
基于GPU 实时仿真小脑模型神经网络优化的研究
2023-12-14 06:07陈嘉卿黄嘉嘉许弢
五邑大学学报(自然科学版) 2023年4期
陈嘉卿,黄嘉嘉,许弢
(五邑大学 智能制造学部,广东 江门 529020)
小脑模型是由Albus[1]于1975 年仿照小脑皮层结构重建的关联控制器经多年发展形成的神经网络模型,该模型能对生物小脑学习行为进行仿真,但其仿真结果与实际细胞电位变化还存在差异,其预测功能和记忆形成的机制尚未明确.大规模细胞的电生理测量难度非常大,生物实验需要花费的时间和材料成本非常高,构建大规模的仿生小脑模型可以解决这些难题.目前比较流行的小脑模型基础架构有Marr-Albus-Ito[1]的小脑模型、Hodgkin-Huxley-model 模型[2]等.基于这些基础模型,科学家能很好地结合模型的特点去解决工程上的一些难题,比如对机器人控制的改进[3-4]和利用小脑模型的生物行为特性进行控制器开发[5-7]等,可见模型在工程上有很大的应用价值.同时,科学家通过实时仿生小脑模型可以进一步探讨学习记忆在小脑中的形成与保存,对研究小脑的学习机制[8]有很大帮助.实时的模型一般以现场可编程门阵列(Field Programmable Gate Array,FPGA)[9]和图形处理器(Graphics Processing Unit,GPU)[10]为基础,值得注意的是随着统一计算设备架构(Compute Unified Device Architecture,CUDA)[11]技术的进一步优化,并行加速开始进入了研究人员的视野,比如针对神经网络的并行计算改进[12-13],但GPU 的实时模型还有优化的空间,在资源利用和时序上还能进一步优化.因此本文在Yamazaki 模型[14]的基础上通过引入流的概念[15]优化GPU 并行线程,为不同计算模块和不同细胞分配相应的线程并使用新的CUDA 特性(如区块均衡和驱动内存对齐等技术)加速网络的计算,最后在不同细胞数量规模下观察小脑模型的实时运行规模和速度.
1 材料与方法
1.1 模型结构
小脑皮层接受到刺激,进行信息处理的信息流如图1 的网络结构所示.以约10 万个细胞规模的模型作为例子,模型由6 种细胞组成,分别为颗粒细胞(granule cells,GCs)、高尔基细胞(golgi cells,GOs)、蓝状细胞(basket cell,BS)、浦肯野细胞(purkinje cells,PC)、下橄榄核(inferior olive,IO)和小脑深部核团(deep cerebellar nuclei,DCN).还有3 种突触纤维,分别为苔藓纤维(mossy fibers,MF)、平行纤维(parallel fibers,PF)和攀延纤维(climbing fiber,CF).整体信息流从MF流入颗粒细胞层和小脑核,信息通过颗粒层分别传输到中间层和浦肯野细胞,最后浦肯野细胞抑制DCN,DCN 作为最后的输出.指导信号由IO 发出,通过CF 传递给PC.

图1 小脑模型网络架构图
模型的规模包括102 400 个颗粒细胞,1 024 个高尔基细胞,16 个浦肯野细胞,16 个中间层细胞和1 个小脑核细胞.程序每次试验的仿真时长为1 666 ms,其他细节参考试验方案章节.苔藓纤维的突触数目为100 条,平行纤维的突触数目由颗粒细胞簇决定.
信号经过颗粒层后由PF 输入到PC 中,另外一路信号通过中间层的星状细胞和BS 处理后发出抑制信号给PC.PC 同时受到了颗粒层的刺激和中间层的抑制.CF 的信号只作为突触权重调节的诱导,诱导LTP(long-term potentiation)和LTD(long-term depression)[17]的产生.
模型的输出是DCN,它同时受到浦肯野细胞抑制输入和苔藓纤维的刺激输入.类似于输出的时候加入一个正则项,最后通过调节平行纤维的权重达到学习的效果.
