
基于双重视图耦合的自监督图表示学习模型
2023-12-20 02:33:26邹俊颖
计算机工程与设计 2023年12期
陈 琪,郭 涛,邹俊颖
(四川师范大学 计算机科学学院,四川 成都 610101)
0 引 言

1 理论基础
1.1 图表示学习
图表示学习通过学习节点特征和图的拓扑结构中蕴含的丰富信息,迭代聚合为新的低维稠密的实值向量化表示,使原始图中相似的节点在图表示向量空间中也相似。
定义图G为:G=(V,E,X), 其中V=(v1,v2,…,vN) 为节点集合,N为节点数量,E为边集合,X∈N×F为节点的特征矩阵,F为节点特征维度。
GCN为图表示学习提供了一个有效的非线性网络学习模型。将节点特征矩阵X和图的邻接矩阵A输入GCN,最终得到低维稠密的实值向量化表示X(l+1), 如式(1)所示
(1)
1.2 孪生神经网络
孪生神经网络[19]是由两个权重参数共享的子网络建立的耦合结构,如图1所示。自监督对比学习将X1和X2作为样本对输入到子网络中,映射为特征向量GW(X1) 和GW(X2), 拉近正样本对的距离作为共性监督信号,拉大负样本对的距离作为差异监督信号,如式(2)所示。其中,D为欧式距离,W为权重共享参数
(2)
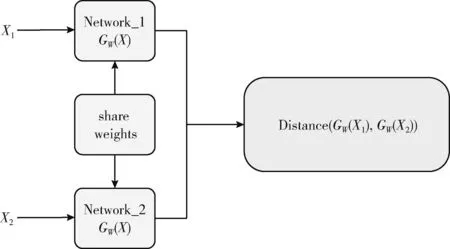
图1 孪生神经网络结构

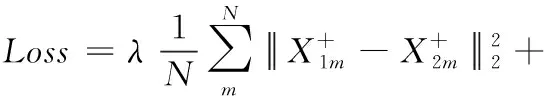
(3)
2 DVCGRL模型
2.1 问题描述
现有的图表示学习采用自监督对比学习方法,构造正负样本对,以此来实现节点分类任务。但存在以下问题:①在局部视图和全局视图上采用不同的图数据增广,使局部视图和全局视图存在一定差异,导致节点特征表示的判别能力弱。②需要额外生成负样本,因此必须对负样本特征进行重新排列,加大了模型的空间复杂度。
2.2 模型结构
