
基于任务空间网格分割的强化学习算法
2023-12-13 02:18祖立鹏王文学
小型微型计算机系统 2023年12期
祖立鹏,王文学
1(中国科学院 沈阳自动化研究所机器人学国家重点实验室,沈阳 110016) 2(中国科学院 沈阳自动化研究所,沈阳 110016) 3(中国科学院大学,北京 100049) 4(中国科学院 机器人与智能制造创新研究院,沈阳 110169)
1 引 言
强化学习在许多虚拟任务中都展示出令人印象深刻的学习结果,例如电子游戏[1,2]、棋盘游戏[3]以及学习复杂的运动行为[4].然而,这些成功的强化学习算法在实际的机器人控制中却并未取得和虚拟世界一样的学习效果,主要是由于难以建立相同的机器人学习环境.同时,在真实的机器人与外界交互过程中,强化学习面临的一个巨大的挑战就是很难准确地定义和描述合适的奖励函数,而在游戏等虚拟任务环境中[5],奖励函数通常是明确定义的,并可以直接优化.对于实际机器人控制,通常希望通过行为来实现某种二进制奖励的目标任务(例如,只有将一个对象移动到所需的位置或实现系统的某个状态,才给予机器人奖励),这种任务的稀疏奖励函数容易设置,这自然会产生稀疏的回报[6].不幸的是,机器人在奖励稀疏的环境中进行探索与学习是非常困难的,因为在随机探索中,智能体很少获得正向的奖励信号[7].
自监督学习(SSL)是用来解决上述问题的有效方法之一[8],该算法学习如何根据需要达到任何预先观察的状态[9],其主要的方式就是通过自己监督自己.这个问题可以表述为训练一个目标制约策略,目标制约策略旨在获得观察结果与目标完全匹配的指标回报.但实际上,这种奖励难以被观察到,因为在像机器人这样的连续空间中,观察到两次完全相同的传感器响应是非常少见的[10].在当前研究中,使用off-policy的RL算法,可以通过在该轨迹中实际到达的最终状态替换其目标状态来“重新标记”收集的轨迹,借助这样的方式可以重新获取多个状态的指标奖励,这种方法被介绍为事后经验回放(HER)[11].虽然它使用了特殊的重置,但奖励实际上是围绕目标的奖励[12].
从演示中学习,或者叫模仿学习(IL),是机器人学中一个研究得很好的领域[13,14].在许多情况下,从专家示范样本那里获得一些演示比提供一个描述任务的好的奖励更容易.以前大多数关于IL的工作都是围绕着轨迹跟踪,或者做一个单一的任务[15].此外,还受到演示性能的限制,或者依赖于设计奖励函数来改进它们.在近期工作中,将IL与HER相结合,可用于多任务连续空间机器人的控制任务,并研究一个更强大的“重新标记”策略,从专家示范样本轨迹中提取额外的信息[16,17].这些研究中,已经证明这类算法组合方式能够在稀疏奖励中,使机器人经过训练完成指定的任务目标.
在此基础上,本文提出了一种新的算法,基于任务空间网格分割的强化学习算法,并表明它具有更快的收敛速度,并达到更高的控制成功率.该算法的设计思想是,当前由人工生成的专家示范样本在一定程度上并不是最优的,并受到具象不匹配与视角差异的影响[18],而利用正在训练的智能体策略网络来生成更优样本有望成为解决这一问题的有效途径.本文主要对算法的两个方面进行研究,一方面是针对行为克隆损失函数梯度系数的取值进行研究,另一方面是针对空间网格分割以及该策略下的优质样本筛选标准进行研究,最后通过仿真实验验证本文提出的算法.本文提出的任务空间网格分割策略扩展了它在实际机器人学中的应用,能够在训练过程中收集更优的样本轨迹,从而提升训练过程的成功率.
2 相关工作
模仿学习是奖励函数工程的一种有效替代方法[19],可以通过专家示范来训练想要的行为.利用专家演示的方法有很多,从直接最大化行为策略梯度下专家行为奖励的行为克隆方法[20],到从这些演示中提取奖励函数,然后训练策略使其最大化的逆强化学习[21,22].另一个接近后者的算法是生成对抗性模仿学习[23].行为克隆的工作都在一定程度上依赖于专家的示范样本,同时用这些方法处理的大多数任务包括跟踪专家状态轨迹,但这类算法在训练后期将会受到的协变量漂移与复合误差的影响[24,25].
