
一种基于双通道的水下图像增强卷积神经网络
2023-12-21 09:57王树林杨建民卢昌宇刘路平
海洋工程 2023年6期
王树林,杨建民,卢昌宇,刘路平
(1.上海交通大学 海洋工程国家重点实验室,上海 200240;2.上海交通大学 三亚崖州湾深海科技研究院,海南 三亚 572024)
深海中的生物种类十分丰富,是人类可持续发展的宝贵资源。随着陆地上的资源日渐枯竭,合理保护和利用海洋生物资源显得尤为重要[1],对这些生物的生存环境进行监测是保护他们的重要方式之一。因此,研究能够进行海洋生物环境监测的水下机器人[2]格外重要。而复杂多变的海洋环境给水下机器人的视觉感知带来了困难[3]。尽管这类机器人使用了高端相机,但是所拍摄到的海底图片带有非线性噪声,导致图片呈现蓝绿色,结果模糊不清。因此,研究可靠的水下图像增强技术显得尤为重要。水下图像增强方法包含有无水下成像模型的水下图像增强方法、基于水下成像模型的水下图像恢复方法、水下成像模型与深度学习相结合的方法以及完全采用深度学习的方法。
无水下成像模型的方法主要分为图像的空间域处理和变换域处理。水下图像的空间域处理可以通过改变像素的值和分布等方式改善水下图像的视觉效果。直方图均衡及其改进算法[4]就是将图像进行像素强度上的重新分布,使水下图像具有更大的动态范围。虽然某种程度上提高了图像的对比度和颜色丰富度,但是容易产生颜色失真和伪晕。Ancuti 等[5]通过不同的方法增强图像的特征,最后通过图像融合的方法来提高水下图像的质量,然而没有考虑水下的成像原理,有一定的局限性。变换域增强算法主要是利用傅里叶变换、小波变换等方法,将水下图像进行变换,在变换域中抑制噪声。例如Khan等[6]提出了一种基于小波的融合方法来改善水下模糊图像的低对比度和颜色变化问题,但是放大了噪声,出现颜色失真现象。
基于水下成像模型的方法多是借鉴大气散射模型。常见的方法是:结合已有的先验知识和成像模型估计通道的衰减系数,然后代入成像模型反求出恢复后的图像。例如基于单幅图像的水下深度估计与图像恢复[7]、水下单幅图像的透射估计[8]、红通道先验[9]和水下光衰减先验[10]等方法。然而先验知识有限,所依赖的模型也不是精确的水下成像模型,应用场景有限。后面Akkaynak 和Treibitz[11]试验研究发现,之前的水下成像模型忽略了一些重要部分,因而提出了修正的水下模型。但是新模型本身较复杂,很少受到关注[12]。
水下成像模型与深度学习相结合的方法是通过深度学习的方法来近似估计水下成像模型中的主要参数。Chen 等[13]通过建立深度学习网络分别对R、G、B 三通道中的水下成像模型参数进行估计,并在成像模型的基础上搭建前向传播网络,获得了一定的效果,但是网络对模型做了简化,有一定的局限。