图1 中箭头表示刺激信号传递方向,圆头表示抑制信号的传递方向.颗粒层中的圆圈表示颗粒细胞,方框为高尔基细胞.纤维上的数字代表其规模.
1.2 计算机制
每个细胞,通过建立积分电导模型[18]式(1)以及概率电导模型式(2)来计算模型中的单个神经元以及一簇神经元随时间变化的活性.最后神经元的膜电位变化按式(3)计算.
其中,g是电导,是最大电导,用下标c表示不同离子通道;wj是突触权重;α(t-s)是电势衰减函数;δj(s)是脉冲发射情况,用1 和0 分别代表有或没有触发动作电位.
其中,gc代表相关离子通道的导通概率,m是化学能推动离子通道打开的概率,n次方代表有多少个这样的离子通道.
其中,V(t) 是t时刻的神经元膜电位;Ec是触发电势;C是膜电容.该公式是每个细胞总电势的积分公式.这里以浦肯野细胞作为例子,刺激信号的正向模型中预测计算为:
其中,PC(t)是t时刻MF 输入经过PF 后的结果,为第i个苔藓纤维链接的突触权重,MFi(t)在t时刻的时候刺激信号.
按照主题内容,可将本次统计的189篇论文划分为9个类别(详见表1)。其中,研究范畴主要围绕MOOC环境下图书馆及馆员的角色定位、MOOC环境下图书馆服务创新展开,研究切入点主要包括信息素养教育、版权服务、MOOC平台技术支持与优化,研究基础侧重于对国外图书馆MOOC实践经验的借鉴。
当IO 被激发的时候PC 也同时被激发,计算在固定窗口下GR 的触发数量作为减少权重的指数,公式如下:
最终结果是由苔藓纤维传输的刺激信号和浦肯野细胞的抑制共同作用输出的:
其中,第二项主要为负数,对CN 起抑制作用.
最后根据CN 是否激活来判断输出:
其中,OUT 作为最终输出,可以根据不同任务改变输出的形式,比如本文采用激活率作为标准,在一段时间内激活率达到一定程度作为模型触发的输出标准.
1.3 硬件实现
本文代码使用C++语言,并使用CUDA 框架提供的API 在内存和显存之间传输数据.先构建数据结构,每个种类的细胞包含细胞数目、电导和触发电势等各项参数.自动平衡CUDA 分配的区块和块内线程数,尽可能利用显卡的所有资源,比传统的固定区块数计算要更加有效.其次,在多流处理上采用原子操作(类似数据的加锁和解锁),防止在异步操作时候取旧数据或者覆盖了不应该覆盖的数据.同时,优化对比数据大小的机制,采用类似减法器的对比方案.
如图2 所示,不同的工作流处理指定的运算,因为输入信号是概率模型,所以由梅森旋转法[19]在显存中生成随机数并作为刺激信号的发生器.Aph 是每个细胞超极化后电位恢复的处理过程,超极化指前一个时刻被激活后,则当前时刻膜电位就变成衰减的膜电位.英文缩写(如GR)表示该细胞(颗粒细胞)的内部膜电位变化处理,一般是针对刺激信号进行膜电位积分.而带箭头的英文缩写(如MF→GR)表示信号从输出纤维(苔藓纤维)到目标细胞(颗粒细胞)的过程.图中每个块的高度代表运算规模,最长的运算模块统一为颗粒细胞数目与2 的次方对齐,在10 万规模细胞下,单个方框的规模是102 400.一共分为100 块,每个块内有1 024 个线程数.每次任务的块大小相同能增加运算效率.