在这项工作中,主要研究目标为机器人在连续空间内对目标物体的持续操作,目标是在多个任务需求下达到一定控制精度.这种多任务学习在机器人中是普遍存在的[26],但如果没有合适的奖励函数设计,在训练过程中将会遇到挑战性和严重的数据缺乏.即使在使用稀疏奖励的算法HER中,算法的固有专家样本初始性质可能仍然会产生效率低下的强化学习策略.在前期的工作中,算法BC+HER将行为克隆损失与Q-Filter一起使用,通过这种方式允许智能体的训练经验样本优于示范样本.但这种方式针对行为克隆损失的学习率却没有被更多的探索.最后,本文针对示范样本库的优化问题提出了一种新的算法,能够与当前采用模仿学习的强化学习算法相兼容.
3 预备知识
3.1 强化学习
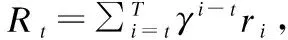
3.2 深度Q网络(DQN)
DQN是一种无模型的强化学习算法用于离散的动作空间[27],这是强化学习算法中最重要的算法之一.在DQN中使用一个神经网络Q来逼近最优价值函数Q*,同时通过贪心的方法执行动作:πQ(s)=argmaxa∈AQ(s,a).又考虑到探索的重要性,使用一个小的概率,从所有动作中以相同概率选择一个动作.
DQN使用的第1个关键技术为经验的回放缓存(Replay Buffer),该技术受到生物学启发[28],在每个时间步t中,先将获得的经验(st,at,rt,st+1)存入经验库中,然后在训练过程中对这些经验进行小批量的均匀采样.DQN的第2个关键技术为使用目标网络,该网络作为独立存在的网络,能够进一步提高智能体训练的稳定性.
3.3 深度确定性策略梯度(DDPG)
DDPG是一种可用于连续空间的无模型强化学习算法[29],同时也是一种演员-评论家算法[30],有效的结合了策略梯度与RL的值估计.简单来说,DDPG通过最小化Bellman误差来学习动作价值函数(critic网络),并用来估计状态-动作对的动作期望回报,同时通过策略梯度来学习参数化的策略(actor网络).在每一个训练过程中,DDPG从经验回放库E中选择N组(st,at,rt,st+1)经验样本,来更新DDPG的网络参数.其中,critic的online网络θQ的损失函数定义为:
yi=ri+γQtarget(si+1,πtarget(si+1))
(1)
(2)
actor的online网络θπ使用策略梯度更新参数:
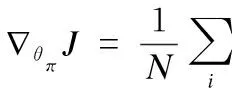
(3)
3.4 事后经验回放算法(HER)
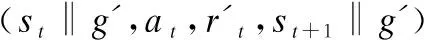
3.5 示范样本的经验库
使用专家示范样本能够加快智能体的学习速度.这里将会建立第2个经验库ED存放专家示范样本的经验,在对经验库ED采样后,先使用评论家网络(critic)判断当前状态-动作价值是否优于智能体的策略产生动作价值,即Q-Filter,随后将优于智能体动作价值的经验以行为克隆损失函数的形式,见公式(4),添加到确定性策略梯度,见公式(5),来更新actor网络θπ的参数,如公式(6)所示:
(4)
Q(si,ai|ED)>Q(si,π(si))
(5)
λ1∇θπJ-λ2∇θπLBC
(6)
4 实验方法
4.1 仿真环境
本文的实验环境使用MuJoCo搭建[31].在所有的实验中,智能体由一个仿真的7自由度的机器人机械手臂与一组平行的夹持器组成,智能体的任务为对一个目标物体进行操作.该目标物体位于机器人前面的桌子上,并需要智能体通过训练完成抓取目标物体并移至指定目标位置.智能体的控制输出是连续的并包含4个控制量:其中前3个控制量指定所需的机械臂末端执行器位置与指定目标位置之需要移动的距离,最后一个控制量为平行夹持器的相对位置,即手指间的距离.智能体在仿真条件下的控制频率为50Hz.
