
基于双通道残差密集网络的红外与可见光图像融合
2023-12-18 09:25:48冯鑫杨杰铭张鸿德邱国航
光子学报 2023年11期
冯鑫,杨杰铭,张鸿德,邱国航
(重庆工商大学 机械工程学院 制造装备机构设计与控制重庆市重点实验室,重庆 400067)
0 引言
图像融合是图像处理的中的一项重要任务,它需要运用融合策略将不同模态传感器获得的图像的重要特征信息进行融合,使得单幅图像具有源图像的显著特征[1]。红外与可见光图像融合是图像融合中一个具有挑战性的任务,可见光图像由传感器捕获反射光形成,符合人眼的成像规律,并且包含了丰富的纹理与细节信息,缺点是容易受到光照环境影响,穿透性不足;红外光图像由传感器捕获热辐射信息形成,相比于可见光图像,它具有较高的对比度,并且具有很强的穿透性,不易受到天气与光线环境影响[2]。将红外光图像与可见光图像的优势结合在一起,生成的具有高对比度且具有良好纹理信息的融合图像在夜间导航[3]、地下勘探[4]以及目标检测[5]等众多领域都具有良好的应用前景。
目前,图像融合算法分为传统和深度学习两个大类。传统方法主要通过在变换域或空间域手动进行活动水平测量以及融合规则的设计完成图像融合。例如在变换域中将多尺度变换与稀疏表示两者相结合的通用方法MST-SR[6],以及基于空间域的梯度转移融合方法(Gradient Transfer Fusion,GFT)[7]。尽管现有的传统算法已经能够取得较好的融合结果,但是传统方法在图像融合过程中需要手动进行融合规则的设计,该过程大大提高了整个算法的工作量。
深度学习方法凭借着强大的特征提取能力在计算机视觉任务中展现出了显著的性能优势,在图像融合任务中也不例外。基于深度学习的融合方法主要有特征提取、特征融合、图像重建三个步骤,各种算法完成这三个步骤的方式也不尽相同。LIU Yu 等[8]通过训练卷积神经网络(Convolutional Neural Network,CNN)模型用于联合生成活动水平测量和融合规则,克服了传统图像融合方法所面临的困难,深度学习逐渐开始进入图像融合领域。MA Jiayi 等[9]在损失函数中引入显著目标掩码,能够较好的提取红外与可见光图像中的显著区域以精确指导网络的优化,但其更加关注于显著特征而忽视了细节特征的发掘。2019 年,MA J 等[10]将图像的融合过程转化为生成器和判别器的博弈过程,将生成对抗网络(Generative Adversarial Network,GAN)模型应用到图像融合任务中。随后,MA Jiayi 等又进一步的对该融合模型进行优化,分别提出了双鉴别器(Dual Discriminator Conditional Generative Adversarial Network,DDcGAN)[11]和一个多分类鉴别器(Multiclassification Constraints Generative Adversarial Network,MccGAN)[12]的生成对抗网络红外与可见光融合模型。