
面向在线课程推荐的评论文本情感分析
2023-12-02 09:25于亮黄宇
电脑知识与技术 2023年29期
于亮,黄宇
(1.桂林电子科技大学计算机与信息安全学院,广西桂林 541004;2.北海市科技信息研究所,广西北海 536000)
0 引言
情感分析是计算机通过文本来挖掘人们对于事物的观点、情感和态度的一种方式,它是一种非常实用的文本分类技术,具有广泛的应用价值[1]。按照粒度粗细来划分,情感分析可以分为文档级别、句子级别和方面级别[2]。其中,方面级情感分析相比其他两种方法能够更准确地识别出文本中每个方面的情感倾向,从而更全面地理解文本的情感含义[3]。由于在线课程评论往往涉及多个方面,因此,本文提出了融合注意力机制的RoBERTa-BiLSTM方面级情感分析模型来获取在线课程评论中蕴含的情感信息。
1 相关工作
方面级情感分析方法大致可以分为下面三类:基于情感词典的方法、基于机器学习的方法和基于深度学习的方法[4]。
基于情感词典的情感分析方法是一种常见的文本情感分析方法,其核心思想是利用预先构建的情感词典[5],对文本中出现的情感词汇进行计数和权重赋值,以推断文本的情感倾向。Vishnu等人通过利用多个不同领域的评论数据,采用多领域知识更新的方式,构建了一个能够适应特定领域的独立情感词典[6]。Rao等人通过三种剪枝方法去除语料库中不重要或者不相关的词语[7],以减少构建情感词典的时间和精力,并且基于主题的方法来构建情感词典。李寿山等人考虑到中文情感词典存在歧义、多义的问题,以及国内对中文词典可用资源较少的问题,利用机器翻译系统以及双语言资源的约束信息来构建了一个中文情感词典[8]。Xu等人创建了一个更广泛的情感词汇表,其中包含基本情感词汇、领域特定情感词汇和多义情感词汇[9]。利用这个更广泛的情感词汇表,并设计了一个情感评分规则,用于实现对文本情感的表达。
基于机器学习的方面级情感分析方法使用统计机器学习算法,通过大量标注或无标注的语料库,抽取特征并进行情感分析,最终输出情感分析结果。Kiritchenko等人将支持向量机与情感词典结合起来[10],用于在数据集SemEva2014上中进行方面情感极性抽取,取得了不错的表现。戚天梅等人采用了逻辑回归,基于朴素贝叶斯,支持向量机和随机森林4种机器学习算法计算情感倾向方面值[11]。Jagdale等人通过在亚马逊数据集上识别评论文本中的情感特征,并构建分类器模型,采用朴素贝叶斯算法进行训练和评估,从而实现对产品评论的分类和情感分析[12]。该方法在实验中取得了较好的情感分析效果,具有较高的准确性和可靠性。
