
三维坐标注意力路径聚合网络的目标检测算法
2023-12-08 11:49涂小妹包晓安金瑜婷张庆琪
计算机与生活 2023年12期
涂小妹,包晓安,吴 彪,金瑜婷,4,张庆琪
1.浙江广厦建设职业技术大学 建筑工程学院,浙江 东阳 322100
2.浙江理工大学 计算机科学与技术学院(人工智能学院),杭州 310018
3.浙江理工大学 理学院,杭州 310018
4.浙江广厦建设职业技术大学 信息学院,浙江 东阳 322100
5.山口大学 东亚研究科,日本 山口753-8514
目标检测一直以来是计算机视觉领域的研究热点之一,其任务是返回给定图像中的单个或多个特定目标的类别与矩形包围框坐标[1-3]。目前两大主流目标检测算法:(1)基于候选区域的双阶段目标检测算法,以RCNN(region-CNN)为代表,双阶段检测算法准确率高,但是训练和推理阶段速度慢,不能满足实时要求[4-5];(2)基于直接回归的单阶段目标检测算法,以SSD(single shot multi-box detector)和YOLO(you only look once)为代表[6-10],单阶段检测算法在准确率和运行速度上能达到一个均衡,是目前目标检测中使用较多的一种检测框架[11-12]。本文主要以单阶段YOLO 系列算法为研究基础,针对现实场景中对目标预测框定位要求较高的场景,提出了一种检测精度较高、定位较准确的检测模型(YOLO-T)。
YOLO系列检测框架主要分为主干网络、特征融合网络、特征解码网络。主干网络提取特征,特征融合网络融合多层语义特征信息,特征解码网络根据具体任务解码网络的输出。为了充分利用主干网络提取的特征,2017年,Lin等人[13]提出了特征金字塔网络(feature pyramid networks,FPN),用于构建多尺度特征获取高级语义信息。FPN 以及基于FPN 的改进版[14-18]在单阶段检测算法上表现出不错的效果。2018年,Liu 等人[14]考虑到网络浅层特征信息对于目标分割的重要性,提出了PANet(path aggregation network)网络,该网络从一个多尺度特征金字塔中捕获远程浅层特征,提高了模型检测精度。2020 年,Tan 等人[15]在PANet 的基础上提出了BiFPN(bi-directional feature pyramid network),该网络在每个层级添加残差连接进行反复堆叠来融合特征。2022 年,Luo 等人[17]提出了通道增强特征金字塔网络(channel enhancement feature pyramid network,CE-FPN),该网络既实现了通道增强又实现了上采样的亚像素跳跃融合方法。以上这些网络模型检测准确率较高,但模型推理速度较慢,参数量较大,用于YOLO 网络会使其失去实时性。于是许多基于YOLO 系列的轻量级模型应运而生。2021 年,Hu 等人[19]将YOLOv3-Tiny 网络中的卷积层替换为深度分布偏移卷积和移动反向瓶颈卷积,并设计渐进式通道级剪枝算法在保持检测性能的同时减少了参数量和计算成本。2022 年,邱天衡等人[20]基于YOLOv5网络提升检测精度的同时,使用Ghost 模块对网络进行轻量化,减少模型复杂度和参数量。2022年,杨小冈等人[21]在基于改进YOLOv5的基础上,使用深度可分离卷积以及对网络进行迭代通道剪枝,以降低模型的参数量和计算量。
YOLO 系列网络在实际工业应用中备受青睐,2021 年,Ge 等人[10]提出了YOLOX,在网络宽度和深度不断递增的过程中,按照主干特征提取网络大小,YOLOX 可以分为S、M、L、X。YOLOX-S 使用的主干特征提取网络网络最小,模型更轻量化,但在实际工业应用场景中发现YOLOX-S 对目标边界框的回归不够准确,如图1 所示。YOLOX-M/L/X 模型随着网络宽度和深度的加深,模型具有更好的检测和识别性能,但会受到硬件条件的制约,难以满足对检测实时性和目标框回归准确率要求都很高的应用场景。针对这个问题,本文基于YOLOX-S 算法提出了一种检测精度较高、定位较准确的目标检测算法YOLO-T。

图1 检测框与真实框的IOUFig.1 IOU of prediction box and ground truth box
(1)在路径聚合特征金字塔网络(path aggregation feature pyramid networks,PAFPN)中,本文提出了采用shortcut 连接方式进行跨层特征之间融合,利用TDCA(three-dimensional coordinate attention)对PAFPN 内特征进行注意力加权的方法。该方法不仅能将浅层特征传递到特征解码网络中,保留浅层语义信息,又解决了融合浅层特征信息的特征金字塔网络存在信息冗余的问题。