然而基于生成对抗网络算法的模型结构复杂,训练的成本高,运用生成器获得包含更多源图像特征的融合图像比较困难。而在自编码网络方面,LI Hui 等[13]提出将自动编码器框架(Auto-Encoder,AE)应用于图像融合,并使用密集连接层来获取更多的图像特征,其后,XU Han 等[14]通过编码器将图像分解为场景信息和传感器的模态信息,通过不同的融合策略将其融合,获得了较好的视觉效果;LI Hui 等[15]通过提出一种新的训练策略,分两阶段训练解码器和融合层,实现了自动编码器的端到端融合。上述方法中的神经网络结构大多都使用单一的骨干网络结构获得图像的特征,然而使用单一网络对图像进行特征提取可能会导致特征提取的固化,从而忽视掉部分特征。
基于上述分析,为了通过神经网络结构获得更多源图像的特征信息,本文结合双通道并联的神经网络思路设计了一种基于自动编码器网络框架的红外与可见光图像融合算法,并且在融合阶段,根据双通道特征的特点,对基于注意力模型的融合策略进行改进。
1 双通道级联残差密集网络框架
1.1 基于双通道级联的自动编码器框架
通用的基于自动编码器的红外与可见光图像融合框架如图1 所示。该网络主要由编码器和解码器组成,原理是通过编码器对输入进行编码或者特征提取,再由解码器还原输入,属于自监督学习网络。在图像融合任务中,将编码器用于提取红外与可见光图像信息,中间加入融合层融合两者的特征,最后由解码器重建融合图像。在训练的过程中只需训练编码器的特征提取能力以及解码器的重建能力,不需要融合层,因此无需红外与可见光数据集进行训练,在网络训练完成后加入融合层即可获得融合图像。

图1 自动编码器结构框架Fig.1 Auto-Encoder structure framework
红外与可见光图像的多尺度特征是决定融合图像质量的重要因素。因此,本文引入双通道级联网络(Dual Path Networks,DPN)[16]的设计思想,结合残差网络(Residual Network,ResNet)[17]与密集连接网络(Densely Convolutional Network,DenseNet)[18]的优势来设计编码器的主干网络结构,该网络结构如图2所示。

图2 编码器网络结构Fig.2 Encoder network structure
图中“+”表示线性相加,“C”表示维度拼接。Res 为残差特征,残差连接模块使用跳层连接,将同一残差块的输入特征连接到输出中,以保证在保留输入特征上具有较好的效果。Den 为密集连接块特征,密集连接模块将输入特征与之前每一层的输出特征进行连接,使得每个密集连接块能够获得之前所有模块的信息,该模块擅长在之前模块特征的基础上发掘新的特征。双通道网络模块将输入分成两条路径,同时进行密集连接与残差连接,能够有效的实现特征的重用和发掘,相比于残差连接和密集连接拥有更低的计算成本和更高的参数效率。
