
基于振动信号的中速磨煤机故障识别
2023-12-06 10:48陈雪飞徐文杰
数字制造科学 2023年4期
陈雪飞,杨 锴,徐文杰,谢 丹
(1.国能长源武汉青山热电有限公司,湖北 武汉 430080;2.武汉理工大学 机电工程学院,湖北 武汉 430070)
磨煤机是锅炉制粉系统最重要的辅机设备,目前,磨煤机故障主要由经验丰富的操作人员来判断。但由于燃煤电厂现有监测手段的诊断逻辑简单,方法单一,加之现场运行数据中所包含的故障状态和故障数据不完整,增加了开展相关研究的难度,导致只有少数学者进行了相关的研究。
基于数学模型和人工智能的故障诊断方法是磨煤机故障诊断相关研究的主要方法。在基于数学模型的故障诊断方法中,首先需对复杂的机理进行分析,建立数学模型,然后比较系统测量值和数学模型预测值之间的差值计算残差,以此判断故障是否发生[1]。基于人工智能的磨煤机故障诊断方法利用分布式控制系统(distributed control system,DCS)获取海量运行数据,通过机器学习和人工智能技术对磨煤机进行故障诊断[2]。大部分研究均利用温度、电流、风压等对磨煤机故障进行诊断。
由于燃煤电厂磨煤机的初始设计测点并未包含振动测点,致使该设备少有进行振动监测,而磨煤机振动是磨煤机的常见症状, 且当磨煤机振动异常时,若不及时处理,会造成接头断裂、加速硬件磨损等,甚至被迫停磨,因此磨煤机振动异常将严重影响机组安全运行和经济性能。
目前,常见的振动故障研究方法是对采集的振动信号通过信号处理方法提取故障特征,然后利用机器学习算法进行分类识别。对于信号的处理,希尔伯特黄变换(hilbert-huang transform,HHT)是一种新的非平稳信号的时频分析方法[3]。EMD (empirical mode decomposition)在HHT中起到关键作用,但EMD存在模式混叠现象,端点效应和停止条件难以判定等缺点。文献[4]为抑制模态混叠现象与端点效应缺陷,利用EEMD(ensemble empirical mode decomposition)改进的HHT进行轴承故障特征提取,结果表明EEMD虽能对模态混叠现象起到一定抑制作用,但不能完全消除。为了解决这个问题,文献[5]提出了变分模态分解(variational modal decomposition,VMD)。与EMD递归筛选模式相比,VMD将信号转化为非递归的变分模态分解模式,具有较好的鲁棒性和稳定性[6]。
