
片段级别的双编码器方面情感三元组抽取模型
2023-12-08 11:49张韵琪李松达兰于权李东旭
计算机与生活 2023年12期
张韵琪,李松达,兰于权,李东旭,赵 慧,2+
1.华东师范大学 软件工程学院,上海 200062
2.华东师范大学 上海市高可信计算重点实验室,上海 200062
对于商家而言,满足顾客日益增长的需求对抢占市场份额至关重要。随着线上信息交流平台的普及,顾客对于商品反馈的信息量大幅增加。同时,顾客往往会对商品多个方面进行评价。方面情感三元组抽取(aspect sentiment triplet extraction,ASTE)是方面级情感分析(aspect-based sentiment analysis,ABSA)的一项子任务[1],实现对方面词-情感极性-观点词三元组的抽取,可以帮助商家从大量评论中挖掘顾客对商品不同方面的观点和情感极性,为商家改进商品提供具体思路,提高消费者满意度。
通过观察可以发现,真实的评论中往往存在以下两种情况:一种情况是顾客会针对同一商品的不同方面进行评价。以“电脑已收到,这价位非常给力,但客服态度不好”为例,顾客同时评价了“价位”和“客服态度”两个方面,并表达了不同的观点和情感。另一种情况是顾客针对同一方面可能存在多种情感极性。以“显示屏很不错,但是太贵了”为例,对于“显示屏”,分别通过“很不错”来表达正面的情感极性,通过“太贵”表达负面的情感极性。
目前,针对ASTE 任务的模型主要可分为两类:流水线模型和端到端模型。
流水线模型[2]将ASTE 任务分为两阶段:第一阶段基于两个序列标注任务,分别预测方面词-情感极性对和观点词;第二阶段基于分类器,判断方面词-情感极性对和观点词是否匹配。在预测方面词-情感极性对的时候,模型采用了一种统一标注方式,把方面词的边界信息和情感极性融入一个标签。但是,该方式没有考虑观点词对判断情感极性的影响,而且无法解决三元组方面词重叠问题。以“显示屏不错,但是太贵了”为例,其中包含(“显示屏”,正面,“不错”)和(“显示屏”,负面,“太贵”)两个三元组。针对“显示屏”这一方面词,同时存在两种情感极性。但是,对于同一方面词,上述标注方式只能标注出一种情感极性。
端到端模型[3-4]将ASTE 任务分为方面词和观点词抽取以及情感极性分类两个子任务,在两项子任务中共享编码器进行多任务学习。方面词和观点词抽取子任务的难点在于确定词的边界。以“耳机盒好看”为例,方面词应为“耳机盒”,如果方面词边界识别错误,可能得到结果“耳机”。情感极性分类子任务的难点在于正确配对方面词和观点词,并判断情感极性。以“物流很快,但质量很差”为例,“物流-很差”虽然语义合理,但不是对应关系。两项子任务难点不同,导致二者所需学习的特征信息之间存在差异。然而,共享编码器为两项子任务提取特征是相同的,导致模型在多任务学习过程中易出现特征混淆问题[5-6],两项子任务无法同时达到最佳效果。
