
基于改进Swin transformer 的遥感图像融合方法
2023-12-18 09:25李紫桐赵健康徐静冉龙海辉刘传奇
光子学报 2023年11期
李紫桐,赵健康,徐静冉,龙海辉,刘传奇
(上海交通大学 电子信息与电气工程学院 感知科学与工程学院,上海 200240)
0 引言
遥感图像广泛应用于土地监测、环境感知、灾害预测和城市分析等工作。大部分商用卫星都同时搭载可以获取全色图像和多光谱图像的传感器[1],全色(Panchromatic,PAN)图像是二维的灰度图像,具有较高的空间分辨率,多光谱(Multispectral Image,MS)图像的波段数一般大于等于四个,但是由于设备的带宽限制,成像的空间分辨率较低[2]。将星载成像系统捕获到的MS 图像和PAN 图像进行融合生成高空间分辨率多光谱(High Resolution Multispectral,HRMS)图像,这一过程即多光谱-全色图像融合,也称全色锐化[3]。二者融合之后得到同时具有高空间分辨率和高光谱分辨率的遥感影像,可以获取被测对象更准确的细节,从而推动农业、环保等各个领域的进步。
多光谱-全色图像的融合方法可以分为传统方法和深度学习方法两类。传统的多光谱-全色图像融合方法可以分为多分辨率分析方法(Multi-Resolution Analysis,MRA),成分替换方法(Component Substitution,CS)和变分模型方法(Variational Optimization,VO)[4]。MRA 方法把理想的融合图像看成金字塔的最顶层,通过建立两幅源图像的金字塔不同层级之间的关系,从PAN 图像推导出多光谱图像缺失的细节信息并生成HRMS 图像。根据尺度变换函数的不同,MRA 方法包含调制传递函数广义拉普拉斯金字塔(Modulation Transfer Function Generalized Laplacian Pyramid,MTF-GLP)[5]、小波变换(Wavelet)[6]等方法,MRA 方法可以对图像光谱信息进行很好地保留,但经常会出现空间变形的情况。CS 方法先将多光谱图像映射到某一空间之后,再用全色图像来替换其中的空间分量,通过反向变换即可得到锐化的波段。典型的成分替换方法包含主成分分析(Principal Component Analysis,PCA)[7]、亮度-色度-饱和度变换(Intensity-Hue Saturation,IHS)[8]等方法,CS 方法没有对全色图像进行空间变换,所以空间结构保留得比较完整,但是相应地,光谱扭曲的现象很严重。BALLESTER C 等[9]提出一种多光谱-全色变分优化方法,该方法依赖于遥感图像的先验知识,将图像融合问题转化为最优化的求解问题,但是该方法对观测模型正则化参数的计算十分复杂。
相比于传统方法,深度学习方法具有特征提取能力强、识别精度高等优点,因此被广泛应用在多光谱和全色图像的融合中。MASI G 等[10]最早提出基于卷积神经网络的全色锐化方法(Pansharpening by Convolutional Neural Networks,PNN),它的整体网络结构比较简单,只包含三层的卷积结构。PanNet[11]增加了网络的深度,为了实现光谱信息的保留,直接将学习到的高频信息注入上采样后的多光谱图像中。多尺度多深度卷积神经网络(A Multiscale and Multidepth Convolutional Neural Network,MSDCNN)[12]将多尺度特征提取和残差学习引入卷积神经网络中,使用不同大小的卷积核来充分提取图像空间信息。
上述方法都是基于卷积神经网络实现,卷积核主要关注图像的局部特征,忽略了全局特征。而遥感图像通常由大量相似地物组成,这些相似地物在进行高分辨率重建时可以互相弥补缺失的信息,增强图像的特征表示,因此充分利用遥感图像的全局特征是十分必要的。基于自注意力机制的transformer 可以捕获上下文之间的全局交互,DOSOVITSKIY A 等[13]提出的Vision Transformers 最先将transformer 应用于视觉领域,将输入图像分成固定的块,再将每个块投影为固定长度的向量,计算这些块的全局相关性。LIU Z 等[14]提出的Swin transformer 在Vision Transformers 的基础上进行改进,将全局注意力机制转换为局部注意力机制,并通过窗口偏移的操作建立长距离依赖,不仅减少了计算量,还在视觉任务中取得更好的性能。ZHOU H 等[15]最先将Swin transformer 结构作为全色锐化网络的主干模块,提出的Panformer 网络表现出了比基于卷积神经网络的模型更好的性能,FAN Wensheng 等[16]也提出了基于Swin transformer 的双分支U 形融合网络,充分地利用了图像的全局上下文特征,但这两种方法只是对Swin transformer 的简单使用,并没有调整其结构以更好地适应复杂地面场景的遥感图像融合任务。
本文提出一种基于多尺度窗口自注意力的多光谱-全色融合方法(Multiscale Swin-transformer with Channel Attention NetWork,MSCANet),在网络的融合部分集成了一种新的即插即用模块:多尺度窗口注意力单元(Multiscale Swin-transformer with Channel Attention,MSCA)。该单元将Swin transformer 输出部分的多层感知器(Multi Layer Perception,MLP)替换成多尺度卷积核和通道注意力的级联模块,在利用区域之间的长程依赖的同时,更好地融合遥感图像不同尺寸地物的特征信息,从而进一步提升融合结果。MSCANet 基于细节注入模型,融合网络不是直接预测HRMS 图像,而是专注于预测多光谱图像丢失的高频细节,再将高频细节与原始图像相加得到高分辨率多光谱图像。
1 网络结构
网络整体结构如图1,输入图像分别为低空间分辨率多光谱(Low Resolution Multispectral,LRMS)图像和PAN 图像,采用结构相同但权重不同的双流结构分别对两幅源图像进行特征提取,特征提取使用到的卷积核大小为3×3。使用大小为2×2、步长为2 的卷积核将特征图像的长和宽下采样为原来的1/2,下采样的特征经过通道维的拼接之后送入融合模块。在融合模块嵌入了MSCA 模块,用于融合多光谱和全色图像的多尺度空间信息,并加强全局特征的交互,最后将MSCA 输出的高层特征与前序的低层特征通过跳跃连接送入恢复模块(Restore Block),恢复模块输出的是多光谱图像缺失的高频信息,将该高频图像注入输入的LRMS 图像中即可生成目标的HRMS 图像。