(2)考虑到坐标注意力机制(coordinate attention,CA)[22]只在X和Y方向进行特征聚合,而忽略了通道Z方向的特征加权,本文在CA的基础上,提出了三维坐标注意力(TDCA),其在特征的X、Y和Z三个方向上进行注意力增强,有效地将空间坐标信息和通道特征信息整合到生成的注意权重中。
(3)在正负样本标签分配策略中,本文沿用了更精准的SimOTA 采样策略,但在cost 代价函数中,使用了软标签高质量焦点损失(soft label quality focal loss,soft-QFL)和GIOULoss 联合作为cost 代价损失以及网络的分类和回归损失,通过在目标区域采集高质量的样本来有效地加速模型收敛。
1 相关工作
YOLO 系列算法直接对预测的目标物体进行回归,在精度要求不高的情况下,速度能达到实时检测。经过不断研究发展,2021 年,Ge 等人[10]提出了YOLOX,YOLOX 由Backbone、Neck 和Head 等部分组成。Backbone采用CSPDarknet提取图片的特征信息;Neck 部分采用PAFPN 的特征金字塔结构,实现不同尺寸特征信息的传递,解决多尺度问题;Head部分采用解耦头,分别计算定位、分类和置信度任务,再通过非极大值抑制(non-maximum suppression,NMS)对最终检测结果进行后处理。2022年,汪斌斌等人[23]基于YOLOX 检测模型以及迁移学习方法实现了玉米雄穗的高精度识别。2022年,杨蜀秦等人[24]提出了基于改进YOLOX 的单位面积麦穗检测方法,利用采样框直接实现了单位面积麦穗计数。YOLOX 在实时检测任务中有一个良好的表现,但YOLOX 也还有优化的空间,如YOLOX 算法的目标预测框定位不够准确,如图1 所示,检测框与目标框的IOU 较低。图1(a)绿色真实框与带分类置信度绿色预测框的IOU值为0.55,图1(b)左边目标dog 的绿色真实框与带分类置信度蓝色预测框的IOU值为0.69,图1(c)红色飞机的绿色真实框与带分类置信度红色预测框的IOU值为0.53。
故本文将YOLOX-S 作为研究的基础网络,主要改进了三方面:(1)在网络的Neck 部分,采用shortcut连接方式进行跨层特征之间融合,保留浅层语义信息(如边缘轮廓特征);(2)提出了TDCA注意力算法,并利用TDCA 注意力对Neck部分的内部特征进行加权融合,通过给特征赋予权重来保留有用信息和去除冗余信息;(3)改进标签分配策略与损失函数,在计算SimOTA 的损失矩阵时,采用联合soft-QFL 和GIOULoss 的计算方法,在保证不损失效率的同时增强了性能。
YOLOX 的Neck 部分是PAFPN,基于PANet[14]创建了自下而上的FPN 增强,加速了底层信息的流动,能快速融合各层语义信息。FPN 是利用图像金字塔的方式进行多尺度变化增强,与图像金字塔不同的是,FPN 是将主干网络提取的特征图垒成金字搭,使用自上而下的方式进行特征融合,目的是融合高低层语义信息提高特征的表达能力,为网络的输出提供更多有效信息。基于FPN 的改进还有BiFPN、DRFPN(dual refinement feature pyramid networks)、CE-FPN、Aug-FPN(augmented FPN)等[15-18]。其中BiFPN、CE-FPN 以及Aug-FPN 的结构如图2 所示,BiFPN[15]在每个层级添加残差连接进行反复堆叠融合特征。CE-FPN[17]实现了通道增强和上采样的亚像素跳跃融合方法,减少了由于通道缩减而造成的信息丢失。Aug-FPN[18]通过一致监督缩小特征融合前不同尺度特征之间的语义差距,减少了金字塔最高层特征图的信息损失。上述通过反复自上而下和自下而上的特征融合结构来提高检测精度,但这样的结构增加了计算复杂度,损失了检测速度。
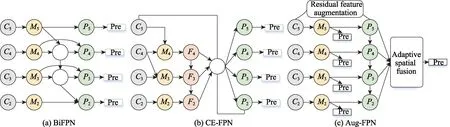
图2 BiFPN、CE-FPN以及Aug-FPN的网络结构图Fig.2 Network structure diagram of BiFPN,CE-FPN and Aug-FPN
本文在改进FPN 的同时,还使用深度可分离卷积(depthwise separable convolution)模块代替主干特征提取网络中的基础卷积结构,深度可分离卷积由逐通道卷积(depthwise convolution,DW)和逐点卷积(pointwise convolution,PW)两部分组成。DW 是一个卷积核对应特征图的一个通道,一个通道只被一个卷积核卷积,生成的特征图通道数和输入通道数一样。PW 与常规卷积运算类似,卷积核尺寸为1×1×C×N,C为上一层的通道数,N为新特征图通道数。因此,在计算量相同的情况下,Depthwise Separable Convolution 可以将神经网络层数做得更深,在实际工业应用中能轻量化网络模型,降低深度学习模型对硬件的要求。
