
类别平衡调制的人脸表情识别
2023-12-08 11:49刘成广王善敏刘青山
计算机与生活 2023年12期
刘成广,王善敏,刘青山+
1.南京信息工程大学 计算机学院,南京 210044
2.南京信息工程大学 数字取证教育部工程研究中心,南京 210044
3.南京航空航天大学 计算机科学与技术学院,南京 211106
面部表情是人类传达情感信息的最直接方式[1-2]。自动的人脸表情识别(facial expression recognition,FER)有着广泛的应用,如人机交互[3]、心理健康问诊[4]、疲劳驾驶检测[5]等。近年来,由于大型数据集的出现,基于深度学习的表情识别技术取得了较大进展。然而,与实验室环境下采集的数据集(例如CK+[6]、MMI[7]和JAFFE[8])相比,自然场景下采集的数据集存在明显的类别不平衡问题[9-11]。图1 展示了RAF-DB 数据集各类别样本的分布和对应的识别精度。数据分布不平衡导致了模型对各类表情的识别精度差异较大。具体地,模型对样本量大的类别识别精度较高,而对样本量少的类别识别精度较低。
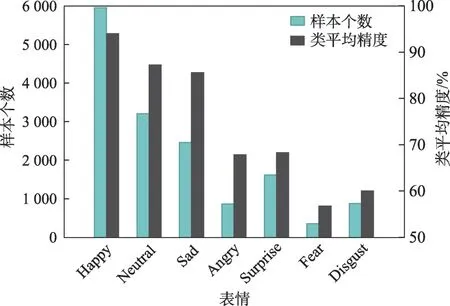
图1 类别不平衡示例图Fig.1 Example of class imbalance
为了解决类别不平衡问题,常用的方案通常统计数据集中各类别的样本分布,对样本进行重采样(re-sampling)[12-15]或重加权(re-weighting)[16-20]。重采样的方式通过数据增强对少样本类别进行上采样,或者对多样本类别进行随机删除的下采样。然而上采样没有给模型带来更多实质性的信息,下采样明显减少了模型的训练数据。因此,重采样的方法没有从本质上解决表情识别任务中样本不平衡的问题。重加权的方法依据类别样本数或样本容量[21],对样本反向加权,强化少样本类别的学习[16-17]。但是,研究表明,图像的特征分布和类别的标注分布是不耦合的[22-23],用类别的分布影响表征学习时的特征分布是不合适的。因此,将图像表征学习和分类器优化过程联合调制的重加权方法,不仅没有平衡各类别的特征分布,而且会影响图像表征的正常学习过程。
为此,本文将图像表征学习和分类器优化过程分离,提出了一种新的类别平衡调制的人脸表情识别方法(class-balanced modulation mechanism for facial expression recognition,CBM-Net),以解决数据不平衡导致的特征分布不平衡和分类器优化不平衡问题。具体地,分别设计了特征调制和梯度调制两个模块。特征调制模块通过增加类间的方向可分性,进而确保模型可以提取出小类样本的区分性特征,使得不同类别在特征分布上保持平衡。梯度调制模块利用每批次训练样本的统计信息来调节各类别分类器的梯度,使得样本数较少的类获得更多优化,获得足够的训练尝试,而不影响其他的类。为了验证该方法的有效性,本文在RAF-DB[9]、AffectNet[10]、SFEW[24]和CAER-S[25]四个流行的数据集上进行了实验。定性和定量结果都证明了CBM-Net在解决类别分布不平衡问题上的合理性和优越性。
本文工作的主要贡献总结如下:
(1)提出了一种类别平衡调制的人脸表情识别方法,该方法从特征调制和分类器梯度调制两方面解决类别不平衡问题。
(2)设计了一个特征调制模块来保证特征间的类别可分性,进而解决类别不平衡导致的表情特征分布不平衡的问题。
(3)设计了一个梯度调制模块对分类器的优化过程进行调制,进而解决分类器中收敛速度不一致的问题。
1 相关工作