针对上述问题,本文提出了片段级别的双编码器方面情感三元组抽取模型(span-level dual-encoder model for ASTE,SD-ASTE)。该模型是一个由片段识别和情感分类两模块构成的流水线模型。两模块分别完成方面词和观点词抽取以及情感极性分类,采用相互独立的编码器学习各自所需的特征信息。片段识别模块侧重于学习方面词和观点词的边界信息,情感分类模块侧重于针对不同方面词-观点词对,学习三元组各元素之间的相互依赖关系。
1 相关研究
ASTE 任务由Peng 等人[2]提出,Peng 等人采用流水线模型将任务分成两阶段,第一阶段分别预测方面词-情感极性对和观点词,第二阶段将二者配对。该流水线模型判断情感极性时,没有考虑观点词,而且无法解决方面词重叠问题,加重了误差积累问题。
之后,开始有研究者采用端到端模型完成该任务。Xu 等人[7]提出了一种采用位置感知标注方式的模型JET(joint extraction of triplets),在BIOES 序列标注方式中融入观点词和方面词之间的位置信息。为了更好地确定方面词和观点词的边界,Wu 等人[8]提出了一种网格标注方式GTS(grid tagging scheme),对句子中的单词两两进行标注,除了单词之间的情感极性之外,还标注出了两个单词是否属于同一个方面词或同一个观点词。
上述模型在判断情感极性时都只利用了单词级别(word-level)的信息,没有充分利用方面词和观点词片段级别(span-level)的信息。
受到实体关系联合抽取相关工作的启发,Xu 等人[4]进一步优化JET 模型,基于片段排列[9-10]的思想,提出Span-ASTE(span-level model for ASTE)模型。该模型采用双通道片段修剪策略确定方面词和观点词,再从片段角度预测候选方面词-观点词对的情感极性。而Mukherjee 等人[3]基于指针网络[11]的解码方式,提出PASTE(pointer networks for ASTE)模型,其核心是一个编码-解码框架。在编码阶段,基于预训练模型,获得片段特征表示。在解码阶段,在方面情感三元组中融入位置信息(方面词和观点词的起始位置),转换成五元组。该模型针对三元组重叠问题有了很大的提升。