针对上述问题,笔者基于所构建的磨煤机振动监测系统采集的振动信号,提出一种K值优化的VMD-HHT边际谱结合最小二乘向量机(least squares support vector machine, LSSVM)模型,应用于磨煤机的故障诊断。
1 构建磨煤机振动监测系统
1.1 传感器安装
根据某电厂#14机组制粉系统的磨煤机现场运行环境,在综合考量实用性和经济性后,最终选择安装精确度为±1%以内,线性度为±2%,分辨率为0.15 mm/s rms,灵敏度为19.7 mv/mms的一体化测振传感器。
由于磨煤机本体的大多数部位表面温度较高,为保证所选传感器存活率,综合考量安装需求和后续采集数据的便利性,选择磨煤机中架体的吊耳安装振动传感器,如图1所示。

图1 振动传感器安装位置
1.2 振动信号采集效果分析
所装的振动传感器采集到的振动数据通过带屏蔽层线缆传输到DCS系统。本文所用数据样本来源于某电厂#14机组制粉系统中速磨煤机故障数据。数据样本包括正常情况、磨煤机断煤、磨辊损坏、磨内有异物、及碾磨油压下降5种状态引起磨煤机振动异常的原始振动数据。
选择各故障前后2.5 min,300个采样点为一个数据样本。图2为磨煤机5种状态的原始振动数据。由于每个类型对应不同样本的原始振动数据类似,因此本文只列举5种类型对应单个样本的原始振动数据。从图2可知,磨煤机正常运行和发生故障时的振动信号波形有所不同,发生不同故障时,振动信号波形也各有特征。
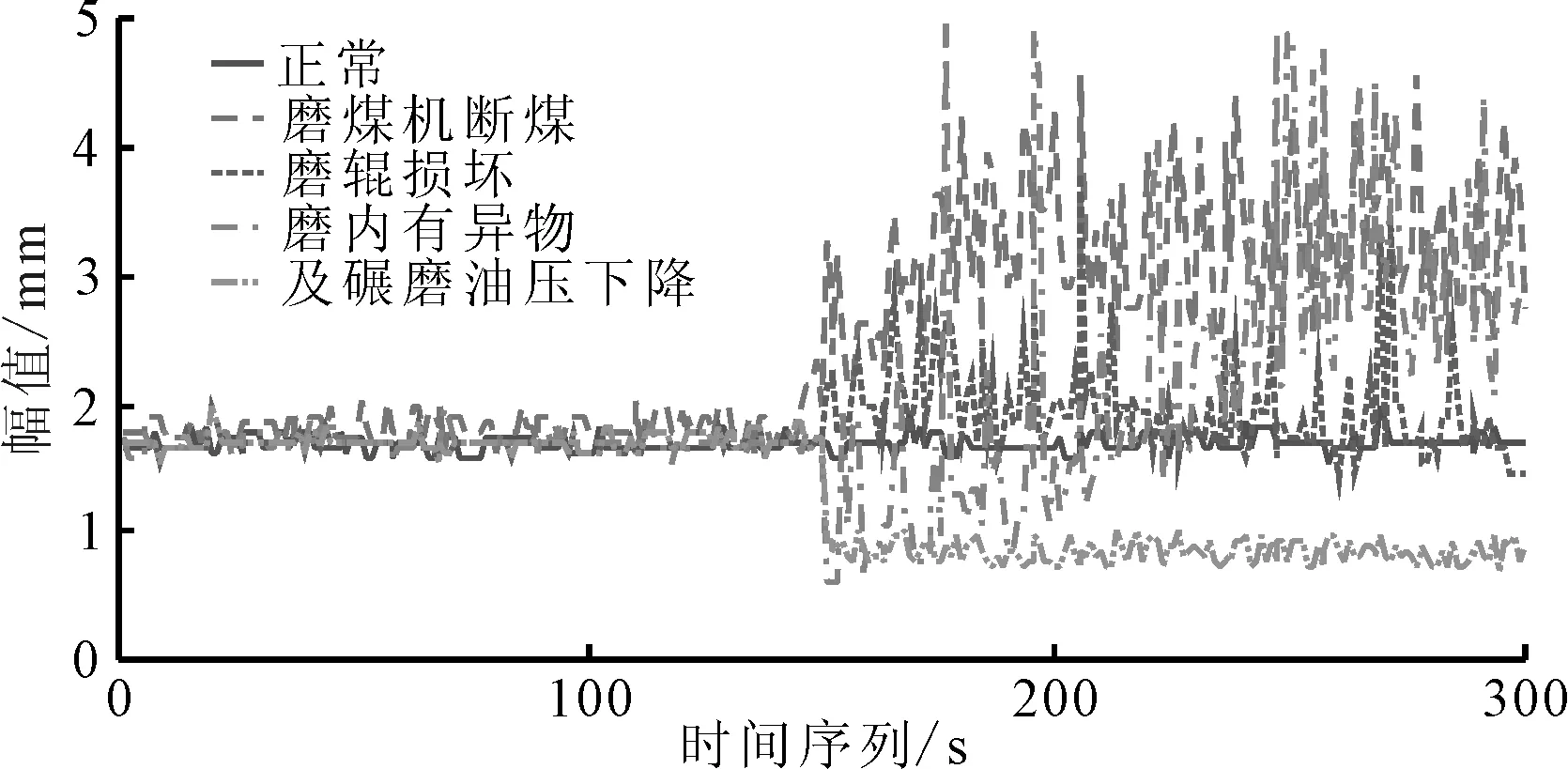
图2 数据样本图
2 VMD-HHT边际谱
2.1 VMD
2.1.1 VMD原理
VMD算法中,本征模态函数(intrinsic mode function, IMF)被定义为一个调幅-调频信号:
uk(t)=Ak(t)cosφk(t)
(1)
式中:Ak(t)为uk(t)的瞬时幅值。ωk(t)为uk(t)的瞬时频率,wk(t)=dφk(t)/dt;φk(t)为相位。
