
融合Skip-gram 与R-SOPMI 的教育领域情感词典构建
2023-12-08 13:10席宁丽李佳敏万晓容
应用科学学报 2023年5期
陈 俊,席宁丽,李佳敏,万晓容
贵州师范大学教育学院,贵州贵阳550025
在线教育为迎合现实需求、满足政策规划,以大规模、半自主趋势深度融入至教育生态中。在线教育在应用过程中仍存在很多问题,如传统粗粒度的情绪二分类技术无法对不良学习情绪进行成因分析及干预,因此已不能满足在线教育中情绪归因研究的需要[1]。
目前,情感分析任务大部分基于情感词典技术完成,故高质量的情感词典对于提高其准确率、精确率和召回率起着至关重要的作用[2]。但通用情感词典面临领域情感分析任务时,存在诸多困难:1)部分情感词存在领域依赖性,无情感实体词在描述领域特定事物时常出现情感倾向,如动词“实践”在实操类课程中描述学生行为时常呈现强烈的正面情感倾向;2)部分情感词存在着领域特异性,如形容词“稳定”在描述算法性能时具有正面倾向,但用于描述后进生成绩起伏时,常指停滞不前,呈现负面情感倾向[3],文献[4] 的实验表明不同领域之间的情绪相关性很低。由此可见,通用情感词典在领域情感分析任务中性能表现不佳。故近年学术界对领域情感词典的构建给予越来越多的关注。
1 相关研究
目前,领域情感词典的构建方法有人工标注法,这类方法较为耗时、耗力,覆盖范围亦较为有限[5-6]。伴随社交媒体的数据密集型特征,越来越多的网络热词和新词大量涌现,人工标注法在日百万量级的新词更新速度前失去了应用价值,于是领域词典的自动构建研究已成为当下热点。下面介绍一下领域情感词典的自动构建技术。
1.1 基于领域知识库或领域语料资源的方法
该方法依托于领域知识库或领域语料资源,可分为两类:1)基于知识库和语法规则。该类方法基于现有的HowNet、SentiWordNet 等开源中英文情感词典资源,作为关系或释义的扩充,此类方法较为简单且准确率高,故在当下情感词典构建任务中应用广泛。但该类方法对知识库的高度依赖,因此所构建的词典在领域性上表现欠佳。2)基于海量语料和共现关系。该类方法中最基础且常用的是逐点互信息技术(pointwise mutual information,PMI),它是根据词的共现关系进行基准词的扩充,当基于领域语料库时可高效扩充领域词[7]。但其缺陷在于,词典的可靠性依赖于初始手工标注的种子词质量,这就要求手工标注者对领域具备深刻的理解。
