
基于双向注意力和类生成器的小样本文本分类
2023-12-13 01:39朱小飞
小型微型计算机系统 2023年12期
王 婷,朱小飞,唐 顾
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
文本是大数据时代分布最广、体量最大、最易获取的信息载体,如何从大规模的文本数据中抽取出有价值的知识是当前亟待解决的难题.文本分类(Text Classification)是自然语言处理(Natural Language Processing,NLP)领域一个经典的任务,过去,研究人员采用人工手动对文本提取特征进行分类,但是伴随着移动互联网络的发展,文本数据呈爆炸式增长,利用人工手动对文本数据进行标注分类的方式因其耗时长且易受到标注人的主观认知影响而被舍弃,转而利用机器实现对文本数据的自动标注.传统的机器学习方法[1]主要通过人工提取特征构成特征向量,再采用支持向量机[2]、朴素贝叶斯[3]、决策森林[4]等算法从大量训练数据中学习分类器,利用分类器对待标注的文本数据进行分类,但此方法依赖于人为设计的规则和功能,同时该方法忽略了文本数据中的上下文信息,使得建模文本的语义信息变得困难.随着大数据时代的到来,基于深度学习算法的文本分类模型取得了巨大的进展,文本分类任务的准确率不断提升.与传统的方法相比,深度学习算法能够建模文本语义表示,解决计算和数据的局限性,显著提高文本分类的准确率.具有代表性的模型结构有3种:1)基于卷积神经网络[5](Convolutional Neural Networks,CNN);2)基于循环神经网络[6](Recurrent Neural Network,RNN);3)图神经网络[7](Graph Neural Network,GNN).
虽然上述方法取得了重大进展,但是它的成功主要依赖于现有的大量有标签数据,然而在现实生活中,大量的有标签数据是不便获取的,所以这极大地限制了文本分类技术的发展与应用,因此,本文开始探索如何在已有少量标注样本的情况下进行文本分类.
近几年来,小样本文本分类问题受到专家学者们的关注,逐渐成为业界重要的研究方向.所谓小样本文本分类方法,其根本目标是希望机器能够像人类一样仅通过学习少量样本特征就能够实现准确的文本分类.现有的小样本分类方法主要分为以下5种:元学习、数据增强、图神经网络、提示学习和度量网络.基于元学习的小样本分类方法旨在学习一个通用的模型,使得这个模型在面对新旧任务时都可以在很少的梯度下降后达到较优解,其中最具代表性的是Finn[8]等人在2017年提出的一种通用的元学习框架(Model-Agnostic Meta-Learning,MAML),虽然该类方法较为简单,但在实际应用中目标数据与源数据之间存在差异可能会导致过拟合现象.基于数据增强的小样本分类方法是指借助已有的少量有标签样本,生成更多的增强数据用于训练,缓解样本不足的情况,帮助模型更好的进行训练,常用的生成式方法有生成对抗网络[9]和自训练[10],但由于其生成了新的数据所以可能会引入噪声反而降低模型的分类准确率.基于图神经网络的小样本分类方法旨在借助图神经网络的消息传递思想将有标签样本的标签信息传递至无标签的样本上但其存在模型复杂度较高的问题.基于提示学习的小样本分类方法旨在通过构造提示模板和标签映射向输入增加“提示信息”,从而提升小样本分类的准确率,但其依赖于人工设计的模板与标签词,换言之,选择不同的模板与标签词都会对实验结果造成影响且该方法更适用于文本输入较短,包含类别数较少的英文数据集[11].基于度量学习的方法直观易懂,其核心思想是在同一个嵌入空间中,通过给定的距离度量函数测量支持集与待分类的测试样本间的距离,以此来进行分类,距离相近则说明样本同属于一个类别,间隔较远则说明不属于同一类.常用的距离函数[12]包括欧几里得度量、皮尔逊相关系数、余弦相似度等.其中基于度量网络的小样本分类方法是本研究的基础与重点,具体研究内容将在第2节阐明.