对类别不平衡问题的现有解决方案可以被分为两类:数据层面的重采样[12-15]和算法层面的权重分配[16-20]。
1.1 重采样
重采样的方法分为上采样和下采样两种。上采样主要是对较小的类进行数据增强,以获得更多的样本[12-13]。然而,上采样方式虽然增加了较小类的样本数,但是完全依赖于数据增强的方式。通过旋转、剪切、平移等简单数据增强式获得的上采样样本与原数据可能高度相似,对模型的训练并没有本质的性能提升[21]。通过生成模型(generative adversarial networks,GAN)来实现数据增强的方式,较难生成细粒度的表情图像。下采样主要是从较大的类中随机选择较少的样本用于训练,以平衡不同类的样本量。然而,这种方式可能使得参与学习的有用信息减少,最终影响模型的学习性能。
1.2 重加权
重加权的方法常常为小类样本在损失函数上赋予高权重,使其获得更多的优化。各类别权重的计算方式主要分为统计样本量占比[16-17]以及评估样本难度两种方式[18-20]。目前,统计样本量占比的方法获得了广泛的应用。通常,分配的权重与该类样本数成反比。此外,评估样本难度的方法认为来自小类的样本往往比来自大类的样本更难学习,因为小类的样本的表征学习更差。更难学习即预测损失函数值很大,将损失值作为样本的权重[20]。部分工作[26-27]认为样本难度与样本数量之间没有直接关系。由于图像的特征分布和类别的标注分布不耦合的本质[22],利用分配权重的损失函数将影响模型对图像的表征学习,并没有为图像表征过程带来更多的提升,各类别的特征分布仍然是不平衡的。为此,采用两阶段,将图像表征阶段与分类器调制阶段分离的平衡调制方式值得考虑。
2 本文方法
2.1 不平衡问题分析
人脸表情识别旨在对人脸图片提取表情特征,并推断表情的类别。具体来说,给定训练数据集为其中,xi,yi分别是训练样本和标签。yi∈{1,2,…,C},C为表情类别数。N为样本总数。针对训练样本(xi,yi),首先,使用CNN 的骨干网络φ(·)提取图像的特征,提取过程表示如下:
其中,θ为骨干网络参数。fi∈RM,M为特征维度。当类别不平衡时,由于小类样本数量较少,在特征质量上也难以有与大类明显区分的关键性特征,致使小类样本的特征与大类样本特征区分不明显,分布不平衡,不利于后续分类。
在获得图像的特征fi后,使用线性分类器建立特征fi到各类别预测概率p的映射,取概率值最大的类别作为样本的预测表情y′。各类别预测概率p计算如下:
其中,p(xi)∈RC。W为分类器最后一层线性参数,W∈RM×C。b为偏置项,b∈RC。预测表情y′=argmax(p)。根据输入特征与各类别预测概率的对应关系,分类器W可进一步表示为W=[w1,w2,…,wC]。设该样本xi属于第c类,将第c类的逻辑输出表示为p(xi)c,则xi的损失为L=-lb(p(xi)c)=-lb(fi∙wc)。当模型根据样本xi计算的损失函数优化分类器参数时,W的参数更新如下:
其中,η为学习率。由于xi的标签为yi属于第c类,损失反传W梯度为:
即当样本xi属于第c类时,损失反传仅更新第c类的权重wc。设训练集中各类样本数为[N1,N2,…,Nc,…,NC],其中,则交叉熵损失函数为:
2.2 方法概述
