
基于地质图编码及深度残差网络的找矿预测方法
——以陕西石泉地区金矿为例
2023-12-21 03:46王建邦薛林福于晓飞李永胜张运杰冉祥金
黄金 2023年12期
王建邦,薛林福*,于晓飞,李永胜,张运杰,冉祥金,丁 可
(1.吉林大学地球科学学院; 2.中国地质调查局发展研究中心;3.自然资源部矿产勘查技术指导中心; 4.中国石油新疆油田分公司采油一厂)
引 言
人工智能是引领未来的战略性技术,以深度学习为代表的新一代人工智能在医疗、自动驾驶等领域得到了广泛应用,基于深度学习方法的找矿预测已成为当前战略性矿产资源勘查领域的研究热点之一[1-2]。中国已积累了海量矿产地质数据[3],深度学习方法处理这些高维、异构、多属性数据具有独特优势,能够更有效地从中挖掘矿床与数据之间的深层次相关性[4],研究如何利用深度学习方法来组织和处理这些数据并进行找矿预测具有十分重要的意义。
首先,利用地质数据进行找矿预测主要集中在化探异常识别和利用物探、化探数据进行找矿远景区圈定等方面。例如:CHEN等[5]提出了采用一种空间约束自动编码器(SCMA)方法来处理多元地球化学异常识别问题。LI等[6]利用元素地球化学数据二维卷积神经网络进行金矿找矿预测。WU等[7]采用迁移学习和孪生神经网络相结合的方法提高了提取多元地球化学异常的能力。其次,综合利用多种地质数据进行找矿远景区预测越来越受到专家和学者的重视。例如,李忠潭等[8]提出一种将航磁和地球化学数据输入卷积神经网络模型进行铜矿找矿预测的方法。
相比传统的机器学习方法,深度学习方法具有特征工程自动化的优点,模型经过大量原始数据的训练就可达到特征自动提取并实现分类、预测等目的[9]。深度学习方法一般分为无监督方法和有监督方法两大类。其中,无监督方法是主要利用自编码网络等模型进行多元地球化学异常识别并圈定找矿远景区的方法[10-12];有监督方法方面,一维卷积神经网络和二维卷积神经网络等方法已被应用到部分区域矿产资源的智能化预测评价工作中[13-18]。例如:DING等[19]提出了利用地质、物探和化探数据,通过孪生神经网络对有矿样本和无矿样本进行对比来实现找矿预测的方法。
尽管上述方法均取得了一定的效果,但目前仍存在一些尚未解决的问题:①地质图中包含的重要信息在找矿预测中尚未被有效利用;②使用模型的精度不够,获得预测靶区的面积较大。因此,本文提出了一种基于地质图ONE-HOT编码方法及深度残差网络模型的找矿预测方法,该方法通过将地质图中的地层、岩体进行ONE-HOT编码,形成二维数组,实现地质图信息的量化表示,并根据断裂与网格单元的距离关系将地质图中的断裂转化为成矿影响强度,在一定程度上解决了以往无法有效利用地质图信息的问题,采用此方法在陕西石泉地区进行了找矿预测研究。
1 地质背景

1—第四系 2—石泉组 3—大枫沟岩组上段 4—大枫沟岩组中段 5—大枫沟岩组下段 6—石家沟岩组上段 7—石家沟岩组下段 8—梅子垭岩组上段 9—梅子垭岩组中段 10—梅子垭岩组下段 11—斑鸠关岩组上段 12—斑鸠关岩组中段 13—斑鸠关岩组下段 14—洞河岩组中段 15—箭竹坝岩组 16—耀岭河组 17—杨坪岩组 18—辉长岩脉 19—中酸性花岗岩脉 20—地质界线 21—角度不整合界线 22—性质不明断裂 23—韧性剪切断裂 24—正断裂 25—逆断裂 26—金矿及编号 27—包含已知金矿的找矿远景区 28—不包含已知金矿的找矿远景区及编号 29—一级构造单元界线 30—二级构造单元界线 31—三级构造单元界线 32—研究区 Ⅲ1—秦岭—大别山新元古代—中生代造山带南秦岭边缘海盆留坝—旬阳晚古生代陆缘海盆舟曲—安康早古生代裂谷扬子陆块北缘镇巴弧形逆冲带图1 石泉地区地质与金矿预测图(A)及大地构造位置图(B)
研究区共发现金矿共15处(见表1,其中金矿编号与图1-B相同),除宁陕县堰沟金矿外,其余均分布在研究区中部斑鸠关岩组和梅子垭岩组中,呈北西向—南东向展布,主要受一系列脆韧性剪切带及次级脆性断裂控制[26-27]。