uk(t)视为幅值为Ak(t)、频率为ωk(t)的谐波信号。
若原始信号可分解为K个IMF分量,则变分约束模型为:
(2)
式中:uk为K个本征模态函数(IMF);ωk(t)为各IMF的中心频率;δ(t)为单位脉冲函数;j为虚数单位;t为时间;ω为频率。
为求解上述模型的最优解,引用ξ来避免约束最小值现象的出现。
(3)
式中:ξ为增广拉格朗日函数;α为惩罚参数;λ(t)为拉格朗日乘子;f(t)为原始信号。
VMD分解与EMD分解有所不同的地方在于EMD分解无需设置参数,而VMD算法需要设置参数,因分解受惩罚参数α和分量个数K的影响,分量个数K值会直接影响最终的处理结果,同时惩罚参数α值越大,得到各IMF分量的带宽越小。
2.1.2 VMD中K值的确定
VMD需要事先选定模态数K,每个模态的区分主要是中心频率的不同。模态分解个数较少时,原始信号中一些重要信息将会被滤掉丢失;信号的分解个数较多时,会产生频率混叠。因此,笔者采用相邻模态分量的相关性确定K[7]。相邻模态的相关系数如表1所示。

表1 相邻模态的相关系数
表1中,Cab为分解出的第a个模态和第b个模态的相关系数。当分解层数K不断增加,IMF分量会出现通频带重合,发生模态混叠的现象,从而导致振动信号的过分解。出现模态混叠之后,多个低频模态成分会被合并,同时高频成分也被分解到了低频成分中,从而导致低频成分之间相互影响的增加,即相关系数Cab会增大。但如果继续加大分解层数,高频成分会被继续分解到低频成分中,从而增加了低频成分中的噪声和杂波,反而可能降低低频成分之间的相关度。当模态数K小于4时,相邻模态分量的相关系数均小于0.15,这表明模态分解正常。当K为4时,分解出的低频模态分量的相关系数相较于K=2、3时,明显增大。笔者认为此时IMF分量出现混叠的现象,导致振动信号过分解。因此对振动信号进行VMD分解时模态数设为3。此外,α采用VMD默认值2 000,τ设为0.3,以保证实际振动信号分解的保真度。
2.2 HHT边际谱
HHT边际谱是将VMD分解得到的IMF分量进行计算,具体计算步骤如下:
步骤1VMD计算IMF分量ci的f(t):
(4)
步骤2计算原始信号f(t)的H(α,t):
