
基于全局节点和多片段的格栅命名实体识别
2023-12-16 10:29:22郭江涛彭甫镕
计算机工程 2023年12期
郭江涛,彭甫镕
(山西大学 大数据科学与产业研究院,太原 030006)
0 概述
命名实体识别(Named Entity Recognition,NER)的目标是标记非结构化文本中的实体词,并分为对应的类别,是自然语言处理(Natural Language Processing,NLP)领域的一项重要研究内容。由于语言的特殊性,中文命名实体识别相比英文更加复杂,在命名实体识别研究工作中备受关注。
命名实体识别任务的发展初期主要关注人名(PER)、地名(LOC)、机构名(ORG)等3 种专有名词的识别,随着任务的不断完善,专有名词的范围被进一步扩大,逐步发展至对特定领域的特定类别实体进行识别。在生物医学领域,命名实体识别任务更关注领域专有名词的识别,如蛋白质、DNA 等,这也就意味着每个特定领域都需要标注新的数据集,但数据标注的代价是相当大的。研究[1]表明:对无标签数据进行准确的标注需要该领域中大量的专家参与,并且标注数据花费的时间是无标签数据的10 倍以上。
近年来,深度学习在命名实体识别中取得了相当不错的成绩,在标注丰富领域(如新闻)的数据集上表现较好,例 如FLAT[2]和SoftLexicon[3]模型在MSRA 和PeopleDaily 上的F1 值已经超过0.95。然而现有深度模型相对复杂,需要大量标记数据对模型参数进行迭代训练。在这种情况下,设计一套面向标注稀缺领域的命名实体识别模型具有重要的现实意义和应用价值。
主动学习模仿了生物学习行为的内部过程,将过去学习到的经验推广到新的数据机制。通过对样本进行不确定性排序,可以让专家(人工)集中精力标注模型最不确定的样本。这有助于模型更快地学习,使专家无需标注对模型帮助较小的数据,从而极大地减少所需标注的数据量。
现有基于主动学习的命名实体识别大多基于统计机器学习,并侧重于设计不同的主动学习策略,例如:HUANG 等[4]基于条件随机场(CRF)[5]模型设计一种融合K 均值聚类和信息熵的主动学习策略。基于主动学习的命名实体识别在深度学习方面的研究相对较少,如何将深度学习技术与已有主动学习策略相结合仍是一个挑战。
理论而言,当数据量很小时,深度学习算法会表现不佳,但随着大规模预训练模型的发展,该问题会得到很大改善。SHEN 等[6]将深度学习技术用于基于主动学习的命名实体识别过程,设计一种CNNCNN-LSTM 模型,采用CNN 作为字编码器和词编码器,使用LSTM 作为解码器,但CNN 词编码器需要提前将文本分词,使用自动分词工具容易引入分词错误,而人工分词标注成本更高。Lattice LSTM[7]提出一种格栅思想,将字符所有可能的词都输入模型,由模型判断最佳序列。FLAT[2]模型设计了Flat-Lattice 结构,使得模型可并行计算,有效提高了模型训练速度。
本文提出一种基于全局节点和多片段的格栅命名实体识别模型。将FLAT 模型中基于全连接注意力机制的Transformer[8]改为融合全局节点和片段节点的注意力机制,减少结构复杂度,从而降低对标注数据的需求量。基于全局节点的结构有助于获取全局语义信息,确定词汇边界,片段节点用于捕获局部的语义。同时,对Flat-Lattice 结构进行改进,可以较好地添加词汇信息而不需要分词。
1 相关工作
1.1 嵌入表示
在自然语言处理中,通过嵌入层将文本处理为可由计算机计算的数值数据。早期的嵌入层使用独热码[9](One-hot)把语料转化为向量表示,但这种方式得到的特征是高维离散稀疏的向量。之后,出现了Word2Vec[10]、GloVe[11]等静态词向量,静态词向量能够考虑单词的上下文相关词,形成词向量的固定表征,可以更好地解决词性孤立且不连贯的问题,但存在一词多义现象[12]。随着预训练模型的发展,Elmo[13]、GPT[14]、BERT[15]等动态词向量技术相继出现,动态词向量技术能够考虑词之间的相关性,还能解决词的多义性问题,从而有效提升最终效果。
