
模糊线性判别QR分析的茶叶近红外光谱鉴别分析
2023-12-13 06:36胡彩平何成遇孔丽微朱优优周浩祥
光谱学与光谱分析 2023年12期
胡彩平, 何成遇, 孔丽微, 朱优优*, 武 斌, 周浩祥, 孙 俊
1. 金陵科技学院计算机工程学院, 江苏 南京 211169 2. 江苏大学电气信息工程学院, 江苏 镇江 212013 3. 浙江大学台州研究院, 浙江 台州 317700 4. 滁州职业技术学院信息工程学院, 安徽 滁州 239000
引 言
中国是饮茶大国, 作为茶叶的故乡, 拥有非常悠久的饮茶历史和深厚的饮茶文化。 茶的作用和功效非常多, 富含多种有益人体健康的物质, 茶在中国受到很多人的喜欢。 中国的茶叶种类非常丰富, 就绿茶而言就有几百种, 各个地方的知名春茶, 如安徽省的岳西翠兰、 六安瓜片、 施集毛峰和黄山毛峰; 浙江省的龙井茶和安吉白茶等。 各个不同品种的茶叶蕴含的功效也不尽相同[1-3]。 因此, 要对不同品种茶叶进行鉴别分析, 挑选出更加优质的茶叶品种。
近红外光谱分析样品具有分析速度快, 应用范围广等特点, 因此是一种经常被用于农产品和食品等诸多领域的检测技术, 近些年来被国内外的学者广泛应用[4-6]。 如Wang等利用近红外高光谱成像技术结合偏最小二乘回归模型的回归系数为茶多酚含量的可视化以及茶叶品种的鉴定提供了一种快速无损的鉴别方法[7]。 Wu等提出了联合Gustafson-Kessel聚类算法对茶叶样品的傅里叶变换红外光谱(Fourier transform infrared spectroscopy, FTIR)进行聚类, 建立一个能进行茶叶品种准确分类的有效判别模型[8]。 Firmani等通过使用近红外光谱技术结合最小二乘鉴别分析和软独立建模(soft independent modelling of class analogy, SIMCA)区分有地理标志的大吉岭茶与其他掺假大吉岭茶时取得了非常好的分类效果[6]。 Luo等使用可见-近红外光谱, 以随机蛙跳作为特征选择方法提取特征波长建立的最小二乘支持向量机的预测模型可以快速检测茶叶中茶多酚的含量[9]。 Thangavel等通过采用漫反射傅里叶变换近红外光谱法快速定量测定姜黄根茎中姜黄素、 淀粉和水分含量, 该方法可以用于香料的加工鉴定分级[10]。 Qian等提出傅里叶变换近红外光谱结合偏最小二乘分析方法实现了对绿豆原产地的鉴别, 提供了一种新的保护绿豆地理标志产品品牌途径[11]。 Wu等建立基于近红外光谱和随机森林法的分类模型, 并结合偏最小二乘回归算法实现了对不同产地五味子的鉴定[12]。 Diniz等使用连续投影算法线性判别分析(successive projections algorithm linear discriminant analysis, SPA-LDA)根据茶叶的化学成分对茶叶品种进行简化鉴别分类[13]。
茶叶的近红外光谱数据通常是高维数据, 数据比较复杂, 计算量大, 需要通过特征提取和特征选择对数据进行降维分析以获取有用的特征信息。 目前常见的用于特征提取的方法分别有主成分分析(PCA), 线性判别分析(LDA)[14]以及模糊线性判别分析(FLDA)[15]。 线性判别分析将高维的数据样本投影到低维的矢量空间中, 其主导思想是保证投影到低维空间的数据样本的类间距离最大以及类内的距离最小, 以此达到压缩信息和对高维数据的降维目的。 FLDA将模糊集的理论融入到传统的线性判别分析中, 实现对样本的特征提取。 本工作在FLDA的基础上, 对模糊类间散射矩阵和模糊类内散射矩阵进行计算, 得出矩阵的特征值和特征向量, 对由散射矩阵的特征向量构成的鉴别向量矩阵进行QR分解, 以新的鉴别向量矩阵实现数据转换。 实验结果表明, 模糊线性判别QR分析对茶叶近红外光谱数据分类处理的准确率高于线性判别分析。
利用傅里叶近红外光谱仪对茶叶样本进行检测, 获取四种茶叶样本的近红外漫反射光谱数据, 然后采用主成分分析法对茶叶的近红外光谱数据进行降维, 将降维后的光谱数据存储在计算机里。 利用模糊线性判别QR分析方法提取光谱数据的模糊鉴别信息, 最后采用K近邻算法对数据集进行分类分析。 最后实验结果发现, 傅里叶近红外光谱结合模糊线性判别QR分析方法可对不同品种的茶叶实现快速准确的鉴别分析。
1 实验部分
1.1 茶叶傅里叶近红外光谱数据采集
实验所用茶叶样本为黄山毛峰、 岳西翠兰、 施集毛峰和六安瓜片等四种不同品种的茶叶。 每个品种的茶叶各采集65个茶叶样本, 样本的总数为260。 将所有采集的茶叶样本进行研磨粉碎, 经40目筛过滤。 实验室的温度和相对湿度保持稳定, 采集茶叶傅里叶近红外光谱数据所使用的AntarisⅡ型的FT-NIR光谱仪需要开机预热1 h。 茶叶的近红外光谱数据通过反射积分球模式采集, 每个茶叶样本扫描32次, 扫描的光谱波数范围是4 000~10 000 cm-1, 光谱的波数间隔为3.857 cm-1, 得到的茶叶近红外光谱的维数为1 557维。 为避免出现较大偏差, 每个茶叶的近红外光谱均采集三次, 取三次的平均值作为茶叶样品光谱原始数据。 使用MatlabR2014b进行程序的编写, 在Windows10的系统环境运行, RAM 4GB。
