
A multimodal dense convolution network for blind image quality assessment#
2023-12-11 02:41NandhiniCHOCKALINGAMBrindhaMURUGAN
Nandhini CHOCKALINGAM, Brindha MURUGAN
Department of Computer Science and Engineering, National Institute of Technology, Tiruchirappalli 620015, India
E-mail: cn.nandhini@gmail.com; brindham@nitt.edu
Abstract: Technological advancements continue to expand the communications industry’s potential.Images, which are an important component in strengthening communication, are widely available.Therefore, image quality assessment (IQA) is critical in improving content delivered to end users.Convolutional neural networks (CNNs)used in IQA face two common challenges.One issue is that these methods fail to provide the best representation of the image.The other issue is that the models have a large number of parameters, which easily leads to overfitting.To address these issues, the dense convolution network (DSC-Net), a deep learning model with fewer parameters, is proposed for no-reference image quality assessment (NR-IQA).Moreover, it is obvious that the use of multimodal data for deep learning has improved the performance of applications.As a result, multimodal dense convolution network(MDSC-Net)fuses the texture features extracted using the gray-level co-occurrence matrix(GLCM)method and spatial features extracted using DSC-Net and predicts the image quality.The performance of the proposed framework on the benchmark synthetic datasets LIVE,TID2013, and KADID-10k demonstrates that the MDSC-Net approach achieves good performance over state-of-the-art methods for the NR-IQA task.
Key words: No-reference image quality assessment (NR-IQA);Blind image quality assessment; Multimodal dense convolution network (MDSC-Net); Deep learning; Visual quality; Perceptual quality https://doi.org/10.1631/FITEE.2200534 CLC number: TP39
1 Introduction
Information and communication technology(ICT) has permeated almost every aspect of human life, helping people to collaborate, exchange knowledge, and learn more effectively.Multimedia technologies for online education, surveillance, ondemand video streaming,high-definition televisions,social media, and video chat have gained popularity, resulting in vast numbers of digital images and videos.The rapid growth of multimedia applications demands a high quality of experience (QoE) for end users.The perceptual image quality is critical to the performance of these applications.On the other hand, digital images are subjected to distortion at different stages, including acquisition, digitization,transmission, noise processing, and display, which degrades the human visual experience.Therefore,predicting the image quality is essential to improve the image content delivered to end users.Image quality assessment(IQA)metrics aid in the identification of low-quality photographs and their removal from galleries and other sources.Furthermore, real-time monitoring during acquisition may help remove annoying distortions by setting optimum parameters.
Over the last decades, researchers have been developing various IQA metrics to predict perceptual image quality.Subjective assessment deals with images evaluated by human subjects, following a standard set of procedures.The mean opinion score(MOS)obtained from different participants over several viewing sessions seems to be the most reliable and accurate metric.However, subjective assessment is laborious, time-consuming, and expensive.Furthermore, it cannot be used directly as an optimization metric for real-time multimedia systems.Objective assessments, which are typically trained using subjective assessment data, can automatically estimate image quality and are ideal for real-time systems due to their performance evaluation and optimization.The three types of objective IQAs are as follows: full-reference IQA(FR-IQA)requires the full pristine image to evaluate the distorted image,reduced-reference IQA(RR-IQA)requires less detail from the reference image,and no-reference IQA(NRIQA)does not need any reference image to access the image quality.Because reference images are typically unavailable in many scenarios, NR-IQA algorithms are useful for a variety of practical applications.As a result, the scientific community is interested in NRIQA approaches.
Deep convolutional neural network(DCNN)approaches have been widely used in recent years and have achieved considerable success in many computer vision tasks, including image recognition(Krizhevsky et al., 2012;He et al., 2016;Ding et al.,2019), visual tracking (Ding et al., 2018), and social image comprehension(Li ZC et al., 2019).Traditional approaches for NR-IQA use natural scene statistics(NSS)based features in most of the successful approaches.NSS features are extracted in image transformation domains using wavelet transform or discrete cosine transform (DCT).These approaches are computationally expensive and too slow.Kang et al.(2014) were the first to apply convolutional neural networks(CNNs)for IQA and achieved excellent results, spawning a multitude of DCNN-based NR-IQA approaches (Mittal et al., 2012; Li QH et al., 2016; Bosse et al., 2018; Ma KD et al., 2018;Zhang WX et al., 2020).Inspired by the success of DenseNet,Huang et al.(2017)proposed a DenseNetbased network model to efficiently learn both the high- and low-level spatial features using a multilayer network.
We analyze two different frameworks based on DenseNet in this paper.Deep networks can significantly increase the number of parameters to train.The increase in parameters leads to overfitting in the absence of massive data.As the dataset for an IQA task contains limited images, dense convolution network (DSC-Net), an efficient and simplified DenseNet framework with four dense blocks for semantic feature representation is leveraged for the IQA task.DSC-Net is much deeper compared to other shallow networks used for IQA tasks and is capable of generating a large number of reusable feature maps by dense connections with fewer parameters.DSC-Net uses a patch-based approach to augment the data,with each patch having equal importance and having the same MOS as the image.
Texture is essential in human visual perception because it helps object recognition.Identifying various textures is a simple task for human eyes,but it is more difficult when applied to computer vision tasks.To obtain a good feature representation,images with different textures are analyzed.Images with uniform and non-uniform textures are significantly different in their intensity distribution along the RGB channels.As shown in Fig.1, the intensity values of non-uniform texture images are widely distributed compared to those of the uniform regions.
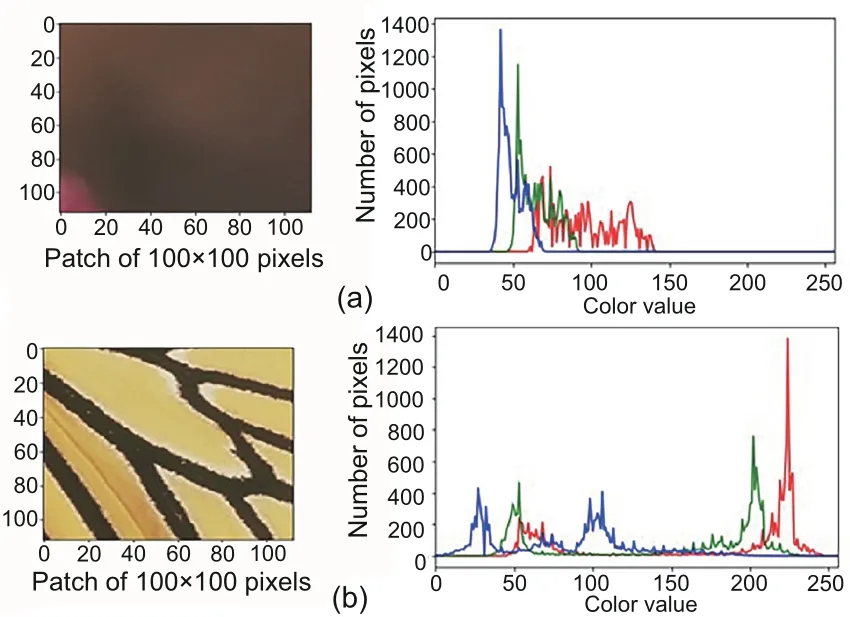
Fig.1 Intensity distribution of uniform (a) and nonuniform (b) texture patches of 100×100 pixels
Moreover,the texture is stochastic in nature and is a function of the spatial variance of brightness and intensity of the pixels in an image.Hence, using their statistical properties is a reasonable choice for extracting the texture features.The gray-level co-occurrence matrix (GLCM) approach is one of the most commonly used statistical methods for extracting texture features.As a result, multimodal dense convolution network (MDSC-Net) introduces a feature fusion strategy that allows for a combined regression of the multimodal features extracted from texture and spatial image representations.In summary,the main contributions are three-fold:
1.A coherent DSC-Net framework is proposed,which makes excellent use of feature reuse and significantly reduces the number of parameters to train.
