
面向雷达多目标跟踪应用的专用片上系统设计
2023-12-20 02:27:06王荣阳曲国远徐佩园
计算机工程与设计 2023年12期
王荣阳,曲国远,童 歆,徐佩园,李 威
(中国航空无线电电子研究所 电子部,上海 200233)
0 引 言
雷达多目标跟踪应用的核心问题是对多传感器在某时刻获取的多目标点迹信息进行点迹-航迹关联,并判断各点迹与航迹的关联效果[1]。目前主流的关联处理算法为最近领域类算法[2],此类算法先对点迹航迹坐标进行大量双精度欧式距离计算,然后通过条件比较、强数据关联运算对关联结果进行判断。这类算法专有的数据流通路和对算力的高要求导致其使用通用处理器(CPU)和图形处理器(GPU)实现运算效率不高[3,4]。这是因为CPU擅长管理和调度,比如数据读取、文件管理、人机交互等,面对稠密计算的数据处理应用,CPU的固有优势无法发挥出来。而GPU擅长规则化的单指令多数据并行处理,没有为多目标匹配算法设计专有数据通路和访存通路,且硬件底层细节隐蔽,面对专用加速时能效比不高。在目标数量较多时,传统处理平台对于算法的整体处理延时较大,导致系统感知能力变弱。
本文借鉴领域专用处理器的设计思想[5,6],通过对雷达多目标点迹-航迹关联算法的分析,设计了一种低延时专用片上系统,该片上系统由主处理器和专用加速器构成,通用主处理器用来处理算法中数据、指令收发、判断、分支跳转操作,专用加速器对算法中的主要计算瓶颈如统计距离计算和多目标匹配进行加速,在FPGA平台上设计、优化片上系统并验证了专用加速器对于这类应用的有效性,为后续的领域专用计算架构设计思想、方法奠定了基础。
1 问题分析
多目标跟踪的核心是进行目标点迹和航迹关联,这是一个在复杂约束条件下进行组合优化得到最优解的问题[7]。点迹航迹关联算法分为统计距离计算、筛选、多目标匹配、整合4个步骤,如图1所示。

图1 点迹航迹关联算法流程
其中,统计距离计算将多个传感器新探测到的目标点迹坐标与已知航迹坐标按照预定公式进行运算,得到统计距离矩阵,涉及大规模矩阵运算;筛选是将统计距离矩阵的所有元素进行阈值比较、条件筛选,得到一批已关联上的点迹航迹信息和一批未关联上的点迹航迹信息;多目标匹配将未关联的点迹和航迹通过匹配算法进行处理,得到最优的点迹航迹关联信息;整合是将前两步的已关联信息整合到一起,送给后续步骤进行航迹生成或更新。
