
面向动态场景的ORB-SLAM3算法研究
2023-12-03 16:12:06刘超群柯宝中蔡洪炜
广西科技大学学报 2023年4期
刘超群 柯宝中 蔡洪炜


摘 要:传统的视觉同步定位与地图构建(simultaneous localization and mapping,SLAM)算法大多是基于静态场景这一假设进行研究,在动态场景中容易出现定位精度不佳、稳定性差等情况。针对这一问题,本文以ORB-SLAM3算法为基础,与YOLOv3目标检测网络相结合,在提取特征点的同时进行动态目标检测,根据目标检测结果剔除动态特征点;再利用对极几何约束剔除残留的动态特征点和误匹配的特征点;最后利用剩余的特征点进行帧间匹配和位姿估计,并在TUM数据集上进行实验验证。结果表明:相比较于ORB-SLAM3,本文算法在高动态场景中的系统绝对轨迹误差减少了85%以上,大大提高了定位精度;同时,本文算法跟踪线程每帧图像平均用时为75 ms左右,能够满足实时运行的需求。
关键词:视觉SLAM;动态场景;ORB-SLAM3;YOLOv3;绝对轨迹误差
中图分类号:TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2023.04.012
0 引言
随着人工智能技术的发展和应用,同步定位与地图构建(simultaneous localization and mapping,SLAM)技术可以使机器人在未知的工作环境中确定自身位置和建立地图,在智能移动机器人、增强现实(augmented reality,AR)技术和自动驾驶等领域中发挥着重要的作用,逐渐受到科技企业、高校和研究所的关注。根据传感器类型的不同,可以将SLAM技术分为激光SLAM和视觉SLAM两大类[1]。视觉SLAM使用相机传感器,由于其价格低廉,获取的环境信息更加丰富,逐渐受到研究者的青睐。
在视觉SLAM中,相机成像容易受光照变化及相机稳定性的影响,在复杂场景中仅依靠单一的视觉信息效果不显著。采用多传感器融合逐渐成为解决这一问题的较优解,可以提高SLAM系统的鲁棒性和精度。Davison等[2]提出的MonoSLAM算法是第一个实时的SLAM算法,但不能在线运行,只能在离线时进行定位和建图。Klein等[3]提出了使用非线性优化作为后端并多线程运行的PTAM算法,此算法仅在小场景中运行。Mur-Artal等[4]基于特征点具有快速方向性和旋转不变性的特点提出了ORB-SLAM2算法。Campos等[5]开源了ORB-SLAM3算法,它相较于之前的算法增加了IMU融合算法和多地图系统,这种算法是目前性能较为优异的算法之一。然而这些传统的视觉SLAM大部分都是假设外部环境是静态的,而对于动态场景,系统在进行特征点提取时会存在误差,从而导致相机位姿估计精度降低。如何减少动态物体对于系统精度的干扰成为视觉SLAM的一个主流研究方向[6]。
伴随着深度学习理论的快速发展,大量结合深度学习的SLAM算法被提出,基于视觉的同步定位与地图构建(visual SLAM,VSLAM)进入一個全新的阶段,即鲁棒性-预测性阶段。Bescós等[7]提出了DynaSLAM算法,该算法以ORB-SLAM2算法为基础,依据语义分割和多视图几何的结果,将语义动态或者几何动态的特征点剔除。Wu等[8]提出了一种YOLO-SLAM动态环境SLAM系统,利用YOLO算法来获得语义信息,滤除检测到的动态特征点。Yu等[9]以ORB-SLAM2为基础提出DS-SLAM算法,选用SegNet网络和运动一致性检验结合的方法进行动态特征点滤除。相较于传统的VSLAM,结合深度学习理论的算法剔除动态特征点效果更好,定位精度也能大大提高。因此,本文以ORB-SALM3算法为基础增加语义信息,主要内容如下:
1)增加一条独立的动态目标检测线程,结合ORB-SLAM3视觉里程计,使用YOLOv3进行端对端目标检测,有效提取动态图像特征。
2)依据动态目标检测结果剔除动态特征点,残留的动态特征点和误匹配的特征点使用对极几何约束滤除;利用剩下的特征点进行帧间匹配和位姿估计,在TUM数据集上对本文所提算法的定位精度和实时性进行评估。
