
一种基于残差网络改进的异常流量入侵检测模型
2023-12-13 01:39王锁成陈世平
小型微型计算机系统 2023年12期
王锁成,陈世平
1(上海理工大学 光电信息与计算机工程学院,上海 200093) 2(上海理工大学 信息化办公室,上海 200093)
1 引 言
传统的网络入侵检测系统使用机器学习的方法来识别异常流量,通常需要较高的存储和计算资源,且这些方法依赖于设计的流量识别特征.因此,这些方法的准确性和推广能力受到限制.另一个问题是当前的网络威胁方法更加隐蔽,关键的入侵行为过程通常隐藏在许多正常的数据包中.恶意通信量和可以捕获的威胁检测样本相对较少,很容易导致模型的学习过程太短和训练不足.上述缺点使得传统的网络入侵检测方法具有较低的准确率和较高的虚警率.近年来,深度学习模型因其高效性和易实现性而被逐步应用于网络入侵检测.它的优势在于可以从大量数据中学习深层次特征,具有较强的非线性拟合能力,并适用于复杂数据的处理[1].因此,深度学习的应用可以降低网络入侵检测系统的成本,增强检测攻击的能力.
一般认为,增加网络层的数量可以更好的提取特征,从而提高模型的性能.然而,简单地叠加更多网络层可能会使任务失败.此外,在层数达到一定阈值后,甚至可能导致性能下降.残差网络[2]是为了解决上述问题而提出的,它最大限度地减少了因网络深度增加而导致的梯度消失,并在保持高精度的同时减少了数据中的信息冗余.本文将残差网络的概念引入到网络入侵检测中,构建更深层次的网络以提高网络入侵的检测能力.CBAM[3](Convolutional Block Attention Module)由通道注意子模块和空间注意子模块组成.本文融合CBAM注意力机制来扩展残差网络中的结构,提升网络模型的特征提取能力,从而提高异常流量分类的准确性和鲁棒性.
本文选择非平衡的网络入侵检测数据集CICIDS2017[4]对模型进行评估.在实时网络入侵检测中,类别不平衡问题对分类结果有重大影响,模型通常会出现预测主要类别而无法识别次要类别的问题.尽管采样技术可用于解决类不平衡问题,但采样技术也有其缺点:1)可能会破坏原始数据,且模型训练需要更长的时间;2)采样不足会导致关键信息丢失,影响分类能力.为了解决上述问题,引入焦点损失函数[5],其最初是为了平衡类别之间的损失.本文在所提出的模型中应用了改进的焦点损失函数,可在不干扰训练数据的情况下,增强检测小样本类别的能力.
本文探索直接对原始流量数据进行图像化处理,将异常流量入侵检测问题转换为图像分类问题.采用端到端的技术将流量数据输入,使模型能自主学习流量的特征信息,避免人为因素造成的特征信息丢失,来最大程度保证原始流量信息的完整性,进而实现更高效的流量异常检测.本文的主要贡献如下:
1)提出了一种新的基于残差网络改进的异常流量入侵检测模型,在CICIDS2017数据集上与基线模型进行实验对比,结果表明,该模型具有99.29%的总体准确度.
2)在网络入侵检测领域,首次应用融合通道注意力机制和空间注意力机制的残差网络,使模型更关注对分类结果有用的特征信息.
3)使用改进的焦点损失函数来处理网络异常流量数据集中的类别不平衡的问题.对比实验表明,所有小样本类别攻击的检测可以达到最高的检测精度.
2 相关工作
2.1 深度学习网络入侵检测相关研究
研究表明,基于深度学习的方法有助于战胜开发有效的入侵检测系统的挑战,如特征选择和表示的困难,以及将线性或非线性的序列模型转换为特定的数据结构.张勇等人[6]提出了一种并行的CNN结构PCCN,该结构实现在不增加网络的深度的情况下,通过特征融合提高网络的泛化能力.彭玉杰等人[7]提出了一种1.5D-CNN模型,是将1D-CNN和2D-CNN相结合,通过提取不同维度的流量特征,实现多分类准确率达到98.5%.袁小勇等人[8]将LSTM用于异常流量检测,可以自动学习不同时间序列的特征并找到其相关性,在ISCX2012数据集上准确率和召回率方面都相对较好.Roopak等人[9]提出了一种结合RNN和CNN的模型,用于检测物联网上的DDoS攻击,其检测准确率达到97.16%.Pham等人[10]提出了一种轻量级入侵检测系统,该系统将原始流量数据转换为二维图像数据,然后使用CNN模型学习有效特征的方法提高了计算效率,但实验结果表明检测精度较低.李志鹏等人[11]提出了将各种流量特征属性转换为二进制向量再转换为图像.使用ResNet50对二元分类的问题进行了一些实验,在测试集上获得了79.14%的准确度.针对将网络流量转换图像分类算法的局限性,尽管残差网络可以提高CNN的整体性能,但在实际应用中,由于缺乏原始训练数据,单独使用残差网络并不能提高模型检测小类别攻击的能力,更无法为入侵检测系统提供更好的性能.
