
遗传算法与带权搜索融合的QoS组播路由算法
2023-12-13 01:39冯永新张文波
小型微型计算机系统 2023年12期
李 姝,冯永新,张文波
(沈阳理工大学,沈阳 110159)
1 引 言
随着网络技术的高速发展,快速增加的网络用户所使用的各类应用业务展现出了高并发、大流量、多任务等特征.组播是一种在一个发送者和多个接收者之间进行通信的方法,组播技术能够有效地满足单点发送、多点接收的需求,解决单播或广播在承载点到多点业务时存在的问题,已经广泛应用于众多行业应用场景中.
组播路由问题是组播服务的核心问题,服务质量(Quality-of-Service,QoS)是网络安全的有效保障机制,用于提供高质量的网络服务,组播路由技术与QoS紧密相关,QoS组播路由是在QoS约束条件下实现高质量组播服务的关键.组播的目标是在该连通图中找到一棵连接起始节点和目标节点的树,该树的Cost和最小,且满足Delay的约束.如图1所示,起始节点为1,目标节点集为{3,5,6},Cost(i,j),Delay(i,j)分别为节点i和节点j之间链路的开销值和传输时延值.QoS组播路由问题可以归结为组播树中计算各条边和节点开销值之和最小的分布树的斯坦纳树问题,其结果是NP完全问题[1,2].QoS组播路由问题是满足QoS约束的组播路由问题,因此可以将带宽、时延、时延抖动等QoS约束引入斯坦纳树问题中,构建出满足QoS约束且开销成本最低的组播树.

图1 网络拓扑图Fig.1 A network topology
在过去的研究中,最短路径树、斯坦纳树和最小生成树等传统算法在路由优化问题上效果并不理想,在实际的网络环境中,网络拓扑复杂性和动态性使得无法简单的通过构建数学模型来解决问题,而且使用严格的逻辑推理的确定性方法会使得计算量非常大,求解的组播树和最优值相差较大.因此,研究人员通过采用智能仿生算法和QoS组播路由优化问题相结合,提出了各种多约束QoS组播路由算法.然而,组播路由协议多主要关注QoS指标约束,并未充分考虑路由持续时间(LDT)和传输延迟之间的相关性,论文考虑了LDT和传输时延之间的相关性,保证组播树中链路的持续时间始终大于源节点的延迟时间,以达到提高路由稳定性的目标.另外,算法如侧重关注某一个通信参数,则对于通信环境和通信要求缺乏灵活应变能力;算法如关注多项通信参数,需同时计算多条不同的通信链路,进而大幅增加计算负担,甚至导致网络失效.针对以上问题,论文提出了一种基于遗传算法与带权宽度优先搜索融合的QoS组播路由算法,所提算法在不需要对全局网络链接信息进行额外的编码/解码的情况下,解决多约束条件下的QoS分组路由问题,因此可以有效降低计算负载、减少算法执行时间.
