
基于数字孪生和智能感知的虚拟分流技术研究
2023-12-18 05:53孙梦琪倪广林张培
电子设计工程 2023年24期
孙梦琪,倪广林,张培
(河北北方学院附属第一医院,河北张家口 075000)
当前,我国的人均医疗资源不均衡问题较为突出。而人口老龄化的不断加剧,使得医疗服务需求量也在持续增加[1-2]。同时由于医疗专业的自身属性,职业培养时间过长且存在较大的人才缺口,因此进一步加剧了医疗资源的紧缺。随着智能分诊技术的不断发展,线上问诊、智能初诊和问答客服技术正在应用与推广,这对减轻医生压力,缓解紧张的医疗资源具有一定帮助[3-4]。目前使用的智能分诊技术通过对临床医疗数据、化验单及病历等文本信息进行分析,所采用的算法大多是知识图谱模型,并根据输入数据提取数据特征。由于该种方法通常依靠人工建立特征框架和诊断模型,主观性较强,故诊断结果准确率较低。虽然其收敛速度较快、对计算机性能的要求较低,但仍然无法应用于实际场景中。与传统的机器学习(Machine Learning,ML)算法相比,深度学习(Deep Learning,DL)算法在性能和稳定度两方面均有显著提升。因此,该文基于海量的专家电子病历文本,利用数字孪生技术(Digital Twin,DT)构建电子病历文本向量模型,同时通过智能感知算法来实现准确的预诊断与分流。
1 虚拟诊断分流技术设计
1.1 词向量训练模型构建
在分流诊断的过程中,依赖于电子病历、检查单和医学影像等数据,其中电子病历与检查单均为文本数据,在模型中需要将其转化为文本向量才能使用模型完成训练,所以该文采用Word2Vec 方法进行词向量的生成及训练。而Word2Vec 模型[5-7]由连续词袋(Continuous Bag-of-Word,CBOW)模型或跳字模型(Skip-gram)构成。相比CBOW 模型,Skip-gram模型通过文本中的词汇对上下文进行预测,故其更为高效。因此,文中使用Skip-gram 模型完成词向量的训练,该模型结构如图1 所示。
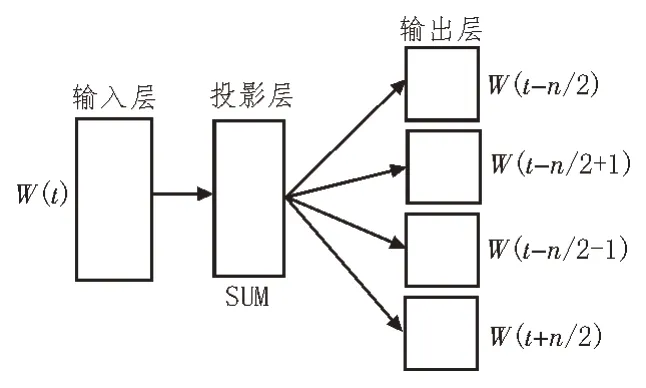
图1 Skip-gram模型结构
在图1 中,Skip-gram 模型由输入层、投影层和输出层三部分组成。首先设定一个文本中心词,假定该词的位置为wt,模型可以预测上下文中wt-1、wt+1等位置词出现的概率。输入层的输入数据为wt位置所对应的m维初始化向量v(wt),投影层对v(wt)进行映射,输出层可类比为哈夫曼树(Huffman Tree)结构。
模型训练目标函数如下所示:
式中,p为概率密度,其通常可表示为:
式中,uw1和vc分别为输出与输入的词向量,uw表示第w个词向量。经过Word2Vec 模型,初始文本可以分割成词向量以便于后续的模型训练。词向量生成过程如图2 所示。

图2 词向量生成过程
在切割成词向量后,还需要对词向量进行交叉相似度的计算,从而去除其中的歧义词,保证语料向量的正确性[8-9]。假定包含歧义词的句子用M来表示,则首先需要生成词向量空间,如图3 所示。
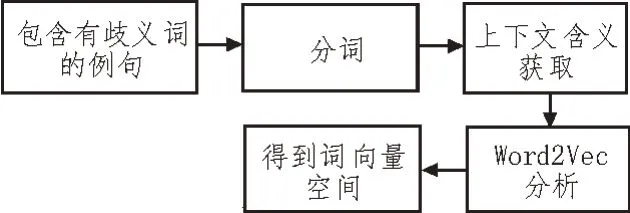
图3 词向量空间的生成过程
将词向量空间中的文本转换为向量,则相似度的计算可以表征为:
式中,Wim为句子m中第i个位置词向量的权重,Win为歧义词文本中第i个位置词向量的权重,且使用三角函数对向量相似度进行计算。
1.2 基于CNN的医学影像分析模型
对于分诊模型而言,除了文本信息外,医学影像也是辅助诊断的重要依据,因此还需对相关数据加以分析。该次使用卷积神经网络(Convolutional Neural Networks,CNN)和残差网络(ResNet)进行医学影像识别。
卷积神经网络(CNN)[10-12]由输入层、卷积层、池化层和全连接层组成。CNN 网络中的卷积层是主要计算层,其可提取输入图像的特征,该层的计算过程如下:
式中,wi为网络层权重,b为偏置值。池化层通过池化操作进行降维,从而减轻计算量,全连接层则将数据特征映射至向量空间。
基础卷积神经网络结构的图像识别准确率偏低,深浅层网络神经元之间的特征联系度不足。因此文中使用残差网络[13]将二者相连接,所采用的残差网络结构如图4 所示。