注意力机制是认知科学领域的学者发现人类处理信息时采用的机制,后来把这种机制引入到卷积神经网络[25]。SENet(squeeze-and-excitation networks)[26]通过Squeeze 和Excitation 两个模块得到特征通道的注意力权值,完成通道特征重标定。CBAM(convolutional block attention module)[27]在SENet 的 基础上使用GAP(global average pooling)和GMP(global max pooling)两个池化进行Squeeze操作,更充分地提取通道特征。之后,有学者提出Dual Attention Network[28]、Selfcalibrated Convolutions[29]和Strip pooling[30]等。2021年,周勇等人[31]提出了弱语义注意力的遥感图像可解释目标检测,利用弱语义分割网络产生强化目标特征的注意力权重值,抑制背景噪声。2022 年,李飞等人[32]提出了混合域注意力YOLOv4 的输送带纵向撕裂多维度检测,改进了轻量级网络MobileNetv3 的特征提取性能。2022年,王玲敏等人[33]提出了一种改进YOLOv5的安全帽佩戴检测方法,该算法在YOLOv5的主干网络中添加CA 注意力机制,将位置信息嵌入到通道注意力当中,使网络可以在更大区域上进行注意。本文算法是在CA[22]注意力基础上提出了TDCA 注意力算法,在CA 的基础上捕获了通道感知注意力特征,提高了注意力的信息融合。
2 本文算法
2.1 网络整体结构
本文以YOLOX-S 为基础网络提出了改进网络YOLO-T,使用TPA-FPN(TDCA path aggregation feature pyramid networks)和TDCA 改进了网络的Neck 部分来提高网络的回归精度和收敛速度,使用Depthwise Separable Conv 模块改进Backbone 中的卷积结构来降低网络模型的复杂度,网络模型结构如图3 所示。YOLO-T 在特征融合部分利用Backbone 中不同位置的3个特征层,分别位于中间层、中下层、底层。中间层保留了较多的浅层特征信息(如轮廓、纹理和颜色等)。中下层保留了一些属性特征(如某一时刻目标的状态)。底层则保留了高级语义信息,高层语义性越强,模型的分辨能力也越强,但高层语义信息容易丢失小目标特征。当网络输入大小为640×640 的3通道RGB 图像时,经实验得出用于特征融合的中间层feat1=(80,80,256)、中下层feat2=(40,40,512)和底层feat3=(20,20,1 024)在保持计算量的情况下效果最好。在feat1、feat2和feat3特征层输入Neck部分之前使用TDCA 注意力机制完成特征重标定。Neck 部分采用TPA-FPN,Head部分沿用YOLOX-S的解耦头结构。
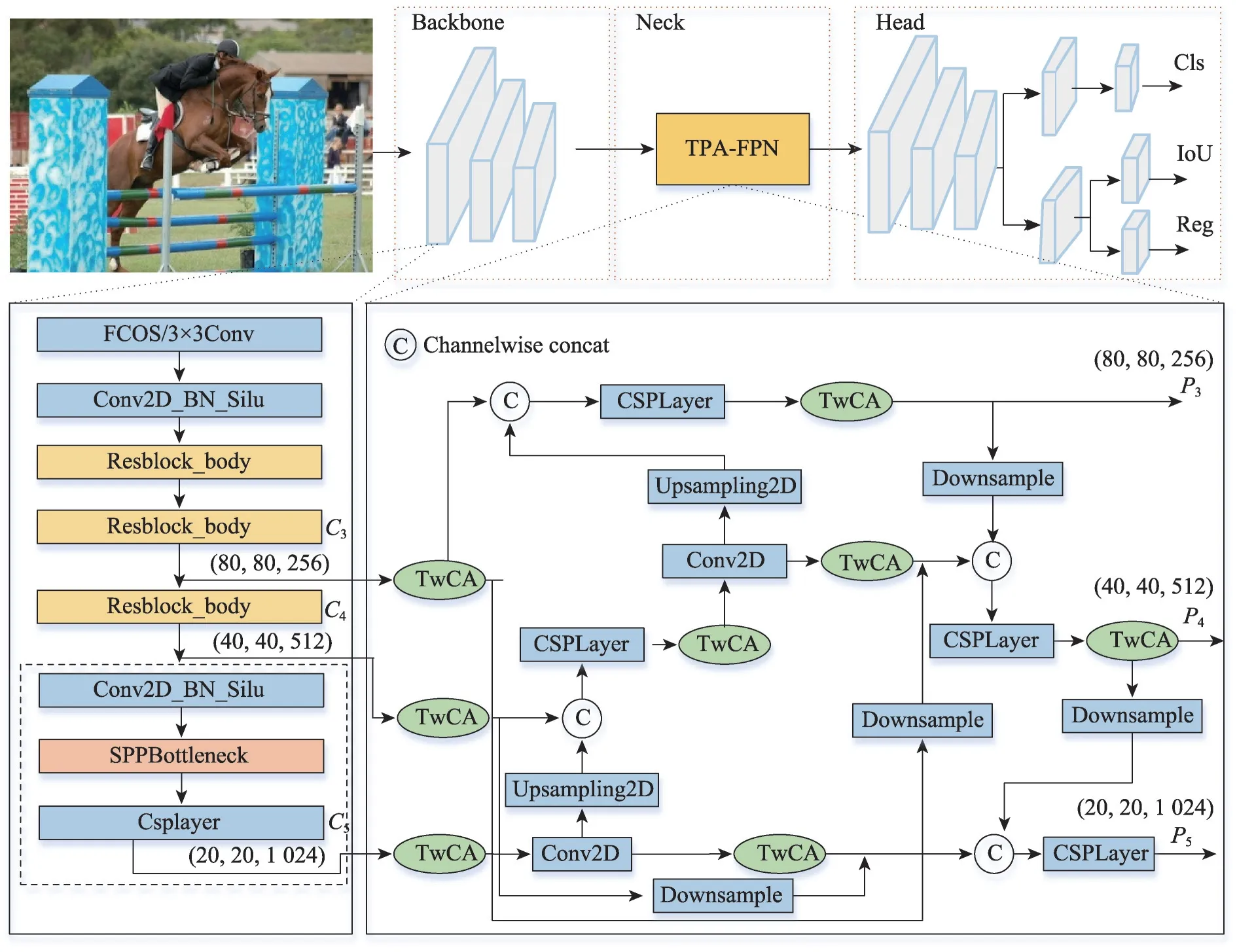
图3 YOLO-T网络结构Fig.3 YOLO-T network structure
2.2 三维坐标注意力(TDCA)
注意力机制通过权重重标定,给特征图中的信息赋予不同的权重,达到加强有用信息、抑制无用信息的目的。Hou等人[22]通过在X和Y两个方向上聚合特征的信息,提出了一种为轻量级网络设计的协调注意力机制(coordinate attention,CA),CA 模型的加入可以有效提高模型的收敛速度和监测精度。事实上,在深度卷积神经网络中,特征图不仅有X和Y两个方向的空间信息,还存在通道Z方向的通道信息,而CA 注意力机制忽略了Z方向的通道信息。对于特征图数据,分别利用不同的卷积模块学习不同方向的信息权重,然后通过可学习的加权融合方式获取输入特征图的权重,也以此进行X、Y和Z方向的信息交流,充分利用X、Y方向的空间信息和Z方向的通道信息,称为三维坐标注意力(TDCA),结构如图4所示。

图4 三维坐标注意力TDCAFig.4 3D coordinate attention TDCA
在结构中对于输入特征图F∈R C×H×W,X、Y和Z方向的注意力模块计算公式如下所示:
经过X、Y和Z方向的权重特征提取后,将Z方向的特征分别与X和Y方向的特征融合,公式如下所示:
式中,ZX∈RC×H×1和ZY∈RC×1×W是X与Z方向,Y与Z方向的通道权重重标定,将ZX转置与ZY沿Y方向进行Concat,Z∈RC/r×1×(W+H)为ZX和ZY结合后的结果特征图,其中r为通道的系数,取0.5,降低通道数以减少计算量。BaseConv2 表示卷积的基本单元,包含卷积层、BN 层和Silu 激活函数。将Z分割成ZX′和ZY′,分别对它们进行卷积和激活操作,可表示为:
fconv2d为1×1 卷积为恢复缩放的通道数操作,最后将得到的两个空间解码权重图与输入特征进行点乘,完成特征权重重标定,TDCA输出公式如下所示:
Fout∈RC×H×W为TDCA 网络结构的输出。通过X和Y方向捕获方向感知和位置感知信息,利用Z方向捕获跨通道信息,使模型更加精准地定位和识别感兴趣的目标,能够更加有针对性地提取图像特征,提升图像识别效果。表1 是从对比实验角度证明TDCA网络结构的有效性。
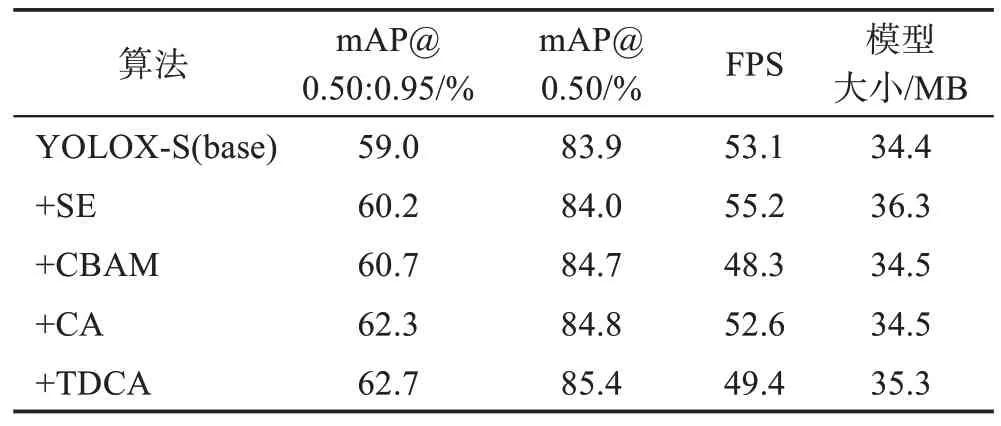
表1 各种注意力机制与TDCA在YOLOX-S下对比Table 1 Comparison of various attention mechanisms and TDCA in YOLOX-S
表1 为YOLOX-S 与加入SE、CBAM、CA 以及TDCA 注意力模块后在PASCAL VOC2007+2012 数据集上训练测试的精度对比。从表1中可以看出,加入注意力机制后普遍能够提升网络的精度,而在加入TDCA 后,在mAP@0.50:0.95 指标上比最优的CA机制提高了0.4 个百分点,比YOLOX-S 算法提高了3.7 个百分点。在mAP@0.50 指标上,TDCA 相较于最优的CA 机制提高了0.6 个百分点,相比原始算法提高了1.5 个百分点。对算法成本进行分析,从表1中可以看出,TDCA 与基础网络YOLOX-S 相比检测速度和模型大小有所增加,但是与其他注意力机制相比都相差不大。因此,从3个方向提取特征注意力信息是对CA模块有效的改进方向。
相比此前的轻量级网络上的注意力方法,TDCA存在以下优势:首先,它不仅能捕获跨通道的信息,还能捕获方向感知和位置感知的信息,这能使模型更加精准地定位和识别感兴趣的目标;其次,TDCA灵活且轻量,可以很容易地插入经典模块,如Mobile-NeXt[34]提出的sandglass block;最后,作为一个预训练模型,TDCA可以在轻量级网络的基础上给下游任务带来增益,特别是那些存在密集预测的任务。
2.3 TPA-FPN网络结构设计
FPN 自顶而下的融合方式极大地利用了高低层特征语义信息,从而提高了特征的表达能力。因此,基于FPN 的改进算法常在融合方式上进行创新,例如PANet 网络[14]从自顶向下再从自底向上融合方式提高特征融合能力,BiFPN[15]网络利用反复堆叠的方式进行特征融合。上述两种融合方式能有效地保证特征之间的信息交流,但是特征内的信息重要程度却被忽略了。此外,特征融合过程中的自顶而下和自底向上的融合方式会使特征内的语义信息被稀释,从而会损失特征图内部的一些较重要的信息。本文提出了TPA-FPN 网络结构,如图5 所示,在PAFPN 特征融合网络中采用shortcut 连接方式进行跨层特征融合,保留其浅层语义信息。但是,融合了跨层特征的特征图信息存在冗余,于是在PAFPN 网络结构中加入TDCA网络结构,对特征内的重要信息进行X、Y和Z方向的加权,TDCA 网络结构通过给特征赋予权重来保留有效信息和去除冗余信息。

图5 TPA-FPN网络结构Fig.5 TPA-FPN network structure
主干网络不同阶段的特征图对应的感受野不同,它们表达的信息抽象程度也不一样,在Backbone网络中抽取特征丰富的C3、C4、C5三层做特征融合,C3、C4、C5除了在自顶向下过程中与邻层特征融合之外,还通过短连接(shortcut)进行跨层级特征融合,将保留的浅层信息传递到间隔层。但以这种方式做信息融合,容易产生信息冗余。解决方法是在特征融合之前以及在自顶向下和自底向上特征融合过程中,加入TDCA 三维坐标注意力网络,通过注意力调节特征信息的重要程度,提高特征的信息表达能力,从而保留有用信息和去除冗余信息。最后特征融合网络TPA-FPN 输出尺度大小为80×80×256、40×40×512、20×20×1 024 的特征层P3、P4、P5,作为目标检测网络中分类和回归特征的依据。
在TPA-FPN 特征融合网络中,不同特征层之间自上向下融合需要对尺寸较小的特征进行上采样,自下向上的特征融合过程中需要对尺寸大的特征进行下采样,本文使用的上采样方法为双线性插值法,下采样方法为普通卷积操作,将下采样或上采样后的特征图与底层特征或高层特征进行concat连接。
表2 为在PASCAL VOC2007+2012 数据集上训练测试的精度对比结果。以YOLOX-S 网络结构为基础,在Neck 部分分别使用FPN、PAFPN 和TPAFPN 作为算法1、算法2 和算法3。在算法3 的基础上,将主干网络结构中的卷积结构替换成Depthwise Separable Conv 模块降低网络模型的复杂度,作为对比算法4。