2 相关工作
研究人员将遗传算法(GA,Genetic Algorithm)、蚁群优化(ACO,Ant Colony Optimization)算法、粒子群优化(PSO,Particle Swarm Optimization)算法等仿生算法和QoS组播路由优化问题相结合,提出了各种多约束QoS组播路由算法,然而,组播路由协议多主要关注QoS指标约束,并未充分考虑路由持续时间(LDT)和传输延迟之间的相关性.Rajan C 等人[3]提出了一种基于遗传算法(GA)和粒子群优化(PSO)的混合遗传组播路由优化算法,并与多播AODV(MAODV)协议、基于PSO和基于GA的解决方案进行了比较.所提出的优化改进了抖动、端到端延迟和分组传输比(PDR),具有更快的收敛速度;Wei等人[4]面向自组织网络的多约束组播路由问题,提出以进化算法(EA)和蚁群算法(ACA)为基础的QoS多播路由算法(EA-ACA-QMRA),在端到端延迟和分组传递率方面具有比传统ACA更高的精度和更快的收敛;Rama A等人[5]提出了一种基于分数布谷鸟搜索的移动自组网 QoS 感知路由的多路径选择方案,通过考虑诸如能量、链路寿命、距离和延迟等 QoS 约束;崔玉胜[6]还提出一种基于 FFO 算法的 QoS 组播路由性能优化模型,引入随机嗅觉搜索策略和概率视觉灵敏性定位策略进行算法优化并利用果蝇味道浓度判定函数求解组播路由问题;尹凤杰等人[7]提出了一种基于改进蚁群算法的 QoS 路由算法,用蚁群算法的正反馈特性提升算法搜索特性,对算法进行优化改进以提高其收敛性和随机搜索性,保证了多约束QoS 路由寻优能力,并提升了寻优效率;卢毅等人[8]将免疫克隆算法与传统蛙跳算法相结合,所提算法在QoS约束下避免了局部最优,降低了数据在传输路径上的能量损耗;王莎莎[9]提出一种基于自适应机制的量子遗传算法,证明了所提算法在收敛性和全局优化能力上均具有较好的性能,将其应用于解决基于网络编码的组播资源优化问题取得了一定效果;毛薇[10]针对LEO卫星网络拥塞问题,提出基于蚁群与遗传联合优化算法的组播路由算法,以实现拥塞规避和节省带宽最优的目标;杨海[11]面向无线网络的组播路由优化问题,提出了一种采用二进制编码和灰狼优化算法的组播路由策略,其方法在时间复杂度相当的情况下具有较强的算法稳定性;N.Papanna等人[12]基于自适应遗传算法提出了一种高效的生命周期感知组播(EELAM)路由选择策略.在众多研究中,遗传算法广泛应用于解决各种 NP 问题,其在进行 QoS 组播路由选择时,具有较好的全局寻优的能力.然而,在交换部分亲本染色体形成新染色体时,新树的合法性难以维护/修复,极易出现环路和目标节点缺失的情况,交叉机制采用Prim[13,14],Dijkstra[15]为代表的最短路径算法可以确保子代树的连通性.但是贪婪算法需要全局网络链路信息,复杂度较高.由于无线组网的动态拓扑特性,这些要求降低了集中式路由方案的有效性.为了解决以上问题,论文提出了一种基于遗传算法与带权宽度优先搜索融合的QoS组播路由算法,对所有通信节点进行初始化处理,其次计算整个样本种群的适应度,之后判断是否达到最大优化代数,达到最大进化代数可确认得到最优解,否则进行遗传操作,以得到第1条链路,同时利用带权宽度优先搜索方法,得到第2条链路,对两条链路进行选择,根据链路的带宽、时延和丢包率3个参数,设定每个参数权重,分别计算两条通信链路的权重计算方程结果,取结果值的链路进行网络通信.
3 本文算法
本文设计的基于遗传算法与带权宽度优先搜索融合的QoS组播路由算法,既可以保证确定不同的备用QoS路由通信链路,也可以根据当前网络环境,根据不同网络参数权重,选择最佳通信链路.其流程如图2所示,包括3部分:遗传算法得到链路L1,利用带权宽度优先搜索方法所选择的链路L2,需要对链路L1与L2进行差异化对比,重复此步骤直到达到筛选阈值.

图2 算法流程图Fig.2 Algorithm flow chart
3.1 遗传算法
3.1.1 遗传编码
对于目标网络利用遗传算法取得第一QoS通信链路,本文在使用遗传算法时,使用特定的网络节点进行编码,编码是设计一个性能良好的遗传算法的关键.许多表示方法,如一维二进制码、Prüfer数字和序列和拓扑编码(ST编码),已经被开发出来.然而,这些表示很可能生成非法树(如ST编码),或局部性差(如Prüfer数字),或效率低,所需的搜索空间随着网络规模的增加而显著增加(如一维二进制码).
本文的编码策略是对所有的通信节点,将任意相邻通信节点进行连接,按照最短欧氏距离连接构成分支通信链路并赋值,可直接连接的分支通信链路赋值为1,不能直接连接的赋值为0;进行适应度计算处理,将赋值为1的分支通信链路去除,并将欧氏距离排名第2短的节点连接,构成新的分支通信链路,可直接连接的分支通信链路赋值为2,不能直接连接的赋值为0;
设计网络节点筛选算子、交叉算子和变异算子,取得符合适应度要求的网络节点,并将这些网络节点连接,按照欧拉距离排序,选择整条QoS通信链路中欧氏距离最短,作为第一通信链路.
