
基于循环神经网络的实时偏好感知兴趣点推荐
2023-12-20 02:33:46韩志媛安敬民
计算机工程与设计 2023年12期
李 勇,韩志媛,安敬民
(1.潍坊学院 计算机工程学院,山东 潍坊 261061;2.潍坊医学院 外国语学院,山东 潍坊 261053; 3.大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 引 言
随着基于位置的社交网络(location-based social networks,LBSNs)的兴起,人们的生活得到了更多改善。这主要体现在用户可以随时随地分享自己的位置和兴趣点(point-of-interest,POI),而且用户还可以在LBSNs上查找符合自己兴趣的POIs(电影院、饭店和景点等),使得用户的生活更加便利。当前国内外有众多典型的LBSNs,比如大众点评平台、Gowalla以及Foursquare等,这些平台被越来越多的用户和学者所关注。若能合理地收集已有的用户签到数据并挖掘其中隐含的信息,将能进一步促进LBSNs的POI的个性化推荐的实现。个性化POI推荐是基于已有的用户签到经验,向其推荐他们未曾访问过且感兴趣的地方。对于个体用户而言,这增加其生活的方便,而对于第三方商家而言,可以更加容易定位用户兴趣偏好,以向特定用户群推送广告。近几年来,基于LBSNs的POI推荐方法大量涌现,如文献[1-3]等,这些方法主要致力于解决POI推荐过程中的数据稀疏问题,以获得更好的推荐效果。通过考虑不同的上下文信息(地理、社会和时间等信息)对用户偏好的影响,并协同用户实际签到数据实现兴趣点推荐。然而,这些方法虽然考虑了时间因素,但均基于用户的历史数据进行POI预测,未能充分考虑在推荐过程中用户的实时需求。例如:某用户ui习惯于在中午某段时间去餐馆吃饭,但ui此时刚刚下飞机并在早些时段已用过餐,其在短时间内连续用餐的概率是低的,而签到一个宾馆的概率更高。现有方法基于用户历史习惯会向该用户推荐餐馆,无法感知用户现有的实时需求。
针对这一问题,本文提出了一种用户实时偏好感知的POI推荐方法。该方法同时考虑了用户实时需求和用户历史偏好。利用用户当前的状态,如:当前签到的POI地理位置和时间信息,学习该用户实时偏好嵌入表示。使用矩阵分解技术(matrix factorization)融合POI类别信息和用户社会关系学习用户历史偏好嵌入。最后,使用一种能处理时序问题的循环神经网络(recurrent neural network)融合用户实时偏好向量和历史偏好向量,预测实时POI需求。通过在广泛被采用的数据集(Foursquare)上的实验,验证了所提方法的有效性。
1 相关工作
在过去的几年中,大量的基于LBSNs的POI推荐方法被提出,这里,本文给出最近的一些工作的介绍。