1.2 命名实体识别
目前,命名实体识别主要分为基于统计机器学习和基于深度学习。基于统计机器学习的模型依赖于领域专家知识量和人工总结特征,但泛化能力高,可解释性强。基于深度学习的模型使用深度学习自动发现隐藏特征,常结合统计机器学习模型以提升可解释性。近年来,基于深度学习的NER 模型成为主流,并取得了较好的结果。
Bi-LSTM[16]是基于 深度学习的NER 模型中 比较经典的模型,但Bi-LSTM 在处理中文NER 时面临分词问题,基于词编码器的模型[17]容易引入分词错误,基于字编码器的模型[18-19]无需分词,但在处理词汇边界问题时精度不高。
Lattice LSTM[7]对一系列输入字符以及与词典匹配的所有潜在词进行编码,显式地利用了单词和单词序列信息,不存在切分错误,因此本文借鉴这种保留所有潜在词的Lattice 结构。
SoftLexicon[3]把字典信息编码到向量表示中来规避复杂的模型结构,提升运算速度,但仍基于LSTM 串行结构。TENER[20]通过带位置感知的注意力机制来改进Transformer Encoder 结构,同时捕捉单词的位置和方向信息,建模词级别和字符级别的上下文信息。FLAT 将Lattice 结构转换为由跨度组成的平面结构,凭借Transformer 和融入词汇信息的位置编码,克服了LSTM 串行结构的缺点,具有出色的并行化能力,但FLAT 基于全连接的Transformer,每个跨度之间都要进行注意力计算,这使得有较多的训练参数,导致需要更多的标注数据来训练这些参数。
LGN[21]设计一种具有全局语义的基于词典的图神经网络,其中词典知识用于连接字符以捕获局部组成,而全局中继节点可以捕获全局语义和长距离依赖。Star Transformer[22]是一种Transformer 的轻量级替代方案,将全连接结构替换为星形拓扑,其中每两个非相邻节点通过共享中继节点连接。因此,复杂性从二次型降低到线性型,同时保留捕获局部组成和长期依赖的能力。本文借鉴该思路,对FLAT 模型进行改进,减少不必要的注意力连接和参数训练,从而降低所需标注数据量。
1.3 命名实体识别中的主动学习策略
大规模获取命名实体识别标注数据的成本很高,主动学习可通过特定策略选择要注释的示例来改善这一问题,以更少的注释获得更高的性能。目前,有关命名实体识别中主动学习研究较少,基于主动学习的CNN-CNN-LSTM[6]模型使用CNN 作为字和词编码器,LSTM 作为解码器,但CNN 词编码器需要提前将文本分词,使用自动分词工具容易引入分词错误,人工分词标注成本更高,并且长距离依赖对于文本处理具有重要意义,而CNN 在获取长距离依赖方面相对欠缺。
综上,当前命名实体识别模型对标注数据的要求较高,基于主动学习的命名实体识别模型还需分词,相对落后。因此,本文综合考虑已有命名实体识别模型和主动学习策略之间的互补性,提出一种基于全局节点和多片段的格栅命名实体识别模型,通过全局节点和多片段结构减少模型对标注数据的需求,利用Flat-Lattice 结构解决现有主动学习策略需要分词的问题,从而在保证模型性能的前提下降低数据标注代价。
2 基于全局节点和多片段的格栅命名实体识别模型
为了降低标注成本,建立一种基于全局节点和多片段的格栅命名实体识别模型,模型结构如图1所示(彩色效果见《计算机工程》官网HTML 版)。该模型主要包括嵌入层、全局节点和多片段模块、改进的平面格栅模块、多头注意力层和残差网络模块、CRF 输出层等5 个部分。