机器阅读理解(machine reading comprehension,MRC)为ASTE任务提供了另一种思路。Chen等人[12]提出模型BMRC(bidirectional machine reading comprehension),通过三轮MRC 任务完成了ASTE 任务。首先,分别查询全部方面词和观点词;随后,将方面词和观点词进行配对;最后,查询方面词-观点词对的情感极性。Mao 等人[13]通过两个BERT-MRC 模型共享参数进行联合训练,先查询出句子中的方面词,然后根据方面词,查询其观点词-情感极性对。
也有学者将ASTE任务建模为生成任务。Yan等人[14]引入了指针索引表示句子中方面词和观点词的起始和结束位置,采用生成式框架,利用预训练模型BART(bidirectional and auto-regressive transformers),生成由方面词指针索引、观点词指针索引和情感极性类别组成的序列。Lu 等人[15]提出了一个文本到结构的生成框架UIE(unified information extraction architecture),通过一种结构化抽取语言(structured extraction language,SEL)编码方面情感三元组,并设计了结构模式指导器(structural schema instructor,SSI)来控制UIE模型的生成。
2 方法和模型
2.1 问题定义
给定数据集D,输入序列为语句X=[w1,w2,…,wn],ASTE任务的目标是抽取出X中所有方面情感三元组构成的集合T={t1,t2,…,tk},ti=(Ai,Pi,Oi),其中,Ai和Oi分别表示方面词和观点词,Pi∈{Pos,Neg,Neu}表示二者对应的情感极性,Pos、Neg和Neu分别表示正面、负面和中性情感。
定义1(片段)设si,j为输入序列X的一个片段,表示X的子序列[wi,wi+1,…,wj],其中1 ≤i≤j≤n。
定义2(片段类别集合)设片段类别集合为C={A,O,NC},其中,A表示方面词片段,O表示观点词片段,NC表示无意义片段。
给定片段si,j,片段识别旨在预测其类别c∈C的概率分布函数P(c|si,j),最大化概率,得到最优类别LC(i,j)。输出为方面词集合SA和观点词集合SO。
定义3(片段对)设片段对为(si,j,sp,q),其中,si,j∈SA是方面词片段,sp,q∈SO是观点词片段。
定义4(情感极性集合)设情感极性集合为V={Pos,Neg,Neu,NV},其中,NV表示无情感。
给定片段对(si,j,sp,q),情感分类旨在预测其情感极性v∈V的概率分布函数P(v|si,j,sp,q),最大化概率,得到最优情感极性LV(si,j,sp,q)。输出为方面情感三元组集合T。
基于上述任务定义,本文提出了片段级别的双编码器方面情感三元组抽取模型SD-ASTE,图1示意了模型结构,包括片段识别模块和情感分类模块。
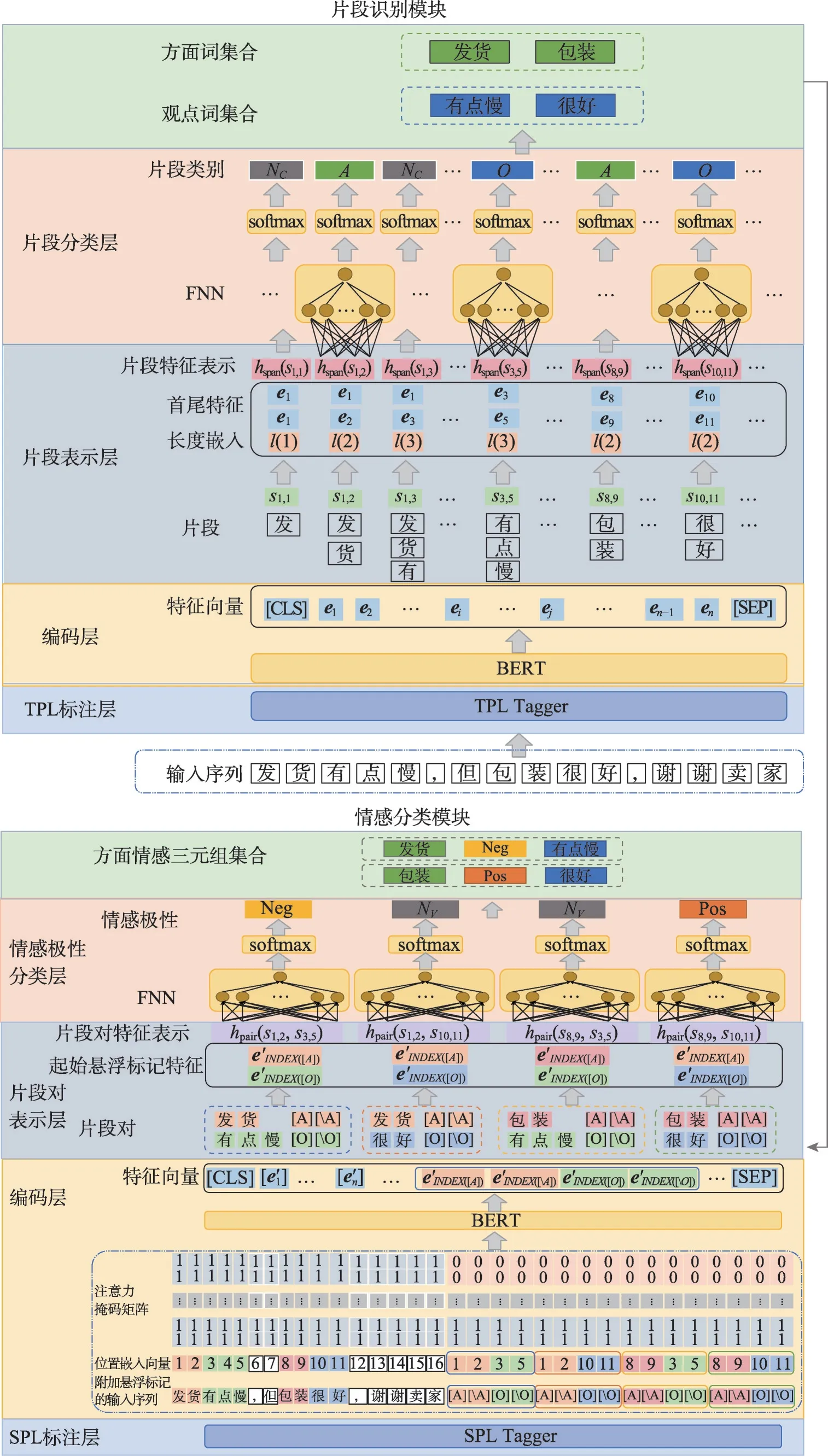