图1 网络总体结构Fig.1 Overall network structure
1.1 细节注入模型
MRA 方法采用细节注入的方法来提高多光谱图像的空间分辨率,如式(1)。原始的多光谱图像用M∈RH×W×C表示,四倍上采样之后的多光谱图像为Mup∈R4H×4W×C,全色图像用P∈R4H×4W×1表示,假设要合成的高分辨率多光谱图像MHS∈R4H×4W×C包含低频分量和高频分量,第k个波段的多光谱图像缺少的高频细节信息可以由全色图像推断出,因此将低频分量与全色图像的高频细节直接相加,gk代表第k个波段的细节注入权重,P和PL分别表示全色图像和它的低通滤波部分,P-PL为全色图像的高频部分,向Mup注入的缺失信息得到融合图像。
细节注入模型通过计算缺失的细节信息,在不影响光谱结构的同时最大程度提升空间分辨率,实现有效的光谱保真[17],可以有效地用于多光谱图像和全色图像的融合。但式(1)只是将全色图像的高频部分与细节注入权重直接相乘的结果作为每个波段需要注入的细节信息,而多光谱各个波段的光谱响应曲线常常是非线性的,且波段之间存在重叠现象。为了建立准确的融合模型,本文保留了MRA 方法的细节注入模型的思想,使用深度学习建模端对端非线性模型,如图2。图中F(Mup,P;θ)代表以θ为参数,输入为Mup和P的深度学习融合模型,模型可以更好地拟合多光谱图像丢失的高频细节,最终输出的高频细节和原始图像直接相加,其计算表达式为

