
多模态大模型驱动的学科知识图谱进化及教育应用*
2023-12-20 01:21罗江华张玉柳
现代教育技术 2023年12期
罗江华 张玉柳
多模态大模型驱动的学科知识图谱进化及教育应用*
罗江华 张玉柳
(西南大学 西南民族教育与心理研究中心,重庆 400715)
当前,以GPT-4为代表的多模态大模型正在促进通用人工智能向多模态融合的方向发展。受益于多模态思维链、涌现能力和提示工程等应用技术,学科知识图谱能够更好地形成一种将抽象的符号概念和多模态的数据加以关联的智能扩展范式,有效解决现有图谱构建中存在的诸多不足,进一步推动多模态学科知识图谱的创生,为智慧教育服务的发展提供有力的支持。基于此,文章首先解构多模态大模型与学科知识图谱的关系;然后,文章探析了多模态大模型对学科知识图谱的驱动前提,从进化角度探讨多模态学科知识图谱的基本内涵和构建框架;最后,文章提出多模态学科知识图谱的四大教育应用场景,包括推动教育资源多元聚合、助力智能教学产品开发、赋能学科资源个性推荐以及促进人机协同智慧教学,以期为学科知识图谱的相关研究提供借鉴与启发。
多模态大模型;多模态数据;学科知识图谱;多模态学科知识图谱;教育应用
引言
2021年,我国教育部等六部门印发《关于推进教育新型基础设施建设构建高质量教育支撑体系的指导意见》(下文简称《指导意见》),提出通过构建学科知识图谱(Discipline Knowledge Graph,DKG),对数字教育资源的学科知识脉络进行语义建模和关联表示,以图模型赋能数字教育资源新基建[1]。在《指导意见》的引领下,我国教育部门开始积极探索DKG的教育应用。从实践效果来看,DKG已成为“新资源”的重要支撑要件,为智慧教学模式的发展提供了丰富的理论基础和坚实的技术支撑[2]。但现有图谱构建方法仍存在诸多不足,不仅构建效率低、人工成本高,而且多数只考虑单一文本数据,忽略了多模态数据的特征表示和语境信息[3]。由此,如何将现有学科知识脉络与图像、视频等多模态数据进行关联表征并构建多模态学科知识图谱,成为当前发展智慧教育服务亟待解决的问题之一[4]。
当前,大模型已经从视觉感知和语言认知发展至多模态认知智能,促使人工智能够更好地为各种应用场景提供更强大的支持。研究发现,基于多模态大模型(Multimodal Large Language Model,MLLM),结合教与学需求进行下游教育任务适配与创新应用,将有利于解决教育领域的实际问题[5]。同时,MLLM的多模态思维链、多模态涌现能力以及多模态提示工程等应用技术也使其能够成为学科知识图谱的动力引擎,实现多模态化的认知体验信息与相应符号概念的关联,推动多模态学科知识图谱的创生。总而言之,新的“模型即服务”——MLLM+DKG+教育应用场景,能够促使教育领域产生智能涌现现象。基于此,本研究从MLLM与DKG的关系解构出发,阐述MLLM对DKG的驱动前提,并从进化角度探讨多模态学科知识图谱的内涵、构建框架与其教育应用前景,以期为DKG的相关研究提供借鉴与启发。
一 多模态大模型与学科知识图谱的关系解构
1 多模态大模型
大模型是指具有海量参数和复杂架构、用于深度学习任务的模型[6],其经历了单语言预训练模型、多语言预训练模型和多模态预训练模型等发展阶段。其中,单语言预训练模型、多语言预训练模型属于单模态大模型,无法同时处理其他模态信息,这在很大程度上限制了其应用范围和性能。2018年BERT、GPT等大模型的崭露头角标志着通用大模型时代的开启,也代表了人工智能领域的第三次范式转变[7]。这些模型的出现不仅为处理多模态数据铺平了道路,也拓宽了大模型的应用范围。从2019年开始,一些模型开始把Transformer作为核心结构进行拓展,视觉和语言嵌入特征可以同时作为输入,在处理多模态数据时表现出更强大的性能和灵活性。