2.2 不平衡数据集上的相关研究
类别不平衡问题意味着类别数据量存在显著差异.当类别数据量分布几乎相同时,机器学习算法的效果最好.因此,数据不平衡也是机器学习分类性能恶化的一个因素.虽然大多数研究可以获得较高的检测精度,但没有考虑数据集不平衡分布对分类结果的影响,只是归因于特定类别样本数量的缺少.Marín等人[12]研究了深度学习模型在数据包级别和流级别识别的准确性.结果表明,流式输入的识别率较高,但作者没有考虑小样本因素对模型的影响.张崇祯等人[13]提出了一种通用的入侵检测框架,使用无监督的自动编码器进行特征提取,低维重组特征被压缩存储在数据库模块中,可以为分类提供再训练和测试.结果表明,在多分类中,小样本的识别率低于其他样本类别.孙鹏飞等人[14]使用了CNN和LSTM的混合模型,通过优化权重来消除样本类别不平衡对模型的影响.模型在多分类中的准确率达到98.67%.Kim等人[15]提出了一种使用GAN模型自动分类恶意流量的方法,由于进行了二元分类,只测量了准确率,数据不平衡的主要性能指标召回率和F1值存在未测量的问题.蒋开元等人[16]使用混合采样方法解决了数据集不平衡问题,通过单侧选择(OSS)减少数量较多样本中的噪声,并使用过采样技术(SMOTE)增加小样本,最终构建了一个相对平衡的数据集.使用CNN-BiLSTM的混合模型未能在数据集上达到所需的识别精度.数据集的平衡性虽然得到了改善,但就近选择时存在一定的盲目性.因此也加大了算法进行分类的难度.
受这些研究的启发,如何在不引起性能下降的情况下,构建更深层次的网络提取数据特征,以及解决数据集中的类别不平衡问题是两大挑战.本文引入融合卷积注意力机制模块的残差网络,来学习网络流量的深层特征来提升模型的泛化能力,用焦点损失函数增加目标类别的权重,从而来提高小样本类别的检测精度.
3 相关算法
3.1 残差网络
CNN的深度对最终的分类结果有很大影响.简单地在网络中添加卷积层和池化层,并不能提高模型的精度,甚至会导致网络性能的恶化.因此引入残差学习来解决上述问题.残差是指输入和输出之间的差异,见公式(1):
f(x)=g(x)-x
(1)
与目标映射相比,残差学习的学习目标是0,即减少输入和输出之间的差异,允许原始输入直接连接到某个网络层,以便网络可以学习残差.残差网络是在传统线性卷积网络结构的基础上增加一个快捷连接,底层的参数可以通过快捷连接传递到下一层.实验证明,引入的快捷连接不仅避免了向网络中添加额外的参数和计算,而且也不会影响原始网络的复杂性,保证性能的同时,网络可以学习更深层次的特征.因此,网络收敛速度加快,可以达到更高的分类精度.如图1所示,残差块主要由残差部分和直接映射组成.
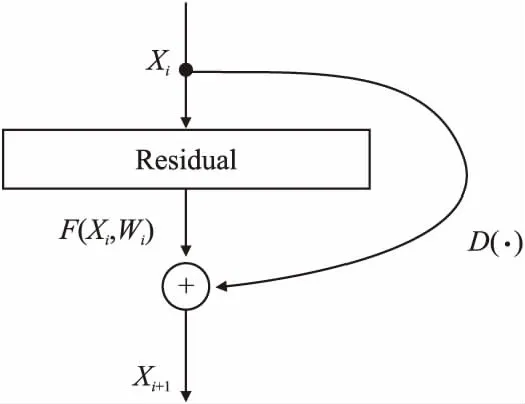
图1 残差块示例图Fig.1 Example of residual block
其中Xi是输入特征,残差部分是F(XI,Wi),Wi表示卷积运算.直接映射见公式(2):
D(x)=W′×x
(2)
W′表示1×1卷积运算,它将输入特征映射的维数降低到与残差部分的输出维数一致.
本文使用残差网络ResNet50的结构,由残差模块、批量归一化和Relu激活函数构造. ResNet50分为5个阶段,第1阶段可以看作数据预处理,第2阶段~第5阶段引入残差块可以加深模型的层数,使网络的每一层都能充分学习原始流量特征.
3.1.1 恒等残差块和卷积残差块
在模型中可以串联多个输入和输出相同维度的是恒等残差块(Identity Block),每层中都有Conv2d和Relu操作.为了加快模型训练速度,增加批量归一化层.当输入和输出的维度不同时,需要使用卷积残差块(Convolutional block)来解决这个问题.它与恒等残差块的最大区别在于不能串联,需要在快捷连接中添加一个1×1大小的Conv2d卷积层,以构建通道平衡残差模块.
