
改进U-net的自密实混凝土骨料语义分割算法
2023-12-03 15:59崔李三邓鹏周圆兀
广西科技大学学报 2023年4期
崔李三 邓鹏 周圆兀

摘 要:为提高自密实混凝土骨料语义分割算法的性能,本文研究了一种融合注意力机制与深度学习的计算机视觉方法,该方法采用主流的编码器(ResNet50)-解码器(U-net)结构,建立了基于融合注意力机制与深度学习的自密实混凝土骨料语义分割模型,可以在像素级别上分割混凝土图像中的骨料,并通过精度、召回率、F1分数和交并比等4个指标对模型进行评估。实验结果表明,在同一数据集下,本文模型评估性能优于目前性能优异的模型DeepLab V3+、PSPNet和HRnet,为评价自密实混凝土的稳定性或抗静态离析性提供了高效率的工具。
关键词:深度学习;注意力机制;语义分割;自密实混凝土;稳定性评价
中图分类号:TP391.41;TU528.041 DOI:10.16375/j.cnki.cn45-1395/t.2023.04.006
0 引言
自密实混凝土是一种高流动性、非离析混凝土,具有良好的自密性和耐久性能,可以在不使用振捣器的情况下实现更好的充填性和均匀性,降低工程施工难度和成本,具有广泛的应用前景,如高层建筑、大型桥梁和水利工程等。自密实混凝土通常使用特殊的配合比和添加剂,其制备过程中需要控制混凝土的流动性和坍落度,以确保混凝土具有均匀的密实性和良好的耐久性能。由于自密实混凝土的制备较为复杂,需要采用特殊的工艺和技术,因此,在实际应用中需要严格控制混凝土的质量和施工工艺,以确保其稳定性和耐久性能。自密实混凝土的稳定性或抗静态离析性通常可以根据硬化视觉稳定性指数进行评估[1],该方法主要通过纵向切割硬化混凝土,依靠人工目视比较不同高度的骨料分布,获得其稳定性信息,工作量大、效率低、数据精度受到限制。因此,利用图像处理技术对自密实混凝土的内部结构进行分析和评价成为了一种新的研究方向。这种方法可以通过数字图像获取和处理,快速、准确地获得自密实混凝土的内部结构信息,提高了评价的效率和精度。
近年来,利用图像处理方法评价自密实混凝土稳定性的研究不断涌现,并取得了一定的研究成果。基于計算机视觉的检测方法已逐渐应用于混凝土骨料分割任务,包括形态学分水岭算法[2]、阈值[3]和边缘检测[4]等,这些方法虽然具有图像处理速度快、人工操作少等优势,但仅适合简单工况,应用范围小。随着全卷积神经网络等一些深度学习算法在图像处理技术中的应用,为解决上述混凝土骨料分割方法的不足提供了有效手段[5]。深度学习算法中的语义分割模型主要使用编码器-解码器结构(如SegNet[6]、U-net[7-8]、BTU-net[9]和PSPNet [10])。编码器通常是一个卷积神经网络,由多个卷积层和池化层组成,用于提取图像的低级和高级特征,如VGG[11]、ResNet[12-13]、MobileNet[14]和GoogLeNet[15]。解码器用于对提取的特征进行进一步优化,通常包括转置卷积层或上采样层以及卷积层,以便将编码器输出的低维特征图映射回原始图像的像素空间。然而,使用编码器-解码器结构应用于骨料语义分割的问题上主要存在2个问题:骨料多尺度和骨料边界信息丢失[6]。Lin等[7]提出特征金字塔网络来解决分割任务中的对象多尺度问题。Chen等[10]使用空洞卷积来放大感受野并聚合多尺度上下文信息,而不会减小特征映射的大小,从而减少边界信息丢失。Sun等 [11]提出了一种多路径高分辨率网络,通过高分辨率和低分辨率并行连接、交换信息,可以有效利用高分辨层的空间语义信息和低分辨率层的语义信息,使网络解决多尺度和边界信息丢失问题更加高效。Milletari等[16]通过使用增加注意力机制模块的ResNet50作为主干网络改进DeepLab V3+[10]网络,进一步提高了模型性能。Wang等[12]设计了一种半监督语义分割网络,与之前的方法相比,在精度指标上(如召回率、交并比和精度)都有较大优势,但模型相对复杂,训练更加困难,需要计算的资源也较大,Yang等[14]基于高速实时语义分割双分支架构设计了一个具有高分辨率分支和轻量化的全局语义分支,有效地保留语义分割所需的远程和局部上下文依赖关系,并且计算开销较低。