图2 细节注入模型Fig.2 Detail injection model
1.2 多尺度窗口注意力单元MSCA
在融合阶段,将全色图像和多光谱图像的特征在通道维进行拼接,从而实现光谱和空间信息的整合。融合网络由多尺度窗口注意力单元MSCA 和特征下采样结构组成。MSCA 是对Swin transformer 的改进,通常一个Swin transformer 由两个级联的滑动窗口transformer 块(Swin Transformer Block,STB)组成,第一个STB 由窗口多头自注意力模块(Window Multihead Self Attention,W-MSA)和MLP 级联构成,第二个STB 则由滑动窗口多头自注意力模块(Shift Window Multihead Self Attention,SW-MSA)和MLP 组成。MSCA 保留了第一个STB 结构,并将第二个STB 中的MLP 替换成多尺度通道注意力模块,在减小计算量的同时捕获了不同尺度的图像特征。
1.2.1 W-MSA
对于尺寸为H×W×C的输入图像,W-MSA 模块将输入划分成尺寸为M×M的互不重叠的窗口,然后在每个窗口中计算自注意力,窗口数量为。对于局部特征窗口X∈RM2×C,将图像块通过线性嵌入(Linear Embedding)转换成长度为C×1 的序列,序列个数为M2,对序列进行相关性的运算,得到Q、K、V向量,分别代表查询矩阵、匹配矩阵和信息矩阵。可学习的相对位置编码表示为B,利用多头注意力机制学习到不同子空间的信息,自注意力的计算表达式为
接下来使用MLP 层来对特征X进行特征变换,为了易于训练,在MSA 和MLP 模块之前加入层归一化(LayerNorm,LN)层和残差连接结构,如式(4),最终输出的特征图尺寸为,将特征重新排列成H×W×C,并送入第二个STB 模块。
1.2.2 多尺度通道注意力模块
Swin transformer 的第二个STB 模块包含SW-MSA 和MLP 部分,其中SW-MSA 通过窗口的移动解决了不同窗口无法进行信息交流的问题,MLP 以像素点为单位进行计算,用全连接的方式进行全局特征交互,却忽略了对不同大小地物(如建筑物、植被、河流、车道等)的特征融合。受到LI B 等[18]在人体行为识别网络中将transformer 中的MLP 模块替换成多尺度卷积这一方法的启发,本文将第二个STB 的MLP 部分替换成多尺度通道注意力机制模块,从而整合和利用不同尺度的全局信息,如图3。不同大小的卷积核可以获取不同大小感受野的特征,在多尺度卷积之后建立特征通道间的依赖关系,增强高频空间特征和光谱分布特征的通道权重,削弱其他不重要的通道权重。
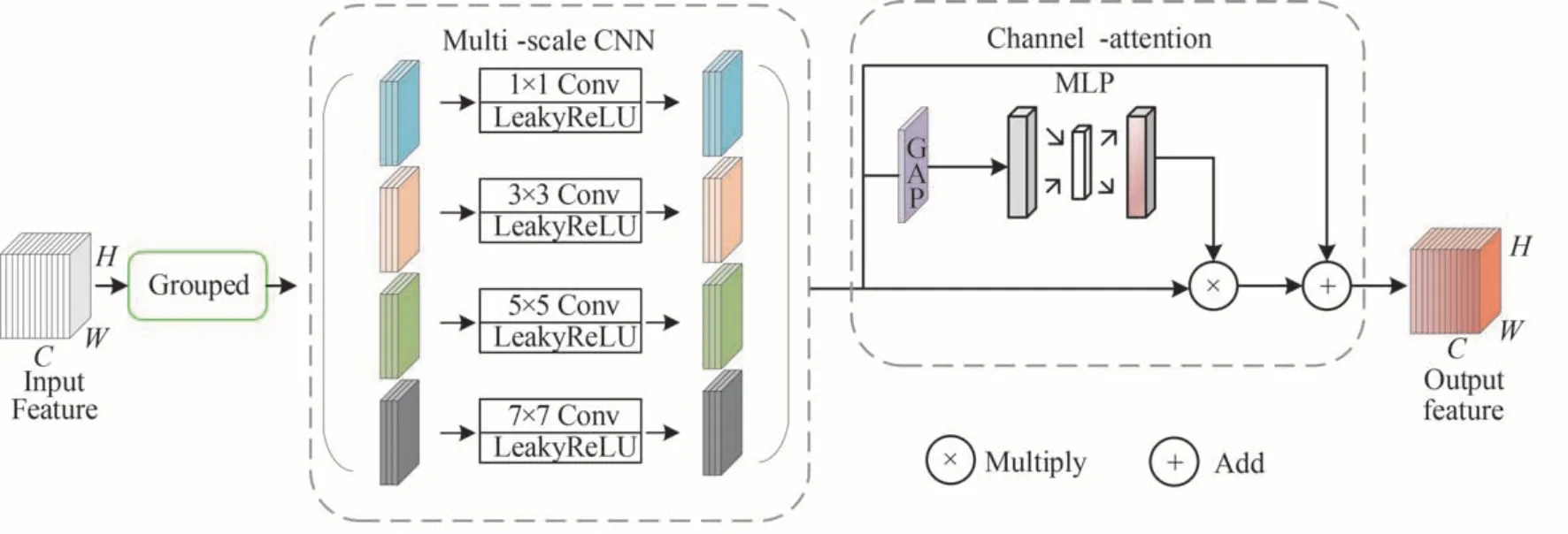
图3 多尺度通道注意力模块Fig.3 Multi-scale CNN and channel attention module
不同于MSDCNN[12]中的多尺度卷积结构,为了节约参数,本文使用分组卷积来替代常规卷积,将尺寸为H×W×C的输入特征图按通道维平均分为4 组,每组的特征尺寸为,然后对每组分别进行卷积运算,卷积核尺寸为1×1、3×3、5×5、7×7,激活函数为LeakyReLU。为了保留有益的空间和光谱信息,MSCANet 在多尺度卷积块之后加入通道注意力机制。首先将级联后尺寸为H×W×C的特征图进行全局平均池化,得到1×1×C的权重向量;然后依次通过两个全连接层,第一次全连接的神经元数目为,第二次全连接的神经元数目为C,再通过sigmoid 函数将权重向量的值固定在[0,1]之间;最终将权重和输入特征相乘,在通道注意力的基础上加入残差连接,帮助融合网络快速收敛。