(5)
步骤3HHT边际谱计算公式为:

(6)
HHT边际谱能反映信号中是否存在这一频率信号,其数值大小更是直接反映这一频率可能在信号中存在概率的大小。
3 LSSVM原理
最小二乘支持向量机LSSVM是支持向量机SVM(support vector machine)的改进, 它能够处理分类和回归问题,且尤其擅长对小样本数据的机器学习。它使用损失函数的线性最小二乘准则代替不等式约束[8]。基本原理是:给定一组训练样本,通过对一个最小化正则化误差的二次规划问题求解,得到一个最优超平面,从而实现对新样本的预测和分类。原空间中,具有等式约束的LSSVM可表示式为:
s.t.yi=wTφ(x)+b+ei
(7)
式中:J(w,e)为目标函数,yi为约束函数;w为权重向量;b为误差;γ为惩罚因子;ei为松弛变量。
拉格朗日函数L可表示为:
L(w,b,e,α)=J(w,e)-
(8)
其中αi为拉格朗日乘子。根据The Karush-Kuhn-Tucker(KKT)条件求解,则LSSVM模型如式(9)所示,该方程为多维空间中的曲线:
(9)
式中:K(x,xi)为核函数;x为训练集样本的输入向量;αi、b为式(9)的求解结果。
Mercer核函数有几种不同的类型,如sigmoid、多项式和径向基函数。径向基函数RBF(radial basis function)是核函数的常见选择,需要设置的参数很少,且总体性能很好。因此,选择RBF作为核函数。
(10)
因此,LSSVM模型需要优化两个参数,即高斯径向基核函数的参数σ2和惩罚因子γ,使用5折交叉验证法[9]来确定LSSVM最佳的参数σ2和惩罚因子γ。
4 故障诊断方法及实例
4.1 故障诊断方法
基于所构建的磨煤机振动监测系统采集的振动信号,利用VMD-HHT边际谱结合灰狼算法优化最小二乘向量机LSSVM方法对磨煤机进行故障诊断,诊断流程如图3所示。
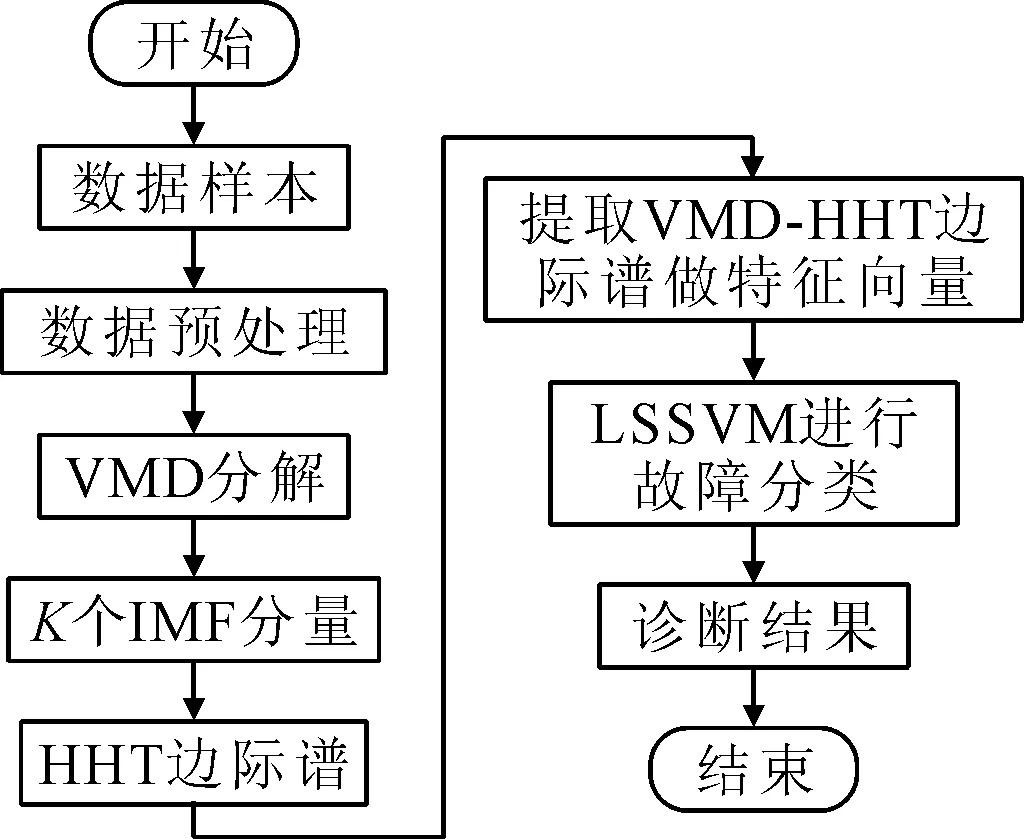
图3 故障诊断流程图
故障诊断的具体步骤如下:
(1)为增强算法的鲁棒性,提高方法的准确性和性能,先对数据样本进行db3层小波包去噪,然后进行中心化和标准化处理,中心化和标准化公式如下:
z=(s-μ)/σ
(11)
式中:s为原始数据样本;μ为平均值;σ为标准差;z为结果。
(2)确定VMD分解层数K(经计算K=3),对数据样本进行分解。
(3)求取K个IMF的边际谱。
(4)提取VMD-HHT边际谱做特征向量,建立基于振动信号的磨煤机故障典型样本空间。
(5)将特征向量输入LSSVM进行故障分类。
(6)根据故障分类结果得出最终的结论。
4.2 故障诊断实例
4.2.1 数据样本获取
定义正常情况为类型F1,磨煤机断煤引起磨煤机振动异常为类型F2,磨辊损坏为引起磨煤机振动异常为类型F3,磨内有异物引起磨煤机振动异常为类型F4,碾磨油压下降引起磨煤机振动异常为类型F5。所用数据样本来源于某电厂制粉系统的故障数据,包括20组F1、20组F2、5组F3、5组F4及10组F5。由于故障样本整体不均衡,采用SMOTE(synthetic minority oversampling technique)算法将少数类样本扩充合成新样本[10]。
SMOTE算法的生成过程为:
(1)对于少数类中每一个样本m,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
(2)根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本m,从其k近邻中随机选择若干个样本,假设选择的近邻为mn。
(3)对于每个随机选出的近邻mn,分别与原样本按式(12)构建新样本mnew:
mnew=m+rand(0,1)×(mn-m)
(12)
对F3和F4样本集,取N=4,k=5,各合成新样本15条,使F3和F4样本与F1样本数据量相同。对F5样本集,取N=2,k=3,合成F5样本总计10条,使F5样本与F1样本数据量相同。
4.2.2 数据特征提取
对数据样本进行db3层小波包去噪,然后进行中心化和标准化处理后,分别以5种状态下的振动信号的特征提取结果为例进行说明,每个类型对应不同样本的特征提取结果类似,因此只列举5种类型对应单个样本的特征提取结果。