如图3所示,对整个网络系统中的节点间通信通路进行编码,并且选择两个通信节点之间的最短通信链路建设通信链路,对于可以进行直接通信连接的两个节点,其通信链路编码状态显示为“1”,不能进行直接通信连接的两个节点,其通信链路编码状态显示为“0”,其中编码状态为“1”的链路定义为非劣解.
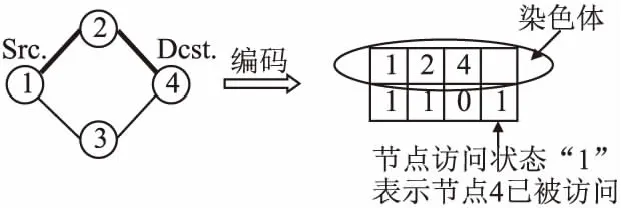
图3 通信通道编码Fig.3 Coding of communication channel
进行适应度计算处理,基于信链路编码的情况下,去除所有通信链路中编码状态为“1”的链路,即去除通信链路中的所有非劣解,之后对剩余的节点进行通信链路的连接,对于连接后链路最短的路径,对其赋予权重“2”,即第二批非劣解的权重为“2”,并以此类推,直到所有的节点之间都可以经过通信节点之间的链路连接,使得所有的通信链路节点均可以分配一个权重值.
3.1.2 初始化族群
对整个节点种群进行分解,从而得到不同的子群体,在子群体间设置共享函数,如下:
(1)
其中,α数值为1,lij为节点i和j间距,σs为网络允许的共享程度贡献参数,对于参数lij的确定方法为:
(2)
其中p表示共享空间中,解码空间的p维空间欧拉距离中被编码的参量数目,xk,i和xk,j表示欧拉距离共享空间中的解码后变量.
对于参数σs的确定方法为:
(3)
其中r表示半径为σs的p为超球面体积,q为欧拉距离共享空间内优化搜索的波峰数目,xk,max表示欧拉距离共享空间中的解码最大值,xk,min表示欧拉距离共享空间中的解码最小值.
3.1.3 算子交叉与适应度选择
对于个体适应度的选择中,其中对于相同权重的非劣集的个体适应度相同,此时需要按照比例参数选择,计算方程为:
(4)
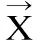
选定算子之后,进行交叉算子处理,其方法为,选取一个个体Xi,同时需要定义“自适应退避选择概率”,其计算方法为:
(5)
其中,|N|表示群体中的个体数量,|Mw|代表权重值为k的非劣集中个体数量.而对于和其交叉的个体Xj,对于选择方式,则按照如下方程选定:
(6)
3.1.4 收敛性优化及Pareto最优解
为了可以提高算法收敛速度,本文采用贪心交叉算子,该算法引入“家族竞争”方式选取两个个体,其中,对于两个个体的选取方程组为:
(7)
之后将v1赋给Xi(n+1),并从节点v1开始查找方程组(7)中v1的紧邻节点v2和v′2,并从中查找最优Pareto最优解,并将优胜解赋值给Xi(n+1),访问向量中该点的访问状态数值置为1.
所谓Pareto最优解为:对于集合A为可行解集Xf中的一个子集,决策向量x∈Xf为非劣的当且仅当不存在a∈A:a>x,即当且仅当x在Xf中是非劣的,决策向量x才是Pareto最优解.
在确定了最优解之后,需要进行对优胜点的后续邻接点连接,此时在Xi(n)和Xj(n)中进行节点处理,对于经过比较而得到的新优胜点,将该优胜点访问状态设置为1.并进行重复运算,对节点进行标定.
交叉算子描述为:
(8)
其中,l1和l2代表Xi和Xj的染色体长度,pc为交叉概率,Tc(Xi,Xj)代表对节点Xi,Xj的适应度,P{Tc(Xi,Xj)}代表节点Xi,Xj的交叉结果.