本研究使用脚本程序与MuJoCo环境进行交互生成示范样本.通过这种生成方式,所得到的示范样本并不是最优的,此外示范轨迹的作为经验样本也需经过智能体的critic网络的判断.脚本程序设置最终目标物体与目标位置之间的误差精度为2mm,经验证仅有18.84%的示范轨迹能达到这一精度,5mm误差精度为60.24%,而10mm误差精度可以达到71.56%.另一方面,在生成专家示范样本过程中添加了更多人为主观因素,这些因素对于实际机器人任务而言是不利的,同时,智能体经过一定时间训练后,在相同初始条件所获得的轨迹回报总是能优于专家示范样本轨迹的回报.
4.2 改进行为克隆损失函数梯度的系数
本研究针对公式(6)中的行为克隆损失函数梯度的系数λ2的取值范围进行深度探索,能够使智能体的训练过程快速收敛.该部分主要分为两个阶段,第1阶段使用固定大小的λ2,第2阶段本文创新性的提出使用改进的sigmoid函数来调整固定大小的λ2,见公式(7).具体实验结果见下一节实验结果部分,λsigmoid函数介绍如下:
λ1∇θπJ-λsigmoidλ2∇θπLBC
(7)
(8)
在公式(8)中,λsigmoid取值范围为[0.1,1],其中参数a控制函数的形状,a越大函数越接近阶跃函数,a越小函数则接近于标准sigmoid函数;参数xmetric1和b1为训练过程中的一个指标以及在该指标上某个选定的值作为函数参数,该指标可指定为与训练过程相关的参数指标,例如训练轨迹的成功率、测试轨迹的成功率以及训练的均方误差,等等.
4.3 任务空间网格分割及示例样本生成
智能体抓取的目标物体为边长5cm的正方体.在初始条件中,机械臂末端手指的中心位置(xg,yg,zg),桌面高度为H,目标物体将随机出现在桌面上边长为Lobject的正方形区域Ωobject内位置为(xo,yo,zo).目标位置(xt,yt,zt)在初始化后会依据一定概率出现两种情况:第1种为空中目标,智能体抓取目标物体后移至空中的指定位置,这是一个三维目标空间Ωair,在水平维度上目标位置将出现在边长为Ltarget的正方形区域内,在垂直维度上目标位置将出现在桌面上方高度HT范围内;第2种为平移目标,即将目标物体平移至桌面指定位置,这是一个二维目标空间Ωtable,目标位置将出现在边长为Ltarget的正方形区域内.
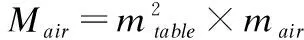
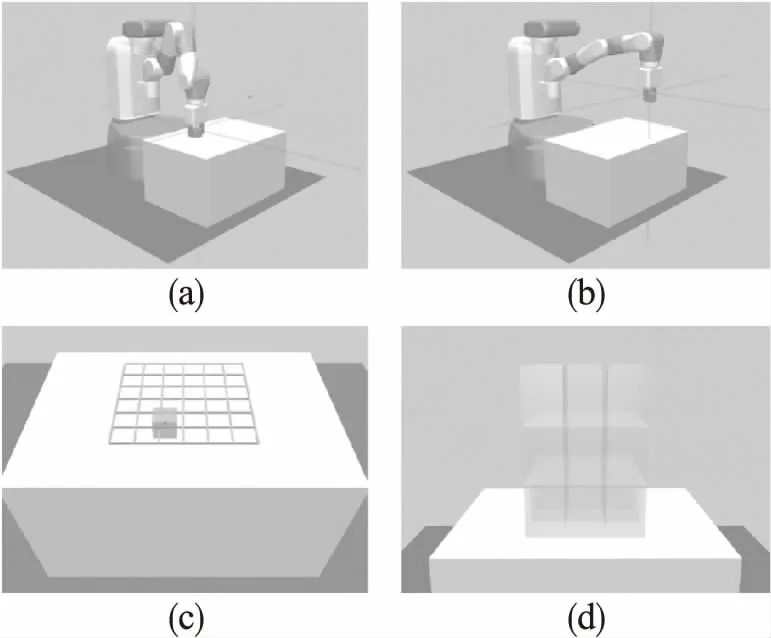
图1 实验环境与任务空间网格分割示意图Fig.1 Simulation environment and schematic diagram of the mesh division of the task space
D=N×(Mair+Mtable)
(9)
4.4 优质样本轨迹判定标准
专家示范样本轨迹的生成方式通常由程序脚本生成或人工采集记录,这些生成的示范样本轨迹原则上并不是最优的,因为由人工获得的样本轨迹的回报往往非常小,而智能体经过一定时间步长的训练后能够获得更优的回报值.因此本研究期望能够在训练过程中,基于正在训练的智能体策略网络,生成并收集一定数量的优质轨迹样本,来补充到专家示范样本库ED中.因此需要建立一系列规则来判断更优的轨迹.