为实现更加通用的人工智能模型,多模态学习的必要性慢慢展现,它是一种涉及不同模态数据的机器学习任务,旨在将这些不同模态的信息整合起来,以提供更全面和丰富的呈现。随着GPT系列模型在自然语言处理领域的不断成熟发展,MLLM迎来了新的发展机遇。与传统的单模态大模型相比,MLLM通过联合建模和预测的方式,能够更好地利用不同模态之间的相关性和交互信息,提高模型的预测性能和泛化能力;而MLLM的思维链和涌现能力,是其不断接近人类思维的关键特征。现阶段,MLLM主要以多语言训练模型为核心,专注多模态内容之间的关联特性与跨模态转换问题。随着生成技术的不断成熟,基于领域知识构建跨场景、多任务的MLLM成为新一代人工智能的重点方向。
2 学科知识图谱
DKG作为KG在教育领域的应用,是一种支持具体学科教学设计与资源组织管理的教育KG[11]。它为教育教学提供了学科知识结构的清晰化表达,是新型教育资源的重要组成部分,也由此成为智慧教育的重点攻坚领域。例如,李艳燕等[12]从智慧教育的角度讨论了DKG的相关定义、构建技术和应用;张春霞等[13]基于数学类课程构建数学课程本体,并提出了基于数学课程本体的数学课程KG构建方法;张玉柳等[14]提出一种结合课程KG和学习者个体认知状态的模糊认知地图构建方法,为破解个性化推荐不足提供了参考。然而,DKG的构建仍然面临巨大的挑战:首先,学科知识富含教育领域专业性和复杂性,但目前的研究还未充分关注多模态教育资源的融合,导致以不同形式呈现的多模态场景被忽视,容易在资源智能组织中出现“信息茧房”[15]。其次,构建DKG需要海量数据,但要找到并收集高质量的数据绝非易事。学科知识是不断更新和动态变化的,其数据需进行持续更新和维护,以保证时效性和准确性。更为重要的是,不同学科领域具有独特的知识特点和结构,需根据学科特点选择适切的表示方式,再加上要考虑学科知识的丰富性和查询高效率等因素,要提高DKG构建效率也存在较大困难。近两年大模型浪潮备受瞩目,利用MLLM解决图谱构建过程中的挑战受到了越来越多研究者的关注。
3 两者的协同、竞争和竞合
在实际应用中,MLLM和DKG的发展关系可以描述为协同、竞争、竞合三类形态。需要注意的是,不同的发展关系在不同应用场景下具有不同的优缺点和适用性。在教育应用中,须根据教学问题和任务需求进行选择和优化,同时还需关注不同关系之间的衔接和创新,以推动大模型和DKG在教育领域的不断进化与成熟发展。
协同关系是指MLLM和DKG为了实现特定目标或效益而形成的一种协调关系。例如,在自然语言处理领域,MLLM可以通过学习大量模态数据来提高对自然语言的理解能力,而DKG则可为MLLM提供更为丰富和准确的知识库,能在一定程度上缓解当前模型输出的事实谬误问题,并具可解释性。根据Pan等[16]提出的前瞻性发展路线,当前MLLM和DKG的三种协同模式如图1所示,具体为:①利用DKG增强MLLM。DKG的优点在于领域知识结构化程度以及准确性高,在MLLM的预训练和推理阶段融入DKG,可加强MLLM对通用知识的理解。②利用MLLM增强DKG。MLLM的优势在于语言理解能力和泛化能力,通过MLLM可高效完成不同阶段DKG的构建任务。③MLLM+DKG协同。两者可以互相转化,以互利的方式共同作用,实现具有强大泛化能力和推理能力的认知智能。
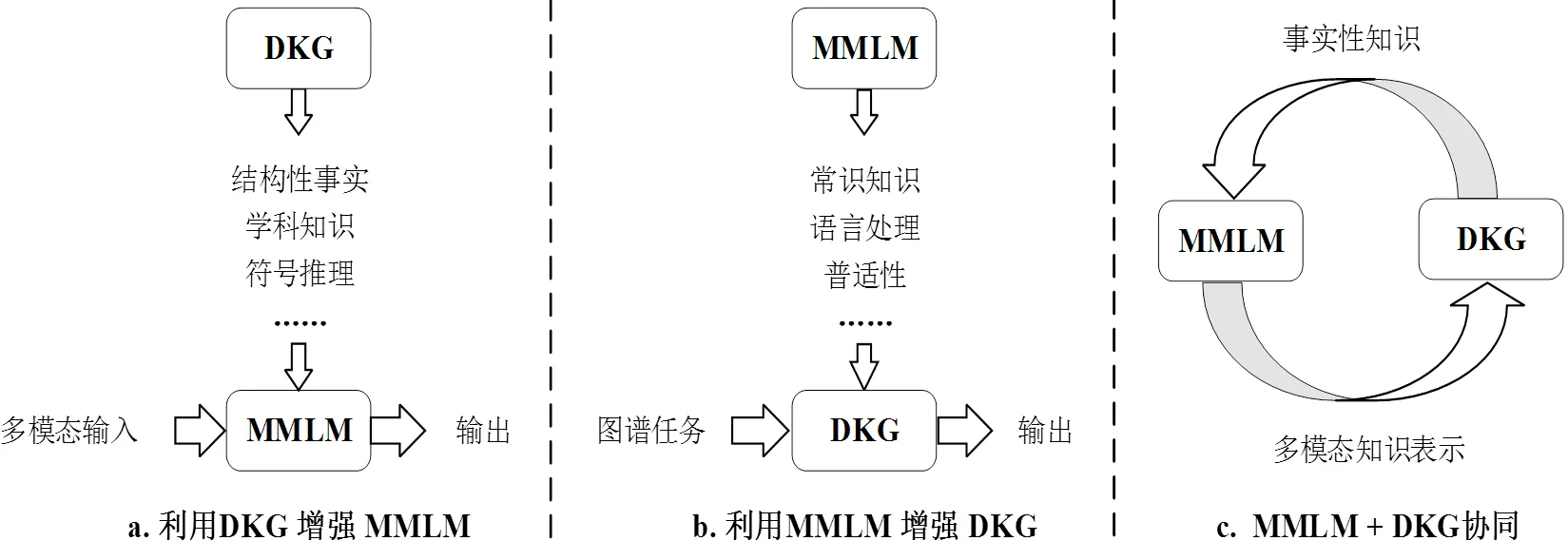
图1 MLLM与DKG的三种协同模式
MLLM和DKG亦存在竞争关系。MLLM虽然会对DKG产生一定的影响,但并不意味着DKG会被取代或者失去其价值。在特定应用场景下,两者在处理信息和解决问题时有着各自的优势和局限性,它们之间的竞争是主体为了获得不同的配置利益,在一定规则下开展的较量,其竞争主要涉及技术性能、原型搭建、产业链构建等。
竞合关系表示MLLM和DKG有时也会保持一种既协同又竞争的关系。此种关系存在的原因是两者都试图采用不同的方法和思路提高或倒逼领域发展水平。在这种情况下,两者必须适应不断变化的技术环境和社会需求,以确保其能够继续发展。此外,竞合关系也反映了人工智能研究中的一个核心问题:如何将不同的技术和方法结合起来,以实现更高效、精准、可靠的智能应用,实现优势互补。
二 驱动的前提:多模态大模型的应用技术创新
MLLM和DKG有其各自的特点和应用场景,亦相互融合和补充,两者可在教育应用中相互结合。具体而言,MLLM的多模态思维链、多模态涌现能力和多模态提示工程等应用技术创新,能够为DKG的智能扩展提供更大的可能性。