3.1.2 批量归一化
在CNN的训练部分,前一层参数的变化会引起下一层参数相应变化,使得深层次的网络模型难以训练.批量归一化使各层的输入保持相同的通道,解决了网络训练困难的问题,有效地提高了收敛速度和稳定性.对于每个批次,所有特征映射都需要在非线性激活之前进行批量归一化(Batch Normalization).本文将每个小批次作为一个单元来规范化特征数据,见公式(3):
(3)
可以说,它是当前深度网络的重要组成部分.批量归一化不仅能提高网络的泛化能力,而且提升了学习的准确性,同时也有防止过拟合的效果.
3.2 CBAM注意力机制
CBAM注意力机制是把通道注意机制模块和空间注意机制模块结合起来的一个轻量级框架,可以用于端到端训练.通道注意模块突出显示图像提供的代表性信息,空间注意模块侧重于对图像有贡献的代表性区域.CBAM从通道和空间两个维度计算特征映射的注意映射,然后将注意映射与输入特征映射相乘以自适应的学习特征[17].对于中间层的特征图,将依次生成一维通道注意特征图和二维空间注意特征图,具体结构如图2所示.
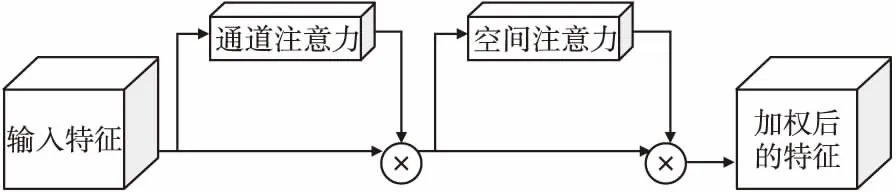
图2 卷积注意力模块Fig.2 Convolution attention module
3.2.1 通道注意模块
通道注意模块如图3所示.输入的特征分别由全局最大池化和全局平均池化处理,输入特征将被引导到多层感知器(MLP)中进行处理,叠加生成通道注意特征图,再将两个输出特征映射按元素求和来计算,最后,对特征图使用Sigmoid函数激活,以获得通道注意模块的输出.具体计算过程,见公式(4):
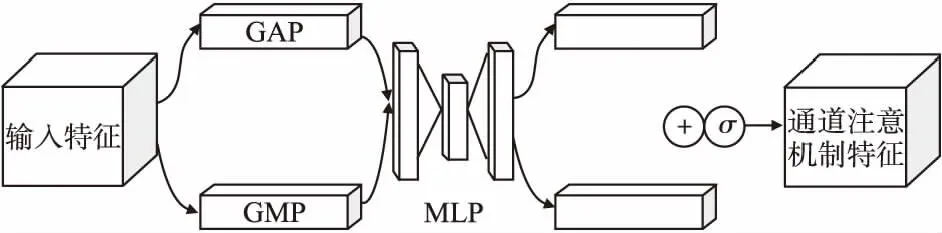
图3 通道注意模块Fig.3 Module of channel attention
X′=σ(MLP(GAP(X)+MLP(GMP(X)))
(4)
其中σ表示应用的Sigmoid函数,MLP表示多层感知器,GAP和GMP分别表示全局平均池化和全局最大池化.
3.2.2 空间注意模块
空间注意模块如图4所示.带有通道权重的特征映射作为输入,沿通道维度上使用全局最大池化和全局平均池化来聚合两种不同的特征描述,生成空间特征映射图,然后使用一个内核大小为7的卷积层将通道维数降低到1.最后,对特征图使用Sigmoid函数激活,最终得到空间注意权重的输出.见公式(5),其中f表示卷积层计算:
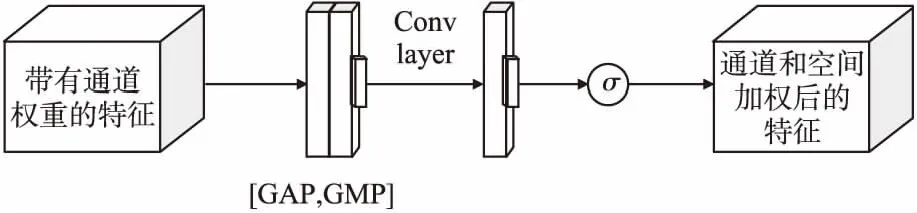
图4 空间注意模块Fig.4 Spatial attention module
X″=σ(f7×7(GAP(X′);GMP(X′)))
(5)
3.3 焦点损失函数
在现实网络中,异常网络流量的数据量是远远小于正常流量.因此,数据通常存在明显的类别不平衡问题.采样技术是处理不平衡数据最常用的方法之一,但欠采样会导致重要信息的丢失,而过采样会添加新信息从而破坏数据,并大大增加训练时间.为提高小样本分类的精度,本文引入了改进的焦点损失函数,可以避免交叉熵损失函数在优化一个类别的同时忽略其他类别的问题,且避免模型在训练时引起的过拟合现象.损失函数是指数据的真实值和预测值之间的差值,差值越小就反映真实值与预测值之间的误差越小,模型的精度也就越高.焦点损失函数旨在解决类别不平衡问题,侧重于难分类的小样本.改进的焦点损失函数在原焦点损失函数的基础上增加了一个调节因子.在模型训练过程中,可以调整难易样本的权重,从而缓解数据不平衡的问题.改进的焦点损失函数定义见公式(6):
FLloss=-αt(1-pt)γlog(pt)
(6)
其中,γ是一个难易样本不平衡的调节因子,可衰减易分类样本权重,降低损失.反之提高难分类样本的关注度.pt计算见公式(7):
(7)
其中,p∈[0,1]表示类别预测概率,y是标签值.当pt→1,模型对流量类别预测的置信度就越高,损失函数值会变小.反之置信度就越低,损失函数值会变大.αt是一个加权因子,可以衡量正负样本的重要性.在本文中,γ设置为2,αt计算见公式(8):
(8)
其中,nt表示属于t类的样本数量,sumn表示训练数据中的样本总数.因此,引入改进的焦点损失函数,来优化模型在不平衡数据集下检测攻击的效果.