2.The MDSC-Net model, which fuses texture features with spatial features from DSC-Net,is introduced to represent the structural information more efficiently.
3.The efficiency of the proposed system is analyzed on the LIVE, TID2013, and KADID-10k datasets, and a cross-dataset evaluation proves the generalization capability of the system.
2 Related works
The majority of the NR-IQA algorithms are concerned with NSS and deep learning based approaches.DIVINE (Moorthy and Bovik, 2011) and BLINDS-II (Saad et al., 2012) are two examples of popular NSS-based NR-IQA algorithms.The wavelet transform (Moorthy and Bovik, 2011) and the DCT (Saad et al., 2012) are often used to extract traditional NSS-based features in image transformation domains.Due to the use of image transformations, these techniques are typically slow and computationally expensive.In the absence of reference images, Sheikh et al.(2003) used statistical features derived from natural images to determine the image quality.
BRISQUE (Mittal et al., 2012) and CORNIA(Ye et al., 2012) encouraged the extraction of features from the spatial domain,which reduced computation time significantly.CORNIA (Ye et al., 2012)and HOSA (Xu et al., 2016) showed that instead of using handcrafted features,it is possible to learn discriminant image features directly from the raw image pixels using codebooks to estimate the visual quality scores.However,the codebook is created using complexK-means clustering on local features.Liu LX et al.(2014) used spectral and spatial entropies to access the image quality.Gu et al.(2018)extracted 17 features from image data sets by analyzing contrast, sharpness, brightness, and other factors, and then used a regression module to produce a measure of visual quality using big-data training samples.In LBIQ (Tang et al., 2011), a set of low-level features from NSS and texture statistics are combined and a kernel support vector machine (SVM) is used to pre-train a deep belief network that works well as a predictor of image quality.The aforementioned approaches depend on a subset of features that are expected to capture important factors affecting image quality, but determining which features are better for IQA tasks is difficult and requires domain knowledge.
According to human visual system(HVS) modeling (Lu et al., 2005), certain areas of an image have more importance than other areas.Taking this into consideration, some works (Wang and Shang,2006;Zhang P et al.,2015)explored different weighting strategies for local quality estimation.Zhang P et al.(2015) suggested a semantic informationbased NR-IQA algorithm.The features based on the image’s semantic obviousness and the local characteristics are combined to access the image quality.However, it has an additional overhead of using the binarized normed gradients (BING) object detector to extract the object-like features which have poor object proposal quality.NRVPD (Wu et al., 2019)used an orientation similarity pattern based modeling that extracts both the visual content and quality degradation patterns using a support vector regression(SVR) for NR-IQA.
Nowadays, deep learning has been successfully applied to a variety of applications(Song et al.,2016;Qiu et al., 2018; Zhang SQ et al., 2018; Gu et al.,2020, 2021a, 2021b) and achieved remarkable success.Kang et al.(2014) were the first to apply a CNN to the NR-IQA.The CNN was trained with normalized small image patches and the whole image quality was predicted by averaging the scores of all the patches.This method assumes that each local patch quality is the same as the global image quality, which is not true, and their network is also too shallow.Kang et al.(2015) further extended their work to reduce the number of parameters and simultaneously estimated the distortion type.Bosse et al.(2016) fine-tuned a CNN network to improve the prediction score by weighting the patches based on image saliency.Kim and Lee(2017)trained a CNN model based on patch extraction,in which the quality scores were estimated from an FR-IQA model and then the network was finetuned using mean and standard deviation statistics of the local features.Despite encouraging performance,these approaches have complex architectures and the evaluation is based on smaller subsets from the IQA dataset.Cheng et al.(2017) trained a CNN and an adaptive strategy using the saliency map,which assigns higher weights to salient patches.RankIQA(Liu XL et al.,2017)trained a siamese network with reference and distorted images and using that knowledge, the network is fine-tuned for single image quality prediction.Multitask end-to-end optimized deep neural network(MEON) (Ma KD et al.,2018) is a multitask framework that identifies the type of distortion, and using that pre-trained layer and distortion type, a quality prediction network is trained.Moreover, the generalized divisive normalization layer was used as the activation function instead of rectified linear unit (ReLU), which significantly reduced model parameters.However, it used the weights from synthetically generated images for different distortion types.Bianco et al.(2018) used different CNN design options,and the CNN features that had previously been trained on the image classification task were taken as inputs to train a quality predictor using SVR.However,their method involves manual parameter settings which are not optimized.
DB-CNN (Zhang WX et al., 2020)models synthetic and authentic distortions used two features,an ImageNet (Deng et al., 2009) trained VGG-16(Simonyan and Zisserman,2014)model and bi-linear pooling (Lin TY et al., 2015)for quality prediction.It also used distortion type and distortion level information for training to obtain better results.The ImageNet dataset includes high-quality photographs intended for object classification and contains different forms of distortions from IQA task.
VIDGIQA (Wu et al., 2019) made use of the distortion information and multitask learning procedure to learn features.In addition to estimating the visual quality,with the help of the distortion classification task,the accuracy of visual quality estimation was improved.EI-IQA (Yang et al., 2020) learned the quality score using a dual-stream network that used wavelet kurtosis features and VGG-16-based spatial features.However, the computation complexity for extracting wavelet features is significantly high.Po et al.(2019)proposed a framework,in which homogenous patches were ignored based on a variance threshold during training and the quality score was based only on the patches with complex structures.NCMQA (Zhou et al., 2020) introduced a neighborhood co-occurrence matrix to extract statistical features and the SVR was trained to predict image quality scores.The dataset amalgamation method (Zhang WX et al., 2021) has been shown to be effective in handling generalization, but it is limited in terms of adaptability to new datasets and computation scalability.RankIQA (Liu XL et al.,2017)used a two-step approach that generates a vast number of images by introducing different levels/types of distortions and ranks them according to their distortion type and level of distortion.Then,the network was trained to learn these rankings using synthetically generated images.Using pre-trained weights, the system was fine-tuned on the NR-IQA dataset.VCRNet (Pan et al., 2022) used the nonadversarial model, which relied on the relationship between the distorted image and its restored image to accurately predict the image quality.
Many works try to model the HVS (Lu et al.,2005;Zhang P et al.,2015),and others(Kang et al.,2014; Bosse et al., 2016; Chockalingam and Murugan, 2023) try to make the best use of the limited number of images in the IQA datasets by learning from small patches of the images as individual samples.Some approaches (Bianco et al., 2018; Zhang SQ et al., 2018; Li ZC et al., 2019) try to fine-tune a pre-trained network on a large dataset for other tasks to transfer the knowledge to the IQA tasks,while other frameworks(Liu XL et al.,2017;Lin HH et al., 2019; Wu et al., 2019) augment the dataset,thereby increasing the labeled training samples.In this paper,we adapt learning from patches and make use of multimodal features to model the HVS to improve the performance of NR-IQA tasks.
3 Proposed work
The proposed approach,which employs a DSCNet convolutional network to predict the visual image quality, is discussed in this section.It begins by laying a general framework for the proposed approach, and then describes the functionality of each module.This section begins by describing how the DSC-Net architecture can be used to learn from image patches, and also explores how multimodal features affect the performance of the IQA task.
The proposed scheme is shown in Fig.2.The non-overlapping image patches are generated for a given image.The spatial features are extracted using DSC-Net, which is fused with texture features extracted using GLCM.The fully connected layers at the end are used as regressors to estimate the image quality.