1 多模态思维链:跨感知模态的知识融合
思维链(Chain of Thought)的形成机制可解释为模型通过学习大量数据构建一个关于语言结构和意义的内在表示,并通过一系列中间自然语言推理步骤来完成最终输出[17]。而多模态思维链是通过观察大量多模态数据来学习其内在表示,然后利用此表示来生成连续输出的机制[18]。此内在表示包含多种模态数据之间的关联和语义信息,可实现对多模态数据的全方位理解和综合化推理。将其应用于MLLM中,能够使MLLM的响应更接近人类的思维方式,从而在认知推理任务中表现出更高的性能。具备多模态思维链的MLLM已经不是传统意义上的词汇概率逼近模型,而是能将一个多步骤的问题分解为单独的中间步骤、实现复杂推理能力的模型。
多模态思维链已被证明能够在复杂的认知推进过程中高效发挥作用,其不仅可以提示MLLM进行输出,还可以展现系列化的推理进程,是认知结构化的范例[19]。依托多模态思维链,MLLM可展开跨感知模态的知识融合,进而对复杂教育情境中的多模态数字教育资源进行智能挖掘和耦合计算[20]。这种跨感知模态的知识理解和融合,能够从图像、文本和语音等数据中提取特征和关联信息,促使DKG实现更加全面和多样化的表示。例如,MLLM可以利用多模态数据中的内隐知识,挖掘DKG中尚未包含的概念、实体或关系,从而产生新的知识和理解并推动学科知识的演化。从发展趋势来看,利用多模态思维链,MLLM得以精准识别并捕捉多模态数据中的隐含关系和规律,以高效支持DKG构建中的常识推理、符号操作等任务。
2 多模态涌现能力:完善和更新学科知识
涌现能力(Emergent Ability)是指大模型具有从原始训练数据中自动学习并发现新的、更高层次特征和模式的能力[21]。一般而言,较小的模型很难具备这样的能力,MLLM的数据规模是涌现能力出现的基础条件。这种能力在达到一定的临界规模阈值之前接近随机,之后性能显著提高,开始表现出一些开发者最初未能预测的、更复杂的能力和特性,如理解能力、生成能力和逻辑推理能力等。
MLLM是否具备涌现能力,是其能否支撑DKG进化的重要条件。事实上,MLLM必须通过学习多模态的海量级数据,才能实现知识涌现。但仅靠数据规模的增加并不能保证涌现能力的发生,还需要将海量的数据规模、合适的度量标准和训练方法等统合起来,进而诱发模型的涌现能力[22]。随着GPT-4的发布应用,MLLM能够从视觉角度和视觉-文字语义融合方面涌现出更多的能力。这些能力的出现不仅是简单的视觉或文本能力的叠加,也体现在其跨模态迁移更有利于改善知识呈现和应用的性能。鉴于此,利用多模态涌现能力,MLLM可以联结不同学科领域的多模态知识数据,自动理解、捕捉不同学科领域中隐藏的丰富而复杂的关联知识特征以生成跨模态知识,进而帮助实现多元融合的图谱构建任务。
3 多模态提示工程:提升图谱构建任务的操纵性
提示工程(Prompt Engineering)是一种方法论,其能够通过设计合适的提示信息和标记数据,帮助MLLM更加有效地理解和应用多模态数据,以生成用户所需的输出,从而提高模型的准确性和鲁棒性[23]。多模态提示工程在提高MLLM的可操纵性方面扮演着重要的角色,促使模型得以根据用户要求或多模态任务需求更改其行为。例如,用户可以通过设计相应的提示信息命令MLLM以不同的风格、语气或内容特征进行反馈,从而操纵模型的回答。针对多模态数据集,MLLM的提示工程包括选择合适的模型架构和参数、设计提示格式和结构、选择合适的任务和训练数据,以及使用选定的提示和数据微调模型等。形式上,多模态提示样本可以用三元组形式表示,即(),其中、、分别表示指令、多模态输入和真实反馈。
MLLM的提示工程能够有效避免仅依赖纯符号表示带来的理解限制。为高效构建DKG,MLLM可以利用提示工程设计学科领域规则、先验知识和图谱构建的约束条件等,辅助MLLM在精调阶段根据DKG的多模态构建任务对模型进行微调,选择合适的输入来提示MLLM理解,以便提升DKG构建的适应性和质量。
三 驱动的进程:多模态学科知识图谱的构建