在POI推荐问题的近几年相关工作中,主要以融合多种上下文拟合用户偏好为主,如地理信息、社会信息、POI类别信息、流行度和时间信息等。这是因为更多有效的上下文信息能够更好地拟合用户签到行为。文献[4]分别利用核密度估计建模了POI地理相关性和使用高斯函数建模了用户的社会关系,并联合用户自身偏好,进行POI预测。文献[5]考虑了地理信息、社会信息以及POI评论内容三方面因素,提出了一个基于卷积矩阵分解框架的上下文融合模型。文献[6]分别学习了地理信息、POI类别信息以及社会关系的向量表示,并将3种特征向量输入到一个深度神经网络中以获取POI预测。文献[7]通过研究用户的签到行为模式的特征,提出一种用户移动模式相似度计算方法。文献[8]重点强调了LBSN中的社会信任关系,并结合地理信息和用户偏好信息设计了一个个性化POI推荐框架。文献[9]对POI文本内容进行了研究,通过对文本内容的挖掘,建模了3类特征,POI属性特征、用户情感特征以及用户兴趣。将3类特征输入到一个卷积神经网络中学习用户POI。文献[10]通过联合用户对POI的评分、社会信息、地理信息、POI流行度和用户签到行为,提出一种面向异构社会网络的POI推荐方法。文献[11]构建了一种用户签到社会关系网络,并通过网络关系表示学习获取用户社会关系对POI决策的影响。通过结合用户自身偏好和地理信息因素,实现POI个性化推荐。文献[12]则利用神经网络良好的感知和表达能力,通过半监督学习方法建模用户社会关系和POI地理信息,并结合协同过滤方法进行POI推荐。文献[13]为进一步缓解用户签到矩阵的稀疏性,将其中融入了POI类别信息,并结合用户的社会关系和POI地理关系实现用户的偏好预测。文献[14]构建了用户-POI标签矩阵以预测用户的自身偏好,并协同社会和地理影响进行最终的POI推荐。文献[15]全面地考虑了不同上下文可能对用户偏好的影响,构建了地理、文本、社会、POI类别和流行度模型,并利用概率矩阵分解模型将这些上下文模型融合,生成推荐列表。考虑到时间因素对用户的偏好的影响,越来越多的方法致力于研究时间感知的POI推荐方法,目的是实现一天内具体不同时间下的POI推荐。文献[1]根据用户的签到时间特征,将用户相似度分为全局相似性和局部相似性。通过对用户相似度的计算,提出了一种基于用户时间特征的协同过滤方法。文献[2]则基于神经网络提出一种时间感知兴趣点推荐方法,同时该方法考虑了POI的空间、流行度以及社会关系。文献[16]将上下文信息和用户签到信息输入图神经网络(graph neural network)学习框架,以获取POI的嵌入表示,通过低维度向量间的相关性实现POI推荐。文献[17]重点考虑了POI的多源文本内容,同时联合时间、社会和地理信息实现POI推荐。最近,文献[3]通过使用社会、地理、时间以及POI类别信息,构建了社会空间、地理空间和POI类别空间的相似度计算模型,进而提出一种用户相似度和POI相似度计算方法,并将两种相似度融合到概率矩阵分解模型以求解用户的POI。
对现有流行的POI推荐方法进行总结发现,现有方法均通过对用户历史签到数据的挖掘技术和固有的上下文特征建模技术的研究,联合用户历史偏好和上下文拟合用户的偏好预测用户POI。然而,这些方法并未考虑现实中用户的实时需求。用户在不同时间、不同地点以及不同状态下,偏好是变化的。所以,本文提出一种用户实时需求感知的POI推荐方法。
2 用户实时偏好模型