近年来,深度卷积神经网络在图像领域大放异彩,在很多图像任务中取得了令人满意的效果,在水下图像增强任务中也取得了不错的效果。Li等[14]收集了一个包含950 张真实世界水下图像数据集,并提出了一个多输入单输出的门控水下增强网络WaterNet,Liu等[15]提出基于残差结构的水下增强网络UResnet,Fabbri等[16]提出了一种生成对抗网络来改善水下图像的视觉效果和质量。这些基于深度学习的方法都在网络结构上有各自的特点,取得了一些水下图像增强效果。
在深度学习的方法中,数据集的多场景化和大小、网络结构、损失函数、训练策略的选择是优化的主要内容。文中主要在网络结构以及损失函数方面进行考量,建立了一种基于双通道的水下图像增强卷积神经网络。区别于其他基于深度学习网络的是,编码器模块采用双通道结构:细节特征提取通道和语义特征提取通道。细节特征提取通道中的密集连接后又引入高效注意力机制,使网络自适应关注特征的权重。语义特征提取通道采用多尺度结构。网络引入了残差注意力模块和自适应融合模块,既弥补了网络在前期传播过程中原始信息的丢失,又对特征进行了优化。此外,文中将像素损失、感知损失与复频域损失相结合进行网络的训练,取得了良好的效果。试验表明:此网络显著改善了水下图像质量。
1 模型介绍
这里主要讨论基于双通道的水下图像增强卷积神经网络模型的主要结构、损失函数、激活函数等的选取。模型主要结构如图1 所示:输入是原始水下图像,输出是增强后的图像。编码器模块是双通道结构:水下图像细节提取模块和水下图像高层语义提取模块。细节提取模块分为两个模块:密集连接模块和高效注意力模块。高层语义提取模块就是多尺度高层语义提取模块。然后,引入了残差注意力模块和自适应融合模块优化特征,将优化后的特征送入解码器进行清晰图像的重建。解码器采用卷积激活串联结构。

图1 模型主要结构Fig.1 Main structure of the model
1.1 密集连接块
密集连接是2017 年Huang 等[17]提出的一种全新网络连接方式。为了最大化网络中所有卷积模块和相关层之间的信息流,将所有卷积模块两两之间都进行了连接,使得网络中的每个模块都接受其前面所有层的特征作为输入。由于网络中存在大量密集的连接,故将这种网络结构称为DenseNet。这里提出的结构吸取了其主要思路,各个卷积模块之间采用密集连接的方式,这样既实现了前面卷积模块提取出来特征的复用,而且一定程度上减轻在训练过程中梯度消失的问题。每一个卷积块都会提取到图像的细节特征,这些细节特征在网络的后向传播中,由于采用密集连接的方式,并不会被丢弃,而会被不断地重复利用,使得每一个卷积块都可以发挥最高效的作用,可以全方面有效提取水下图像的细节特征。采取的密集连接块如图2所示。一共包含4个提取细节特征的卷积块,每个卷积块的结构如图3所示。具体参数如表1所示。