尽管基于深度学习的语义分割方法已在土木工程中广泛使用,如建材质量检测[17]、建筑垃圾分类[18]、现场安全管理等,然而在自密实混凝土骨料图像处理中的应用较少。为提高深度学习的语义分割算法在自密实混凝土骨料图像处理中的应用,提出了一种基于深度卷积神经网络的混凝土骨料语义分割算法,对自密实混凝土的图像进行自动化处理,以期提高评价的准确性与可靠性。
1 融合注意力机制的自密实混凝土骨料语义分割模型
为了实现混凝土截面图像中自密实混凝土骨料的精确分割,本文提出了一种基于深度学习的新型架构。该模型使用U-net[19]对沉积图像进行处理,并根据预测结果从图像中提取骨料的形态特征。本文提出的自密实混凝土骨料语义分割框架如图1所示。该方法采用具有编码器-解码器主流的语义分割结构。编码器提取输入图像特征,解码器将低分辨率编码器特征映射到输入分辨率特征图以实现全像素的分类。修改后的ResNet50[20]作为编码器提取沉降图像的特征,U-net作为解码器实现分割。注意力机制通过学习进行通道和空间维度上的注意力特征融合,本文在ResNet50的结构中引入了一种通道空间注意力机制(convolutional block attention module,CBAM)[21],以模拟通道、空间维度之间的相关性并增强基本特征。本文模型使用的U-net解码器部分可以分为2个阶段:上采样和卷积。上采样阶段使用2*2卷积核将编码器中的低维特征图放大,经过5次上采样放大到原始图像的尺寸。U-net解码器的上采样阶段与编码器的相应阶段通过跳跃连接在一起,将编码器中的高级特征图与解码器中的低级特征图结合起来。跳跃连接保留高级特征图的信息,可以减少多次卷积导致的骨料多尺度和边界信息丢失,提高了分割精度。在最后一个卷积层上应用softmax激活函数生成概率分布,进行图像分割预测。
1.1 注意力机制
在深度学习中,注意力机制为一个可学习的模块,即通过在特征图的通道或空间上计算一个权重向量,使网络模型在训练时能够动态、自适应地调整输入的不同部分,达到使模型关注特定信息的目的。例如,在图像分类中,注意力机制可以帮助模型识别与分类相关的局部区域,在语义分割中,可以帮助模型聚焦于具有语义信息的区域。本研究使用的CBAM[21]模块的注意力机制结构如图2所示。CBAM模块允许网络动态调整通道和空间权重以提高网络的表达能力。通过该操作有效特征获得大权重,无效或低效特征获得小权重,训练模型获得显著效果。CBAM模块的输入和输出的通道数、特征图尺寸都是相同的,可以集成到网络的任何位置。CBAM模块分为通道注意力模块(channel attention module,CAM)和空间注意力模块(spatial attention module,SAM)两部分。CAM和SAM的计算公式分别为式(1)、式(2),
1.2 主干网络
随着神经网络层数的不断加深,训练CNN模型的难度也会逐渐增加。为了应对训练深度CNN模型的困难,He等[20]提出深度残差网络(ResNet)来解决网络深度加深引起的梯度消失或爆炸问题,使用残差连接(跳跃连接),以使原始输入信息直接传入以下输出部分,进一步降低了深度神经网络的训练难度,有助于误差反向传播并优化模型参数。在图像识别、图像分割、目标定位等计算机视觉相关任务中取得了良好的效果。