经典的度量网络结构有4种,分别是:双生神经网络[13](Siamese neural network),匹配网络[14](Matching network),原型网络[15](Prototypical network)以及关系网络[16](Relation network).双生神经网络由两个相同结构、共享权值的神经网络连接而成.当训练样本与测试样本组成一对作为输入,分别通过两个神经网络后会输出其高纬特征向量表示,通过比较两个表征之间的距离来衡量两者的相似度,两个样本同属一类则标注为1,否则标注为0.双生神经网络并不是对输入进行分类而是进行区分,通过计算损失函数,最小化同类样本损失实现分类.随后,匹配网络被提出,Orid Vinyals等人[14]设计了一个通用的end-to-end的网络框架,结合LSTM和注意力机制来捕获样本的表征,再使用余弦相似函数度量查询样本与支持样本之间的相似性,实现小样本分类目标.在训练阶段,模型要求支持集和查询集的数据分布必须相同,在训练的时候让匹配网络只学习每一个类别的少量样本,保证和测试过程的一致性.当标签分布存在较大误差时,该方法的分类效果会大打折扣.2017年,另一种适用于小样本文本分类的网络架构-原型网络[15]被提出,该网络能够应用于不同的小样本数据集,是一种简单、高效的小样本的学习方式.原型网络的目标是学习到一个向量空间来实现文本分类任务,它的主要思想是先将所有的样本通过映射至低维的向量空间中,再对同属一个类别的多个样本求均值作为类别原型表示,针对每个待分类的查询样本,采用欧氏距离计算类别原型与查询向量之间的距离来确定分类结果.与以往固定的度量方法不同,FloodSung等人[16]进一步研究了一种可迁移的深度度量网络-关系网络,整个网络由两部分组成,第1部分是特征提取模块,用于提取样本的特征信息,第2部分自适应度量模块,通过输出查询集特征信息与各个支持集特征信息之间的相似性得分,从而判断是否同属于一个类别.
目前通过各种途径,已有一些方法实现了在小样本场景下完成文本分类任务.尽管这些方法取得了一定的成效但是仍然面临着以下挑战:首先,有效标注样本数量少,文本语义稀疏,上下文信息未被充分挖掘,特异性表征提取不到位;其次,以往的研究大多忽略了支持样本与查询样本之间存在匹配信息且在各自的信息提取中忽略了特征间的重要性程度不同,最后,原始的原型网络模型难以生成更具区分性的类别原型表示,为解决上述问题,本文提出了一种新的小样本分类方法.
针对传统的网络结构无法捕获文本深层的语义信息且无法有效提取样本的重要特征,设计了一个嵌入注意力机制的双向循环神经网络(Bi-AGRU)作为特征提取器,同时考虑到支持集与查询集之间存在交互信息且在各自的信息提取中忽略了特征间的重要性程度不同,因此提出了融合支持样本和查询样本的双向注意力网络,除此之外,由于小样本学习场景中缺乏标注样本,所以如果同一类中支持样本之间的距离较远,则难以捕捉它们的共同特征并生成具有代表性的类别原型,如果不同类的支持实例在特征空间中彼此接近,则生成的原型是无法区分的,因此构造了一个结合双向LSTM和注意力机制的类生成器,通过非线性映射使原型向量的生成不易受到支持集中噪声的影响,并设计了原型感知的正则化项对模型进行优化.
综上所述,本文的主要创新点与贡献点如下:
1)提出了一种新的小样本文本分类模型(Few-shot classification model based on bidirectional attention and class generator,简称BACG-FC模型),结合注意力机制的局部细节学习能力和门控循环单元的序列建模能力对文本进行特征提取,使得模型可以全面建模文本的深层语义信息;
2)构建了双向注意力网络,通过从query2support和support2query两个方向上计算注意力来获取支持样本与查询样本间的交互信息;
3)提出了一个由双向长短期记忆网络和注意力机制构成的“类生成器”,用以更好地划分类别界限,生成更具区分性的类别表示;
4)将本文提出的模型分别应用于ARSC和FewRel数据集,均取得了比目前最优基线模型更好的分类效果.