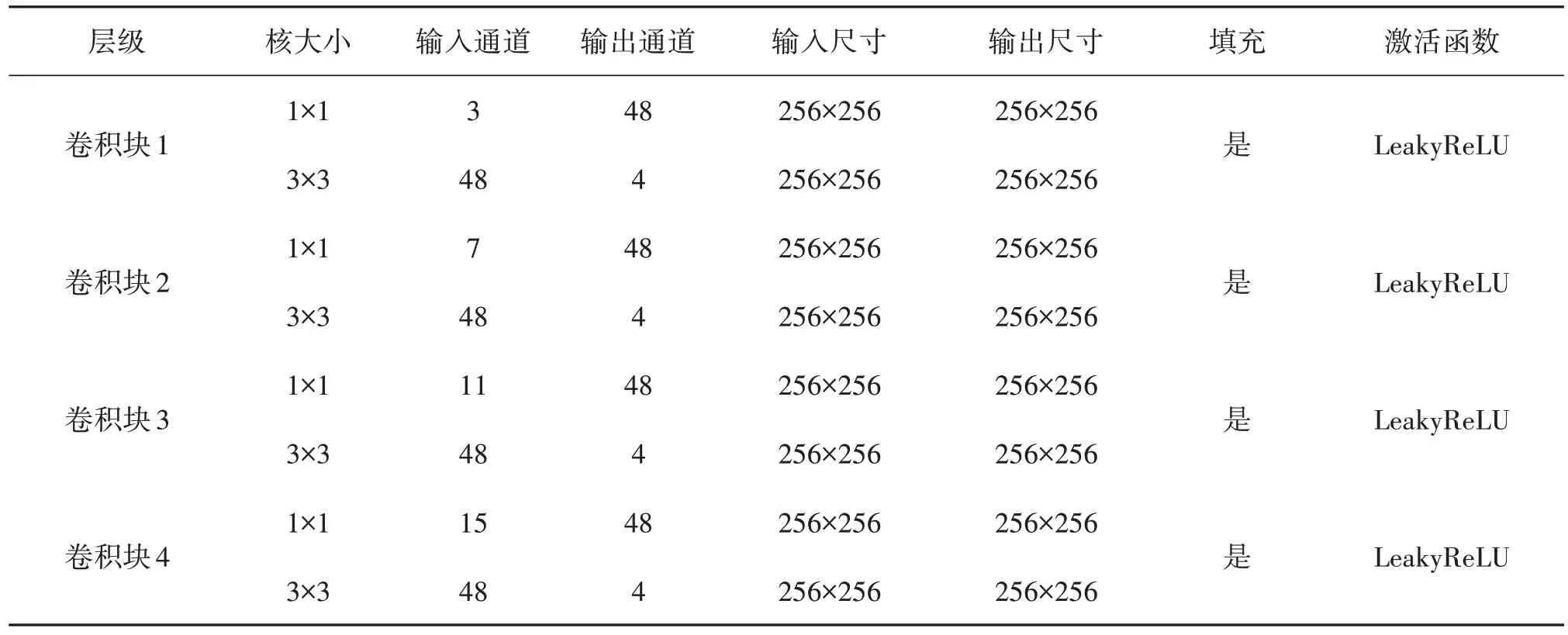
表1 密集连接模块主要网络参数Tab.1 Main network parameters of dense connection module

图2 密集连接块Fig.2 Dense connection block
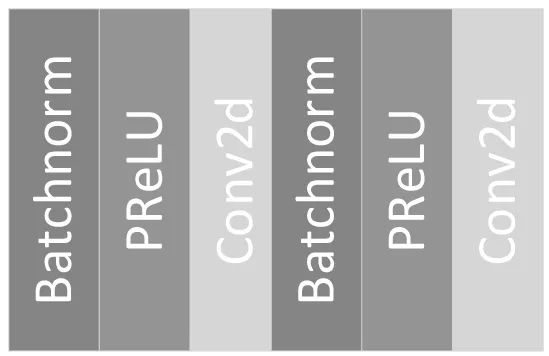
图3 卷积块结构Fig.3 Convolution block structure
1.2 高效通道注意力机制模块
注意力机制是深度学习中改善模型提取特征的一种优化方法,其实现形式多种多样,采用高效通道注意力机制,让网络在优化的过程中,自适应地关注密集连接网络提取的不同特征的权重,从而更好地提取水下图像的细节特征。采用2020年Wang等[18]提出的高效通道注意力模块,该模块避免了降维,有效实现了跨通道交互。具体细节如图4所示,其中H、W分别为特征的高度和宽度。通过卷积激活操作将密集连接的输出19通道转换为64通道,故高效通道注意力模块的输入通道也为64。该输入特征经过全局平均池化,得到每个特征的池化值,然后采用式(1)计算出一维卷积核大小为3。
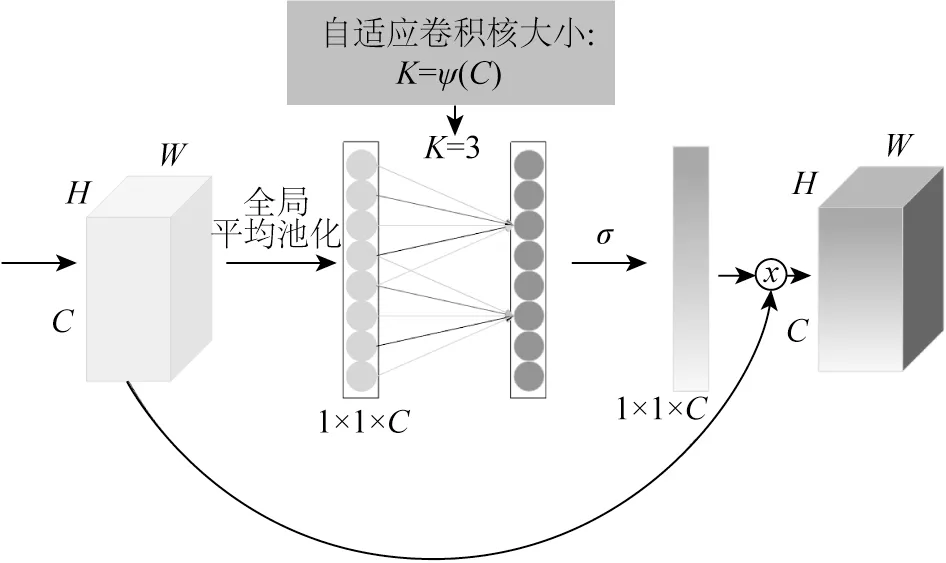
图4 高效通道注意力Fig.4 High efficient channel attention
其中,C为输入的通道数,K为一维卷积核大小,取最近邻的奇数。
通过该卷积核在1×1×64的特征上滑动,得到具有跨通道特点的新的相同维度特征,然后经过Sigmoid函数σ将特征的大小映射到0到1之间,最后与原始特征进行相乘,得到带有权重的高效通道注意力特征。所以高效通道注意力机制网络的输出为:
其中,Fc为通道注意力前一阶段输出第c通道的特征,Fc(1)表示通道注意力模块的输出;AvgPool 为平均池化操作,参数为1;Conv1d为一维卷积,参数为:输入通道数1,输出通道数1,核大小为3,没有偏置参数;σ表示Sigmoid激活函数。
1.3 多尺度高层语义提取块
解码器中的第2个通道分支多尺度高层语义提取模块如图5所示。
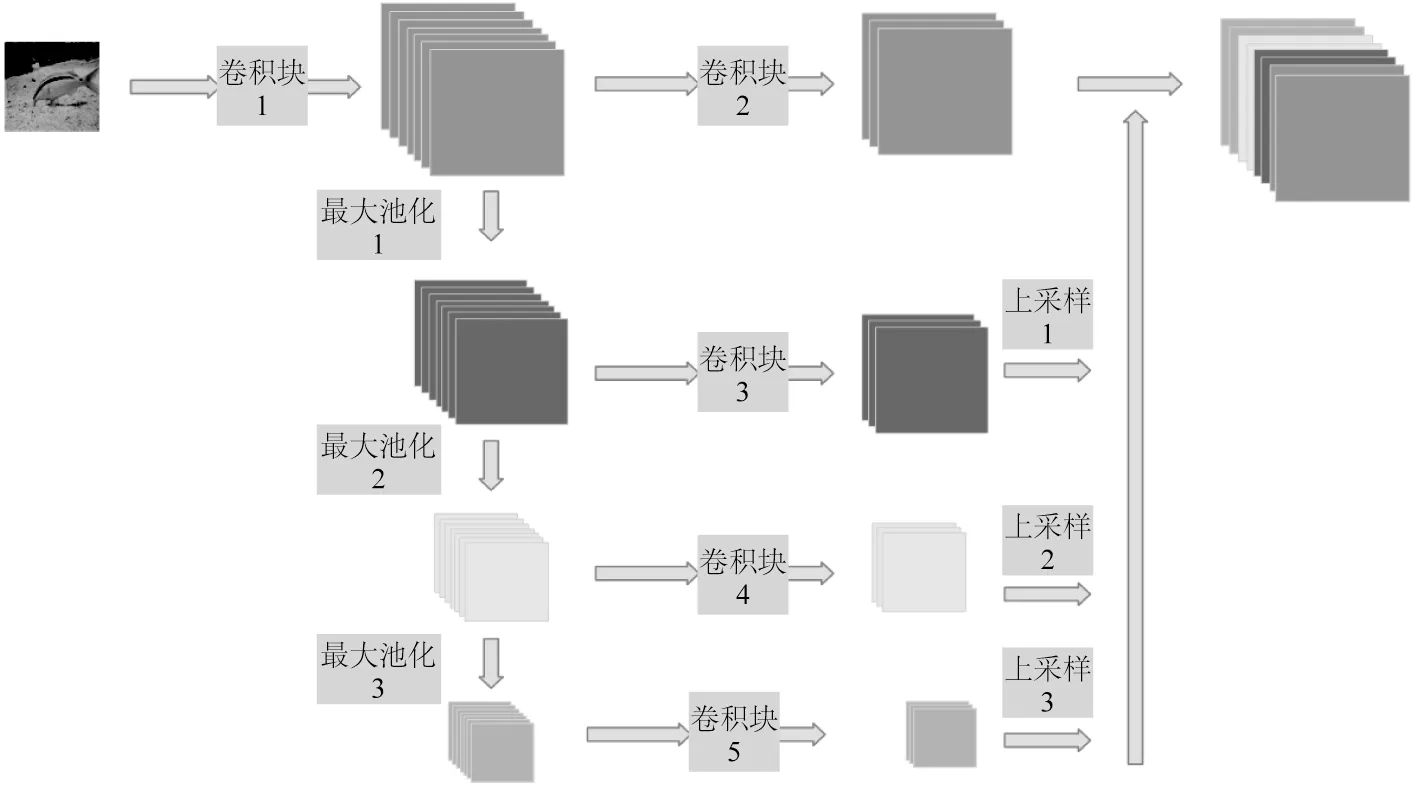
图5 多尺度高层语义提取块Fig.5 Multi-scale high-level semantic extraction blocks