4 CBAM-FL-ResNet入侵检测模型设计
针对网络入侵检测分类任务,不仅有添加神经网络层可能无法改善分类结果,而且存在不平衡数据集中的小类别攻击检测准确率低的问题.因此,本文建立了一个异常流量入侵检测模型来解决上述的问题,称为CBAM-FL-ResNet.
CBAM-FL-ResNet模型的工作流程,一共有3个阶段组成,各阶段工作流程的描述如下:
1)预处理阶段:为提升网络的特征提取能力,减少模块计算,提高网络收敛速度,将网络异常流量处理为28x28的单通道灰度图作为模型的输入.
2)训练阶段:在ResNet50结构的基础上,引入CBAM注意力机制来提高模型对网络流量的特征提取能力,用改进的焦点损失函数改善数据集类别不平衡的问题,再用 Softmax分类器对网络异常流量检测分类.
3)测试阶段:用训练好的模型在测试集上进行测试,并将异常流量检测的实验结果与基线模型进行对比分析.
CBAM-FL-ResNet模型的核心框架结构如图5所示,其中s是卷积步长,BN是批量归一化,Relu是激活函数.模型采用初始卷积层、最大池化、4个残差块和CBAM注意力机制组成模型特征提取模块结构.
初始卷积层由卷积层、批量归一化和Relu激活函数组成,其中卷积层的卷积核大小为7×7,步长为2.最大池化内核大小为2×2,步长为2.残差模块采用三层对称卷积残差模块结构,每层中的残差块数为[3,4,6,3],适用于深度网络.将残差块中的卷积层替换为由批量归一化、Relu激活函数和卷积层组成复杂的卷积层,以进一步提高模型的运算速度和精度.
在特征提取模块中加入CBAM,通过其中的通道注意模块和空间注意模块,对流量特征图中的每个区域进行权重分配,增加对有效特征的关注度,压缩不重要特征. 12个Identity Block之间集成了12次CBAM,可以将中间特征映射细化为更能代表输入的目标信息.通过全局最大池化层和全局平均池化层不仅可以减少模型的计算量,而且可以提高模型预测速度.与此同时,在每个残差块使用残差连接,通过快捷连接将残差块输入添加到残差块输出中.为了保证残差块输入和输出特征大小的一致性,在快捷连接上增加了一个复杂的卷积层,卷积核为1×1,步长为2.
引入改进的焦点损失函数来估计CBAM-FL-ResNet的损失,实现不同流量类别样本使用不同的权重.当样本数据量少且难分类时提升权重,样本数据量多且容易分类时降低权重,减少数据不平衡对模型训练的影响,增强模型泛化能力,起到优化模型的效果.最后,SoftMax层将特征转换为概率值输出,来判断流量的类型.
5 实验结果及分析
5.1 实验环境
本文的实验环境如表1所示.

表1 实验环境设置Table 1 Experimental environment setting
5.2 数据收集和预处理
5.2.1 数据集收集
深度学习在入侵检测领域有许多开源数据集,但其中大多数都有以下缺点:1)这些数据集并不是原始流量,其中的一些数据集已经过时,且缺乏类别多样性和样本完整性;2)其中很多只包含报头信息,缺乏有效载荷信息,不能很好地反映攻击趋势.因此,使用这些数据集有可能会达不到预期的客观效果.
CICIDS2017是一个开源的网络入侵检测数据集,由加拿大网络安全局连续5天的时间内在完整的网络配置下收集的,包括调制解调器、防火墙和路由器等各种网络设备以及各种操作系统.通过分析人类交互的行为来收集和标记各种类型的流量.根据统计分析,该数据集共包含13种不同类型的攻击流量,且不同攻击的数量是不平衡的.综合考虑,选择CICIDS2017作为本文的实验数据集.
5.2.2 数据集预处理
本文从CICIDS2017数据集中提取10种类型网络流量分别为Normal、WebAttack、PortScan、DGoldenEye、DDoS、DSlowhttptest、DSlowloris、FTP、DHulk、SSH作为本文模型的数据集,其中70%用作训练集,20%用作验证集,10%用作测试集.网络流量类别和数量分布如图6所示,数据集是明显不平衡的,其中Normal、PortScan、DHulk、DDoS数据量是比较多的,其他攻击类别流量样本数量都较少,符合原数据集分布.