本文在孪生神经网络基础上,提出了基于双重视图耦合的自监督图表示学习模型DVCGRL,如图2所示,该模型由4部分组成:图数据增广、图编码器、映射、耦合网络。首先,采用特征空间增广和结构空间扩充相结合生成双重视图,组成正样本对,使双重视图在孪生网络结构中的特征相似;其次将双重视图固定维度,作为正样本对输入到图编码器中,对双重视图的节点属性特征以及图结构信息进行融合,提取双重视图中节点的低层次特征;然后通过映射,聚集与下游任务相关的高层次抽象语义特征,获得映射后的特征向量;最后在耦合网络中通过缩小双重视图间节点特征表示的距离,增强双重视图的特征耦合性;通过方差正则化均匀分布节点独有特征,并利用协方差进行维度缩放,将不同维度的特征去相关,防止模型坍塌,最终达到减小空间复杂度,同时达到增强节点特征表示判别能力的效果。

(4)
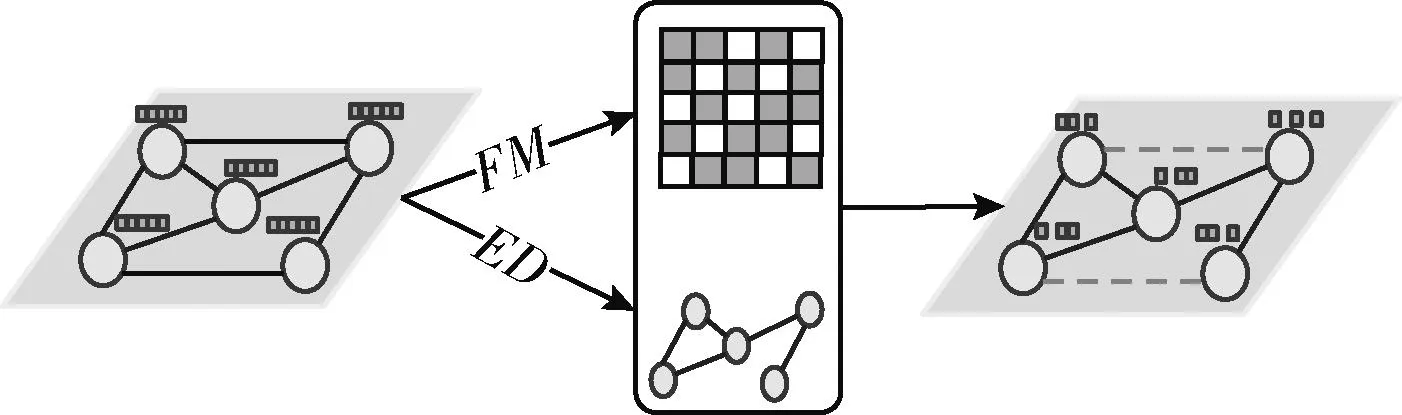
图3 图数据增广
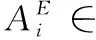
(5)
(2)图编码器(graph encoder):图编码器通过节点的邻居节点提取局部低层次细粒度特征。其中图编码器由两个图卷积神经网络GCN和一个线性激活层ReLU线性组成。将双重视图G1和G2传入图编码器中,对双重视图中节点的低层次细粒度特征进行特征提取,完成节点特征表示与邻居节点特征表示的融合,更新视图中节点特征的表示,获得双重视图的低层次特征表示Y1和Y2, 如式(6)所示。其中W1和W2分别为两个图卷积神经网络层的权重参数
(6)
(3)映射(projection):该映射通过多层感知器网络得到双重视图的向量化表示Z。其中多层感知器网络由两个全连接层和一个线性激活层ReLU线性组成。由于经过图编码器后的特征表示更具有通用性,与下游任务的节点分类无关,因此需要将这些细粒度特征Y1和Y2经过映射,使双重视图的特征向量化表示倾向于任务相关的高层次抽象语义特征向量化表示Z1和Z2, 如式(7)所示。其中ζ1和ζ2分别为两个全连接层的权重参数,b1和b2分别为两个全连接层的偏执
Z=ReLU(ζ1Y+b1)ζ2+b2
(7)