表1 石泉地区典型金矿统计结果
2 数据网格化方法
2.1 地质图ONE-HOT编码网格化
ONE-HOT编码方法是对研究区地质图中的各地质体进行数量化表示。研究区共有19类地质体,包括17类地层和2类侵入岩。将研究区以50 m×50 m网格化为383×477个网格,对每个网格用长度为19 m的一维ONE-HOT编码数组进行地质体表示,如[0,0,0,1,…,0,0,0]。当确定了每个网格单元的编码后,将各网格单元地质体的ONE-HOT编码数组进行组合得到1个三维数组,其形状为(383,477,19),以此来数量化表示整个图幅内各网格的地质体。为方便与地球化学数据叠加后输入卷积神经网络,将形状为(383,477,19)的三维ONE-HOT编码数组采用自编码神经网络(AE)降维方法压缩为(383,477)形状的二维数组(见图2)。

图2 石泉地区地质体编码方法
2.2 断裂成矿影响强度网格化
成矿作用通常在断裂或断裂附近比较发育,随着与断裂距离的增加,成矿作用强度总体呈衰减趋势。可以用指数函数将与断裂的距离表示成断裂对成矿作用的影响强度(I),计算函数见式(1):
I=ae-bx
(1)
式中:a为影响的幅度值,取1.0;b为衰减系数,其值越大,衰减速率越快,取0.1;x为与地质要素的距离(m)[28]。
研究区断裂影响强度见图3。由图3可知:除少数金矿外,大部分金矿都位于高或较高影响强度区附近,这与研究区金矿(化)体主要受脆韧性剪切断裂及次级脆性断裂控制的情况相符。