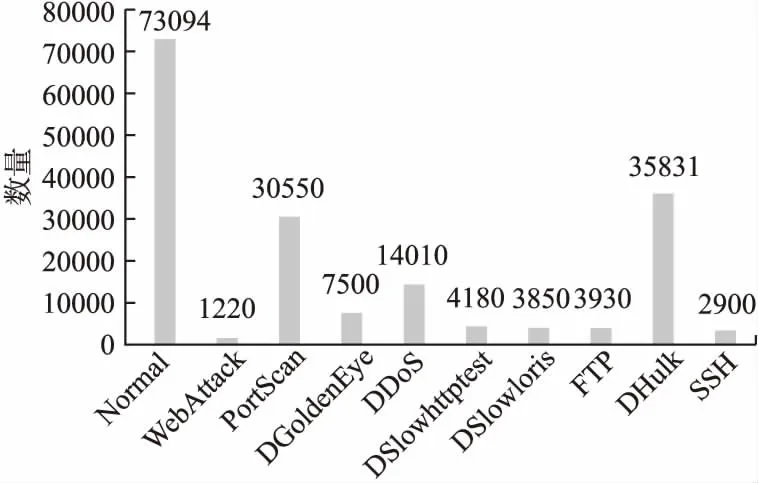
图6 CICIDS2017数据集流量种类和数量分布Fig.6 CICIDS2017 flow type and quantity distribution
因为网络的原始流量数据长度不同,所以不是模型的理想输入格式.CICIDS2017 数据集预处理有4个步骤,在这个过程中,本文将原始网络流量数据转换为IDX格式作为模型的输入.
数据预处理步骤如下:
步骤1.
流量切分:CICIDS2017原始数据集是一个大型PCAP文件,本文使用SplitCap工具将连续PCAP流量文件拆分为多个离散的流量单元,把具有相同五元组的数据合并到所有层的双向流中.这是王伟等人[18]评估基于深度学习的流量分类最理想的表示方式.
步骤2.
流量匿名化:对原始的 PCAP 文件进行匿名化操作,去除数据包中不相关的数据信息,例如数据链路层中一些与以太网相关的数据.
流量清理:删除重复和空的文件.
步骤3.
长度统一:使用缩减方法或归零方法将数据包的长度统一为784字节,当文件长度小于784字节在文件末尾添加0x00s,将其扩充为784字节.
步骤4.
IDX填充生成:将长度统一后的网络流量文件转换为即28×28 2-D IDX格式文件.IDX格式是深度学习中的一种常见文件格式,也是本文框架输入的理想格式,映射到[0,1],这些文件将被视为灰度图像.如图7所示,可以看到不同的网络流量经过预处理后,通过可视化后变成各种灰度图像,不同的网络流量纹理特征区分度比较明显.

图7 网络流量可视化结果图Fig.7 Visualization results of network traffic
5.3 评估指标
为了分析模型对每一类流量的检测精度,本文选择准确率作为模型的整体指标,并选择精确率、召回率和值作为每一类流量的分类指标.对于类流量,计算以下4个指标:
1)准确率(Acc):对于n分类的模型,表示正确分类的样本数量与测试样本总数的比率.计算见公式(9):
(9)
2)精确率(Pi):正确分类的正样本的比率.对于某一类的精确率的计算见公式(10):
(10)
3)召回率(Ri):正确分类的正样本与正样本总数的比率.对于某一类的召回率计算见公式(11):
(11)
4)F1值(F1i):精确度和召回率的加权平均值,某一类F1值指标计算见公式(12):
(12)
其中真阳性(TPi):表示预测的类别是i,真实的类别也是;假阳性(FPi):表示预测的类别是i,但真实的类别不是i;假阴性(FNi):表示预测的类别不是i,但真实的类别是i.
准确率是衡量了模型的一般分类效果,但并不是特定于某一类别的识别精度.对于本文来说,不仅是要关注一般的分类效果,还要关注特定类别的分类的效果.相比之下,精确率、召回率和F1值更注重评估模型在不同类别上的检测效果.使用上述指标为本文的模型提供了全面而客观的评估.
5.4 结果及分析
为了研究该模型在不平衡异常流量数据集上的检测攻击的能力,设计了3组消融对比实验,使用ResNet50、CBAM-ResNet和FL-ResNet作为对照组.在训练阶段设置不同epoch的学习率不一样.表2显示不同epoch的学习率设置.同时,在每个epoch的训练后,本文使用测试集对模型进行训练,并在模型学习过程中获得实际的精度.

表2 学习率随epoch变化Table 2 Variation of learning rate with epoch
为了体现模型的效果,本文采用控制变量的方法,不同的算法均在同一台机器上运行.避免准确率、精确率、召回率和F1值的随机性,每个模型本文取10次实验的平均值.
1)引入CBAM注意力机制的残差网络
模型CBAM-ResNet检测异常流量分类的各项指标如表3所示.在残差网络中仅添加了CBAM注意力机制,模型的准确率提高了5.73%,精确率提高了5.72%,召回率提高了5.7%,F1值提高了6.53%,这也证明加入CBAM注意力机制的残差网络可以从流量信息中提取更深层次的目标特征,从而提高模型分类的精度.