基于残差连接与密集连接网络强大的特征提取能力,本文提出一种双通道并联模块设计自动编码器的编码器与解码器结构(Dual Paths Cascade Auto-Encoder,DPCAE),其详细的网络架构如图3 所示。编码器由一层卷积层和双通道级联模块构成,通过残差以及密集连接通道级联的方式提取并传递源图像的特征信息,实现通道间的信息共享。融合层采用空间L1 范数和注意力机制分别融合残差与密集通道特征。解码器根据编码器的特点,对密集以及残差特征进行不同的处理,高维的密集特征层数更深,则使用更多的卷积采样层进行特征的还原,低维的残差特征层数较浅,则减少卷积层的数量,通过这种方式将不同通道和层次的特征相结合,从而获得源图像中更加详细丰富的细节信息。
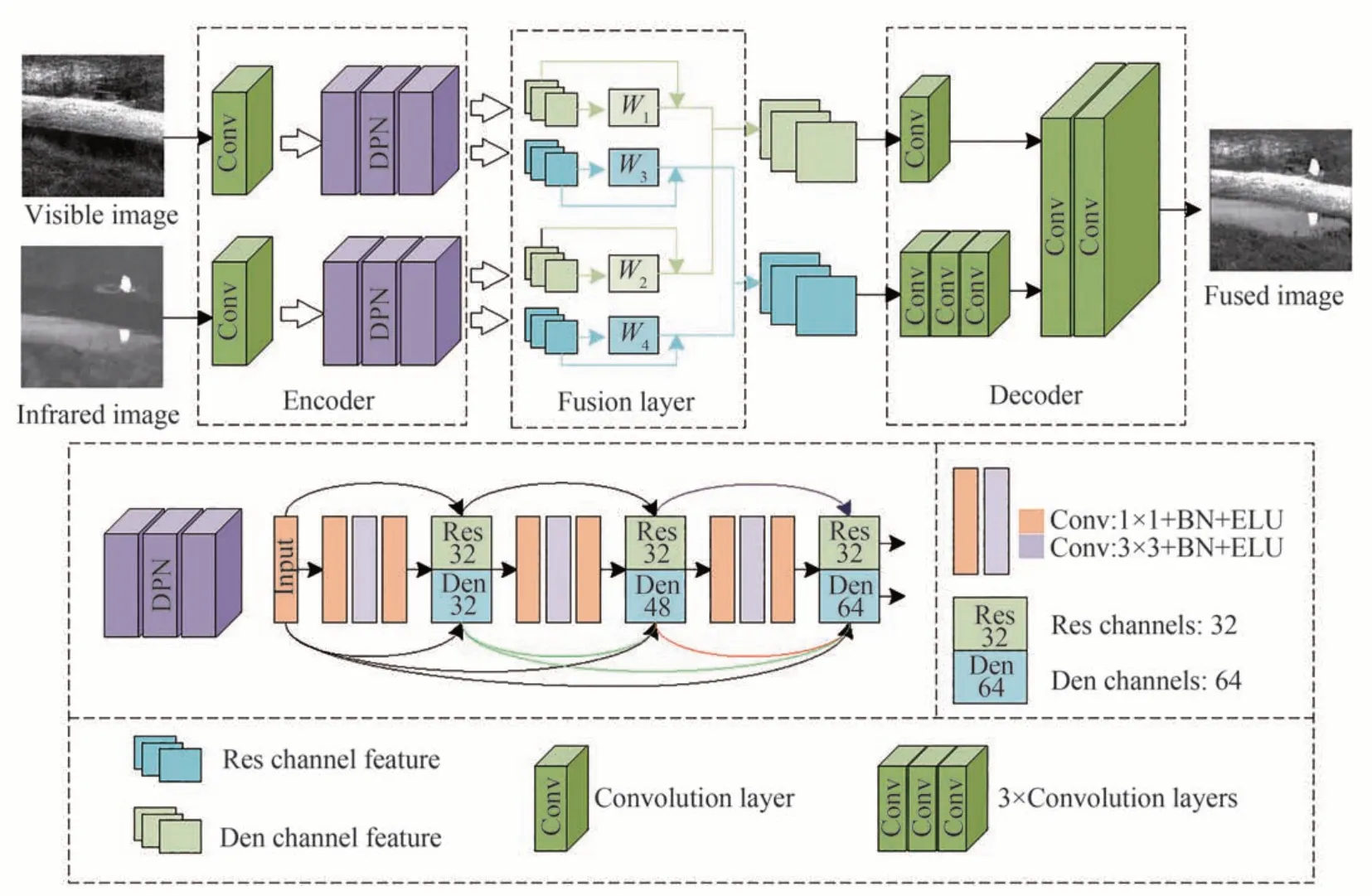
图3 基于双通道级联的残差密集网络融合框架Fig.3 A Residual dense network fusion framework based on dual-channel cascade
双通道级联模块由三个双通道层构成,每个双通道层的输入与输出层采用步长为1,卷积核为1×1 的卷积层调节特征维度;中间层采用卷积核大小为3×3,步长为1 的卷积层进行特征提取。与此同时,为了减少参数量,提高网络的效率同时防止过拟合,在卷积层之后加入池化(Batch Normalization,BN)[19]操作,然后通过ElU 激活函数提高网络的效果。根据双通道的编码器结构,将解码器的结构设计为双通道分别处理后结合,图像信息通过融合之后,输出的残差特征通道数为32,密集特征通道数为64,分别通过1 层和3 层卷积降低特征维度,随后对残差通道与密集通道进行维度拼接,经过两层卷积之后在最后一层使用tanh 激活函数。为了避免图像信息的丢失,在整个网络结构尽量避免了使用数据归一化运算,同时较多使用激活函数提高网络的拟合效果,这也是ELU 激活函数的优点,能够在进行少量归一化运算的条件下达到Relu 激活函数的效果[20]。
网络结构如表1 所示,其中,size 表示卷积核的大小,stride 表示步长,input 与output 的值表示输入与输出的通道数,activation 表示该层使用的激活函数,×3 表示三个相同的层。

表1 网络结构表Table 1 The table of network structure
1.2 损失函数