上一节定义的空间网格分割的方式来生成示范样本,机器人机械臂末端在单位时间步长内的每个方向上最大位移为dmax.根据稀疏奖励函数的定义:
(10)
阈值δ为智能体的操作目标物体需要达到的训练精度,在每条任务轨迹生过程中,最终回报主要由三部分组成:机械手移至目标物体附近R1、抓取目标物体R2以及将目标物体移至目标位置R3.
(11)
(12)
如果将目标物体出现空间Ωobject以及目标位置出现空间Ωair和Ωtable分割为网格边长为dmax的单元,本文定义为最小化分网格,则可以精确比较初始化为相同网格区域内轨迹的优劣程度,本研究以较大的网格边长分割方式生成示范样本,并记录样本轨迹回报RD={rew1,rew2,…,rewD},随后进一步将任务空间分割为网格边长为dmax的最小单元并记录初始化位置所在最小化分网格空间的位置坐标为LD={loc1,loc2,…,locD},其中loc=(locobj,loctar).
在最小分割网格中,选择更优轨迹的标准为所获得的回报值与示范轨迹相比应相同或更高.同时,更优的轨迹应满足另一重要条件,即轨迹最终达到的控制精度在δg范围内:δg<δ.本研究在上述两条要求同时满足时,则将该生成的轨迹作为优质样本补充到示范样本库ED中,并更新该轨迹所处网格分割空间坐标的回报值,这一点保证了在后续选择的轨迹样本的回报会不断接近最大回报.在这里,本文使用第2个xmetric2来启用样本筛选过程,目的是使智能体已经能够较好的完成任务的基础上,再由其生成优质轨迹样本.
4.5 算法实现
初始条件:
强化学习算法:HER,future strategy
示范样本轨迹参数:RD,LD
初始化:HER,经验回放库E,λsigmoid
whilenot donedo
初始化仿真环境获得目标g,智能体初始状态s0
fort=0,T-1do
使用DDPG算法的行为网络生成动作at
智能体在执行动作at后,获得新状态st+1
endfor
E←E∪(s0,a0,s1,…)添加轨迹到经验库在EDandE中使用future strategy采集训练集 batchB
θQ+=λ3∇θQL,更新critic网络参数
θπ+=λ1∇θπJ-λsigmoidλ2∇θπLBC,更新actor网络参数
xmetric1←xmetric1,更新训练指标xmetric1
λsigmoid←λsigmoid,更新系数λsigmoid
xmetric2←xmetric2,更新训练指标xmetric2
ifxmetric2>b2do
fori=0,Nexpolredo
初始化仿真环境,目标g,状态s0,坐标标签loc
iflocinLDdo
从RD中返回该位置标签下的回报值Rlabel
轨迹回报Rexplore=0
fort=0,T-1do
使用DDPG算法的行为网络生成动作at
智能体在执行动作at后,获得新状态st+1,奖励r
Rexpolre+=r
endfor
轨迹最终执行精度为δexplore
ifδexplore≤δg&Rexplore≥Rlabel+1do
ED←ED∪(s0,a0,s1,…),添加轨迹到示范样本库
RD(loc)←Rexplore,更新位置坐标处的回报值
endif
endif
endfor
endif
endwhile
5 实验结果
5.1 仿真实验环境配置
本研究基于Github上的开源项目库OpenAI Baselines(https://github.com/openai/baselines).智能体的actor网络和critic网络结构均为4层的MLP网络,隐含层包含256个节点,使用ReLU作为激活函数以及L2正则化,网络优化器为Adam.每次训练batchB包含256个经验样本,其中32个来自示范样本库ED,λ1=λ3=0.001,奖励折扣因子γ=0.98.初始化时,空间网格化分生成的示例样本库ED轨迹参数,n=2,mtable=mair=3,生成的样本轨迹总数量N=144.设置Lobject=Ltarget=30cm,HT=45cm.本研究探索的智能体控制精度分别为δ=10mm和δ=5mm.
