
五种机器学习模型预测颈动脉粥样硬化患者发生缺血性脑卒中的效能比较
2023-12-14 04:50张红珍杨少玲赫兰林文华顾家红赵坤胡静彭媛媛
右江医学 2023年11期
张红珍,杨少玲,赫兰,林文华,顾家红,赵坤,胡静,彭媛媛
(1.安徽理工大学附属奉贤医院超声科,上海 201499;2.上海市第八人民医院超声科,上海 200235)
缺血性脑卒中是脑卒中高危人群致残与致死的主要原因,其发病率逐年升高[1]。约30%的缺血性脑卒中是由颈动脉粥样硬化易损斑块破裂,微小栓子引起颅内动脉栓塞所致[2]。颈动脉超声检查是早期筛查易损斑块的首选方法[3-4]。然而目前我国超声医师紧缺、易损斑块识别技术水平要求较高[5],阻碍了颈动脉超声检查在脑卒中高危人群筛查中的广泛应用。
随着人工智能技术逐步应用于医学领域,机器学习模型大大提高了解决部分医疗问题的效率[6-7]。利用机器学习模型有望预测颈动脉粥样硬化斑块(carotid atherosclerosis,CAS)患者发生缺血性脑卒中的风险。logistics分类(LR)、高斯朴素贝叶斯分类(GNB)、补充朴素贝叶斯分类(CNB)、支持向量机(SVM)和k近邻分类(KNN)是经典的机器学习模型,目前已部分应用于疾病的预测及数据分析中[8-9]。在预测CAS患者发生缺血性脑卒中的风险方面应用较少。本研究旨在比较LR、GNB、CNB、SVM和KNN五种不同的机器学习模型预测CAS患者发生缺血性脑卒中的效能。
1 资料与方法
1.1 研究对象2021年3月1日—11月30日在上海市第八人民医院神经内科住院的CAS患者101例。纳入标准:(1)年龄≥35岁;(2)经颈动脉彩色多普勒超声检查诊断为颈动脉粥样硬化的住院患者;(3)未接受颈部血管手术治疗者;(4)无严重脑血管疾病史。排除标准:(1)年龄<35周岁;(2)合并严重的肝、肾、肺及消化系统疾病者;(3)有颈动脉内膜剥脱术、血管搭桥术或颈动脉支架成形术等颈部血管手术史者;(4)有严重脑血管疾病史者;(5)颈动脉闭塞患者;(6)住院信息不全或临床随访资料不全。
1.2 数据库建立采集CAS患者性别、年龄、糖类抗原CA-50、鳞癌抗原SCC、维生素B12、甲胎蛋白、神经元特异烯醇化酶、铁蛋白、游离甲状腺素、三碘甲状腺原氨酸、甲状腺素、甲状腺球蛋白、癌胚抗原、糖类抗原CA19-9、糖化血红蛋白、免疫球蛋白IgG4、免疫球蛋白E、补体C3、血液生化、血常规及颈动脉超声检查结果建立数据库。
1.3 数据预处理搜集的101例CAS患者中,有缺血性脑卒中90例,无缺血性脑卒中11例,数据存在不均衡现象,为了减少模型预测性能的偏倚,本研究采用了SMOTE(sythetic minority over-sampling technique)方法对数据进行样本平衡,使得结局变量比例为2∶1。
1.4 超声仪器设备及检查方法GE Vivid E9超声诊断仪,配备L9探头,频率为5~12 MHz。患者去枕平卧,充分暴露颈部,头后仰偏向对侧,检查患者双侧颈动脉,记录有无斑块、斑块的内部回声、表面形态、内部构成、测量斑块大小及颈动脉狭窄率。
1.5 诊断标准(1)CAS超声诊断标准。依据2005美国放射学年会超声会议公布的超声诊断CAS标准:颈动脉内-中膜厚度(imtima-media thickness,IMT)>1.0 mm,诊断为增厚;IMT≥1.5 mm,局限性增厚或内中膜增厚大于周边IMT的50%,并凸向血管腔内,则定义为斑块[10-12]。(2)缺血性脑卒中诊断标准。缺血导致的持续24 h以上的症状性神经功能恶化,或新发症状性神经功能恶化并伴有新发脑梗死的神经影像学证据[13]。