2 BACG-FC模型
本节详细介绍了所提模型的具体实现过程,包括问题的定义、整体模型架构以及各模块的细节说明.首先模型的输入是多个支持样本和查询样本,通过词嵌入模块获得样本的固定词嵌入表示,再在双向门控循环单元的更新门中引入注意力分数,替换原始的更新门,得到Bi-AGRU,借助其捕获对应的文本级特征表示,之后使用双向注意力网络融合支持集与查询集的匹配信息,得到支持感知向量表示和查询感知向量表示,将原始特征向量与支持感知向量或查询感知向量进行拼接融合,得到最终的支持样本特征表示和查询样本特征表示,然后采用带有注意力机制的双向LSTM作为类生成器,生成更具代表性的原型表示,最后度量查询样本与类别原型之间的相似性实现小样本文本分类.整体架构如图1所示.

图1 基于双向注意力和类生成器的小样本分类模型Fig.1 Few-shot classification model based on bidirectional attention and class generator
2.1 问题定义
本文将数据集D分为训练Dtrain集和测试集Dtest,其中训练集和测试集所包含的样本类别各不相同,两者都有各自的标签集合Ytrain和Ytest.针对小样本分类问题,其旨在训练出一个可以从Dtrain中学习先验知识的分类器,学习过程主要分为两个阶段:元训练和元测试.元训练阶段需从同一任务分布中划分出多个元子任务Ti,再从训练集Dtrain中随机抽取包含N个类别,每个类别K个样本,一共N×K个样本的子集S进行训练,然后将来自Ti的N个类别上的剩余样本作为测试集Q进行测试,为避免引起混淆,将元子任务中的训练集定义为“支持集”(support set),测试集定义为“查询集”(query set).
2.2 特征提取模块
特征提取模块包括单词嵌入模块和上下文编码模块.假设支持集和查询集中每个文本都包含T个单词,在单词嵌入模块中,本文使用GloVe[17]预训练词向量获取每个单词的固定嵌入表示,表达式如下:
xi=f(wi)
(1)
其中,f表示映射函数,wi表示文本中的第i个单词,xi∈Rd为经过映射后的第i个单词的向量表示.第k个支持样本表示为Xk=[x1,…,xT]k∈RT×d,查询样本表示为Q=[q1,…,qT]∈RT×d.

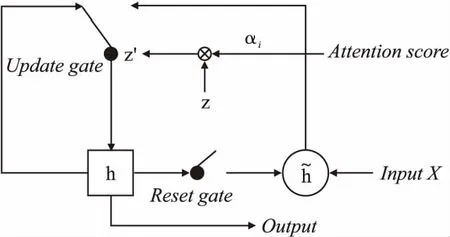
图2 AGRU结构图Fig.2 Structure of AGRU
Uk=WKk+b
(2)
αK=softmax(Uk)
(3)
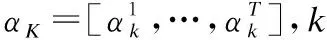
zt=σ(Wz[ht-1,xt])
(4)
(5)
τt=σ(Wr[ht-1,xt])
(6)
(7)
(8)
(9)


(10)
(11)
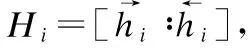
Sk=BiAGRU(Xk)
(12)
(13)
2.3 双向注意力网络
双向注意力层考虑查询样本与每个支持样本间的匹配信息,以交互的方式对它们进行编码,从support set到query set和从query set到support set两个方向上计算注意力.双向注意力计算的前提是得到一个共享的词级相似性矩阵M∈RTq×Tk,这个相似性矩阵的含义是计算查询样本与第k个支持样本之间的逐词相似度,该矩阵计算公式如下:
(14)
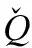
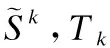
(15)
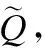
(16)
然后融合每个支持样本和查询样本的原始特征表示和感知向量表示.针对支持样本,其融合表示为式(17),其中,g(·)表示ReLU.
(17)
针对查询样本,其融合表示为式(18),其中,W是一个可训练的参数矩阵,[∶]为拼接操作,⊙表示哈达玛积,g(·)表示ReLU.
