
面向无人机遥感场景的轻量级小目标检测算法
2023-12-16 10:29:50胡清翔饶文碧熊盛武
计算机工程 2023年12期
胡清翔,饶文碧,2,熊盛武,2
(1.武汉理工大学 计算机与人工智能学院,武汉 430000;2.武汉理工大学 三亚科教创新园,海南 三亚 572000)
0 概述
目标检测是计算机视觉领域的重要研究方向,随着深度学习的不断发展,基于深度学习的目标检测方法逐步取代了传统的检测方法。
小目标检测是目标检测领域中的重点和难点方向之一。CHEN 等[1]将小目标定义为目标所占的像素面积与图像总面积的比值小于0.58%。此外,不同的数据集对小目标也有各自的定义。在COCO 数据集中,尺寸小于32×32 像素的目标为小目标。小目标具有分辨率低、像素过少以及位置缺乏准确性的特点。因此,相对于通常尺寸的目标,小目标的检测更加困难。
为获得较优的检测结果,研究人员不断增加目标检测网络模型的宽度、深度,网络结构复杂,模型参数量以及运算量极大,难以部署到无人机等边缘设备且无法达到实时检测的目的[2-3]。具有实时检测能力的小目标检测算法逐步得到研究人员的关注。为提升小目标检测能力,主要有以下方法:对图片进行超分辨率[4-5]、数据增强[6-8]、多特征融合[9-11]、结合上下文信息加强特征提取[12-13]以及额外预测目标框的旋转角度[14-15],使预测框更贴近真实目标。上述方法为增强小目标的检测能力,需要增加极大的计算代价,因而在实际应用中难以满足实时检测要求。
文献[4]提出通过生成对抗网络(Generative Adversarial Network,GAN)对两阶段算法中的候选区域进行超分辨率,然后对超分辨率后候选区域中的目标进行分类以及定位。为减少MTGAN 中超分辨方法带来的巨量计算代价,文献[5]提出一种对候选区域进行裁剪的方法,将超分辨率方法应用于裁剪后的候选区域。但是上述方法具有较大的计算代价和时间开销,并且基于GAN 的超分辨率方法会产生人工噪音,对小目标的检测起到负面影响。
AKYON 等[6]提出SAHI 方法。SAHI 方法通过切片辅助推理,将图片分割为多个重叠的切片,提升小目标在切片图像中的占比,最后对切片图片检测出的结果进行非极大值抑制(Non-Maximum Suppression,NMS)后处理,从而获得最终的检测结果。SINGH 等[8]提出图像金字塔方法,将同一张图像设置为不同尺寸大小,并将其送入神经网络,在尺寸大的图片上检测小目标,在尺寸小的图片上检测中、大型目标。WOO 等[9]提出StairNet 方法,在上采样过程中引入反卷积操作。与不可学习的线性上采样相比,可学习的反卷积可以获得特征的细节信息,有利于小目标特征信息的保存以及传递。戚玲珑等[11]提出一种改进YOLOv7 的小目标检测方法,利用注意力机制与SIoU 损失函数提高网络对小目标的敏感度,但是没有进一步研究IoU 度量方法对小目标的影响。ZHU 等[12]提出TPH-YOLO 方法,TPH-YOLO方法在YOLOv5 方法的基础上,使用Transformer 获取上下文信息,在特征融合网络中加入CBAM 注意力机制加强小目标的特征提取能力。HAN[14]等提出ReDet,通过额外预测目标框的旋转角度并且提出旋转不变的特征对齐方法,加强对航空图像中的小目标的检测精度,但是网络需要额外预测目标框角度,增加了网络的学习成本与收敛难度。