原始水下图像首先经过卷积激活操作得到64个通道的特征图,然后经过3次下采样(池化)操作得到不同尺度大小的特征图,经过下采样后的特征丢失了大量的细节信息,每个尺度的特征接着经过卷积激活操作进行特征通道数的转换,既丰富了深度语义信息的提取,又方便了上采样操作后特征的融合,最后将不同尺度的特征在通道维度拼接,得到带有高层语义特征的一组特征图。具体操作细节如表2 所示。图5 中上采样1、上采样2和上采样3的尺度因子分别为2、4、8。
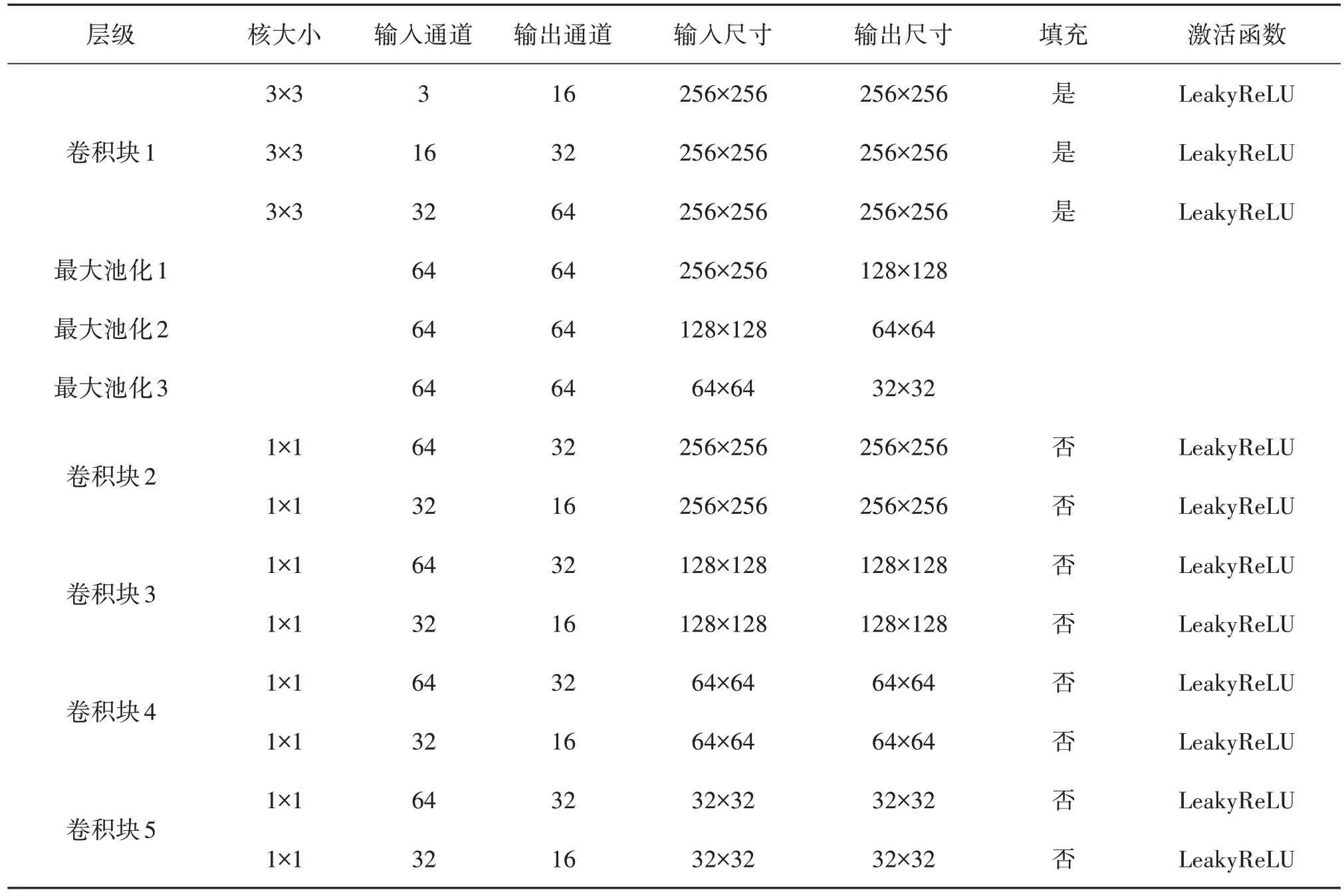
表2 多尺度语义提取块网络参数Tab.2 Multi⁃scale semantic extraction of block network parameters
1.4 残差注意力模块和自适应融合模块
残差注意力模块[19]和自适应融合模块分别如图6和图7所示。网络前期特征提取的水下图像特征Fin进入残差注意力模块,经过卷积2后,特征数量从64转换为3,接着与原始水下图像进行像素上的叠加,弥补了前期网络在传播过程中丢失的水下图像原始信息,输出y1一方面会流入图7 所示的自适应融合模块进行特征的融合,另一方面会流向卷积3 和激活(Sigmoid)得到带有权重的特征图,该特征图和前期提取特征Fin进行叠加,得到优化后的输出特征图y2(Fout)。
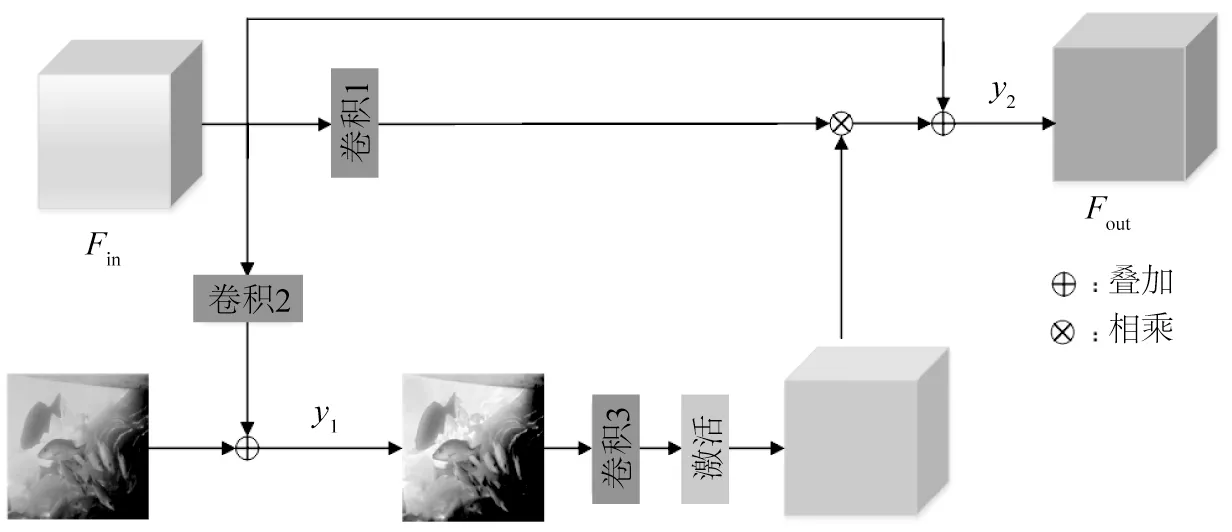
图6 残差注意力模块Fig.6 Residual attention module
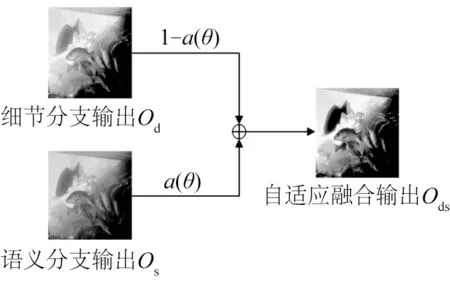
图7 自适应融合模块Fig.7 Adaptive fusion module
如图7所示,细节分支输出为Od,多尺度语义分支输出为Os,a(θ)为特征的自适应权重参数,自适应融合输出为Ods。则输出Ods表示为:
1.5 激活函数的选取
常见的激活函数主要有修正线性单元(ReLU)、带参数的修正线性单元(LeakyReLU)和Sigmoid 函数(图5中的σ),如式(4)~(6)所示。
其中,x代表特征图上任意点的位置,a是可以学习的参数。采用带参数的修正线性单元(LeakyReLU),可以避免当x为负数时,梯度为0,相应参数无法被更新的现象发生。注意力机制中权重特征图的计算采用Sigmoid函数。
1.6 损失函数介绍
一般情况下,输入一幅图像经过增强网络转换成另一幅图像,往往以监督训练的方式,利用的就是图像像素之间的误差。高质量的图像可以通过定义和优化感知损失函数[20]来生成,该损失函数是基于预训练好的网络提供的高层次特征。然而上述损失函数特征图均为实数,难以捕捉图像复频域之间的差距。利用图像的快速傅里叶变换,得到图像在复频域中的特征图,然后定义了两幅图像之间的复频域损失,并结合均方差损失、感知损失来训练搭建的双通道水下自编码器图像增强网络。