图1 基于全局节点和多片段的格栅命名实体识别模型结构Fig.1 Structure of lattice named entity recognition model based on global nodes and multi-fragments
2.1 嵌入层
由预处理得到整个句子的字和词后,生成一个跨度序列,一个跨度包括一个标记、一个头部和一个尾部。跨度是一个字或一个词。头和尾表示原始序列中标记的第一个和最后一个字的位置索引,表示标记在格中的位置。对于字而言,头部和尾部是相同的。所有字按照原本的句子顺序位于整个序列前,词按照头部的顺序排在字序列后。将整个序列输入由预训练语言模型BERT 组成的嵌入层得到部分跨度的向量表示。
2.2 全局节点和多片段模块
在FLAT 模型中,每个字都与整个句子直接进行注意力计算,这使得注意力连接的复杂度为O(n2),其中n为单个句子长度,需要训练的参数越多,需要标注的数据也越多。为了降低注意力连接的复杂度,借鉴Star-Transformer 中的连接方式,但删除了其中用于多层叠加的ei节点,其中i代表编码器的层数,因为在命名实体识别任务中仅需一层Transformer 编码器。考虑仅靠一个全局节点可能不能捕获所有非邻居节点间的依赖,设计一种融合全局和局部节点的方案,为每个跨度向量hx构造上下文矩阵Cx,上下文矩阵Cx的计算方法如式(1)所示:
其中:x表示跨度在整个序列中的位置,将整个序列视为循环序列,当x=0 时x-1 代表跨度序列的最后一个跨度;每个句子平均分为A个片段,每个片段拥有一个片段节点Fa,Fa的初始值为片段内节点的均值;在全局节点G的作用下,每两个不相邻的节点都是两跳邻居,并通过与全局节点G的注意力计算获取长距离依赖。在这种结构下,每个字仅与对应上下文矩阵Cx进行注意力计算,复杂度降为O(n)。
2.3 改进的平面格栅模块
在中文命名实体识别中,词汇信息能够帮助确定实体边界,平面格栅结构可以很好地支持并行计算并添加词汇信息,根据当前模型结构对其进行改进。
相对距离计算方式如式(2)~式(5)所示:
相对距离编码计算方式与Transformer 相同,具体如下:
其 中:d为表示位 置编码 的维度索引。
跨度的最终相对距离编码是4 个距离的简单非线性变换,具体如下:
2.4 多头注意力层和残差网络模块
通过多头注意力层和残差网络将相对距离编码和跨度特征嵌入进行融合计算。Transformer 通过M个注意力头分别对序列进行自注意力计算,然后将M注意力头的结果拼接起来。
将自注意力计算改为将序列中每个跨度向量hx与对应上下文矩阵Cx进行注意力计算。为了简单起见,忽略多头注意力层的头部索引,每个头的计算公式如下:
多头注意力层输出作为残差网络的输入,残差网络与Transformer 编码器相同,残差网络输出后舍去词的嵌入表示,仅将字符表示嵌入CRF[5]输出层。
2.5 CRF 输出层
注意力机制能够对特征进行融合,得到每个跨度的最大概率分布和标签,但标签之间相互独立,无法解决相邻标签之间的合理性问题。CRF 层通过在标签之间添加转移矩阵分数排除部分不合理标签序列,从而更容易获得最佳预测序列。
3 实验与结果分析
3.1 数据集
在MSRA[23]、OntoNotes 5.0[24]、PeopleDaily、Weibo[25]等4 个中文NER 数据集上评估所提模型:
1)MSRA 数据集是由微软亚洲研究院发布的一个新闻领域NER 数据集,实体类型主要包括LOC、ORG、PER。中文分词在训练集中可用,但在测试集中不可用。
2)OntoNotes 5.0 是OntoNotes 数据集 的最后 一个版本,由BBN 科技公司、科罗拉多大学、宾夕法尼亚大学和南加州大学信息科学研究所合作构建。该语料库由英语、汉语和阿拉伯语3 种语言的文本组成,本文仅使用其中的中文数据集。通过脚本将其处理为命名实体识别专用的BMES 格式后,包括数量、日期、事件、语言、法律、位置、金钱、组织、百分比、人名、产品、时间、艺术品等18 种粗粒度的实体类型。
