
基于动态多头注意力机制的藏文语言模型
2023-12-20 02:34:12张英,拥措,于韬
计算机工程与设计 2023年12期
张 英,拥 措+,于 韬
(1.西藏大学 信息科学技术学院,西藏 拉萨 850000;2.西藏大学 藏文信息技术教育部工程研究中心, 西藏 拉萨 850000;3.西藏大学 西藏自治区藏文信息技术人工智能重点实验室,西藏 拉萨 850000)
0 引 言
目前,注意力机制在预训练模型如BERT[1]、RoBERTa[2]、ALBERT[3]中得到了广泛的应用。相关研究表明,多头注意力中并不是每个头都发挥着重要作用,大多数注意力头实际上是冗余的[4];为了减少冗余注意力的影响,研究者提出了“disentangled”[5]掩码注意力机制和自适应注意力机制[6]等概念。由上述研究可知语言模型固定注意力机制的头数并不是最优选择,在模型训练过程中,不同词数的句子均由相同头数的注意力机制进行特征学习,可能会造成注意力头的冗余。
为了减少冗余头数造成的干扰,例如在包含特征相对较少的短句中,可能不需要关注罕见词或某些复合关系等不常见的特征,从而导致多余的头对特征向量造成一定的噪声。因此本文提出了在训练过程中根据长短句动态选择注意力机制头数的方法。另外,目前国内对藏文预训练模型的研究较少,所以本文在藏文数据上进行探究。综上所述,本文共提出以下方案:①研究动态多头注意力机制的有效性,并揭示了将其融入预训练模型可以有益于文本分类任务;②在ALBERT模型的注意力层进行改进,并提升了该模型的效果;③本文构建的模型可以较好地表示藏文语义关系,实验结果表明,在公开数据集TNCC分类任务上F1值均获得了2%以上的提升。
1 相关工作
自以多头注意力为核心创新的transformer模型被提出以来,已成为一大研究热点[7]。Paul Michel等提出部分注意力头较冗余的看法;E Voita等[8]为了优化Bert模型设计混合向量提取注意力头捕捉的通用信息;随后,Clark K等[9]针对BERT注意力机制进行分析,发现注意力机制除了关注直接宾语、介词关系等,还大量集中于分隔符、标点符号。为了增强序列学习表示,Chien等提出了一种新的“disentangled”掩码注意力机制,以减少冗余特征。上述研究表明,注意力机制头数的固定,可能会造成注意力头的冗余或过度注意。