1)均方差损失:用来计算被增强后的图像I和清晰的真实图像I*之间像素层面的均方差。

3)图像的复频域损失:用来计算被增强后的图像I和清晰的真实图像I*分别经过快速傅里叶变换后所提取的复频域特征之间的损失。
假设通过网络后输出图像I的快速傅里叶变换后复频域矩阵为A,真实值图像I*的快速傅里叶变换后复频域矩阵为B。令A-B=C,cij表示复频域矩阵C中的元素。则图像的复频域损失定义为:
其中,Lfft表示复频域损失,0 ≤i,j≤N- 1,且取遍0到N-1之间所有整数,cij*表示cij的共轭复数。
采用的总损失函数为:
其中,λ1、λ2、λ3为平衡参数,主要是为了平衡各个损失之间的数量级大小,加速网络的收敛。
2 试验结果与分析
为验证文中所提出的水下增强网络算法的有效性,设计并进行了对比试验。试验使用PyTorch 深度学习框架搭建网络模型、数据处理模块、训练模块和测试模块,所使用的计算机基本配置为Intel i7-CPU、64GB RAM 和NVIDIA GeForce RTX 2060 GPU。深度学习网络训练过程中使用的批尺寸为2。开始训练前,将图像大小统一到256×256,并对数据进行增强以提高网络的泛化能力。试验中的数据集为UIEB 数据集[14],该数据集收集了大量真实水下场景中拍摄到的图像,一共890 对,选取该数据集挑战集中60 张留做训练好的模型的测试集。训练网络模型参数过程中训练集和验证集的比为7∶3,训练过程中的网络损失函数优化如图8 所示,损失函数值在训练过程中虽然有小幅度波动,但总体在减少,说明增强图像正在逐步逼近真实水下图像,没有出现梯度爆炸导致损失值突增的现象,网络结构具有一定的可靠性。
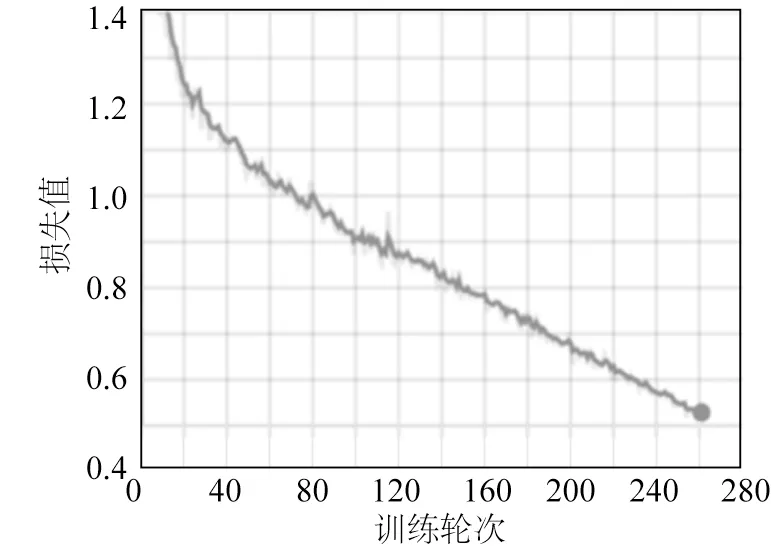
图8 损失函数值随训练次数的变化Fig.8 Change of loss function value with training times
这里从主观视觉效果、客观图像评价指标对文中的水下图像增强网络进行效果评价,选取用来对比的算法分别为水下光衰弱先验ULAP[10],相对全局直方图延展算法RGHS[21],融合深度学习与成像模型的水下图像增强网络算法(ModelCNN)[13],以及完全采用深度学习方法的ShallowUWNet[22]。此外,在训练数据集UIEB[14]上得到的模型也在EUVP[23]数据集上进行了测试,以验证文中提出的水下增强网络的可迁移能力。接着,对网络的速度做了相应的分析。最后,为了验证文中提出的基于图像快速傅里叶变换的复频域损失和网络中各个主要模块的作用,做了相应的消融试验。
2.1 视觉效果分析