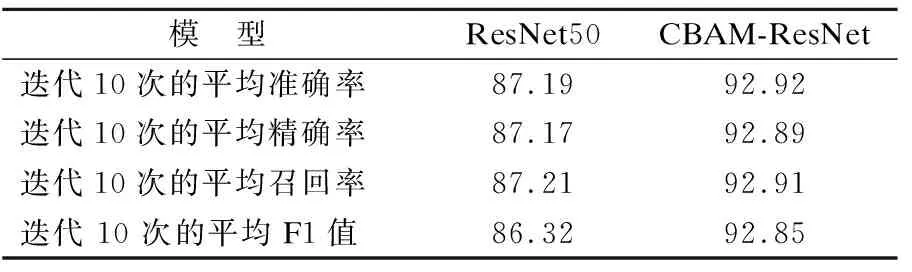
表3 CBAM优化结果比较(%)Table 3 Comparison of CBAM optimization results(%)
2)引入焦点损失函数的残差网络
模型FL-ResNet检测异常流量分类的各项指标如表4所示.用改进的焦点损失函数替换掉交叉熵损失函数的条件下,模型的准确率提高了8.6%,精确率提高了8.61%,召回率提高了8.57%,F1值提高了9.42%.相比传统残差网络,各项指标提高的原因在于把训练重点放在难分类的负样本上,使得分类的结果更加准确.
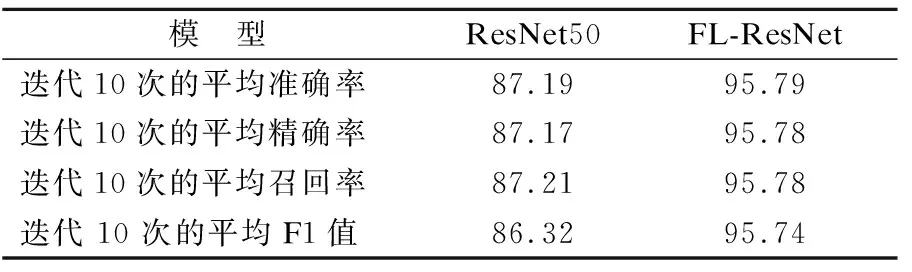
表4 损失函数优化结果比较(%)Table 4 Comparison of loss optimization results(%)
3)基于所有优化方式的残差网络
模型CBAM-FL-ResNet检测异常流量分类的各项指标如表5所示.CBAM-FL-ResNet的准确率比ResNet50准确率大幅度提高了12.1%,精确率提高了12.11%,召回率提高了12.09%,F1值提高了12.96%.依据多项指标的提升,证明了本文使用的多种优化方式对提高异常流量网络入侵检测分类的有效性.
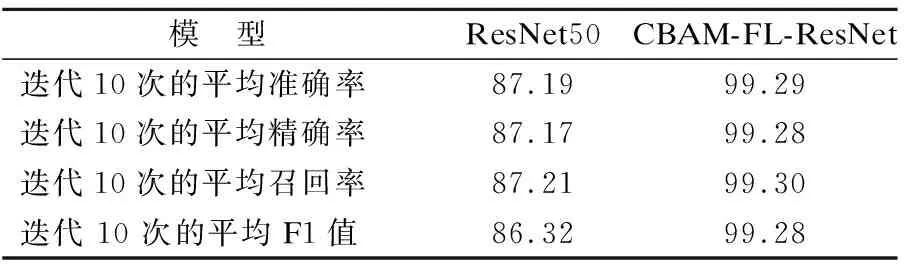
表5 所有优化方法结果比较(%)Table 5 Based on all optimization methods(%)
4)基线模型及对比实验在各类流量上指标对比
由于数据集不平衡会导致正常样本的数据是倾斜的,即使出现异常样本很容易被识别为正常样本的问题,但准确率仍然很高,因此准确率有时不能反映模型的真实性能.为了评估CBAM-FL-ResNet在异常流量入侵检测中检测攻击的能力,本文将其性能指标与基线模型LeNet5、Inceptionv3、DenseNet和GAN,还有消融实验的RestNet50、CBAM-ResNet和FL_ResNet作为对照组,以验证引入CBAM注意力机制和改进的焦点损失函数对异常流量分类的有效性.因此本文不仅对比了总体准确率,而且对比了每一类流量的精确率、召回率和F1值.
如图8显示了每个模型的总体精度,可以看到本文提出的模型的准确率是99.29%,是几个模型中准确度最高的.其中ResNet50比LeNet5的准确率高9.43%,说明残差网络因为比LeNet5网络层数的增加,所以可以更好地学习网络流量特征.因此,准确率有明显提升.Inceptionv3和DenseNet准确率分别有86.64%和93.6%,但数据集是明显不平衡的,导致整体准确率都并不理想.使用GAN过采样的方法生成超过30000个训练样本,以减少数据集的不平衡,因此也获得了96.84%的准确率.