(18)
2.4 度量网络模块
度量网络模块是基于原型网络进行改进优化的.传统的原型网络先通过对每个类的支持集样本求取均值得到类别原型表示,再通过计算查询样本与每个类原型之间的距离来实现分类的.但是考虑到传统方法生成的类别原型向量易受到支持集中个别噪声数据的影响而丢失准确性,且每个支持样本对于类别原型的贡献程度是不同的,因此在计算类别原型时采用融入注意力机制的双向LSTM作为类原型生成器以获得更具代表性的原型表示(如图3所示),再通过度量类别原型与查询样本之间的距离,实现文本分类.
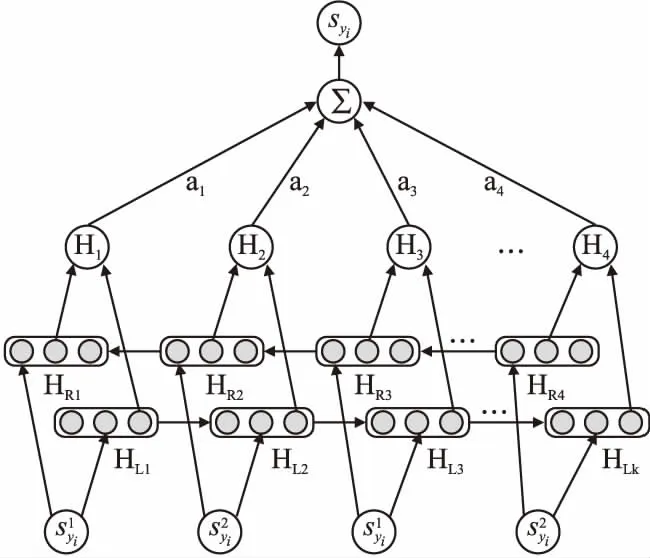
图3 类生成器结构图Fig.3 Structure of class generator

(19)
(20)
(21)
(22)
(23)
其中,N表示支持集的类别数,K表示支持集的样本数,maxpooling(·)表示最大池化,v、W为可学习的超参数,[∶]为拼接操作.
在训练过程中,采用交叉熵损失[18]lossTi来优化模型,Q表示每个训练轮次中采样的查询集,|DQ|表示查询样本的数量.除此之外,本文还设计了一个原型感知的正则化项lossproto来进行优化,使得类内距离更为接近,类间距离更为疏远.具体公式如下:
(24)
(25)
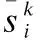
L=lossTi+βlossproto
(26)
3 实 验
本节介绍了研究过程中所使用的2个小样本数据集、实验环境的配置信息、超参的设置详情及评价指标,并对2个数据集上的实验结果进行了分析.
3.1 实验数据集
为了验证所提方法的有效性与适用性,本文在2个公开数据集上进行了对比实验,两个实验数据集的统计信息如表1所示,Dataset表示数据集,Num.train表示训练样本数,Num.test表示测试样本数,Vocab size表示词汇数量,Avg.len表示文本的平均长度.

表1 数据集统计Table 1 Dataset statistics
亚马逊评论情感分类数据集[19](Amazon Review Sentiment Classification,ARSC)由Yu等人提出,该数据集由23种亚马逊商品的评论数据组成,针对每一种商品,构建了3个具有不同评分阈值的二分类任务,评分阈值分别设置为5星、4星和2星.基于此,共构建了69个分类任务,为了进行评估,本文从4个领域(书籍、DVD、电子产品、厨房)中选择12个任务作为元测试集,其余57个任务作为元训练集[20].对于目标任务,创建了2-way 5-shot学习问题.
实体关系抽取数据集[21](Few-shot Relation classification,FewRel)覆盖了100种关系,每种关系700个注释实例,本次实验使用公开发布的80种关系,48种关系作为训练集,12种关系作为验证集,剩下的20种关系进行预测.
3.2 实验环境搭建
本研究的实验配置为:Ubuntu 20.04.3操作系统,AMD Ryzen 5 PRO 3500U w/ Radeon Vega Mobile Gfx 2.10 GHz的计算机,NVIDIA RTX 1080Ti的GPU,Python 3.7.5的开发环境以及PyTorch 1.3.1的学习框架.