注意力机制通常用于预训练模型。OpenAI提出了GPT[10]模型,以学习文本的长距离依赖。随后,Devlin等提出BERT模型,在不同自然语言处理任务上达到了最好效果。OpenAI提出了在BERT基础上进行精细调参的RoBERTa模型。同年,Zhenzhong Lan等提出用两种策略提高模型训练速度的ALBERT模型,该文结果表明注意力层的参数共享策略对模型效果影响小,因此本文将在参数量较小的ALBERT模型的自注意力层上进行改进,以提升该模型的效果。
上文介绍的模型大多应用在中英文上,对于语料稀少的藏文而言预训练模型较少。Ziqing Yang等提出了面向少数民族语言的多语言模型CINO[11]。为了促进藏文自然语言处理任务的发展,Yuan Sun等提出使用藏文语料进行训练的TiBERT[12]模型。除此之外,Hanru Shi等构建了包含5种语言的MiLMo[13]模型。同年,于韬等[14]提出用于关系抽取任务的藏文ALBERT模型。另外,安波等[15]训练藏文BERT模型并在标题分类任务上进行实验。上述皆是对藏文预训练模型的应用研究,因此本文将对语言模型进行改进,以增强藏文下游任务性能。
2 方法与模型
2.1 动态多头注意力机制方法
自注意力机制是指通过运算获得句子在编码过程中每个位置的注意力权重,再计算整个句子的隐含向量[16]。同时,为了避免模型对当前位置信息进行编码时,过度集中于自身从而提出了多头注意力机制。与使用单独的注意力池化不同,多头注意力机制使用序列不同位置的子空间表征信息进行数据处理,然后并行地进行注意力池化,再将多个注意力池化的输出拼接,以构建最终输出[17]。
在以往的模型预训练过程中,多头注意力机制的头数h往往是固定的,但这样会存在一定的弊端,例如当h较大时,对于特征数量较少的句子会学习到更多不重要的特征,即在信息组合时会有一定的噪声;当h较小时,对于特征数量较多的句子,不能全面学习句子的含义。但在实际训练过程中,长短句所需要关注的信息数量并不同,如表1所示,长句共有56个藏文音节,包含的特征信息较多,需要更多头数的注意力机制关注句子中词与词之间的关系,如较为明显的时间、数词、处所等关系信息;而短句仅有11个藏文音节,包含的特征相对较少,相对长句来说较为明显的仅有处所关系,因此当长短句共用一个注意力机制头数时,多余的头可能会关注标点符号等包含信息量较少的特征,对特征向量的提取过程会造成一定的干扰。因此本文针对不同词数的句子均由相同头数的注意力机制进行特征学习这一情况,提出根据句子的特征数量选择注意力机制的头数,即在训练过程中根据句子长度动态确定注意力机制头数。

表1 藏文长短句示例