在整个多目标点迹航迹关联算法的运行过程中,统计距离计算和多目标匹配是最耗时的两个步骤,涉及到定制化的大规模矩阵运算以及重复迭代运算,适合专用加速处理;而筛选和整合运算量不大,但涉及到分支判断跳转等操作,适合采用通用处理器处理。
目前针对特定算法设计专用加速器有两种常用的方案,一种是在输入输出接口处放置硬件加速器的方式,数据在输入到输出的过程中即完成运算,这种类型的加速器称为通道加速器。例如,文献[8]中设计了基于以太网口的多核并行CNN硬件加速器,利用运算器内嵌缓存、运算过程分割和数据复用,减少运算器和存储器之间的数据交互,提高CNN运算的并行度,提升了训练和推理效率。另一种为协处理器方案,将加速器嵌入主处理器的内存或流水线中,通过自定义指令的形式来调用,实现主处理器与协处理的紧耦合。文献[9]中基于RISC-V(reduced instruction set compute-V)扩展指令集设计实现了一个低功耗嵌入式卷积神经网络协处理器,该协处理器内核扩展4条自定义神经网络指令,最大程度复用了原RISC-V的数据通路和功能模块,减小了额外的功耗和芯片面积等资源开销。
面向算法的不同特征,合理采用不同的硬件加速器设计方案可以最大程度的对算法定制化加速,提高运算效率。根据对点迹航迹关联算法和硬件加速器方案的分析,对于统计距离计算和筛选步骤中的阈值比较部分,本文将设计多运算单元的通道加速器实现并行加速,运算结果交由主处理器调用;对于多目标匹配算法将设计RISC-V自定义扩展指令及对应协处理器完成对算法的细粒度加速。第2节将对这两种硬件加速器设计进行详细阐述。
2 片上系统设计
面向多目标跟踪应用的低延迟专用片上系统主要由3部分组成,即主处理器、用于统计距离计算的通道加速器、用于多目标匹配算法的自定义指令协处理器,片上系统的整体架构如图2所示。

图2 面向多目标跟踪应用的专用片上系统框架