为了解决类别不平衡导致的特征分布不平衡和分类器优化不平衡的问题,本文提出了一种类别平衡调制的人脸表情识别方法(CBM-Net)。如图2 所示,CBM-Net 包括常规的深度学习骨干网络以及特征调制和梯度调制两个分支模块。CBM-Net 输入为一批人脸表情图像,输出为对应的预测表情y′。为了应对数据不平衡情况,本文将图像的表征阶段与分类器调制阶段分离。具体地,在反向的调制过程中,分别应用特征调制和梯度调制模块优化特征分布和分类器参数。首先,针对骨干网络提取的样本特征fi,通过最大化类间的方向性,进而确保模型可以提取出小类样本的区分性特征,使得不同类在特征分布上保持平衡。其次,针对输出概率p,计算其与标签y的交叉熵获得分类器梯度,利用批次样本统计信息k来调节分类器梯度,使得欠优化的小类获得更多的优化。

图2 网络框架图Fig.2 Network framework diagram
2.3 特征调制模块
特征调制模块作用于图像表征阶段,通过约束类间特征的方向性,进而确保样本不平衡的类在特征分布上保持平衡。该模块的核心是特征调制损失LFM。受文献[28]启发,LFM依据特征的相似性,增加类间距离的同时,减少了类内距离。
对于给定的两个样本xi和xj,其特征分别为fi和fj,通过余弦相似度计算它们之间的特征相似性,即:
特征调制损失LFM可以表示如下:
其中,Nyi是属于yi类的样本数,是剩余类的样本数,满足,i,j是索引。
2.4 梯度调制模块
如前所述,模型的优化过程通常由大类主导控制,从而小类的性能未能充分优化。为了解决该问题,梯度调制模块作用于分类器调制阶段,其利用批次样本的统计信息来调节各类别梯度,使得小类获得更多的优化。为简单理解,以第c类为例。在第t批次中,定义为该批次第c类样本数,c∈{1,2,…,C},C是表情类别数。Nt为该批次样本总数。定义样本比
即样本数越少,该类在当前批次将获得更多优化。为自适应调节梯度,设计梯度权重:
其中,a是控制调制程度的超参数。将系数整合到SGD(stochastic gradient descent)优化方法中,更新分类器第c类梯度,更新如下:
2.5 损失函数
在训练过程中,CBM-Net 有两个约束函数,分别是交叉熵损失函数LCE以及特征调制函数LFM。
综上,本文所采用的损失函数为:
λ为平衡超参数。
3 实验分析
3.1 实验数据
RAF-DB[9]:包含了30 000 张带有基本或复合注释的表情图片。在实验中,为了对比公平,本文仅使用数据集中的7 种基本表情,包括6 种离散的基本表情和1种中性表情。
AffectNet[10]:从搜索引擎中查询与情感相关关键词收集的100 多万张图像,是目前公开可用的最大FER数据集。其中,超过44万张图像被手动标注为8种表情(7种基本表情+蔑视)。本文使用28万个训练样本和4 万个测试样本,分别在7 种基本表情和包括蔑视的8种表情上进行实验。
SFEW[24]:采集于同一个电影的静态图片,并被标注为了7 种基本情绪。被划分为了958 张训练图片和436张测试图片。
CAER-S[25]:基于CAER 选择的视频静态帧获得的数据集。该数据集被独立注释为7 类基本表情,包含65 983 张图像,其中44 996 张图像用于训练,20 987 张图像用于测试。
3.2 实验设计
(1)预处理和面部特征。在CBM-Net 中,图像通过RetinaFace[29]进行人脸检测和对齐,并通过数据预处理进一步调整为224×224 像素。CBM-Net 由Pytorch实现,主干网为ResNet18[30],从主干网最后一个池化层提取512 维特征。随后,特征由512 维降低到10 维。数据预处理过程包括基础性数据增强和标准化。在与各种最先进的方法进行比较时,主干网ResNet-18 在MS-Celeb-1M[31]人脸识别数据集上进行预训练。
(2)训练。本文使用1 个Nvidia Titan 2080s GPU以端到端的方式训练CBM-Net,并将批量大小设置为128。整个网络采用LFM和LCE联合优化。