3.3 实验设置
本文在ARSC数据集上进行了2-way 5-shot的实验,词编码阶段采用300维的GloVe词向量进行初始化,最大句长设置为128,在FewRel数据集上构造5-way 5-shot任务,采用50维的GloVe词向量进行初始化,最大句长设置为40.在特征提取模块,设置GRU的隐层状态大小为128.为了避免训练过度还设置了早停,模型的所有参数均采用随机梯度下降策略[22](SGD)进行优化.初始学习率设为 0.1,学习率衰减步长为3000,衰减率为0.1,为了防止小样本常出现的过拟合现象,本研究设置了dropout参数为0.2.模型一共训练30000轮,每1000轮进行一次测试,每次测试阶段包含1000轮,定义每轮实验结果作为单轮准确率,每次测试阶段的平均准确率作为该模型的阶段准确率,取最好的阶段准确率作为模型的结果.另外,对于超参数γ和β的取值在3.6.3节进行了实验,最终选定γ=1,β=1.
3.4 评价指标
本文所采用的评价指标为正确率(ACC),正确率表示在所有样本中预测正确的样本数量占总样本数量的比例.A表示分类器预测标签为正,实际标签也为正的样本数,B表示分类器预测标签为负而实际标签也为负的样本数,C表示分类器预测标签为正而实际标签为负的样本数,D表示分类器预测标签为负而实际标签为正的样本数.
3.5 对比模型
在本次研究中,选取了多种小样本分类模型作为基线模型,分别在ARSC和FewRel数据集上进行了实验,下面对基线模型进行简要介绍.
Proto Net[15]:原型网络,通过学习一个嵌入函数将所有样本映射到统一的向量空间中,并根据支持样本的句子嵌入均值来生成类别原型,最后通过设定好的度量函数来判断查询样本的类别.
Relation Net[15]:关系网络,采用神经网络进行距离度量,使得模型进行端到端的训练并通过汇总支持集中的样本向量来计算类别向量.
ROBUSTTC-FSL[19]:根据各子任务间的差异实施聚类操作,不同的子任务类别自动生成对应的度量方式.
DC-GNN[20]:一种双通道图神经网络模型,借助图的标签传播机制,通过共享两通道的信息传播矩阵解决了元学习框架下的监督信息稀疏化,缓解了图神经网络中过度平滑问题.
MAML[23]:采用元学习方法解决小样本问题的经典模型之一,是一种与模型无关的算法,可以兼容各种模型并且适用于各种任务.该算法最大限度地提高了新任务损失函数的敏感性,因此当参数发生微小变化时便可以大大改善任务的损失,实现快速的收敛.
GNN[24]:一种采用图神经网络解决小样本学习的算法,适用于非结构化数据,其核心思想是借助图结构将有标注样本的标注信息传递至待标注样本中,实现最终的分类.
SNAIL[25]:一种简单且通用的元学习器架构,利用时序卷积神经网络和软注意力学习支持样本的标签信息,借助学习到的信息对序列的最后一个样本进行预测,该方法可以快速的学习和吸收以往的经验,显著的提升性能.
TPN[26]:利用转导的思想,为整个语料库构建一个无向权重图,通过标签传播的方式得到预测结果.
Meta Network[27]:借助高阶元学习器来监督训练过程,利用损失梯度生成快权重,有助于模型快速适应新的任务.
Induction Network[28]:它通过将元学习框架与动态路由算法相结合来学习广义的类别表示,整体是end-to-end的元训练,具有良好的可扩展性.
MEDA[29]:通过在元学习中引入数据增强方法,生成置信度高的增强样本以增加新类别的样本数量,提高模型在小样本情况下的泛化能力.MEDA-PN表示采用原型网络进行度量.
3.6 实验结果分析
3.6.1 对比实验
表2和表3是不同模型在实体关系抽取数据集(Few-Rel)和亚马逊评论情感分类数据集(ARSC)上的评测结果(粗体部分表示在2个数据集上的最优结果).