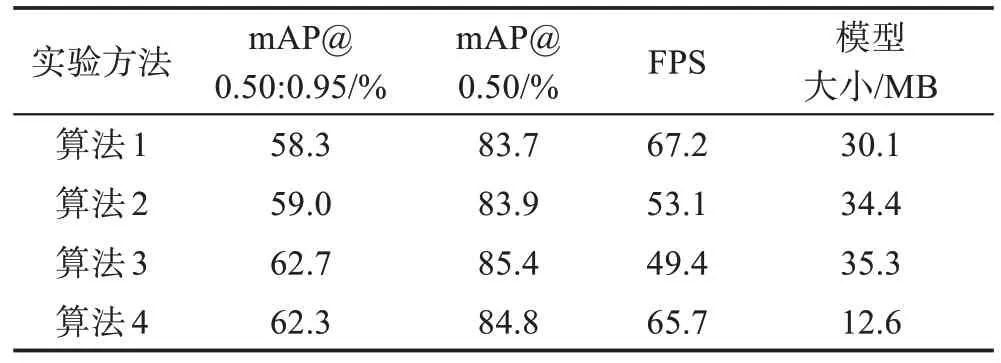
表2 FPN、PAFPN和TPA-FPN在YOLOX-S下对比Table 2 Comparison of FPN,PAFPN and TPA-FPN in YOLOX-S
由表2 可知,算法3 中的TPA-FPN 在推理速度上略低于FPN 和PAFPN,但在高交并比要求下TPAFPN 比PAFPN 的mAP@0.50:0.95 指标提升了3.7 个百分点,mAP@0.50 指标提升了1.5 个百分点。表明跨层级特征融合和利用TDCA 网络结构保留有效信息和去除冗余信息能提高网络对边界框的回归精度。算法4使用了Depthwise Separable Conv模块,虽然在准确率上有所降低,但能有效地对网络进行轻量化,模型大小减少了64.3%,由检测速度(FPS)指标可知,模型检测速度提升了33.0%。模型大小的降低和检测速度(FPS)的提升能有效减少在实际应用场景下模型对硬件的要求。参数量的降低能有效减少在实际应用场景下模型对硬件的要求。通过TPAFPN 结构使特征金字塔网络能更好地融合各层语义信息,可以更好地回归目标边界框,契合高交并比下的工业目标检测任务。
2.4 标签分配策略与损失函数
目标检测中预测定位的过程是模型开始训练时先在图像的每个位置生成一系列锚框,网络结构按照一定的规则将锚框分成正负样本,但由于图像中目标的数量有限,这样生成的锚框大部分都是背景,导致模型训练样本不均衡。因此,在正负样本标签分配策略中,本文沿用YOLOX-S中更精准的SimOTA采样策略,但在cost代价函数中,本文使用了soft-QFL作为cost 代价损失和分类损失。考虑到one-hot 标签中0 和1 的绝对情况下,本文的soft-QFL 分为两种情况:(1)half soft-QFL将正类别中的1使用IOU的值代替,其他类别的值使用0;(2)soft-QFL 在正类别中的1使用IOU的值代替的情况下,其他类别的值使用(1-IOU(gt,anchor))/C,结构如图6 所示。在原基础网络中回归损失函数使用的是IOULoss,本文针对IOU 存在当锚点与真实框没有相交时,不能反映两者的距离关系,使用GIOULoss 作为网络的回归损失。上述改进目的是通过在目标区域采集高质量的样本来有效地加速模型收敛,从而改善目标正负样本标签分配不均衡的问题。改进的SimOTA 采样策略如式(8)所示,其中ai的值作为样本的标签,ai的值越大表示此锚点更接近真实框。

图6 改进的SimOTA采样策略Fig.6 Improved SimOTA sampling strategy
IOU(gt,anchor)表示目标真实框gt与生成的anchor锚点框之间的IOU 值,C表示总类别。在分类损失中,将one-hot 编码中的1 替换为ai的值,0 替换为(1-IOU(gt,anchor))/C,这样更能反映出锚点与真实样本的关系,如式(9)所示:
式中,pi表示预测为第i类的概率,β为调节参数,实验取值为2。当anchor是难分的正样本时,ai的值偏低,1-ai的值偏高,而Lcls在逐渐降低的过程中,网络就相当于增加了难分正负样本的loss权重,使得网络在训练时不会花太多时间在易分的负样本上,加快了模型收敛。
利用IOU 指导正负样本标签的分配,再与分类置信度损失函数进行联合预测,在速度无损的情况下能有效地改善正负样本不均衡问题。表3 中的消融实验为在PASCAL VOC2007+2012 数据集上的精度对比结果,基础网络采用YOLOX-S,“√”代表引入模块,实验环境参数以及网络超参数设置如3.1 节所示。

表3 标签分配策略与损失函数的mAP对比Table 3 Comparison of mAP of label allocation strategy and loss function
在表3 中对比1、2 组实验发现,使用half Soft-QFL 进行改进的模型在mAP@0.50:0.95 和mAP@0.50 的指标上有所下降,而通过对比1、2、3 组实验可以看出,Soft-QFL 的表现比half Soft-QFL 在mAP@0.50:0.95 指标上提高了3.2 个百分点,在mAP@0.50指标上提高了1.0个百分点。分析half Soft-QFL可能是使用IOU 指标作为正类别的标签反而削弱了损失函数的表现,Soft-QFL 则是在改变正类别时,对负类别也进行了改进,并同时作用于损失函数,从而使模型表现出良好的效果。对比1、4 组实验,GIOULoss在mAP@0.50:0.95 指标上比原算法提高了1.2 个百分点,有一个较好的效果。通过5、6 组实验可以看出,soft-QFL+GIOULoss的表现效果最好。