1.3 特征重建网络
获取到融合图像的特征图之后,使用转置卷积(Transpose Conv)操作对其进行逐级上采样并恢复其空间分辨率。由于直接从高层特征恢复纹理信息是困难的,本文借鉴了U-Net[19]的思想,通过跳跃连接(Skip Connection)降低从高层特征中恢复细节纹理的难度。在每个上采样操作之后,将前序特征与当前特征图进行拼接,有利于恢复真实的空间细节。在网络的结尾使用卷积核和Tanh 激活函数层来重建输出的高分辨率多光谱图像,如图4。
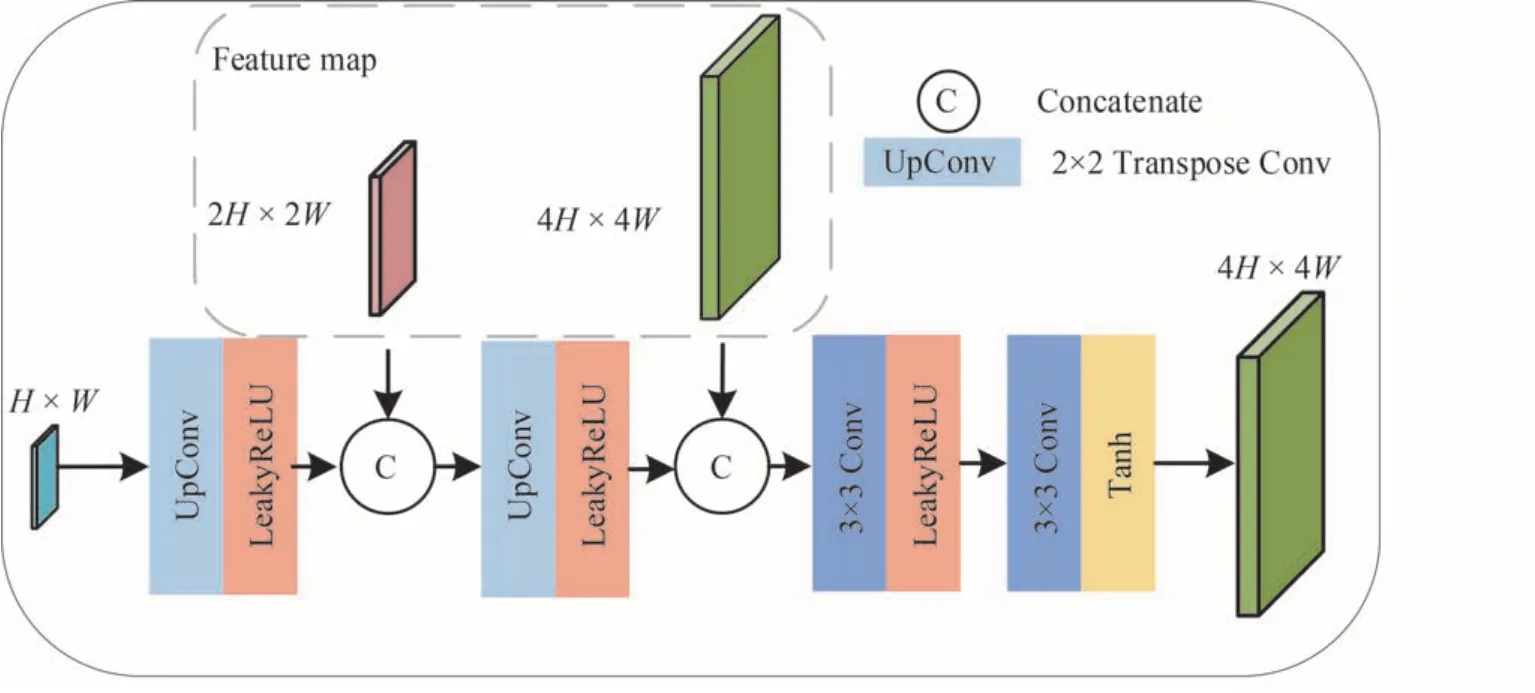
图4 特征重建网络结构Fig.4 Structure of feature reconstruction network
2 损失函数
常见的多光谱-全色融合方法采用平均绝对误差(Mean Absolute Error,MAE)损失函数对网络参数进行优化,相比于均方误差(Mean Square Error,MSE),MAE 可以更好地减少回归问题引起的平滑伪影,MAE损失表示为式(5),其中为模型预测得到的融合图像,G为参考图像,‖·‖1代表一范数运算。
MAE 损失虽然可以对融合图像进行约束,但是缺乏对光谱波段的关系运算和空间结构的保真运算。本文在MAE 损失的基础上分别加入空间结构损失和光谱损失,其中光谱损失如式(6),参考了SAM 的计算公式,用于约束光谱损失,〈·,·〉表示内积的运算。
为了最大程度地进行空间信息的保留,空间结构损失的计算式参考SSIM 公式,如式(7)、(8),其中μx和μy代表局部像素强度的平均值,σx和σy代表局部标准差,C1和C2是防止损失无穷大的平衡参数。
总损失L的计算如式(9),它是MAE 损失、光谱损失和空间结构损失的线性组合,光谱损失和空间结构损失的权重系数分别为α和β,通过最小化L来训练本文提出的融合模型。
3 实验结果与分析
3.1 数据集
实验使用公开的标准数据集NBU_PansharpRSData[20],选取其中的WorldView-4(WV4)、QuickBird(QB)以及WorldView-2(WV2)卫星数据。每个卫星数据包含500 对多光谱-全色图像,其中原始多光谱图像的尺寸为256×256×C,WV4 卫星和QB 卫星包含四个波段,C=4,WV2 卫星包含八个波段,C=8,原始全色图像的尺寸为1 024×1 024×1。
按照9∶1 的比例划分训练集和测试集,将其中的50 张图像用于测试,450 张图像用于训练。由于缺少真实的高分辨率多光谱参考图像,在训练时把原始多光谱图像作为参考的HRMS 图像,并采用Walds 协议,根据卫星的MTF 函数分别对原始多光谱图像和原始全色图像进行高斯滤波和四倍的下采样,得到LRMS 图像和PAN 图像。为了扩充训练的数据集,还要对HRMS 图像、LRMS 图像和PAN 图像进行裁剪,经过滤波之后的PAN 图像的尺寸为256×256×1,对每张PAN 图像按照32 像素的重叠从左至右,从上至下依次进行裁剪,裁剪得到的每个图像块的尺寸为64×64×1,因此一张原始尺寸为256×256×1 的PAN 图像可以裁剪成49 张尺寸为64×64×1 的PAN 训练图像。MS 图像的裁剪方式与之相同,重叠像素设置为8,图像块大小为16×16×C。最终得到的训练集包含22 000 对空间尺寸分别为16×16×C和64×64×1 的多光谱-全色图像对,参考图像的尺寸为64×64×C。全分辨率测试集则直接对原始的LRMS 图像和PAN 图像进行融合,没有参考的HRMS 图像,数据集的具体信息如表1。