3)PeopleDaily:由《人民日报》语料标注而成,并标注了LOC、ORG、PER 3 种命名实体,不包含人工标注分词。
4)Weibo 数据集:由来自新浪微博的注释NER信息组成。数据集包含PER、LOC、ORG、行政区名(GPE)等粗粒度实体类型,且每种实体都包括特指和泛指两种细粒度实体类型。
采用BMES 标记格式,B 代表实体的首部,M 代表实体中部,E 代表实体尾部,O 代表非实体。由于BERT 输入的最大长度限制为512,为了充分利用标注数据,对数据集进行分段处理,当句子长度大于200 时将句子以标点符号为分隔符将句子分为多个片段,标点划分到之后片段的句首。根据数据集规模,按照不同比例划分为训练集、验证集和测试集。处理后的数据集规模信息如表1 所示。

表1 数据集规模信息Table 1 Dataset scale information
3.2 评价指标
采用F1 值作为模型精度评价指标,F1 值的计算方法如式(12)~式(14)所示:
其中:P代表精确率,即预测正确的实体数占所有预测为实体的数量的比例;R代表召回率,即预测正确的实体数占所有实际为实体的数量的比例;TP、FP、FN分别代表预测正确的实体数、预测为实体但实际不为实体的实体数、实际为实体但预测错误的实体数。
本文的目标是在保持精度的情况下降低数据标注代价,因此还需定义一种标注代价方面的评价指标。在命名实体识别中,数据标注代价与标注字数被认为正相关,且在主动学习过程中存在波动,因此设定在主动学习的多轮循环中添加标注数据,当3 轮训练结果达到设定对应F1 阈值时,标注数据集的总字数更少则表现更好。
3.3 对比实验
3.3.1 实验设置
所有实验都在主动学习框架下完成。将已有训练集的2%初始化为标注数据集,其他放入待标注数据集(即不使用标注,仅使用文本评估可信度),实验中的主动学习策略统一设定为最低可信度策略。每个主动学习循环添加2%训练集的标注数据,每个主动学习循环通过主动学习策略从无标注数据集中选择训练集句子总数2%的句子转到标注数据集(模拟现实中的人工标注)。模型仅使用标注数据集进行训练,默认训练100 个迭代(epoch),且25 次迭代没有提升精度就结束训练。主动学习算法的伪代码如下:
3.3.2 对比模型
对比模型具体如下:
1)基于主动学习的CNN-CNN-LSTM[6]模型。
2)在主动学习框架中复现的FLAT[2]模型。
3)Star_Trans 模型:由Star Transformer[22]和平面格栅结构组合而来,在上下文向量Cx=cat(hx-1,hx,hx+1,ei,G)中保留Star Transformer 中用于多层叠加的ei节点。
3.3.3 对比实验结果分析
按照实验设置分别对4 个中文NER 数据集进行实验,各数据集的实验结果如图2 所示。由图2 可以看出,所提模型(简称为Star_Frag)在MSRA 数据集上明显优于其他模型,且两种基于全局节点的模型也都优于FLAT 模型;在OntoNotes 5.0 数据集上,两种基于全局节点的模型相差不多,略优于FLAT 模型,明显优于CNN-CNN-LSTM 模型;在Weibo 数据集上,Star_Frag 明显优于其他模型,且两种基于全局节点的模型也都优于FLAT 模型;在PeopleDaily 数据集上,3 种模型相差不多,在标注字数小于200 000时,FLAT 模型相对较差。
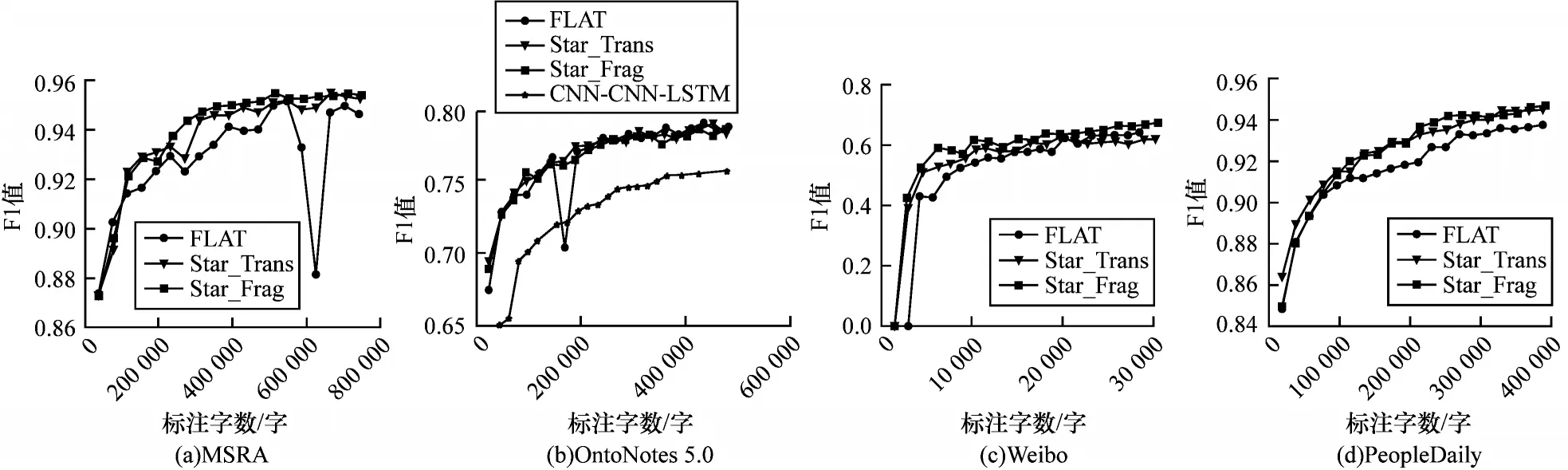
图2 对比实验结果Fig.2 Comparative experimental results
