作为任务模型,具体过程包含五个步骤:第一步数据预处理,将实体标注后的语料预处理为包含实体关系的句子形式;第二步词嵌入,使用BERT 模型进行预训练获得预处理语料的词向量;第三步获取句子特征向量,使用BiGRU 获取含有上下文语义信息的原始句子特征向量。第四步特征向量加权,使用注意力机制为原始句子特征向量赋予不同的权重;第五步关系分类,通过sofrmax函数选取概率值最大的向量对应的关系作为输出结果。关系抽取研究方法框架如图4 所示:

图4 关系抽取研究方法框架图
GRU 网络相关公式为:
Attention 相关公式为:
关系分类公式可以表示为:
6 结语
自然语言处理技术在内蒙古旅游知识图谱建设中的成功应用很好地解决了传统知识图谱构造中存在的问题,提高了命名实体识别和关系抽取的准确率,为内蒙古智慧旅游发展提供了新的思路。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
计算机教育(2020年5期)2020-07-24
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
计算机工程(2015年8期)2015-07-03
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