使用修改后的ResNet50主干特征提取网络,ResNet50整体结构如图3所示。本文方法是在Conv Block和Identity Block 2个残差块内增加CBAM注意力机制,以提高网络的表达能力。修改后的ResNet50主干特征提取网络有5个特征提取阶段(Stage 0—Stage 4),每个阶段都会得到1个特征图(Feature),这5个特征图为主干特征提取网络的输出。
1.3 损失函数
损失函数(loss function)在深度学习中的作用是衡量模型预测结果与真实标签之间的差异程度,通过最小化损失函数来调整模型的参数使其能够更准确地预测输出结果。损失函数的作用是将深度学习任务中的问题转化为一个数学优化问题,使得模型的优化过程可以通过求解损失函数的最小值来实现。语义分割任务的常用损失函数包括交叉熵损失函数、Dice损失函数、Jaccard损失函数和focal损失函数等,常常根据具体任务和数据集的特点来选择使用的损失函数。用于自密实混凝土骨料分割的数据集表现出样本不平衡,图像中骨料只占其中一部分像素,砂浆和拍摄背景占据了大部分像素。不平衡的训练样本会导致训练模型专注于具有大量样本的类,低估具有少量样本的类,并最终影响测试集上的泛化性能[6]。为了解决网络训练期间发生的样本不平衡问题,将Dice损失函数和focal损失函数结合起来指导神经网络训练。Dice损失函数用于计算2个样本之间的相似性,通过学习类分布来缓解不平衡的像素问题。focal损失函数侧重于困难样本,这迫使模型更好地学习分类不佳的像素。组合损失函数将难以分类的类和像素都考虑在内,使其在训练过程中更加稳定。
[αt]是不平衡系数,可通过设置[αt]取值实现控制易分类和难分类样本对损失的贡献;[pt]是模型的估计概率;[lnpt]为标准交叉熵损失函数;γ是可调聚焦参数,可通过设置γ取值实现控制正负样本对损失的贡献;[α]是一个可调参数,用于控制易于分类的样本在损失计算中的权重,[α]的取值范围为[0,1];y是标签值;[p]为模型对于样本属于真实类别的预测概率。
1.4 数据集
为了评估所提出的自密实混凝土骨料分割算法的性能,本文通过纵向切割混凝土圆柱体,可以获得混凝土截面骨料分布的高分辨率图像,使用Labelme标注工具对图像中的骨料进行像素级的标识,每个像素对应于骨料或背景类别。图4为本文数据集样本,标签图为PNG格式,骨料被标注为1,背景被标注为0。标注后数据集在GitHub上进行了开源共享(https://github.com/fanta12138)。同时加入了Coenen等提供的数据集[23]。由于计算机硬件的限制,不能将完整图片输入模型进行训练,因此,制作数据集时截面图像被裁剪为分辨率是512×512的图像,共获得了2 072张图像。数据集分为训练集(包含1 491张图像)、验证集(包含166 张图像)和测试集(包含415张图像)。在数据集带标簽的像素中,骨料类别的像素占比25.4%,背景类别占比74.6%。因此,类别分布是不均衡的。
2 模型训练
本文使用 Chollet[17]深度学习框架。实验是在Ubuntu系统工作站上进行,该工作站配置了Intel Core i7-11700 CPU,工作频率为2.50 GHz,32 GB DDR4内存和NVIDIA RTX2080Ti GPU。迁移学习通常用于计算机视觉任务,将信息从经过训练的网络传输到新网络,以解决类似的问题并为模型提供更好的初始状态。从头开始训练卷积神经网络时,将对整个模型的权重进行随机初始化,没有经过大型数据集的预训练,神经网络不容易收敛,而且所需计算资源太大。虽然本文提出的模型对原始ResNet50作了一定的改动,但仍使用原始ResNet50在ImageNet[18]大型数据集上预训练的权重作为初始权重。