在进行主观视觉效果分析时,文中方法与上述算法进行对比,对比结果如图9 所示。选取UIEB 挑战集中的6 张图片做对比,第1 列为原始水下图像,后5 列分别是经过上述算法处理后的结果。从图9 最后一列可以看出文中的双通道水下图像增强网络对于暗淡的水下图像具有较好的增强效果,提升了原始图像的对比度、清晰度的同时,对色偏也进行了一定的校正,改善了视觉效果。第4 行和第5 行虽然与其他图片有不同的背景噪声,但是文中算法都有效地去除了。而水下光衰弱先验ULAP 算法[10]对背景噪声没有很好地去除。全局直方图延展算法RGHS[21]处理过的结果虽然对偏绿色的噪声有较好的改善,但是出现了颜色失真现象,而且从第4 行和第5 行图片可以看出该算法没有很好地去除偏蓝色的背景噪声。融合深度学习和成像模型的算法(ModelCNN)[13]及完全采用深度学习方法的ShallowUWnet算法[22]一定程度上也去除了水下图像偏蓝色的背景,但是在色彩饱和度上还有待提高。

图9 不同算法在训练数据测试集上的视觉效果图Fig.9 Visual renderings of different algorithms on test sets of training data
2.2 客观指标分析
试验中采用的评价指标分为有水下图像真实值参考指标和无水下图像真实值参考指标。常用的无水下图像真实值参考指标有:
图像信息熵(ENTROPY):水下图像中包含的图像信息的丰富度,越大越好。
水下图像颜色质量评价(UCIQE)[24]:水下图像饱和度、色彩度和对比度的加权求和。值越大,图像质量越高。
水下图像质量衡量(UIQM)[25]:水下图像色彩测量、清晰度测量、对比度测量的加权求和。值越大图像品质越高。
常用的有水下图像真实值参考指标有:
图像峰值信噪比(PSNR):信号的最大功率与噪声功率的比值,数值越大代表图像失真越少,有价值的图像信息越多。
图像结构相似度(SSIM)[26]:用来衡量两张图像相似程度的指标,范围在0 到1 之间,越接近1 代表两张图像结构越相似。
由于图6 中的图片是无真实清晰图像可以对照的,故采取无真实图像参考指标进行对比。选取测试集中的图片计算各个算法增强后的平均值,如表3所示。可以看出:传统的相对全局直方图延展算法RGHS[21]在UCIQE 指标上排名第一,但是视觉增强效果并不理想,这是因为UCIQE 是色彩、对比度和饱和度3个方面的统计加权求和,即使图片在某个方面被过度增强,导致色彩偏差,仍然可能取得较高的UCIQE 得分,这点在文献[14]中有被提及。文中算法的UCIQE 得分在使用深度学习的算法中得分第一。另外,文中算法在ENTROPY 和UIQM 上成绩分别为7.654 7 和3.005 6,分别高出第二名0.123 2 和0.097 5。说明了文中算法是有效的。