在进行了交叉处理之后,还需要设置变异因子,采用随机点变异方案,其方程为:
(9)
其中,d(X,Y)为个体X和Y中配对的基因对数目,pm为变异概率,Tm(Xi,Xj)代表通信节点Xi,Xj在含有变异情况下的适应度,P{Tm(Xi,Xj)}代表通信节点Xi,Xj在含有变异情况下的交叉结果.
3.2 带权候选通信链路
1)将QoS通信链路的状态概率,和设定的通信链路状态概率阈值比较,并根据QoS通信链路状态概率从大到小排序,将排序为第1和第2的QoS通信链路分别命名为第2的QoS通信链路和第3的QoS通信链路.
本文确定分支通信链路可用性步骤如下:
计算任意两个通信节点i和j的加权参数,对于分支通信链路的任意两个节点i和j,计算这两个节点分支通信链路的参数,其中涉及4个参数,即带宽、时延、丢包率和时延抖动,并设定包括这4个参数的带权比较方程,比较方程为:
C=alnW+blnD+clnL+dlnJ
(10)
其中,C代表带权比较方程的结果,W、D、L和J分别代表分支通信链路的带宽、时延、丢包率和时延抖动,a、b、c和d分别代表以上4个参数的权重,另外,由于在通信网络网络中,带宽为限制性参数,因此可在带权分支链路的正式选择之前,对带宽W设定比较阈值,如:带宽参数小于100k的链路去除,则整个网络路由的稳定性提升.
2)在得到了所有分支通信链路之后,需要设定带权比较方程因变量C的阈值,去除整个网络内综合通信质量低于C的分支通信链路,并将所有的分支通信链路连接.
确定整个网络内各个链路之间的状态概率,同时要分析节点i的失效率和修复率,此时就要分析该节点i的可用性,计算方程为:
(11)
其中,μi和γi分别表示节点i的失效率和修复率,Ui表示节点i的不可用性,在假定第一个节点为可用状态的情况下,则第1和第2个节点分支通信链路处于工作状态的概率计算方程为:
(12)
其中,θi1-i2代表进行通信连接的两个通信节点,即分支通信链路的概率计算方程,μi1和μi2分别代表两个通信节点的失效率,γi1和γi2分别代表两个通信节点的恢复率.同时设置分支通信链路工作状态概率结果θi1-i2的阈值,并将得到的各个分支通信链路工作状态概率结果和该阈值比较,低于该阈值时,则该分支通信链路被从整个通信网络中删除.
对于假设整条通信链路可用的情况,其运行概率方程为:
(13)
其中,θ代表整条通信链路的运行概率,m代表节点数量,μi和γi分别表示节点i的失效率和修复率,Ai表示节点i的可用性.
对得到的QoS通信链路状态概率排序,并求取链路状态概率均值作为阈值,QoS通信链路状态概率低于该阈值的通信链路认为不合格,在QoS通信链路集合中删除处理,得到整条QoS通信链路,按照链路状态概率由大到小排序,选择排序为1和2的整条QoS通信链路命名为第2、第3的QoS通信链路.
3)比较第1条QoS通信链路和第2条QoS通信链路的分支通信链路是否完全相同.在经过链路状态概率由大到小排序的处理之后,剩余的链路空间内链路都是可用,或者说符合设定阈值标准的,此时需要在剩余的链路中进行最佳链路选定,此时采用的方法是,对于所有可用链路的最终运行概率进行比较,从中选择最大值,并将其作为最终结果.
4)计算基于遗传算法和带权宽度优先搜索方法取得QoS通信链路安全性方法为,计算取得第1条和第2条QoS通信链路的运行状态概率.实际上,在依靠步骤3选定了链路L2之后,该链路有可能和基于遗传算法的QoS路由寻路算法所选取的链路L1相同,那么此时就需要对链路进行差异化对比,如若确定这两条链路完全相同,则对于利用带权宽度优先搜索方法所选择的链路L2过程,返回排序后进行选择,具体的,可选择最终运行概率最值中排名第2高的链路B2进行选定,并将该条链路认定为该情况下的最优通信链路.