表1 数据集的具体信息Table 1 Specific information about the dataset
3.2 实验设置
本模型基于PyTorch 框架实现,使用的显卡型号为NVIDIA GeForce RTX 3090 Ti。设置的最大训练代数(Epoch)为200,批大小(Batch Size)为32。根据式(9)进行损失函数的计算,损失函数中的α和β均设置为0.1,并采用Adam 优化器对模型参数进行优化。初始学习率为1×10-4,每隔3 500 个训练步数,学习率衰减为原来的0.99 倍,训练时将图像数据归一化到[ -1,1]。在训练过程中,输入的LRMS 和PAN 的尺寸分别为16×16×C和64×64×1,C为波段数目,网络输出的是融合图像归一化到[ -1,1]之后的结果,融合图像的尺寸为64×64×C。在真实图像的测试阶段,使用训练好的模型参数,输入的LRMS 和PAN 的尺寸分别为256×256×C和1 024×1 024×1,输出的HRMS 的尺寸为1 024×1 024×C。MSCANet 的训练过程如下:

为了验证提出方法的有效性,将MSCANet 与9 种常见方法进行比较,包括四种传统方法MTF-GLP[5]方法、Wavelet[6]方法、IHS[8]方法和PCA[7]方法以及五种深度学习方法FusionNet[21]、Panformer[15]、MSDCNN[12]、LAGConv[22]和TFNet[23],其中Panformer 基于Swin transformer 实现,FusionNet、MSDCNN、LAGConv 和TFNet 基于卷积神经网络实现。所有对比方法都使用了原始的设定参数和相同的测试集,基于深度学习的方法使用了相同的训练集。
3.3 客观评价指标
在图像融合过程中,目标的高分辨率多光谱图像的真实值实际上不存在,因此通常采用的评价指标体系基于两种方式,分别是降分辨率(Reduced Resolution,RR)评价指标和全分辨率(Full Resolution,FR)评价指标。
降分辨率评价指标用于有参考影像的评估,将待融合的全色和多光谱图像分别下采样到更低分辨率的训练图像,将原始的多光谱图像看成真实值,并计算融合图像和真实值的差异。本文采用四种评价指标,分别是衡量融合综合性能的相对全局误差(Erreur Relative Global Adimensionnelle Synthesis,ERGAS)、图像峰值信噪比(Peak Signal to Noise Ratio,PSNR)、计算融合图像和参考图像之间光谱相似度的光谱角度(Spectral Angle Mapper,SAM)和计算融合图像和参考图像高频空间细节相似度的空间相关系数(Spatial Correlation Coefficient,SCC)。
全分辨率指标用于无参考影像的评估,使用真实的数据,将多光谱和全色图像在原始尺度进行融合,分别计算融合图像和两幅源图像的差异。本文采用无参考质量指标(Quality with No Reference index,QNR)以及它的光谱细节损失分量Dλ和空间细节损失分量DS来定量评价全分辨率下的融合结果。
3.4 降低分辨率下的实验结果分析
在四波段卫星数据集WorldView-4、QuickBird 以及八波段卫星数据集WorldView-2 进行降低分辨率下的多光谱-全色融合实验,分别从主观视觉结果和客观评价指标ERGAS、SAM、PSNR、SCC 给出各个方法的实验结果。
3.4.1 WV4 数据集实验结果
WV4 数据集下主观视觉比较结果如图5,MTF-GLP 方法虽然恢复出了大部分的纹理信息,但是在放大区域泛白严重,而且整体较参考图片颜色更淡;Wavelet 方法出现了明显的和细节模糊;IHS 方法和PCA方法的空间清晰度很高,但是整体颜色与真值差距较大,无法很好地还原地物色彩。可以看出,五种基于深度学习的方法相比传统方法的主观视觉融合效果更好。