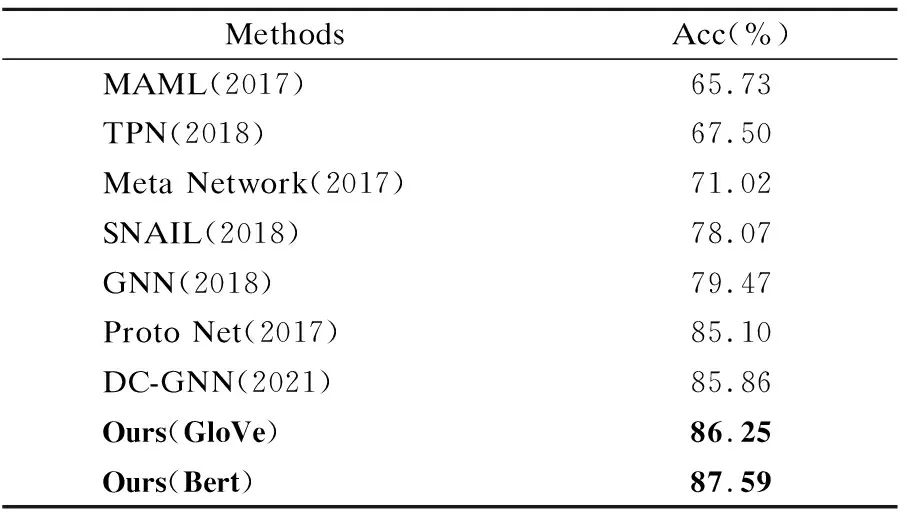
表2 不同模型在FewRel数据集上的准确率对比Table 2 Comparison of the accuracy of different models on the FewRel dataset

表3 不同模型在ARSC数据集上的准确率对比Table 3 Comparison of the accuracy of different models on the ARSC dataset
实验结果显示,在FewRel数据集上,DC-GNN的准确率明显高于GNN和Proto Net,其原因在于它融合了支持本的全局特征与查询样本的标签信息,而在ARSC数据集上,Induction Network相较于度量网络的两大经典模型-Proto Net和Relation Net,分类准确率分别提升了17.46%和2.56%,其原因有两个:1)提供了一个可学习的非线性分类器,在分类的能力上要优于传统的线性分类器;2)融合了动态路由算法,针对类别原型表示进行了改进,将每个类别中的样本表示凝练成了更具代表性的类别表征,获得了更优的分类性能,这验证了好的类别表征能够提升模型的性能.与Induction Network相比,MEDA-PN的分类准确率达85.68%,其主要原因在于该模型提出了一个球生成器,用以生成更多的样本进行训练,从而改善了模型的性能.而本章所提的方法在5-way 5-shot和2-way 5-shot的设定下均优于所有的基准模型,这是因为本文的方法在原型网络的身上充分吸取了教训,在建模时重视查询集和支持集的交互信息并针对不同的特征分配了不同的注意力权值,且不再采用简单的均值法来获取类别表征,有效提高了模型的分类性能.同时本文为了探究不同预训练词向量对模型性能的影响,在两个少样本数据集上进行了对比实验(实验结果见表2和表3粗体部分).从结果中不难看出,当使用了Bert[30]作为预训练词嵌入表示时,两个数据集上的准确率均有所提升,这是因为相较于GloVe,Bert提供了更高质量的词嵌入来表示上下文的语义信息.
3.6.2 消融实验
本文通过去除模型的特定部分来进行消融实验以验证其影响.