5)对于取得的两条链路,经过利用带权宽度优先搜索方法和基于遗传算法的QoS路由寻路算法两个阶段的选路操作中,最终得到的两条链路势必不同,但是在不同的网络环境和需求下,对于通信链路的本身要求也很可能具有不同,在此选定3个参数进行取值,选择得到σ结果更大通信链路.其中,对于权重参数α、β和δ,可依据实际通信需求进行调整,择优选择使用的通信链路.
取得的QoS通信链路安全性、带宽和分支链路参数带入可变权重的加权计算方程,选择两条QoS通信链路中的最佳QoS通信链路方法为,建立加权比较方程,该方程如下:
σ=αlnμ+βlnθ+δlnm
(14)
其中,σ代表QoS通信链路的评定数值,μ代表整条QoS通信链路的带宽,m代表QoS通信链路的分支链路数量,θ代表整条QoS通信链路的运行概率,α、β和δ分别代表实际带宽和网络总带宽的比值权重、整条通信链路的运行概率权重和通信链路的分支链路数量权重;根据两条QoS通信链路的评定数值,取通信链路的评定数值σ较大的链路为最优链路.
3.3 最优链路选择
依照3.1小节与3.2小节所述原理,最优链路选择可分为遗传算法通信链路获取模块、带权宽度优先搜索通信链路模块、通信链路比较模块和通信链路选路模块.
1)遗传算法通信链路获取模块,用于对网络节点利用遗传算法取得第1条QoS通信链路;
2)带权宽度优先搜索通信链路模块,用于对于同一个网络,利用带权宽度优先搜索方法取得第2条QoS通信链路、第3条QoS通信链路;
3)通信链路比较模块,用于比较第1条QoS通信链路和第2条QoS通信链路是否完全相同;若完全相同时,则将第3条QoS通信链路作为第2条QoS通信链路;
4)通信链路选路模块,用于分别根据第1条QoS通信链路和第2条QoS通信链路,取得QoS通信链路安全性、带宽和分支链路数量;根据QoS通信链路安全性、带宽和分支链路数量参数,对同一个网络中得到的第1条QoS通信链路和第2条QoS通信链路进行对比,得到最佳通信链路.
4 实 验
本节中基于本文所提算法在仿真条件下,对算法的收敛延迟变化,平均成功率(SR),平均代价以及运行时间进行了验证.实验中将上述指标的评价与最短延时组播路由算法(LDT)作为参考,因为其获得的最小延时组播树是由组播源点与各组播 终点的最短延时路径组成,在所有延时约束的组播路由算法中其路由请求的平均成功率最高.
在仿真实验中,主要测试算法的收敛能力,对于一个20个节点的确定性加权网络拓扑进行实验,如图4所示,图中的边中加权值三元组为:(带宽,代价,延迟).选定源节点为节点0,目的节点为(18,19),遗传算法以及网络拓扑的参数设置如下:pm=0.05,pc=1,Np=20.Np为实验节点数目,pm为公式(9)遗传变异概率,pc为公式(8)中遗传交叉概率.图5显示了在延迟阈值设置为18下本文算法的收敛过程.由图5可知,本文算法能够在8代以内收敛到满足延迟约束且成本较低的解.图6表明,该算法的代价小于LDT算法.