从结构上分析在基于锚框检测的目标检测算法中,使用Soft-QFL 和GIOULoss联合能有效改善网络检测精度,使网络训练更稳定,加速网络训练收敛速度。
3 实验结果及分析
3.1 实验环境与参数设置
为了公平分析和评估本文提出的算法性能,实验测试环境配置如下:CPU 为Intel®Xeon®Gold 5218R CPU@2.10 GHz,64 GB 内 存,Ubuntu16.04 操作系统,2 张GeForce RTX3090 型号的显卡。运行环境配置如下:Python 版本为3.7,Pytorch 版本为1.9.0,CUDA 版本为10.2。网络运行的超参数设置如下:网络训练分为冻结训练和解冻训练,冻结训练50 个epoch后再进行解冻训练,冻结训练的batch-size设置为64,解冻训练的batch-size 设置为32,动量参数为0.937,学习率初始值为0.01,最小值为0.000 1,随着网络的训练,学习率进行余弦退火衰减,解冻阶段训练300 个epoch,并使用Adam 优化算法更新网络权重。
超参数置信度阈值、NMS 阈值的作用是剔除每一类别中的重复预测框,其取值对模型性能有一定影响。通过非极大值抑制(NMS)算法,本文设计了一组超参数置信度阈值和NMS 阈值的灵敏度实验。根据NMS算法思想,置信度阈值和NMS阈值过大容易将正确的预测框剔除,过小不能达到去除重复框的效果。实验结果表示,在置信度阈值取值0.45,NMS阈值取值0.50时,本文算法展现出较好的性能。
算法1非极大值抑制(NMS)算法
3.2 评价指标
本实验的评价指标使用平均检测精度(mAP@0.50、mAP@0.50:0.95)和检测速度(FPS)作为模型的衡量标准,平均检测精度能有效地评估模型的性能,包括识别准确率、定位准确率,检测速度能有效地衡量模型的推理性能,是实际工业应用中的重要指标。其中,mAP@0.50 表示IOU 阈值为0.50 时的mAP;mAP@0.50:0.95 表示步长为0.05 的IOU 阈值从0.50到0.95 的各个mAP 的平均值。mAP@0.50 主要体现目标检测模型的识别能力,mAP@0.50:0.95 由于IOU 最高取值达到了0.95,IOU 取值高主要体现目标定位效果以及边界框回归能力。mAP 的值与模型的性能呈正相关,FPS 表示每秒检测图像的数量,其值越大表示检测速度越快。
mAP表示平均检测精度即P-R曲线下方的面积,P-R 曲线是以准确率(Precision)为纵轴,召回率(Recall)为横轴的二维曲线。具体计算公式如式(10)~式(12):
式中,TP表示为真正例样本数;FP表示为假正例样本数;FN表示为假反例样本数。Precision 表示预测样本中的正样本数占所有实际正样本数的比例。Recall 表示预测样本中的正样本数占所有预测样本的比例,Precision与Recall呈负相关。
3.3 PASCAL VOC2007+2012数据集对比实验
PASCAL VOC 数据集是计算机视觉挑战赛公开的数据集,常被用来检验目标检测模型的性能。PASCAL VOC2007+2012 是两个年份公开发布数据集的并集,此数据集更复杂,使用该数据集对模型性能进行验证可增加数据量,同时也更具说明性。该数据集包含20 类检测目标,模型的训练集使用PASCAL VOC2007+2012 数据集中的train+val 部分,共16 551 张图像,模型的测试集使用PASCAL VOC 2007数据集中的test部分,共4 952张图像。
为了验证YOLO-T模型的性能,本实验将与以下算法做对比:(1)双阶段目标检测算法Faster R-CNN[35]、Mask R-CNN[4]和Cascade R-CNN[5];(2)高精度单阶段算法RetinaNet[36]和以SSD[6]为基础改进的ASSD(attentive single shot multibox detector)[37]算法;(3)单阶段无锚框算法FCOS(fully convolutional one-stage object detection)[38]和ATSS(adaptive training sample selection)[39]算法;(4)以YOLO系列为基础的YOLOv3[20]算法以及改进的轻量级算法YOLOv4-mobileNetv2[20]、YOLOv4-ghostNet[20]、YOLOv5-S[20]和YOLOX-S。与以上算法对比结果如表4所示。
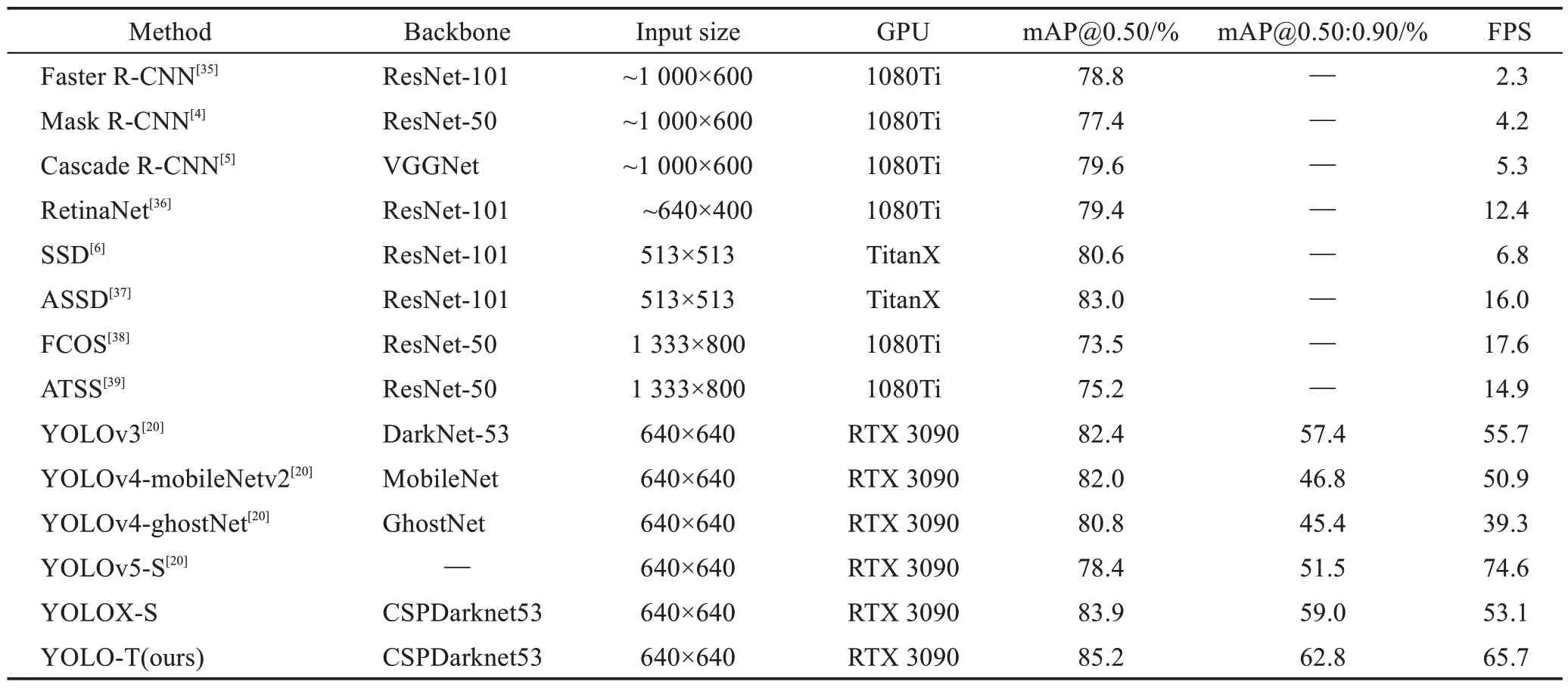
表4 PASCAL VOC2007测试集上各目标检测算法对比实验Table 4 Comparative experiment of each object detection algorithm on PASCAL VOC2007 test set