针对目标检测模型难以部署在边缘设备、不能达到实时检测以及小目标检测不佳的问题,本文提出基于YOLO 的轻量级小目标检测算法SS-YOLO。为达到实时检测速度,SS-YOLO 使用深度可分离卷积操作删除多分支并行结构,精简网络架构。为解决小目标检测能力不足的问题,SS-YOLO 增加了用于检测微小目标的特征图P2,并且通过SUCA(Semantic Upsampling Convolution with Adaptive fusion factor)模块加强低层特征图的语义信息。使用基于二维高斯分布的LCNWD损失函数增强网络对小目标进行定位,克服IoU 度量方法对目标尺寸敏感的缺点。
1 YOLO 模型及改进思路
YOLO 系列算法在目标检测领域中具有推理时间较快、检测精度较高的优点。因此,本文提出轻量级主干网络、SUCA 模块以及LCNWD损失函数,并将其应用于YOLOv5 算法。
1.1 YOLO 算法
YOLOv5 网络模型结构如图1 所示。该模型由3 个主要部分构成,分别是用于初步提取特征的主干网络Backbone、特征融合网络Neck 以及用于分类和定位的预测头Head。Backbone 在对输入图像进行特征初步提取获得特征图后,送入特征融合网络Neck 进行特征增强,得到下采样倍数分别为8、16、32 的特征图P3、P4、P5。检测头Head 在不同尺寸的特征图上检测不同尺寸大小的目标。

图1 YOLOv5 网络模型结构Fig.1 Structure of YOLOv5 network model
1.2 改进思路
本文提出的改进思路示意图如图2 所示。加快目标检测速度的主流方法是使用深度可分离卷积以减少网络参数量、删除网络中多余的旁路分支以精简结构。受TRC 方法[16]的启发,本文提出结合归一化注意力的PP-LCNet[3]轻量级网络作为特征提取网络,以加快网络的检测速度。

图2 本文的改进思路示意图Fig.2 Schematic diagram of improvement ideas in this paper
在YOLOv5 中,Neck 部分会输出下采样倍数分别为8、16、32 的3 个特征图,分别用于检测小型、中型以及大型目标。但是在面向无人机遥感领域中,存在大量尺寸小于12 像素的远景目标。这些目标即使在下采样倍数为8 的特征图中也很难保存足够的 特征信息。受YOLOF[17]的启发,在Neck 网络中额外加入下采样倍数为4 的特征图P2,用于检测极小的远景目标。
文献[18-19]提出的目标检测包含需要语义信息的分类任务以及位置信息的定位任务。高层的低分辨率特征图(P4、P5)具有较强的语义信息,但是定位信息较弱。与其相反,低层的特征图(P2、P3)语义信息较弱,但是定位信息较强。自底向上的路径聚合网络通过加强高层特征图的定位信息,提升中大型目标的检测能力。但是在无人机遥感图像中,待检测的小目标聚集在P2、P3 特征图中,因此单独提升P4、P5 特征图的定位信息对于小目标检测性能基本没有提升。由于P2、P3 特征图的语义信息较弱,因此为加强小目标的检测能力,需要额外增强其语义信息。受DUC(Dense Upsampling Convolution)[20]以 及fusion factor[21]的启发,本文提 出SUCA 结合自适应融合因子的语义上采样卷积方法,用于补充低层特征图中的小目标的语义信息。