本研究在计算机配置为CPU:i7 11700KF,GPU:3080ti的个人主机上运行,并使用多线程并行编程技术,每次运行使用5个MPI进程并行.
5.2 LBC梯度的系数改进
通常情况下,深度网络的学习率是一个非常重要的参数,可以认为学习率的定义就是每次网络参数移动的幅值,本研究使用HER算法并结合模仿学习行为克隆的方式进行训练,有3个需要定义的学习率分别对应λ1、λ2、λ3,其中λ1、λ2为actor网络学习率,公式(6)以及critic网络学习率λ3.本研究对行为克隆损失函数梯度的学习率λ2进行探索,在先前的研究算法(BC+HER)中[17],并将该系数赋值为λ2=1/ND=3.125e-2,但这一取值未被过多的讨论.本研究首先使用固定大小的λ2=3.125e-6;3.125e-5;3.125e-2.示范样本库ED包含100条随机生成的轨迹样本,智能体的训练目标误差范围δ=5mm,如图2所示.
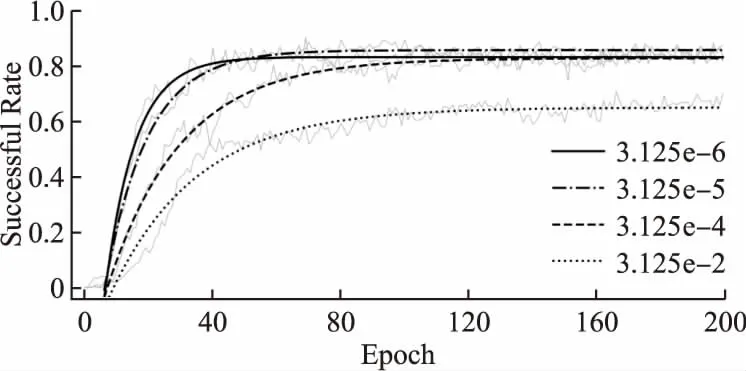
图2 设置不同λ2大小的训练曲线Fig. 2 Training processing using the fixed λ2
图2所示的结果为20次训练结果平均后的拟合曲线,拟合函数以及上升曲线的时间常数为:
func=a×exp(-b×x)+c(τ=1/b)
(13)
由图2所示的结果表明,当λ2=3.125e-2时智能体训练的收敛速度十分缓慢.同时,λ2越小智能体训练的收敛速度越快,但一味的减小λ2并不能获得更高的训练成功率,当λ2=3.125e-6有较快的收敛速度,λ2=3.125e-5智能体能够达到较高的成功率,需要指出的是取该值时,其大小与λ1的存在关系为λ2=λ1/ND.本研究基于上述发现,使用一种在训练过程中调节学习率的方式,提出使用λsigmoid函数来调整固定大小的λ2,如公式(8)所示,本研究使用3组λsigmoid函数的参数进行对比mode1:a=20,b1=0.5;mode2:a=20,b1=0.65;mode3:a=10000,b1=0.8,选择测试轨迹的成功率作为xmetric1指标,其中mode1和mode3的λsigmoid曲线如图3所示.
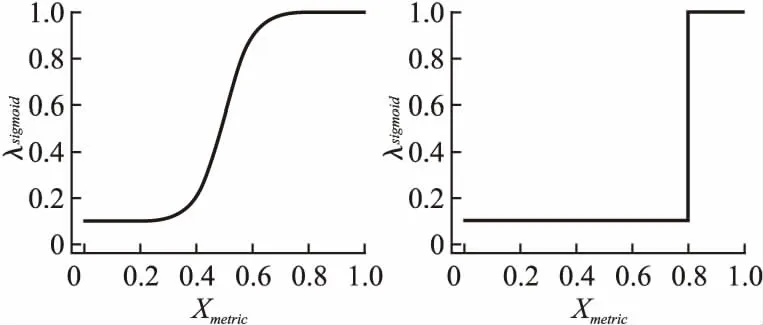
图3 mode1(左)和 mode3(右)的λsigmoid函数曲线Fig. 3 λsigmoid curves of mode1 (left) and mode3 (right)
由图3可知,mode1参数设置下能够让学习率平稳过渡,而mode3参数设置的曲线则更接近阶跃响应函数,在b1处直接跳变.通过设置λ2= 3.125e-5,则λBC=λsigmoidλ2.通过使用这种可动态调节学习率参数的方式,可以在智能体训练起始阶段时使用较小的学习率(λBC=3.125e-6),而在训练后期时调整为较大的学习率(λBC=3.125e-5),既能保证训练过程的快速收敛,又能得到较好的训练成功率.使用上述方式将20次训练的平均拟合曲线如图4所示.