其动态多头注意力机制具体公式如下所示,式(1)中headi表示第i个头数对应的注意力机制运算后的结果[18],式(2)中DMA(Q、K、V) 表示将多个注意力机制head1,…,headh进行拼接再乘以矩阵Wh的结果,其中Wh为多头注意力的权重,下标h的取值根据len_token决定,如式(3)所示
(1)
DMA(Q,K,V)=Concat(head1,…,headh)Wh
(2)
iflen_token>mh=hlelseh=hs
(3)
图1为动态多头注意力机制的架构。首先将输入句子的词向量转化为3个矩阵(Q、K、V),再判断句子的词数(len_token)是否大于临界值m,若小于m,则动态多头注意力机制取较小的头数,再根据头数构建hs层线性投影,然后将Q、K、V输入至左侧的路线left route进行学习,并通过hs层线性投影获得特征向量矩阵,最后进行拼接与映射获得输出结果;反之,动态多头注意力机制取较大的头数,除线性投影层数hl与路线right route之外,其余操作同理。
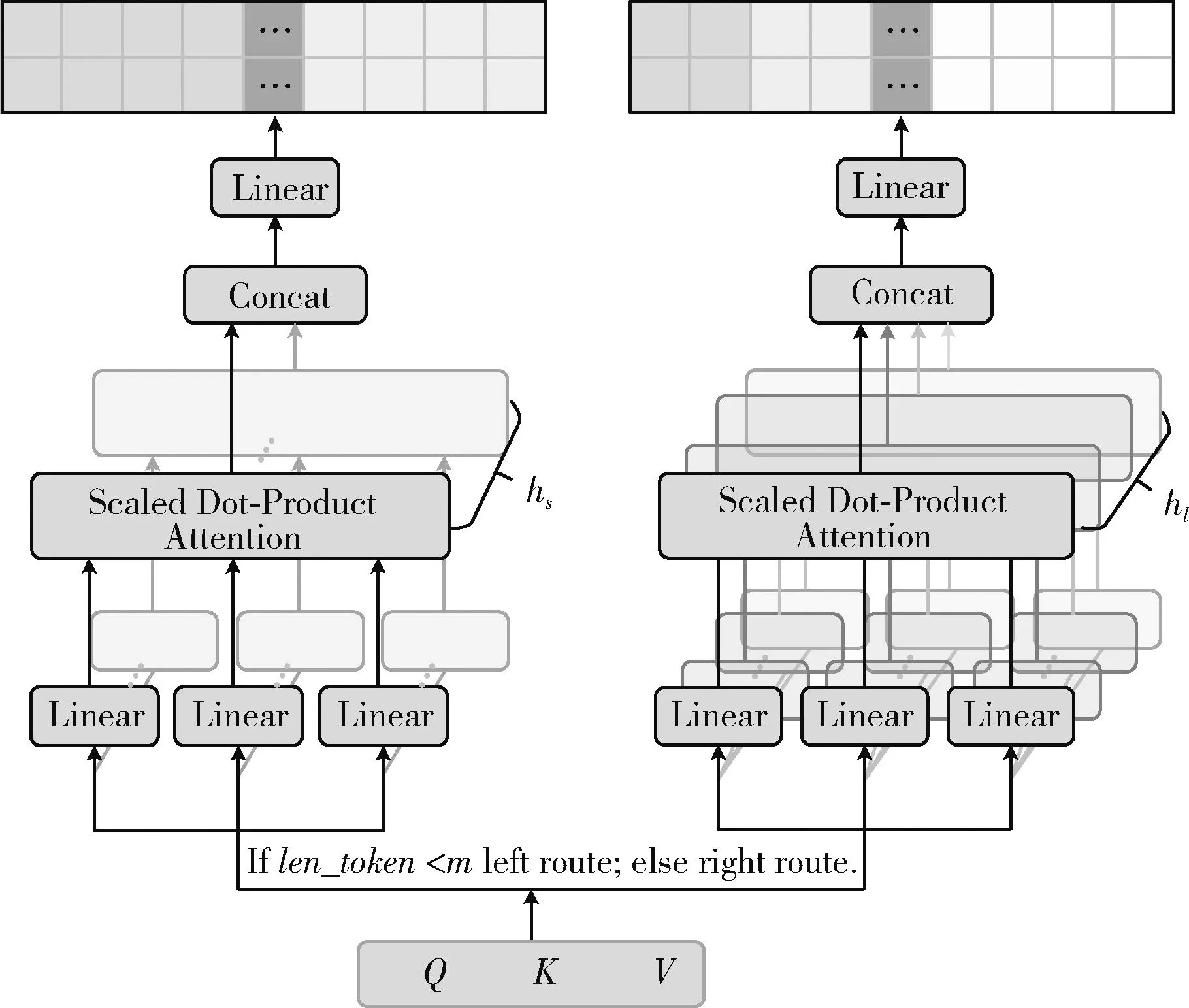
图1 动态多头注意力机制架构
2.2 基于动态多头注意力机制的语言模型
为解决BERT模型参数量过大、训练时间过长的问题,ALBERT语言模型于2019年问世,该模型的结构和BERT相似且参数量更小,本文将上述提出的动态多头注意力机制应用于ALBERT的注意力模块,构建了基于动态多头注意力机制的语言模型(dynamic multi-head attention albert,DMA_ALBERT)。为了验证改进后的模型的有效性,本文使用4.5 GB藏文通用领域数据分别训练注意力层改进前后的模型。将动态注意力机制应用在语言模型中,动态传递注意力机制的头数,既可以获得该句子的重要信息,学习句子上下文相关的双向语义特征表示,又可以减少不重要的特征对信息整合过程的干扰。
由于预训练模型结构较为复杂,且训练数据量较大,因此动态多头注意力机制的头数选择方式由每句的总词数改进为每批次(batch)的总词数。即在藏文DMA_ALBERT模型的实际训练过程中,动态多头注意力机制的头数根据一个batch的总词数获得,当总词数大于m与batch的乘积(m×batch)时,该批次的注意力机制头数h取hl;反之,h取hs,如式(4)所示,其中token_Ci表示在当前批次中第i个句子的token个数
(4)
3 实验数据与评价指标
3.1 ALBERT模型训练数据及评价指标