1 算法框架
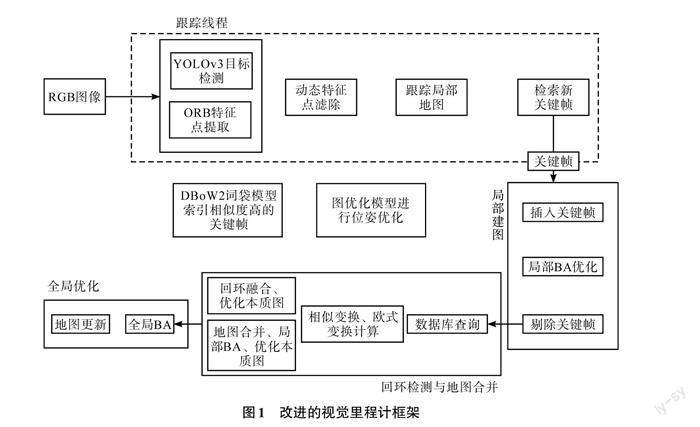
本文算法以ORB-SLAM3算法为主体框架,在视觉里程计的前端加入一个动态目标检测线程,通过动态目标检测网络YOLOv3分割图像中的静态和动态特征,将动态目标视为离群值,增加系统的鲁棒性。根据目标检测的结果,将动态特征范围内的特征点剔除,再利用对极几何约束滤除残留的动态特征点和误匹配的点,利用完全过滤后的静态特征点进行位姿估计和非线性优化操作,减少动态特征点对于系统的影响。改进的视觉里程计框架如图1所示。
1.1 ORB-SLAM3系统概括
ORB-SLAM3是一种基于特征点法的视觉里程计系统,其充分利用了图像特征点对光照强度和环境尺度的稳健性,在室内和室外环境中的表现都较为良好。主要由以下几部分组成[5]:
1)跟踪线程的主要作用是为活动的地图提供新的关键帧。对输入系统中的图像进行ORB特征点提取,对相邻2幅图像进行特征点匹配,使用最小化重投影误差确定当前图像帧相机的初始位姿,利用初始值进行最小化重投影误差,尽可能使多的特征点与地图点相匹配。
2)局部建图线程主要是在活动的地图中添加关键帧的位姿以及新的地图点,删除冗余数据,利用滑动窗口进行BA优化,更新地图数据。当初始化完成后,若关键帧跟踪成功,则利用预积分误差和最小化重投影误差进行关键帧的优化,最终剔除冗余的关键帧。
3)经过筛选后的关键帧会进入回环检测和地图合并线程。检测活动地图与其他地图存在的共有区域,检测是否存在回环或者融合等情况,若存在,则使用相似变换合并地图和回环矫正。在优化完成后,打开另一个线程进一步更新地图,通过在回环检测的同时合并共视地图,可以保障系统的实时性。
1.2 YOLOv3目标检测原理
YOLOv3是一个可以实现端对端目标检测的算法,它的主干网络由Darknet-53组成,通过调节不同的卷积步长控制特征图尺寸,借助金字塔思想,用小尺寸特征图检测大尺寸物体,大尺寸特征图用于检测小尺寸物体[10]。
在前向进程中,YOLOv3网络依据不同的输入尺寸,输出3个不同尺寸的特征图:[y1、y2、y3]。输出特征图的维度为
其中:[m]表示矩形框坐标参数,主要由矩形框中心坐标[(x, y)]以及矩形框宽和高组成;[l]表示预测矩形框坐标的偏移量;[g]表示默认框和与之相匹配的真实框之间的偏移量;[bx、by、bw、bh]表示预测目标矩形框参数;[cx、cy、pw、ph]表示默认矩形框参数;[gx、gy、gw、gh]表示其匹配到的实际目标框参数[12]。
在对数据集完成动态目标检测后,将物体分为3类,即高动态物体、中动态物体、静态物体。只有当特征点位于高动态物体框内且不存在于静态物体框内时,认为此特征点是一个动态特征点,并剔除这些动态特征点[13]。
1.3 对极几何约束
在经过上述动态特征点滤除后,数据集中可能存在动态物体被大面积遮挡、动态特征点漏检的情况,需要进一步滤除特征点。对相邻2帧图像中的剩余特征点进行特征匹配,计算两特征点之间的汉明距离,选取距离最小的点为匹配点[14]。为了减小由于暴力匹配产生的误差,按照已匹配点对之间的汉明距离进行升序排列,选取排序靠前的1/3点对求解基础矩阵。随机抽样一致(random sample consensus,RANSAC)算法的具体操作步骤如下:
1)随机在匹配成功的点对中选取4组,求得基础矩阵F。
2)计算剩余特征点到矩阵F所对应极线的距离[a],并与设定好的阈值[an]进行比较。当[a
3)重复执行上述步骤[N]次,选择内点数目[I]最大的一次,将此次求得的基础矩阵当作最终的基础矩阵。
在求取基础矩阵之后对所有的匹配点进行检验,判断是否满足对极几何约束。
对极几何约束示意图如图2所示。
在视觉SLAM系统需要用金字塔对图像进行不同层次的降采样处理。阈值d的取值与置信度、图像金字塔层数紧密相关,当距离[d]超过给定的范围,则认定该特征点是动态的或者误匹配的点,予以剔除。
在动态场景中,由于存在大量的动态特征点,会造成相机位姿估计偏差[15]。本文所提出的方案使用YOLOv3算法进行目标检测,将被判定为动态特征点的点进行剔除;再利用对极几何约束剔除残留的动态特征点和误匹配的特征点,进而增加定位的精度。