本文使用用户ui当前(第k次)所签到的POIpk的地理位置lk和签到时间Tk表示用户实偏好ek
ek=(Δlk,Δtk,velk,tk,twk)
(1)
这里,Δlk表示pk与pk-1间的距离,用以表示用户当前位置特征。 Δtk表示ui连续签到pk与pk-1间的时间间隔。velk是Δlk和Δtk的特征抽取,velk=Δlk/Δtk。Tk={tk,twk},tk表示ui签到pk的时间,本文将时间以小时为单位分为24个时间片,即tk∈{0,1,2,…,23}。twk表示ui是否在周末签到pk,如果twk=1表示ui在周末签到pk,twk=0表示ui在工作日签到pk。这原因是大多用户的工作日和周末签到习惯不同,在工作日用户可能偏好与工作地点距离近的POI,而周末他们可能偏好距离远一些的POI,所以本文设定twk来学习用户在两个时间阶段的偏好。
3 用户历史偏好建模
用户历史偏好是决定用户是否签到一个POI的主要因素。目前矩阵分解(matrix factorization,MF)技术被视为最流行的方法之一。因为用户签到数据是一种隐式数据集,具有庞大且稀疏的特点,MF已被证明能够有效地应对这一问题。令R表示用户-POI签到矩阵,rik∈R,rik=1表示ui签到过pk,rik=0表示ui未签到过pk。一般公式如下
(2)
这里,α表示正则化系数。U表示K维用户潜在向量,L表示K维POI潜在向量。用户历史偏好可以学习表示为
(3)
用户往往展现出对某一类的POI的兴趣,比如用户经常签到某一川菜馆,说明其可能偏好麻辣口味一类的食物。所以,本文将POI类别信息融合到用户历史偏好表示中,以增强用户偏好学习。令vi,caj为ui对POIlk所属类别Cak偏好的K维特征向量。此时,用户历史偏好更新为
(4)
式中:γ是权重参数。
考虑到用户的社会关系对用户偏好决策的影响,本文采用一种基于网络关系表示学习的社会关系建模方法。主要因为用户的社会关系是多样化且复杂的,而常用的方法,如Consine相似度、Pearson相关度以及Jaccard系数等,均直接采用用户的签到记录计算用户的相似度,无法获取用户间复杂的社会关系。首先,为表达复杂的用户社会关系(朋友关系、邻居关系以及同事关系等),本文构建一种用户共同签到(co-visit)图G=(V,E)。V={v1,v2,…,vn} 是图中的顶点,表示每一个用户。E={(v1,v2),(v3,v2),…,(vn,vm)} 是图中边,(vn,vm) 表示用户un和um签到过相同的POI。为学习图G中每个用户的向量表示,本文使用了skip-gram模型,以用户ui为中心学习他/她在社会关系中的向量表示
(5)
(6)
基于sij,本文利用协同过滤方法预测社会关系对用户ui的偏好影响scik
(7)
结合scik,本文再次更新用户历史偏好
(8)
4 基于循环神经网络的融合模型
联合用户实时偏好ek和历史偏好Prefik,本文表示用户需求为
Dk=(ek,Prefik)
(9)
进一步地,考虑到用户的实时需求不仅与当前第k次签到相关,同时与前k-1次的签到相关。比如,出差中的用户ui结束工作之后,应该去某个餐馆用餐,然后可能去某个宾馆休息。所以,准确地建模用户实时需求,需结合用户的签到序列。本文根据ui的签到时序,给出ui的签到序列如下