知识图谱经历了从人工和群体智慧构建到利用机器学习、信息抽取等技术自动构建的过程,现如今已逐渐从单一的文本模态扩展到庞大的多模态共存[24]。MLLM具有强大的表示学习能力和涌现能力,利用其驱动DKG的进化,便是在传统DKG的基础上,为其增添多模态属性和关系的结构化表示的持续过程,即构建多模态学科知识图谱(Multimodal Disciplines Knowledge Graph,MMDKG),这也是降低DKG构建高成本的一个可行路线。
1 多模态学科知识图谱的内涵
MMDKG是以学科知识为核心,通过整合多种模态数据来丰富符号知识表达,包含多模态知识信息、多模态语义关系的知识图谱。参考领域内比较有代表性的DKG顶层本体[25],MMDKG的顶层本体如图2所示,其中多模态分面是指同一学科知识点所包含的不同模态属性。
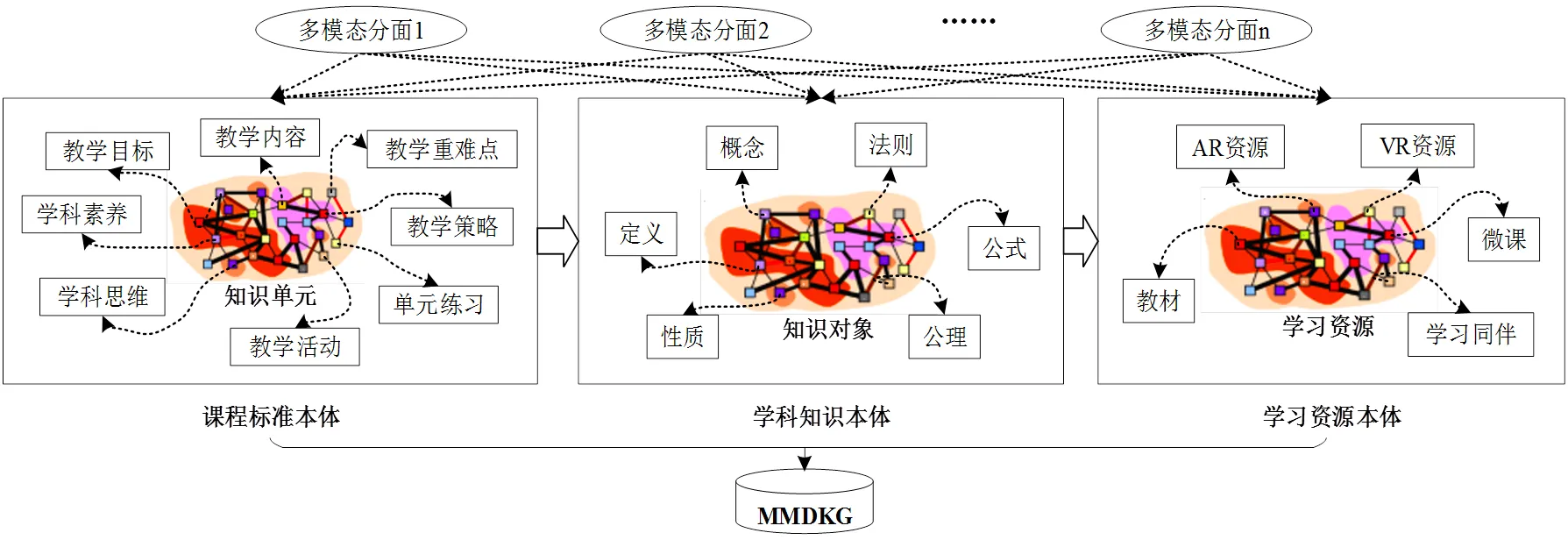
图2 MMDKG的顶层本体
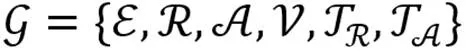
2 多模态学科知识图谱的构建框架
MLLM支持的MMDKG构建,是基于图论的符号推理与形式化方法的表达,旨在发挥MLLM之所长,建立跨模态数据之间的语义关联,将符号直接关联具体的视觉模态对象,为学科知识网络挂载多模态信息。MMDKG的构建框架如图3所示:首先,基于已有DKG和学科领域语料训练MLLM,将多模态学科数据融合以支撑下游多模态构建任务,如知识抽取、知识表示和知识推理等。然后,采用人类反馈强化学习进行多步决策的优化。MLLM可以根据人类反馈的奖励信号逐渐优化自身的性能,提高MMDKG构建的精准度。最后,通过多模态幻觉检测,实现更加精确和高效的MMDKG构建。
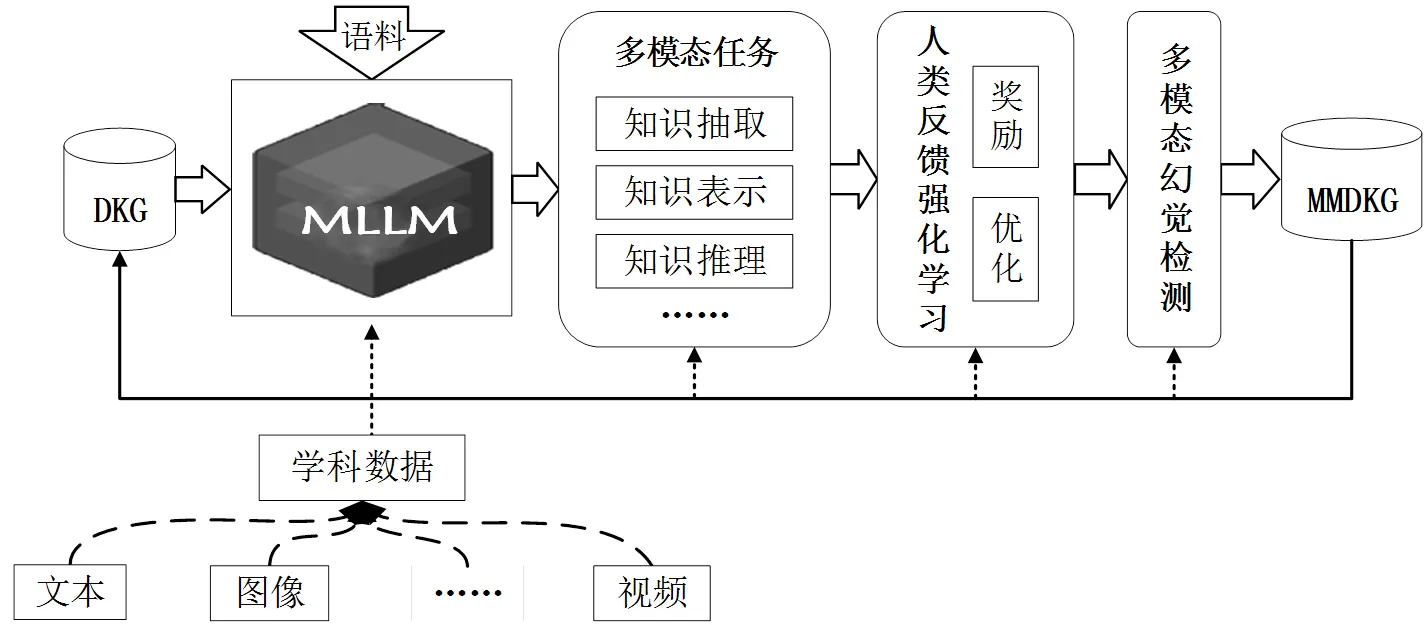
图3 MMDKG的构建框架
(1)多模态任务
①多模态知识抽取。多模态知识抽取是融合不同模态数据并生成DKG的关键步骤,包括多模态的实体抽取和多模态的关系抽取。GPT系列大模型在命名实体识别、关系提取任务中的使用显著提高了知识图谱的质量和准确性。例如,Agrawal等[27]通过InstructGPT模型进行零样本和少样本学习,实现临床笔记中实体和关系的抽取;Dunn等[28]基于GPT-3提出一种适合于科学文本中复杂层次信息实体-关系联合抽取的序列到序列方法,以实现实体和关系抽取。
MLLM的超强语言理解能力,能够有效应对实体和关系抽取过程中涉及的指代消解、歧义处理等一系列复杂问题:其一,通过知识萃取快速获取大量知识。提示工程可以帮助MLLM学习教育领域的专业术语、模式和规律,指导DKG构建中的多模态实体抽取和关系抽取。例如,可以构建针对学科领域的Prompt模板(如“在教育领域中,下列概念有哪些:”),以引导模型产生与教育领域相关的实体和实体间的关系。Prompt既能以语言模型作为知识库,从大模型中探测语言知识和关系知识,又能够以视觉语言模型作为常识库,从MLLM中探测跨模态对齐知识和视觉常识知识。其二,零样本、小样本进行开放知识抽取。MLLM具有显著的特征提取和零样本泛化能力,即使是训练集中未出现的学科实体和关系,模型也可以通过已有知识对陌生数据进行分类、推理和预测。
②多模态知识表示。多模态数据虽然在底层表征上是异构的,但是同一实体的不同模态数据在高层语义上是一致的。为了方便对抽取到的多模态知识信息进行处理,须对输入数据进行表示。多模态表示学习旨在缩小模态信息在联合语义子空间中的分布差距,分为基于特征的方法和基于实体的方法两种类型[29]。其中,基于特征的方法是将多模态知识信息作为实体的辅助特征来处理;基于实体的方法则将不同的模态信息作为结构化知识的关系三元组。从MMDKG的构建角度来看,通过基于特征的方法进行知识表示可以利用多模态之间的互补性,学习到更好的特征表示。图4为MLLM支持的多模态表示学习框架,基于该框架,MLLM可以在语义含义上对不同的特征空间进行匹配,实现多模态数据的统一表征,从而得到在共同表示空间中各模态的高层语义表示[30]。