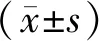
2 结 果
2.1 两组CAS患者临床基线特征101例CAS患者,其中男性52例(51.49%),女性49例(48.51%),年龄41~97岁,平均(69.96±11.03)岁,经统计检验分析,碳酸氢根、嗜碱性粒细胞比率、中性粒细胞数、血清淀粉样蛋白A和淋巴细胞比率在脑卒中的各组间差异有统计学意义(P<0.05)。见表1。
2.2 特征重要性分析采用极端梯度提升树对所有的变量进行变量重要性分析,筛选变量的模型参数为优化目标函数(objective): 学习速率 (reg:squarederror;learning_rate): 0.1;最大树深度(max_depth): 4;最小分叉权重和(min_child_weight): 4;L2正则化系数(reg_lambda): 1。重要度最高的十个特征变量为前白蛋白、淋巴细胞比率、嗜碱性粒细胞比率、低密度脂蛋白胆固醇、甲状腺结节、碳酸氢根、鳞癌抗原SCC、铁蛋白、神经元特异烯醇化酶、嗜碱性粒细胞,见图1。下一步将这十个重要变量纳入不同的机器学习模型中。
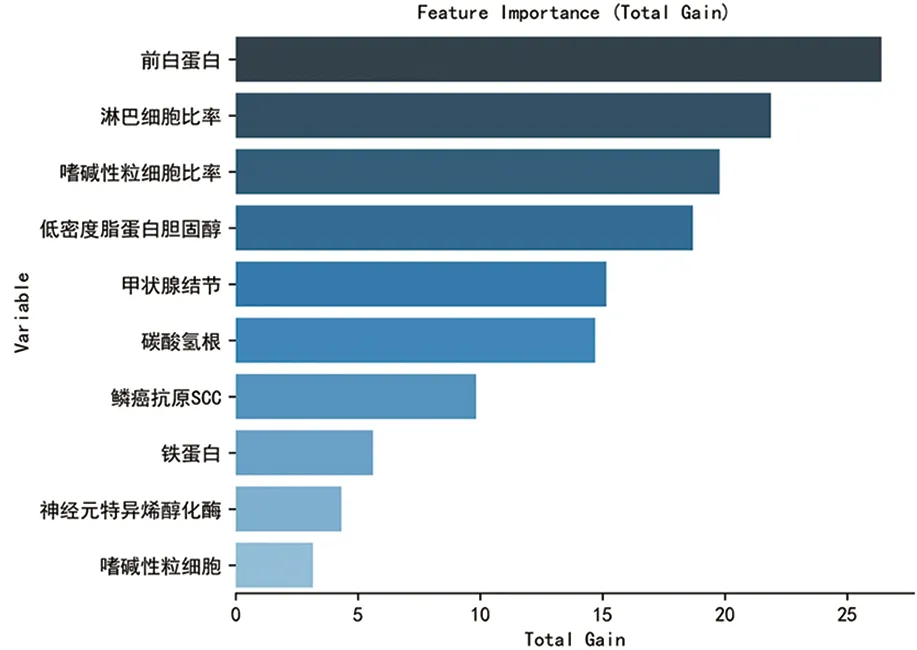
图1 特征变量重要性排序
2.3 五种ML模型预测效能比较从准确度方面分析,LR(72.6%)、GNB(83.0%)、CNB(62.2%)、SVM(72.6%)和KNN(65.9%),按准确度从高到低排列依次为GNB模型、LR模型、SVM模型、KNN模型、CNB模型;从灵敏度方面分析,LR(67.5%)、GNB(81.6%)、CNB(62.9%)、SVM(62.5%)和KNN(83.6%),按灵敏度从高到低排列依次为KNN模型、GNB模型、LR模型、CNB模型、SVM模型;从特异度方面分析,LR(96.0%)、GNB(100.0%)、CNB(77.4%)、SVM(91.2%)和KNN(82.7%),按特异度从高到低排列依次为GNB模型、LR模型、SVM模型、KNN模型、CNB模型;从AUC方面分析,LR=0.810(0.052)、GNB=0.936(0.032)、CNB=0.629(0.104)、SVM=0.781(0.062)和KNN=0.854(0.065),按AUC值从高到低排列依次为GNB模型、KNN模型、LR模型、SVM模型、CNB模型,见表2、图2及图3。

注:A为训练集,B为测试集

图3 五种ML模型预测效能比较森林图

表2 五种ML模型的效能结果
综上所述,训练集中,GNB模型的真实性(灵敏度、AUC值)和可靠性(准确度)均高于其余四种模型;预测性上,LR模型的阳性预测值(0.978)最高,GNB模型的阳性预测值(0.977)比LR模型略低,而GNB模型的阴性预测值(0.748)在五种模型中最高。测试集中,GNB模型的真实性(特异度、AUC值)和可靠性(准确度)均高于其余四种模型;预测性上,LR模型的阳性预测值(0.983)最高,GNB模型的阳性预测值(0.962)仅次于LR模型,而GNB模型的阴性预测值(0.644)在五种模型中最高。综合比较五种ML模型的预测效能,GNB模型预测效能最高,LR模型、KNN模型、SVM模型、CNB模型按序次之。GNB模型和LR模型两种模型ROC检验的P值等于0.012,这两种模型的ROC检验组间比较差异有统计学意义。见表3。

表3 Delong检测五种ML模型P值均值表