(4)耦合网络(coupling networks):用于衡量双重视图间的耦合性能,由距离损失、防止模型坍塌损失、去相关性损失组成。
Ls(Z1,Z2)为距离损失,衡量双重视图的特征耦合距离,其距离越小,表明模型预测效果越佳,如式(8)所示。其中i为视图中一个节点
(8)
LV(Z)为防止模型坍塌损失,衡量标准偏差与目标值间的偏离程度,与目标值的距离越近,表明节点的独有特征得到了更加均匀的分布,可以更好防止模型坍塌,如式(9)所示
LV(Z)=(max(0,1-Std(Z)))2
(9)
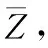
(10)
再由均值计算得到视图的标准偏差Std(Z), 如式(11)所示
(11)
最后设置标准偏差的目标值为1,使用ReLU对其进行正则化,防止结果陷入零解,使视图中节点的独有特征能够均匀分布,因此对其标准偏差正则化的结果进行平方,得到方差正则化的结果。
Lc(Z)为去相关性损失,衡量视图中不同维度的特征去相关性所产生的损失,减小不同维度的特征相关性,防止模型中的维度坍塌。本文定义协方差矩阵为C(Z), 如式(12)所示。通过对非对角线系数进行平方,使用超参数ν迫使协方差的非对角线系数接近于0,使双重视图间不同维度的特征表示向量中的每个元素之间增强独立性,并且对其进行一个维度缩放,将不同维度的特征之间去相关,避免维度间的特征类似,以此防止模型的维度崩溃,最终得到去相关性损失Lc(Z), 如式(13)所示,其中C(Z)i,j为协方差矩阵C(Z) 中第i行第j列的值
(12)
(13)
DVCGRL模型的总损失函数为Ltotal, 如式(14)所示。其中λ、μ、ν分别为距离损失、防止模型坍塌损失、去相关性损失的超参数
Ltotal=λLs(Z1,Z2)+μ{LV(Z1)+LV(Z2)}+ν{Lc(Z1)+Lc(Z2)}
(14)
2.3 算法流程
DVCGRL模型的整体算法流程如算法1所示。
算法1:DVCGRL模型训练