图1 SD-ASTE模型结构Fig.1 Structure of SD-ASTE
2.2 片段识别模块
该模块首先采用TPL(token pair linking)方式,标注所有片段的类别,构建词元之间的联系。其次,基于BERT(bidirectional encoder representations from transformers)模型[16]得到输入序列的特征向量。然后,基于片段边界和长度信息,对片段进行特征表示。最后,通过前馈神经网络(feedforward neural network,FNN)学习片段特征信息,对片段进行分类,得到所有方面词片段和观点词片段。
2.2.1 TPL标注层
TPL 标注的标签集合为C⋃{U}={A,O,NC,U}。设标注矩阵为TC。若1 ≤j-i+1 ≤L且i≤j,则标注TC(i,j)为si,j片段类别;否则标注为U。其中L为超参数,是片段长度阈值。图2为L=5的标注结果。

图2 TPL标注方式Fig.2 TPL tagging scheme
2.2.2 编码层
编码层基于BERT 对输入序列编码。对于输入序列X=[w1,w2,…,wn],先获取其字嵌入向量、段嵌入向量和位置嵌入向量,BERT 将三种向量相加,再通过Transformer得到特征向量E=[e1,e2,…,en]。
2.2.3 片段表示层
片段表示层对每个片段进行特征表示,由片段首尾特征表示和片段长度嵌入表示两部分构成。对于片段si,j,其首尾词元分别为wi和wj,那么在特征向量E中,其首尾对应的特征表示分别为ei和ej;其长度为j-i+1 ∈[1,L],对片段长度构造独热向量x=[x1,x2,…,xL],其中xj-i+1=1,将x输入到一个全连接层,得到长度j-i+1的嵌入表示l(j-i+1):
其中,W和b是模型要学习的权重矩阵和偏置向量。
将片段首尾特征表示和长度嵌入表示拼接,得到片段si,j的特征表示hspan(si,j),具体如下:
2.2.4 片段分类层
对于片段表示层的输出hspan(si,j),将其输入到一个两层FNN 中,通过softmax 函数归一化,得到片段si,j的类别c∈C的概率分布:
通过公式,得到片段最优类别标签:
最终,输出方面词集合SA={si,j|LC(i,j)=A}和观点词集合SO={si,j|LC(i,j)=O}。
模型训练过程中,损失函数为交叉熵损失:
其中,TC(i,j)是片段si,j的真实类别标注。
2.3 情感分类模块
基于片段识别模块的输出,该模块首先通过SPL(span pair linking)方式,标注所有片段对的情感极性,构建片段之间的联系。其次,在输入序列末尾插入悬浮标记[17],并针对附加悬浮标记的输入序列,设计位置嵌入向量和注意力掩码矩阵,通过BERT 得到特征向量。然后,基于悬浮标记对片段对进行特征表示。最后,通过FNN 学习片段对的特征信息,分类片段对的情感极性,得到所有方面情感三元组。