3 讨 论
随着计算机技术的不断发展,机器学习已渗透到部分医疗领域并带来了前所未有的效率及进步[14]。有研究将机器学习模型应用到疾病预测中,最终实现了患病风险预测[15-16]。既往关于CAS患者发生缺血性脑卒中的风险研究,大部分仅局限于危险因素、预后及病理生理方面[17-18],很少有利用机器学习模型预测CAS患者发生缺血性脑卒中的风险。本研究比较五种机器学习模型预测CAS患者发生缺血性脑卒中风险的效能,五种预测模型的准确度(62.2%~83.0%)、灵敏度(62.5%~83.6%)、特异度(77.4%~100.0%)、AUC(0.629~0.936),GNB模型的准确度(83.0%)、特异度(100.0%)、AUC(0.936)在所有模型中最高,推断出GNB模型在预测CAS患者发生缺血性脑卒中风险效能最优,差异有统计学意义,此模型有望应用于临床,进一步为缺血性脑卒中高危人群提供精准预防策略。
颈动脉粥样硬化是缺血性脑卒中高危人群发生缺血性脑卒中的高危因素[19-20]。目前国内超声工作人员人数与日益增加的超声检查需求极不对等。我们的研究将人工智能手段应用于CAS患者发生脑卒中风险的预测中,以筛选出急需进行检查的患者,缓解上述矛盾。本研究比较LR、GNB、CNB、SVM和KNN五种经典的机器学习模型对CAS患者发生缺血性脑卒中的预测效能,结果表明GNB模型在处理二分类结局变量的小样本数据中具有优势,这与VERMA等[21]的研究观点一致。不仅如此,本研究还发现最终纳入ML模型的预测因子,经过单因素多因素筛选后,再利用Xgboost对筛选出的预测因子进行重要性排序,可以提高模型的精准预测性能,本研究结果显示GNB模型的特异度为1.000,具有理想的区分度。在既往的研究中,已有学者论证了ML模型预测因子筛选的重要性,ALI等[22]使用统计模型对常用的13个心力衰竭数据特征进行排名,不仅解决了心力衰竭数据的准确率较低的问题,还将GNB模型的预测精度提高了3.33%,此结论与本研究相符。
在既往的研究中,TU[23]利用LR模型进行疾病的预测模型,但LR模型具有普遍适用性。贝叶斯模型在医学研究中是一种新兴技术[24],CNB可以均匀地使用每个类别的训练数据量,从而使估计结果更具客观性[21-23],但CNB模型适合处理样本量较大的数据,以实现其结果的客观性,而本研究属于小样本研究。相比之下,GUO[25]等利用SVM模型对高维数据进行分类和预测,并表现出出色的预测性能。本研究中SVM模型的AUC达到0.781,该模型在预测CAS患者发生缺血性脑卒中方面,预测性能表现良好,但不是最佳。LENNARTZ等[26]应用KNN分类器对光谱探测器CT(SDCT)衍生的碘图(IM)与传统图像(CI)的纹理进行分析对比,KNN模型在处理图像特征方面具有优势,相比于结局变量为二分类变量的数据,KNN模型的预测性能可能相对较弱。基于本研究数据分析CAS患者发生缺血性脑卒中的预测研究,结果显示GNB模型的各项指标明显大于其他四种模型,具有更高的预测性能和临床实用价值。