在目标检测网络中使用最广泛的定位回归损失函数为IoU 损失函数,但是IoU 度量方法对目标尺寸敏感。在相同偏移下,大目标的IoU 值显著大于小目标的IoU 值,因此网络对小目标的定位关注程度明显低于大目标。受CIoU 损失函数与归一化Wasserstein距 离(Normalized Wasserstein Distance,NWD)方法[22]的启发,本文提出结合NWD 度量方法与中心点距离惩罚项的LCNWD定位回归损失函数,使目标检测网络更加关注小目标的定位回归,加强定位精度。
2 SS-YOLO 算法
SS-YOLO 网络模型结构如图3 所示。

图3 SS-YOLO 网络模型结构Fig.3 Structure of SS-YOLO network model
2.1 轻量的主干网络
YOLOv5 使用CSPDarkNet 作为主干网络,结构复杂,需要大量计算资源并且推理时间较长,不满足实时性要求,不适合部署在无人机等边缘设备上。为满足在边缘设备上的实时检测要求,本文基于轻量级网络PP-LCNet,结合基于归一化的注意力机制NAM 提出一种新的主干网络。改进后的PP-LCNet主干网络的参数信息如表1 所示,其中,Conv 代表普通卷积,DSConv 3、DSConv 5 为使用深度可分离卷积搭建的基础模块,NAM[23]为加强网络特征提取能力的注意力模块。

表1 改进的PP-LCNet 主干网络参数信息Table 1 Parameter information of improved PP-LCNet backbone network
在PP-LCNet 中使用深度可分离卷积大幅度减少网络参数量。通过反复使用DSConv 3、DSConv 5这2 个模块进行网络堆叠,以较低的计算成本实现多尺度特征融合和感受野扩展。
深度可分离卷积减少了网络参数量、加快网络速度,但是其忽略了通道与空间之间的联系。因此,深度可分离卷积通常会降低网络检测性能。为弥补深度可分离卷积带来网络性能下降的不足,本文使用NAM 模块加强网络对特征的提取能力。NAM 使用批归一化的比例因子表示权重的重要性,不用额外加入SE 和CBAM 中的全连接层和卷积层,以极低的计算代价增强PP-LCNet 网络的特征提取能力。
2.2 微小目标检测层P2
YOLOv5 与YOLOv7 都采用特征金字塔网络(Feature Pyramid Network,FPN)结构,在Neck 网络尾部输出3 种不同下采样尺度的特征图,分别用于检测大型、中型以及小型目标。原始特征提取网络模型结构如图4 所示。

图4 原始特征提取网络模型结构Fig.4 Structure of original feature extraction network model
上述的分治方法在COCO、Pascal VOC 等常规数据集中非常有效,但是在无人机遥感图像中效果不佳。这是因为待检测目标大多为尺寸极小的远景目标,在原图中的尺寸可能小于8×8 像素,这种目标即使被分配在下采样倍数为8 的小目标检测层中,所占尺寸不超过1 像素,没有足够的特征信息用于分类以及定位。为解决上述问题,本文在Neck 网络中加入1 个下采样倍数为4 的特征层P2,专门用于检测极小的目标,增加极小尺寸后的特征提取网络模型结构如图5 所示。