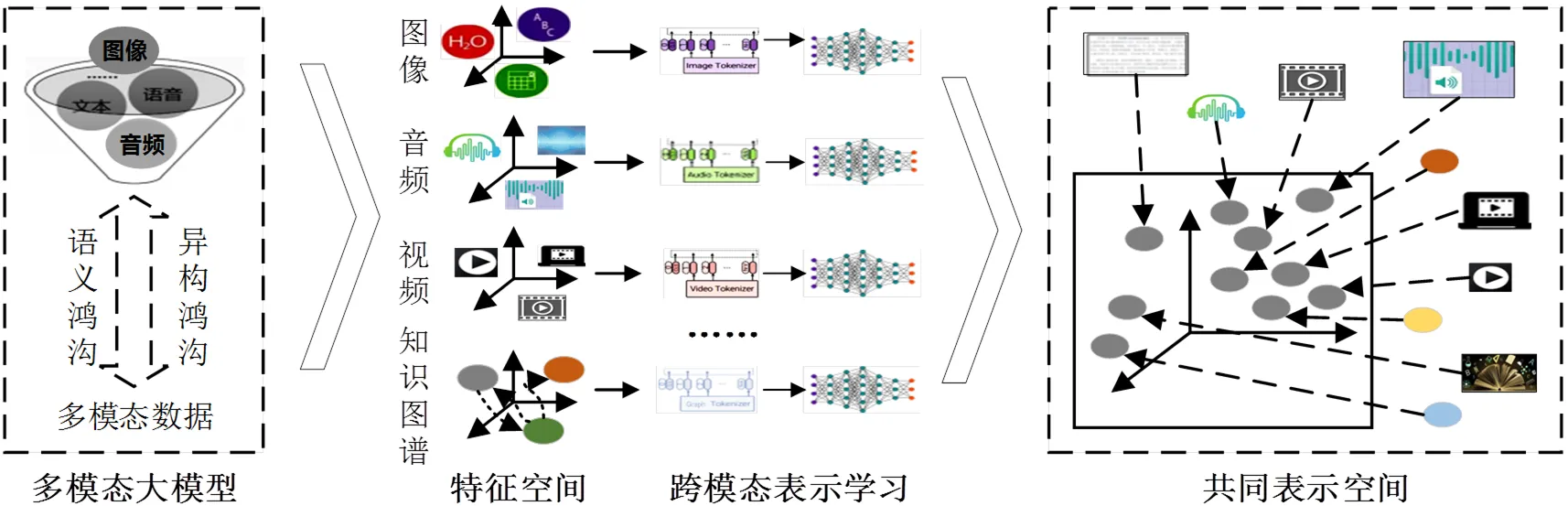
图4 MLLM支持的多模态表示学习框架
③多模态知识推理。多模态知识推理的目标是基于现有学科知识数据推理新的学科知识,如两个学科知识实体之间的隐式关系[31]。其中,知识补全通常被视为知识推理的过程,旨在对已有知识进行推理并推断缺失的链接[32]。近年来,基于大模型的知识图谱推理方法开始获得关注。通过大模型,知识可借助知识图谱的架构承载,并在后续参与知识计算。例如,Jiang等[33]提出了TAGREAL框架,自动生成高质量的查询Prompt提示,并从大型文本语料库中检索支持信息以探测大模型中的知识,从而完成知识图谱补全;Kim等[34]提出了一个名为KG-GPT的通用框架,该框架利用大模型进行图谱推理。
MLLM的思维链是“一系列中间推理步骤”,已被证明在复杂推理任务中是有效的[35]。应用MLLM进行多模态知识推理,可以将外部模态的学科知识信息注入多模态大模型,将它视为强大的推理器,利用Prompt执行相应信息提取和思维链的各种视觉推理任务,为DKG构建提供更好的跨模态表示和推理。
(2)人类反馈强化学习
人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)是指通过与人类专家的交互和反馈来优化模型的学习和决策过程[36]。这一训练范式增强了人类对模型输出结果意向的调节,并且对结果进行了更具理解性的排序。考虑到DKG中“学科知识”这一人类发展经验总结的特殊性,在构建过程中应当利用学科专家提供关于知识表示、推理等方面的反馈信息,为MLLM提供奖励信号和优化目标。这种反馈需要MLLM将人类反馈信号与奖励信号关联起来进行微调并持续迭代,以引导MLLM成为MMDKG构建中“既懂规矩又会试探的博学鹦鹉”[37]。其中,优化方法可以使用各种强化学习算法,如值函数方法、策略梯度方法等,以优化模型的多步决策。总之,人类反馈的强化学习可以帮助模型逐步提升对多模态学科知识的理解和应用能力,并不断增强MMDKG的构建质量和准确性。
(3)多模态幻觉检测
由于MLLM本质上可以视为训练集(人类知识)的有损压缩,因此当模型根据数据中的统计模式生成输出时,就会产生听起来合理但与现实世界知识不一致的输出,即幻觉[38]。多模态幻觉的本质是多模态信息有损压缩偏差的体现。对于MMDKG构建过程中的多模态任务来说,其产生的幻觉包括3类[39]:①含义相关性的幻觉,MLLM生成的输出可能包含与输入语境不相关的内容;②语义扩张的幻觉,MLLM生成的输出可能包含与输入语境相关但是过于具体或者过于抽象的内容;③结构错误的幻觉,MLLM生成的输出可能不符合正确的语言表达或句子结构。为了降低幻觉出现的概率,须通过幻觉检测机制或评估基准[40],检测MMDKG中无中生有的幻觉或不一致问题,从而更好地确保MMDKG的应用可靠性。
3 多模态学科知识图谱的构建示例
《义务教育数学课程标准(2022年版)》指出,义务教育数学课程应使学生通过数学的学习,形成和发展面向未来社会和个人发展所需要的核心素养[41]。因此,本研究以2017年出版的人教版《数学四年级上册》“角的度量”单元为例,简单描述MMDKG的构建。“角的度量”包括直线、射线以及线段等知识内容,教学目标旨在通过点的运动向射线的旋转运动转变,让学生领会各种图形的特征,促进其空间观念的发展。本研究确定了“角”的大概念与角分类、量角等知识单元的父子关系、平行与前驱后继关系,构建过程如图5所示。其中,txtOf指向文本节点,imgOf指向图片节点,vidOf指向视频节点。
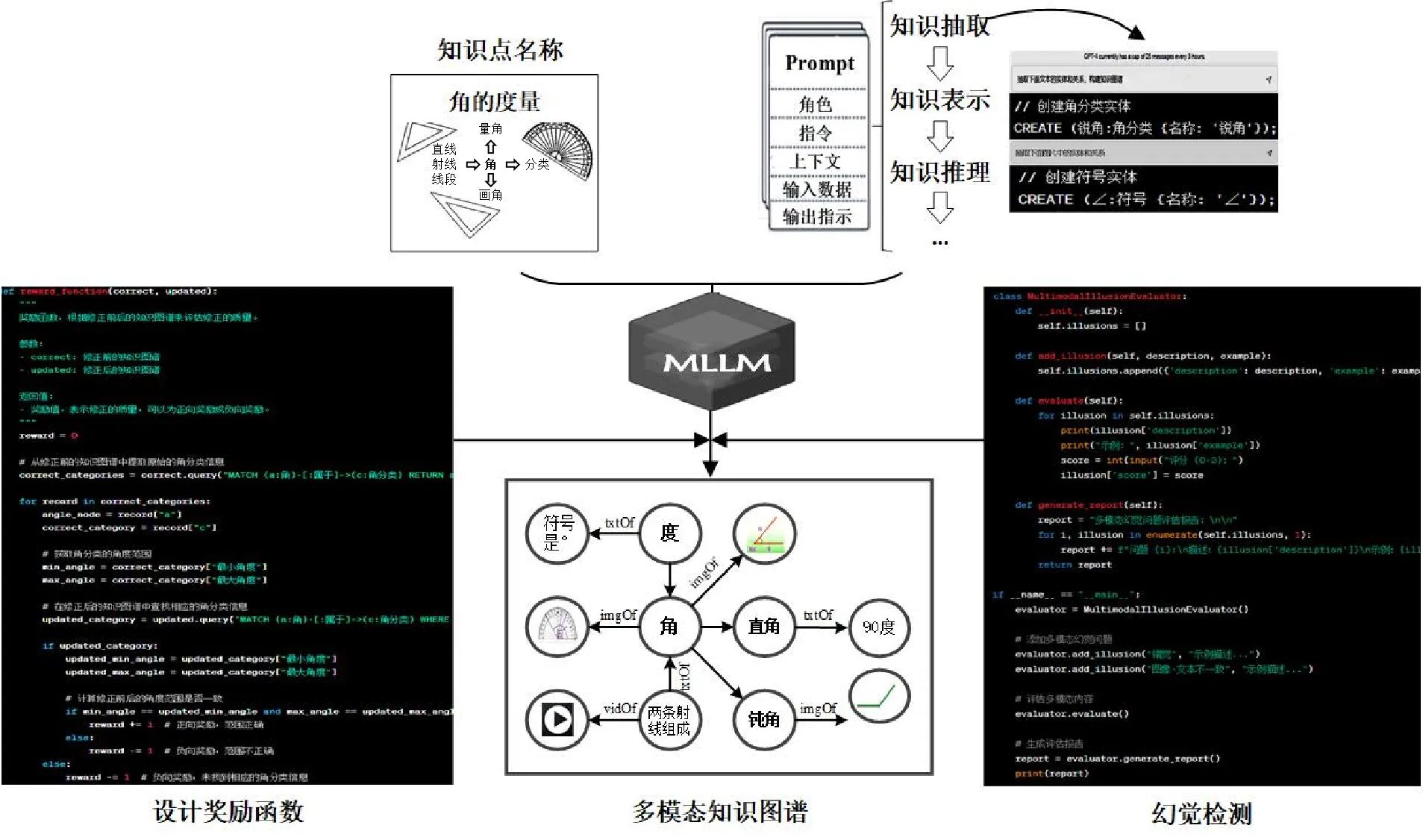
图5 “角的度量”MMDKG构建过程
(1)利用Prompt优化多模态任务
提示工程可理解为基于提示的学习来训练语言模型,一个Prompt通常包含五个元素:①角色,指模型执行生成任务时所扮演的角色;②指令,指希望模型执行的具体任务;③上下文,指背景或外部信息,以引导模型提供更好的反馈;④输入数据,指希望获得反馈的输入内容;⑤输出指示,指模型输出反馈的类型或格式[42]。本研究利用Prompt引导MLLM进行多模态知识抽取、表示学习和知识推理,以“角的度量”知识抽取为例,通过精确指令从输入数据中提取类型为Neo4j格式的数据。其中,CREATE用于创建节点和关系;节点1、节点2等是节点的名称,可以附加标签和属性。