本文采用CCL2022跨语言文本分类任务提供的4.5 GB藏文语料作为语言模型的训练数据,语料主要来自维基百科、微信公众号。同时,本文训练SentencePiece[19]模型以构建藏文词表及训练语料。分词粒度方面,选用unigram[20]对训练语料进行子词级分割,其原理为先初始化一个较大的词表,再根据算法标准不断地舍弃,直到词表满足预先给定的大小[21]。在藏文语言模型的训练过程中,由于使用ALBERT预训练模型作为实验的基础,因此参照ALBERT原文共选取了5个评价指标,分别是掩码语言模型(MLM)任务的损失值(mask_loss)、预测遮掩单词的精确度(mask_accuracy);句子顺序预测(SOP)任务的损失值(sop_loss)、预测句子顺序的精确度(sop_accuracy);以及MLM和SOP任务这两部分的损失和相加所得到的总和(loss)。
3.2 文本分类数据及评价指标

由于本文使用TNCC测试语言模型的实际效果,使用精确率Precision、召回率Recall以及F1值作为文本分类任务的评价指标,具体公式如下所示
(5)
(6)
(7)
其中,首先需要计算每个类别的Precision、Recall、F1值,其中TPi表示类别i预测正确的数量;FPi表示将其它类别的样本预测成类别i的数量;TPi+FPi表示测试集的所有文本预测成类别i的总数量;FNi表示将文本类别i预测成其它类别的数量;TPi+FNi表示真实的文本类别i的总数量。
另外该数据集是在多类别通用领域上构建的,其样本分布并不均匀,因此采用Weighted算法对上述指标进行计算,即需要根据每个类别占比的权重计算本次分类所有类别评价指标的具体值,如式(8)~式(10)所示,其中wi表示在测试集中文本类别i在总文本中的占比比例
(8)
(9)
(10)
4 实 验
4.1 实验设置
本文训练tiny版本的藏文改进注意力机制前后的语言模型并进行效果对比,在训练前需确定模型中注意力机制的头数。其中隐藏层维度的值为384,而注意力机制的头数需要被384整除,即可取值2、3、4、6、8等,考虑到语言模型结构的复杂性,本文选择如表2所示的注意力机制头数进行实验,具体训练参数见表3。
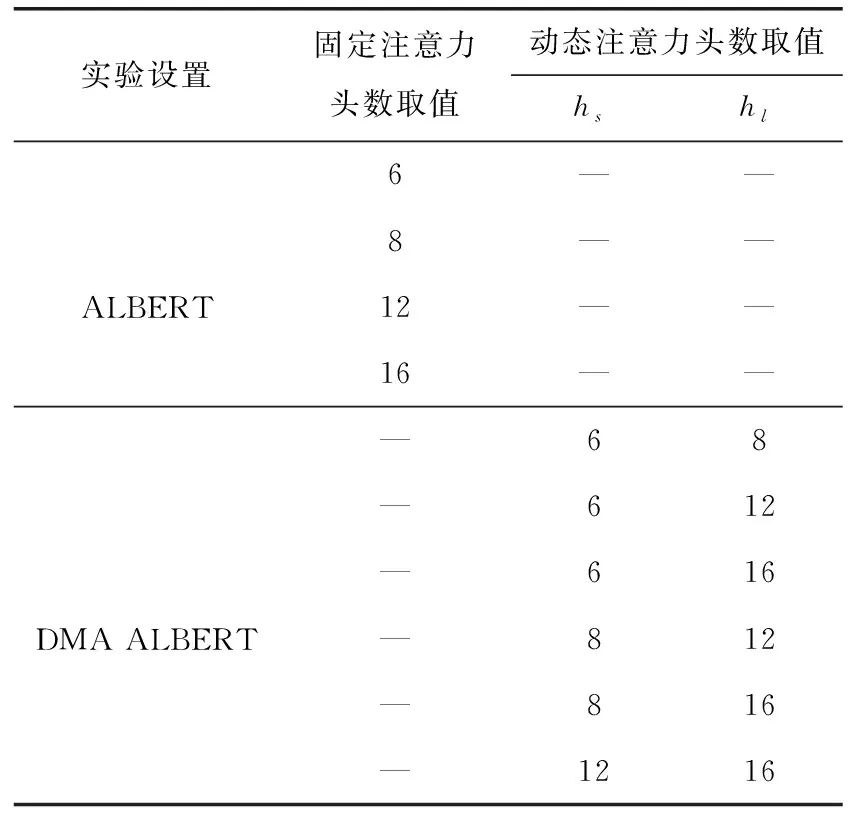
表2 注意力机制头数设定

表3 预训练模型主要参数
由表2可知,本文共设计了10组语言模型对比实验,分别是4组原始的语言模型以及6组应用动态多头注意力机制的语言模型。实验环境为搭配RTX3080Ti GPU的Ubuntu服务器,显存为12 GB。