RISC-V作为一款新型指令集具有轻量化、开发效率高等特性,自提出至今,得到越来越多的应用[10,11]。RISC-V指令集创新性地提供了4类自定义指令格式,允许片上系统开发者按照需求设计相关的协处理器电路,实现主处理器和协处理器的紧耦合。通过设计自定义指令及对应协处理器,开发者可以容易的在复杂算法代码中插入对应的自定义指令,从而实现对算法的细粒度加速。本文在伯克利官方开发的开源RISC-V架构片上系统生成平台Rocket Chip[12]上设计实现片上系统,同时在处理器内配置浮点运算单元(float processing unit,FPU)。主处理器与协处理器之间通过RoCC接口实现紧耦合,RoCC接口用于主处理器与协处理器间的通信以及协处理器对内存的访问。为了提高协处理器的数据存取效率,将一级数据缓存配置成Scratchpad的形式,即作为一块有地址的片上存储使用。此外片上系统还配置了用于数据存储的DDR4控制器、用于与上位机通信和调试的UART接口、PCIE接口以及用于向上位机发送计算完成信号的GPIO接口。
片上系统的运算流程如图3所示:PC上位机将不同传感器的多个目标坐标由PCIE总线发送至片上系统的PCIEtoAXI4接口处理模块,通过内部AXI4总线将数据存储至双口缓存中。数据接收完成后通道加速器开始进行统计距离计算,同时将有效的结果由写入双口缓存组,通道加速器计算完成后通过中断管理模块向处理器发送中断信号。主处理器收到中断信号后开始执行筛选运算。当执行到可以进行协处理器加速的多目标匹配计算步骤时,主处理器会向协处理器发送自定义指令,协处理器接收到自定义指令后开始启动相应的计算,通过RoCC总线从内存中读取数据并进行流水线计算,计算结束后将结果写回内存固定位置。根据RoCC接口的定义,主处理器在等待协处理器的过程采用了写回目的寄存器的方式,这种处理方式主处理器会暂停运行,关闭流水线,直到协处理器完成工作写回目的寄存器后再开始工作。全部算法运行完成后,主处理器通过GPIO通知PC上位机将结果取回。
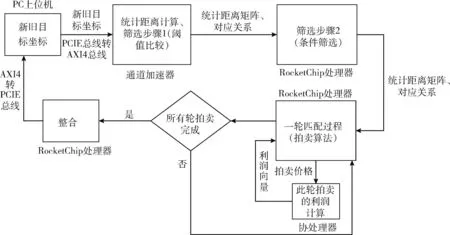
图3 面向多目标跟踪应用的专用片上系统数据流程
2.1 主处理器配置与设计