2.3.1 SPL标注层
SPL 标注的标签集合为V={Pos,Neg,Neu,NV}。设标注矩阵为TV。将TV(si,j,sp,q)标注为片段对(si,j,sp,q)的情感极性。图3为一个SPL标注的示例。
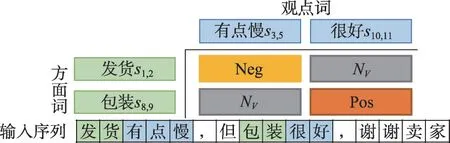
图3 SPL标注方式Fig.3 SPL tagging scheme
2.3.2 编码层
编码层在原始输入序列中插入悬浮标记,通过BERT,对附加悬浮标记的输入序列进行编码。
第一步,插入悬浮标记。对于输入序列X中所有可能的片段对,在序列末尾插入悬浮标记[A]和[A]用于标记方面词,插入悬浮标记[O]和[O]用于标记观点词,得到附加悬浮标记的输入序列X′=[x1′,x2′,…,xn′,…,xm′]。
第二步,设计BERT 输入中的位置嵌入向量。在附加悬浮标记的输入序列中,同一片段的悬浮标记可能出现在多个不同的位置。以图1输入序列为例,绿色[O]均对应“有”,但在X′中的位置索引不同。此外,本文基于悬浮标记对片段对进行特征表示,因此悬浮标记应该学习到其对应片段所在位置的上下文特征。因此,需要把悬浮标记的位置嵌入与其对应片段的位置嵌入关联起来。对于片段si,j∈SA和sp,q∈SO,其悬浮标记的位置嵌入为:
其中,e′pINDEX(∙)表示悬浮标记对应的位置嵌入,[A:si,j]和[A:si,j]、[O:sp,q]和[O:sp,q]分别表示si,j和sp,q的起始和终止悬浮标记。
第三步,在BERT 输入中设置注意力掩码矩阵。Transformer 通过自注意力机制计算序列中每个词元与所有词元的相互关系,再利用这种关系调整词元的特征表示。而文本词元的含义与悬浮标记无关,因此在编码过程中,文本词元不需要考虑悬浮标记。本文通过设置注意力掩码矩阵来解决该问题。如果wi′为文本词元,wj′为悬浮标记,则令注意力掩码矩阵M的元素mij=0;否则,令mij=1。这样,在计算文本词元wi′和其他词元的相互关系时,BERT 会对wj′掩码,从而不考虑wj′对wi′的影响。
第四步,将上述位置嵌入向量、注意力掩码矩阵和X′ 输入 BERT,得到X′ 特征向量E′=[e′1,e′2,…,e′m]。
2.3.3 片段对表示层
片段对表示层实现每组片段对的特征表示。对于片段对(si,j,sp,q),其特征表示由两个片段的起始悬浮标记的特征表示拼接而成:
其中,INDEX(∙)表示悬浮标记在X′中的下标索引。
2.3.4 情感极性分类层