为了更好地对比是否动态获取注意力头数语言模型的效果,本文将上述10个预训练模型应用在文本分类任务上,包括长、短文本两种分类任务,这两个任务的句子长度分布情况如图2所示。

图2 TNCC数据集句子长度分布
由图2(a)可知,长文本中各句子长度区间的分布较为均匀,综合考虑训练设备及预训练模型的句子长度取值要求,该任务的pad_size取值为300;而图2(b)中的短文本中99%的标题长度小于20,且最长不超过50,因此短文本任务的pad_size取值为50,下游实验的主要参数见表4。

表4 下游实验部分主要参数
4.2 实验结果
首先将本文训练的10组语言模型应用于TNCC文本分类任务,并观察模型在长、短文本分类任务上的效果;然后使用10组预训练语言模型分别结合卷积神经网络(CNN)[22]进行文本分类的对比实验。
4.2.1 固定与动态头数语言模型实验对比结果
TNCC数据集包含藏文长文本及短文本分类语料,将10组训练好的藏文语言模型分别应用在长/短文本分类任务上,实验结果见表5,‘/’前后分别为长文本分类结果和短文本分类结果。在长文本下游分类任务中,使用ALBERT模型时,head取8、16时F1值分别为73.29%、72.79%,而使用融入了动态多头注意力机制思想的语言模型时,hs、hl取8、16时实验F1值为75.34%,与前者相比F1值分别提升了2.05%、2.55%。该结果表明:在训练过程中,语言模型动态获取注意力机制头数时效果更佳,同时改进语言模型中除hs=6、hl=8的其余4组实验均能验证动态多头注意力机制的有效性。但当固定头数取6或8时F1值为74.63%、73.29%,而hs、hl动态取6、8时F1值为73.67%,较头数直接取6时F1值下降了0.96%,取8时提升了0.38%。该情况的主要原因是应用动态多头注意力机制时,动态选择的两个头数均较小且相差不大,因此无法较好地学习长、短句的语义特征,导致模型效果提升不明显。
在表5中的短文本分类结果表明,头数取12时模型效果表现最好,其F1值为68.74%,而应用了动态多头注意力机制思想的语言模型F1值最高为67.25%,较前者F1值低了1.49%,由此可见,动态多头注意力机制在短文本分类上效果较为低迷,其原因为标题浓缩了一篇文章的主要内容,且词数不超过20的标题数量占比99%,标题中词与词之间的语义关系并不明确,即根据藏文长文本训练的DMA_ALBERT模型,对标题的理解能力有限,对藏文标题分类任务的帮助较小。