通过图2 分析比较直观,但不够精确。由于数据标注代价与标注字数正相关,并且不同数据集在主动学习过程中存在波动,取模型3 次达到F1 阈值所需的标注字数为评价指标。F1 阈值的取值以使用20%标注数据时模型的平均结果为基准,结果如表2所示。根据表2 中的实验结果可得,Star_Frag 模型在4 个数据集上所需标注代价更低,相较于FLAT 模型,达到对应F1 阈值所需的标注数据量分别降低了39.90%、2.17%、34.60% 和35.67%,取得了 最好的结果。

表2 3 次达到F1 阈值所需的标注字数Table 2 Required number of annotated words to reach F1 threshold three times 单位:字
3.4 消融实验
消融实验的实验设置与对比实验相同。
1)删除片段节点(Star_withoutFa)。删除片段节点Fa后的上下文矩阵Cx计算公式如下:
在相对距离编码计算时,设定当P代表G时,都设定为1,表示所有跨度到全局节点的距离为1。
2)删除全局节点(Star_withoutG)。删除全局节点G后的上下文矩阵Cx计算公式如下:
在相对距离编码计算时,设定当P代表Fa时,都设定为1,表示所有跨度到片段节点的距离为1。
消融实验结果如图3 所示,由图3 可以看出:在MSRA 数据集上,删除全局节点的模型表现最差,其次是删除片段节点的模型,Star_Frag 模型表现最好;在OntoNotes 5.0 数据集上,3 种模型相差不大,无法明显区分;在Weibo 数据集上,删除片段节点的模型表现最差,其次是删除全局节点的模型,Star_Frag 模型表现最好;在PeopleDaily 数据集上,3 种模型在200 000 字之前相差不大,在200 000 字之后Star_Frag 模型相对更好。

图3 消融实验结果Fig.3 Ablation experimental results
3.5 参数分析实验
Transformer 和Star-Transformer 的编码 器都设置了多层叠加结构,但在FLAT 模型中仅使用1 层。对此进行参数分析实验,为了节约训练时间,参数分析实验仅进行10 个主动学习循环,每次添加100 句句子。实验结果如图4 所示,由图4 可以看出,实验结果没有随着编码器叠加层数的增加而变好,在叠加3 层时F1 值甚至会出现明显的下降趋势,因此多层叠加编码器在当前结构中不会带来性能提升。

图4 参数分析实验结果Fig.4 Parameter analysis experimental results
4 结束语
本文提出一种融合全局节点和片段节点的格栅命名实体识别模型,通过全局节点和片段节点的结构有效减少了标注数据的需求量,对Flat-Lattice 结构的改进可有效添加词汇信息,避免了人工分词。对比实验结果表明,所提模型达到对应F1 阈值所需的标注数据量相比于已有命名实体识别模型更少,有效降低了标注代价。后续将对主动学习策略进行改进,利用CRF 层的转移矩阵和输出分数评价样本质量,进一步降低标注代价。
猜你喜欢
建材发展导向(2022年14期)2022-08-19 02:10:52
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
西部交通科技(2021年9期)2021-01-11 18:28:15
智富时代(2019年6期)2019-07-24 10:33:16
上海建材(2018年4期)2018-11-13 01:08:54
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
高中生·天天向上(2016年9期)2016-11-22 09:10:34
河南科技(2014年24期)2014-02-27 14:19:37
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