图5 WorldView-4 仿真数据集融合结果Fig.5 Fusion result of WorldView-4 simulation dataset
计算融合图像与参考图像在各个波段的的平均差值,结果如图6。FusionNet、Panformer、MSDCNN、LAGConv 方法和TFNet 的边缘轮廓失真比MSCANet 更加明显,而MSCANet 和真值图像具有更好的相似性,在主观视觉上具有最好的效果。

图6 WorldView-4 仿真数据集的残差图Fig.6 Residual graph of WorldView-4 simulation dataset
对客观评估结果进行分析,如表2,其中传统方法中IHS 的结果最好,MLP、Wavelet 和PCA 方法的各项评估指标较深度学习方法有较大差距,证明传统方法无法对多光谱图像进行很好的光谱保真和空间细节增强。TFNet 在各种深度学习方法中性能第二,MSCANet 的各项指标均优于TFNet,其中SAM 减少了9.12%,ERGAS 减少了11.99%,PSNR 和SCC 分别提升了3.47%和0.41%。

表2 仿真数据集的客观评价指标Table 2 Objective evaluation index of simulation dataset
3.4.2 QuickBird 数据集实验结果
QuickBird 数据集下的主观效果如图7,其中四种传统方法与真实值的颜色差距较大。图8 为QuickBird 数据集融合图像和参考图像在各个波段的平均残差图,FusionNet和MSDCNN 在建筑物的边缘轮廓与真值的偏差较大,Panformer、LAGConv 和TFNet在细节处的空间清晰度相对较高,但是在房屋和道路的分界区出现了一些失真,MSCANet 相比于其他方法在残差图中出现的亮点更少。对客观评估结果进行分析,其中MTFGLP 在传统方法中表现最好,但各项评估结果还是落后于深度学习方法,MSCANet相比于排名第二的TFNet分别在SAM 指标减少2.53%,ERGAS 指标减少0.4%,PSNR 和SCC 指标分别提升了0.11%和0.04%。

图7 QuickBird 仿真数据集融合结果Fig.7 Fusion result of QuickBird simulation dataset

图8 QuickBird 仿真数据集的残差图Fig.8 Residual graph of QuickBird simulation dataset
3.4.3 WorldView-2 数据集实验结果
WorldView-2 是八波段卫星,选取其中RGB 波段显示主观视觉效果,如图9。MTF-GLP 方法的图像颜色偏淡,Wavelet 和IHS 方法对空间细节的恢复程度较好,但整体光谱扭曲较明显,蓝色建筑物和灰褐色道路的色彩和真值图像差距较大,PCA 方法的表现较差,几乎无法辨认房屋的边缘轮廓。

图9 WorldView-2 仿真数据集融合结果Fig.9 Fusion result of WorldView-2 simulation dataset
进一步分析波段平均残差图的结果,如图10,可以看出FusionNet、MSDCNN、LAGConv 在白色U 形区域出现了明显的纹理失真,Panformer 和TFNet 的效果相对较好但也出现了较多亮线,证明与真实图像存在一定的偏差,而MSCANet 在各种方法中的主观视觉效果最好。
WorldView-2 卫星含有八个波段,所以融合难度要高于四波段图像,在传统方法和深度学习方法的定量评估结果相比其他两种数据集略差,但MSCANet 依然在各种方法中表现出了最好的效果,相比于排名第二的方法,ERGAS 降低了3.43%,SAM 降低了2.68%,PSNR 和SCC 分别提高了0.94%和0.32%。
3.5 全分辨率下的实验结果分析
在三个数据集分别进行全分辨率实验,将真实的多光谱和全色图像融合,使用主观视觉图像效果以及无参考质量指标QNR、QNR 的光谱细节损失分量Dλ、QNR 的空间细节损失分量DS三个指标来对比各个方法的融合效果。图11 给出各种方法在WV4 数据集的真实图像融合效果,MTF-GLP 和Wavelet 方法的边缘模糊严重,IHS 方法的图像整体偏红,PCA 方法生成的图像比较暗,而且屋顶处的红色物体几乎难以辨认,存在一定的光谱扭曲。FusionNet、MSDCNN 和LAGConv 在建筑物的交界处出现了细节丢失的现象,Panformer、TFNet 则在左下角的泳池处出现了一定程度的色彩失真,而MSCANet 的主观视觉效果最好。