2.3 算法迁移能力分析
为了验证文中所提出的算法具有一定的迁移能力和通用性,在非训练数据集EUVP[23]上选取图片进行测试和对比分析,选取6张进行效果对比,如图10所示。

图10 不同算法在EUVP数据集上测试效果图Fig.10 Test results of different algorithms in EUVP data sets
视觉效果上,水下光衰弱先验算法ULAP[10]和相对全局直方图延展算法RGHS[21]在第3行的海星图像上都出现了欠增强现象,没有很好地去除蓝色背景噪声。文中算法很好地去除了该数据集中水下图像的背景噪声。客观指标上,如表4所示,水下光衰弱先验算法ULAP[10]在UCIQE 指标上排名第一,色彩丰富度最好,但是出现过增强现象。文中算法在基于深度学习的方法中UCIQE 得分第一,数值为0.611 0。另外,文中算法在UIQM、PSNR 和SSIM 指标上得分分别为3.138 6、24.349 9、0.832 3,分别高于排名第二的算法0.096 1、0.487 8 和0.029 2。综上所述,文中的水下图像增强网络在非训练数据集EUVP[23]上取得了良好的增强效果,具有一定的迁移能力和通用性。

表4 EUVP数据集上不同水下图像增强算法对比Tab.4 Comparison of different underwater image enhancement algorithms in EUVP data set
2.4 水下目标特征点匹配测试
水下图像增强是水下图像预处理的关键一步,可以提供高质量的图像,提高水下机器人的视觉感知能力。图像特征点匹配是一种基本的视觉感知任务,同时也是水下三维重建、图像拼接等高级任务的基础。局部特征更完整的高质量水下图像会得到更多的匹配点数量。因此,基于GMS 匹配算法[27],选取两幅具有重合特征的水下鱼类场景进行特征点匹配测试,在相同的试验条件下,比较不同算法的特征点匹配数量,验证文中算法的实际应用效果。各种算法匹配结果如图11所示。

图11 水下鱼类场景GMS特征点匹配Fig.11 Underwater fish scene GMS feature point matching
匹配点数量对比如表5 所示。试验结果表明:文中提出的方法既能够有效地进行局部特征的提取和匹配,而且匹配的特征点数为305个,在对比的算法中最多,验证了算法具有较好的实际应用前景,为下一步的水下图像任务奠定了基础。

表5 水下鱼类场景GMS特征点匹配数对比Tab.5 Comparison of underwater fish scene GMS feature point matching number