1.2 基于词向量的方法
构建情感词典可采用深度学习优化分词、种子词构建和特征识别过程。深度学习技术在情感分析等自然语言处理中的应用已成趋势,目前流行的深度学习模型包含卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、长短期记忆神经网络(long short-term memory,LSTM)和注意力机制等。文献[8] 通过构建神经网络分类器,基于深度学习技术进行二分类训练,得到金融领域情感词典,同时提出了CNN 与RNN 方法在此类场景中的局限性。文献[9] 使用了卷积神经网络与词频统计(convolutional neural network-term frequency,CNN-TF)结合的方法来计算种子情感词,并使用情感倾向点互信息(semantic orientation pointwise mutual information,SO-PMI)方法构建二分类农业领域情感词典。
基于词向量的方法能直接提取词的相似性信息,对于文本分析相关应用有着非常重要的意义。该方法通过词的分布式学习进行领域词典自动构建,目前常采用Word2vec 模型训练词向量来实现。模型中包含跳字(skip-gram)和连续词袋(continue bag of words,CBOW)两种方法,通过神经网络将词映射到语义空间中。该方法具有规模大、准确性高的优点,在情感特征任务中具有较大价值。文献[10] 将人工筛选的466 个正负情感词作为种子词,通过Word2vec 引入的语义相似性信息框架自动构建旅游领域情感词典,实验表明除召回率外各项指标都优于现有公开词典。但是该方法的局限表现为用语义相似度来判别情感极性存在一定的误差率。
基于此,文献[11] 提出一种扩充CBOW 模型的分布式情感嵌入学习,通过短语级分类器训练大规模Twitter 语料,得到二分类情感词典,评估结果表明其各方面性能均取得较大提升。类似研究对于语义相似度局限性进行了改善,但是提出的模型较为复杂[12],且该模型用于领域情感词典自动构建的可行性还有待论证。