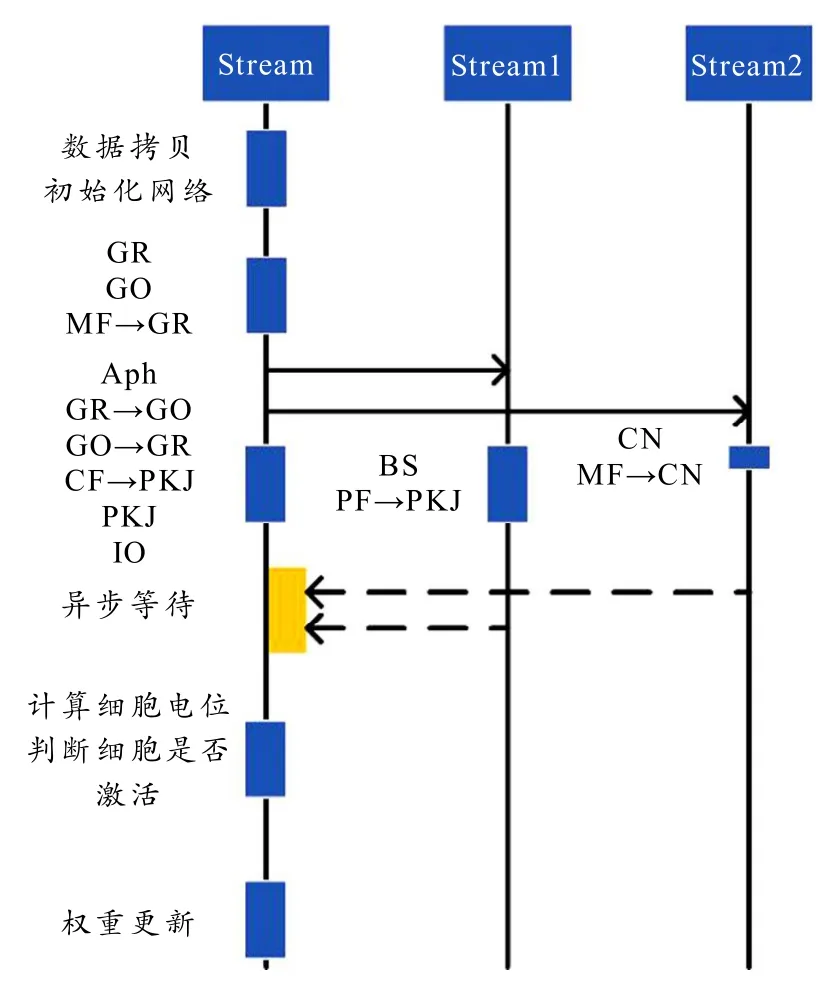
图2 GPU 计算流架构图
2 实验结果与分析
为了测试模型的性能,本文使用8 Gb 显存的NVIDIA 显卡,单精度浮点性能不低于8.1 TFlops.通过梅森旋转算法生成伪随机序列模拟细胞在小脑中的电生理活动.最后通过运行不同规模的小脑网络对比不同方案下的耗时.
2.1 实验方案
本文进行了小鼠的延迟眨眼条件反射dEBC(delay eyeblink conditioning)[20]仿真试验,观察小脑对于延迟眨眼条件反射记忆的形成.刺激信号如图3 所示,总仿真时长1 666 ms.200 ms 之前作为稳定时间,从205 ms 开始发送有条件刺激,在450 ms 的时候发送无条件刺激并持续30 ms,最后有条件刺激信号在1 200 ms 时结束.这样一个流程作为一次试验,重复100 次以达到现实小鼠学习到眨眼条件反射的最低次数,观察过程中各个细胞的电生理变化.

图3 延迟眨眼刺激信号
图3 中蓝色部分为条件刺激信号,以均匀分布的概率形式刺激颗粒细胞神经元的触发,黄色条状作为无条件刺激信号输入到下橄榄体(IO).而图中上部作为普通训练时候的刺激信号,下部作为测试时候的刺激信号.因为学会延迟眨眼后小鼠会在有条件刺激下产生无条件刺激的反应.