图3 石泉地区断裂影响强度
2.3 地球化学数据网格化
将研究区内16种元素的1∶5万水系沉积物地球化学数据以50 m×50 m为网格单元进行网格化,绘制出了8种与成矿密切相关的元素等值线图,结果见图4。
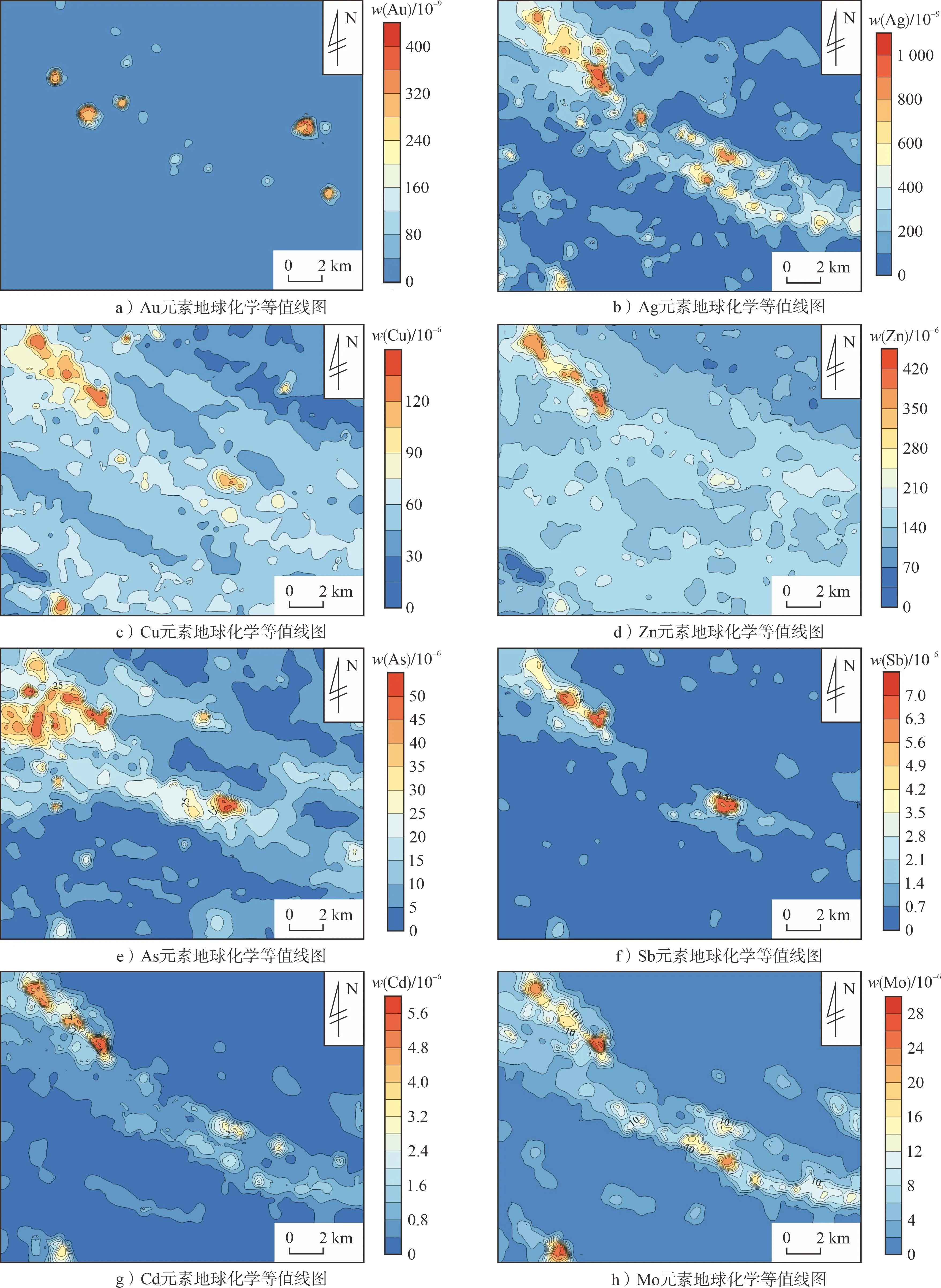
图4 石泉地区元素地球化学等值线图
研究区内Au元素地球化学场分布自东北至西南方向具有一定的分带性,主要表现为中间高、南北低的地球化学场格局。高值区呈北西向分布于斑鸠关岩组和梅子垭岩组内,这2组地层为研究区内金矿主要的赋矿地层。低值区主要分布于南部的洞河岩组内,北部大枫沟岩组亦有小面积分布。
Ag、Cu、Zn、As、Sb、Cd、Mo高值区沿泥盆系与志留系接触界面下方分布,总体呈北西向展布。除上述高值区地段之外的广大地区都为低值区。Ag低值区在东北部泥盆系地层中多呈团块状分布,与地层走向不一致。Cu、Zn、Cd、Mo低值区分布在东北角泥盆系地层。在西南角,Cu、Zn高值区沿斑鸠关岩组、洞河岩组和元古代地层绿片岩相的断裂接触界线呈串珠状分布,串珠之间多以背景区相连。As、Sb在西南角分布一致,高值区呈孤峰状分布在断裂交会处。
3 深度残差网络找矿预测方法
深度残差网络找矿预测方法是通过平移、旋转、缩放等数据增强方法从网格化数据中获取训练样本,再对深度残差网络进行训练及优化超参数后获得预测模型,最终将预测模型应用于研究区金矿找矿预测任务。其关键步骤为:数据样本集生成、模型构建、模型训练与超参数优化。ResNet神经网络预测模型找矿预测流程见图5。

图5 ResNet神经网络预测模型找矿预测流程
3.1 数据样本集生成
根据金矿与其所在区域的地球化学及地质特征的相关性,将围绕金矿获取一定格网窗口大小的数据样本作为正样本,在无金矿的位置随机选取一定格网窗口大小的数据样本作为负样本。仅利用研究区15个金矿生成的数据样本很难训练出在全区具有泛化能力的预测模型。为获得更多的数据样本,对于每个金矿,通过窗口平移、缩放、旋转等方式从不同位置、不同距离、不同角度对周围的地球化学及地质特征进行样本获取(见图6)。采用此种数据增强方法在研究区共获得了26 611个数据样本。