基于深度学习的方面级情感分析最大的优势是不依赖人工定义特征,神经网络可以自行学习文本中蕴含的情感信息。方面级情感分析往往要确定文本中目标词、方面词和情感词,目标词是文本评价的对象,方面词是文本对评价对象某个方面的评价,情感词是文本评价该方面的好坏程度。为了解决目标-方面-情感检测(TASD)任务,即从一个句子中检测目标-方面-情感三元组。Wan等人开发了一种新的基于神经网络的目标-方面-情感联合检测方法[13]。Li等人提出一种同时考虑语法结构互补性和语义相关性的双图卷积网络[14],使用一个包含更丰富句法信息的依存概率矩阵,并精心设计了正交和差分正则化器,以增强精确捕捉语义关联的能力。Phan等人提出了将语法信息融入上下文嵌入中,提出了一种包含方面提取器和方面情感分类器的ABSA解决方案[15],用来解决方面提取无法确定多词方面的边界。Liang等人提出一种新的端到端ABSA迭代多知识转移网络,通过在token层和文档层进行知识转移来充分挖掘ABSA任务中的交互关系[16]。Mao提出了一种联合训练框架,在一个模型中处理所有ABSA子任务,来提高训练的效率[17]。Wu等人提出了两种上下文引导BERT(CGBERT)的变体[18],可以学习在不同的上下文下分配注意力,合理地分配上下文的注意力权重。Tian等人提出情感知识增强预训练[19],将不同类型的情感知识集成在一起,为各种情感分析任务提供了统一的情感表示。Liu等人考虑一种更直接地利用预训练语言模型的方法[20],用句子来表示输出。该方法通过直接遵循预训练期间的任务设置,允许在seq2seq语言模型中更直接地使用预训练知识。
2 模型方法
首先对在线课程评论方面词进行抽取,然后提取出每个方面的情感极性。通常地,评价指标分为五个方面。
本文提出了基于注意力机制的RoBerta-BiLSTM模型,其模型结构图如图1所示。它主要由五层网络结构组成,分别是方面词提取层,通过相似度的计算,提取出评论文本中与方面词最接近的词语作为方面词;RoBERTa词向量层,将课程评论和方面词分别转换成为字向量;语义抽取层,使用BiLSTM语义抽取层提取方面词和评论文本上下文的语义,再通过交叉注意力机制对信息进行更好地编码,从而可以捕获到关键信息,输出层通过softmax分类后得到输出结果。
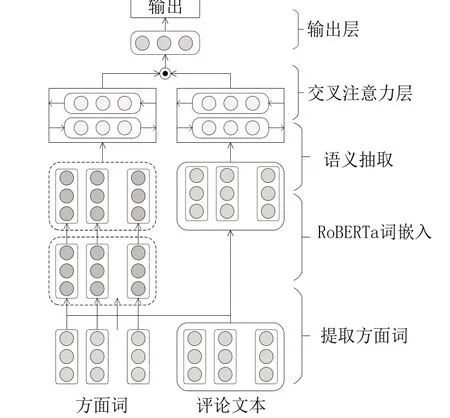
图1 RoBERTa-BiLSTM模型
第一层是方面词抽取层。本文的方面词是通过教育学者研究在线课程评价指标的基础上,综合考虑后选定了五个方面:课程内容、教师、课件、课程设计和专业度,作为方面词的输入。选定的方面词可能和在评论中抽取方面词有一定的误差,这一层的任务是提取出评论文本中和方面词相似度最高的词作为方面词。设定方面词输入为:A={a1,a2,a3,…,an},课程评论文本的输入为:C={w1,w2,w3,…,wm},通过余弦相似度来计算两者相似度,最终选用相似度最高的评论文本中的词作为方面词进行输入。