seqi=(D1,D2,…,Dk)
(10)
假定pc是ui偏好POI的候选对象,则可以使用Dc表示pc,并给出组合序列
seq′i=(D1,D2,…,Dk,Dc)
(11)
基于对seq′i的学习,本文预测ui签到pc的概率。具体地,本文将seq′i输入到LSTM神经网络来学习对应的隐藏向量表示。以Dk为例,求解Dk对应的隐藏向量hk
it=σ(WiDk+Mihk-1+bi)
(12)
ft=σ(WfDk+Mfhk-1+bf)
(13)
ot=σ(WoDk+Mohk-1+bo)
(14)
ct=ft⊙ct-1+it⊙tanh(WcDk+Mchk-1+bc)
(15)
hk=ot⊙tanh(ct)
(16)
这里,it、ft、ot以及ct分别是输入门、遗忘门、输出门和单元状态。
类似地,可以计算获得h1、h2、…、hk-1和hc,并得到隐藏序列seq″i
seq″i=(h1,h2,…,hk,hc)
(17)
预测ui偏好pc的概率受其之前访问过的POI的影响,且访问过的POI的影响权重是不同的。本文采用一种注意力机制,计算seq″i中隐藏向量 (h1,h2,…,hk) 的权重。具体地,使用单层神经网络求解隐藏向量 {hk-w,…,hk} 对应的隐藏值 {Kk-w,…,Kk}
Ki=Wzhi+bz
(18)
这里,i∈[k-w,k],w是注意力机制窗口大小。计算hc对应的查询值Q
Q=Wahc+ba
(19)
进一步地,本文为了更好地学习效果,采用多头注意力机制(multi-head attention mechanism)学习Ki和Q
(20)
Qmulti=Q1⊗…⊗Ql
(21)

(22)
利用βic,ui签到pc的向量表示为
(23)
结合Dc和Gc,本文采用多层神经网络结构计算ui签到pc的概率。首先,利用一个单层神经网络将Gc映射为一个与Dc相同维度的向量G′c
G′c=WGGc+bG
(24)
将G′c和Dc输入到L层神经网络中,求解ui签到pc的概率Pic
Pic=WTeL
(25)
这里,eL是通过以下方式学习得到
e1=W1(G′c⊙Dc)+b1……eL=WLeL-1+bL
(26)
最后,为了能得到最优的学习效果,本文给出如下损失函数
(27)
这里,c+是来自于ui偏好POI的候选对象中正样本,c-是正样本对应的负样本。
5 实验与结果分析
文中所涉及到的算法均在WIN 10环境下使用Python实现,并在具有1755 MHz 23 GD6 GeForce RTX 2080 Ti GPU和64 GB内存的服务器上进行实验验证。这一节,本文将从实验数据集、参数设置、评价标准、对比方法以及实验结果5方面进行说明。
5.1 数据集