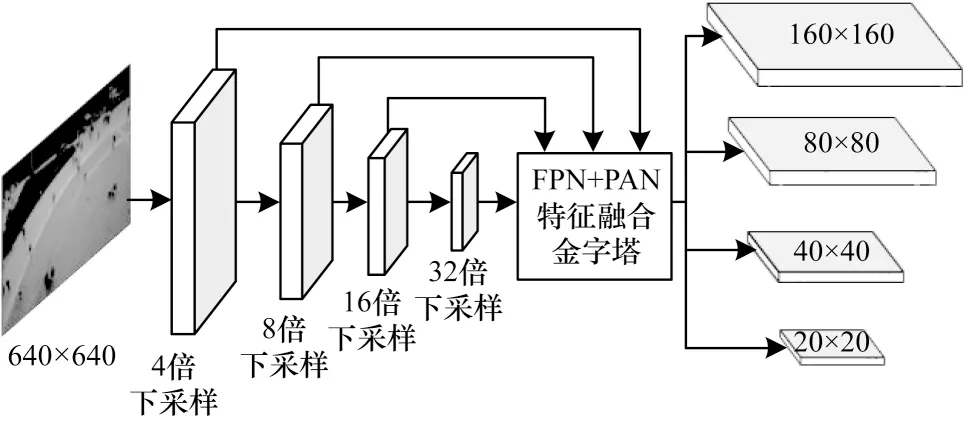
图5 增加极小尺寸后的特征提取网络模型结构Fig.5 Structure of feature extraction network model with minimal size addition
2.3 SUCA 模块
在P2、P3 特征图上进行检测时,由于其感受野较小,因此没有足够的语义信息用于分类任务,导致小目标的检测结果不佳。文献[21]提出FPN 在小目标检测任务中效果不好的另一个原因是低层特征图的检测任务会被高层影响,为了让低层特征图专注于小目标的检测,应该控制高层语义特征的影响权重。
在低层特征图中的语义信息可以从高层特征图自顶向下传播而来。在FPN 的自顶向下传播路径中,需要对低分辨率特征图进行上采样,绝大多数目标检测算法都采用双线性插值方法。但是该方法不可学习,并且会带来大量的人工噪音,损坏语义信息的传递。因此,受DUC 与fusion factor 的启发,本文提出适应融合的语义上采样模块SUCA,增强上采样过程中丢失的语义信息。
SUCA 模块将亚像素卷积迁移到目标检测任务中用于替代原有上采样方法。上采样倍数为2 的亚像素卷积过程如图6 所示。首先对输入的原始低分辨率特征图(H×W×1)进行3 层卷积操作,使其通道数变为4,再将特征图中每个像素的4 个通道映射到1 个通道上,使其重新排列为2×2 的区域,对应高分辨率图像中1 个2×2 大小的子块。重排后H×W×4 的特征图像就转换为2H×2W×1 的高分辨率图像。在图像从低分辨率到高分辨率的放大过程中,插值函数被隐含地包含在前面的卷积层中,可以随网络自动学习。亚像素卷积不仅解决了线性插值中不可学习的问题,并且没有带来会损坏检测精度的人工噪音。
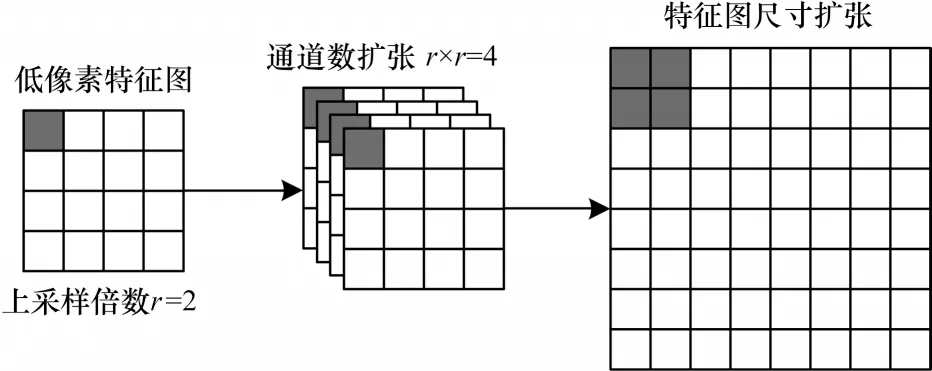
图6 亚像素卷积像素重排过程Fig.6 Rearrangement process of subpixel convolution pixel
SUCA 模块结构如图7 所示。为避免亚像素卷积中的通道扩张操作带来巨大的计算代价,从而影响算法的检测速度,SUCA 模块中的第1 个卷积操作并不会扩张通道数,而是仅对特征进行提取。经过亚像素重排、减少通道数、扩张尺寸后,再利用卷积操作恢复为输入的通道数,得到图7 中的B"。

图7 SUCA 模块结构Fig.7 Structure of SUCA module
在FPN 结构中,上采样所得到的特征图会与主干网络中提取的特征图进行拼接融合,为避免低层检测小目标的任务被高层所影响,本文在SUCA 模块中加入可学习的自适应融合因子α(α∊{0,1}),用于控制从高层上采样得到特征图的权重。在图7中,特征图B"逐点乘α,然后与低层的高分辨率特征图C"进行通道拼接融合,从而得到最后需要送入检测头的特征图D"。加入SUCA 模块后,SS-YOLO 算法的特征提取网络模型结构如图8 所示。
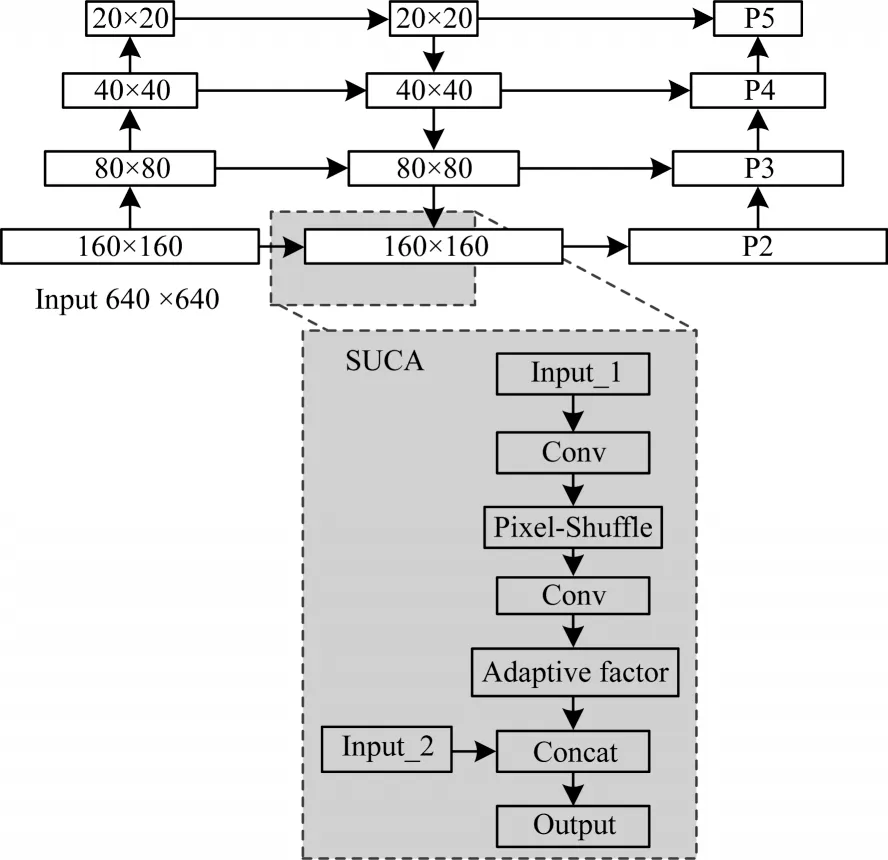