第二层是词嵌入部分,主要工作把词转换成为计算机能够识别的向量输入模型,并且尽可能不因为丢失句子其他特征,而导致降低最后实验效果。本文采用的词嵌入模型是RoBERTa预训练模型,RoBERTa模型是BERT模型的改进,能够更加准确地表达评论文本和方面词的含义。RoBERTa模型对于每一个课程评论C和方面词A中的每一个单词转换成为一维向量。定义课程评论输入为C={w1,w2,w3,…,wn},方面词输入为A={w1,w2,w3,…,wn},RoBERTa模型将输入以wi作为单位映射到低维向量vi∈Rdw。得到评论句子的向量可表示为{v1c,v2c,v3c,…,vnc}∈Rn×dw和方面词向量可表示为{v1a,v2a,v3a,…,vma}∈Rm×dw。
第三层是语义抽取层,课程评论中的语义特别重要,他能表达出用户的情感和认知等。为了能够更好地获取到课程评论的语义信息,该层采用了Bi-LSTM模型来抽取评论文本中隐藏的语义,在双向LSTM中,每个时间步骤都有两个LSTM层,一个从前向后处理序列,一个从后向前处理序列。这意味着,每个时间步骤的输出都来自前向和后向两个方向的信息汇总。假设Bi-LSTM当前权重为w和u,当前输入为Xt,输出为ht,前一单元输入为Xt-1,输出为ht-1,后一单元的输入为Xt+1,输出为ht+1。将输入向量[x1,x2,x3,…,xn]输入正向LSTM中,得到正向语义信息h→如公式(1)。
第四层是注意力层,虽然在语义抽取层能够充分抽取出正向和反向的语义信息,但是对于每个方面的单词重要程度是一样的,不能够区分出来哪一个更重要,往往评论文本中对于每个方面重要程度不一样。这里可以借助交叉注意力机制来解决这个问题。由语义抽取层得到方面语义ha∈Rm×2dw和评论文本hc∈Rn×2dw通过交叉注意力机制来计算影响权重。先通过两者乘积可得到匹配矩阵I,如公式(4)所示。
对匹配矩阵I的每一列进行softmax得到每个方面对课程评论的关注程度α,如式(5) 。对匹配矩阵I的每一行进行softmax得到每个课程评论对方面的关注程度β,如公式(6)所示。
得到方面对评论关注程度矩阵α和评论对方面关注度矩阵β后,可重新计算评论和方面词表示,如公式(7)和公式(8)所示。
输出层通过注意力交互层得到的方面词和课程评论文本连接,如公式(9)所示,再通过softmax进行预测课程评论中在这五个方面情感极性,如公式(10)所示,其中w和b分别为全连接层的权重矩阵和偏置向量。
3 实验分析
本文以在线观看课程人数和文本评论人数为主要的筛选条件爬取了bilibili 平台上10 门数据结构课程真实的评论,并进行了预处理和标注。最后在爬取的13 509条的评论中筛选出4000条评论数据,数据集的分布如表1所示:

表1 数据集分布
最终处理完之后,bilibili 课程评论信息数据集如图2 所示,数据集包括了评论以及5 个方面的情感极性,分别是内容、教师、课件、专业度和合理性这五个方面,情感极性有三个类别,其中-1 代表该方面为消极,0代表该方面为中性,1代表该方面为积极。把实验数据平均分成10份,其中8份做训练集,剩下2份做测试集。
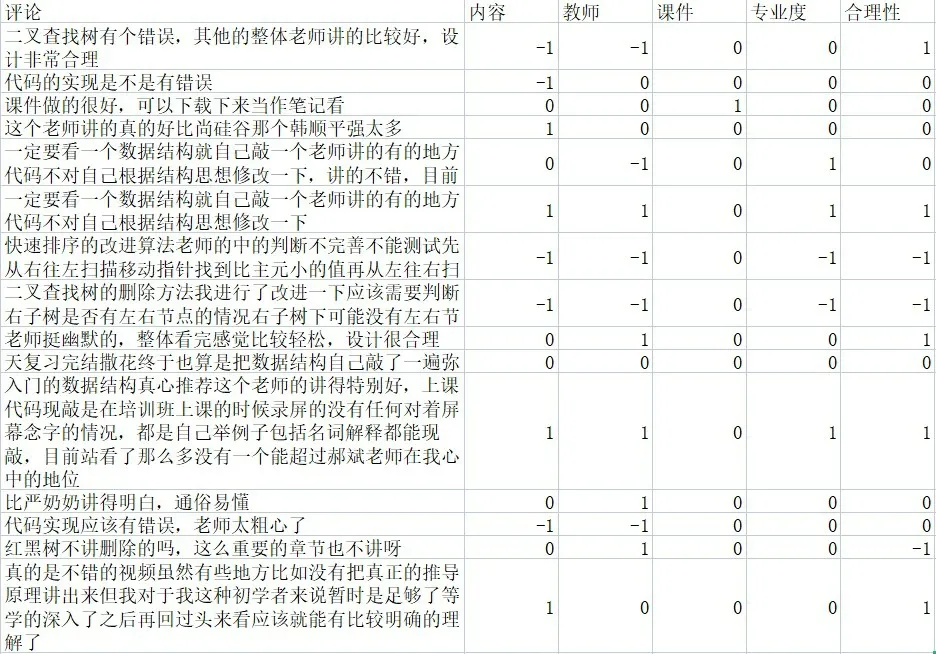