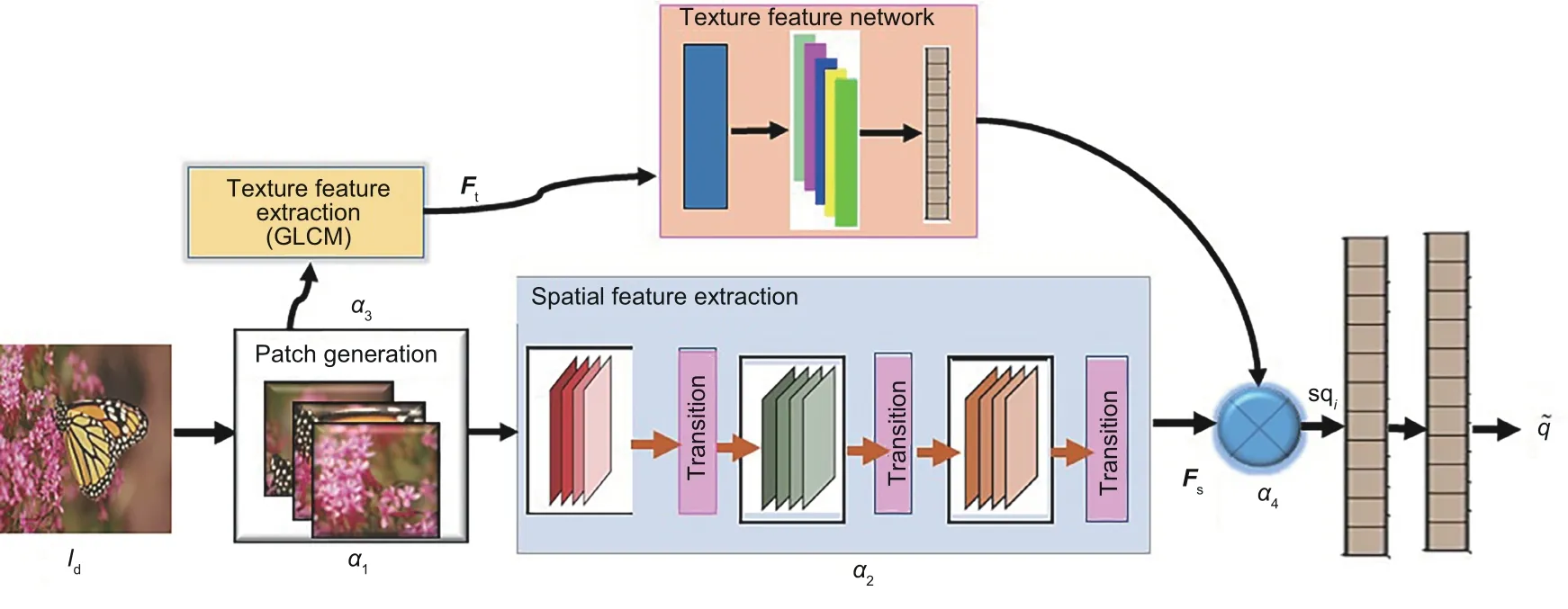
Fig.2 General framework of the proposed work
For a given distorted input imageId, its perceptual quality ˜qcan be predicted by a quality estimation modelψ:
whereβis the model parameter.The proposed frameworkψconsists of four major elements,including a patch generation module (α1), spatial feature extraction module (α2), texture feature extraction module(α3),and feature fusion and regression module (α4).
Multiple non-overlapping image patches are generated for the input imageIdby the patch generation module.This module also applies local contrast normalization(LCN) to all the patches as a preprocessing step.This module (α1) can be formulated as
The spatial feature extraction module extracts spatial featuresFs∈R256for each image patchPi.This module is denoted asα2with parameterβ1∈β.
The DSC-Net model learns the perceptual quality sqiof the image, using the spatial features.The MDSC-Net model extends the DSC-Net model with the addition of two more modules.The texture feature extraction module extracts texture features using GLCMFt∈R60for each image patchPi.This module is used for all image patches and denoted asα3with parameterβ2∈β.
The feature fusion and regression module concatenates the spatial and texture features and regresses the quality score sqifor each patchPi.This module is denoted asα4with the network parametersβ1,β2∈βfrom the spatial feature extraction and texture feature extraction modules,respectively.
3.1 Patch generation(α1)
The patch generation module is used to increase the number of training samples in this study.This module also deals with LCN as a pre-processing step.To train a deep learning network,the data available in publicly accessible image quality datasets are inadequate.As a result, cropping is used to increase the amount of training data in the proposed study.Cropping, rather than resizing, retains the image’s perceptual consistency.As a result, a large number of patches are generated from different spatial positions to cover the object’s local visual details.
The non-overlapping cropped patches can be of any size.However, the neural network typically accepts fixed size input,and the proposed implementation uses a patch size of 56×56.The total number of local image patches in an image will vary depending on the image size.
Therefore, the total number of non-overlapping cropped patches for each image is given by
wherewi×hiis the resolution of the image andwp×hpis the resolution of the local patches.■*」means floor function, which inputs a real numberxand gives the highest integer less than or equal tox.Once the patches are generated,LCN is applied to all the patches, as described in the supplementary materials, to make the network robust to illumination and contrast changes.
3.2 Spatial feature extraction (α2)
A good set of features plays a significant role in any deep learning task, like IQA.The DenseNet architecture with more layers has shown excellent accuracy in various image classification tasks, and has good generalization ability.To overcome the vanishing gradient descent problem, DenseNet directly connects all layers with each other by concatenating its features, which reduces the computation.Hence,to extract the spatial features,DSC-Net,the network based on DenseNet, is explored for the first time for the IQA task.
The architecture of DSC-Net is shown in Fig.3a and has components like DenseBlock and a transition layer.The DenseBlock contains a fixed number of dense layers with bottleneck connections to reduce the depth of feature maps, which significantly reduces the model parameters.The transition layer aggregates the output from the DenseBlock and helps reduce the size of the feature maps using average pooling.
The architecture of the DenseBlock is as shown in Fig.3b.A DenseBlock contains a sequence of dense layers.A dense layer has feature maps from all its preceding layers in that block, which contributes to diversified features.Each dense layer also adds its own feature maps,thus building collective knowledge.
DSC-Net concatenates the feature maps between the subsequent layers.Letxlandxl-1denote the output of thelthand(l-1)thlayers,respectively.Then produces the composite functionH(*).xlis given as follows:
The amount of information contributed by each layer is regulated by the growth rate (k) of the network.Hence, if each dense layer produceskfeature maps, thelthlayer hask0+k(l- 1) feature maps, wherek0is the number of channels in the input image.As the number of layers increases, the number of feature maps also increases,to reduce the depth of the feature maps, and a bottleneck layer with a 1×1 filter is introduced,which outputs 4×kfeature maps.So, each dense layer in Fig.3c has batch normalization(BN),ReLU,and convolutional filters with kernel size 1×1 followed by a BN–ReLU 3×3 convolution.In the proposed framework, four DenseBlocks are used, each with three layers, and the growth ratekof each layer is 8.Transition layers are introduced after the DenseBlock to down-sample the feature maps.The architecture of each transition layer is as shown in Fig.3d, which contains a BN layer, ReLU activation followed by a 1×1 convolution filter,and a 2×2 average pooling layer.
In the proposed framework, DSC-Net is used to extract spatial features and it has the following differences compared with the original DenseNet architecture:
1.Input size: the input layer of DSC-Net accepts 56× 56 patches, whereas in the original DenseNet implementation it is 224×224.This size is fixed due to limited data in the IQA dataset, and patch-based training is done.
2.DenseBlocks with fewer dense layers: as the input size is small, the number of layers is reduced in DSC-Net.In the DenseNet implementation, the number of layers in each DenseBlock is 6,12,24,and 16,and hence the total number of convolution filters sums to more than 100.However, in the proposed implementation,the number of layers in all the dense blocks is 3, reducing the number of dense layers to 12 with a total of 28 convolution filters.
3.Reduced growth rate: each dense layer produces the number of feature maps based on the growth rate.In DenseNet implementation, the growth rate is 32,while in the proposed work it is set to 8.