模型训练时利用 Adam优化器更新模型参数。本文采用了余弦退火学习率下降方法调整学习率,与常规的学习率衰减方法相比,余弦退火学习率下降方法能够更好地避免训练过程中的震荡和过拟合问题。其中初始学习率为1×10?4。通过使用余弦退火学习率下降方法,初始学习率被设置为一个比较大的值,这使得模型在训练初期可以快速地找到一个相对较好的局部最优解。随着训练的进行,学习率会不断地降低,使得模型可以缓慢地调整参数并最终收敛到全局最优解。该网络经过100次迭代训练,每一轮中单次传给网络的图像数量设置为4张。为方便训练,在前50次迭代训练时冻结主干网络权重。在训练和验证过程中,参考模型在训练集和验证集上的损失、交并比作为模型训练状态的监控指标,并根据曲线的变化判断模型是否收敛。如图5所示,随着训练迭代次数的增加,训练和验证过程中的交并比逐渐增加。在前50次训练结束后,主干网络权重解冻,训练和验证损失曲线出现波动,随着模型继续训练优化,最终收敛。
3 实验验证
3.1 骨料分割评估指标
根据几个常用于评价语义分割模型的指标,定量评价本文模型的性能。通过与标签的比较,评估了自密实混凝土骨料分割的结果。本文选择了通常用于评估模型的4个指标:精度、召回率、F1分数和交并比。将骨料像素视为正样本,将背景像素视为负样本。精度是指分类为骨料的所有像素中正确骨料像素的百分比;召回率是指正确分类的所有骨料像素的百分比;F1分数是指精度和召回率的调和平均数;交并比是指边界框的真实值交集和并集的比值,用来预测分割精度。
3.2 注意力机制消融实验
本文利用相同的数据集进行训练和测试,以验证注意力机制CBAM块对骨料分割模型性能的影响。如表1所示,由于增加了CBAM块,网络可以使用全局信息有选择地增强包含有用信息的特征,并抑制无用的特征以提高模型性能。与没有CBAM块的神经网络相比,精度、召回率、F1分数和交并比值分别提高了0.76%、1.90%、1.34%和2.59%。
3.3 损失函数消融实验
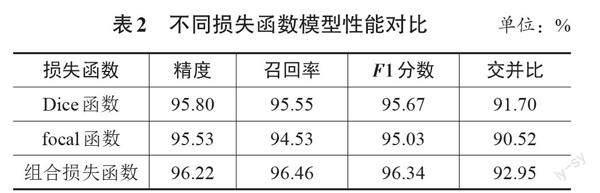
骨料分割数据集存在样本不平衡,损失函数对模型性能有重大影响。本文训练了3个使用不同损失函数的网络,其他参数保持相同,以验证所提出的组合损失函数的效果。从表2中可以看出,提出的组合损失函数在精度、召回率、F1分数和交并比方面的效果均好于其他2个损失函数。
3.4 模型对比
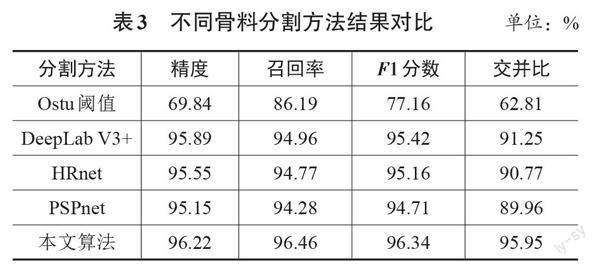
使用测试集来进一步比较本文模型和其他3种语义分割模型及传统阈值方法的性能。如表3所示,本文模型计算结果在4个指标中都实现了最优性能。此外,可以明显看出,与传统Otsu阈值方法相比,本文模型在精度、召回率、F1分数和交并比方面的表现均优于Otsu阈值方法,分别提升了37.77%、11.92%、24.86%和52.76%。
图6为不同分割方法结果对比图。由图6可看出,本文模型可以对自密实混凝土骨料和砂浆进行精确分割,特别是对小目标骨料、轮廓和边缘信息表现更高的准确性(红圈标识所示),骨料的详细分布信息可以很容易获取。
表4为硬化自密实混凝土试样视觉稳定性指数评级标准(HVSI)[1],将图像在高度方向上分割为4层,对分割结果进行后处理,可准确地得到图像中骨料的分布。图7为典型的自密实混凝土横截面图像和分层骨料分布。经过本文算法预处理后,将横截面切割成尺寸相等的4层,骨料像素被标记为1,砂浆像素被标记为0,经算法统计确定每层的骨料/砂浆面积比,即图7中的白/黑面积比。使用本文方法可以高效、客观地评价自密实混凝土的稳定性。
4 结论
本研究基于深度学习和图像处理技术提出了一种混凝土骨料语义分割模型,可以快速、高效地提取出图像中的骨料分布密度等相关参数。本文方法使用语义分割主流的编码器-解码器结构、具有跳跃连接的U-net模型对自密实混凝土截面图像的输出特征图进行多尺度特征提取和融合,提高了模型对骨料边缘信息的提取能力。引入CBAM注意力机制模块显著提高了编码器的特征提取能力,综合了Dice和focal 2种损失函数,减少正负样本不均衡的影响。通过与DeepLab V3+、HRnet和PSPnet 3种高性能分割方法在本文数据集上进行比较,验证了本文方法的优越性。自密实混凝土的图像可以通过本文方法进行自动化处理,避免了人工处理的主观性和不稳定性,提高了评价的准确性和可靠性。