机器学习临床应用方面,李桃等人[27]利用一种机器学习算法(随机森林)结合十个临床指标建立了2型糖尿病患者颈动脉粥样硬化斑块预测模型,但该研究局限于一种机器学习算法,临床应用价值有限。本研究将五种机器学习模型应用于CAS患者缺血性脑卒中的预测中,结果显示GNB 模型的真实性(灵敏度、特异度、F1分数、AUC值)、可靠性(准确度、Kappa值)和预测性(阴性预测值)均高于其余四种模型,该模型在颈动脉粥样硬化患者发生缺血性脑卒中的预测效能方面表现最优。王娇娇等[28]利用了SVM、BP与RF三种机器学习模型预测了钢铁工人颈动脉粥样硬化的发生,但该研究未对颈动脉粥样硬化患者缺血性脑卒中结局进行探讨。本研究不仅筛选了CAS患者发生缺血性脑卒中的风险预测因子,还基于不同机器学习模型预测了CAS患者缺血脑卒中的结局发生,具有十分重要的临床意义和应用价值。且我们的研究是在前人研究的基础上,分析了五种经典的机器学习模型对CAS患者缺血性脑卒中发生结局变量的研究,这使得筛选出的模型预测性能更加精准。本研究结合准确度、灵敏度、特异度、阳性预测值、阴性预测值、F1分数、Kappa值、Cutoff值和AUC等多种指标比较了五种不同机器学习模型的预测效能,这在一定程度上减少了单一模型或单一评价指标带来的研究偏倚。
李鹏等人[29]选择了十个影响缺血性脑卒中发病的高危因素,包括年龄、缺乏运动、遗传、高血脂、高血压、不良饮食、高血糖、吸烟、心脏病、酗酒,作为模型预测因子,利用LR模型预测了缺血性脑卒中的发病率,该研究纳入LR模型的预测因子主要局限于患者的一般基线病史数据,未涉及实验室检测指标及影像学数据。陈莉平等[30]利用大数据应用平台收集了脑卒中患者的临床数据,包括患者个人信息,实验室数据及住院诊疗情况等,这与本研究数据搜集方面存在相似之处,但该研究主要针对脑卒中初患人群的复发情况机器学习模型风险预测。本研究搜集了CAS患者的一般基线信息、实验室检查数据及超声影像学检查结果共70个研究变量,从多维度纳入模型备选变量,最终筛选了十个ML模型的重要预测因子,分别为前白蛋白、淋巴细胞比率、嗜碱性粒细胞比率、低密度脂蛋白胆固醇、甲状腺结节、碳酸氢根、鳞癌抗原SCC、铁蛋白、神经元特异烯醇化酶、嗜碱性粒细胞,都是目前临床容易获得的变量,可广泛应用于临床,从而有针对性地再进行颈动脉筛查,这样可以部分缓解现有超声医生不足与日益增加的脑卒中高危人群的矛盾。
然而,本研究还存在一些局限性。第一,本研究的样本量较小,数据分析前采用了合成少数类过采样技术(SMOTE)平衡正负样本比例,SMOTE的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中,因此分析出的模型结果可能容易出现过拟合的现象,接下来的研究会进一步加大正负样本量,让模型更接近真实预测值。第二,本研究的主要目的是探索不同的机器学习模型预测CAS患者发生缺血性脑卒中的可行性,下一步的研究中可以加入其他更多的机器学习模型,如随机森林、决策树、XGBoost等,通过探索比较更多不同机器学习模型的性能,进一步推进机器学习模型在CAS患者发生缺血性脑卒中的临床预测应用。第三,本研究的CAS患者全部来自上海市第八人民医院,利用了5倍重采样技术将该数据集按8∶2的比例拆分为训练集和测试集,没有使用外部数据集进行模型测试,因此,模型结果可能会存在地域偏差性,加入外部测试集可以成为未来研究的一种途径。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
心肺血管病杂志(2019年9期)2019-12-09
中医眼耳鼻喉杂志(2019年3期)2019-04-13
电影(2018年8期)2018-09-21
中国民族医药杂志(2016年5期)2016-05-09
中国继续医学教育(2015年4期)2016-01-07
中国继续医学教育(2015年3期)2016-01-06
医学研究杂志(2015年11期)2015-06-10
小猕猴智力画刊(2015年4期)2015-04-28