Input:有N个节点的原始图G=(V,E,X),X为节点特征矩阵,A为邻接矩阵,图数据增广的超参数pf、pe, 损失函数超参数λ、μ、ν, 最大训练步骤T。
Output:DVCGRL模型Ψ
(1)随机初始化模型Ψ中所有网络层的参数;
(2) fortinTdo:
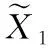
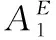
2.4 将双重视图传入图编码器提取低层次特征,根据式(6)获得节点的低层次特征表示,分别为:Y1和Y2;
2.5 将Y1和Y2传入多层感知器网络中,聚集与任务相关的高层次抽象语义特征,根据式(7)获得双重视图的特征向量化表示,分别为:Z1和Z2。
2.6 根据式(8)计算双重视图的距离损失Ls(Z1,Z2);
2.7 根据式(9)计算双重视图的防止模型坍塌损失,分别为:LV(Z1)和LV(Z2);
2.8 根据式(12)、式(13)计算双重视图的去相关性损失,分别为:Lc(Z1)和Lc(Z2);
2.9 根据式(14)计算模型的总损失Ltotal;
(3)end for
(4)输出DVCGRL模型Ψ,算法停止。
3 实验结果与分析
为了说明DVCGRL模型的有效性,本文进行了5种不同的实验:①双重视图耦合有效性实验;②节点分类对比实验;③空间复杂度实验;④图数据增广的超参数实验;⑤模型收敛性实验。
3.1 实验设置
3.1.1 数据集
实验在Cora、CiteSeer、PubMed、Amazon photo、Coauthor CS这5个公开数据集上进行。其中Cora、CiteSeer、PubMed为引文网络,节点为论文,边为引文关系,标签为论文的类别。Amazon photo为亚马逊共同购买图表的一部分,其中节点为商品,边为两种商品经常一起购买,节点特征是单词包编码的产品评论,而类标签是由产品类别给出的。Coauthor CS来自KDD杯2016挑战赛中基于微软学术图的合著图。有关数据集的详细信息见表1。
3.1.2 参数设置