图11 WorldView-4 真实数据集融合结果Fig.11 Fusion result of WorldView-4 real dataset
表3 展示了各种方法的客观评价指标结果。MSCANet 在所有数据集的QNR 数值指标均优于其他方法,综合视觉效果和数值指标结果分析,本文方法在全分辨率下的实验结果最佳。
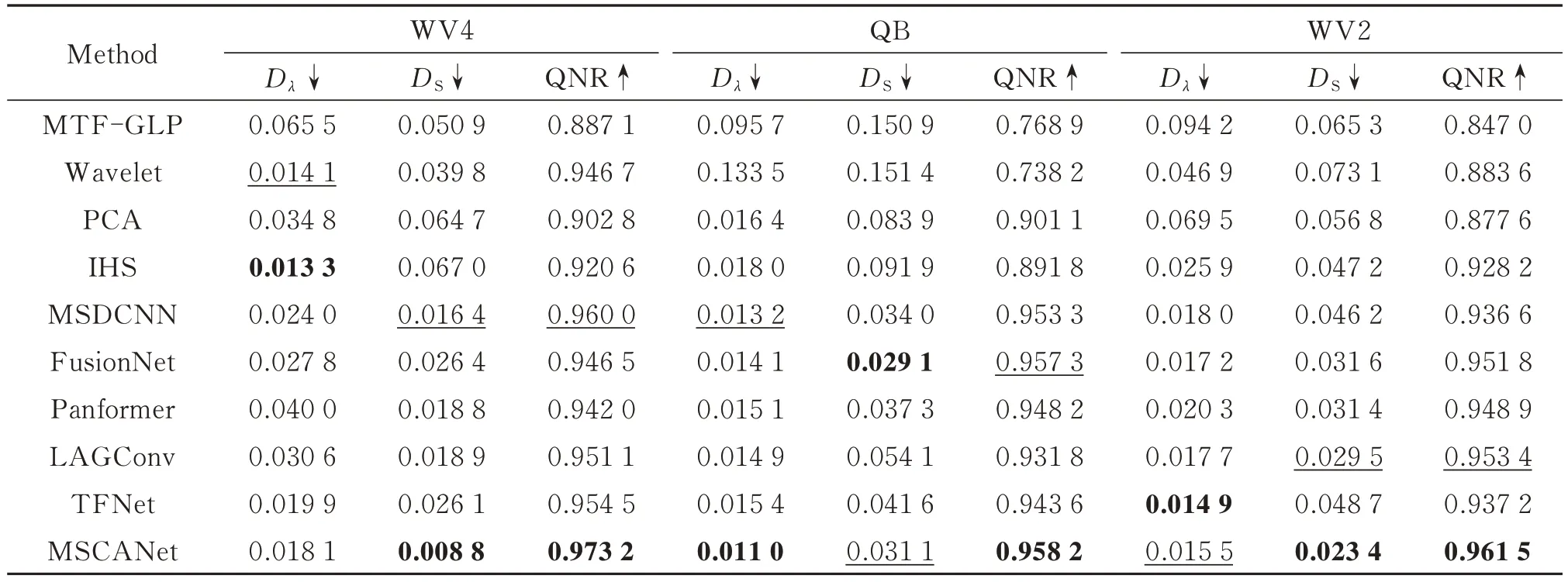
表3 真实数据的客观评价指标Table 3 Objective evaluation index of real dataset
3.6 消融实验结果分析
本文融合方法使用的三个策略分别是:1)使用细节注入模型注入高频细节;2)使用多尺度窗口自注意力MSCA 模块作为融合网络的主干结构;3)在MAE 损失函数的基础上加入光谱损失和空间损失,在WorldView-4 数据集上针对每个策略分别进行了消融实验并验证其有效性。
3.6.1 注入模型的有效性分析
本文方法基于注入模型(Injection model),融合网络直接预测多光谱图像缺失的细节,再将网络输出的细节与原始多光谱图像相加,如式(2),而另一种常见的多光谱-全色融合模型是非注入模型(Non-injection model),网络直接预测目标高分辨率多光谱图像,其计算表达式为
分别给出这两种模型在WorldView-4 数据集上的融合结果,如表4,可以发现注入模型在各个客观评价指标上的结果均优于非注入模型,验证了本文采取的注入模型策略的有效性。