图8 加入SUCA 模块后特征提取网络模型结构Fig.8 Structure of feature extraction network model with SUCA module
2.4 LCNWD定位回归函数
IoU 是目标检测中最重要的指标之一,常用于评估真实框与网络预测框之间的位置关系,计算表达式如式(1)所示:
其中:B为网络给出的预测框的中心点;BGT为物体真实框中心点。如果预测框和真实框没有重叠,此时IoU 值将会退化为0,IoU 定位损失将无法计算。针对该问题,YOLOv5 和YOLOv7 采用改进后的IoU损失函数CIoU:在IoU 损失函数的基础上加入距离以及长宽比2 个惩罚项。CIoU 损失函数主要考虑以下3 个特点:1)重合区域面积;2)预测框与真实框之间中心点的距离;3)预测框与真实框之间的长宽比例。CIoU Loss 表达式如下:
其中:B、BGT分别表示预测框以及真实框的中心点;ρ为计算2 个中心点之间的欧氏距离;v用于计算2 个框宽高之间的相似性;ωGT与hGT为真实框的宽、高;w与h为预测框的宽、高;α为宽高相似度的权重因子。
CIoU 解决IoU 中没有重叠时梯度为0 的问题,并且考虑2 个框之间中心点的距离与宽高比例之间的相似性。但是IoU 度量方法对目标的尺寸极其敏感,如图9 所示。在相同的距离偏移下,小尺寸目标的IoU 下降速率远大于大尺寸目标。

图9 IoU 对目标尺寸的敏感性Fig.9 Sensitivity of IoU to object size
文献[22]提出一种对目标尺寸不敏感的度量方法NWD。图10 所示为目标尺寸分别为12、32、64 在不同偏移下的IoU 与NWD 对比。
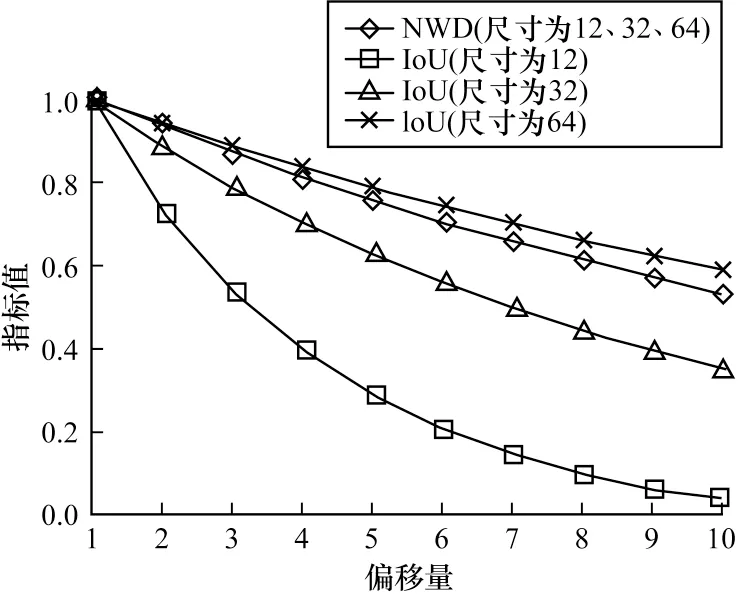
图10 尺寸为(12,32,64)的目标在相同偏移量下的IoU 与NWD 对 比Fig.10 IoU and NWD comparison of object with size(12,32,64)at the same offset
NWD 方法通过二维高斯分布表示边界框,并通过其对应的高斯分布计算预测框和真实框之间的相似度。对于任意2 个目标框,本文均可以通过其对应高斯分布的相似性来测量其关系。NWD 的计算式如式(5)和式(6)所示:
其中:W2(N,NGT)表示预测框与真实框的Wasserstein距离;N、NGT分别为预测框与真实框的二维高斯分布;C表示依据数据集中目标尺寸设置的常数。基于上述2 种方法,本文提出结合CIoU 与NWD 的针对小目标回归损失函数LCNWD,如式(7)所示:
LCNWD利用NWD 对目标尺寸不敏感的特性,加强网络对于小目标的关注程度,并且加入CIoU 的中心点距离惩罚项,使预测框更加贴近真实框,减小预测时产生的位置偏移。
3 实验
3.1 实验数据集
本文在VisDrone-2019 Det 和AI-TOD 数据集上进行实验,验证SS-YOLO 的鲁棒性以及有效性。VisDrone 数据集是由天津大学开源的1 个大型无人机遥感数据集。该数据集被分为3 部分:训练集(具有6 471 张图片)、验证集(具有548 张图片)、测试集(具有1 610 张图片)。VisDrone 数据集共有10 个不同类别,其目标分类难度较大,并且类别存在长尾效应。其中汽车类别目标最多,遮阳三轮车类别的目标最少。与COCO、Pascal VOC 等常规数据集相比,该数据集上的物体尺寸更小,目标的平均尺寸仅为35.8 像素,标注目标数量更多并且具有不同的拍摄角度。