由表4 可知,本文提出的YOLO-T 在检测精度上有着显著优势,在PASCAL VOC2007测试集上mAP@0.50 的精度达到了85.2%,相较于基础网络YOLOXS 提高了1.3 个百分点,而能体现定位效果和边界框回归能力的mAP@0.50:0.90精度达到了62.8%,相较于基础网络YOLOX-S 提高了3.8 个百分点,说明YOLO-T网络结构能有效提高预测定位的检测精度;与双阶段检测器相比,mAP@0.50 提高了5.6~7.8 个百分点;与单阶段经典算法SSD 以及基于SSD 改进的ASSD 算法相比有4.6 个百分点和2.2 个百分点的提升;与高精度RetinaNet 算法以及单阶段无锚框的FCOS 和ATSS 算法相比,YOLO-T 网络结构更展现了其优势,检测精度都有大幅度提升;相比于有相同baseline 的轻量化网络YOLOv4-mobileNetv2、YOLOv4-ghostNet、YOLOv5-S 和YOLOX-S,虽然检测速度不如基础网络YOLOX-S,但是检测精度上有着明显的优势。总体来看,在检测精度和检测速度兼具的条件下,YOLO-T在众多模型中的表现更加出色。
由于超参数置信度阈值和NMS阈值的取值对模型性能有一定影响,本文设计了一组超参数的灵敏度实验。根据非极大值抑制(NMS)算法,选取了9组数据对模型的性能进行测试。在取值的过程中,阈值过大容易将正确的预测框剔除,过小不能达到去除重复框的效果。因此,本文的置信度阈值从0.40到0.50 以0.05 为步长递增,NMS 阈值从0.30 到0.50以0.1为步长递增,实验结果如表5所示。
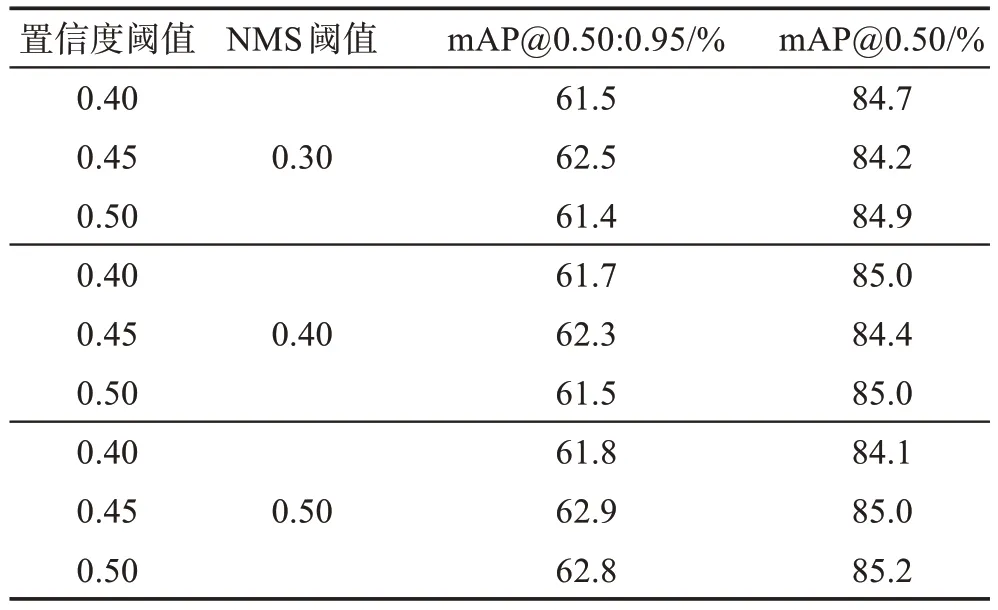
表5 超参数置信度阈值、NMS阈值的实验结果Table 5 Experimental results of hyperparameter confidence threshold and NMS threshold
根据表5的实验结果,不同的超参数置信度阈值和NMS阈值对模型性能有一定影响。当置信度阈值取0.45,NMS 阈值取0.50 时,模型的mAP@0.50:0.95指标最高;当置信度阈值取0.50,NMS 阈值取0.50时,模型的mAP@0.50 指标最高。综上实验结果,实验中测试的超参数置信度阈值设为0.45,NMS 阈值为0.50。
本文还对VOC数据集的场景图像进行定性评价分析,效果如图7 所示。图7 中(a)和(b)为经过CA注意力和TDCA注意力处理后的加权热力图,图7(a)中从左到右预测框与真实框的IOU 值分别为0.55、0.69 和0.53,图7(b)中从左到右预测框与真实框的IOU 值分别为0.79、0.99 和0.78。从图中可以看出,和CA 注意力机制相比,加入TDCA 后,网络对检测目标区域的定位和关注程度都获得了提升,证明在Neck部分加入TDCA能更好地融合关键特征信息。

图7 注意力机制CA与TDCA的热力图对比Fig.7 Heat map comparison of attention mechanism CA and TDCA
第1 组实验对cat 进行检测,目标cat 由于衣物的遮挡,将身体和头部分开了,此时图7(a)检测器出现定位不准确,只检测到了头部以下的部分,而图7(b)检测定位较图7(a)准确,IOU 提高了0.24。从热力图中也可看出,TDCA比CA更能关注到目标的特征。第2 组实验中两个目标较聚集,从对比图来看,图7(b)的模型对左侧的目标定位比图7(a)模型准确,IOU提高了0.3。第3组实验对较明显的大目标aircraft进行检测,图7(b)模型定位性能表现得比图7(a)好,IOU 提高了0.25,但是在小目标person 的检测上,YOLO-T模型检测效果略逊色。但总体来说,YOLO-T在目标定位上要优于基础网络,平均IOU 提高了26%,证明网络提取到了更加丰富的语义信息,表现出更好的性能。YOLO-T 更适合于定位要求较高的现实场景。
3.4 消融实验
本文算法从TDCA、TPA-FPN 和Soft-QFL 三方面对YOLOX-S 进行改进,为探究各改进方法的有效性,在基线网络YOLOX-S 的基础上设计了4 组消融实验,实验数据集使用3.3 节的PASCAL VOC2007+2012 数据集,每组实验所采用的实验环境、网络超参数以及训练技巧均相同,实验结果如表6 所示。其中,TPA-FPN 代表所提Neck 结构,Depthwise Separable Conv 模块代表修改主干特征提取网络中的基础卷积结构,Soft-QFL 代表提出的标签分配策略与损失函数,由于TDCA 结构是融入到TPA-FPN 结构中的,不对TDCA模块进行消融实验。