2 实验结果及分析
2.1 实验数据集和环境
本文实验中使用的设备为ThinkPadE560笔记本电脑,CPU型号为英特尔i5-6200U,主频2.4 GHz,8 G内存,操作系统为Ubuntu20.04。选用公开的TUM RGB-D动态数据集中的6组数据进行实验,TUM数据集由德国慕尼黑工业大学采集制作,包含了由深度相机采集到的彩色图像、深度图像以及由8个高速追踪相机获取到的真实位姿等数据。本次实验选用的动态场景分别为freiburg2_desk_with_person、freiburg3_sitting_static、freiburg3_sitting_xyz、freiburg3_walking_halfsphere、freiburg3_walking_static、freiburg3_walking_xyz等6组数据集,部分数据集如图3所示。其中在sitting序列中展示的是桌子前面有2个人,他们的肢体或者桌上的物品存在轻微移动;在walking序列中展示的是2个人在桌子周围进行大幅度的移动;在static序列中,相机相对静止;xyz序列中,相机在x、y、z方向上移动。
2.2 动态特征点剔除
选用COCO数据集进行YOLOv3网格的训练。COCO数据集中包含80个类别,这种检测算法输出3个特征图用以检测数据集中的大中小型物体,例如数据集中的人、椅子、鼠标等动态物体。当对极几何约束中给定阈值过小时,会造成剔除的误匹配和动态特征点过多,余下的静态特征点过少,不利于后续的相机位姿估计。当给定阈值过大时,动态特征点滤除效果会变差,后续相机位姿估计中有太多的误匹配和动态特征点,降低定位的精度。本文对极几何约束的阈值选为金字塔第[n]层,置信度取95%时,阈值[d]的约束条件为[d<3.84×1.22n],在这个范围内的特征点被保留,则动态特征点剔除前后效果图如图4所示。
该图例选自TUM数据集中的freiburg3_walking_xyz动态场景,在此场景中2个人围绕桌子运动。当图像中存在动态目标时,ORB-SLAM3算法对动态目标不作处理,将特征点一起进行位姿估计,而本文的算法剔除了运动中人边界框中的特征点,剩下的静态特征点用于进行位姿估計。图4(a)是ORB-SLAM3系统特征提取效果图,图4(b)是增加了YOLOv3线程之后的特征点提取效果图。对比图4(a)、(b)可以看出,处于动态目标范围内的大部分动态特征点已经被剔除,由于图中右侧人手边的笔记本属于中动态物体,因此这部分特征点被保留。
2.3 定位精度分析
本文选择的是在传统ORB-SLAM3视觉前端添加一个深度学习模块YOLOv3,并剔除动态特征点。此次实验主要对改进方案的定位精度和实时性进行评估。SLAM系统精度的评价指标为绝对轨迹误差(absolute trajectory error,ATE),能够较为直观地反映相机轨迹的精度,通过不同时间戳下真实位姿和估计位姿之间的均方根误差来表示[8],计算公式如式(13)所示,
式中:[eATE]为绝对轨迹误差,[ei]为真实位姿和估计位姿李代数的差,[T-1gt, i]为数据集中真实的轨迹,[Testi, i]为SLAM系统估计的轨迹。本文使用均方根误差(RMSE)、平均值(mean)和标准差(std)这3个参数来反映系统的性能,平均值反映估计位姿的精度,均方根误差和标准差体现系统的鲁棒性[16-17]。
本文选用目前性能较为优异的ORB-SLAM3算法进行对比。在经过数据集的测试后,两者的绝对轨迹误差和性能提升率如表1所示。
从表1中可以看出,在高动态场景中,本文所提方案的均方根误差、平均值和标准差都有较大程度的提升,在walking_half、walking_static、walking_xyz这3个走动序列中,系统精度至少能提升85%以上。在这3个序列中,由于人走动较为频繁,动作幅度过大,本文算法在对特征点进行筛选时,剔除了大多数的动态特征点,选用静态的特征点进行位姿估计。相较于ORB-SLAM3算法,本文算法在动态场景中的适应性更好,定位精度更高。在sitting系列场景中,与ORB-SLAM3算法相比较,本文算法提升效果不明显,甚至在sitting_xyz序列中,本文算法的精度略微下降,均方根误差下降了11.11%。这是由于在进行阈值判断剔除动态特征点时删除了部分静态特征点,影响了定位的精度。总体而言,本文的方案相较ORB-SLAM3算法仍然有所提升。