本研究融合了以上两种技术基于词向量模型对词语的语言特征进行提取,引入Skip-gram方法识别低频词从而保证词典的新词覆盖率,并提出使用“情绪对”结合提取词语概率统计特征方法[13],融合特征进行多分类教育领域情感词典(educational-oriented sentiment lexicon,EoSL)构建,包括语料预处理、语言概率特征提取、融合统计概率特征和评估修正过程,如图1 所示。
研究创新点为:
1)提出特征融合的方法。在使用Skip-gram 方法基础上结合本研究提出的R-SOPMI 进行特征融合以提高情感词典的性能指标。
2)提出R-SOPMI 方法。设置“情绪对”基准类别集合,依据“情绪对”映射关系进行共现相似度迭代计算,将二分类方法扩充至多分类,进而对统计概率特征无法识别的情感词进行特征融合计算,从而提高模型准确率。
2 前期准备工作
2.1 情绪类别设置
情绪分类是情感分类下的子任务,属于细粒度文本分析任务,研究所提及的情绪词典与情感词典均为同类词典。目前较权威的情绪分类方法为Ekman 的情绪六分类理论,即基于面部表情将情绪分为乐、哀、怒、惊、恶和惧[14-15]。此外,针对学业情绪的特点,研究以厌学学业情绪为依据新增“倦”类别,该情绪特征在教育领域中独具价值性,与产品评论、股票预测等场景相比,“倦”在教育应用场景中较为常见,与评论者、评论对象具备显著的情绪相关性。在学业情绪分类研究中,文献[16] 依据Pekrun 的学业情绪理论,设置消极低唤醒情绪,包含厌倦、无助、沮丧、疲倦和失望,研究选取这5 个词作为“倦”的种子词。
DUT 为大连理工通用情绪词汇本体的名称,依据Ekman 将类别扩充为7 大类共27 466个情感词[17]。NRC 为加拿大国家委员会词典,包括怒、惧、惊、哀、乐、恶、期待和信任8种情绪。研究以DUT 7 个类别情绪为基础,选取NRC 中与DUT 交叉的6 个类别情绪并与DUT 求并集整合得到通用情绪词典,延续DUT 情绪细分标准。采用“好-恶、乐-哀、怒-惧、惊-倦”作为目标情绪类别,以便进行后期R-SOPMI 处理,见表1。
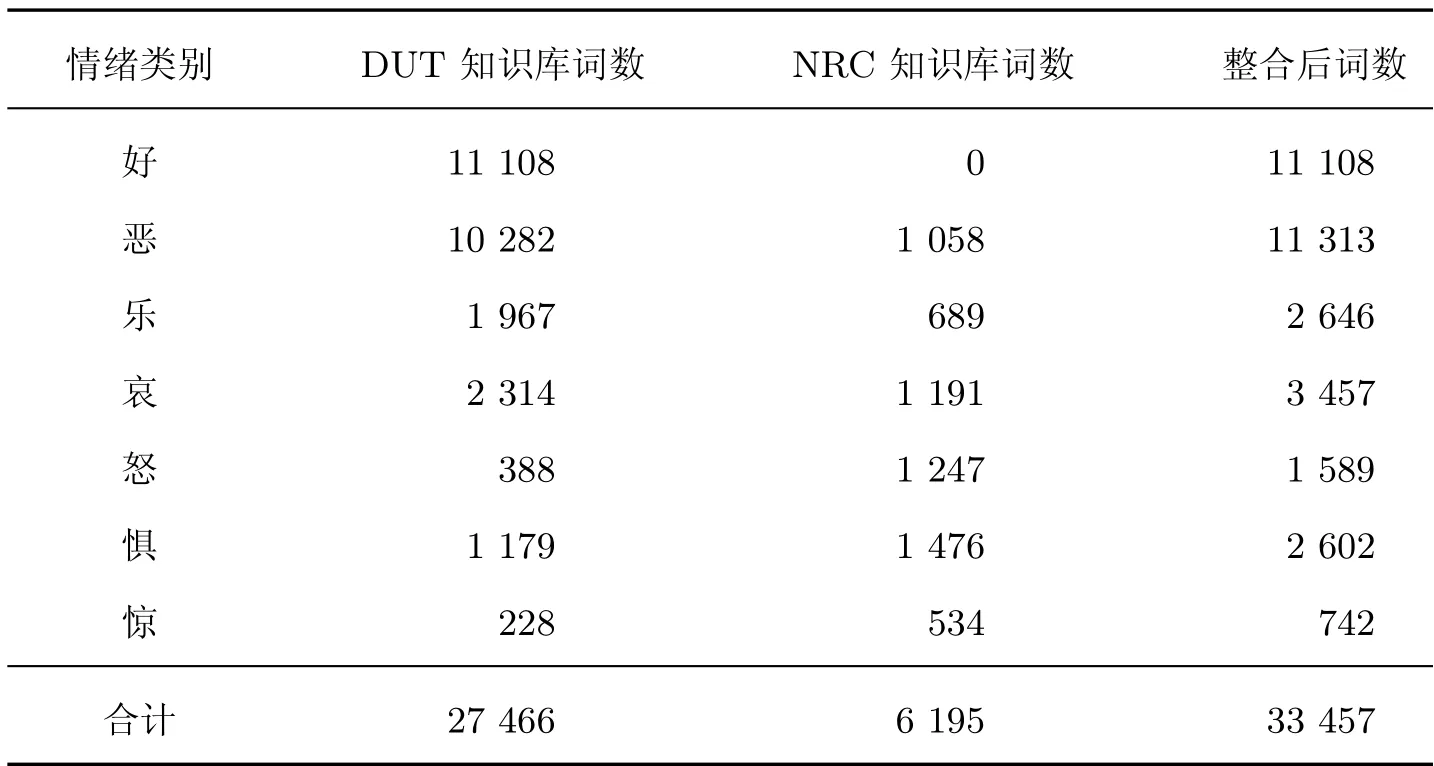
表1 DUT 与NRC 知识库整合情况Table 1 Integration of DUT with NRC knowledge base
2.2 语料库构建