本设计中主处理器核需要处理浮点比较、浮点加减等运算,且算法中产生的中间数据比较多,因此配置主处理器核时需要较高的性能、较大的内存容量以及浮点运算单元。为了使用协处理器加速多目标匹配阶段的运算,还需配置协处理器RoCC接口。主处理器与协处理器的耦合关系框架如图4所示,当主处理器收到自定义扩展指令后会在写回阶段将该指令通过扩展指令发送模块发往协处理器。协处理器端指令响应和解码模块负责接收和解码对应的指令,运算控制逻辑模块控制计算模块与内存控制模块从内存中读取、写入相应的值。由于协处理器和主处理器都会访问内存,故设置一个仲裁模块来仲裁二者对内存的访问权限。
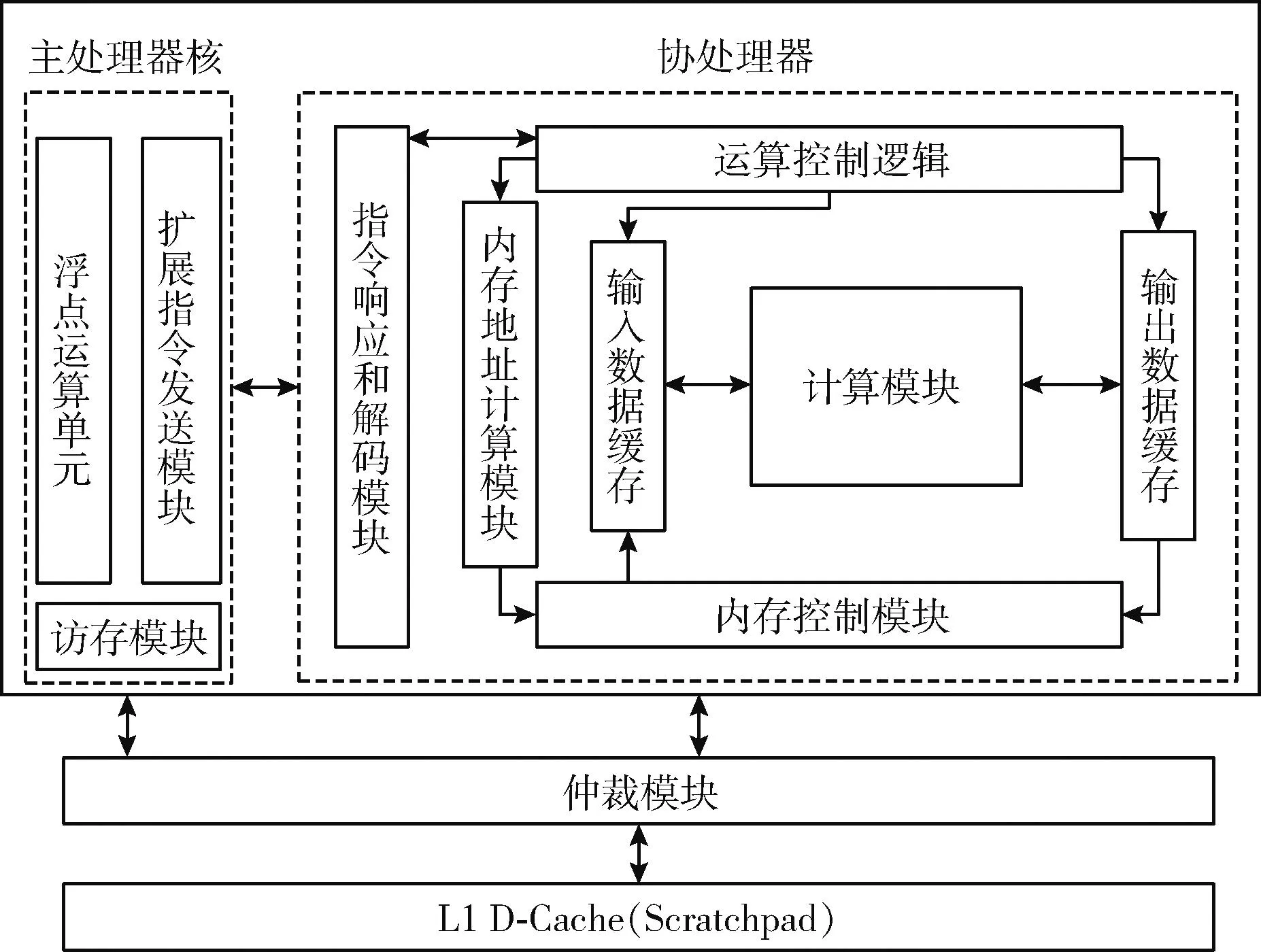
图4 主处理器与协处理器耦合关系框架
主处理器采用基于RISC-V指令集的开源处理器核Rocket Chip。RISC-V扩展指令集定义的标准扩展指令中,“I”表示基本整数操作,包含整数计算、load、store和控制流指令,RV64代表整数寄存器宽度为64位,“M”表示标准整数乘法和除法扩展,“A”代表标准原子指令扩展,“F”代表标准单精度浮点扩展,“D”表示标准双精度浮点扩展,一个基本整数内核加上这4个标准扩展(“IMAFD”)组成一个通用的标量指令集。本文采用RV64IMAFD架构,主要参数配置见表1。
RISC-V自定义指令的格式如图5所示,各个字段的含义可参考文献[13]。当一条指令进入流水线被解码后,主处理器会判断这条指令的格式是否为自定义指令,而后其会在执行完这条指令后保证这条指令之前的指令执行完毕,如果xd为1,则在这条自定义指令执行完成发往RoCC接口后关断流水线,如果xd为0则在自定义指令后继续执行。

表1 主处理器核参数配置

图5 RoCC自定义指令格式
2.2 通道加速器架构设计
通道加速器特指一类在数据输入输出通路上进行计算的硬件加速器,输入数据经过该类加速器后可直接获得的预期的运算结果。本文通道加速器的结构如图6中虚线框内所示,该通道加速器依附于输入数据通道,主要由多路分配器、控制逻辑、乒乓缓存、10个通道计算单元以及与每个通道计算单元对应的3个双口缓存组成。