损失函数的设置对于图像融合的结果非常重要,自编码网络通过损失函数计算重建图像与源图像的损失来监督学习过程,为了更好的完成图像的重建,本文引入像素损失Lpix、结构相似性损失Lssim以及梯度损失Lgra来综合设置损失函数Ltotal。其中像素损失主要用于约束源图像和融合结果之间的总体像素水平,结构相似度用于约束两者之间的亮度对比度和结构信息,梯度损失用于约束梯度信息和纹理特征。损失函数如式(1)所示,它们的关系为
式中,α、β、γ分别用于调节像素损失、结构相似性损失和梯度损失之间的平衡,使训练的解码器和编码器在应对红外与可见光图像时能够平衡的获得红外与可见光信息,其取值由消融性实验获得。
像素损失Lpix通过融合图像与源图像的像素误差计算,表示为
式中,H和W分别表示图像的高和宽,Y表示输出图像,X表示输入图像。
图像的梯度特征中包含了大量的纹理特征信息,在训练自动编码器时可以通过减小梯度损失来达到保留源图像纹理细节信息的目的,梯度损失Lgra表示为
式中,∇表示对图像进行梯度计算,参考文献[21]的处理,运用Sobel 算子对图像进行梯度计算。
结构相似性损失Lssim主要通过亮度、对比度、结构来对比输出图像与源图像之间的差异,结构相似性损失可以通过式(4)计算。
式中,SSIM 表示输入与输出图像的结构相似度[22],μX、μY为图像X、Y的均值,σX、σY为X、Y的标准差,σXY是X与Y的协方差,C1、C2、C3是用于保证公式稳定性的足够小的常数,结构相似性从更符合人类视觉感知的图像内容和结构角度出发,与像素损失和梯度损失相互补足。
1.3 融合策略
自动编码图像融合框架属于非端到端的图像融合框架,编码器的输出通过融合层后的特征通道数不变,通过设计合适的融合策略将红外与可见特征融合之后将作为解码器的输入。目前,融合策略常见的主要如加法、最大值和平均值等方法。但是,加法、最大值和均值的融合策略是比较直接的图像融合策略,这类融合策略相对来说粗糙,对于一些目标和背景复杂的图像融合质量不佳,并且,由于编码器提取出的双通道特征具有不同的特点,因此本文在双通道网络的基础上改进了融合策略,通过空间L1 范数和注意力机制对残差与密集通道的特征分别进行融合。
1)残差通道特征的融合策略:残差通道输出特征的特点是突出显著信息,目标特征明显,并且特征的层次低,通道数少。因此,在融合残差通道特征时更强调特征图的空间信息,将L1 范数与softmax 运算引入该融合策略,通过L1 范数计算初始活动水平度量的值,随后运用块平均算法计算得到最终活动水平测量值,如式(6)所示。
2)密集通道特征的融合策略:由于编码器提取的红外与可见光信息往往是多通道的,在融合目标图像时需要考虑到空间信息和通道信息,而基于空间L1 范数的融合策略更加侧重于计算空间信息的融合。因此,本文参考文献[23]的处理方式,引入通道注意力机制进行通道信息的融合。通过通道均值运算和softmax 回归运算获得红外与可见光特征通道的权重信息,如式(9)所示。