教育领域的公开语料库资源较为匮乏,本文通过爬虫程序构建教育领域情感词典的语料,包含以下内容:1)爬取教育类微博文本,随机爬取新浪微博中通过了平台认证的教育博主2018 年以来的微博;2)选取中国大学MOOC、果壳网和学堂在线这3 个平台,随机爬取课程截止于2021 年5 月1 日的学生评论文本。爬取得到7 万余条文本用以构建教育领域语料库,并进行语料预处理:首先,采用正则表达式,完成语料的清洗过滤掉无意义符号字符;修正教育领域情感停用词表,在原有1 893 个停用词表中去掉带有情感倾向的停用词,得到含有1 625 个停用词的停用词表;最后,使用jieba0.42.1 工具调用上述操作得到的语料文本和停用词词表,进行分词。
3 情感词典构建
3.1 语言概率特征计算
将预处理后的语料形成词表,与DUT、NRC 整合知识库进行词表交集处理,匹配情绪特征,形成各情绪类别种子词集合,见表2。“倦”情绪类别仍按上文介绍的5 个种子词进行构建。研究采用Word2vec 模型进行语言概率特征计算,进而计算语料库词表与种子词集合的相似度,并进行词表扩充。

表2 情绪基准词集合数量Table 2 Number of emotional benchmark word sets
在语言概率模型中,往往很难结合语义。Tomas Mikolov 在2013 年发布了开源的Word2vec 工具,能训练高维度稠密词向量。Word2vec 包含Skip-gram 模型和CBOW 模型,能处理百万级别的超大数据集,训练高质量词向量。
Skip-gram 模型是通过当前语义单元来预测上下文的,如图2 所示。CBOW 模型则是通过上下文来预测当前语义单位的,相较之下,Skip-gram 模型对低频词的敏感度更好,算法精度更高,在存在较多新词的情况下总体性能更优,故选取Skip-gram 进行模型训练。
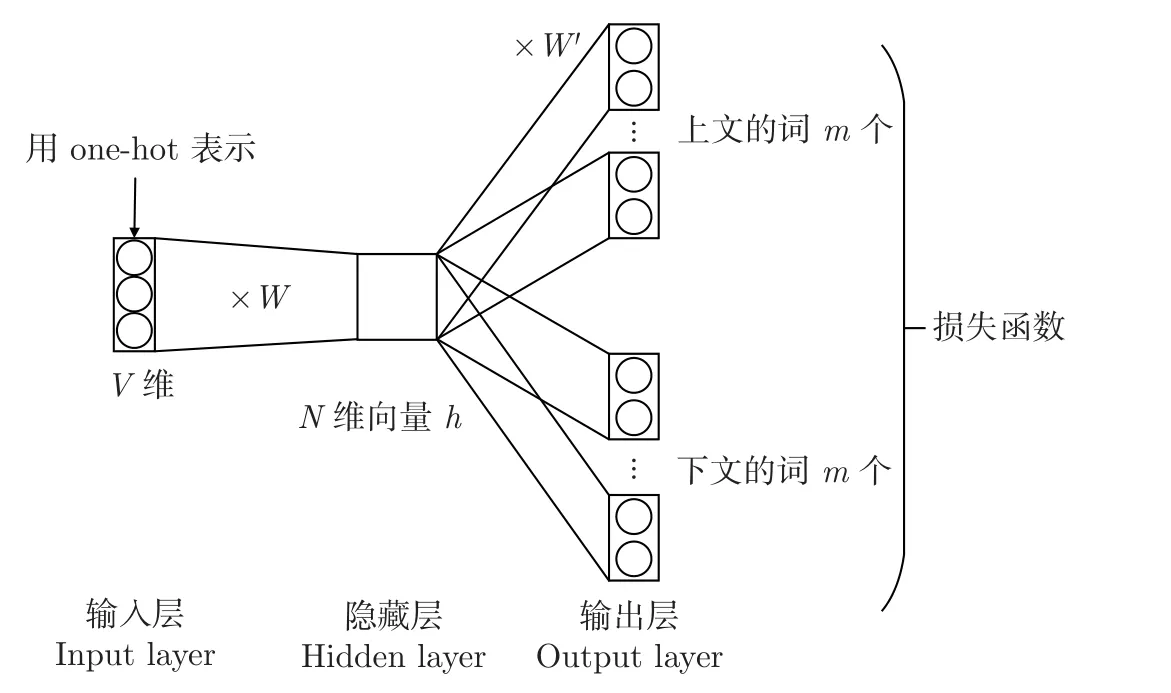
图2 Skip-gram 模型结构示意图Figure 2 Skip-gram model structure diagram
由图2 可知,该模型首先将中心词ω以one-hot 编码方式存储,以上下文的损失函数之和作为目标函数,损失函数为