2.5 消融试验
为了验证文中提出的基于图像的快速傅里叶变换复频域损失、网络中的多尺度语义提取模块和残差注意力结合自适应融合模块的作用,做了消融试验,评价指标采用UIQM 和UCIQE 评价指标。结果如表6 所示。由表6 可见:同时存在多尺度模块(模块1)、复频域损失(模块2)、残差注意力和自适应融合(模块3)的情况下取得了最高的得分,UIQM 和UCIQE 得分分别为3.138 6 和0.606 0,验证了各个网络模块在提高水下图像质量上的有效性。

表6 网络结构消融试验结果Tab.6 Experimental results of network structure ablation
另外,为了验证网络中密集连接和高效注意力模块的细节提取功能,做了对比试验,结果如图12 所示,第1行至第3行分别为原始水下图像、没有细节分支时的结果和文中网络的结果。容易得出,虽然没有细节分支时,网络也去除了水下图像的一些噪声,但是得到的结果图边缘特征模糊,色彩失真严重,缺乏水下图像较好的细节信息,从而验证了文中网络中细节分支对水下图像的细节提取起到了一定的促进作用。

图12 细节分支测试结果Fig.12 Test results of detailed branches
3 结 语
海底生物资源丰富,合理保护和利用海底生物至关重要,海洋环境监测水下机器人等水下监测设备在进行海洋生物监测保护时,需要安装水下相机提供近程视野信息,然而水下相机拍摄到的光学图像偏蓝绿色调,暗淡模糊。文中针对该问题提出了一种基于双通道的水下图像增强卷积神经网络,设计了编码器中的细节特征提取模块和多尺度语义特征提取模块,提出了复频域损失函数。为了弥补网络前期传输过程中原始信息的丢失,同时优化特征,融入了残差注意力模块和自适应融合模块。消融试验表明了各个模块对于提高水下图像质量均有一定的改善。另外,文中算法不仅在训练数据集UIEB 中取得了较好的增强效果,而且在非训练数据集EUVP中表现良好,具有一定的可迁移能力与算法通用性,对于海洋环境监测水下机器人的视觉感知有重要意义。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
燃气涡轮试验与研究(2021年6期)2021-08-01
数学小灵通·3-4年级(2021年5期)2021-07-16
海洋信息技术与应用(2020年4期)2021-01-18
中国生物医学工程学报(2019年5期)2019-07-16
今日农业(2019年15期)2019-01-03
北京航空航天大学学报(2017年3期)2017-11-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