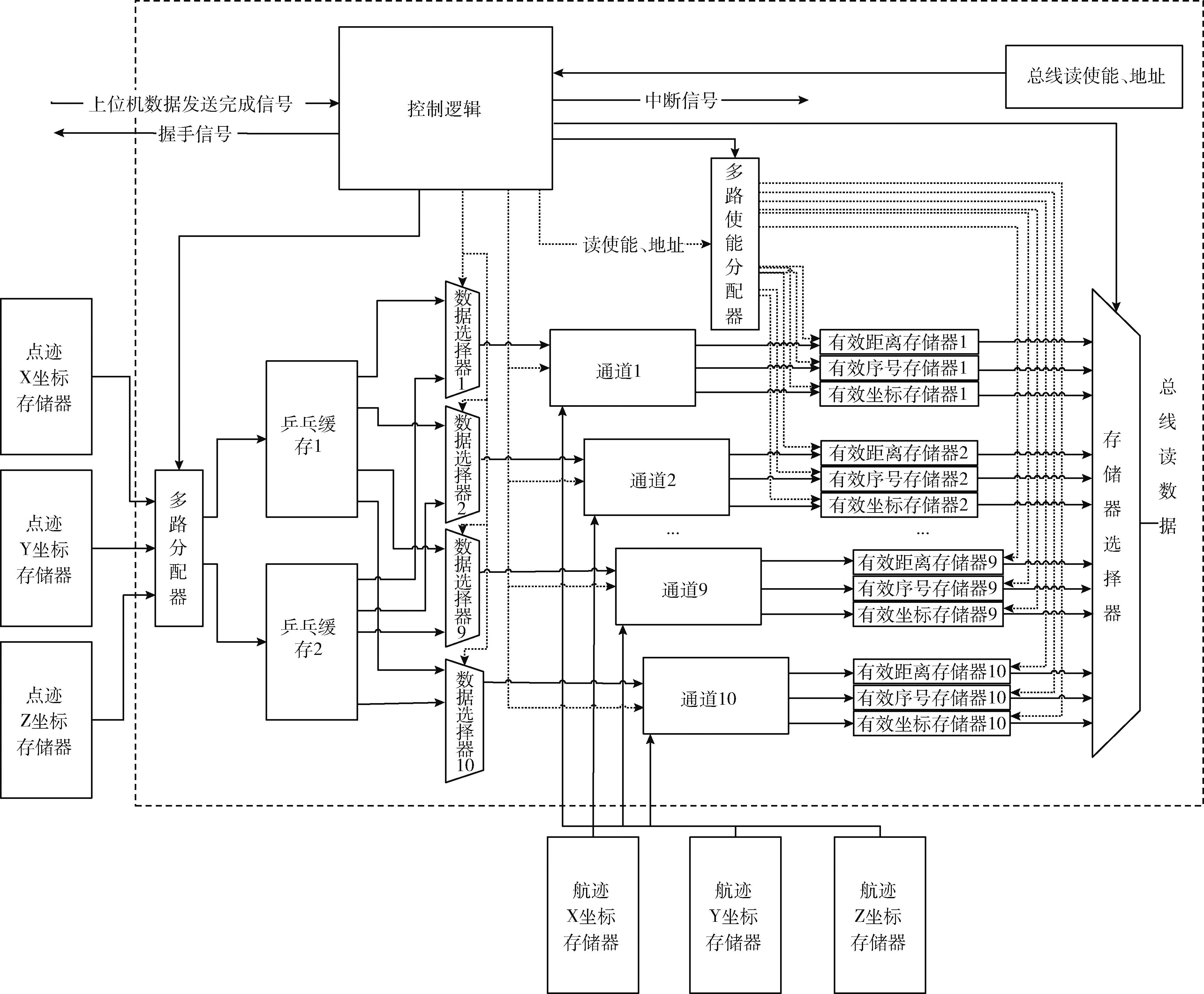
图6 通道加速器结构框架
上位机通过PCIE将待计算的数据发往与通道加速器对应的点迹、航迹坐标存储器,数据发送完成之后向通道加速器的控制逻辑发送完成信号,通道加速器的控制逻辑收到该信号后返回握手信号并开始数据运算。首先读取点迹的3个坐标缓存,先将乒乓缓存1中写满10组点迹的XYZ坐标,10组坐标分别与10个计算通道对应。而后每个时钟周期依次从航迹对应的3个坐标存储器中读出一组XYZ坐标送入10个计算通道,并开始与点迹的XYZ坐标进行预定公式的统计距离计算。同时,控制逻辑会再次从点迹坐标存储器中读取10组坐标存于乒乓缓存2,当航迹坐标存储器的所有坐标取完后将乒乓缓存2的10组坐标发送给10个计算通道,再从航迹坐标存储器中依次读取所有的坐标并送入10个通道进行计算。接下来,再从点迹坐标存储器中读取10组坐标存入乒乓缓存1,按照上述步骤循环,直到点迹所有坐标被取走且与航迹所有坐标完成统计距离计算后停止。
通道计算单元内部采用浮点流水线设计,分别采用浮点减法、浮点乘法、浮点除法单元。为了节约片上缓存资源,本设计根据算法的特点在通道计算单元中加入了浮点比较器,将计算结果与设定的阈值作比较,若计算结果小于阈值则将该值保存,同时将该结果对应的航迹序号记录,再将点迹序号对应的数值加一。这两个保存的数值和序号,可以减少原算法筛选步骤中的大量运算,从而对筛选部分起到加速效果。每个通道加速器的存储器组包含有效距离、有效坐标、有效序号存储器3种类型。当处理器通过总线发送地址、使能信号访问双口缓存时,控制逻辑根据全局地址范围译码使能对应的存储器供主处理器访问。
通道加速器完成计算任务后将有效数据存储于对应的存储器组,并向中断管理模块发送中断信号,中断管理模块经过仲裁决定响应后将中断信号发往主处理器,最终将处理的结果取回。
2.3 自定义指令协处理器设计