參考文献
[1] ASSAAD J J. Correlating thixotropy of self-consolidating concrete to stability,formwork pressure,and multilayer casting[J]. Journal of Materials in Civil Engineering,2016,28(10):1-10.
[2] 杨子晴,杨健,熊吴越. 基于改进分水岭算法的堆积态再生混合粗骨料图像分析[J]. 硅酸盐学报,2021,49(8):1691-1698.
[3] 范九伦,赵凤. 灰度图像的二维Otsu曲线阈值分割法[J]. 电子学报,2007,35(4):751-755.
[4] 高广运,杨成斌,高盟,等. 持力层对大直径扩底灌注桩竖向承载性状的影响[J]. 岩土工程学报,2012,34(7):1184-1191.
[5] 李涛,王子豪,王庸道,等. 基于深度残差网络的油纸绝缘老化状态识别策略研究[J].广西科技大学学报,2022,33(1):39-45.
[6] WANG W J,SU C,ZHANG H. Automatic segmentation of concrete aggregate using convolutional neural network[J]. Automation in Construction,2022,134:104106.
[7] LIN T Y,DOLL?R P,GIRSHICK R,et al. Feature pyramid networks for object detection[C]// Proceedings of 30th IEEE Conference on Computer Vision and Pattern Recognition,2017,106:936-944.
[8] 龙雪,李政林,王智文,等. 基于改进U-Net网络的肺部CT图像结节分割方法[J].广西科技大学学报,2022,33(1):63-70,77.
[9] 文泽奇,林川,乔亚坤. 轮廓检测深度学习模型中解码网络融合方法[J].广西科技大学学报,2021,32(4):43-49,57.
[10] CHEN L C,ZHU Y K,PAPANDREOU G,et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//15th European Conference on Computer Vision,2018,11211:833-851.
[11] SUN K,XIAO B,LIU D,et al. Deep high-resolution representation learning for human pose estimation[C]// Proceedings of the 32nd IEEE Conference on Computer Vision and Pattern Recognition,2019,2019:5686-5696.
[12] WANG W J,SU C. Semi-supervised semantic segmentation network for surface crack detection[J]. Automation in Construction,2021,128:103786.