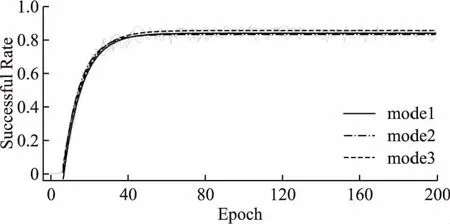
图4 使用λsigmoid调节λ2大小的训练曲线Fig. 4 Using λsigmoid to adjust the value of λ2
从图4中可以看出,3组λsigmoid的收敛速度相近,但最后一组mode3的成功率更高.进一步对比分析mode1、mode3、3.125e-6、3.125e-5以及3.125e-2的训练情况,结果如表1所示.从表中数据可以看出,采用mode3的方式能够达到85.70%的训练成功率,同时,收敛速度接近固定大小的λ2=3.125e-6组.在相同训练步长Timestep=500000,Epoch=200情况下,与算法BC+HER相比,本文提出的学习率调节方式具有相当明显的优势,大幅提升了训练速度与任务的成功率,与预期结果一致.
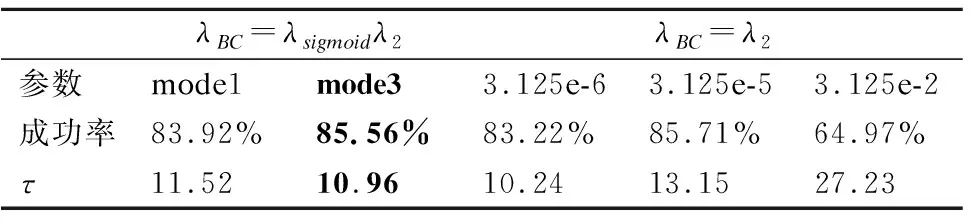
表1 4组不同学习率方式对比Table 1 Comparison of four learning rate methods
5.3 基于任务空间网格分割算法的机械臂控制
基于上一小节结论,本节将直接使用mode3设置的参数进行训练.使用空间网格分割的方式生成144条样本轨迹经验存于示范样本库ED中,其中n=2,mtable=mair=3.设置dmax=5cm,则在最小化分网格中,n=6,mtable=6,mair=9,根据公式(9),任务空间的组合数将达到12960,显然,144条轨迹在这样的空间分割下仍然十分稀疏.初始化机械臂的仿真环境后,zg-zo=0.115cm,机械臂末端手指的水平位置为目标物体出现区域的中心:max(|xg-xo|)=max(|xg-xo|)=0.15cm,由公式(11)可知,max(R1)=-3,最优的奖励大小为固定值,而另一方面需考虑R3大小,使用最小网格分割的方式,判断更优样本的方式将使用公式(14),这种判断方式确保了收集到的轨迹样本只能是更优的.
Rexplore≥Rlabel+1
(14)
本节主要研究的智能体控制精度分别为δ=10mm和δ=5mm,同时将选择训练轮数epoch作为xmetric2指标,控制精度为δ=10mm时,设置b2=20,Timestep=125000,Nexpolre=500;控制精度为δ=5mm时,b2=35,Timestep=200000,Nexpolre=500.本研究将随机生成示范样本的算法BC+HER与本文提出的算法(BC+HERmode3+mesh)进行对比分析,在两种控制精度要求下的结果分别如图5(左)和图5(右)所示.从训练曲线中可以看出,本文提出的任务空间网格分割算法与‘+mode3’相结合能够将任务的成功率明显提升.另一方面,δ=10mm时,训练结束后新加入示范样本库ED的经验轨迹数增加了约70条.δ=5mm时,新加入示范样本库ED的经验轨迹数增加了约120条.