多目标匹配算法作为最近领域类算法的核心,一直是最优关联研究的难点和热点问题。当下比较常用的多目标匹配算法有拍卖算法、遗传算法以及粒子群算法等[14-16]。粒子群算法是较早出现的用于解决最优化的搜索算法,自提出以来得到诸多研究,基础粒子群算法存在局部搜索能力差、过早收敛等问题,因此在不断的衍生改进;拍卖算法和遗传算法都为较成熟算法,文献[17]根据不同的作战方法分别采用遗传算法和拍卖算法对目标关联进行了研究,发现遗传算法对全局优化分配占优势,而针对重点目标,从局部采用拍卖算法效果更好,且拍卖算法的实时性更高,这更加符合雷达多目标跟踪应用场景的需求。
拍卖算法的基本思想源于实际拍卖的过程,其过程为将n个物品拍卖给m个买家,每个买家对每件商品都有一个预期价值,假设买家j对物品k的心理价值为ajk(当该买家想获得该物品需要支付价格pjk大于该买家对该物品的心理价值时则该买家不会购买该物品),对于j买家来说其购买k商品的预期利润为ajk-pjk,对每个买家来说该预期利润应该为最大值。当每个买家都得到了最大利润时,这组物品与买家的分配就达到了整体最优。在实际算法实现过程中引入一个用于打破循环的正数ε,每个物品的每次竞标价格需要比上一次至少增加ε。本文将为新旧未跟踪坐标视为买家的物品,利用拍卖算法将未关联信息对进行匹配。
基于拍卖算法的多目标匹配在每一轮的运算中都会计算一次买家拍卖一件物品的利润,通过合理设计算法,将该步运算从算法中独立出来,为买家设置一个利润向量,通过调用协处理器执行拍卖利润计算,并采用流水线形式将该买家对当前所有的物品利润全部计算完,主处理器再依次从该向量中取对应的值用于拍卖。运行过程中,提前将有效信息写入两个源寄存器,包括价格向量在内存中的基地址、标价向量在内存中的基地址、待计算的数量、计算结果存于内存的基地址。由于算法中存在数据依赖性,故设置了目的寄存器有效,当协处理器在工作时主处理器会暂停并等待协处理器写回目的寄存器。拍卖利润计算自定义指令的格式见表2。

表2 自定义指令格式
本文设计的协处理器结构如图7所示。图中粗实线代表数据线,细实线代表控制线。其工作过程为:当指令响应和解码模块收到对应指令后将该指令对应的源寄存器中有效数据保存在对应寄存器中,运算控制逻辑控制输入数据内存地址计算模块,从寄存器中对应的基地址开始计算取数地址并发往内存控制模块,内存控制模块负责与内存接口进行通信,当内存可响应时将对应地址发出,并将内存发来的数据存入对应的缓存中。