式中:T为文本序列长度,t为ω的索引,m为窗口大小。利用F计算已知ω的情况下上下文出现的概率,之后,模型采用随机梯度下降进行迭代,迭代子序列中的中心词和背景词向量计算输入侧权重,产生对应行向量,作为词的分布式向量表示。
本实验调用gensim 库、jieba 库与re 库来实现Skip-gram。结果表明,设定输出词向量的维度size 为140,窗口距离window 为5,采用负采样方法且负采样个数negative 为5,此时结果最优。训练好的模型通过余弦距离判断相似性[18],公式为
式中:ω1和ω2分别为两个相异词元,该模型能很好地进行词之间的相似度判断,但仍存在情感词极性歧义,如“不厌其烦”与“棘手”在向量空间中的余弦相似度较高,为0.813 2(相似度最高不超过1),但两词“不厌其烦”与“棘手”分属于“好”与“恶”类别。研究面对这一问题提取候选关键词输出结果,取相似度大于0.6 的词作为候选关键词,筛选出其具备的语义特征,并依据上文已作映射的“好-恶、乐-哀、怒-惧、惊-倦”进行候选关键词库过滤。
3.2 统计概率特征
在获得高质量的基准词集合后,研究通过R-SOPMI 计算词的共现性以获得其统计概率特征,在语言统计特征的基础上使用结合技术,进行教育领域情绪词典的构建。SO-PMI 是在PMI 的基础上进行改进,公式为
式中:ω为目标词,P(ω)和P(sword)分别为词ω和sword 出现的概率,P(ω,sword)为词ω与基准词sword 共同出现的概率,SO-PMI(ω) 为目标词的情感倾向点互信息值,PMI(ω,sword)能通过词之间共现的频繁程度表示目标词与基准词之间的语义相似度,Ssome-kind为某一类别情绪词集合,Sothers为其他类情绪词集合之和[19]。
3.3 词典扩充
词典扩充通过设置“情绪对”基准类别集合,将二分类SO-PMI 方法改进至多分类R-SOPMI 方法实现。具体实现步骤如下:
步骤1词向量训练。以某一情绪组为例,根据映射关系迭代语义相似度运算,得到经过语言概率特征计算的扩充词表。
步骤2进行子集的顺序运算,公式为
式中:ωt为计算目标词,Si和Aj分别为上文中对应映射组的基准情绪词集合,SO-PMI(ωt)为改进算法中目标计算词的情感倾向点互信息值。若SO-PMI(ωt)>0 则形成Si候选情绪词集合;若SO-PMI(ωt)<0 则形成Aj对应类别集合;若SO-PMI(ωt)=0 则形成中性候选情绪词集合。