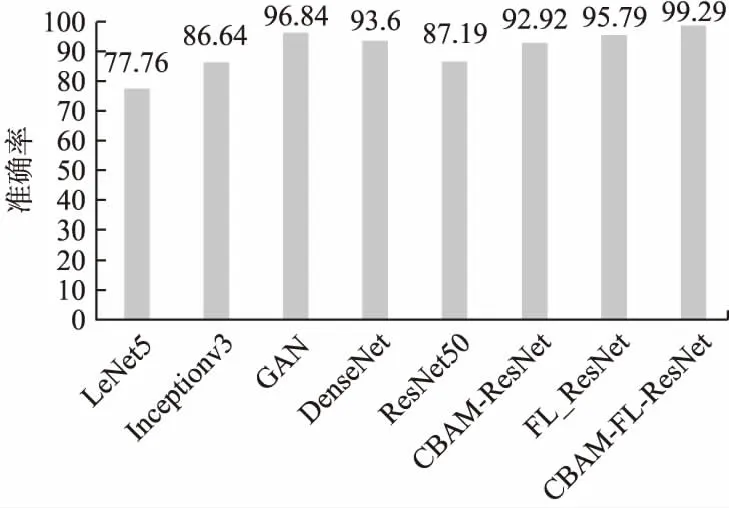
图8 不同实验的准确度Fig.8 Accuracy of different experiments
从表6、表7、表8中发现模型Inceptionv3和ResNet50在Normal、PortScan、DDos、DHulk样本数量较多的情况下,都有接近90%的召回率,但在WebAttack、DGoldenEye、DSlowloris样本数量较少时,这些异常流量类别的召回率几乎为0.也就是说,这些模型根本无法学习样本较少的异常流量的特征,导致小样本在异常检测中检测率较差.虽然DenseNet在小类别样本上召回率有改善,但是在DSlowhttptest、DSlowloris、SSH精确率还是较低,分别只有70%、53%、63%.GAN模型在小类别流量上均取得不错的效果,但都没有达到最优,同时由于新添加的样本造成模型需要消耗更多的时间和内存.

表6 10种类别流量精确率指标上的比较(%)Table 6 Precision of 10 categories of imbalanced traffic(%)
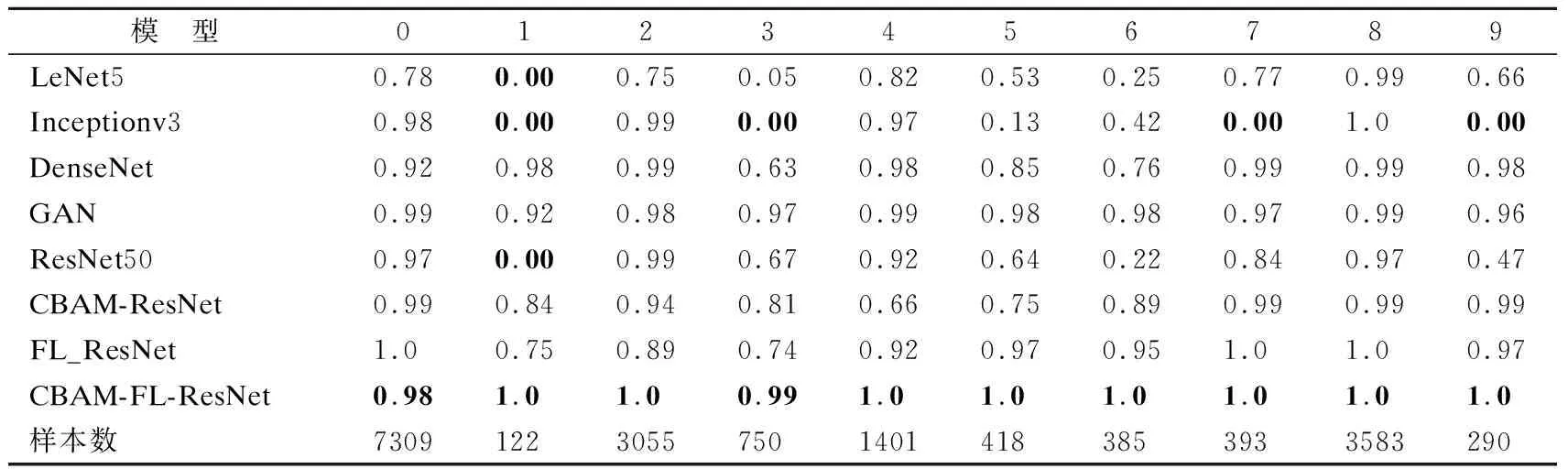
表7 10种类别流量召回率指标上的比较(%)Table 7 Recall of 10 categories of imbalanced traffic(%)
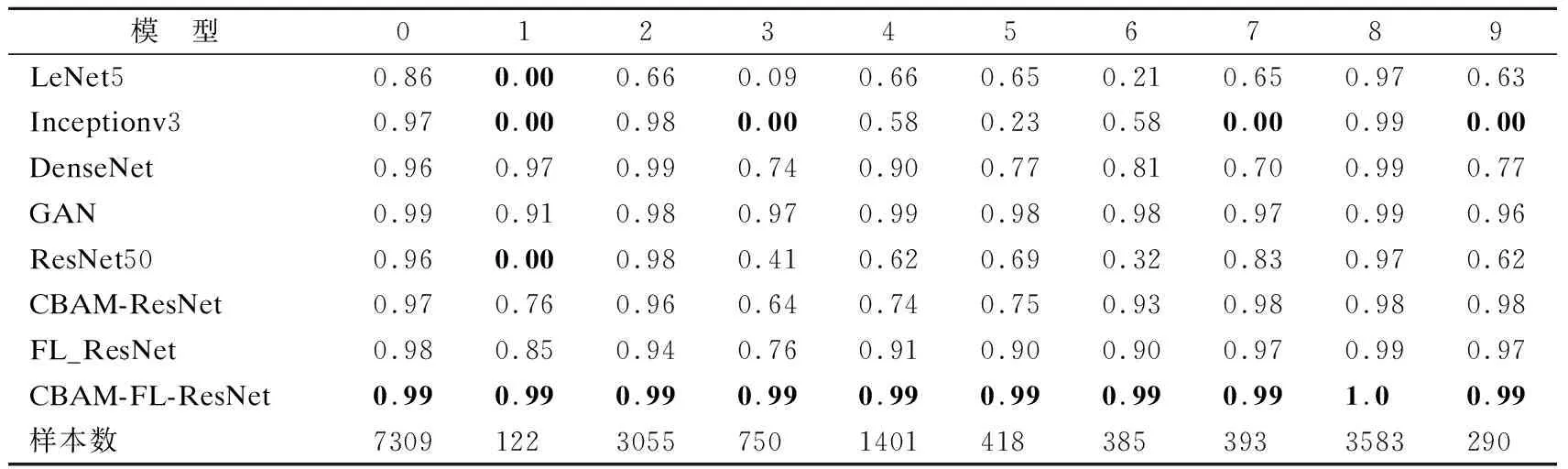
表8 10种类别流量F1指标上的比较(%)Table 8 F1-score of 10 categories of imbalanced traffic(%)
融合CBAM注意力机制的残差网络之后,WebAttack的精确率由原来的0%提升到69%,F1值由原来的0%提升到了76%. SSH的精确率由原来的47%提升到了97%,F1值由原来的62%提升到了98%,其他类别流量各项指标也有提升.这说明了使用通道注意力和空间注意力,分别强化层次特征中通道维度和空间维度的目标信息.因此CBAM-ResNet比ResNet50不仅是整体准确度的提升,而且在小类别样本上其他各项指标也有所改善.引入改进的焦点损失函数之后,WebAttack的精确率由原来的0%提升到98%,F1值由原来的0%提升到了85%.SSH的精确率由原来的47%提升到了98%,F1值由原来的62%提升到了97%,其他类别流量各指标也有明显提升.这表明焦点损失函数可以增强样本少且难分类的检测能力,适用于不平衡的数据集的分类.