图2 部分数据集
测试验证环境和参数配置信息如表2、3:

表2 实验环境
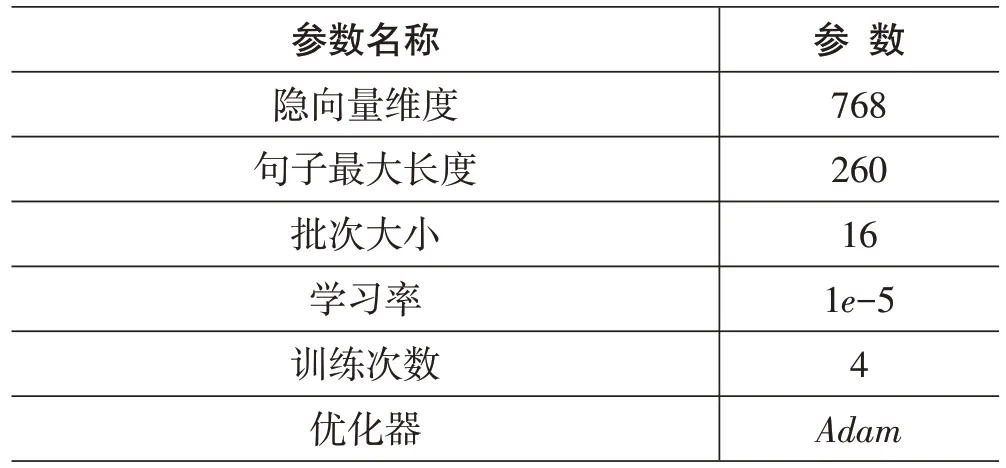
表3 参数设置配置信息
表4 展示了数据集在不同模型上的准确率和F1值。

表4 实验结果
在方面级情感分析实验中,ATAE-LSTM模型与Word2Vec-LSTM模型相比,其准确率和F1 值准确率都提高了3%左右,ATAE-LSTM利用注意力机制和LSTM模型相结合,将句子和方面词作为输入进行情感分析任务,将方面词嵌入到每个词向量中,并利用注意力机制来获取不同方面的上下文信息。其在考虑方面词对于情感分析的重要性方面表现更好,这表明在训练时将方面词与文本关联,能够有效获取方面词前后的情感信息,从而提高模型的性能。ATAE-LSTM模型相比Word2Vec-BiLSTM-AOA模型,其准确率和F1 值准确率都降低了7%-9%,而在BiLSTM中,每个时刻的输出不仅依赖于该时刻及之前的输入,还依赖于该时刻及之后的输入。这种前后两个方向的信息流通使得BiLSTM比LSTM更加全面地理解了整个序列的信息,从而在处理自然语言处理任务时更为有效。本章提出的RoBERTa-BiLSTM-AOA模型相比于Word2Vec-BiLSTM-AOA模型,其准确率和F1值准确率都提高了4%~5%,RoBERTa模型,可以通过对文本的上下文进行建模来获得更好的语义表示能力而Word2Vec模型只能通过单词出现的上下文来获得单词的语义表示,这种表示缺乏上下文的全局信息。RoBERTa模型更好的处理长文本,并能够捕捉文本中的整体信息,而Word2Vec则不擅长处理长文本。RoBERTa可以为同一个词汇的不同含义学习不同的嵌入向量,相比之下Word2Vec只为每个单词学习一个嵌入向量,无法区分一个单词的不同含义。RoBERTa通过在大规模语料库上训练,可以处理各种类型的文本数据,并具有较强的泛化能力,相比之下Word2Vec只是在局部上下文中学习单词嵌入向量,泛化能力相对较弱。
4 结束语
本文采用RoBERTa模型来嵌入词向量,采用全词掩码的方式进行训练,使用注意力机制关注文本的重要部分,能够对句子和方面词进行建模,从而获得它们的向量表示。相比于Word2Vec等模型,RoBERTa能够建立更加准确的上下文和方面词之间的联系。此外,RoBERTa还使用BiLSTM模型对句子和方面词进行建模,以捕获它们的双向语义依赖关系,并使用遗忘门和记忆门来解决梯度消失和爆炸问题。这使得BiLSTM模型在处理序列标注任务中标签具有上下文依赖的情况时表现良好。最后,RoBERTa的交叉注意力机制使得它可以建立句子和方面词之间的关系,并学习方面词对上下文的交互作用。这有助于进一步获取文本中的重要信息,提高模型的性能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