为了验证VMD-HHT边际谱的诊断识别效果,利用EMD-HHT边际谱和EEMD-HHT边际谱对振动信号的5种状态进行特征提取,如图4(a)~图4(c)所示。从图4可知:①EMD-HHT边际谱的故障特征频率幅值混叠,无法清晰辨识不同故障信号的主要频率成分;②EEMD-HHT边际谱相较于EMD-HHT边际谱,故障特征频率幅值相对清晰,但仍无法完全清晰辨识不同故障信号的主要频率成分;③VMD-HHT 边际谱相对于EEMD-HHT边际谱、EMD-HHT 边际谱而言,能直接清晰辨识故障特征频率幅值。
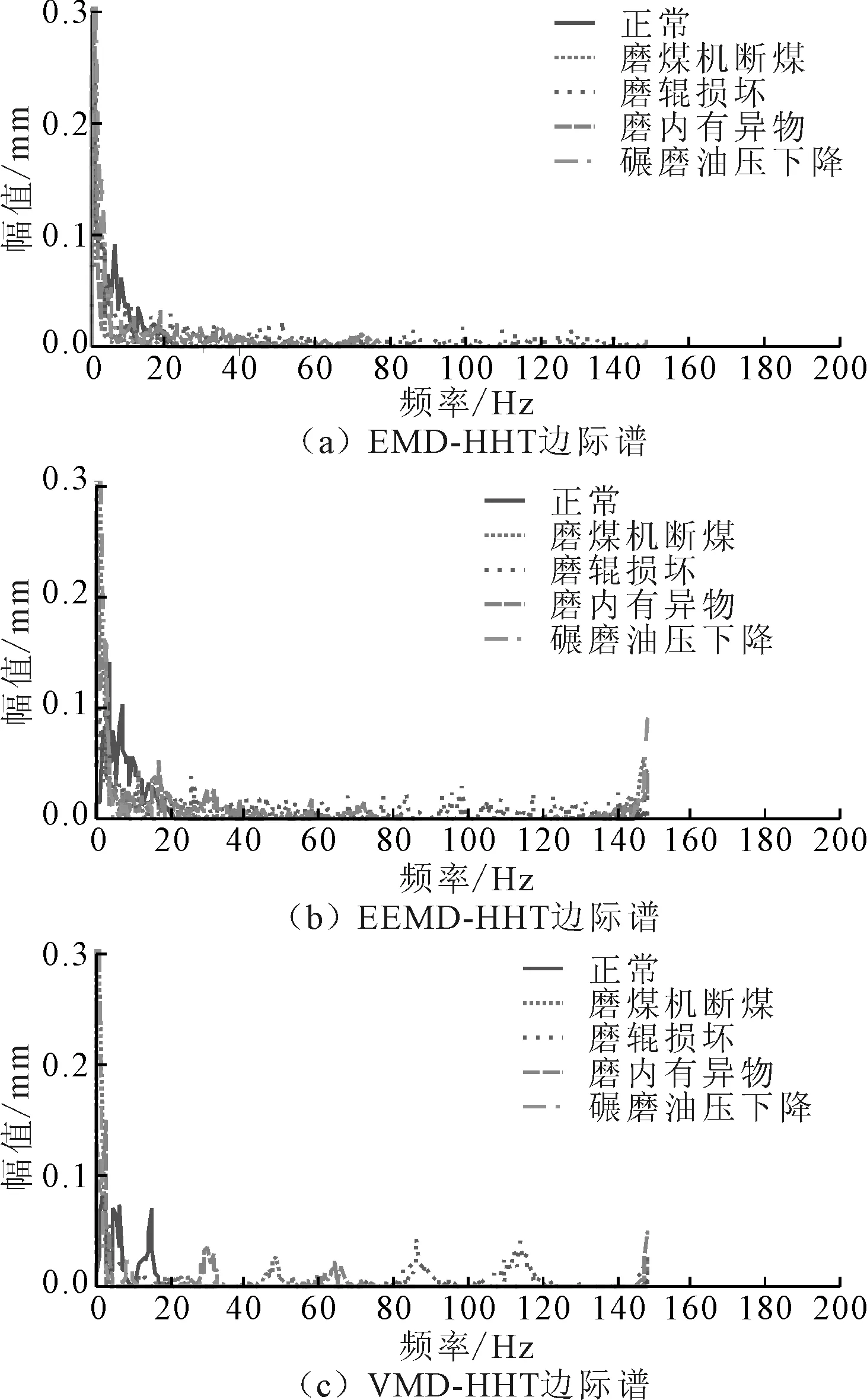
图4 各边际谱的特征提取结果
为了进一步分析VMD-HHT边际谱的特征提取效果,设置幅值上限值为0.1,其VMD-HHT边际谱-2如图5所示。从图5可知,特征提取结果不仅在不同的频率段有各自的波峰特征,且各波峰幅值也有所不同。在图5中,F1类型特征提取结果中,在0~10 Hz和10~20 Hz有数个波峰;F2类型特征提取结果中在20~30 Hz和45~55 Hz有数个波峰;F3类型特征提取结果中在10~15 Hz、85~95 Hz和100~120 Hz有数个波峰;F4 类型特征提取结果中在25~35 Hz和55~70 Hz有数个波峰;F5类型特征提取结果中在5~10 Hz和25~35 Hz分别有数个波峰。因此,不同故障引起磨煤机振动异常对应的特征提取结果都可以表征引起振动故障的具体原因。

图5 VMD-HHT边际谱-2
4.2.3 诊断结果及分析
将VMD-HHT边际谱作为磨煤机故障GWO-LSSVM(grey wolf optimizer-LSSVM)模型的输入特征样本。数字标签1~5分别分配给F1,F2,F3,F4,F5 5种状态。经SMOTE算法处理后,各样本均有20组,总共100个样本。分别取各样本10组,共50组用于训练,剩下的50个样本用于测试。将训练样本和测试样本分别集成到GWO-LSSVM模型中进行分类故障识别。为了达到满意的效果,使用5折交叉验证法[10]来确定GWO算法的种群大小和迭代次数。选择种群大小为20,迭代次数为50。
将50种训练样本整合到GWO-LSSVM模型中,进行5种类型的特征训练。训练完成后,将剩下的50组测试样本输入到训练好的GWO-LSSVM模型中进行分类验证。训练分类效果如图6所示。