4.Fewer parameters to train: because the number of layers is reduced in DSC-Net, the number of parameters is significantly reduced.
The DSC-Net generates the feature mapFs∈R256with parametersβ1, which is fed into a fully connected layer for quality score sqiestimation.
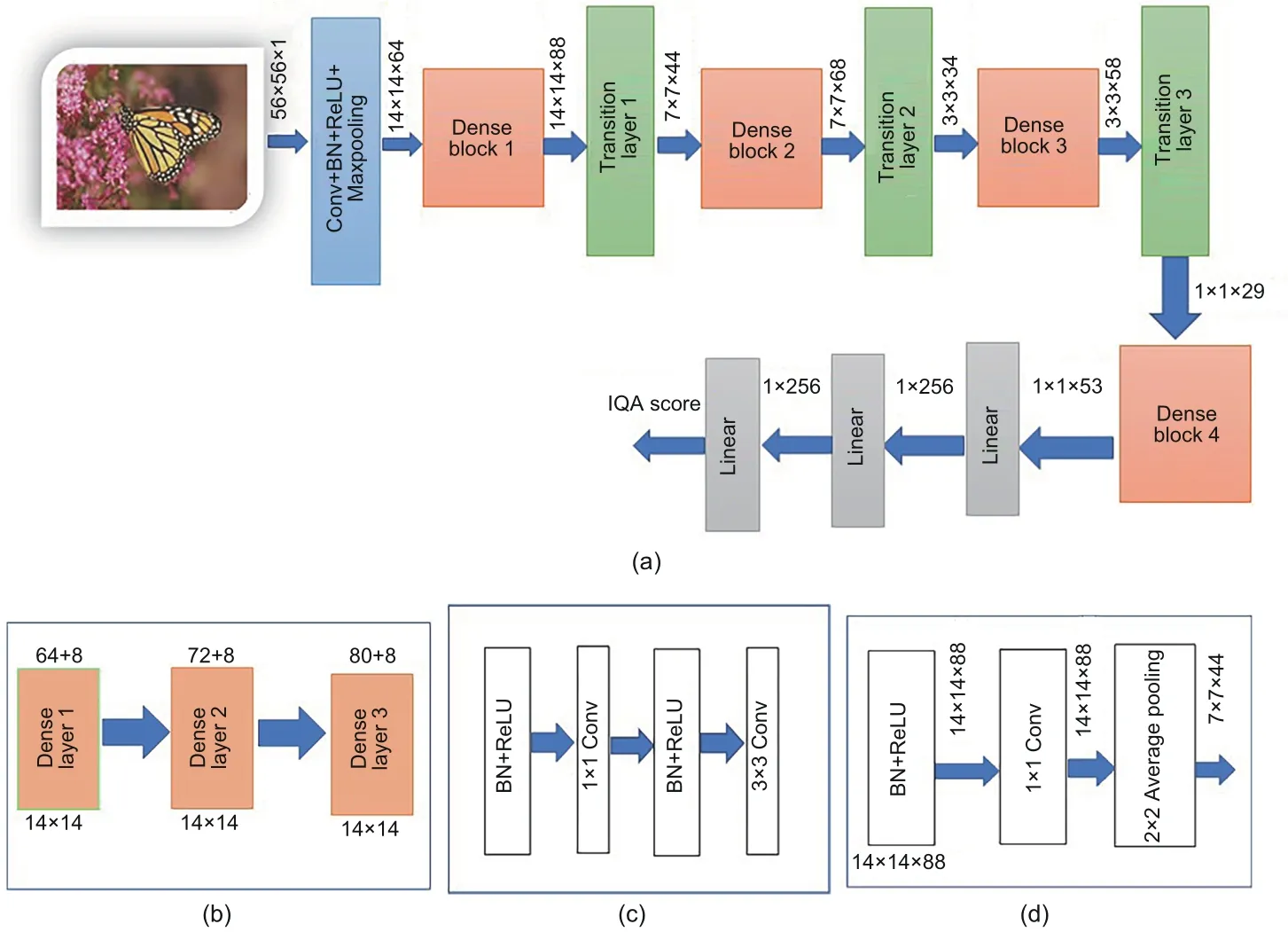
Fig.3 Spatial feature extraction using DSC-Net: (a) DSC-Net architecture; (b) structure of DenseBlock; (c)structure of dense layer; (d) structure of the transition layer
3.3 Texture feature extraction (α3)
In addition to the existing DSC-Net implementation, texture feature extraction and feature fusion are used in the MDSC-Net model.
The texture of an image is an attribute that represents the grouping of pixels based on their similarity.It also exhibits the structural arrangement of an image and can be used to recognize different objects.The texture characteristics are extracted using the GLCM method in the proposed research.GLCM is a second-order statistical approach that calculates the co-occurrence matrix by looking at how often pairs of pixels with the same intensity value appear in an image.Once the matrix is created,several statistical features related to textures can be derived.
The GLCMMwill be of sizeL×L,whereLis the number of gray levels in an imageIirrespective of the image size.The elementMφ(i,j)of the GLCM is expressed using Eq.(8):
wherepijrepresents the number of occurrences of gray levelitogether with gray leveljin nearest neighbor pixels either horizontally, vertically,or diagonally.φdefines the position relation between pixelsiandj(φ=(d,θ),ddecides the interpixel distance), andθdefines the orientation of the neighbor pixels in the four directions(0°,45°,90°,and 135°).
In the proposed work,the GLCM is constructed for each gray-scale image patchPi.Then, the five textural features, contrast, correlation, energy, homogeneity, and dissimilarity, as defined in Table 1 are derived from the GLCM for the four directions with interpixel distanced=1,2,and 3,and used for training.

Table 1 Texture features extracted using GLCM and their definition
In Table 1,Mijrefers to the element in the normalized co-occurrence matrix, andμiandμjare the averages calculated along rows and columns of matrixM, respectively.Similarly,σiandσjare standard deviations calculated along rows and columns, respectively.The detailed analysis of the texture features mentioned in Table 1 is discussed in the supplementary materials to show that the features extracted using GLCM can influence the performance.
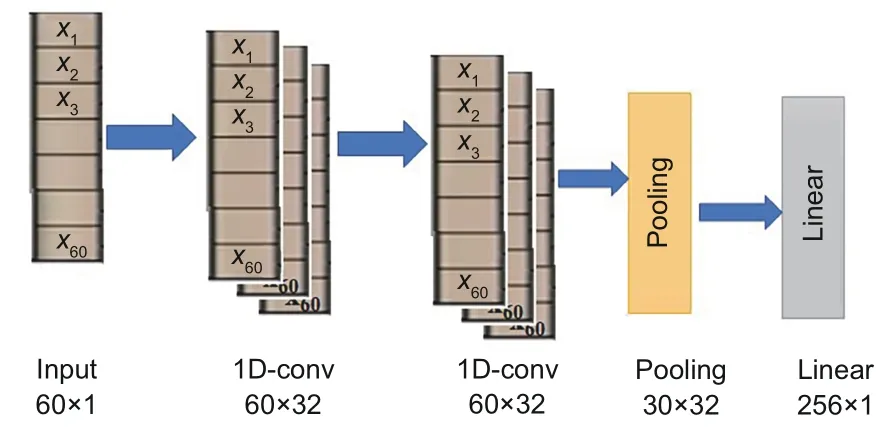
Fig.4 Texture feature extraction network
Once the texture features TFi ∈R60are extracted for each image patchPi, it is trained using one-dimensional convolution(1D-conv)to boost the performance of the image quality prediction as shown in Fig.4.It contains stacking two layers of 1D-conv filters, followed by a pooling and fully connected layer, which produces the output vector of dimensionFt∈R256with parametersβ2.rons.The previous layer is coupled with a regression layer that outputs the predicted visual quality score sqi.The input features are translated into a continuous target variable by the regression layer with a single-node neuron.The regression network is trained using the mean absolute error as the loss function that seeks to minimize the difference between the predicted and target variables.