2.2 实验分析
模型仿真延迟眨眼条件反射试验结果如下:
如图4 所示,上部分为不同训练次数下各个细胞的神经元尖峰放电情况,下部分为学习过程中各个细胞在各个阶段的电生理仿真图像.观察到PC 和CN 随着训练次数变化明显,CN 在IO 激活位置的激活率逐渐增加.其中trial 1 是网络刚刚开始学习的时候,明显发现这个时候的PC 的激活率很高,但随着学习的进行,激活率慢慢下降,到了trial 30 已经有明显的学习迹象.最后在trial 50的时候习得了延迟眨眼,判断标准是CN 的激活率在IO 给出信号的位置激活率显著上升,表明CN在这个时候的输出.再随着学习的进行,在trial 100 的时候已经会提前预判眨眼的动作,观察CN最开始的激活位置比IO 的指导信号还提前了,到此该模型已经学会了延迟眨眼条件反射试验.

图4 电生理仿真图
观察发现GR 和GO 在学习的过程中激活情况变化不大,而PC 的变化很大,可以看出学习的位点并不在前面信号预处理的细胞上而是在浦肯野细胞上.而浦肯野细胞在IO 的指导信号下,受到LTP 和LTD 的机制影响调节平行纤维(PF)的权重.
图5 是颗粒细胞(GR)和高尔基细胞(GO)在一次仿真过程中的神经元激活情况,图中每个黑点代表该序列的神经元细胞在该时间点激活,纵轴是每个不同的细胞,并按一定顺序排序.可以看出不同簇的细胞对刺激信号产生不同的反应,在收到刺激信号的时候高尔基细胞的平均激活率显著提高,颗粒细胞则是表现出对刺激信号的不同特性,有的反而激活率下降.这样有利于信号的模糊化和预处理特性,使信号的隐藏特征通过网络的随机连接关系展现出来.
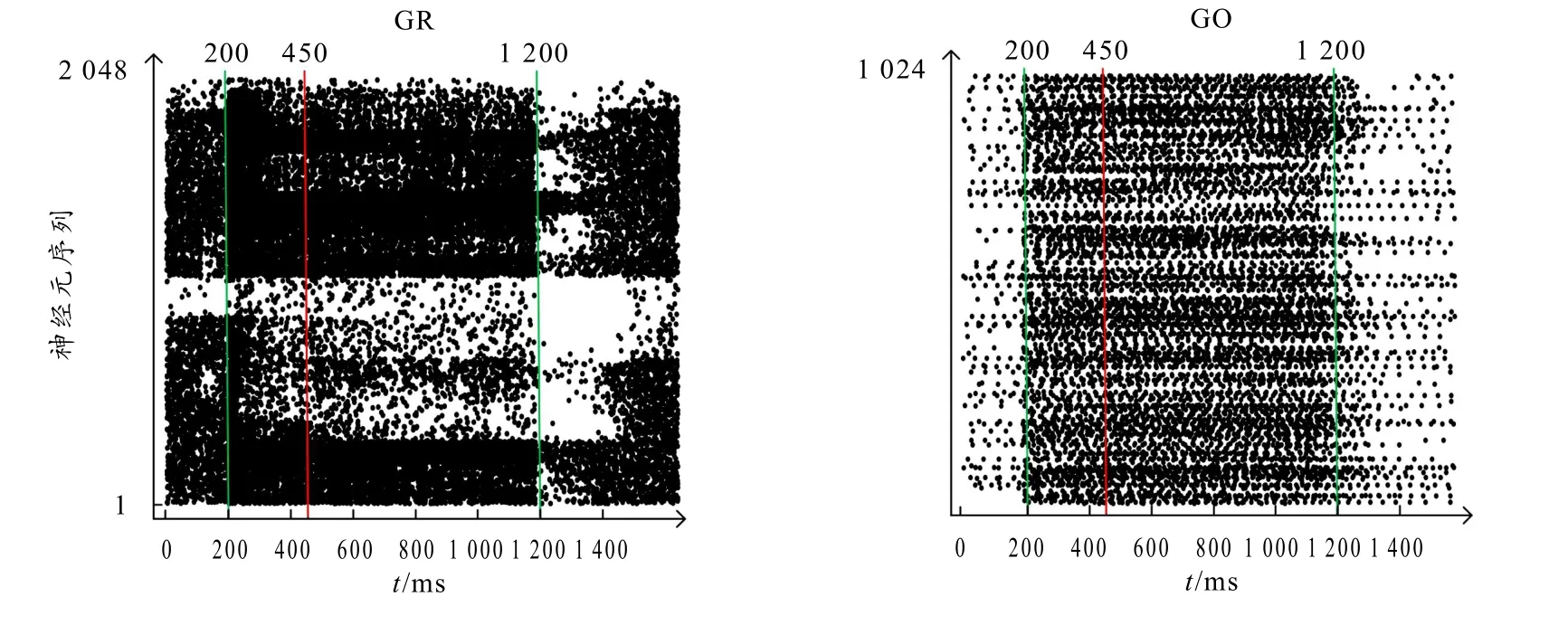
图5 细胞激活散点图
3 讨论
针对实时仿生小脑模型的加速和扩大运算规模的问题,本文提出了一种基于GPU 的流式处理优化方法.通过试验,仿真小脑模型能学习延迟眨眼条件反射,并仿真其学习过程中神经元的激活状态变化,而学习记忆离不开突触可塑性的形成,平行纤维是学习延迟眨眼条件反射的关键位点.GR和GO 细胞则对数据起着清洗作用,挖掘输入信号的潜在特征同时也给神经网络提供了更多的输入模板.在不同细胞规模下的模型对比仿真表明,使用流方案的模型运行速度更快,这个加速效果除了是流技术带来的高效并行化[12],还离不开优化运算单元分配[13].保证每次进入显卡的任务序列的运算单元数目尽可能相同.