表4 注入模型在WV4 数据集的消融实验结果Table 4 Ablation result of injection model in WV4 dataset
3.6.2 多尺度窗口注意力单元MSCA 的有效性分析
本文提出了多尺度窗口注意力单元MSCA,该单元将原始的Swin transformer 中第二个STB 的MLP 结构替换成了多尺度卷积结构,并在多尺度卷积单元之后加入通道注意力(Channel Attention,CA)结构。为了验证MSCA 的有效性,将三种结构进行对比,分别是原始的STB 结构、MSCA 消去注意力机制的结构以及本文提出的MSCA,分别对应图12 中的(a)、(b)、(c)。

图12 三种不同的窗口注意力单元结构Fig.12 Three different window attention unit structures
实验结果如表5,将MLP 模块替换成多尺度单元之后,各项客观评价指标结果都比原始的STB 结构有明显提升,证明了对遥感图像不同尺度的信息进行融合的策略相比于原始STB 的MLP 全连接结构更加有效。在多尺度单元后加入通道注意力机制,融合结果进一步提升,其中ERGAS 和SAM 分别减小了4.59%和3.43%,证明了在融合模块中加入通道注意力权重对空间和光谱信息的保留都是有益的。另外,将Swin transformer 模块改进之后,模型的总参数量由2.20×106减少为1.99×106,证明改进后的模型不仅融合效果更好,运算效率也有所提升。

表5 MSCA 模块在WV4 数据集的消融实验结果Table 5 Ablation result of MSCA in WV4 dataset
3.6.3 损失函数的有效性分析
本文提出的损失函数在MAE 损失的基础上增加了光谱损失(Spectral loss)和空间结构损失(Spatial loss),为了验证新加入的损失函数的有效性,设计了四种不同的损失函数组合,分别是MAE、MAE+Spectral loss、MAE+Spatial loss 和MAE+Spectral loss+Spatial loss。在WorldView-4 数据集进行消融实验,实验结果如表6。

表6 损失函数在WV4 数据集的消融实验结果Table 6 Ablation result of loss function in WV4 dataset
分析结果可知,相比单独的MAE 损失,单独加入光谱损失可以提升其SAM 结果,即减少融合图像的光谱扭曲程度,单独加入空间结构损失主要提升了ERGAS 结果,增加了融合图像与参考图像的空间相似程度。同时加入光谱损失和空间损失之后各项评估指标比单独加入其中一项的结果更好,有利于空间信息和光谱信息的同时保持,证明了本文提出的组合损失函数的有效性。
3.7 网络性能分析
所有方法的训练和测试实验在NVIDIA GeForce RTX 3090 Ti 显卡下实现,表7 给出了各个网络训练所需的参数量和三个数据集平均每张图片所需的测试时间。其中传统方法无需训练,所以只给出平均测试时间,MTF-GLP 在各个方法中耗时最长,运行效率最低。

表7 所有方法的平均测试时间和参数量Table 7 Average test time and number of parameters for all methods
在深度学习方法中,自注意力运算相比卷积神经网络的方法时间开销更大,所以MSCANet 和Panformer 方法的测试时间略高于其他四种基于CNN 的深度学习方法,但是本文方法的测试时间短于Panformer。MSCANet 的模型参数量高于MSDCNN、FusionNet 和LAGConv 三种轻量级模型,但比TFNet的训练参数更少,虽然MSCANet 网络运算复杂度适中,但是考虑到融合效果相比其他方法具有更好的光谱保真和空间结构相似性,本文方法依然更具优势。
4 结论
为了更有效地提升卫星捕获到的多光谱图像的空间分辨率,提出了一种基于改进Swin transformer 的融合网络MSCANet。模型使用双流分支提取多光谱图像和全色图像的特征,降采样之后的特征图像在通道维级联并送入融合网络。为了提高在各种复杂地面场景中特征提取的鲁棒性,在融合部分集成了一个多尺度窗口注意力单元MSCA,该单元是对Swin transformer 的改进,将第二个STB 中的MLP 模块替换成了多尺度卷积和通道注意力机制。最后,将高层特征与低层特征进行跳跃连接,采用注入模型恢复出高分辨率的多光谱图像。为了实现空间结构信息保真和光谱保真,用MAE 损失、光谱损失和空间结构损失的组合损失函数优化模型。分别在三种商用卫星的仿真数据和真实数据集进行对比试验,MSCANet 相比其他方法的视觉表现效果和客观评估结果都显著提升。针对本文提出的三个融合策略进行了消融实验,实验结果表明,本文采用的注入模型、MSCA 模块的搭建以及损失函数的组合对于光谱保真和空间分辨率提升均是有效的。在未来的工作中,可以将本文提出的MSCANet 迁移到多光谱图像和高光谱图像的融合、可见光图像红外图像融合等类似的任务中,提高本文模型的泛化性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
家庭影院技术(2021年7期)2021-08-14
数学小灵通·3-4年级(2021年5期)2021-07-16
家庭影院技术(2020年8期)2020-09-11
收藏界(2019年4期)2019-10-14
今日农业(2019年15期)2019-01-03
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