步骤3在扩充词表中删除中性候选情绪词,完成教育领域情感词典EoSL 构建。
最终得到的教育领域情感词典EoSL,包含39 138 个词,扩充结果见表3。
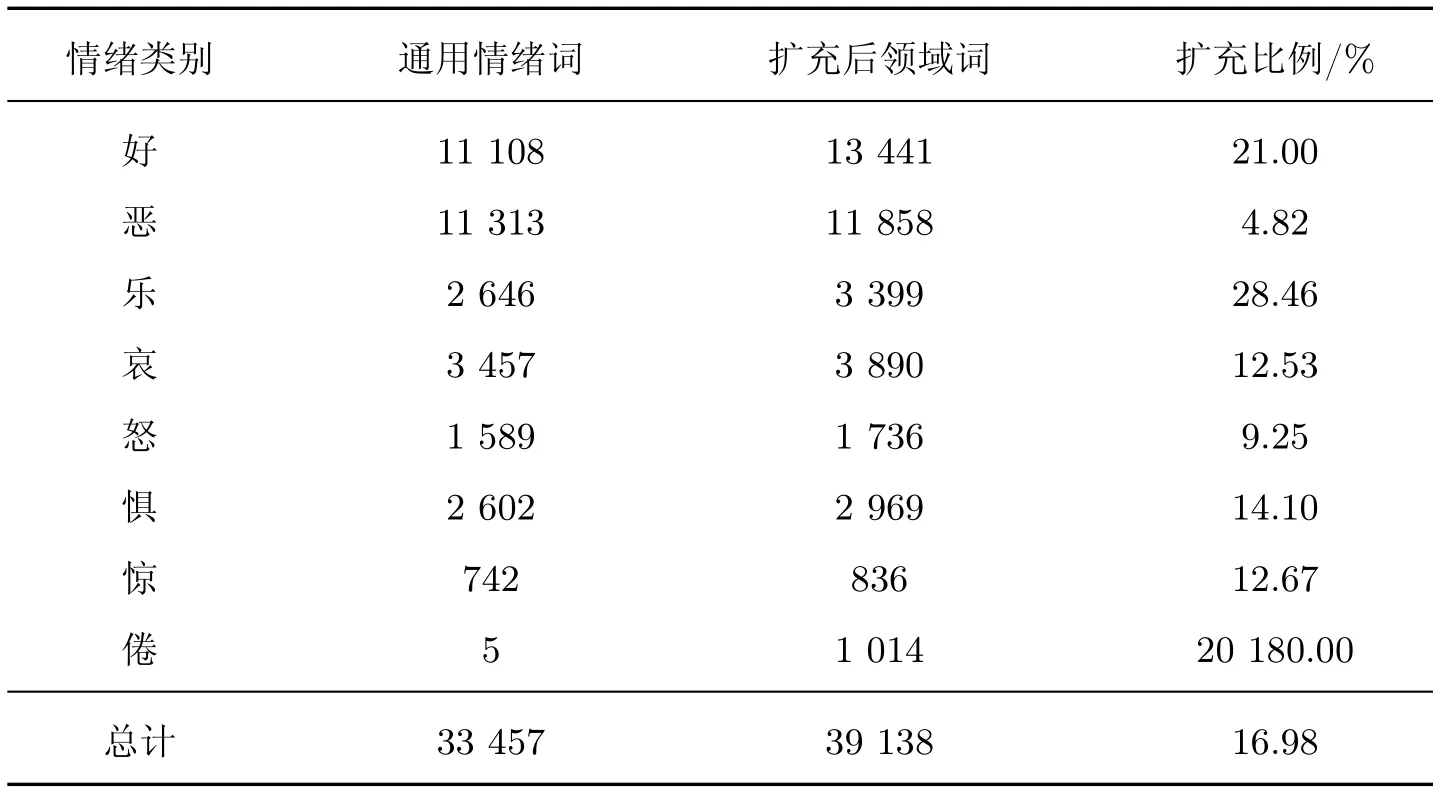
表3 词典扩充结果对比Table 3 Comparison of dictionary expansion results
4 评估
为评估改进算法性能和扩充后的教育领域情感词典性能,本文将R-SOPMI 与SO-PMI进行对比实验,将扩充后的教育领域词典EoSL 和融合DUT、NRC 得到的通用情绪词典进行对比实验。
4.1 R-SOPMI 与SO-PMI 性能对比
算法平均复杂度由算法性能、种子词质量和训练语料大小决定。本实验采用同一种子词集合比较不同规模训练语料数据集对应的精确率及其变化趋势,以对R-SOPMI 与SO-PMI进行对比。SO-PMI 算法只能处理二分类问题,故实验针对每一情绪类别,以单一类别为一分类,其余情绪类别为二分类方法实现SO-PMI 算法处理。
实验结果由图3 可知,恶、哀、怒和倦这4 类情绪随着语料规模的增加,R-SOPMI 始终高于SO-PMI,整体在性能上提升显著。语料规模增加过程中,情绪“乐”在[122.2,239.5] 区间内,情绪“惧”在[111.3,275.8] 区间内,R-SOPMI 的精确率低于SO-PMI 算法,随着语料规模继续增加,最终在大规模语料上R-SOPMI 的精确率比SO-PMI 算法分别高出14.31%和17.40%。两类算法中情绪“惊”的精确率都处于较低水平,当语料大于275.8 万之后,最终R-SOPMI 的准确率高于SO-PMI 算法,且提高了15.09%。情绪“好”在较小语料时精确率略高于SO-PMI 算法,当语料增大到78.6 万时开始低于SO-PMI 算法,其原因可能是该情绪在语料中分布较多,随着语料的增加引入了误差,降低了情绪类别精确率。
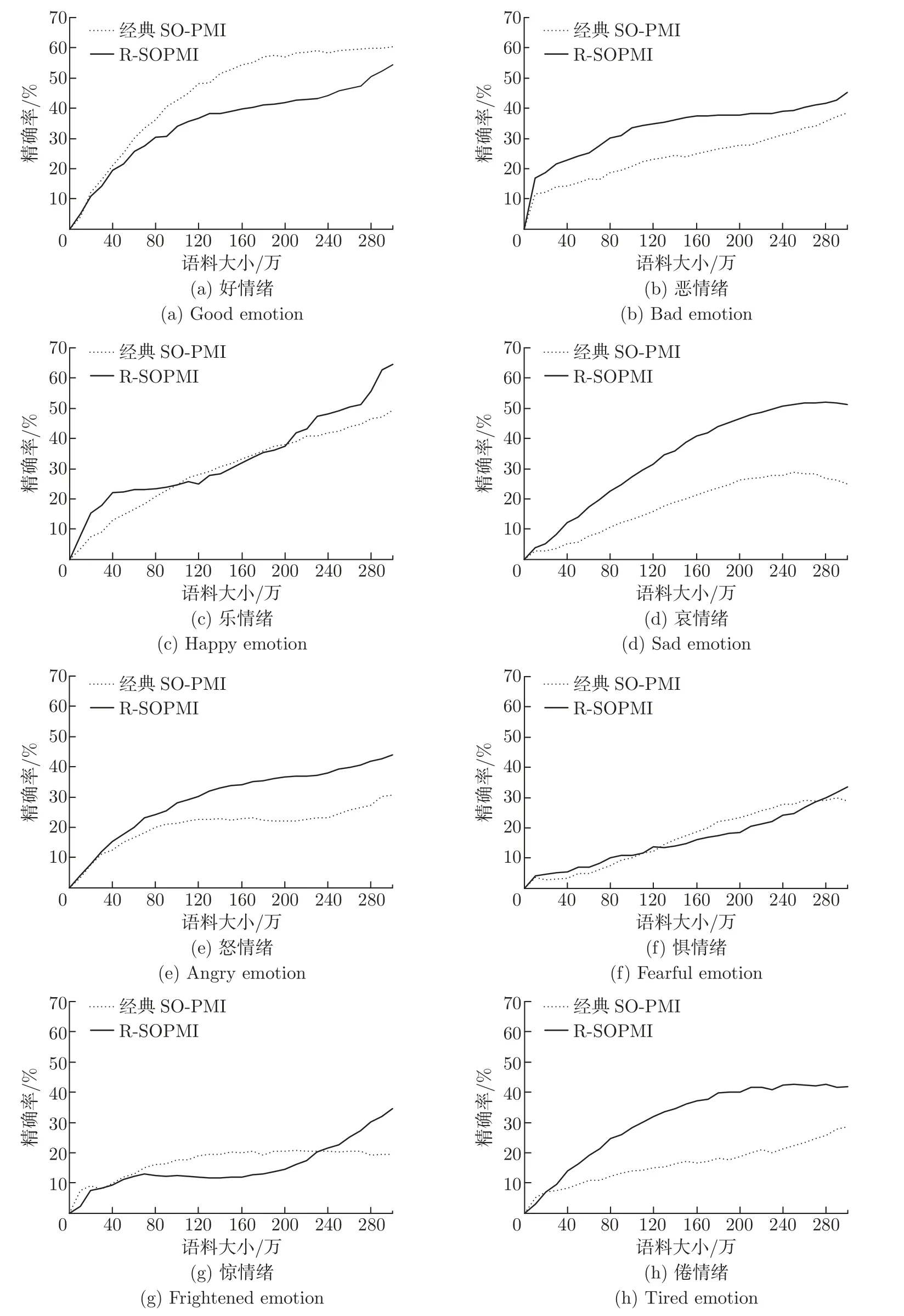
图3 R-SOPMI 精确率对比Figure 3 R-SOPMI accuracy rate comparison
4.2 词典性能评估