当两个取数缓存中的数据存完后,运算控制逻辑控制拍卖利润计算模块开始从两个缓存中读取数据并以流水线形式进行拍卖利润计算。每计算完一个结果就将结果保存在输出数据缓存中,当所有输出数据都计算完后运算控制逻辑再计算输出数据对应的内存地址并由输出控制模块将这些数据存入内存对应位置。整个流程结束后协处理器在目的寄存器写零,处理器从利润向量中取数并进行下一步运算。
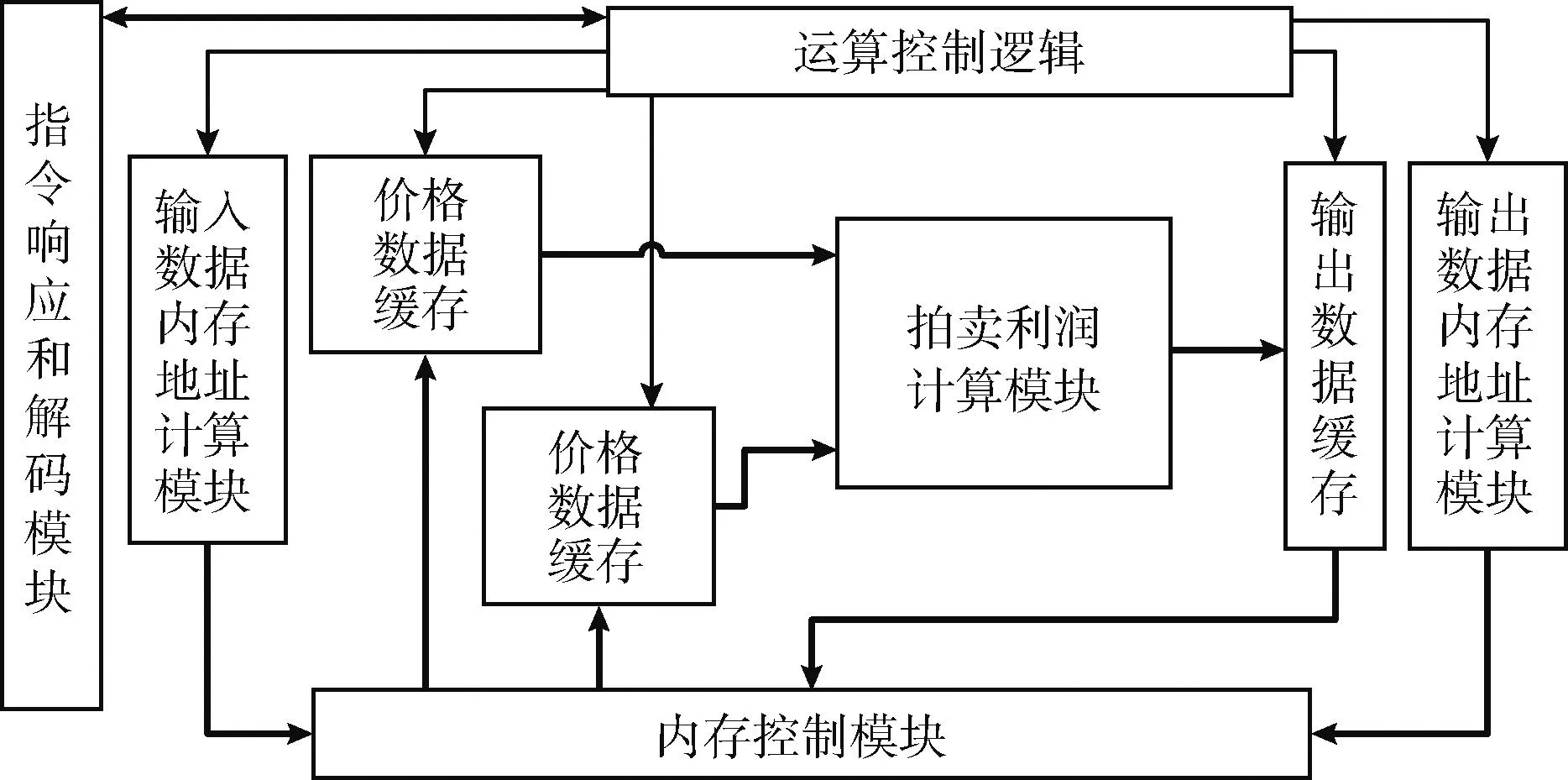
图7 协处理器结构框架
3 实验结果与分析
本文使用PC上位机以及主芯片为Xilinx XCKU040-2FFVA1156i FPGA的开发板进行专用片上系统原型测试验证。测试所用的数据按照雷达多目标跟踪典型应用情况生成,开发板如图8所示。

图8 专用片上系统测试验证开发板
PC上位机通过PCIE发送点迹、航迹原始数据到开发板,接收并记录各个步骤运行时间。专用片上系统包含RISC-V主处理器、两种加速器、片上存储资源以及内嵌逻辑分析仪。在KU040 FPGA上部署后,各项资源使用情况见表3。其中PCIE-AXI4和通道加速器的主频为250 Mhz,Rocket Chip核的主频为100 Mhz。
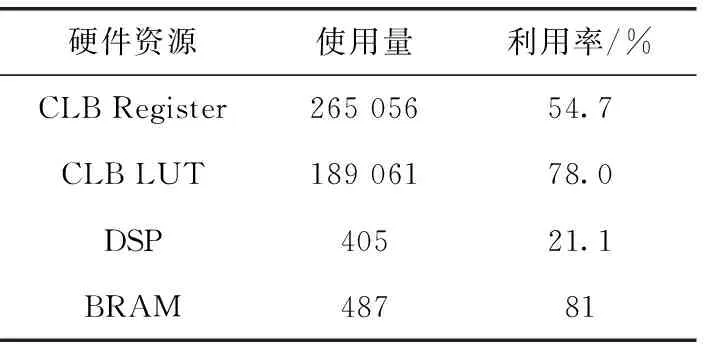
表3 FPGA资源使用情况
为了对比Rocket Chip和加速器的实际性能,选用相同平台未搭载加速器的片上系统以及同为RISC-V架构的开源处理器蜂鸟E200片上系统进行测试。图9为内嵌逻辑分析仪对信号进行捕获的截图,图中XA、YA、ZA、XB、YB、ZB为点迹航迹坐标数据,cmd_valid为过程触发,使能cmdReady进行运算,Calvalid信号表示出现一个有效的值并存储,最终通过中断向处理器提出响应。统计并记录了完整运行同一算法时3种片上系统的耗时,见表4。未挂载加速器的Rocket Chip片上系统运行原始算法时间为536 ms,挂载了通道加速器和协处理器的Rocket Chip专用片上系统运行算法时间为96 ms,蜂鸟E200片上系统运行算法时间为1624 ms。