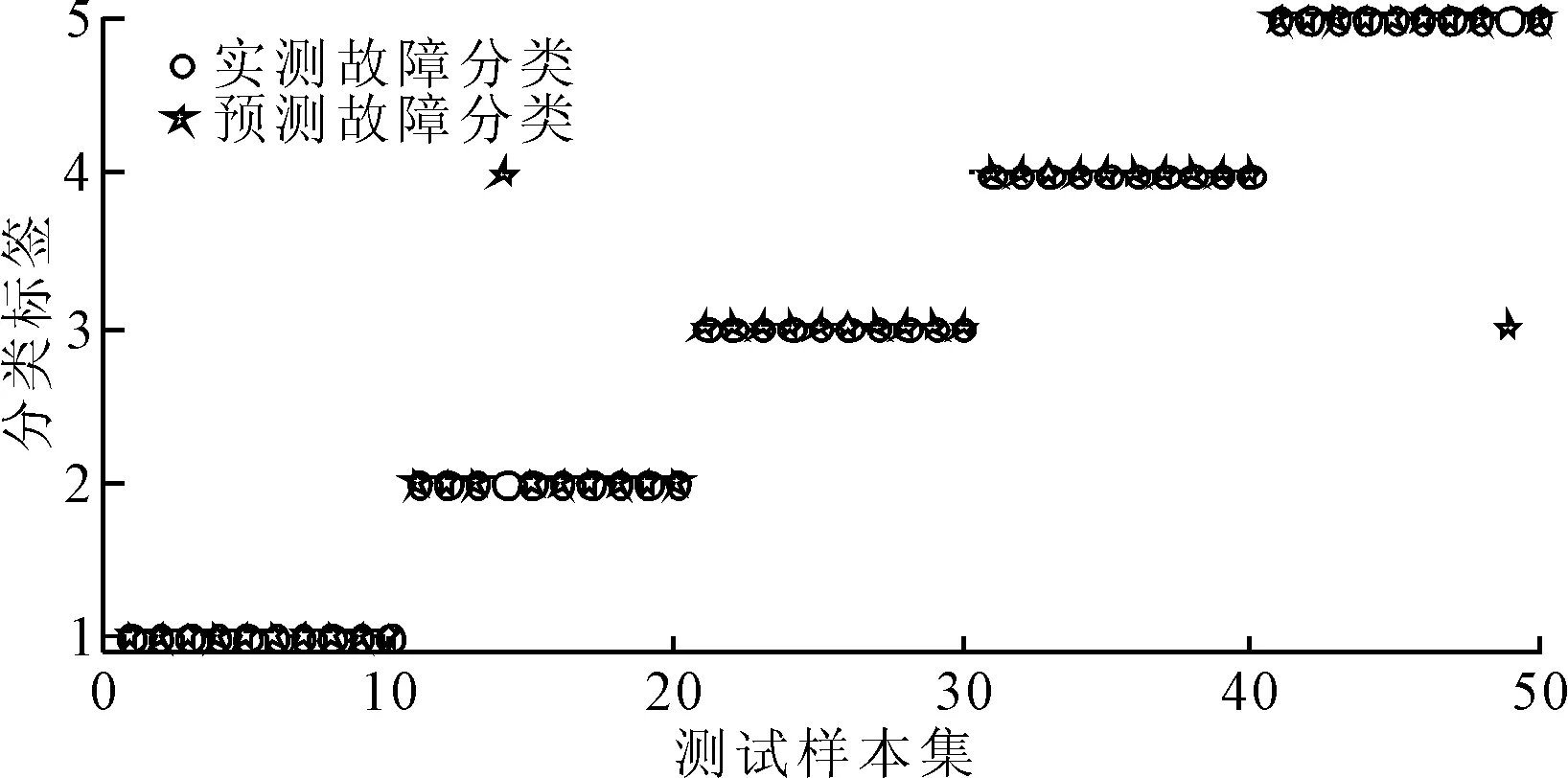
图6 GWO-LSSVM分类结果图
实验结果表明, 50个测试样本中,正确识别48个测试样本,只有2组分类错误。因此,GWO-LSSVM对验证样本的分类准确率为96%。产生识别误差的原因可能是可用的训练样本较少,如果增加训练样本的数量,则可以进一步提高识别结果的准确性。为了比较验证VMD-HHT边际谱的诊断识别效果,将EMD-HHT边际谱和EEMD-HHT边际谱也作为GWO-LSSVM模型的输入特征样本。分别使用这3种方法进行训练和分类,表2为3种特征提取方法的故障识别率比较。

表2 不同故障特征提取方法的识别率比较
从表2可知,VMD-HHT边际谱得到的特征向量的诊断识别效果的正确识别率要高于EMD-HHT边际谱和EEMD-HHT边际谱得到的特征向量。这是因为VMD比EMD和EEMD具有更好的鲁棒性,可以有效地提取不同中心频率的模态分量。因此,它具有较高的状态识别率。
结果表明,VMD-HHT边际谱特征值提取结合GWO-LSSVM模型的故障诊断方法能够准确地对中速磨煤机的上述4种故障状态进行分类。
5 结论
笔者构建了磨煤机振动监测系统,并基于所构建的磨煤机振动监测系统采集的振动信号,提出一种K值优化的VMD-HHT边际谱结合最小二乘向量机LSSVM模型,应用于磨煤机的故障识别。实验结果表明,该方法的分类准确率高于基于EMD和EEMD的方法。虽然GWO-LSSVM模型的数据样本有限,但分类验证样本的准确率可以达到96%。
猜你喜欢
ELLE世界时装之苑(2023年2期)2023-02-17
湖北电力(2022年6期)2022-03-27
中国自行车(2018年10期)2018-11-30
电子制作(2018年19期)2018-11-14
消费导刊(2018年8期)2018-05-25
自动化学报(2017年11期)2017-04-04
广西电力(2016年4期)2016-07-10
河北地质大学学报(2015年5期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
河南科技(2014年15期)2014-02-27