由词典扩充结果可知,8 种情绪在分布上不均衡,故采用精确率PPrecision、召回率RRecall和F1 进行评估。随机抽取4 000 条文本作为测试集,并进行手工标注。对比情绪类别输出结果与人工标注结果,进行精确率、召回率和F1 的计算:
式中:TP 为输出结果与人工标注相匹配数量,FP 为输出结果不在人工标注数量,FN 为未成功识别数量。性能评估结果如表4 所示,表中通用情绪词典指通过人工操作将DUT、NRC 中原有词与情绪类别进行关联[20],粗体为较优指标。通用情绪词典不包含“倦”情绪,因此表4中“倦”情绪对应通用词典的实验数据为空。
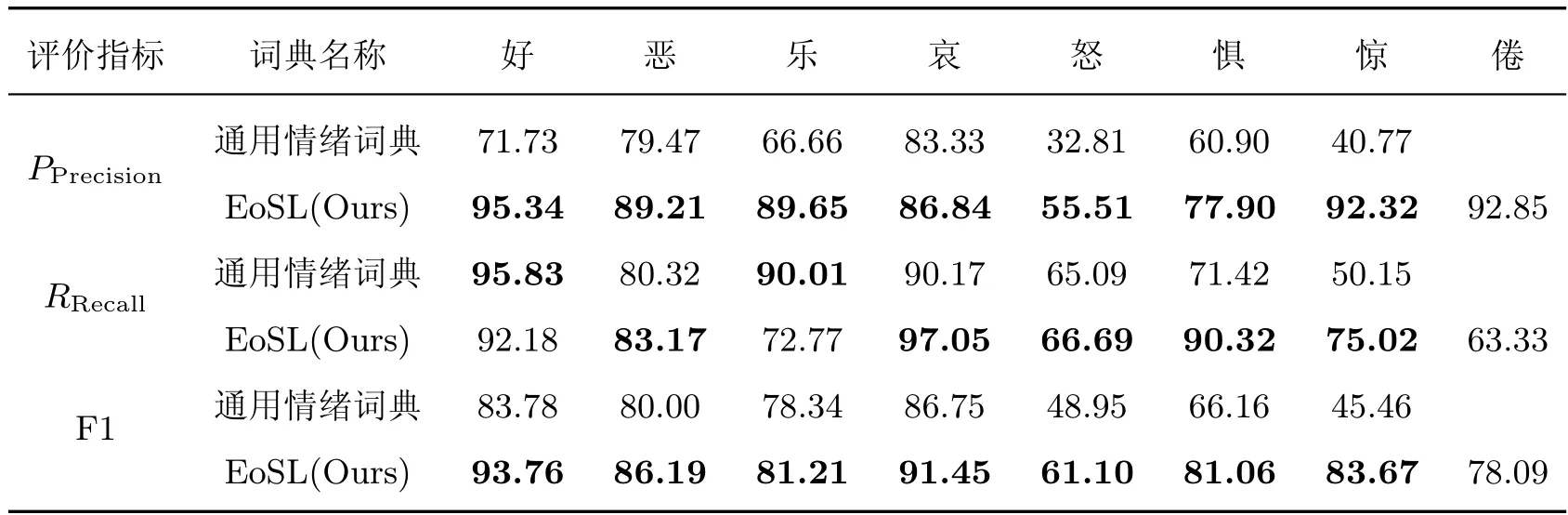
表4 各情绪类别精确率、召回率和F1 对比图Table 4 Comparison of PPrecision, RRecall and F1 by sentiment category %
由表4 可知,较于融合DUT、NRC 的通用词典,除“好”和“乐”的召回率外,各指标性能均处于较高水平:1)各情绪类别的精确率表现良好,好、恶、乐、哀、惊和倦这6 类情绪的准确率表现显著,均高于86.84%,表明歧义词数量少;2)情绪“惊”在3 类指标上均有大幅提升,其中F1 提升了38.21%,综合性能的提升在所有类别中最为显著。其原因应为增加“倦”情绪类别与惊情绪类别构成“情绪对”,通过引入R-SOPMI 算法提高了各项性能指标;3)情绪“怒”在整体中表现欠佳,虽然F1 值比通用词典提升了12.15%,但仅达到61.10%,导致其扩充后性能不佳的原因是“怒”在教育领域中出现频率较低,对于其情绪词的领域内情境依赖关系的挖掘还较欠缺,可考虑在语料库中增加富含怒情绪的事件。
根据上述指标可以计算出词典的宏平均准确率为84.18%,较通用词典提升了21.95%,其宏平均召回率为80.07%,较通用词典提升了2.50%,其宏平均F1 为82.08%,较通用词典提升了13.01%,充分证明了“情绪对”融合特征模型对于领域情绪知识扩充的有效性。