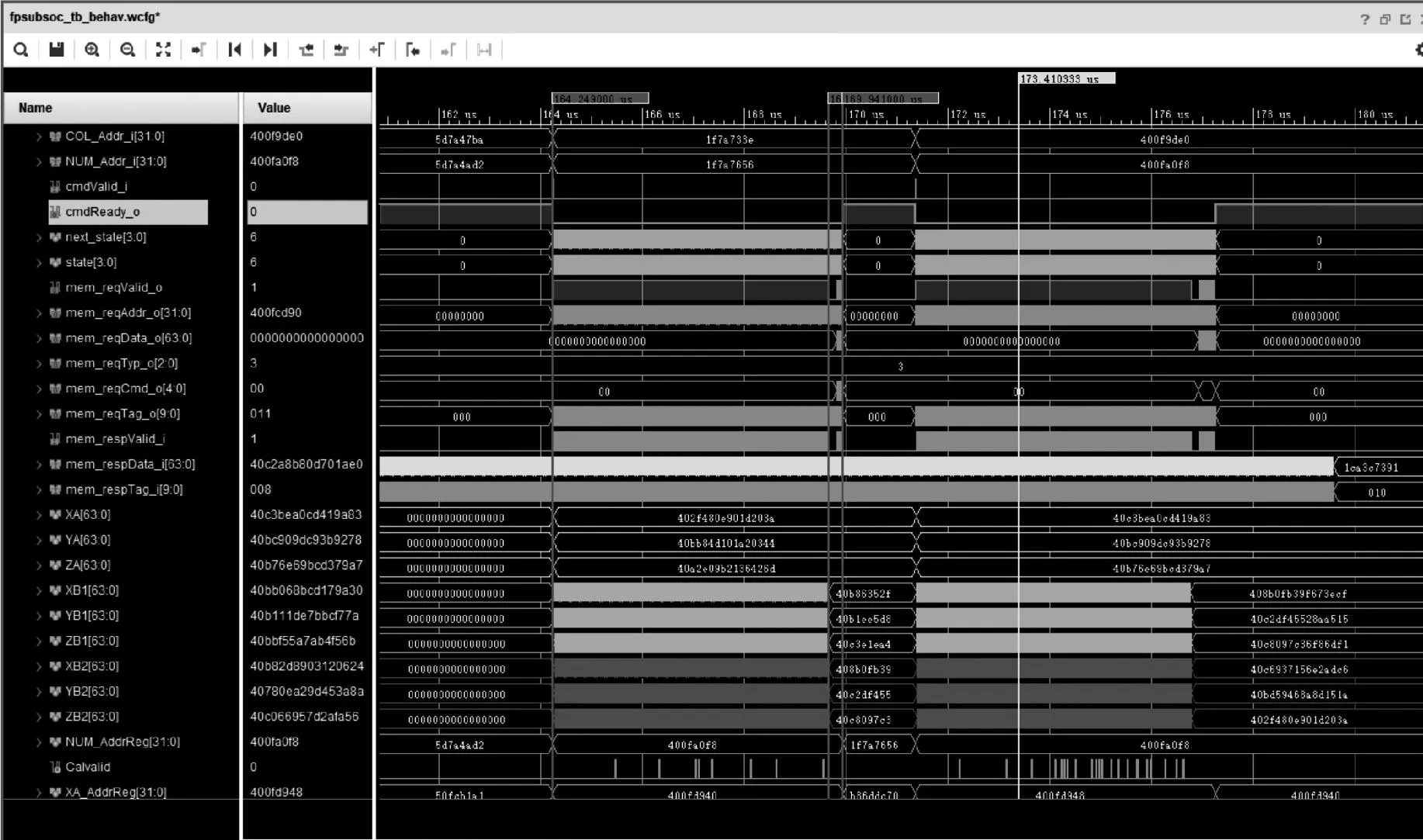
图9 内嵌逻辑分析仪信号捕获

表4 几种片上系统性能对比
从总体运算时间来看,本片上系统相比Rocket Chip处理器原始片上系统的加速比为5.6倍;相比蜂鸟E200处理器片上系统的加速比为16.9倍。本算法应用场景是以运算速度为主要优化目标,该处理器架构符合领域专用计算目标需求,可以预见,在替换为更高性能的RISC-V核后,本文设计的RISC-V扩展指令集架构的片上系统将获得更高的能效比。
4 结束语
多目标跟踪应用算法复杂的数据流导致当前的主流运算平台对这类算法的运算效率不高。本文通过对当前主流最近领域类算法结构及数据流分析,设计了面向多目标跟踪应用的专用片上系统架构,通过合理设计硬件通道加速器、面向拍卖利润计算的自定义扩展指令以及对应的协处理器实现了对该算法的硬件加速。
在FPGA原型验证平台的实际测试表明,该协处理器片上系统本算法的性能相较于原平台有显著提升。面向此类应用,本设计具有一定的领域通用性,对于其它最近领域类算法,只需更改处理器运行的软件代码就可以继续调用加速器实现通用性的加速,也可以设计新的自定义指令来进行针对性硬件加速,为领域专用片上系统设计提供了思路和现实参考。
猜你喜欢
故事作文·高年级(2024年5期)2024-06-04 23:39:22
高中数理化(2024年8期)2024-04-24 16:58:14
少先队活动(2021年6期)2021-07-22 08:44:24
科学与财富(2021年4期)2021-03-08 10:14:32
科学与财富(2020年34期)2020-03-11 18:58:06
青年歌声(2019年12期)2019-12-17 06:32:32
软件导刊(2018年3期)2018-03-26 02:14:46
北京航空航天大学学报(2017年7期)2017-11-24 05:27:33
北京航空航天大学学报(2016年6期)2016-11-16 01:50:52
少年博览·小学低年级(2016年5期)2016-05-14 11:59:03