(2)基于奖励机制的专家反馈优化
基于奖励机制的专家反馈优化首先需要领域专家依据自身经验审查知识图谱并标识不准确或缺失的信息以反馈修改,然后根据反馈信号创建奖励函数以度量知识图谱的质量。其中,奖励函数的设计需要考虑知识图谱构建的具体情境,正向奖励分配给正确的信息,而负向奖励分配给错误或不准确的信息,以识别需要修正的节点或关系。图5左侧是一个奖励函数示例,用于验证修正前后角分类的角度范围是否一致。
(3)幻觉分类与检测
图5右侧的示例创建了一个简单的多模态幻觉检测机制,以便为输入的多模态内容提供幻觉评估报告。多模态幻觉问题分类和评分标准示例如表1所示,研究者或机器可以根据此分类标准对模型生成的多模态内容进行评估,为多模态内容提供适当的分类和分数以评估模型的性能,帮助改进内容质量。
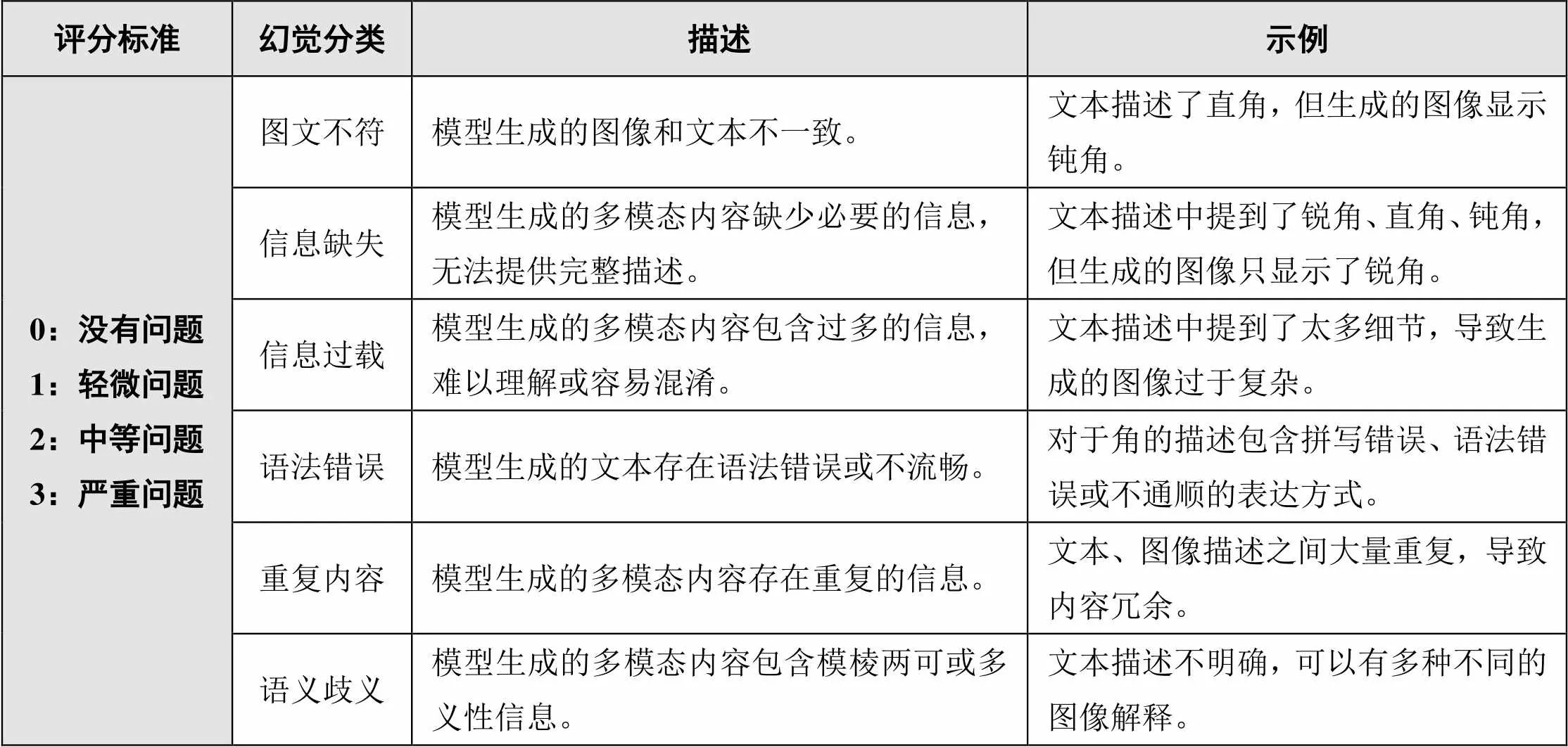
表1 多模态幻觉问题分类和评分标准示例
四 多模态学科知识图谱的教育应用场景
目前,MLLM的教育应用模式正在从专用向通用转变,其应用流程正在从分发走向生成,应用场景正在从单一走向多元[43]。新的“模型即服务”——“MLLM+MMDKG+教育应用场景”应用模式为智慧教育提供了更多可能性,可有效支持教学资源多元聚合、智能教学产品开发等应用。
1 推动教育资源多元聚合
首先,依托MMDKG可以支撑构建数字教育资源平台,通过制订统一的数字教育资源表示标准,MMDKG能实现细粒度的资源切分、识别与关联,对教育资源进行知识化标注和链接,从而在多模态数字教育资源之间建立语义联系,为教育资源元数据管理提供支持。其次,MMDKG可以将文本、图像、视频等多模态数据与特定知识点或教育资源关联起来,更好地表达和组织教育资源的内容与结构,为数字教育资源的多元聚合提供有效的技术支撑。基于MMDKG,多模态数字教育资源可以被知识化标注和链接,这意味着师生能够通过不同的感官方式接触和理解同一知识概念,从而更深入、全面地展开学习。另外,MMDKG能够整合来自不同学科领域的教育资源,也可帮助学习者更好地理解不同学科之间的关系和交叉点,有助于促进其跨学科思维培养。
2 助力智能教学产品开发
目前,智能教育机器人正处于发展初级阶段,面临教学性不足、反馈性差、感知力欠缺等诸多问题[44];数智教材建设正从“知识图谱”逐渐向“能力图谱”和“价值图谱”发展[45],诸如此类的智能教学产品智能化发展水平有待提高。而MMDKG在跨模态知识检索、学习者学习画像建模等方面具有技术优势,可提高智能教育机器人、数智教材等智能教学产品的交互性、个性化和智能化程度。
MMDKG关于跨模态检索研究的基本内容是寻找不同模态知识资源之间的关系,通过使用一种类型的数据作为查询来检索其他类型的数据。例如,结合图像和语音识别技术,将教学资源中的图片和语音转化为可理解知识,并与相关文本知识进行关联,与教育机器人、数智教材等智能教学产品进行交互。MMDKG关于学习者学习画像建模研究的基本内容是强化学习者多维特征的抽象化描述,建构学习者标签化模型,目的是为特定的精准教学提供指引。目前,教育机器人、数智教材的学习者画像建模水平普遍不高,其针对学习者学习画像建模的方法大多无法深入捕捉学习者的多维认知特征。如果利用MMDKG进行知识链接追溯,并合理控制不同学习者视角下的DKG,可以更好地理解和分析学习者的需求以进行有效干预。
3 赋能学科资源个性推荐
学科资源个性推荐的技术特征之一是按需推送、因材施教,为学习者推荐适合其认知状态的学习资源以及学习服务。基于知识图谱的个性化资源推荐依据学习理论和学科知识结构特征构建DKG,不仅具有较好的推荐效果,还能够解决数据稀疏、冷启动等问题[46]。相较于传统的DKG,MMDKG将大模型与知识图谱结合起来,得以汇聚多时相、多类型、多模态的学科资源,为进行可解释且需要知识的智能问答提供了新的范式[47]。如是,学科资源个性推荐能够规避知识片面性风险,根据师生习惯和兴趣,通过分析不同的数据模态,进而自适应推送与学习者相适配且具有互动性和生成性的学习资源。总体来看,在对学习者进行认知诊断的基础上,MMDKG在学习过程中体现的导航价值能够很好地解决海量学科资源给学习者带来的“知识迷航”“认知负荷”问题。