首先,探究了特征提取模块的效果.在ARSC数据集上,通过观察LSTM、GRU、双向LSTM、双向GRU和双向注意力GRU这5种不同结构充当上下文特征提取模块时模型准确率的变化,验证双向注意力GRU的有效性.对比结果如图4所示,相较于单向结构,采用双向结构的准确率增长了约1.8个百分点,产生该结果的原因在于双向结构更能捕获文本的全局信息,在进行分类时不仅考虑到了文本上文的信息,同时还结合了文本末端的信息,有助于实现正确的分类.例如在ARSC数据中,因单向结构仅关注上文信息,因此容易将亚马逊购物评论“我很喜欢这条裙子,但是它缩水太严重了,我没法穿出去.”(译文)判定为积极态度,然而结合上下文看来该评论应判定为消极态度.所以,相较于单向提取特征,双向结构在处理文本分类任务中更具优势.除此以外,还观察到在处理小样本文本数据时,无论是单向或双向,GRU结构的准确率均高于LSTM结构,这说明了GRU结构更擅长于提取文本信息,同时不难注意到嵌入了注意力机制的双向GRU效果要比双向GRU更好,这是因为注意力机制有助于捕获重要的局部信息,再结合双向GRU捕获全局信息,有效的提升了模型分类的准确性.
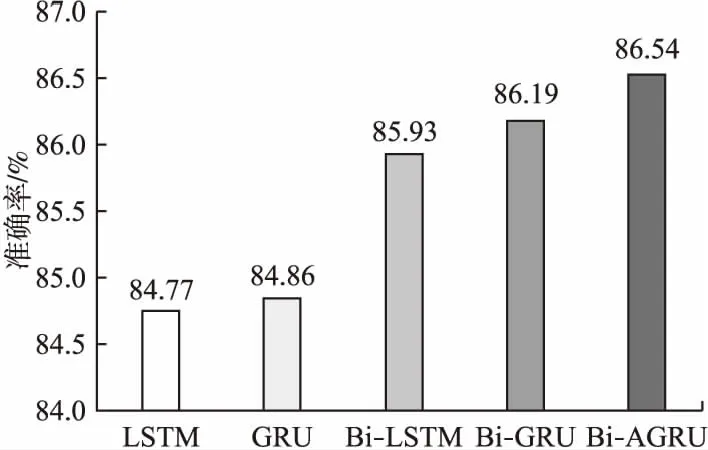
图4 不同特征提取模块在ARSC数据集上的准确率Fig.4 Accuracy of different feature extraction modules on ARSC dataset
其次,为了证明双向注意力模块的有效性,在FewRel数据集上分别就无注意力特征提取模块、自注意力特征提取模块和双向注意力特征提取模块进行了对比实验,结果如表4所示.由表4可知,当模型去除注意力模块后(w/o att),准确率大幅下降,因此注意力机制是模型不可或缺的一部分,在特征提取模块发挥重要作用,生成更具区分性的语义表征,从而提升模型的分类性能,此外,还发现融入了自注意力模块(Self-att)的模型准确率为85.71%,与融入了双向注意力模块(Bi-att)的准确率相比低了约0.6个百分点,这是因为双向注意力模块不仅专注于支持集的信息,还考虑到了查询集的信息,通过在两个方向上使用注意力机制,学习支持集与查询集之间的联系.

表4 不同注意力模块在FewRel数据集上的准确率Table 4 Accuracy of different attention modules on FewRel dataset
然后,为了探索类别数和样本数对于不同模型性能的影响,本文在FewRel数据集上进行了实验.首先验证不同测试类别数对于分类准确率的影响.固定样本数为5,即5-shot,设置测试类别的数量范围为5~10,同时选取Proto Net、GNN、DC-GNN作为对比模型,实验结果如图5所示.然后验证不同的样本数对于分类准确率的影响.固定测试类别数为5,即5-way,设置样本数的范围为1~5,同样选择Proto Net、GNN、DC-GNN作为对比模型,实验结果如图6所示.可以看出,本文提出的模型在所有设置下均优于3个对比模型,同时可以注意到随着测试类别数的增多,所有模型的准确率均随之下降,随着支持样本数的增多,所有模型的准确率均随之上升.值得注意的是,本文提出的模型在测试类别数过多或者样本数过少的情况下依然优于所有的对比模型,验证了所提方法的有效性与健壮性.