本文采用的是来自LBSNs中广泛被使用的数据集Foursquare Dataset(https://foursquare.com)。本文对数据集进行预处理,首先选定用户的签到序列,规定一天内签到POI属于相同序列,并过滤掉异常数据,即删除用户(这些用户是签到POI记录不足10条或者签到不同POI的数量小于5);删除POI(这些POI被签到总次数不足10次);删除POI序列(这些签到序列长度小于3)。最终获得表1所示的数据集,其中用户数量为2293,POI数量为7873,POI类别数量为186,所有用户签到记录总量为447 547,则可计算出数据的稠密度为2.48%。本文将Foursquare数据集中的80%作为训练集,其余20%作为测试集。为了更好地训练和测试,对于每一个签到序列,本文将第k+1次签到的POI作为候选POI,前k次签到作为已发生签到。

表1 数据集信息
5.2 参数设置
本文提出的模型中涉及的参数主要包含POI类别信息权重γ和矩阵分解模型维度K。使用网格搜索技术(gird search),设定γ=0.4且K=20时,模型性能最优。
5.3 对比方法
为了评估本文提出的用户实时偏好感知POI推荐方法的有效性,本文选择了以下4种对比方法:
UCGSMF[13]:该模型建模了POI地理特征和用户社会关系对用户偏好的影响,并将POI类别信息融合到用户的自身偏好模型中。联合地理影响、社会影响及自身偏好模型进行POI推荐。
ST-RNet[2]:该模型建模了POI地理信息向量表示、用户社会关系向量表示和POI流行度向量表示,并联合时间信息输入到神经网络中学习用户偏好低维度向量,以完成POI推荐。
SSTPMF[3]:该模型基于时间、空间、POI类别和社会关系,建模了用户相似度和POI相似度模型,并将其融入到概率矩阵模型中,进行POI推荐。该模型上当前最新研究工作之一。
RTPAR:本文提出的模型,该模型利用地理信息和时间信息建模了用户实时偏好向量表示,联合社会信息、POI类别信息以及用户历史签到信息建模了历史偏好向量表示。融合两种向量并输入到循环神经网络中预测用户实时POI。
5.4 评价标准
本文采用推荐系统中最常用的两个评价标准,准确率(precision@k)和召回率(recall@k)。具体如式(28)和式(29)所示
(28)
(29)
这里,#k表示top-k推荐列表中的POI,表示测试集中用户访问过的POI。
5.5 实验结果
首先,本文评估不同模型在top-1、top-3和top-5推荐情况下的性能,结果见表2。从结果可以发现,RTPAR在所有对比方法中取得最优的结果,这得益于RTPAR对于用户的实时偏好的建模。UCGSMF、ST-RNet和SSTPMF均考虑了多种上下文因素的影响,但是这些方法是利用用户历史签到特征,未考虑用户实时的偏好变化。尽管用户每天的实际签到存在周期性规律,但随着签到轨迹的变化,其偏好也随之动态地调整。RTPAR不仅考虑了用户实时需求,而且充分地建模了用户历史偏好。所以,比较于之前的方法,性能得到了提升。具体地,较SSTPMF,准确率和召回率分别平均提升了8.7%和8.3%。
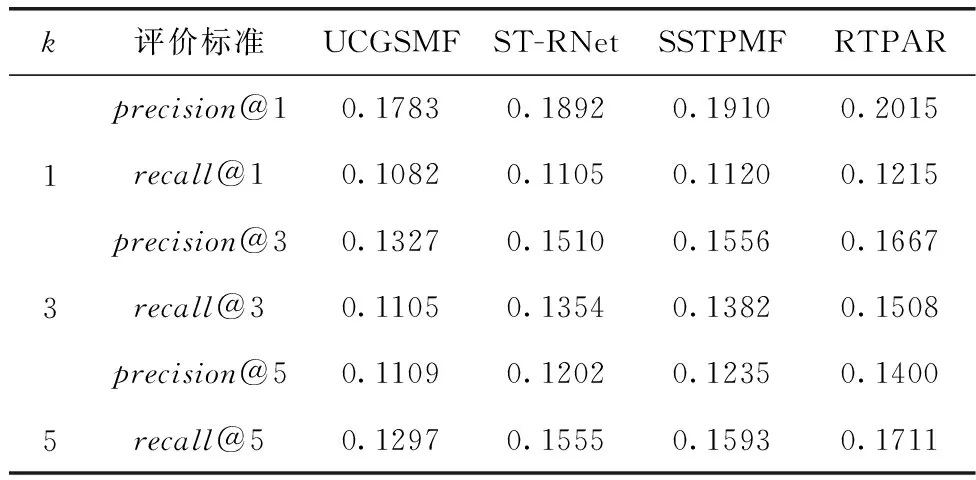
表2 top-k推荐时模型性能对比