通过验证集设置学习速率为0.001,学习率衰减参数为0.01,线性求值权重衰减为0.0001,节点特征输入和输出的维度设置为512,使用Adam优化器对模型进行训练。其中属性掩蔽的参数pf和边扰乱的参数pe为0.2。距离损失的参数λ设置为10,防止模型坍塌损失的参数μ设置为10,去相关性损失的参数ν设置为0.01。Cora、CiteSeer、PubMed的训练为30个epochs,Amazon photo和Coauthor CS的训练为50个epochs,测试为400个epochs。
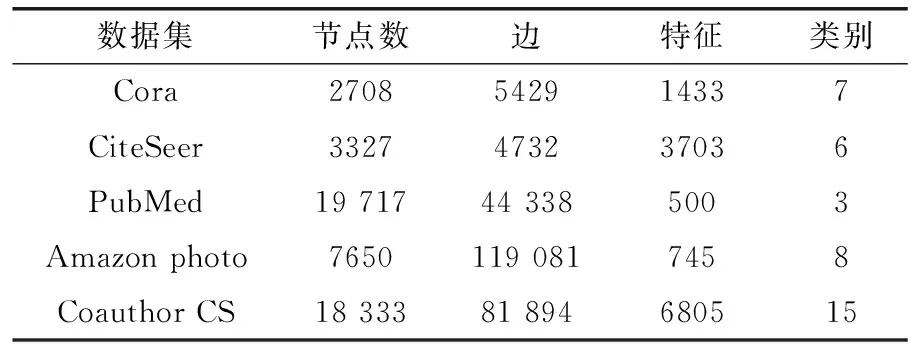
表1 节点分类数据集描述
3.2 双重视图耦合有效性实验
本实验完成了DVCGRL模型在Cora、CiteSeer、PubMed、Amazon photo、Coauthor CS上对双重视图特征耦合有效性验证。本实验分别采用特征空间增广中的属性掩蔽(FM)、结构空间扩充中的边扰乱(ED)作为对比,以此验证特征空间增广和结构空间扩充相结合(FM+ED)对双重视图特征耦合的有效性。本实验对3种方式的节点分类性能进行了直方图绘制,实验结果如图4所示。
从图4可以观察到,相比对视图采用单一的属性掩蔽或者边扰乱的增广,属性掩蔽和边扰乱的结合增广在节点分类性能上始终保持最佳。仅对特征空间或结构空间扩充的增广,图编码器中难以提取部分缺失信息的低层次特征,分类精度较低。双重视图对节点特征空间和结构空间进行相同增广后,双重视图在图表示向量空间更具有相似性。因此,双重视图的特征耦合效果较好,分类精度更高。这表明在双重视图中采用特征空间增广和结构空间扩充,可以增强双重视图的特征耦合性,提高节点特征表示在分类时的判别能力。由此,双重视图耦合有效性得到验证。
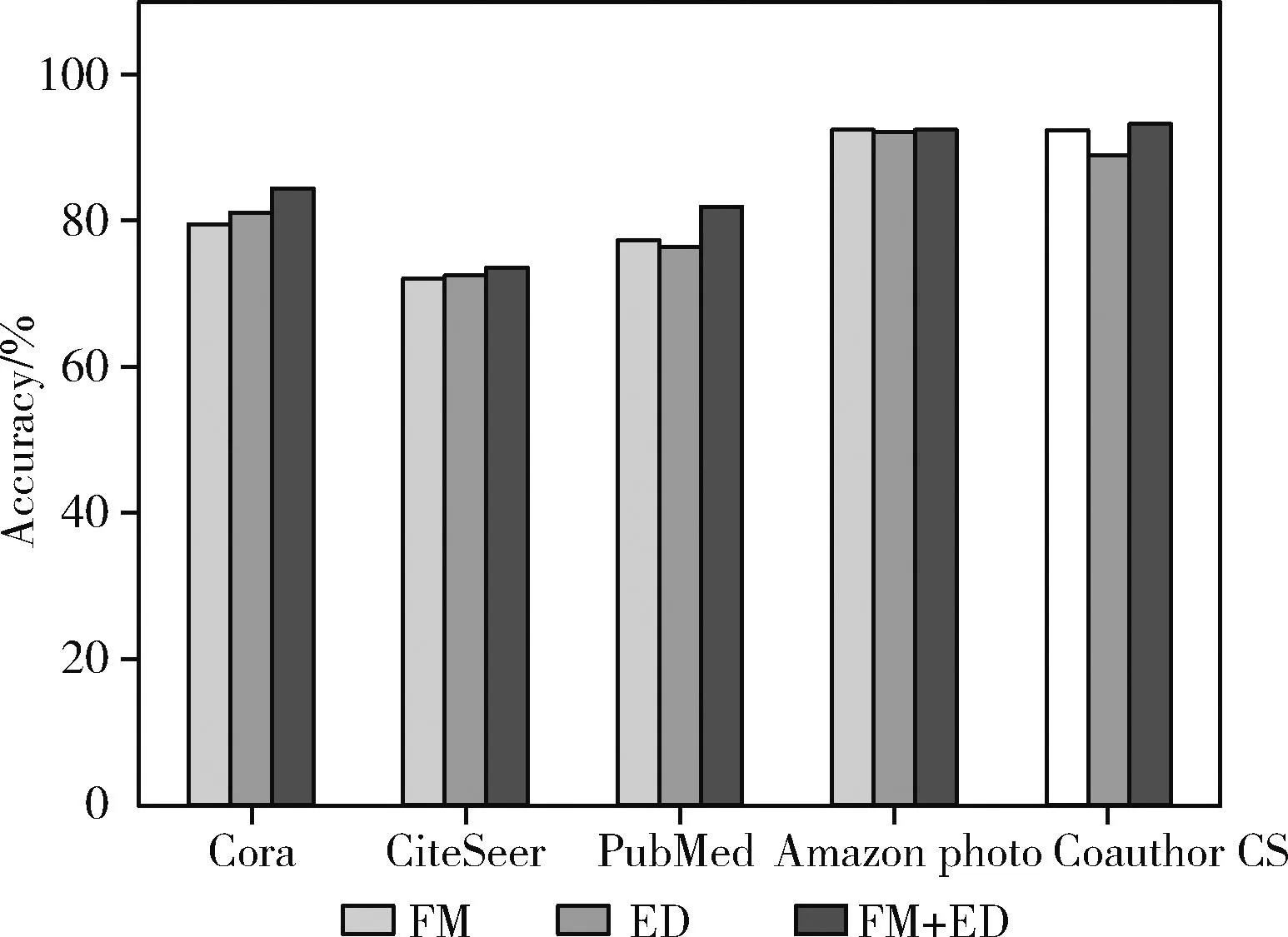
图4 双重视图耦合有效性实验结果
3.3 节点分类对比实验