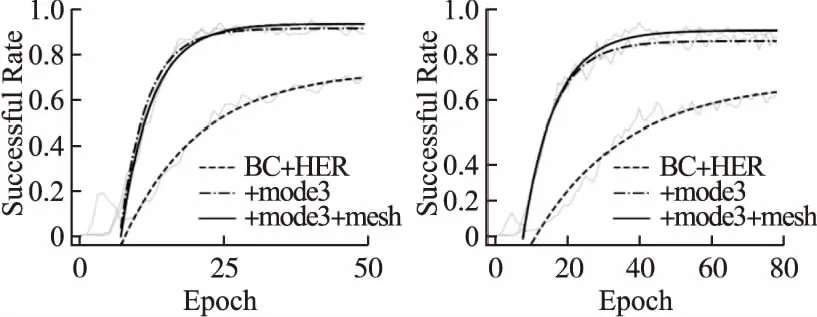
图5 在10mm (左)和5mm (右)控制精度下的训练曲线Fig. 5 Training curves at 10mm (left) and 5mm (right) error
本文使用相同的训练时间步长Timestep作进一步的对比分析,如表2所示.与先前的算法(BC+HER)、本文提出的mode3设置方式(+mode3)以及本文提出的任务空间网格分割策略(+mode3+mesh)的训练结果对比.由训练数据可知,本文提出的方法在训练过程中能够大幅优于BC+HER算法的表现.相比较于BC+HER+mode3,在δ=10mm控制精度要求下,任务空间网格分割的方式能够提升约1.8%的成功率,而在δ=5mm控制精度下,能够提升约4.7%的成功率,达到了90.45%.

表2 不同控制精度要求下的成功率对比Table 2 Comparison of different control accuracies
6 结论与展望
本文提出一种基于任务空间网格分割的强化学习算法,能够在稀疏奖励函数下,以较高的训练速度下实现更高精度的机器人控制的任务成功率.本文主要针对两方面进行研究,一方面,针对LBC梯度的系数λ2的取值进行优化,经实验发现该值满足λ2=λ1/ND时能够取得最好的控制成功率,同时智能体训练的收敛速度也随着该值的减小而加快.基于这两个规律,本研究创新地使用函数变量λsigmoid来调控λ2的大小,选择训练过程指标xmetric1和b1作为函数参数,需要指出的是该指标可指定为任何与训练过程相关的参数指标.经实验论证,本文中选择的mode3参数方式能够以较快的训练的收敛速度达到更高的成功率.
另一方面,本文介绍了空间网格分割算法的空间分割方式以及优质样本选择标准,该方式能够在最小分割网格策略下,对处于相同位置坐标轨迹样本的优劣程度进行直接比较,从而选择更优样本补充到示范样本库ED中.使用该算法能够有效提高智能体在控制目标物体任务中的成功率.任务空间网格分割的方式虽然对完整的任务空间进行映射,但这样的方式也默许了机器人所要执行的任务是均匀的.因此,算法的筛选优质轨迹部分,本文并没有直接初始化为对应示范样本空间的位置,而是选择了随机初始化的环境,这是因为智能体在执行真实任务时具有一定倾向性,这一点能够保证优质样本轨迹是智能体所需要的.
本文提出的算法具有较强的结合能力与适用性,能够与目前任何使用专家示范方法的强化学习算法结合.在算法参数设置方面,训练指标xmetric1和xmetric2能够使用与训练过程相关联的任何指标,比如训练轮数、测试样本的成功率又或者训练过程的均方误差,等等.同时在更优样本的判断标准上也可选择更为严格的择优标准,来获得更高的训练成功率.
猜你喜欢
中学生数理化·七年级数学人教版(2022年10期)2022-11-11
当代水产(2022年6期)2022-06-29
中国生殖健康(2020年8期)2021-01-18
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
数学年刊A辑(中文版)(2019年3期)2019-10-08
中国生殖健康(2018年3期)2018-11-06
现代装饰(2018年5期)2018-05-26
北京航空航天大学学报(2017年6期)2017-11-23
中国三峡(2017年2期)2017-06-09