AI-TOD 数据集包含8 036 张航拍图像,包含8 个类别,700 621 个对象实例。与通常目标检测数据集相比,AI-TOD 中目标的平均大小约为12.8 像素,远小于其他数据集。
3.2 评价标准
实验中采用平均精度(Average Precision,AP)、平均精度均值(mean Average Precision,mAP)作为模型检测精度的评价标准。AP 为单类别的检测精度,由P-R曲线与坐标轴构成的面积计算得到。mAP 为所有类别的AP 平均值。为评估模型大小,本文使用模型参数量以及推理时间作为评估标准。
3.3 结果分析
在本文实验中,所有算法均在对应数据集的训练集上训练80 轮次。网络输出的置信度阈值设置为0.25,以保证预测结果的分类精度。SS-YOLO 在VisDrone 测试集上检测的评价指标如表2 和图11 所示。SS-YOLO 的mAP 为28.9%,mAP50 为45.9%,推理时间仅为11.5 ms,FPS 最高可达71 帧/s,能够在满足无人机等边缘设备上实时检测要求的同时,取得较优的检测精度。

表2 SS-YOLO 在VisDrone 测试集上的评价指标Table 2 Evaluation indicators of SS-YOLO on the VisDrone test set %

图11 混淆矩阵Fig.11 Confusion matrix
3.3.1 横向对比实验
本文将YOLOv5s 以 及YOLOv7-tiny[24]作为实验对比基准,与近年来多种前沿方法进行横向对比,分别是Cascade R-CNN[25]、YOLOR[26]、YOLOx[27]、Center Net[28]和TPH-YOLO[12]。由于部 分方法对训练环境要求较高,因此仅引用论文中的实验结果。横向对比实验的结果如表3 所示。从表3 可以看出,SS-YOLO 相较于YOLOv5s 的模型参数量减少了37%,推理时间缩短了3.4 ms,mAP50 和mAP 提升2.1 和2.3 个百分点。与最新的YOLOv7-tiny 相比,尽管YOLOv7-tiny 采用repVGG 结构重参数化加速推理,但是比SS-YOLO 的推理时间缩短5.2 ms,在检测精度上mAP50 和mAP 分别提升6.7和7.5 个百分点。与目前VisDrone 数据集上最优秀的目标检测算法TPH-YOLOv5 相比,SS-YOLO 模型尽管mAP 下降了7.9 个百分点,但是参数量仅为其4%,推理速度仅为其4.1%,能够满足边缘设备的实时检测要求。

表3 不同目标检测算法在VisDrone测试集上的横向对比结果Table 3 Horizontal comparison results among different object detection algorithms on the VisDrone testset