本实验完成了DVCGRL模型在数据集Cora、CiteSeer、PubMed、Amazon photo、Coauthor CS上的节点分类准确率实验,并且与当前主流的有监督和自监督的图表示学习模型进行对比,实验结果见表2。其中,分类精度的最大值进行了加粗标记。
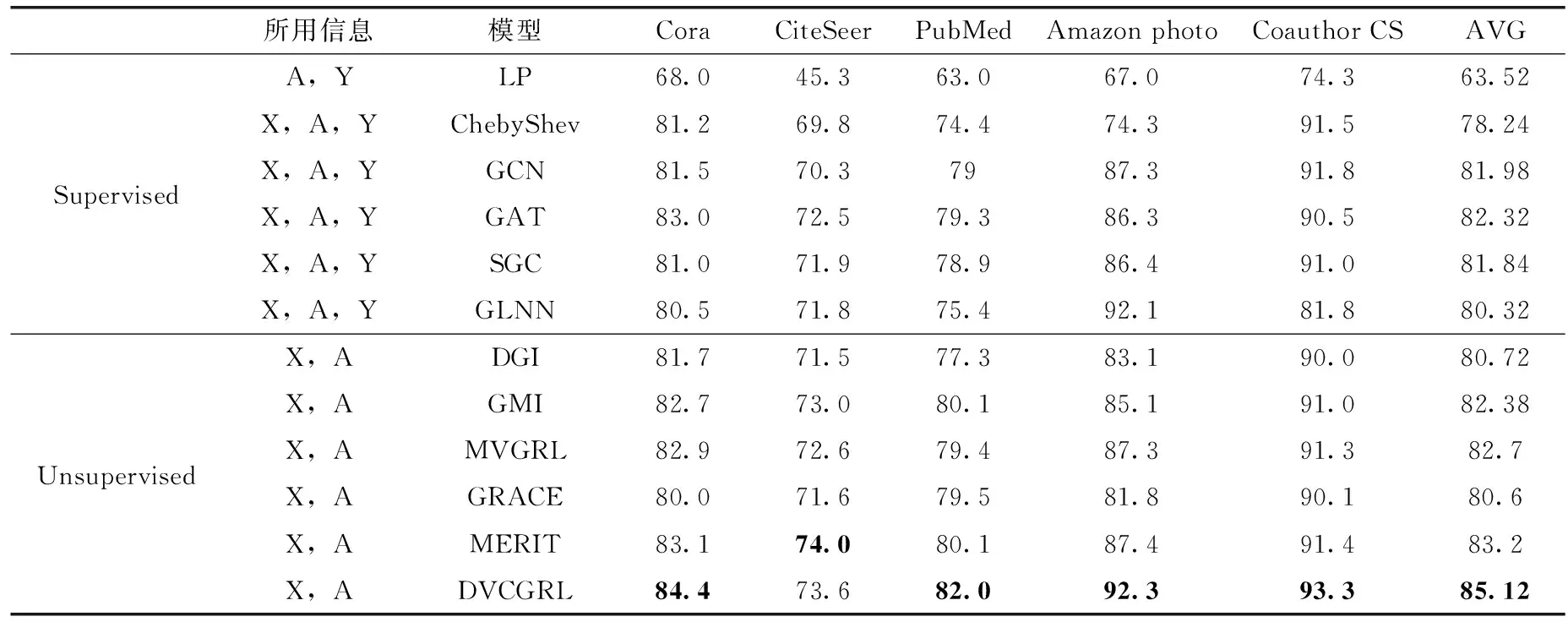
表2 节点分类正确率(A为邻接矩阵,Y为标签,X为节点特征矩阵)
从表2可以观察到,DVCGRL模型在5个数据集上都展现了良好的性能,平均精度值均超过其它模型。其中与有监督的主流模型相比,在5个数据集上,DVCGRL均超过了有监督的图表示学习模型;与自监督模型相比,在Cora、PubMed、Amazon photo、Coauthor CS数据集上节点分类性能保持最佳,在最佳自监督模型上,分别提高了1.3%、1.9%、4.9%、0.9%。在CiteSeer数据集上,虽然DVCGRL模型比MERIT模型低了0.4%,但均超过了当前其它主流的图表示学习模型的分类精度。在Amazon photo数据集上,与当前有监督的最佳模型GLNN[21]相比,DVCGRL的分类精度只提高了0.2%,但是缓解了人工标记数据集的负担,且在数据集上更具有客观性;与当前自监督的最佳模型MERIT相比,DVCGRL的分类精度超出了4.9%。在Amazon photo数据集上可以看出,该数据集的边数是Cora数据集的21~22倍,是PubMed数据集的2~3倍,是Coauthor CS数据集的1~2倍,这意味着Ama-zon photo数据集的节点拥有更加丰富的拓扑结构信息,因此DVCGRL模型相比其它数据集精度提高较大。由此,这表明DVCGRL模型能够通过双重视图特征耦合增强节点特征表示的判别能力。
3.4 空间复杂度实验
空间复杂度定性地描述了一个算法运行时所需要的存储空间大小。本实验在32 GB的GPU上对当前有监督的GLNN模型、自监督的MVGRL、GRACE、MERIT模型进行了空间复杂度对比,实验结果见表3,其中占用存储空间最小值使用了加粗标记。