对于片段对表示层的输出hpair(si,j,sp,q),将其输入到两层FNN 中。通过softmax 函数归一化,得到片段对(si,j,sp,q)情感极性v∈V的概率分布:
通过公式,得到其最优情感极性标签:
最终,得到方面情感三元组集合T={(si,j,LV(si,j,sp,q),sp,q)|LV(si,j,sp,q)≠NV}。
模型训练过程中,损失函数采用交叉熵损失:
其中,TV(si,j,sp,q)是片段对(si,j,sp,q)的真实情感极性标注。
3 实验设计及结果分析
3.1 实验数据集
本文在三个数据集上对模型进行了评估。数据集1(DS1)来自《CCF-BDCI 2018 汽车行业用户观点主题及情感识别》,是汽车论坛评论,包含观点词、方面类别、情感极性三个字段。DS1在原数据集的基础上标注了方面词[18]。数据集2(DS2)来自《之江杯电商评论观点挖掘大赛》,包含观点词、方面词、情感极性三个字段,是化妆品相关的商品评论。数据集3(DS3)来自《基于主题的文本情感分析比赛》,是电商评论,包含观点词、方面词、情感极性三个字段,其涉及的商品类别更加广泛。
过滤方面词或观点词为空的数据,按6∶2∶2将其划分为训练集(train)、验证集(dev)、测试集(test)。实验数据统计如表1所示。

表1 实验数据统计Table 1 Statistics of datasets
3.2 实验设计
3.2.1 对比实验
该实验用于对比SD-ASTE模型和其他基线模型的效果。本文对比的模型包括以下方法:
PengTwoStage[2]:基于双向长短时记忆神经网络(bi-directional long short-term memory,BiLSTM)和图卷积网络(graph convolutional networks,GCN)的两阶段流水线模型。
BMRC[12]:通过三轮MRC 任务,分别实现方面词抽取、观点词抽取和情感极性判断。
BARTABSA[14]:基于BART 完成序列生成任务,再将其转换为方面情感三元组。
JET-BERT[7]:提出位置感知标注方式,模型核心是条件随机场和半马尔科夫条件随机场。
GTS-BERT[8]:提出网格标注方式,用于解决方面情感三元组重叠问题。
PASTE[3]:基于指针网络的解码思想,考虑了方面词和观点词片段级别的信息。
Span-ASTE[4]:基于片段排列的思想,并提出双通道片段修剪策略,用于确定方面词和观点词。
3.2.2 有效性实验
该实验用于验证本文提出的片段特征表示、片段对特征表示和编码方式的有效性。表2 示意了实验具体设计。

表2 有效性实验设计Table 2 Design of validity experiments