3.3 消融实验
3.3.1 评估CBM-Net的不同模块
为验证本文提出的各模块的有效性,设计了一项消融研究以评估CBM-Net 中不同模块的准确率。如表1,包括骨干网络、特征调制模块和梯度调制模块。分别从不同模块组合的效果进行分析,以证明网络整体设计的有效性。为了更好地展示实验效果,CBM-Net 采用的主干网络不通过预训练,而是从头开始训练,并对最优结果进行加粗展示。
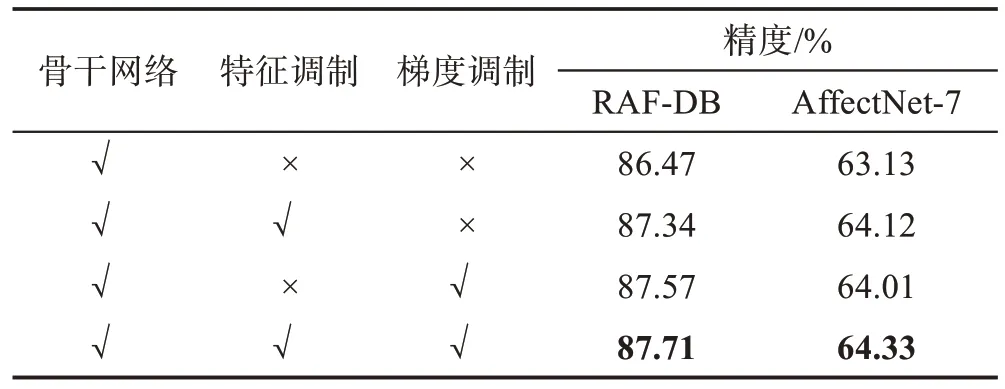
表1 CBM-Net中两个模块的评估Table 1 Evaluation of two modules in CBM-Net
从表1 可以直观地观察到,在RAF-DB 和AffectNet-7 数据集上,仅使用特征调制时,精度分别比基础提高了0.87 个百分点和0.99 个百分点;仅使用梯度调制时,精度分别比基础提高了1.1 个百分点和0.88 个百分点。这表明了本文提出的各模块的确有效。最终,CBM-Net 在没有预训练的情况下,在数据集RAF-DB 和AffectNet-7 上分别达到了87.71%和64.33%的精度。
3.3.2 评估CBM-Net中各模块类平均精度
为了进一步验证各模块解决类别不平衡问题的能力,本文使用各模块与仅使用ResNet-18 作为主干网络的类平均精度对比,以定量地测试各模块对尾部类的性能影响,直观地展示各模块的类别平衡调制效果。其中,在最有代表性的RAF-DB数据集上进行实验,对梯度调制模块中的超参数a进行多次不同赋值测试,以挑选最合适超参数a。最后,将两模块共同使用,以探索CBM-Net 的类平衡效果。为了更好地展示对比效果,网络不通过预训练。
如表2,可以直观地观察到,在样本量较少的类Fear、Disgust 和Angry(加粗行),类平均精度均得到了明显的提升,这表明了CBM-Net 中各模块在解决类别不平衡问题的有效性。其中,当a设置为0.5时,梯度调制效果提升最为显著,为了方便后续实验,当批次大小为128时,本文将a统一设置为0.5。最终报告的结果也受a为0.5的限制。

表2 各模块在RAF-DB数据集上的类平均精度Table 2 Class average accuracy of each module on RAF-DB dataset 单位:%
3.3.3 评估损失函数的平衡超参数λ
超参数λ控制着分类交叉熵损失函数LCE以及特征调制函数LFM在训练过程中的占比,为此,依次选取不同的λ取值进行实验,以探索λ对CBM-Net的影响。同理,网络不通过预训练。
图3 展示了超参数λ对CBM-Net 的影响,很明显,过大或过小的选取都会降低CBM-Net 的性能。当λ在0.8 到1.2 的范围,网络可以获得良好的性能。在后续实验中,本文将λ统一设置为1.0。
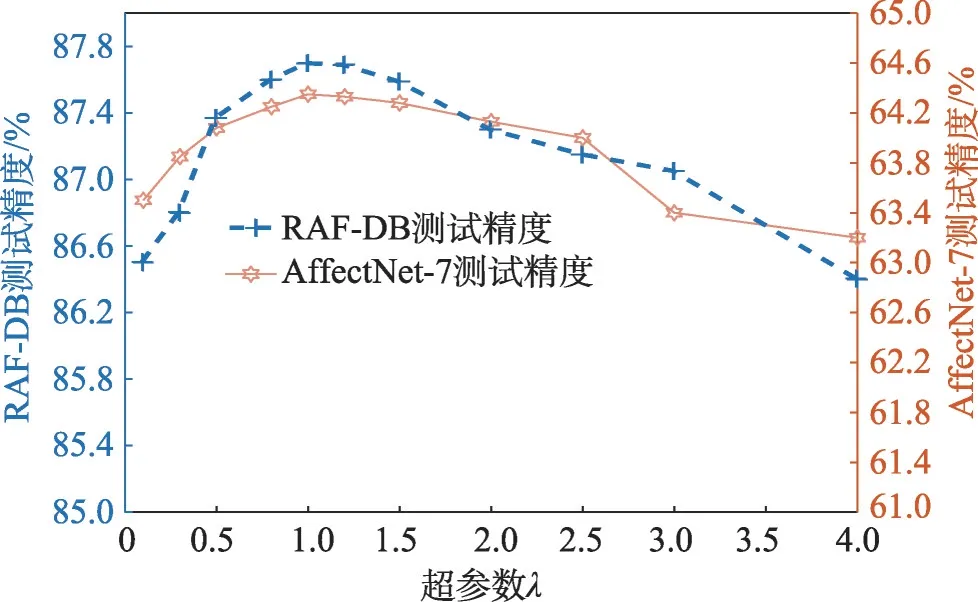
图3 损失函数的平衡超参数λ评估Fig.3 Evaluation on hyperparameter λ of loss function
3.4 特征调制模块的效果可视化
为了直观展示特征调制模块效果,本节采用TSNE(T-distributed stochastic neighbor embedding)[32]方法对骨干网络提取的图像特征进行可视化。为了比较公平,模型统一采用了在数据集MS-Celeb-1M预训练的ResNet-18 作为主干网络,在RAF-DB 测试集上进行可视化比较。图4(a)显示了仅使用分类损失LCE作为训练约束的特征分布结果。图4(b)显示了除了分类损失LCE之外,还添加了特征调制模块的LFM作为约束的特征分布结果。