4 Experiments
This section reports on the experiments designed to evaluate the proposed approach and compare it to other existing state-of-the-art approaches for NR-IQA.The experiments are conducted using Intel Core i7-9700K CPU with the NVIDIA GeForce RTX 2080Ti with 16 GB RAM and a 3.60 GHz processor, and the implementation is done using Python.The proposed framework uses the three large-scale benchmark IQA datasets, LIVE (Sheikh,2003), TID2013 (Ponomarenko et al., 2015), and KADID-10k (Lin HH et al., 2019).These three datasets contain images along with their MOS or differential MOS(DMOS) predicted by the observers.
3.4 Feature fusion and regression(α4)
The feature fusion and regression layer is implemented as part of the MDSC-Net model.Feature fusion is one of the major research components in modern deep learning architecture and is applied in various computer vision tasks like image recognition.The model becomes more robust by learning rich features from different forms of input.Spatial featuresFs∈R256and texture featuresFt∈R256are fused together in the proposed MDSC-Net model.A concatenation operation is used in the proposed feature fusion to build a more complete representation of the image.The spatial feature provides the pixel-level information,like edges,location,and the orientation of objects.The smoothness and roughness characteristics can then be retrieved using the texture features.These two sets of featuresFs,Ft∈R512have different characteristics and give precise details about the image, which improves the image quality prediction accuracy.The fused features are connected using a fully connected layer with 256 neu-
4.1 Experimental protocols
The two different proposed network architectures have been tested, and the performance is evaluated using standard evaluation metrics on the three benchmark datasets described in Section 4.
1.DSC-Net: the network uses spatial features derived using the simplified DenseNet architecture as described in Section 3.2.The input to the model isPiand the predicted visual quality score is represented using ˜q=ψ(Id;β1).
2.MDSC-Net: the network fuses texture features extracted using GLCM as described in Section 3.3, and features extracted from DSC-Net are concatenated and trained to predict the quality score ˜q.The model takes input as (Pi,TFi) and the output of the DSC-Net featureFs, and the predicted quality score can be formulated as ˜q=ψ(Id;β1,β2)
The proposed work uses the Spearman rankorder correlation coefficient (SROCC) and Pearson linear correlation coefficient(PLCC)to evaluate the performance of the model.
4.2 Training and testing strategy
The proposed network architectures mentioned in Section 4.1 are implemented using the PyTorch library.The entire dataset is split into training and testing by the ratio of 80:20.The training and testing sets are unrelated subsets of the dataset.All the different versions of the distorted images generated from a pristine image belong to either training or testing.During training,all patches are assigned the same quality score as their image MOS.The training phase of quality score estimation is given in Algorithm 1.The proposed network is trained to minimize the objective function so that the input image is expected to output a quality score that is as close to its MOS/DMOS values as possible.
The network is trained to minimize the loss function, which gives equal importance to each patch:
where∈is 1.The error calculated using the loss function is backpropagated,and gradient descent is used to update the model parametersβ1andβ2based on the magnitude of the loss.Adam, an adaptive optimization algorithm, is used in the proposed work to update the weights of the network with a learning rate of 1e-3.The first- and second-order moments equivalent to 0.9 and 0.999,respectively,are used to enhance the generalization ability of the network.
During testing, the image is cropped into nonoverlapping patches of size 56×56.For each patch,LCN is applied, and the texture features are extracted using the GLCM approach and given as the input to the trained model, which outputs the predicted quality score of that patch.The scalar average value is the final quality score of the input image.
4.3 Performance analysis
To evaluate the performance of the proposed work,experiments are conducted on LIVE,TID2013,and KADID-10k datasets.The IQA dataset contains images of varying resolution and the number of images in each dataset may vary.Each dataset will have different types of distortions.Because rescaling or resizing the image will affect the image quality,the proposed implementation augments the dataset by cropping the images with small patches.The network is trained 10 times with different samples

A lg: I orithm 1 Quality estimation learning 1mgD ←distorted training image dataset 2: Mqs ←MDSC-Net model 3: loop 4: do forward algorithm, yielding estimate Mqs 5: for each Idi ∈ImgD do 6: Pnop ←extract patches(Idi)7: for each patch Pi ∈Pnop do 8: Fpi ←LCN(patch)9: Fglcmi ←glcmFeat(patch)10: end for 11: end for 12: Mqs =customizeNet(DenseNet,GLCMNet)13: θ =[w,b] of Mqs 14: while i ≤maxepochs do 15: for i=0 to lenImgD do 16: ˆqsi =Mqs(Fpi,Fglcmi,mosi)17: compute loss Li =(ˆqsi,qsi)18: compute θi =Adam(Li,θ)19: update θ 20: end for 21: end while 22: end loop 23: return Mqs
each time and the result is reported by taking an average of those values to avoid bias.The evaluation results are grouped into traditional and DCNNbased approaches, and the results are reported in their respective papers.The PLCC and SROCC values for the proposed networks on the LIVE and TID2013 datasets are as shown in Table 2, and the top two results are in bold.The GLCM features with dimension R60performed well in terms of PLCC and SROCC in both datasets.MDSCNet has shown good performance compared to other models, which shows that GLCM features play a significant role in NR-IQA approaches.The proposed approach achieves comparable performance on both LIVE and TID2013 datasets.It is better than the DB-CNN (Zhang WX et al., 2020), which uses the pre-trained features and GAN-based RAN4IQA(Ren et al.,2018).The performance of the proposed method is slightly lower than those of AIGQA (Ma JP et al.,2021)and VCRNet(Pan et al.,2022)on the TID2013 dataset.Generally, the GAN-based models RAN4IQA (Ren et al., 2018), AIGQA (Ma JP et al., 2021), and VCRNet (Pan et al., 2022) have a large number of training parameters, so they take more training time and memory overhead.Overall, the proposed model can achieve state-of-the-artperformance in the LIVE and TID2013 datasets with less memory and less computation overhead.
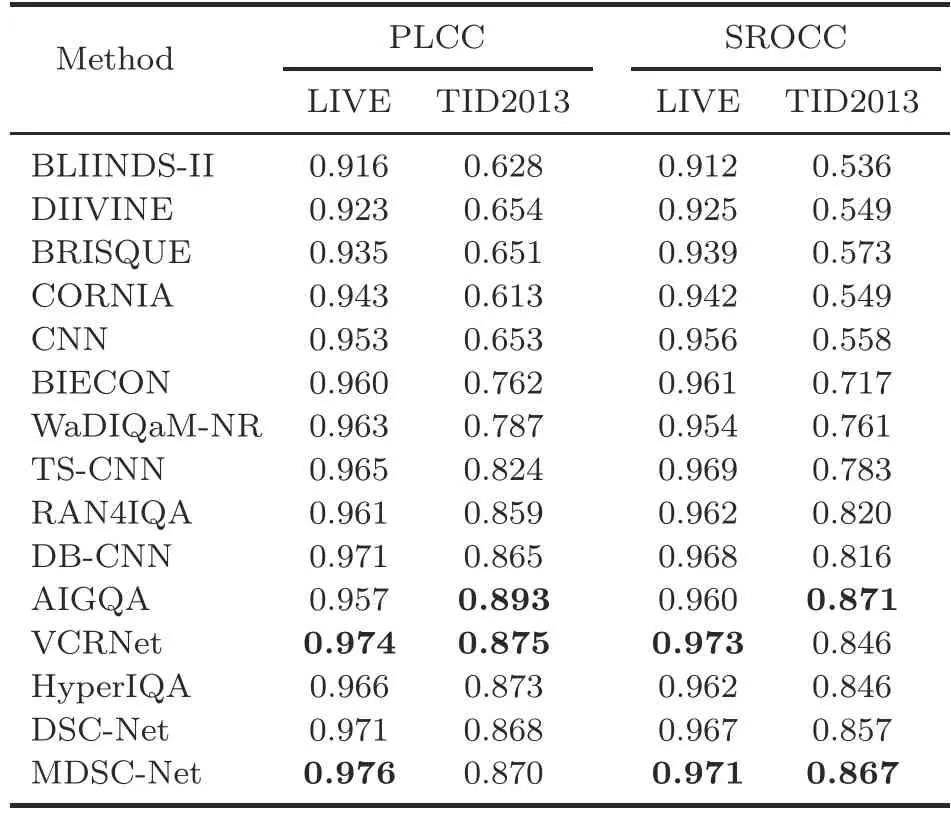
Table 2 PLCC and SROCC performance on the LIVE and TID2013 datasets
Because KADID-10k is a recent dataset, most of the approaches did not report their performances with that dataset.The performance of MDSC-Net on the KADID-10k dataset is given in Table 3.All the compared results are taken from Ma JP et al.(2021).The proposed method performs better than the GAN-based approach AIGQA (Ma JP et al.,2021)on the KADID-10k dataset, which uses active inference to learn the primary content and multistream prior information to predict the IQA score.In general, the proposed method works well on all synthetically distorted datasets, which verifies the effectiveness of the proposed approach.This performance improvement is mainly due to many images in the KADID-10k dataset, which helps the model effectively learn the features.