4.2.2 语言模型结合卷积神经网络对比实验结果分析
表6为固定与动态头数的语言模型分别结合CNN模型在长/短文本分类任务上的实验结果。长文本中,hs、hl动态取8、12时效果最好,其Weighted F1值为75.69%;在不使用动态多头注意力机制的ALBERT模型中,head取8时效果最好,其Weighted F1值为74.80%。后者F1值降低了0.89%,该结果表明在进行长文本分类时,动态获取其注意力机制的头数效果优于非动态方式。根本原因是动态多头注意力机制可以更好地学习长、短句中的语义关系,而非动态方式由于固定了头数的大小,直接制约了其对语义关系的学习能力,因此DMA_ALBERT模型构建的词向量质量更高,再使用模型结构相对复杂的CNN网络的卷积及池化操作可以较好地学习词向量中的重要分类特征。与直接使用DMA_ALBERT模型相比,结合CNN模型时长文本分类效果更好,后者较前者F1值提升了0.35%。
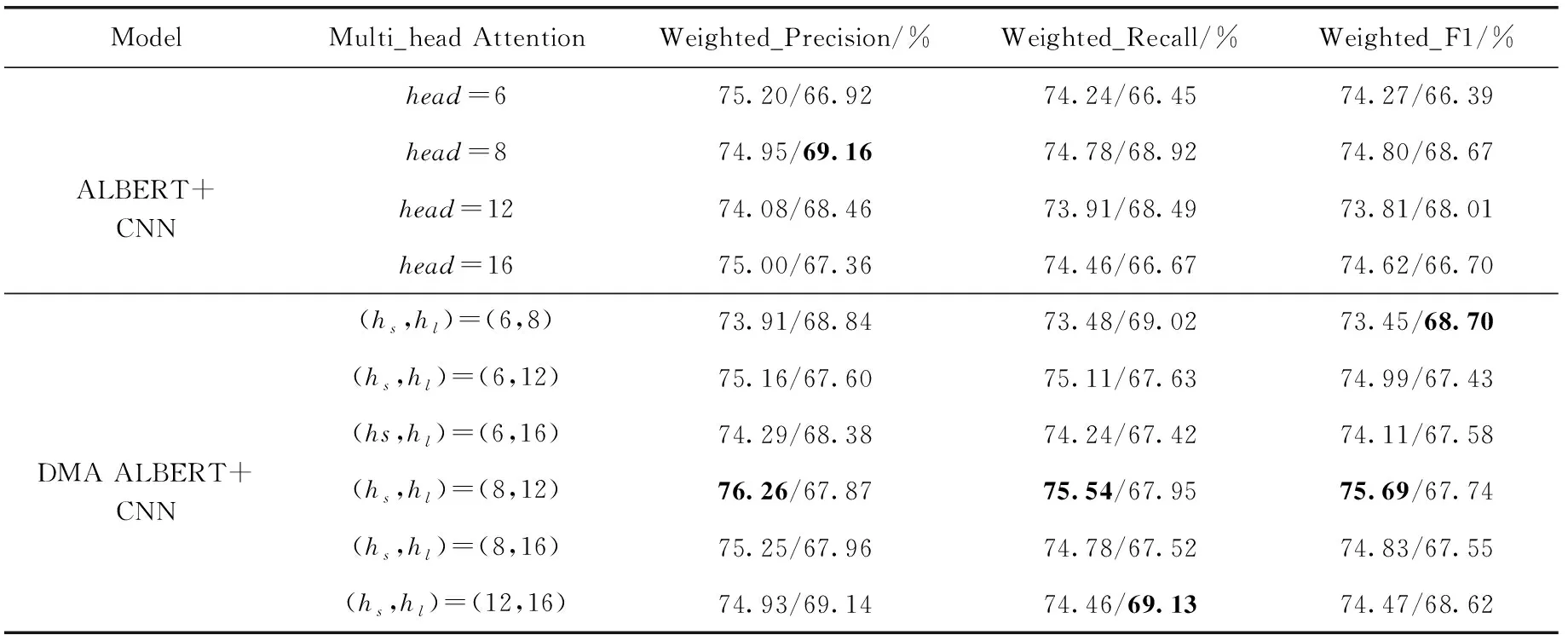
表6 预训练模型结合卷积神经网络在长/短文本分类任务上的实验结果
由表6的短文本分类结果可知DMA_ALBERT与原始ALBERT在短文本分类任务上的效果相近,固定头数取8时模型效果最好为68.67%;hs、hl动态取6、8时语言模型效果最为68.70%,两者仅相差0.03%。该结果表明在结合CNN模型的短文本标题分类任务上,由于使用长文本训练的语言模型对标题的学习能力有限,因此对模型结果影响甚微。
为了更好地对比本章实验结果,将上述结果使用折线图进行可视化展示,如图3所示。其中,h=6表示使用固定头数为6的注意力机制;h=6,8表示动态使用头数为6、8的注意力机制,即曲线前后段分别为原始语言模型的结果、结合动态多头注意力机制的语言模型的结果,上、下两条曲线分别为长文本分类、标题分类。
由图3可知,长文本分类任务中,两条实验结果曲线的后半段整体趋势均高于前半段,表明动态获取注意力机制的头数效果更优。在不结合CNN模型的短文本分类中,原始语言模型效果更好;而结合CNN模型后,曲线后半部分更稳定,表明CNN网络能较好地学习DMA_ALBERT所得到词向量的重要分类特征。

图3 预训练语言模型结果对比
4.3 与其它模型的对比实验结果分析
为了验证本文模型的有效性,将本文训练的语言模型与现有模型效果进行对比分析,其中DMA_ALBERT模型各评价指标的具体值见表7。所对比的模型分别为:哈工大讯飞实验室发布的CINO模型、藏文TiBERT模型、安波等提出的藏文BERTCNN模型,其评价指标皆采用Macro计算方式,因此采用Macro相关指标与前人的模型在TNCC文本分类任务上进行对比。其中长、短文本分类任务对比结果分别见表8、表9。