本模型相比于Yamazaki[15]的模型,使用流方案并行多模块运行,同时将所有数据都存放在显存当中,减少数据拷贝时间,加快了模型运行速度.而在硬件方面对比FPGA 有着更大规模的神经元,不受限于硬件上资源的紧缺.本文的关键点在于将不同运算量的细胞分配到不同的流中,使并行程序中的有效并行数目得到充分的发挥.同时使用显存存储数据,减少了数据转移带来的性能损失,并且利用CUDA 的新特性加速计算单元.
图6 是原方案和使用流方案的模型在不同规模神经元下的仿真耗时对比,最大取40 万规模进行比较是因为本模型实时模拟1 666 ms 在40 万规模左右接近极限.从图中可以看出使用流方案的模型耗时更少.在小规模下两者差距不明显,但在大规模下两者差距逐渐拉开,而且流方案下耗时方差更小更加稳定,但随着规模变大方差也逐渐变大.在40 万规模下,原方案运行时间已超过仿真总时长,不能满足实时要求.

图6 仿真耗时图
4 结语
本论文主要利用 CUDA 新特性以及均衡各个线程的计算量来优化模型,提高了模型的运行速度,并且在相同规模下模型耗时更短.通过延迟眨眼条件反射实验的仿真,验证了模型的基本学习功能.本模型使用C++语言直接编写CUDA 脚本.目前模型中的数值运算采用矩阵运算,但是有很多细胞不参与某些时刻的运算,是否可以采用稀疏矩阵[21]或者优化算法本身加速运算是未来要研究的方向.
猜你喜欢
自然杂志(2021年6期)2021-12-23
中国临床解剖学杂志(2021年2期)2021-04-19
中国计划生育和妇产科(2021年9期)2021-04-18
中国临床医学影像杂志(2019年6期)2019-08-27
创新作文(小学版)(2019年4期)2019-07-24
现代装饰(2018年5期)2018-05-26
中成药(2017年9期)2017-12-19
哲思2.0(2017年12期)2017-03-13
西南军医(2016年2期)2016-01-23
电源技术(2015年5期)2015-08-22