The objective of distortion specific experiments is to determine how well the proposed algorithm performs on images of a particular type of distortion.
The performance of SROCC and PLCC in the LIVE dataset is evaluated using the model that performs better during the training session.During distortion specific evaluation,all the images of that particular distortion are considered in the LIVE dataset.The resulting analysis for various distortion types is shown in Table 4.The proposed approach is compared with four traditional NR-IQA methods,DIVINE (Moorthy and Bovik, 2011), BLIINDS-II(Saad et al., 2012), BRISQUE (Mittal et al., 2012),and CORNIA (Ye et al., 2012), and deep learning based approaches like CNN(Kang et al.,2014),SOM(Zhang P et al.,2015),MEON(Ma KD et al.,2018),BIECON(Kim and Lee,2017)and DB-CNN(Zhang WX et al., 2020).It is also compared with the recently introduced NR-IQA method, NRVPD (Wu et al., 2019), which uses neighborhood correlation among the pixels to facilitate the quality prediction.The top three results from each distortion type are marked in bold.The performance of VCRNet (Pan et al., 2022)is relatively good, but the model size is larger, which makes it unsuitable for embedded devices like cameras.DSC-Net performs well in terms of SROCC for JPEG compression and WN distortions.It also has significant performance for WN in terms of PLCC.MDSC-Net achieves state-of-theart SROCC and PLCC values for JP2K,JPEG,and WN.SOM (Zhang P et al., 2015) performs well for BLUR and FF distortions in terms of both SROCC and PLCC.SOM augments the dataset based on the objectness measure and is trained with a large dataset.In summary,the proposed method performs well on distortions due to compression,which clearly shows that it is sensitive to capturing distortions related to compression artifacts.
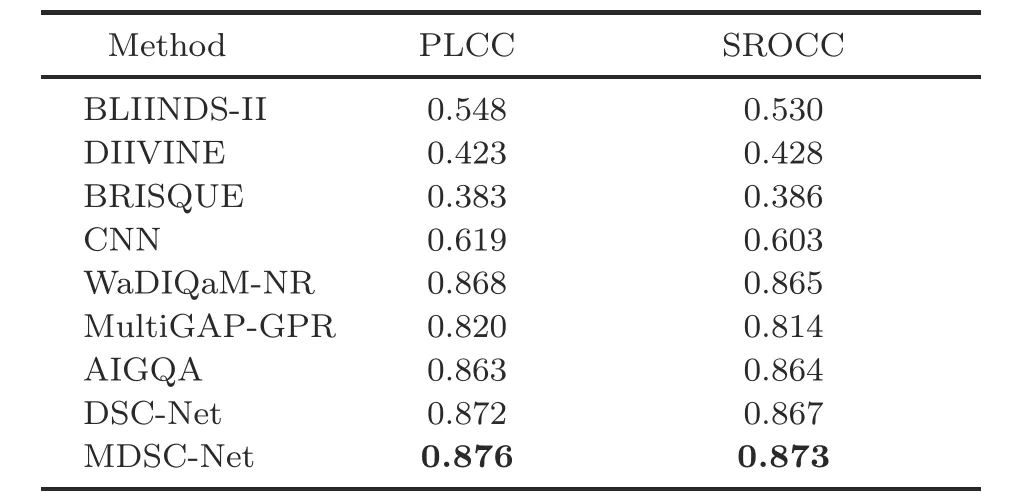
Table 3 Performance comparison on the KADID-10k dataset
The performance of the distortion specific experiments conducted with 24 types of synthetic distortions available in the TID2013 dataset is shown in Table 5, and the top two results are in bold.The results with respect to the challenging TID2013 dataset are diverse compared to those on the LIVE dataset.DSC-Net is able to capture the distortions related to additive gaussian noise (AGN), Gaussian blur(GB),image denoising(DEN),and transmissionerrors such as JGTE and J2TE well in TID2013 dataset.Moreover, MDSC-Net outperforms existing state-of-the-art RankIQA (Liu XL et al., 2017)and DB-CNN (Zhang WX et al., 2020)models, and uses pre-trained weights for different distortions in the TID2013 dataset.Particularly, the proposed method MDSC-Net is able to perform well on distortions introduced by spatially correlated noise(SCN),quantization noise (QN), and compression related distortions such as JPEG, sparse sampling and reconstruction (SSR), and change of color saturation(CCS),which clearly shows that it is sensitive to capture distortions related to spatial frequency.Most of the blind image quality assessment (BIQA) models fail to achieve reasonable performance on distortion types like non-eccentricity pattern noise(NEPN),local block-wise distortions (Block), and mean shift(MS).These results demonstrate that DenseNetbased architecture can improve the deep learning based NR-IQA performance, and GLCM features play a significant role in NR-IQA approaches.The performance of MDSC-Net on KADID-10k with different distortion types is shown in Fig.5,and the proposed approach performs well for all distortion types except color saturation 1 (CSA1), color shift (CS),color block (CB), and non-eccentric patch (NEP).The performance of the proposed model on TID2013 and KADID-10k with up to 25 distortion types is superior to other state-of-the-art solutions, which shows that the proposed MDSC-Net is capable of learning multiple distortions effectively.In general,the proposed method works well on all synthetically distorted datasets.