图4 特征调制效果可视化示意图Fig.4 Diagram of feature modulation effect visualization
图4(b)展示的带特征调制模块的效果,很明显,最大化类间方向间隔约束使得较小的类也获得更有差异性的特征,不同类在空间分布上保持了平衡。
3.5 梯度调制模块的效果可视化
为了直观展示梯度调制模块的效果,本节对训练迭代过程中RAF-DB 测试集的类平均精度进行了可视化。模型不通过预训练,不使用特征调制模块,直接在ResNet-18的骨干网络下选择是否使用梯度调制模块,以体现本文设计的梯度调制优势。图5(a)显示了仅使用ResNet-18 作为模型的类平均精度随epoch的收敛过程。图5(b)显示了除了ResNet-18 之外,还添加了梯度调制模块的各类收敛过程。
相较于图5(a)展示的无梯度调制的效果,很明显,图5(b)中带梯度调制的较小类优化更快地得到了收敛。各类的收敛速率更加协调,分类器的优化得到了平衡。此外,较小类的类平均精度得到显著提升,致使总体的平均精度得到提升,这与表2 中的结论一致。
3.6 与常规类平衡方法对比
本文设计了一项对比实验,统一使用ResNet-18作为骨干网络,在同样使用本文提出的特征调制损失LFM的前提条件下,将本文的梯度调制方法与使用不同的权重分配方法进行对比,以探索本文提出的梯度调制方法的有效性。如表3,使用权重分配的方法包括常规的带权交叉熵损失函数(W-CE)以及Focal Loss[20]。为了更好地展示对比效果,网络从头进行训练,不通过预训练,并对最优结果进行加粗展示。
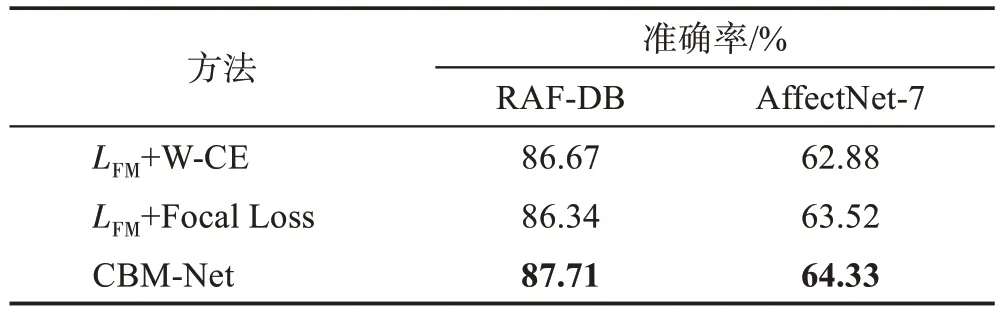
表3 CBM-Net与常规类平衡方法的对比Table 3 Comparison between CBM-Net and conventional class balance methods
从表3可以直观地观察到,在相同实验设置的前提下,本文的梯度调制方法比常规的带权重的交叉熵损失以及Focal Loss 效果更好。优异的对比性能得益于本文提出的两阶段的类别平衡调制方法,即分别对特征和分类器进行调制。而直接作用于最终分类损失的类平衡方式影响了模型对图像的表征学习,进而影响了分类器分类性能,这也从侧面印证了本文将图像表征阶段与分类器调制阶段分离的合理性。
3.7 与最先进的方法对比
为了进一步展示CBM-Net 的优越性,本节将CBM-Net 在RAF-DB、SFEW、CAER-S 和AffectNet数据集上与最先进的方法进行定量实验对比,如表4、表5和表6所示。最先进的方法包括SCN(self-cure network)[33]、EfficientFace[34]和DAN(distract your attention network)[37]等方法。SCN通过设计鲁棒损失函数抑制不确定样本参与网络训练。Efficient-Face 使用通道注意力以及标签分布学习监督网络训练。DAN的代码可以获得,因此在相同的设置上复现了该算法,但重新实现的结果和报告的结果有一定的差距,这可能是由于不同的数据预处理和运行环境带来的影响。为了公平,本实验采用相同的设置,复现的结果用星号“*”在表中单独标出。CAER-S 数据集比较新颖,在此上的研究比较少,因此DAN[37]和Res2Net-50[40]的结果由复现提供。ADDL(adaptive deep disturbance-disentangled learning)[36]在数据集Multi-Pie[43]上进行了预训练,DAN、Efficient-Face、SCN 和DMEU(latent distribution mining and pairwise uncertainty estimation)[27]在MS-Celeb-1M 数据集[31]上进行了预训练。CBM-Net 和大多数经典算法一样采用的MSCeleb-1M数据集预训练方式。