图5和图6分别为walking_xyz和sitting_xyz序列在ORB-SLAM3和本文算法下的预估相机轨迹和真实轨迹的对比图。从图中可以看出,ORB-SLAM3在一个地点旋转角度过大时会产生较大偏移,受到大量的动态特征干扰时,会产生明显的漂移,相比较之下,本文的算法在动态场景中有着较好的表现。
2.4 实时性评估
实时性对于SLAM系统是否具有实用性非常重要。为了验证本文算法的实时性,在本次实验中选用的是跟踪线程中处理每帧图像所花费的时间[18]。与DynaSLAM算法和DS-SLAM算法进行对比,对照实验在walking_xyz序列中进行,对比结果如表2所示。由表2可知,本文算法的平均跟踪时间为75 ms,大体上可以满足系统实时性的要求。虽然这几种方案都是采用融合深度学习的方式,但由于本文采用快速检测网络YOLOv3进行动态目标检测,相比较于DynaSLAM算法使用Mask-RCNN、DS-SLAM算法使用SegNet网络,本文算法在速度上有较大优势[19]。通过对比验证了本文算法能够较好地满足定位精度和实时性要求。
3 结论
本文构造了一种面向动态场景的视觉里程计,以ORB-SLAM3为基础框架,增加了一条独立的目标检测线程,选用YOLOv3网络检测动态目标,剔除位于高动态物体框内且不存在于低动态物体框内的动态特征点,以防动态特征点剔除不完全;再次利用对极几何约束进一步剔除动态特征点和误匹配的特征点。通过在TUM数据集上的实验表明,本文算法在定位精度和实时性方面有较大提升。在后续的研究中,将会尝试加入三维语义地图,以便此系统能够应用到机器人导航中。
参考文献
[1] 李浩东,陶钧,刘辰宇,等. 基于ORB-SLAM框架的直接法改进与对比[J]. 测绘地理信息,2022,47(S1):211-215.
[2] DAVISON A J,REID I D,MOLTON N D,et al. MonoSLAM:real-time single camera SLAM[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(6):1052-1067.
[3] KLEIN G,MURRAY D. Parallel tracking and mapping for small AR workspaces[C]//6th IEEE and ACM International Symposium on Mixed and Augmented Reality,2007:225-234.
[4] MUR-ARTAL R,TARD?S J D. ORB-SLAM2:an open-source SLAM system for monocular,stereo,and RGB-D cameras[J]. IEEE Transactions on Robotics,2017,33(5):1255-1262.
[5] CAMPOS C,ELVIRA R,RODRIGUEZ J J G,et al. ORB-SLAM3:an accurate open-source library for visual,visual-inertial,and multimap SLAM[J]. IEEE Transactions on Robotics,2021,37(6):1874-1890.
[6] 李博,段中興. 室内动态环境下基于深度学习的视觉里程计[J/OL]. 小型微型计算机系统,2022:1-9[2022-11-25]. http://kns. cnki. net/kcms/detail/21. 1106. TP. 20211019. 1809. 020. html.