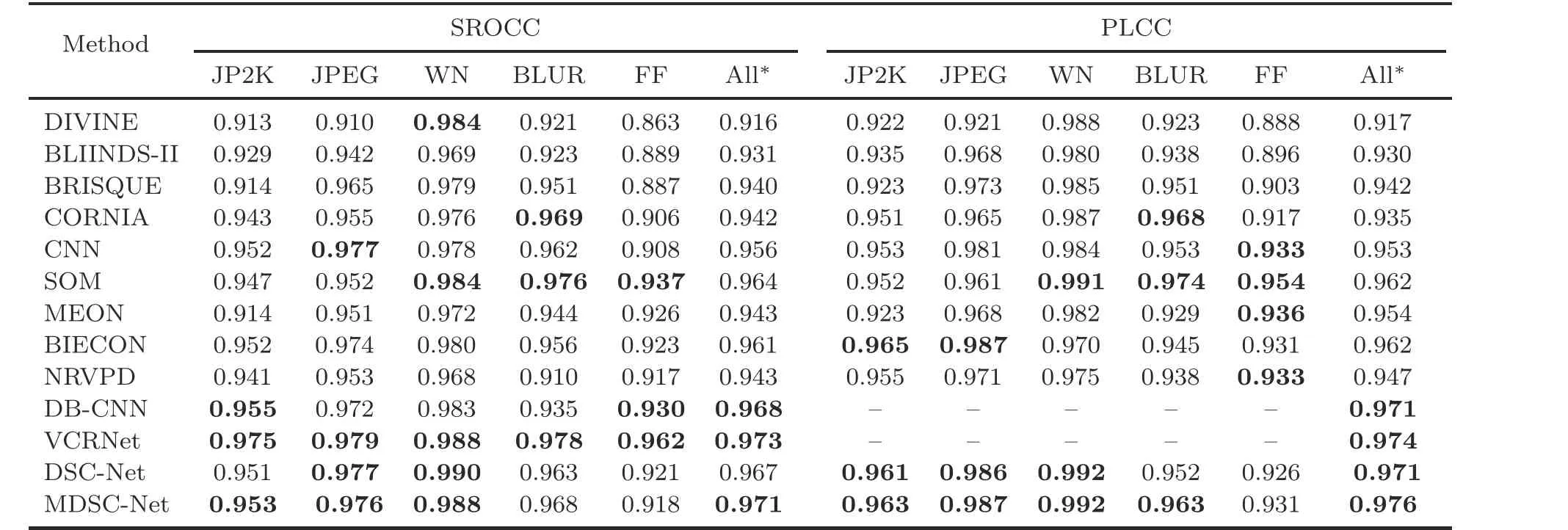
Table 4 Distortion specific comparison of SROCC and PLCC on the LIVE dataset
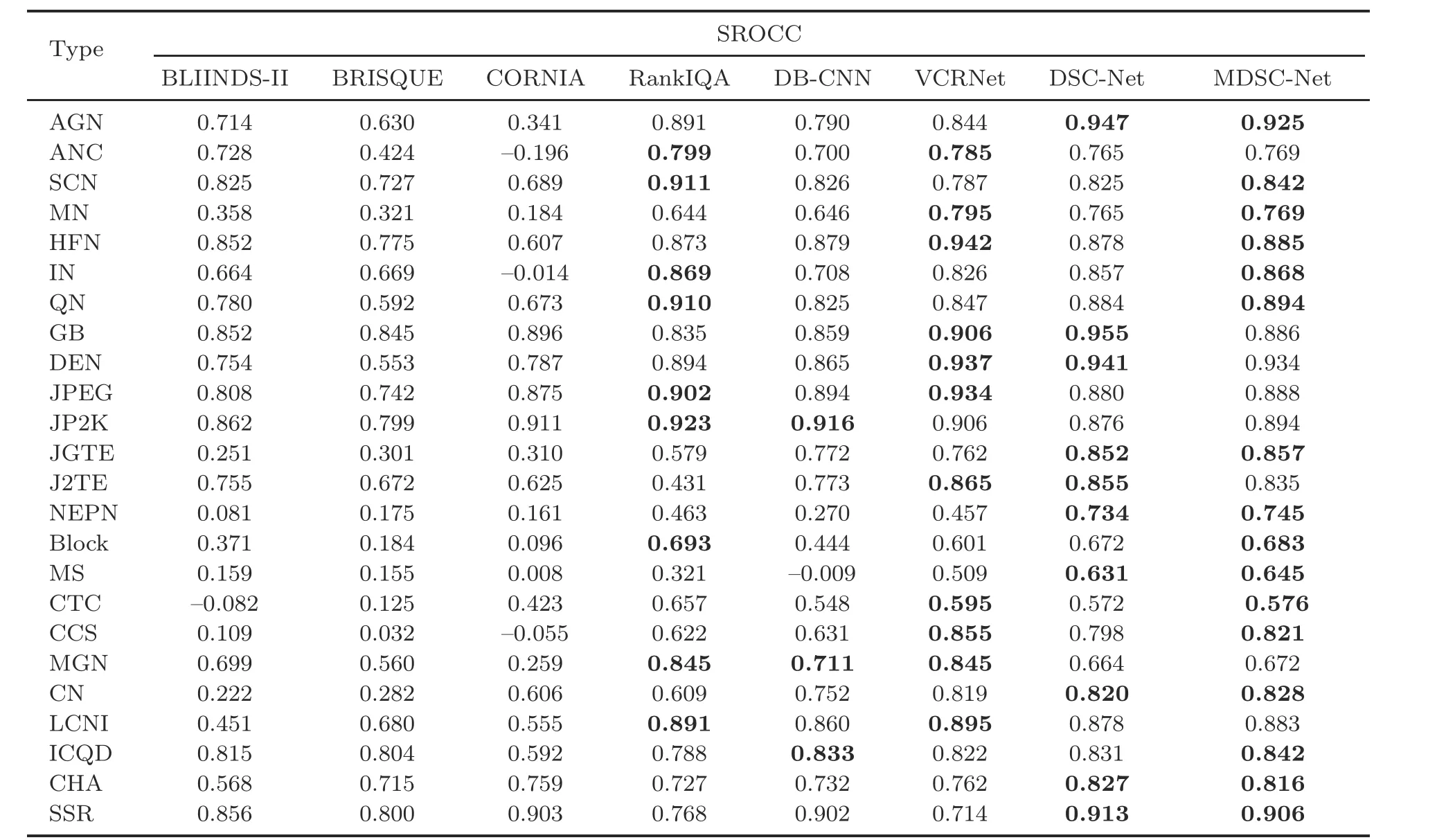
Table 5 SROCC comparison among different methods under different distortion types on the TID2013 dataset
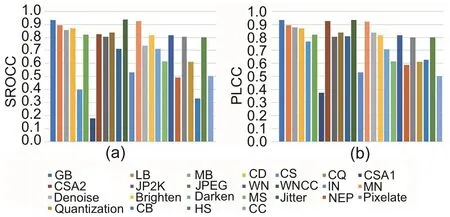
Fig.5 Distortion specific performance on the KADID-10k dataset: (a) Spearman rankorder correlation coefficient (SROCC); (b) Pearson linear correlation coefficient (PLCC)
4.4 Cross-dataset evaluation
To evaluate the generalization performance,the model trained on one dataset is used to test on the remaining datasets as shown in Table 6.The MDSCNet model trained on the LIVE dataset is evaluated on the TID2013/KADID-10k dataset.The five distortion types in the LIVE dataset are only parts of the 24/25 distortion types in another dataset.The remaining distortion types are not included in the training data.The proposed model is tested on the full set.Moreover, both MOS and DMOS have different ranges and meanings, and hence logistic regression is added to match the quality scores predicted by the network.The cross-dataset evaluation is repeated for other datasets in a similar manner.It is observed from Table 6 that the cross-dataset evaluation on the LIVE dataset, which is trained on TID2013/KADID-10k,is superior, because it learns from known distortion types.The generalization capability of the KADID-10k model is superior to those of the other models due to the larger size of the dataset.
The cross-dataset comparison is done by training on LIVE and testing on the full set of TID2013 and vice versa, and the proposed MDSC-Net has state-of-the-art generalization ability.The crossdataset results are shown in Table 7, and the proposed method achieves competitive results and performs above state-of-the-art results.It can be concluded that the proposed model is more robust and able to perform well on unknown images.The proposed method performs significantly better, because it extracts all the salient patches and learns more significant features to predict the image quality.