对于片段特征表示,采用以下方式进行实验:方式1将片段首尾特征和长度嵌入拼接,即本文采用的方式;方式2 在方式1 的基础上去除长度嵌入;方式3从输入序列的特征向量中,获取片段对应的特征向量,对其进行最大池化;方式4 将方式3 中的最大池化替换为平均池化。
对于片段对特征表示,采用以下方式进行实验:方式1 将方面词和观点词对应的起始悬浮标记的特征表示拼接,即本文采用的方式;方式2参考PASTE[3]和Span-ASTE[4]模型的方式,将片段特征表示和片段之间的距离嵌入拼接。
对于编码方式,端到端方法认为,在方面词和观点词识别子任务以及情感极性分类子任务中共享编码器,可以使两项子任务相互促进。而SD-ASTE 模型通过两个独立编码器对两阶段分别编码。因此,本文在SD-ASTE模型的两个阶段中采用一个共享编码器,修改模型损失为两阶段损失之和,进行实验。
3.3 实验设置
对于PengTwoStage,基于本文的数据集训练300维GloVe[19]向量,作为词嵌入模型。BARTABSA 采用bart-base-chinese[20]作为预训练模型。其余模型均采用bert-base-chinese[16]作为预训练模型。
模型在单Nvidia GeForceRTX-3090 Ti GPU 上训练。实验机器的操作系统为Linux Ubuntu 20.04,内存为32 GB,Python 版本为3.8.0,深度学习框架为PyTorch 1.10.2。表3 示意了SD-ASTE 模型的实验参数设置。

表3 实验参数设置Table 3 Experimental parameter setting
3.4 实验结果
本文采用精确率、召回率和F1 值作为模型评估标准。实验重复三次,取结果的平均值。
3.4.1 对比实验
该实验对比了SD-ASTE模型和其他基线模型的效果,实验结果如表4所示。
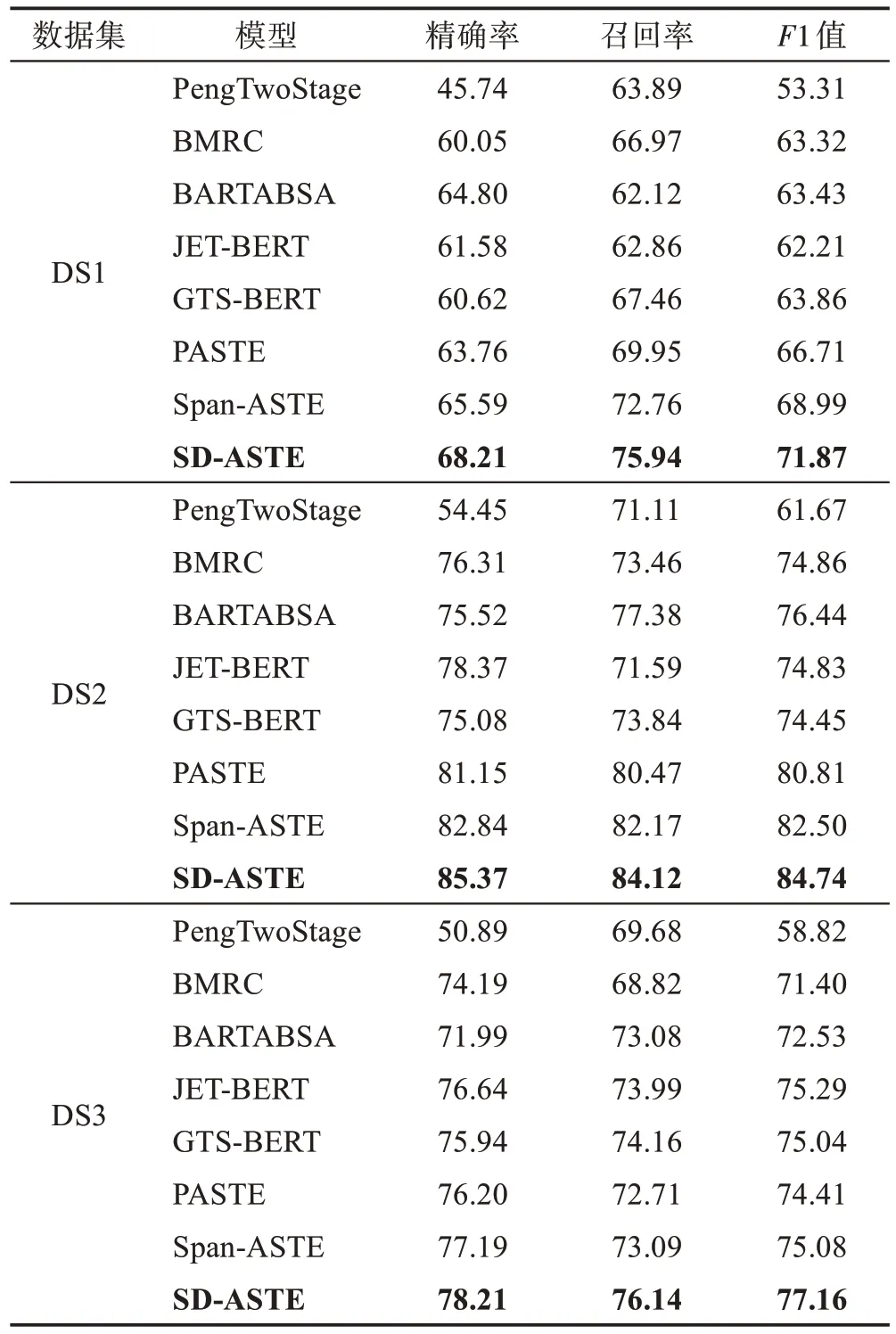
表4 对比实验结果Table 4 Results of comparative experiments 单位:%
结果表明,本文提出的SD-ASTE 模型在三个数据集上的效果都是最优的。
相较于流水线最优模型PengTwoStage,SD-ASTE模型在三个数据集上的F1 值分别提高了18.56 个百分点、23.07 个百分点、18.34 个百分点。这一显著提升是因为SD-ASTE 采用SPL 标注方式,避免了三元组重叠问题。同时,本文提出的基于悬浮标记的片段对特征表示方式,可以更好地学习三元组各元素之间的依赖关系,从而更准确地判断情感极性。
相较于端到端最优模型Span-ASTE,SD-ASTE模型在三个数据集上的F1值分别提高了2.88个百分点、2.24 个百分点、2.08 个百分点。分析认为,SDASTE 模型在两模块采用独立编码器,并针对两模块分别设计了特征表示方式,可以更好地学习两模块各自需要的特征。