表4 与最先进的方法精度对比Table 4 Precision comparison with state-of-the-art methods
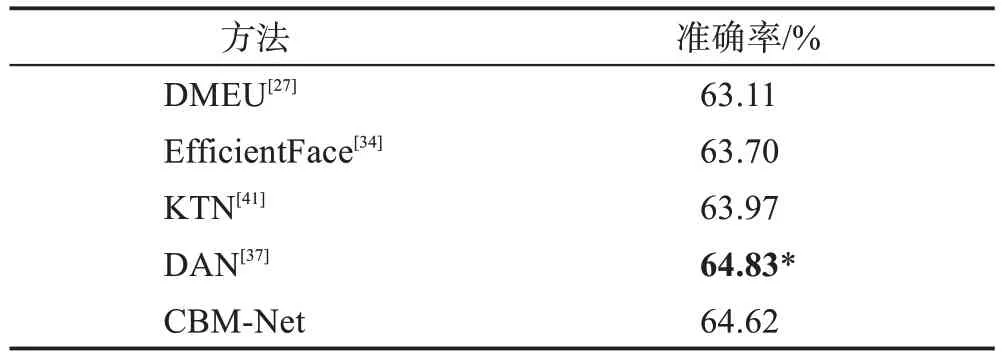
表5 AffectNet-7数据集上与最先进的方法对比Table 5 Comparison with state-of-the-art methods on AffectNet-7 dataset

表6 AffectNet-8数据集上与最先进的方法对比Table 6 Comparison with state-of-the-art methods on AffectNet-8 dataset
表4 给出了RAF-DB、SFEW 和CAER-S 数据集上的定量比较结果。如表4,在经典的RAF-DB 数据集上,CBM-Net 取得了与最先进的一些方法几乎持平的结果。在SFEW 和CAER-S 数据集上,CBM-Net都取得了最好的效果,分别为60.32%和86.52%。对比的方法都没有针对类别不平衡问题设计方法,而精度的巨大提高,也进一步说明在自然场景下采集的数据集需要进行类平衡调制。表5 和表6 给出了AffectNet-7 和AffectNet-8 数据集上的比较结果,CBM-Net 在这些基准测试中同样获得了不错的表现。值得注意的是,RAF-DB 与AffectNet 均为经典数据集,为了提高识别精度,当前最先进的方法几乎均采用了大网络或设计特殊的注意力方法,如EfficientFace 与DAN。而CBM-Net 仅采用最基本的ResNet-18 模型,在增加有限的计算量和模型参数的基础上,对各类别特征和分类器进行调制,带来了性能大幅度的提升。一方面证明了数据分布不平衡问题确实对模型性能产生了负面的影响,另一方面证明了本文提出的类别平衡方法的有效性。
4 结束语
本文分析了人脸表情识别(FER)中的类别不平衡问题,并提出分别从图像表征阶段与分类器调制阶段来解决这个问题。因此,本文提出了一种类别平衡调制的人脸表情识别方法(CBM-Net),设计了特征调制和梯度调制两个模块。具体的,特征调制模块对图像提取过程进行调制,确保不同类在特征分布上保持平衡。梯度调制模块对分类器梯度进行调制,使得欠优化的小类获得更多的优化。在四个公共数据集上的实验验证了所提出的CBM-Net的有效性和优越性。然而,CBM-Net 可能存在的问题是没有脱离权重分配方法范畴,默认了类样本数量等价于类别的信息量。然而,已经有工作指出[21],类别信息的增量随着样本数量的增加而减少,即同类样本存在信息冗余的情况。因此,下一步将着重研究样本数量与类信息量的具体关系,来调制各类别分布。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
电子测试(2018年1期)2018-04-18
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
电测与仪表(2014年15期)2014-04-04
中国中医药现代远程教育(2014年16期)2014-03-01