Table 6 SROCC results of cross dataset evaluation
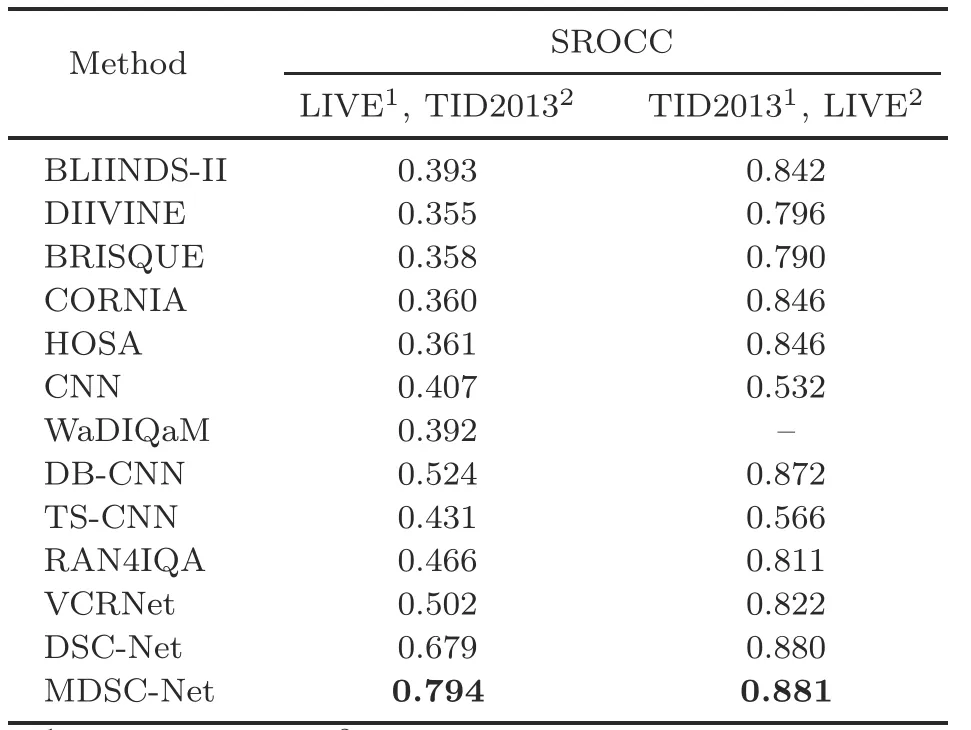
Table 7 Cross-dataset comparison of SROCC
4.5 Algorithm complexity
The informal analysis,to determine the speed of the proposed system prediction, is discussed in this subsection.Let imageIdbe cropped intoNppatches of sizewp×hp.Tlcnis the time taken to obtain the LCN image for a patch of sizewp×hp,Tglcmis the time taken to extract the texture features using a GLCM for a patch, andTpredis the time taken to predict the image quality for allNppatches using the proposed trained model.The time taken to predict the quality of imageIdisO((Np×(Tlcn+Tglcm))+Tpred).An image of resolution 512×384 is cropped into 54 patches,each of size 56×56.The time taken to extract features for MDSC-Net is about 1.04 s includingTlcnandTglcmfor all patches and for DSCNet withTlcnof 0.06 s,which is negligible.DSC-Net is faster than other models, which implies that the GLCM feature extraction step is time consuming.For the above analysis, the time used for feature extraction is the only time considered, beause the time for loading the pre-trained model and prediction time are negligible.
4.6 Effect of trainable parameters
The model parameters are computed for the proposed work,and the comparison with state-of-the-art methods is shown in Table 8.DSC-Net has fewer parameters compared to MDSC-Net.The added GLCM feature network adds more parameters to MDSC-Net due to the fully connected layers.Due to dense connections and bottleneck layers in the proposed work,the number of parameters is reduced significantly, which avoids overfitting and reduces the training time.The BIECON (Kim and Lee, 2017)model has slightly lower SROCC,but the model size is almost 7 times that of MDSC-Net.The VCRNet(Pan et al.,2022)model has a slightly higher SROCC value,but there are significantly more parameters to train than for DSC-Net.CNN++(Kang et al.,2015)and MEON (Ma KD et al., 2018) have fewer parameters, but the SROCC value is lower compared to that of DSC-Net.Hence, the proposed MDSCNet achieves state-of-the-art performance with fewer parameters.
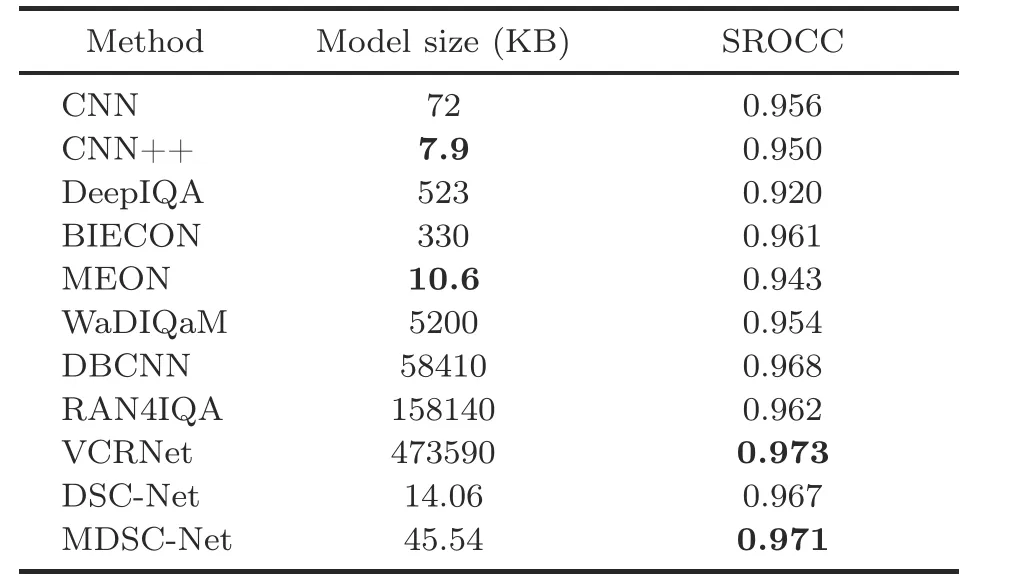
Table 8 Comparison of trainable parameters and SROCC on the LIVE dataset
5 Conclusions
A multimodal simplified DenseNet-based model is proposed for the NR-IQA problem,which demonstrates good performance.The proposed DSC-Net network with more layers promotes feature reuse with fewer parameters,which makes the model more appealing for spatial feature extraction.The GLCM features fused with DSC-Net significantly increase the model performance.The proposed algorithm has shown good performance on the LIVE,TID2013,and KADID-10k datasets and demonstrates high consistency with human-perceived quality.The crossdataset evaluation has shown good generalization capability of the proposed approach and is found to be efficient over state-of-the-art NR-IQA algorithms.The current work deals with IQA for synthetic distortion.The possible future direction will be designing a unified NR-IQA method that deals with both authentic and synthetically distorted images.Furthermore, the MDSC-Net based approach may be used in other image processing tasks that deal with the perceptual attributes of the images,such as image restoration and image enhancement.In the future, hardware implementation of the proposed model will be realized to integrate it in realtime applications such as surveillance cameras.The other possible future direction of this work can be a video quality assessment to address issues related to motion, frame rate, and compression artifacts.It can also be extended to focus on applications such as medical quality assessment or social media image quality.Further research is needed to enhance the knowledge behind IQA and its relationship to neuroscience,which may provide new insights.
Contributors
Nandhini CHOCKALINGAM designed the research,processed the data, and drafted the paper.Brindha MURUGAN helped organize and revise the paper.Nandhini CHOCKALINGAM and Brindha MURUGAN finalized the paper.
Compliance with ethics guidelines
Nandhini CHOCKALINGAM and Brindha MURUGAN declare that they have no conflict of interest.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
 Frontiers of Information Technology & Electronic Engineering2023年11期
Frontiers of Information Technology & Electronic Engineering2023年11期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Magnetically driven microrobots moving in a flow:a review*#
- Embedding expert demonstrations into clustering buffer for effective deep reinforcement learning*
- A hybrid-model optimization algorithm based on the Gaussian process and particle swarm optimization for mixed-variable CNN hyperparameter automatic search*
- A high-isolation coupled-fed building block for metal-rimmed 5G smartphones*
- Dynamic parameterized learning for unsupervised domain adaptation*
- High-emitter identification for heavy-duty vehicles by temporal optimization LSTM and an adaptive dynamic threshold*#