3.4.2 有效性实验
该实验分别验证了片段特征表示方式、片段对特征表示方式和编码方式的有效性,图4(a)~(c)示意了实验结果。
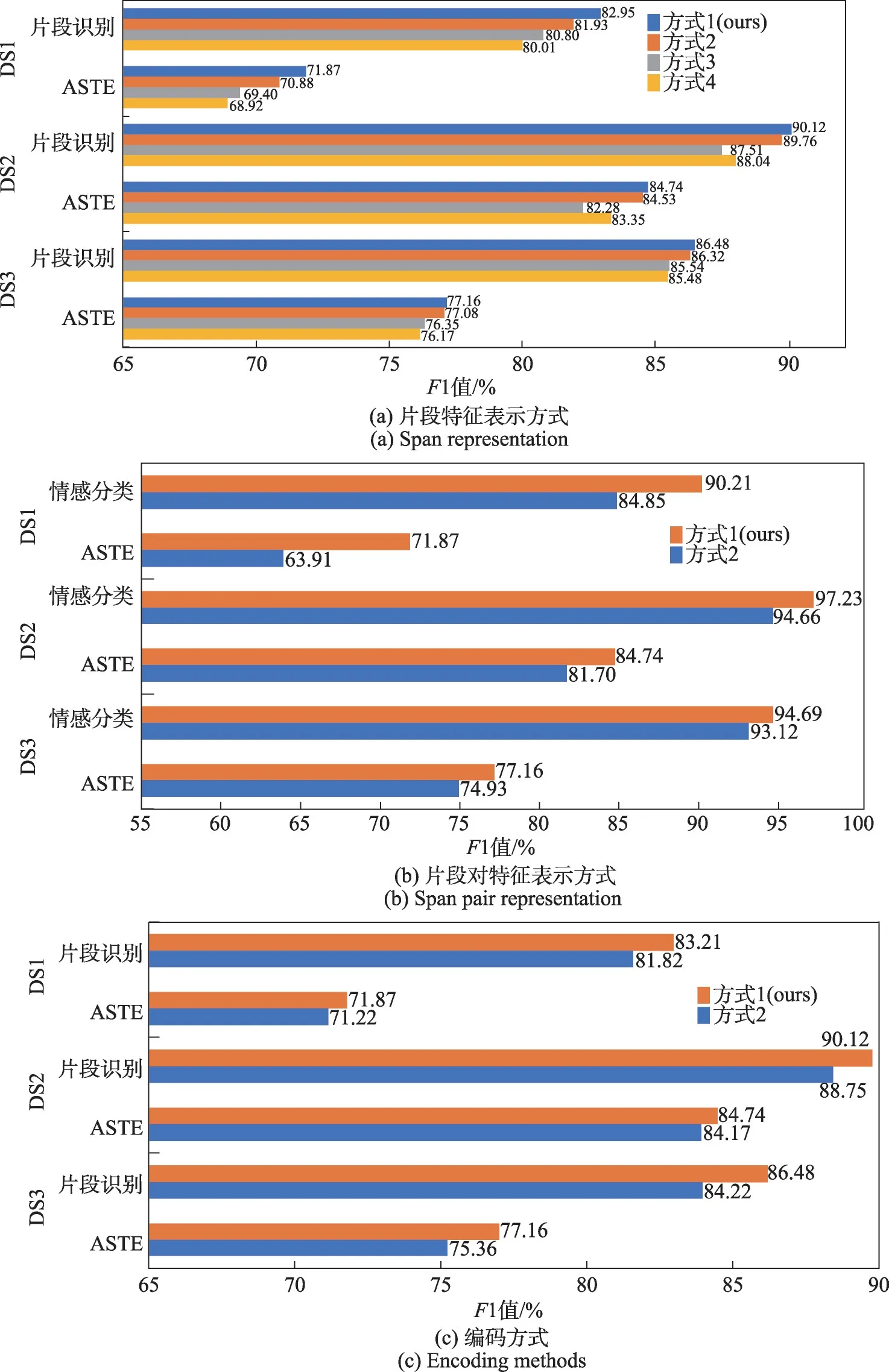
图4 有效性实验结果Fig.4 Results of validity experiments
片段特征表示方式的实验结果表明,片段长度和首尾特征信息在片段识别过程中起到了重要作用,这两项信息可以帮助模型更好地确定片段边界。
片段对特征表示方式的实验结果表明,本文采用的方式对情感极性分类的效果有明显提升。这种特征表示方式可以针对不同片段对,更有效地学习方面词和观点词之间的依赖关系,从而提取更多有助于情感极性分类的特征信息。
编码方式的实验结果表明,共享编码不能帮助提高情感三元组抽取的结果,而采用两个独立的编码器可以更好地提取不同任务所需的特征,有效提升了模型整体的效果。
4 结束语
ASTE 任务是细粒度的方面级情感分析任务,其目的是抽取句子中所有方面情感三元组。目前ASTE 任务面临以下问题:流水线模型没有考虑观点词对判断情感极性的影响,且无法解决三元组重叠问题;而端到端模型采用共享编码器,存在特征混淆问题。
本文提出了片段级别的双编码器方面情感三元组抽取模型SD-ASTE。该模型分为片段识别和情感分类两模块,分别采用TPL 和SPL 标注方式,解决了三元组重叠问题。片段识别模块采用融入片段首尾和长度信息的片段特征表示方式,可以更好地确定方面词和观点词的边界。情感分类模块采用基于悬浮标记的片段对特征表示方式,可以更有效地针对不同片段对,学习三元组各元素之间的依赖关系。两模块各自通过一个独立编码器进行特征提取,避免了特征混淆问题。多个数据集上的对比实验验证了SD-ASTE 相比其他主流模型具有更优效果,有效性实验验证了本文所采用的片段特征表示方式、片段对特征表示方式和编码方式的有效性。
目前,ASTE 任务的数据集主要集中于商品评论这一场景,下一步工作将针对其他场景,探索基于迁移学习、半监督学习或无监督学习的方法。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
时代英语·高一(2019年5期)2019-09-03
军营文化天地(2018年1期)2018-08-15
电测与仪表(2016年11期)2016-04-11
电源技术(2015年5期)2015-08-22
营销界(2015年22期)2015-02-28
清风(2014年10期)2014-09-08
现代防御技术(2014年6期)2014-02-28