图6 通过格网窗口平移生成更多数据样本的方法
3.2 深度残差网络找矿预测模型构建
相比于普通的卷积神经网路(CNN),深度残差网络引入了跨层的恒等连接,使得网络模型更容易被训练[20]。通过恒等连接,中间层被跳过,使深度网络更容易被训练,恒等映射不贡献任何额外的参数[29]。深度残差网络模型不是直接堆叠层以满足特定的底层映射F(x),而是堆叠层以适应残差映射H(x),让H(x)表示所需的底层映射,从而使得网络映射[20]:
F(x)=H(x)-x
(2)
转化为:
H(x)=F(x)+x
(3)
考虑到多维地质数据不同于图像数据,本文采用的基本残差单元去除了批规范(Batch Normalization,BN)层,避免BN层将网络学习的地质数据特征进行强制归一化,造成数据损失。本文构建的深度残差网络找矿预测模型由6个残差单元构成(见图7)。优化器选择Adam优化器,学习率初始化为0.001,并在训练过程中逐步降低。

图7 深度残差网络找矿预测模型架构
3.3 模型训练与参数优化
利用从地球化学、断裂及地质体在网格化数据中获取的数据样本,对ResNet神经网络预测模型进行100轮训练。其中,75 %的数据用于模型训练,25 %的数据用于模型验证。为确定最优超参数,在训练过程中将各超参数设定一系列的预设值,通过对比试验结果确定最优值。
3.3.1 AE数据压缩维度
由于经网格化后的数据量较大,模型不易收敛。因此,采用自编码神经网络(AE)数据压缩方法在模型训练前对数据进行压缩。将格网窗口规定为16×16网格数,进行数据压缩维度参数分别为3,5,7,9的对比试验,结果见表2。由表2可知:当AE数据压缩维度为7时,在保证数据量少的同时,找矿远景区面积占比(7.12 %)也较小。因此,训练时将AE数据压缩维度设置为7。
3.3.2 格网窗口大小
格网窗口大小对结果有一定的影响,窗口越小,通过数据增强所得到的训练数据就越少;窗口越大,找矿远景区面积也会越大。将数据压缩维度设置为7,对不同窗口大小8×8、16×16、24×24和32×32(网格数)的数据进行对比,结果见表3。当格网窗口大小为16×16(网格数)时,模型验证精度最高,为99.64 %,且找矿远景区面积占比较小,为6.54 %。因此,格网窗口大小最优值为16×16。

表3 格网窗口大小对预测结果的影响
3.3.3 batch_size参数
合适的batch_size值能够使模型训练收敛最快或者收敛效果最好。将数据压缩维度设为7,窗口大小设为16×16(网格数)后,分别进行了batch_size为32,64,128和256 4种情况的对比试验。当batch_size为128时,验证精度(99.64 %)达到最优,且找矿远景区面积占比最小,为6.54 %(见表4)。因此,batch_size最优为128。

表4 batch_size对预测结果的影响
4 结果与讨论
4.1 金矿预测结果
用试验筛选出的最优参数,数据压缩维度为7,窗口大小为16×16(网格数),batch_szie为128,对预测模型进行训练,结果见图8。由图8可知:模型经过50轮训练后,模型精度趋于稳定,此时验证集精度约为99.6 %。最后,将预测模型应用于研究区进行金矿找矿预测,经过多次预测结果的综合分析,共圈定19处找矿远景区(见图1)。其中,11处找矿远景区包含已知金矿,8处找矿远景区为不包含已知金矿的新找矿远景区,新找矿远景区特征如下。