图4 残差网络的结构
假设残差结构的输入为x,则输出为F(x)+x,其中F(x)为残差。在卷积神经网络完成数据训练后,需要对训练完毕的数据进行特征分类,此次使用了受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)来进行分类。RBM 由隐藏层和可视层组成,隐藏层负责接收输入的数据,可视层则可对数据特征加以提取。RBM 分类函数可表示为:
式中,wij为隐藏层和可视层之间的权重值,ai为可视层偏置值,bj为隐藏层偏置值。
针对CNN 网络的高依赖性,需要在初始模型中加入注意力机制(Attention Mechanism,AM)[14-16]。该文加入的注意力机制结构,如图5 所示。

图5 注意力机制结构
图5 中,L为输入矩阵。对于该矩阵,进行线性变换以得到查询向量Q、键值向量K和值向量V共计三个参数,计算公式如下所示:
式中,Wq、Wk以及Wv为均线性参数矩阵。对Q向量和K向量进行转置,可得到评分矩阵S为:
之后使用Softmax 层将S矩阵归一化以获得概率分布参数,最终得到全局特征矩阵,并输出融合诊断结果:
1.3 算法执行过程
该算法结构如图6 所示,其包括文本数据特征提取模块、图像特征提取模块以及输出分类模块。其中文本数据特征提取模块使用Word2Vec 模型对化验单、检查单中的文本进行训练和验证,并输出初始词向量,再使用VSM 算法对词向量进行消歧。图像特征提取模块使用CNN 对数据特征加以提取,同时利用残差结构和RBM 网络提升网络训练精度及分类准确度,且采用注意力机制完成权重分类。最终通过Softmax 层对文本与图像数据训练模型进行融合,进而完成数字孪生过程,并输出诊断结果。诊断结果共分为十类,分别对应不同类型的疾病。

图6 该算法执行流程
2 实验与结果分析
2.1 实验环境以及数据集
该文所设计的模型算法使用Python 进行实现,同时采用TensorFlow 作为深度算法的部署框架。实验运行环境如表1 所示。

表1 实验环境
使用的数据集包括文本和图像数据集,其中前者采用公开数据集THUCNews 进行性能对比,而后者则为MIMIC-III 大型公开医疗数据集。同时还使用爬虫从某互联网医疗平台爬取文本数据作为验证集,从而增强模型的泛化能力。此外,该模型还将准确率、召回率以及F1 值作为评价指标,其数学公式如下所示:
式中,TP 为真正例,FP 为假正例,FN 为假负例。
2.2 算法测试
首先验证文本分类结果的准确率,在文本数据集中使用BERT、TF-IDF、Text-CNN 以及该算法进行验证。为了验证模型对数据的最佳处理能力,采用了不同维度的输入数据,测试结果如表2 所示。

表2 文本分类算法测试准确率
由表2 可知,该模型在不同数据集、不同维度词向量情景下的文本分类准确率均维持在较高的水平。而当数据维度为100 时,所有算法的准确率均较高,因此该算法的输入向量维度选择了100。同时,相较于对比算法中性能较优的Text-CNN 模型,该算法在公开数据集中的准确率由89.45%提升至92.15%,私人数据集中的准确率由81.15%提高至85.41%,说明该算法的分类性能较为理想。
在图像分类性能的验证中,使用常见的图像分类算法XGBoost、CNN、RF、SVM 与该算法进行对比,分类评估指标为准确率、召回率与F1 值,实验测试结果如表3 所示。

表3 图像分类评估测试结果
在表3 中,该算法使用了CNN-RBM-AM 的组合算法,在所有对比算法中其评价指标均为最优,与原始算法CNN 相比,F1值提升了约4%。而相较于对比算法中最优的组合算法XGBoost,F1 值增长了约2%。由此说明了,该算法具有较强的图像分类能力。
在最后的诊断结果输出中,该算法输出的分诊结果也将起到辅助诊断的作用。因此使用爬虫抓取的医疗数据集进行诊断结果测试,该次实验选择了五位患者的信息,经过模型训练,输出的诊断结果如表4 所示。

表4 诊断结果对比
由表4 可以看出,该算法的分诊结果与医生的诊断结果大致相同,可以对患者的疾病进行较为准确地分类,这表明其具有一定的工程实用价值。
3 结束语
现阶段使用的智能医疗分诊技术依赖于主观的知识图谱技术,较少涉及智能算法。该文基于数字孪生的思想,使用智能感知算法提出了一种医疗分诊技术。该算法将Word2Vec 和VSM 算法相结合,生成无歧义的词向量数据,再使用改进后的CNN 网络对医疗影像进行特征分类,使用Softmax 函数进行数据融合并输出诊断结果。多项实验测试表明,该算法的性能良好且应用价值较高。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中国交通信息化(2018年5期)2018-08-21
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