2 实验结果与分析
2.1 实验平台及参数设置
在训练自编码器时,根据自编码网络本身不具备图像融合的能力并且不会对最终的融合性能造成影响的这一特点,由于MS-COCO 数据集相对于已配准的红外与可见光数据集的场景的覆盖面更广,因此选用MS-COCO 数据集[24]的5 000 图像作为训练集,并且将图像的大小缩放为224×224。选用TNO 数据集[25]的42 组已配准的红外与可见光数据集作为测试数据。训练参数设置为:训练批量为32,训练迭代次数为10,初始学习率为10-4并随着迭代次数下降,损失函数中α设为10,β设为30,γ设为15。在训练过程中去掉融合层,输入为5 000 张彩色图像;在测试过程中加入融合层,输入为成对的红外与可见光图像,并获得融合结果,同时支持彩色图像的融合,方法为将RBG 图像转化为YCrCb 空间实现融合后还原色彩通道。
本次实验的硬件平台为Win10 操作系统;AMD Ryzen 7 3700X CPU,主频为3.6 GHz;GPU 为NVIDIA GeForce RTX 3080。软件平台为VS Code,MATLAB 2019a。代码环境为Python 3.7 版本;Pytorch 1.11.0版本。
2.2 消融性实验分析
为了证明本文重点提出的双通道模块的有效性,在实验过程中测试了单独使用残差连接或者单独使用密集通道(参考文献[13])结合融合层算法的融合性能,由于单个通道不能使用双通道的融合策略,为了控制融合策略的影响,统一使用L1 范数作为融合策略进行实验。
从TNO 数据集中选取4组红外与可见光图像,从上到下分别为“ground”、“people”、“house-1”、“house-2”。对四组图像进行融合的结果如图4 所示,图4(a)为可见光图像,图4(b)为对应的红外图像,图4(c)、(d)、(e)分别为单独使用残差通道、密集通道以及使用双通道级联的融合图。以“house-2”为例进行主观评价可以发现,通过单个通道进行融合后的图像可以提取源红外与可见光图像的大部分信息,但是单个通道提取的特征信息不如双通道的详尽,比如图中红框标出的云朵信息,残差通道提取出的亮度信息有所丢失,密集通道提取的边缘轮廓信息不足,而双通道结构则保留了更多的信息。同时,为了验证本文融合策略的有效性,从TNO 数据集中选取“car”组数据进行对比分析,结果如图5 所示。不难看出,在这组图像中,除去最大值策略的融合结果较少的保留了红外图像特征之外,其余几种融合策略都较好的融合了源图像的信息,其中双通道融合策略相对优秀,在保留细节特征的同时图像的对比度更好,更加清晰。

图4 不同通道的红外与可见光融合结果Fig.4 Infrared and visible light fusion results of different channels