4 促进人机协同智慧教学
随着人工智能的快速发展,教育人工智能已经由“支持智能”和“增强智能”逐渐发展到“人机协同智能”阶段。其中,人机协同智慧教学是教育主体与机器相互协作、形成正反馈关系的教学方式,具有数据多模态、适应性反馈等特点[48]。DKG的构建是教育新型基础设施建设的重要组成部分,而由MLLM支持的MMDKG能够融合不同模态数据的特性,有效推动多模态知识驱动的人机协同教学[49]。在教学场景中,师生可通过交互界面与计算机系统进行交流和操作,人机协同的“诊断-反馈-干预-反思”环节贯穿于整个教学过程。借助MMDKG,“机”能够更好地理解教育情境,使“机与人”交互更加接近“人与人”之间的交流,为师生提供适应性反馈。
五 结语
在生成式人工智能的发展推动下,本研究从MLLM与DKG的技术原理,以及两者的协同、竞争和竞合出发,探索了MLLM驱动MMDKG构建的前提、进程和教育应用场景布局,旨在为新一代人工智能背景下DKG的相关研究提供借鉴与启示。当前利用MLLM技术构建MMDKG虽然可行,但也存在数据偏见、知识准确性不高等诸多挑战。未来,以MLLM为基座构建面向教育主体认知、情感、技能等目标的MMDKG,可以通过强化智能评估和反馈体系,明确不同应用模式下的服务机制,以推动智慧教育生态稳健发展。
[1]柯清超,林健,马秀芳,等.教育新基建时代数字教育资源的建设方向与发展路径[J].电化教育研究,2021,(11):48-54.
[2]穆肃,谭梓淇,骆珏秀,等.面向精准教研的立体知识图谱构建方法研究[J].电化教育研究,2023,(5):74-81.
[3]高茂,张丽萍.融合多模态资源的教育知识图谱的内涵、技术与应用研究[J].计算机应用研究,2022,(8):2257-2267.
[4]Li N, Shen Q, Song R, et al. MEduKG: A Deep-learning-based approach for multi-modal educational knowledge graph construction[J]. Information, 2022,(2):91.
[5]卢宇,余京蕾,陈鹏鹤,等.多模态大模型的教育应用研究与展望[J].电化教育研究,2023,(6):38-44.
[6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[OL].
[7]Sevilla J, Heim L, Ho A, et al. Compute trends across three eras of machine learning[OL].
[8]肖仰华,徐波,林欣,等.知识图谱:概念与技术[M].北京:电子工业出版社,2020:8-15.
[9][26]Zhu X, Li Z, Wang X, et al. Multi-modal knowledge graph construction and application: A survey[OL].
[10]Pu F, Zhang Z, Feng Y, et al. Learning context-based embeddings for knowledge graph completion[J]. Journal of Data and Information Science, 2022,(2):84-106.
[11]林健,柯清超,黄正华,等.学科知识图谱的动态生成及其在资源智能组织中的应用[J].远程教育杂志,2022,(4):23-34.
[12]李艳燕,张香玲,李新,等.面向智慧教育的学科知识图谱构建与创新应用[J].电化教育研究,2019,(8):60-69.