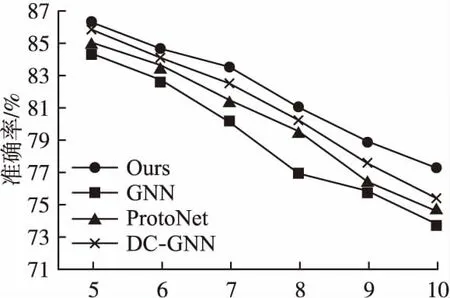
图5 N-way 5-shot下各模型准确率对比结果(N取值范围为5~10)Fig.5 Accuracy comparison results of each model under N-way 5-shot (N ranges from 5 to 10)

图6 5-way N-shot下各模型准确率对比结果(N取值范围为1~5)Fig.6 Accuracy comparison results of each model under 5-way N-shot (N ranges from 1 to 5)
最后,分析了不同类别原型对于模型准确率的影响,实验结果如表5所示.由于小样本任务具有支持样本稀缺的特殊性,所以当样本嘈杂噪声较大时,容易出现个别样本表示远离其他同类样本表示导致生成的类别原型出现巨大误差,降低模型的性能.因此,为了获得更为准确的类别原型,本文提出了一个类原型生成器,使得类别原型的生成更为灵活,同时也能将更多的注意力集中在那些与查询相关的样本上,减少噪声的影响.可以看出,使用类原型生成器替代均值原型和注意力原型能够正确定位与查询样本最为相似的样本,有效提高模型的准确率.

表5 在ARSC数据集上不同类别原型对于模型准确率的影响Table 5 Influence of different types of prototypes on the model accuracy on the ARSC dataset
3.6.3 参数敏感性实验
在这一节中探究了超参数γ和β的取值对于模型分类准确率的影响,首先固定β的值为1,在[0.8、1.0、1.2]中探究γ的最佳取值,然后固定γ的值为1,在[0.8、1.0、1.2]中探究β
对于模型性能的影响,结果如表6和表7所示,不难看出,当超参数γ和β均取1时,模型的分类效果是最好的.

表6 超参数γ对于模型性能的影响Table 6 Effect of hyperparameter γ on model performance

表7 超参数β对于模型性能的影响Table 7 Effect of hyperparameter β on model performance
4 结束语
基于已有的小样本实现准确的文本分类是NLP领域一个正在攻克的难题.本研究针对传统的网络结构无法有效提取样本重要特征设计了一个嵌入注意力机制的双向循环神经网络作为特征提取器,同时对查询集和支持集之间的相互依赖关系进行了探索,提出了融合支持样本和查询样本的双向注意力网络.在此基础上,还对原型网络中原型向量的表示进行了改进,构造了一个类原型生成器,改变了原有的均值计算法与加权求和计算法,使原型向量的生成更为灵活,并设计了原型感知的正则化项对模型进行优化以提升模型分类的准确性.
虽然本研究取得了一些进展,但仍有诸多待改进之处,在后续的研究中有待重视:
1)在小样本文本分类任务中,本文致力于挖掘文本深层语义信息,但是支持集所含信息不足以支撑模型进行更细粒度的分类研究,未来应该考虑结合文本增强技术和外部知识来增强不同任务间的文本表示,弥补训练数据不足的问题.
2)分类结果的好坏不仅仅与建模的算法相关,还取决于模型超参数的设置.目前超参数的设置大多是人为通过不断地实验得到,该过程既耗时又耗力且收效甚微.如果能够实现超参数的自动化调优,将会大大减少人工手动调参的时间还有助于模型实现更好的分类效果.
3)本文设计了一个原型感知的正则化项来进行优化,使得类内距离更为接近,类间距离更为疏远.但同时有监督的对比学习也被提出用于拉近类内距离,拉远类间距离,未来可以考虑使用对比学习来进行类生成器的优化.
猜你喜欢
出版人(2022年11期)2022-11-15
小资CHIC!ELEGANCE(2021年45期)2021-01-11
英美文学研究论丛(2018年2期)2018-08-27
剑南文学(2016年14期)2016-08-22
通信电源技术(2016年5期)2016-03-22
新校长(2016年8期)2016-01-10
人间(2015年20期)2016-01-04
电源技术(2015年9期)2015-06-05
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