1.2 模糊线性判别QR分析描述
模糊线性判别QR分析方法提取由主成分分析降维压缩后的茶叶近红外光谱数据中的鉴别信息, 具体的步骤如下:
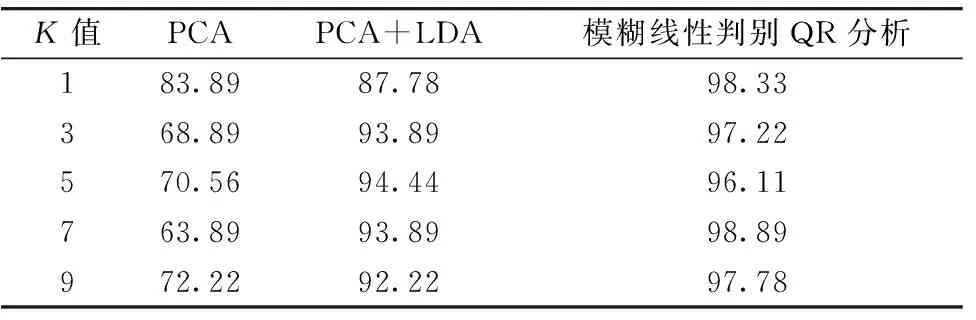
步骤一: 初始化参数。 开始时设置类别数为K, 设置茶叶的训练样本数为N1, 测试样本数为N2, 类别数为c, 权重指数为m, 其中, 1 步骤二: 类中心和模糊隶属度的计算。 利用模糊K近邻算法计算茶叶的第j(1≤j≤N1)个训练样本xj[为第t(1≤t≤c)类训练样本]隶属于第i(1≤i≤c)类的模糊隶属度μij (1) 式(1)中,ni是隶属于第i类的近邻样本数,K为模糊K近邻算法的参数。 第i类初始类中心γi为 (2) 步骤三: 计算模糊类间散射矩阵Sfb和模糊类内散射矩阵Sfw (3) (4) (5) (6) 由于茶叶样本颗粒和形状大小影响, 采集到的茶叶近红外光谱数据会出现散射问题, 因而要对茶叶近红光谱数据进行预处理, 通过多元散射校正(MSC)来降低因散射带来的影响, 提高实验的准确度[16-17]。 茶叶的近红外光谱数据的维数是1 557维, 维数很高, 直接进行分类处理, 计算量相当大, 并且得出分类准确率会比较低。 因此需要先使用主成分分析将光谱数据的维数进行压缩, 将数据的维数降到7维, 再使用模糊线性判别QR分析提取降维后的光谱数据集中的鉴别信息。 从四类茶叶样本中随机各抽取20个样本茶叶组成训练样本集, 训练样本集的总数为80个, 则测试样本集由四种茶叶每类45个样本作为测试样本集, 测试样本集的总数为180个。 运行模糊线性判别QR分析计算20维的训练样本集的鉴别向量, 将20维的测试样本集投影到前三个鉴别向量上, 模糊线性判别QR分析处理后的数据如图1所示。 在图中, 圆点“·”表示“岳西翠兰”, 星号“*”表示“六安瓜片”, 圆圈“○”表示“施集毛峰”, 加号“+”表示“黄山毛峰”。 图1 模糊线性判别QR分析处理后的数据图Fig.1 The data after fuzzy linear discriminant QR analysis 运行模糊线性判别QR分析之前需要设置算法的初始参数: 设置模糊K近邻的参数K=1, 算法的权重指数m=2, 类别数c=4。 聚类中心由式(2)计算得出, 初始的模糊隶属度如图2所示。 图2 模糊隶属度值Fig.2 Fuzzy membership values 先用主成分分析对茶叶近红外光谱数据进行降维, 后直接使用K近邻算法进行分类, 得到的分类准确度比较低; 其次分别用LDA和模糊线性判别QR分析提取数据的鉴别信降维息后再使用K近邻算法进行分类分析; 结果表明: 当K取不同的值得到的分类准确率, 模糊线性判别QR分析得到的分类准确率均高于PCA和PCA+LDA。 其中, 当K=7时, 模糊线性判别QR分析得到的分类效果最好, 其分类准确率结果如表1。 表1 三种模型的分类准确率(%)Table 1 Accuracies of three models (%) 模糊线性判别分析结合矩阵的QR分解, 提出了模糊线性判别QR分析方法。 模糊线性判别QR分析通过提取经主成分分析降维后的茶叶光谱数据中的鉴别信息, 得到有效光谱数据的鉴别信息, 分类准确率比线性判别分析更高。 实验结果显示: 在利用茶叶的近红外光谱数据信息, 经主成分分析进行数据的降维处理, 分别使用模糊线性判别QR分析和线性判别分析提取降维后的光谱数据中的鉴别信息, 最后利用K近邻分类器进行分类处理。 由模糊线性判别QR分析建立的模型可以准确有效的鉴别茶叶品种, 且准确率高于用线性判别分析建立的模型。

2 结果与讨论
2.1 茶叶红外光谱的主成分分析和线性判别分析

2.2 模糊隶属度和类中心

3 结 论
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
车主之友(2022年4期)2022-08-27
数学物理学报(2022年4期)2022-08-22
中学生数理化·高一版(2021年2期)2021-03-19
海峡姐妹(2019年12期)2020-01-14
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
计算物理(2014年1期)2014-03-11
燕山大学学报(2014年1期)2014-03-11