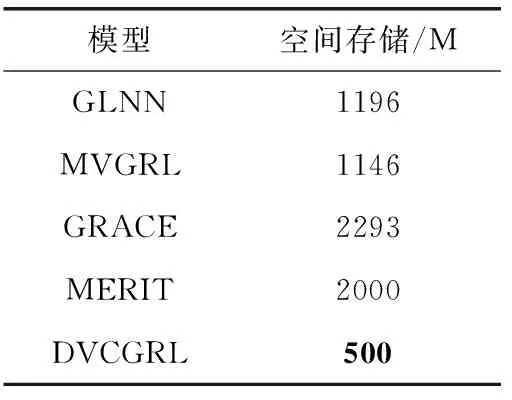
表3 空间存储大小
从表3可以观察到,DVCGRL模型在存储空间上所占内存最少。DVCGRL模型在存储空间只有GLNN、MVGRL模型的1/2,GRACE、MERIT模型的1/4。由此,DVCGRL模型的空间复杂度降低得到验证。
3.5 图数据增广的超参数实验
本实验选取了 [0,0.2,0.4,0.6,0.8] 5个数作为属性掩蔽pf和边扰乱pe的值[22],并在Cora、CiteSeer、PubMed、Amazon photo、Coauthor CS数据集进行超参数验证。实验中设置pf和pe(属性掩蔽+边扰乱)的参数值相同,图5展示了图数据增广的不同超参数对节点分类任务准确率的影响。从图5可以观察到,当超参数的值为0.2时,节点分类准确率最高,当超参数的值为0时,节点分类准确率最低,当超参数超过0.2,逐渐变大时,节点分类准确率也在逐步降低。由此,当超参数为0.2时,DVCGRL模型分类性能达到最佳。
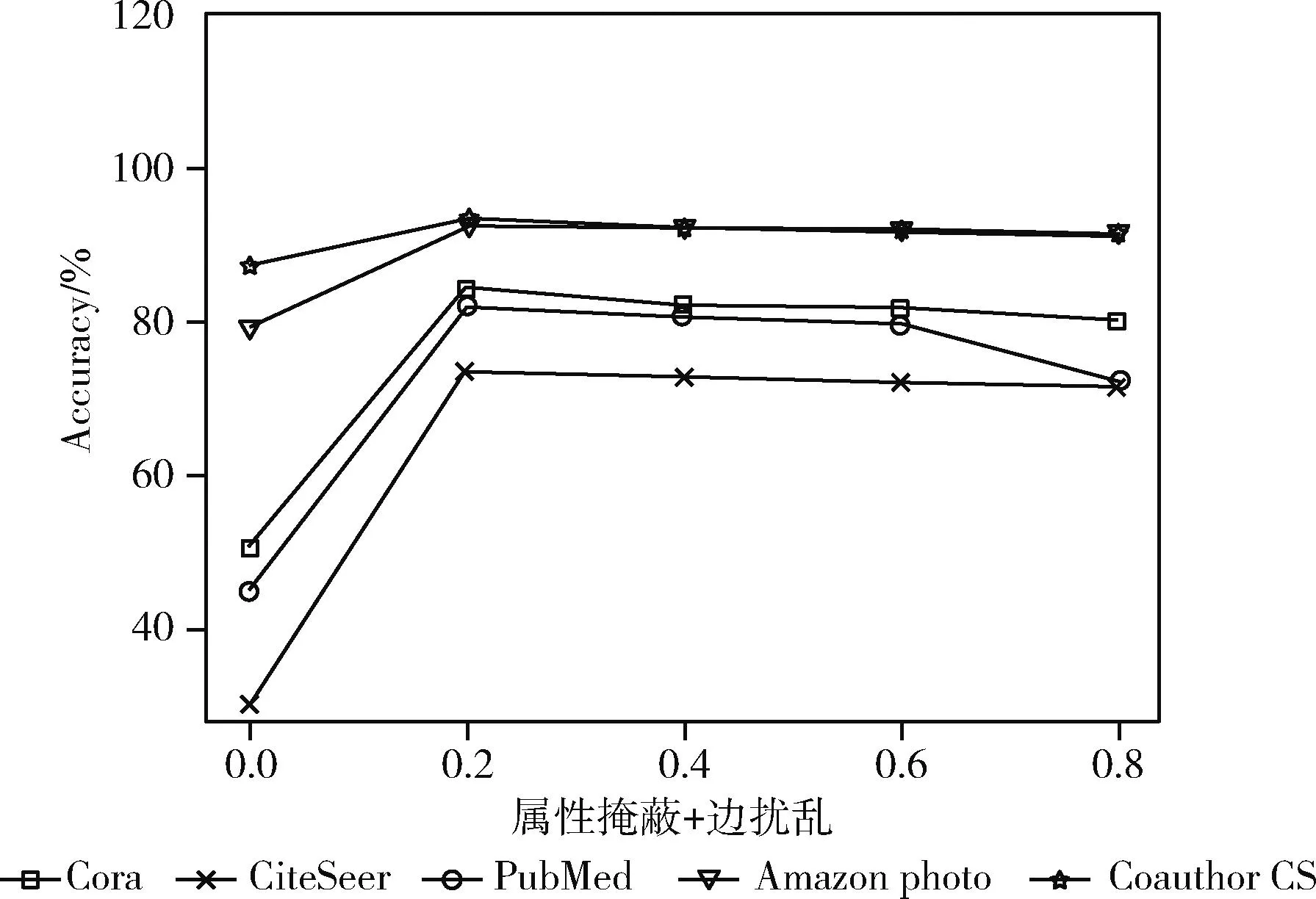
图5 图数据增广下的超参数实验结果
3.6 模型收敛实验
本实验完成了DVCGRL模型与自监督的模型GRACE、MERIT在5个数据集上的测试步长与精度折线图的绘制,实验结果如图6所示。图6(a)~图6(e)分别代表在数据集Cora、CiteSeer、PubMed、Amazon photo、Coauthor CS上的收敛实验效果对比。
从图6可以观察到,GRACE、MERIT、DVCGRL模型在100次前,精度提升速度很快,100次以后,测试精度趋于平缓状态,且DVCGRL模型在5个数据集上均具有良好的收敛性。从图6(b)中可以观察到,DVCGRL模型在150次以前,处于优势状态,在150次以后,MERIT模型略优于DVCGRL模型,原因是DVCGRL模型与MERIT模型的精度在CiteSeer数据集上相差0.4%,而DVCGRL模型与GRACE模型相比,收敛性保持较好。