表6 各改进模块在YOLOX-S框架下的消融实验Table 6 Ablation experiment of each improved module under framework of YOLOX-S
由表6可知,以YOLOX-S为基础,加入TPA-FPN模块后mAP@0.50:0.95 提升了3.7 个百分点,mAP@0.50 提升了1.5 个百分点,TPA-FPN 网络结构融入了TDCA注意力机制,mAP@0.50:0.95指标的提高说明模型对目标预测框的回归能力提高了,使预测的目标框与真实目标框更接近,这对需要更准确定位的回归任务来说,加入TPA-FPN 是非常有效的;其次,使用了Soft-QFL 改进标签分配策略以及损失函数,mAP@0.50:0.95 提升了1.6 个百分点,mAP@0.50 提升了0.3 个百分点。Soft-QFL 通过改进标签分配策略以及损失函数来提升网络模型的识别能力,Soft-QFL 在几乎不消耗网络的训练和推理性能的基础上,提高了网络检测精度。此外,由于网络结构引入了TPA-FPN 模块,模型的复杂度增加,网络检测速度和模型参数量有所增大。
在YOLO-T 主干网络中引入Depthwise Separable Conv 模块代替普通卷积模块,由表2 和表6 可知,引入深度可分离卷积模块mAP@0.50:0.95 和mAP@0.50准确率只降低了0.8个百分点和0.1个百分点,但模型的参数量和网络复杂度减少了64.3%。最终的YOLO-T 网络模型达到了速度和检测精度两方的平衡,并且模型对目标预测框的拟合能力进一步增强,在实际应用中对硬件的要求更小,能被用于需要定位更加准确的工业应用场景中。
3.5 COCO数据集对比实验
为了进一步评估YOLO-T 目标检测模型的精度和定位效果,本文在类型更多、图像环境更加复杂的COCO 数据集上进行实验。COCO 数据集是由微软提供的大型目标检测数据集,具有数据类别多和目标尺寸跨度大等特点。实验中将COCO2017 数据集中的训练集随机划分为包含105 539 张图像的train和11 727 张图像的val,并在包含5 000 张图像的COCO2017 验证集上进行测试。主要评估不同IOU阈值下的平均精度。其中,不同IOU 阈值下的平均精度可以体现模型的定位效果,高IOU 阈值代表预测框和真实框重合度的标准更加严格。实验数据中YOLOX-S 和YOLO-T 通过实验得到,实验环境和参数设置如3.1节所示。
如表7 所示,在COCO 数据集上,YOLO-T 的mAP@0.50:0.95 达到了42.0%,较原YOLOX-S 提高了2.4 个百分点,mAP@0.50 提高了0.8 个百分点,mAP@0.75提高了2.8个百分点。在不同的IOU阈值下,mAP@0.50:0.95 指标涨点最多,这也说明本文算法对预测框定位以及边界框回归能力有着明显的优势。对比其他的检测算法YOLOv5-S、YOLOv3、RefineDet 和FAENet,mAP@0.50:0.95 也有着显著的提高,由此说明YOLO-T在复杂场景下也具有较好的预测框定位效果和检测性能。

表7 COCO数据集上的对比实验Table 7 Comparative experiments on COCO dataset
4 结束语
本文基于YOLOX-S 网络结构提出了一种改进的目标检测算法YOLO-T,目的是改进YOLOX-S 算法对目标预测框定位不准确的问题。采用TDCA、TPA-FPN 和Soft-QFL 结构对网络的精度和目标框边界的回归能力进行提升。使用Depthwise Separable Conv 改进Backbone 中的卷积模块使模型轻量化,平衡了检测速度和检测精度。在PASCAL VOC2007+2012 数据集上,YOLO-T 和YOLOX-S 相比,模型大小减少了64.3%,检测速度提升了23.7%,mAP@0.50提高了1.3 个百分点,mAP@0.50:0.95 提高了3.8 个百分点。因此YOLO-T是一种检测精度较高、定位较准确的目标检测模型,适用于对定位要求较高的现实场景。但YOLO-T 仍有改进的空间,如Neck 部分可以再使用较低分辨率的特征图,可以更好地对小目标进行检测。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
疯狂英语·新策略(2019年10期)2019-12-13
制造技术与机床(2019年9期)2019-09-10
电子制作(2019年11期)2019-07-04
当代陕西(2019年10期)2019-06-03
西南交通大学学报(2018年6期)2018-12-18
北京航空航天大学学报(2018年1期)2018-04-20
数学小灵通·3-4年级(2017年9期)2017-10-13
河北遥感(2017年2期)2017-08-07
衡阳师范学院学报(2016年3期)2016-07-10