[13] 王衢,林川,陳永亮. 基于ResNet网络与离散变分自编码器的精细轮廓检测方法[J].广西科技大学学报,2022,33(3):8-13,28.
[14] YANG M Y,KUMAAR S,LYU Y,et al. Real-time semantic segmentation with context aggregation network[J]. ISPRS Journal of Photogrammetry and Remote Sensing,2021,178:124-134.
[15] 罗绍猛,文家燕,陈彬. 基于改进GoogLeNet的瘢痕色泽和血管分布评估算法[J]. 广西科技大学学报,2022,33(3):36-42,52.
[16] MILLETARI F,NAVAB N,AHMADI S A. V-Net:fully convolutional neural networks for volumetric medical image segmentation[C]//Proceedings of the 4th IEEE International Conference on 3D Vision,2016,2016:565-571.
[17] CHOLLET F. Keras:the python deep learning library[EB/OL]. (2017)[2022-10-19]. https://keras.io/.
[18] DENG J,DONG W,SOCHER R,et al. ImageNet:a large-scale hierarchical image database[C]// IEEE Conference on Computer Vision and Pattern Recognition,Princeton,USA:IEEE,2009.
[19] RONNEBERGER O,FISCHER P,BROX T. U-net:convolutional networks for biomedical image segmentation [C]//18th International Conference on Medical Image Computing and Computer-Assisted Intervention,2015,9351:234-241.
[20] HE K,ZHANG X Y,REN S,et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recog-
nition,2016,2016:770-778.
[21] WOO S,PARK J,LEE J Y,et al. CBAM:convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision,2018,11211 LNCS:3-19.
[22] LIN T Y,GOYAL P,GIRSHICK R,et al. Focal loss for dense object detection[C]// Proceedings of the IEEE International Conference on Computer Vision,2017,2017:2999-3007.
[23] COENEN M,SCHACK T,BEYER D,et al. Semi-supervised segmentation of concrete aggregate using consensus regularisation and prior guidance [C]// ISPRS Annals of the Photogrammetry,Remote Sensing and Spatial Information Sciences,2021,5(2):83-91.
Improved U-net semantic segmentation algorithm for
self-compacting concrete aggregate
CUI Lisan, DENG Peng, ZHOU Yuanwu*
(School of Civil Engineering and Architecture, Guangxi University of Science and Technology,
Liuzhou 545006, China)
Abstract: To improve the performance of semantic segmentation algorithm for self-compacting concrete aggregate, a computer vision method integrating attention mechanism and deep learning was developed. This method adopted the mainstream encoder (ResNet50)-decoder (U-net) structure, and established a semantic segmentation model of self-compacting concrete aggregate based on attention mechanism and deep learning. It could segment aggregate in concrete image at pixel level. The model was evaluated by four indicators:precision, recall, F1 score and IoU. The experimental results show that under the same dataset, the evaluation performance of this model is better than those of DeepLab V3+, PSPnet and HRnet, which have excellent performance at present. This provides an efficient tool for evaluating the stability or static segregation resistance of self-compacting concrete.
Key words: deep learning; attention mechanism; semantic segmentation; self-compacting concrete; stability evaluation
(责任编辑:罗小芬)
收稿日期:2022-11-26
基金项目:广西高校中青年教师科研基础能力提升项目(2022KY0348);国家自然科学基金项目(51908141);广西科技大学博士挂职驻柳企业工作项目(BSGZ2127);广西科技大学博士基金项目(校科博14z13);广西高等教育本科教学改革工程项目(2020JGZ129);2022年度校级本科教育教學改革项目(2022XJJG51)资助
第一作者:崔李三,博士,工程师,研究方向:建筑储能与节能材料
*通信作者:周圆兀,博士,副教授,硕士生导师,研究方向:遗传算法、边坡稳定性分析,E-mail:ywzhou@gxust.edu.cn
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