从图6(c)中可以观察到,GRACE模型在第0次时,精度比MERIT、DVCGRL模型高,但在100次以后,DVCGRL模型的精度超过GRACE、MERIT模型,且DVCGRL的曲线波动比GRACE模型更加平缓。从图6(d)可以观察到,DVCGRL模型在Amazon photo数据集精度提升最大,在第0次精度达到了90.6%,且超过了GRACE、MERIT模型的最终精度。由此,DVCGRL模型的收敛性得到验证。
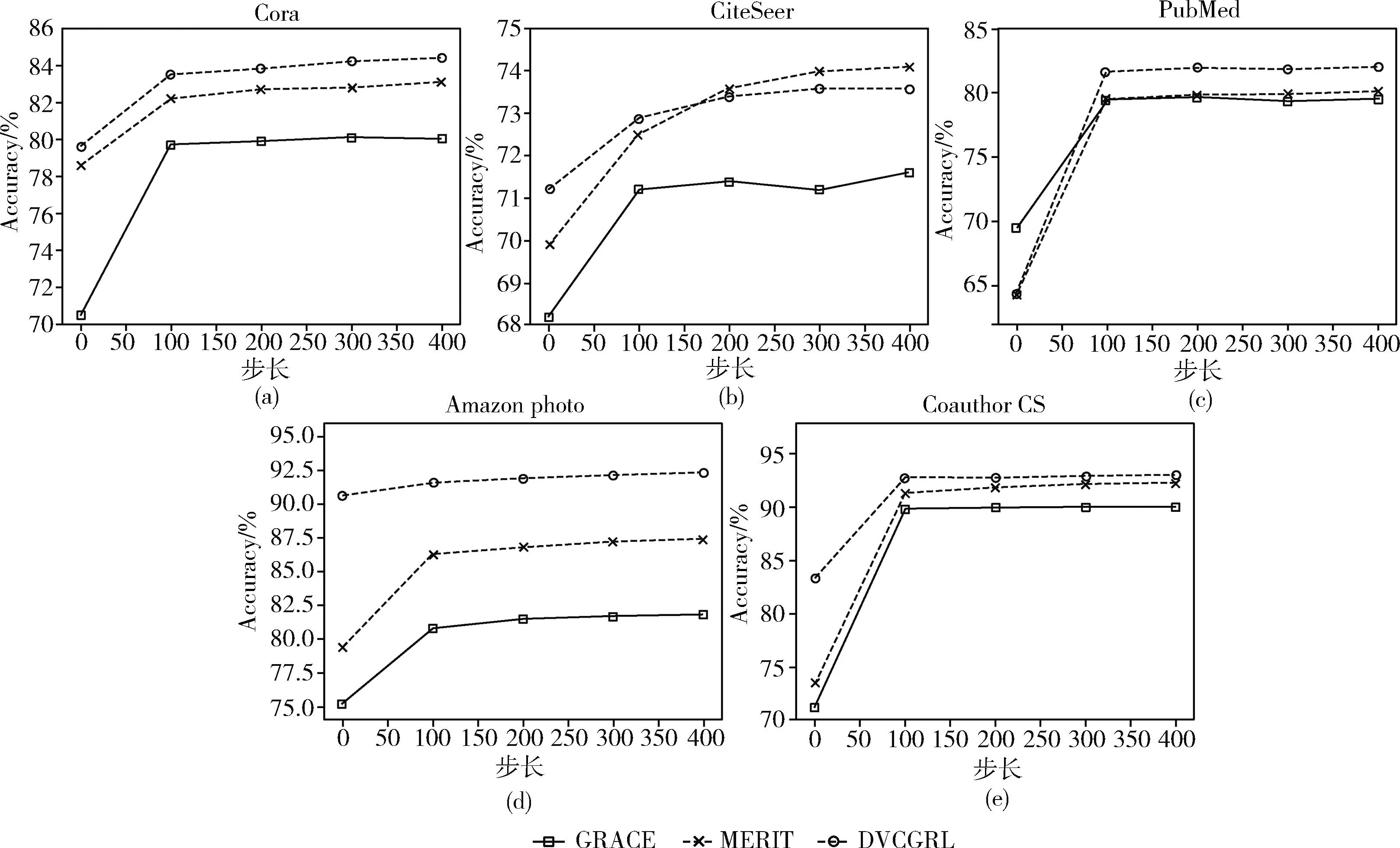
图6 模型收敛性实验结果
4 结束语
本文在没有使用负样本对的情况下,提出了基于双重视图耦合的自监督图表示学习模型DVCGRL,解决了现有图表示学习在自监督对比学习中视图差异大以及依赖于负样本,造成节点表示能力弱以及空间复杂度加大的问题。DVCGRL模型采用特征空间增广和结构空间扩充相结合生成双重视图,并作为正样本对传入两层参数共享的图卷积神经网络层,提取视图中的节点低层次特征;在多层感知器网络中,提取高层次的抽象语义特征,获得映射后的特征向量;在耦合网络中通过拉近双重视图的特征向量距离以增强特征耦合性,采用方差正则化和协方差以此防止模型坍塌;在减小模型空间复杂度的情况下,同时提高了DVCGRL模型的分类精度。此外,如何使模型保证一致性的情况下,在下游任务中实现跨任务学习是本文需要进一步研究的问题。
猜你喜欢
作文小学高年级(2023年6期)2023-07-14 11:13:38
数学物理学报(2022年2期)2022-04-26 14:08:28
中国外汇(2019年7期)2019-07-13 05:44:56
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
大型铸锻件(2015年5期)2015-12-16 11:43:20
发明与创新(2015年1期)2015-02-27 10:38:26
湖南理工学院学报(自然科学版)(2014年1期)2014-02-28 22:12:27