此外,将本文词典与深度学习技术所构建的词典进行比较,文献[9] 使用了CNN-TF 卷积神经网络与词频统计结合的方法构建二分类农业领域情感词典,见表5。本文采用了通用性较强的Word2vce 方法,自动生成情感种子词,再改进到R-SOPMI 算法中,实现对细粒度情绪的情感倾向计算。尽管在表5 中京东数据集上的综合精确率为82.88%,略好于本文中“乐”、“惧”和“倦”的精确率指标,但考虑到文献实现的是粗粒度二分类,对比本文细粒度多分类(多分类方法对比二分类方法具备性能下降属性)区别并不显著;且对比文献的方法使用了人工调精处理,本文方法未进行人工筛选种子词,故本文词典构建方法具备差异化优势。
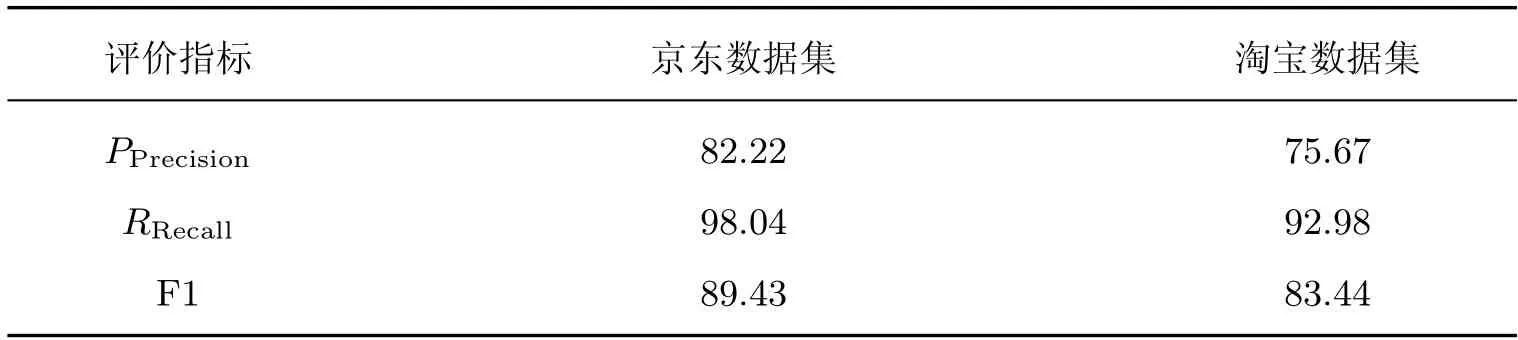
表5 CNN-TF 深度学习领域词典实验结果Table 5 CNN-TF deep learning field dictionary experimental results %
5 结语
本文提出了一种基于“情绪对”融合特征模型扩充的教育领域情感词典构建方法。首先通过词向量进行语义相似度判断,实现“情绪对”扩充,为词典初步构建节省时间;然后采用R-SOPMI 算法按“情绪对”进行词典调整,并结合统计概率特征对模糊词分类。经过实验评估,以上方法能得到性能良好的结果,除“怒”和“惧”外各情绪类别精确率均达到86.84%;除“怒”和“倦”外,召回率均达到72.77%;除“怒”外,F1 均达到78.09%。从性能提升上看,各情绪类别指标均大幅提升,其中“惊”精确率提升了51.55%,召回率提升了24.87%,F1 提升了38.18%。该词典仍然存在着改进的空间,通用词典中部分词的情绪分类标签在教育领域中的适切性并不高,如“重点”在DUT 本体库中划分为惧,而“重点”在教育领域常用于强调能够把握重点知识点,应属于好这一情绪类别。因此,如何结合语义知识优化教育领域情感词典,将成为下一步研究目标。
猜你喜欢
文苑(2019年24期)2020-01-06
电脑与电信(2018年10期)2018-12-29
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
海外华文教育(2016年1期)2017-01-20
湖南师范大学教育科学学报(2015年4期)2016-01-06
当代教育理论与实践(2015年9期)2015-12-16
当代教育论坛(2014年1期)2014-11-10
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