由表8可知,DMA_ALBERT结合CNN模型效果最佳,hs、hl分别取8、12时模型F1值为73.23%,较CINO提升了4.63%;较TiBERT提升了2.29%;在表9中,DMA_ALBERT结合CNN时效果最佳,hs、hl分别取6、8时模型F1值为64.47%,较BertCNN提升了11.47%,较TiBert提升了2.75%。实验结果再次说明了融入动态多头注意力机制思想的语言模型的有效性。
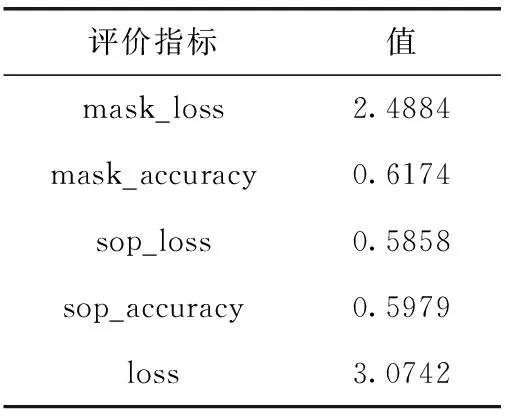
表7 hs、hl动态取8、12时语言模型评价指标
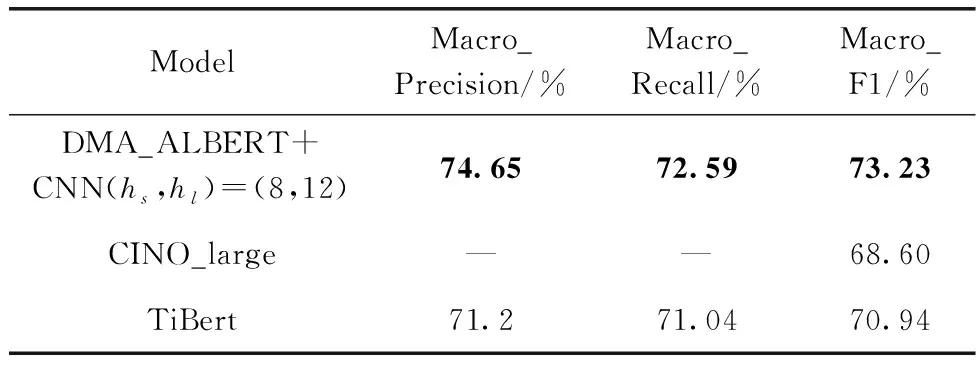
表8 不同模型在长文本分类任务上的实验结果对比
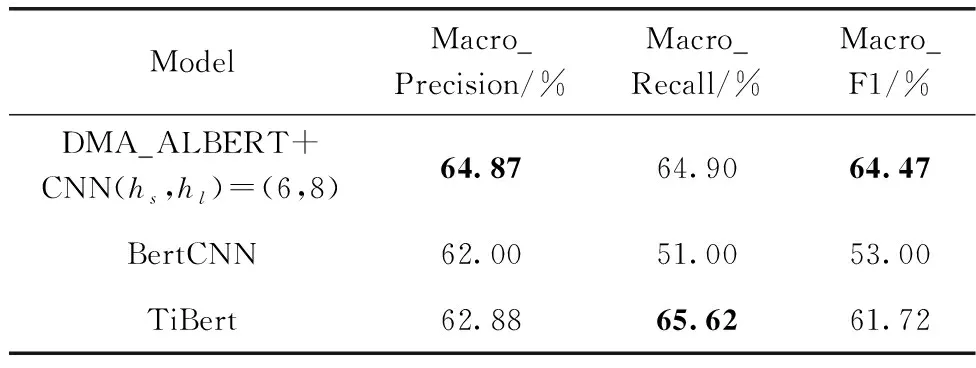
表9 不同模型在短文本分类任务上的实验结果对比
5 结束语
本文主要针对不同词数的句子均由相同头数的注意力机制进行特征学习这一情况,提出了动态获取注意力机制头数的思想。并在TNCC数据集文本分类任务上分别进行了实验,实验结果表明,应用了动态多头注意力机制的语言模型效果最优。
与前人的模型相比,本文模型在不同任务的Macro_F1值均提升了2%以上,再次验证了该文方法的有效性。在未来的工作中,将继续研究注意力机制头数与句子长度的关系,并进一步扩大语言模型训练语料的规模,或者利用语料较多的中、英文数据检验本文的方法,并在权威数据上验证其效果。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
湖北畜牧兽医(2021年11期)2021-02-23 10:04:20
浙江畜牧兽医(2020年3期)2020-06-22 08:49:54
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
传媒评论(2017年3期)2017-06-13 09:18:10
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
新闻传播(2016年17期)2016-07-19 10:12:05
读写算·小学低年级(2016年4期)2016-05-30 10:48:04