[13]张春霞,彭成,罗妹秋,等.数学课程知识图谱构建及其推理[J].计算机科学,2020,(S2):573-578.
[14]张玉柳,赵波.深度学习视角下学习者模糊认知地图的构建与应用[J].现代教育技术,2021,(11):37-45.
[15]李龙飞,张国良.算法时代“信息茧房”效应生成机理与治理路径——基于信息生态理论视角[J].电子政务,2022,(9):51-62.
[16]Pan S, Luo L, Wang Y, et al. Unifying large language models and knowledge graphs: A roadmap[OL].
[17][35]Wei J, Wang X, Schuurmans D, et al. Chain-of-thought prompting elicits reasoning in large language models[OL].
[18]Zhang Z, Zhang A, Li M, et al. Multimodal chain-of-thought reasoning in language models[OL].
[19]Yin S, Fu C, Zhao S, et al. A survey on multimodal large language models[OL].
[20]罗江华,张玉柳.基于跨模态理解与重构的适应性数字教育资源:模型构建与实践框架[J].现代远程教育研究,2023,(6):91-101.
[21]Wei J, Tay Y, Bommasani R, et al. Emergent abilities of large language models[OL].
[22]Schaeffer R, Miranda B, Koyejo S. Are emergent abilities of Large Language Models a mirage?[OL].
[23]Liu V, Chilton L B. Design guidelines for prompt engineering text-to-image generative models[OL].
[24]陈烨,周刚,卢记仓.多模态知识图谱构建与应用研究综述[J].计算机应用研究,2021,(12):3535-3543.
[25]李振,周东岱,王勇.“人工智能+”视域下的教育知识图谱:内涵、技术框架与应用研究[J].远程教育杂志,2019,(4):42-53.
[27]Agrawal M, Hegselmann S, Lang H, et al. Large language models are few-shot clinical information extractors[A]. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing[C]. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, 2022:1998-2022.
[28]Dunn A, Dagdelen J, Walker N, et al. Structured information extraction from complex scientific text with fine-tuned large language models[OL].
[29]Sun R, Cao X, Zhao Y, et al. Multi-modal knowledge graphs for recommender systems[A]. Proceedings of the 29th ACM International Conference on Information & Knowledge Management[C]. New York: Association for Computing Machinery, 2020:1405-1414.
[30]刘建伟,丁熙浩,罗雄麟.多模态深度学习综述[J].计算机应用研究,2020,(6):1601-1614.
[31]Liu J, Xia F, Wang L, et al. Shifu2: A network representation learning based model for advisor-advisee relationship mining[J]. IEEE Transactions on Knowledge and Data Engineering, 2019,(4):1763-1777.
[32]Wang L, Zhao W, Wei Z, et al. SimKGC: Simple contrastive knowledge graph completion with pre-trained language models[OL].
[33]Jiang P, Agarwal S, Jin B, et al. Text-Augmented open knowledge graph completion via pre-trained language models[OL].
[34]Kim J, Kwon Y, Jo Y, et al. KG-GPT: A general framework for reasoning on knowledge graphs using large language models[OL].
[36]Bai Y, Jones A, Ndousse K, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback[OL].
[37]腾讯调研云.人机共生——大模型时代的AI十大趋势观察[OL].
[38]Azamfirei R, Kudchadkar S R, Fackler J. Large language models and the perils of their hallucinations[J]. Critical Care, 2023,27:1-2.
[39]Mündler N, He J, Jenko S, et al. Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation[OL].
[40]Zhang Y, Li Y, Cui L, et al. Siren’s song in the AI ocean: A survey on hallucination in large language models[OL].
[41]教育部.义务教育数学课程标准(2022年版)[S].北京:北京师范大学出版社,2022:2.
[42]Giray, L. Prompt Engineering with ChatGPT: A guide for academic writers[J]. Annals of Biomedical Engineering, 2023,(6):1-5.
[43]吴砥,李环,陈旭.人工智能通用大模型教育应用影响探析[J].开放教育研究,2023,(2):19-25、45.
[44]卢宇,薛天琪,陈鹏鹤,等.智能教育机器人系统构建及关键技术——以“智慧学伴”机器人为例[J].开放教育研究,2020,(2):83-91.
[45]宋武全,李正福.日本数字教材建设:政策演进、实施路径和问题启示[J].全球教育展望,2023,(6):89-99.
[46]沈杰,乔少杰,韩楠,等.融合多信息的个性化推荐模型[J].重庆理工大学学报(自然科学),2021,(3):128-138.
[47]Luo H, Haihong E, Tang Z, et al. ChatKBQA: A generate-then-retrieve framework for knowledge base question answering with fine-tuned large language models[OL].
[48]符雪姣,曾明星,张友福.人机协同精准教学整体框架与关键环节设计[J].开放教育研究,2023,(2):91-102.
[49]吴砥,陈敏.“大模型”视角下的人机协同教学[N].中国教师报,2023-10-18(13).
Evolution and Educational Application of Discipline Knowledge Graph Driven by Multimodal Large Model
LUO Jiang-hua ZHANG Yu-liu
At present, the multimodal large model represented by GPT-4 is promoting the development of general artificial intelligence in the direction of multimodal integration. Benefiting from application technologies such as multimodal thought chain, emergent abilities and prompt engineering, discipline knowledge map can better form an intelligent expansion paradigm that correlates abstract symbolic concepts with multimodal data, which can effectively solve many shortcomings in the construction of existing maps, and further promote the creation of multimodal discipline knowledge graphs, and provide strong support for the development of smart education services. Based on this, this paper firstly deconstructed the relationship between multimodal large model and discipline knowledge graph. Then, this paper explored the driving premise of multimodal large model on discipline knowledge graph, and discussed the basic connotation and construction framework of multimodal discipline knowledge graph from the evolutionary perspective. Finally, four educational application scenarios of multimodal discipline knowledge graph were proposed, including promoting the diverse aggregation of educational resources, helping the development of intelligent teaching products, empowering the personalized recommendation of discipline resources, and promoting the smart teaching of human-machine collaboration, expecting to provide reference and enlightenment for the related research of discipline knowledge graph.
multimodal large language model; multimodal data; discipline knowledge graph; multimodal disciplines knowledge graph; educational application

G40-057
A
1009—8097(2023)12—0076—13
10.3969/j.issn.1009-8097.2023.12.008
本文为2021年度国家社科基金教育学重点项目“以教育新基建支撑高质量教育体系建设研究”(项目编号:ACA210010)的阶段性研究成果。
罗江华,教授,博士,研究方向为智慧教育理论与实践,邮箱为swusun@swu.edu.cn。
2023年7月25日
编辑:小时
猜你喜欢
参花(上)(2023年2期)2023-03-06
江苏教育·教师发展(2021年6期)2021-08-11
少先队活动(2020年12期)2021-01-14
中国德育(2017年17期)2017-09-15
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
图书馆理论与实践(2015年7期)2016-01-19
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