[7] BESC?S B,F?CIL J M,CIVERA J,et al. DynaSLAM:tracking,mapping and inpainting in dynamic scenes[J]. IEEE Robotics and Automation Letters,2018,3(4):4076-4083.
[8] WU W X,GUO L,GAO H L,et al. YOLO-SLAM:a semantic SLAM system towards dynamic environment with geometric constraint[J]. Neural Computing and Applications,2022,34(8):6011-6026.
[9] YU C,LIU Z X,LIU X J,et al. DS-SLAM:a semantic visual SLAM towards dynamic environments[C]//Proceedings of the 25th IEEE/RSJ International Conference on Intelligent Robots and Systems,IEEE,2018:1168-1174.
[10] 吴静,王智文,王康权,等. 基于改进CRNN算法的电动自行车车牌识别研究[J]. 广西科技大学学报,2022,33(4):63-69.
[11] 张政,林志诚. 基于ORB-SLAM2的四足机器人定位和建图[J]. 工业控制计算机,2022,35(10):78-80,84.
[12] 徐武,高寒,王欣达,等. 改进ORB-SLAM2算法的关键帧选取及地图构建研究[J]. 电子测量技术,2022,45(20):143-150.
[13] 陆佳嘉. 面向室内复杂环境的无人车同时定位与建图研究[D]. 南京:南京信息工程大学,2022.
[14] 乔亚坤,林川,张贞光. 基于深度学习的轮廓检测模型的交互式解码网络[J]. 广西科技大学学报,2022,33(1):46-53.
[15] 张杰. 动态环境下视觉惯性定位方法研究[D]. 西安:西安工业大学,2022.
[16] 冯一博,张小俊,王金刚. 适用于室内动态场景的视觉SLAM算法研究[J]. 燕山大学学报,2022,46(4):319-326.
[17] 张昊宇,柳祥乐,王思山. 基于深度学习特征提取的改进ORB-SLAM3算法[J]. 湖北汽车工业学院学报,2022,36(2):55-59.
[18] 伍晓东,张松柏,汤适荣,等. 基于改进关键帧选择的ORB-SLAM3算法[J/OL]. 计算机应用研究,2023:1-7[2023-02-04]. https://doi.org/10.19734/j.issn.1001-3695. 2022. 09. 0480.
[19] 江浩玮. 基于改进Mask-RCNN的SLAM算法研究[D]. 芜湖:安徽工程大学,2022.
Research on ORB-SLAM3 algorithm for dynamic scenes
LIU Chaoqun1, KE Baozhong*1, CAI Hongwei2
(1. School of Automation, Guangxi University of Science and Technology, Liuzhou 545616, China; 2. School of Information Science and Engineering, Liuzhou Institute of Technology, Liuzhou 545616, China)
Abstract: Most of the traditional visual SLAM algorithms are based on the assumption of static scenes, which is prone to poor localization accuracy and stability in dynamic scenes. To address these problems, based on the ORB-SLAM3 algorithm, combined with the YOLOv3 target detection network, dynamic target detection is performed while feature points are extracted, and dynamic feature points are rejected according to the target detection results; then the pairwise polar geometric constraints are used to reject the residual dynamic feature points and mismatched feature points; and finally the remaining feature points are used for inter-frame matching and bit pose estimation. The final experimental validation on the TUM dataset shows that compared with ORB-SLAM3, this algorithm reduces the absolute trajectory error of the system by more than 85% in highly dynamic scenes, which greatly improves the localization accuracy. At the same time, the average time spent per image frame by the tracking thread of this algorithm is around 75 ms, which can meet the requirements of real-time operation.
Key words: visual SLAM; dynamic scene; ORB-SLAM3; YOLOv3; absolute trajectory error
(責任编辑:黎 娅)
收稿日期:2022-12-13
基金项目:2022年度广西高校中青年教师科研基础能力提升项目(2022KY1704);2019年度广西科技大学鹿山学院科学基金项目(2019LSKY09);2020年自治区级大学生创新创业训练计划项目(202013639028)资助
第一作者:刘超群,在读硕士研究生
*通信作者:柯宝中,学士,高级工程师,研究方向:自动控制,E-mail:64285076@qq.com