为进一步验证模型的鲁棒性与有效性,本文在AI-TOD 数据集上与YOLOv5s、YOLOv7-tiny 进行额外的对比实验,输入图片大小为800×800 像素。实验结果如表4 所示。从表4 可以看出,在目标尺寸更小的AI-TOD 数据集上,SS-YOLO 能够有效提升检测精度。

表4 不同目标检测算法在AI-TOD 验证集上的横向对比结果Table 4 Horizontal comparison results among different object detection algorithms on the AI-TOD validation set
消融实验结果如表5 所示。从表5 可以看出,在Baseline 中加入SUCA 模块后,网络的推理时间与模型参数量均有所增加,但是检测精度mAP 与mAP50得到了提升,表明SUCA 模块可以提升网络对小目标的检测精度。在Baseline+SUCA 中加入LCNWD之后,网络的参数量没有发生变化,但是检测精度有进一步的提升,说明本文提出的LCNWD损失函数具有一定的有效性。

表5 消融实验结果Table 5 Results of ablation experiment
3.3.2 可视化实验
为更加直观地观察该方法在检测精度上的提升,本文使用多张无人机拍摄的图像测试算法YOLOv5s、YOLOv7-tiny 和SS-YOLO,检测结果 如图12 所示。
从图12 可以看出,SS-YOLO 的检测结果优于YOLOv5s 以及YOLOv7-tiny。以第1 张图为例,仅有SS-YOLO 算法检测到了右上角的2 辆汽车以及1 辆面包车。因此,本文提出的改进方法针对小目标能有效提升检测性能。
4 结束语
针对无人机遥感图像场景,本文提出一种基于YOLOv5 的轻量级小目标检测算法。为解决现有目标检测算法无法在无人机等边缘设备中进行实时检测的问题,本文提出轻量级的主干网络,简化主干网络结构,减少网络参数量,加快其推理速度。为解决小目标在高层特征图中特征信息不足的问题,利用分治方法,加入下采样倍数为4 的特征图P2,使其专注于检测微小目标。针对小目标所在的特征图P2、P3 缺乏的语义信息问题,提出结合自适应融合的语义上采样方法,在增强特征图语义信息的同时使其自主学习高层特征图对低层特征图的影响权重。针对IoU 度量方法对目标尺寸敏感问题,提出了目标尺寸不敏感的LCNWD损失函数。实验结果表明,该算法能有效提升了小目标检测性能,减少模型参数量、加快其检测速度。下一步将对标签分配算法与检测头中的特征不对齐问题进行研究,提升模型在无人机遥感场景中小目标的检测性能。
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
智族GQ(2022年12期)2022-12-20 07:01:18
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
China’s foreign Trade(2021年6期)2021-12-26 06:22:58
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
汽车与新动力(2017年3期)2017-06-29 12:00:21
CHIP新电脑(2016年3期)2016-03-10 14:22:03