图5 不同融合策略的红外与可见光融合结果Fig.5 Infrared and visible light fusion results of different fusion strategies
为了能够更加直观地体现消融性实验的结果,从TNO 数据集中选取8 组数据分别对双通道网络模块和融合策略进行客观评价分析,为了控制实验变量,对于不同通道都使用相同的L1 范数融合策略,对于不同融合策略则都使用相同的双通道网络结构。实验结果如表2 所示,本文提出的双通道自编码器结构和融合策略在SSIM[26]、SCD[27]和PSNR[28]指标上都带来了融合性能的提升,与主观描述相符合。

表2 消融性实验评价指标平均定量值Table 2 The table of mean quantitative values of experimental evaluation indexes for ablation
2.3 融合图像的主观评价
为了验证本文提出方法的有效性,将本文的方法与7 种红外与可见光融合方法进行比较,包括2 种传统方法:MST-SR[6]、GFT[7]和5 种深度学习方法,分别是基于卷积神经网络框架的IFCNN[29]、PMGI[30]、U2Fusion[31];基于自动编码器框架的DenseFuse[13],Res2Net[21],基于生成对抗网络框架的FusionGAN,从TNO 数据集中选取“pedestrian”组数据进行对比分析。各种算法的对比图如图6 所示,从对比图中不难看出,图中的算法都能够完成红外与可见光融合任务,反映出图中行人的信息,但是一些算法在树枝的纹理特征方面的信息不足,比如GFT、DenseFuse、Res2Net、FusionGAN 方法,而本文提出的算法,在双通道注意力融合策略下相对完整的提取并融合了可见光中的树枝特征,效果略优于其他算法。

图6 “pedestrian”的融合结果Fig.6 Fusion results of “pedestrian”
单一场景的融合图像对比的结果是比较片面的,本文从TNO 数据集中选用六种不同场景下的图像融合结果扩大对比实验。实验结果如图7 所示。从图中不难发现,GFT、FusionGAN 方法的融合图像中物体的轮廓不清晰,缺乏可见光图像的信息;PMGI 和U2Fusion 方法能够较好的反映目标的特征,但是引入了过多的噪声,图像的质量不佳;MST-SR、IFCNN、DenseFuse 方法的图像含有较为清晰的轮廓信息及目标特征,但仍会出现部分信息不明显的情况。而本文方法在大多数融合场景下都能够维持红外与可见光图像间的信息平衡,获得较好的融合结果。

图7 各算法红外与可见光融合结果Fig.7 Infrared and visible light fusion results of each algorithm