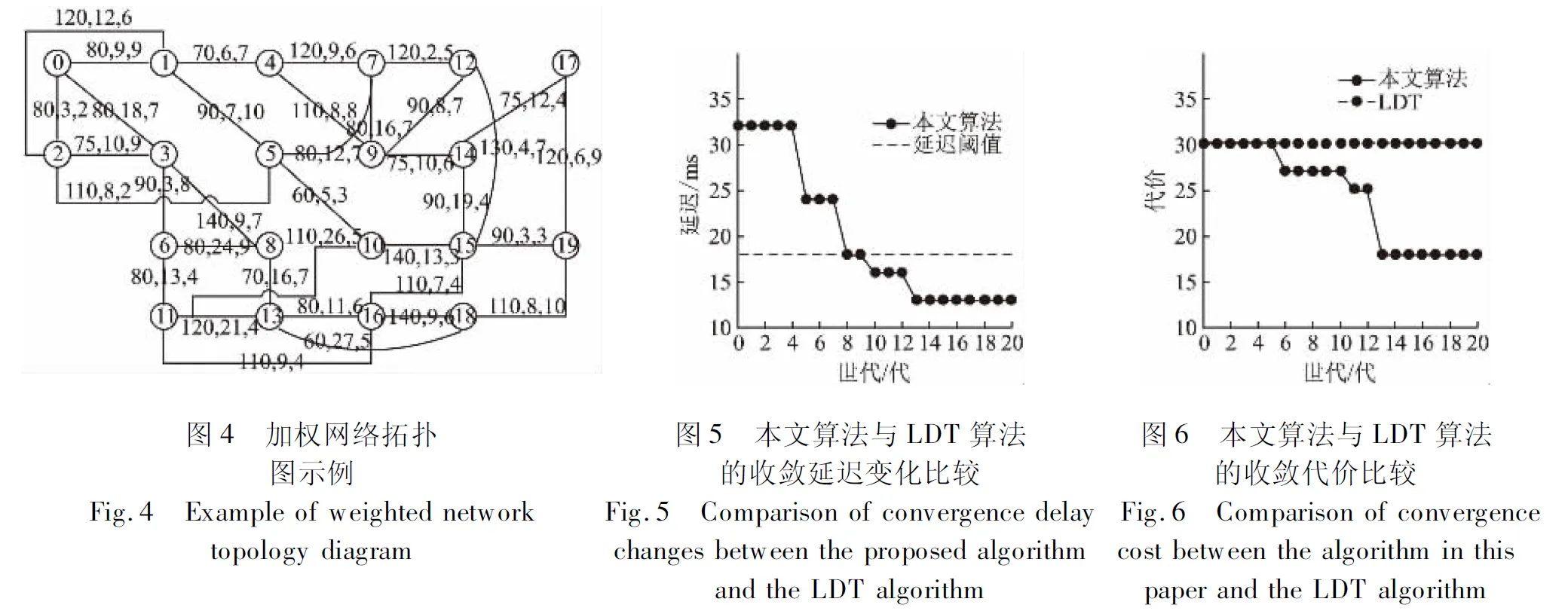
图4 加权网络拓扑图5 本文算法与LDT算法图6 本文算法与LDT算法图示例的收敛延迟变化比较的收敛代价比较Fig.4 Example of weighted network Fig.5 Comparison of convergence delay Fig.6 Comparison of convergence topology diagramchanges between the proposed algorithmcost between the algorithm in this and the LDT algorithmpaper and the LDT algorithm
5 总 结
本文通过引入一种设计节点权值的交叉机制和带权宽度优先搜索,实现了一种新的选路方法.该方法在不需要全局网络链接信息、额外的编码/解码和修复过程方面优于现有的交叉机制.实验结果验证了组网的有效性和遗传算法的有效性.仿真研究表明,与现有的其他选路算法相比,本文所提算法可以获得更好的QoS路由,并大幅减少了执行时间.
未来将进一步围绕路由树的编码与交叉衍化,优化完善遗传算法,并将带权图优化的思想带入新的实验.同时,面向移动自组织网络优化调整本算法,以适应自组织网络场景.不断完善QoS寻路体系.从而在能源消耗,通路稳定等方面为通信路由做出贡献.
猜你喜欢
纺织科学研究(2023年9期)2023-10-23
移动通信(2021年5期)2021-10-25
学生天地(2019年28期)2019-08-25
网络安全和信息化(2018年3期)2018-11-07
数学物理学报(2018年1期)2018-03-26
中国交通信息化(2014年3期)2014-06-05
电测与仪表(2014年16期)2014-04-22
计算机工程(2014年6期)2014-02-28
河南科技(2014年5期)2014-02-27
自动化与仪表(2014年10期)2014-02-26