本文提出的CBAM-FL-ResNet模型在每一类流量上精确率、召回率和F1值都有大幅度的提高,且各项指标平均在99%,尤其是对于小样本.由于训练集中的类别不平衡问题,其他模型的在4个指标上表现都不理想.与GAN模型相比,可以避免生成新数据的同时检测到更多攻击,这也证明了本文的模型优于其他模型,能够有效地识别各种异常流量攻击.
表6、表7和表8展示了所有模型在每个流量类别上的精确率、召回率和F1值.其中数字0~9分别表示流量:Normal、WebAttack、PortScan、DGoldenEye、DDoS、DSlowhttptest、DSlowloris、FTP、DHulk、SSH.
6 总 结
随着网络流量的快速增长和网络攻击的推进,使用更有效、更准确的入侵检测系统的需求变得更加迫切.本文提出了一种融合CBAM注意力机制、焦点损失函数和残差网络的方法应用于网络入侵检测.融合CBAM注意力机制的残差网络可以更好地提取流量的关键特征,改进的焦点损失函数来处理训练数据中存在的类不平衡问题.实验结果表明,本文提出的模型更容易训练,测试数据集的准确率更高.与其他模型相比,本文的模型不仅在总体准确率上取得99.28%,而且在小类别的网络流量上各项指标平均也都达到了99%.虽然取得了显著的结果,但这项研究仍有其潜在的局限性.本文的模型检测具有小类别攻击方面优于其他深度学习算法,但由于权重值降低,其检测某些优势类的性能有所减弱.因此,如何在不影响模型检测主要类别的情况下提高模型在次要类别上的性能,是未来需要解决的一个重要问题.此外,CICIDS2017数据集包含攻击类型还是相对较少.因为在网络入侵检测过程中对错误的容忍度较低,我们将结合其他数据集,以涵盖未来各种类型的攻击.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
中国交通信息化(2018年5期)2018-08-21
新校长(2016年8期)2016-01-10
河南科技(2015年8期)2015-03-11
商事法论集(2014年1期)2014-06-27