图8 模型训练精度曲线
P-1找矿远景区:该找矿远景区位于温家沟南部,北西向断裂较为发育,地层主要为斑鸠关岩组;该区存在Zn、As、Cd元素异常高值区,具有良好的找矿潜力。
P-2找矿远景区:该找矿远景区位于温家沟南部,地层主要为斑鸠关岩组和梅子垭岩组,该区为Ag、Cu、Zn、As、Cd元素异常高值区。
P-3找矿远景区:该找矿远景区位于北西向珍珠河—酒店韧性剪切断裂内,地层主要为斑鸠关岩组,岩性为泥砂质结晶灰岩夹石榴石二云石英片岩、钙质黑云卷云石英片岩;该区存在Au、Ag、As、Mo元素异常高值区。
P-4找矿远景区:该找矿远景区位于北西向珍珠河—酒店韧性剪切断裂内,地层主要为斑鸠关岩组,岩性为泥砂质结晶灰岩夹石榴石二云石英片岩、钙质黑云卷云石英片岩;该区存在Ag、As、Mo元素异常高值区。
P-5、P-6找矿远景区:该找矿远景区位于平定寨北部,北西向断裂较为发育,地层主要为斑鸠关岩组,岩性为炭质绢云石英片岩、黑色石英岩和黑云母绢云石英片岩,存在Ag、As、Mo元素异常高值区。
P-7找矿远景区:该找矿远景区位于干饭沟东北部,受北西向断裂影响,主要地层为斑鸠关岩组和梅子垭岩组;该区存在Ag、Cu、Zn、As、Cd、Mo元素异常高值区。
P-8找矿远景区:该找矿远景区主要位于北西向珍珠河—酒店韧性剪切断裂内,地层主要为斑鸠关岩组、梅子垭岩组;该找矿远景区为石英脉韧性变形与脆性变形强硅化区,Au、Ag、Sb元素异常明显。
4.2 不同数据集的结果对比
为对比地质图ONE-HOT编码数据和断裂影响强度数据的预测效果,构建了3种数据集,分别为地球化学数据、断裂影响强度+地质图ONE-HOT编码数据、地球化学+断裂影响强度+地质图ONE-HOT编码数据,来讨论地质图数据对预测结果的影响,结果见图9。
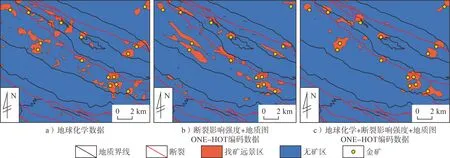
图9 石泉地区3种数据集金矿预测结果对比图
使用地球化学数据预测时,找矿远景区仅仅是依据区域地球化学异常得到的,表现出找矿远景区面积较大且分布散乱。使用断裂影响强度+地质图ONE-HOT编码数据时,找矿远景区呈条带状,与地层展布方向和断裂走向一致,但未加入地球化学数据进行控制,找矿远景区面积较大且多处找矿远景区未包含已知金矿。综合利用地球化学+断裂影响强度+地质图ONE-HOT编码数据后,多数已知金矿包含在找矿远景区内,且找矿远景区主要分布在梅子垭岩组和斑鸠关岩组中,且在断裂附近。此时找矿远景区面积(占比6.5 %)最小。
4.3 与不同预测方法的结果对比
采用证据权重法、CNN及ResNet3种方法对陕西石泉迎丰街地区进行找矿预测,结果见表5、图10。3种方法的找矿远景区均呈北西向展布,且断裂走向一致。ResNet方法相比其他方法具有更好的预测精度和最小的找矿远景区面积。

表5 3种方法的预测结果对比

图10 石泉地区3种方法金矿预测结果对比图
5 结 论
1)通过地质图ONE-HOT编码网格化及断裂影响强度网格化,实现了将岩性和断裂信息加入基于深度学习方法的找矿预测过程,有效利用了已有地质数据。
2)在融合地球化学和地质数据后,采用基于深度残差网络找矿预测方法提高了找矿预测的精度和可靠性。与证据权重法和CNN预测方法比较,深度残差网络找矿预测模型可以获得更高的预测精度和更小的找矿远景范围。
3)基于深度残差网络模型在石泉地区圈定了8处新的找矿远景区,为在该区进一步开展金矿找矿提供了新的方向。
猜你喜欢
幼儿画刊(2023年4期)2023-05-26
网络安全与数据管理(2022年3期)2022-05-23
云南画报(2021年6期)2021-07-28
矿产勘查(2020年2期)2020-12-28
矿产勘查(2020年6期)2020-12-25
矿产勘查(2020年3期)2020-12-19
北京航空航天大学学报(2020年10期)2020-11-14
杂文月刊(2019年24期)2020-01-01
杂文月刊(选刊版)(2019年12期)2019-09-10
自动化学报(2019年6期)2019-07-23