2.3 融合图像的客观评价
为了更进一步的验证本文提出方法的有效性,对主观评价中的算法采用6 种典型的客观评价指标进行融合结果质量评价,分别为标准差(Standard Deviation,SD)[32]、相关系数(Correlation Coefficient,CC)、峰值信噪比(Peak signal-to-noise ratio,PSNR)、多尺度结构相似度(Multi-Scale Structural Similarity,MS-SSIM)、差异相关性总和SCD 和互信息(Mutual Information,MI)[33]。本文从TNO 数据集中选取10 组融合图像进行对比实验,通过折线图直观地表示出来,如图8 所示。融合结果的平均定量值如表3 所示,从图表中可以看出,本文所提出的算法相比较于典型传统方法以及近年的深度学习方法在SD、PSNR、MI 三个指标中处于领先,在其余指标中也处于中上水平,具有最好的综合质量。也说明本算法在保留源图像信息、减少噪声的引入同时提高融合图像的质量上有较好的效果,与主观评价相符合。
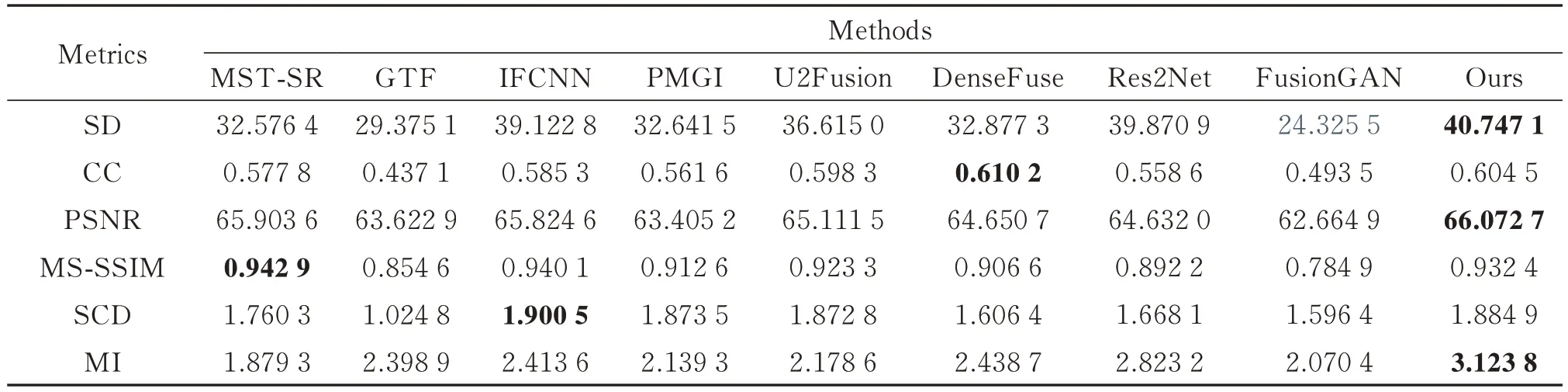
表3 10 组评价指标平均定量值Table 3 The average quantitative value of each evaluation index
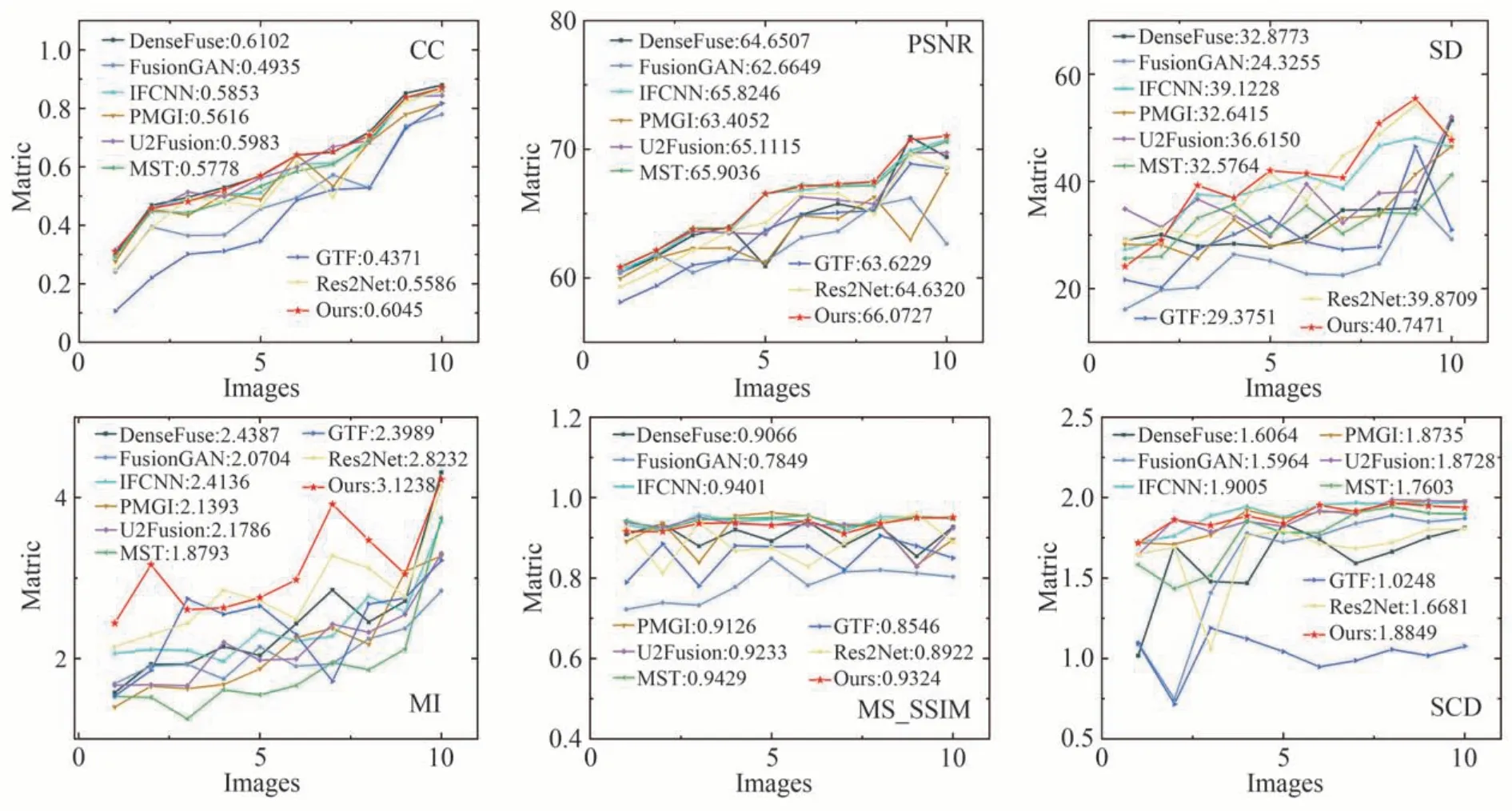
图8 客观实验折线图Fig.8 Objective experimental line chart
3 结论
本文提出了一种基于双通道残差密集网络红外与可见光图像融合方法,用于改善红外与可见光融合图像与源图像间的部分细节特征丢失的问题,充分提取红外与可见光图像中的特征信息,同时在网络结构的基础上,改进了融合策略。通过将该方法与单通道的网络结构对比,证明双通道并联的结构的确提升了图像特征提取的效率。最后将本文的方法与传统以及深度学习融合方法进行对比与分析,结果表明该方法在保留源图像更多细节特征的同时减少噪声和其他干扰的引入,有助于后续的高级视觉应用。后续工作中将继续优化网络参数、优化融合策略、简化网络结构并获取更好的融合效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
昆明医科大学学报(2021年4期)2021-07-23 01:21:56
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
河南科技(2015年8期)2015-03-11 16:23:52
电子设计工程(2015年16期)2015-02-27 12:07:56
电测与仪表(2014年13期)2014-04-04 12:04:18