进一步地,本文对推荐模型在冷启动情况下的性能进行测验。给定用户签到记录n=1、n=3和n=5,分别预测只有1次、3次和5次签到记录的用户POI。结果见表3,RTPAR仍优于其它所有的对比方法。推荐冷启动问题是推荐系统中常见的问题,是指在用户的签到数据极少情况下实现POI推荐。UCGSMF、ST-RNet和SSTPMF通过建模上下文,如社会关系、地理信息和时间信息等,来弥补数据的不足。本文在此基础上,进一步建模了用户实时需求,而且在无法获得用户历史偏好情况下,用户实时偏好模型更加能够表达该用户的POI。冷启动情况下,相比于SSTPMF,在准确率和召回率分别平均提高了6.55%和6.02%。

表3 冷启动情况下模型性能对比
最后,本文评估了参数γ和K对模型RTPAR的性能影响。如图1所示,γ取0、0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9和1。从图中可以发现,γ的取值对模型的性能有较大影响,合适的γ值能够进一步提升模型性能,而其它的γ值会影响模型的性能。这里,当γ=0.4时,模型性能达到最优。
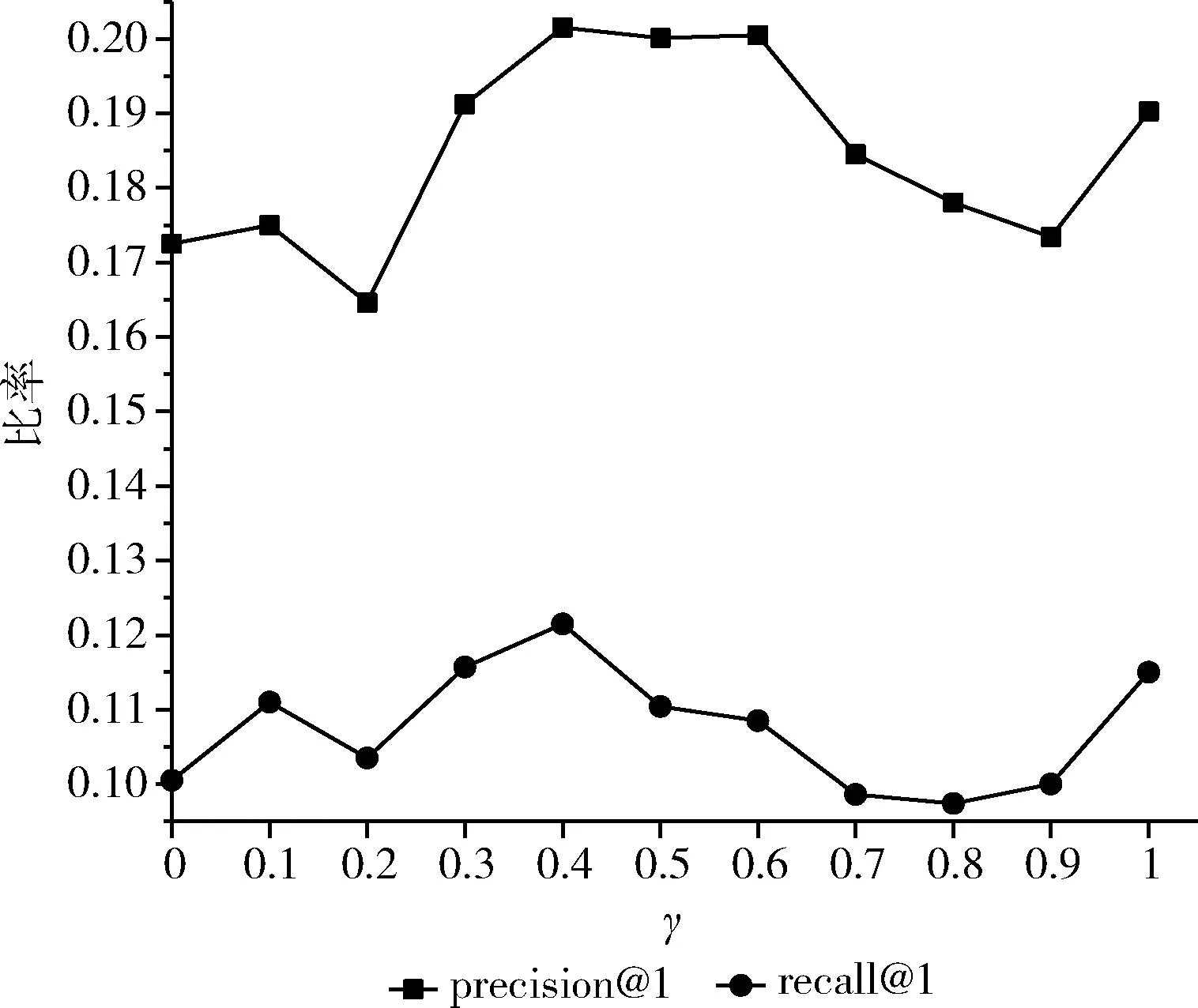
图1 参数γ对RTPAR的影响
如图2所示,潜在向量的维度K取5、10、20、30和40。当K≤20时,随着K值增大,模型性能不断提高。当K>20时,模型性能下降。这里,K=20时,模型性能达到最优。
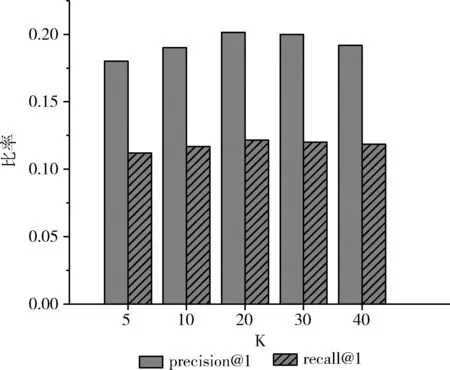
图2 参数K对RTPAR的影响
为了评估RTPAR中不同上下文因素的影响,本文使用控制变量方法从RTPAR中删除地理信息(RTPAR-G)、删除时间信息(RTPAR-T)、删除社会信息(RTPAR-S)以及删除POI类别信息(RTPAR-Ca)分别进行实验,结果如图3所示。从结果中不难发现,每一种上下文信息均对RTPAR性能的提升做出了贡献。其中,贡献从大到小依次为:地理信息>时间信息>社会信息>POI类别信息。
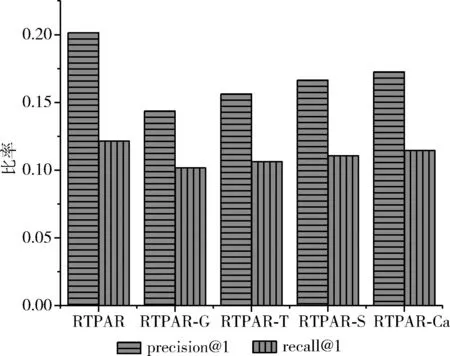
图3 不同上下文信息对RTPAR的贡献
6 结束语
针对大多现有POI推荐模型不能满足用户实时偏好需求,本文提出了一种基于循环神经网络学习的用户偏好实时感知POI推荐模型。该模型主要从两方面建模了用户偏好。一是通过利用签到的地理信息和时间信息对用户实时偏好进行向量表示。二是使用用户历史签到数据,通过矩阵分解框架学习用户偏好,并结合POI类别信息和用户社会关系,学习用户历史偏好嵌入表示。融合用户实时偏好向量和历史偏好向量,并将其输入到一种基于注意力机制的循环神经网络中,预测目标用户的实时POI概率。通过在Foursquare数据集上的大量实验,验证了本文所提出的模型比现有流行的推荐方法更具优势。同时也说明了本文提出的实时POI感知模型的可行性和有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新校长(2016年8期)2016-01-10 06:43:59
新高考·高二数学(2015年11期)2015-12-23 18:17:44
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
