
基于YOLOv5的课堂抬头低头行为识别研究
2023-12-02 09:25:00欧阳维晰樊万姝陈麟伟
电脑知识与技术 2023年29期
欧阳维晰,樊万姝,陈麟伟
(大连大学软件工程学院,辽宁大连 116622)
0 引言
随着智能化教育体系的不断发展和完善,如何将人工智能技术更好地应用于高校课堂教学场景中具有现实需求性。目前高校课堂教学纪律主要依靠于教师的管理和学生的自我约束,教室中的监控录像无法实现对课堂上每个学生的课堂行为进行监督与管理,教师不能及时接收学生对教学情况的真实反馈。鉴于此,利用智能化技术[1]对课堂学生行为进行监测具有必要性和迫切性。针对课堂学生行为的检测识别,传统方法大多使用特征检测算法及分类算法对其状态进行提取和分类。最近,深度学习的快速发展为学生行为检测识别提供了新的思路。不同于传统的人工提取工作,深度学习方法不需显式地给出具体的检测模型,而是利用设计好的网络模型端到端地隐式学习相应的映射函数,在识别精度上有了较大程度提升[2]。得益于深度学习在图像数据集上具有很强的学习能力,本文采用检测速度和精度都较优的YOLOv5算法对学生课堂抬头低头行为识别,针对学生不同状态实时反馈得到一个合理识别结果。将深度学习技术引入高校的教学质量评估中,实时对学生课堂上的抬头低头状态进行检测,有助于教师及时了解学生的学习状态,根据学生反馈调整教学方式以提高教学质量,推动高校课堂教学的改革和教学体系的优化。
1 基于YOLOv5的课堂抬头低头行为识别算法
1.1 YOLOv5s网络框架
YOLOv5作为基于深度学习的物体检测框架的典型代表,被广泛应用于各类目标检测任务。该算法是YOLO系列目标检测算法的第五代,相比前几代算法,在速度与精度方面都得到了极大的提升。目前,YOLOv5 共 有4 种 网 络 模 型YOLOv5s、YOLOv5l、YOLOv5m 以及YOLOv5x,其中YOLOv5s 是YOLOv5 系列中网络深度和宽度最小的模型[3],可以更好地应用于小数据集的模型训练。鉴于此,本文采用YOLOv5s模型实现学生课堂抬头低头行为识别。YOLOv5s 网络模型主要由Input、Backbone、Neck、Prediction 四部分构成。YOLOv5s算法的整体网络架构如图1所示。
1.1.1 Input
YOLOv5s的输入端采用Mosaic数据增强的方式,对多张大学生课堂图片进行处理,进而扩充数据集,提升模型对小目标检测的性能;在每次训练时,基于训练数据自动学习的方式自适应计算最佳锚框值。在网络训练阶段,模型根据初始锚点框输出相应的预测框,计算其与真实框之间的差异,执行反向更新操作,从而迭代更新网络参数;此外,YOLOv5s对原始课堂的图片进行缩放时使用了自适应缩放技术,在缩放后的图片中自适应地填充最少的黑边,旨在进行推理时,大幅降低计算量,进一步提升目标检测速度。
1.1.2 Backbone
Backbone 主要包含Focus 结构以及CSP 结构[4]。Focus结构用于实现高分辨率图像信息从空间维到通道维的转换,将大小为608×608×3 的课堂图片输入到Focus 结构,经过4 次切片操作得到大小为304×304×12的特征图,再使用1次32个卷积核的卷积操作输出大小为304×304×32 的课堂图片特征图。YOLOv5s 设计了两种CSP 结构:CSP1_X 和CSP2_X,分别应用于Backbone 和Neck 中。CSP 结构克服了其他卷积神经网络框架中梯度信息重复的缺陷,在减少模型的参数量和FLOPS 数值的同时提高了推理速度和准确率。此外,Backbone 中还加入了SPP 模块,增强网络对多尺度特征进行融合的能力。
1.1.3 Neck
Neck是在Backbone和Prediction之间插入的用于更好地提取融合特征的网络层,其采用特征金字塔网络(Feature Pyramid Networks,FPN)[5]和感知对抗网络(Path Aggregation Network,PAN)相组合的结构进行上采样和下采样。通过自顶向下的FPN,上采样高层特征以传递强语义特征,生成预测特征图。在FPN后添加自底向上的PAN 传达强定位特征。FPN 与PAN 的联合使用可以实现不同的主干层对不同的检测层的参数聚合,同时获得语义特征和定位特征,进一步提高模型的特征提取能力。
1.1.4 Prediction
Prediction 主要由损失函数和非极大值抑制两部分组成。YOLOv5s 中采用GIOU_Loss[6]作为Bounding box 的损失函数。GIOU_Loss中增加了相交尺度的衡量方式,有利于缓解课堂图片边界框不重合的特殊情况。针对大量目标框的筛选问题,使用非极大值抑制方法对冗余的预测框进行过滤,以获取最优的目标框,进一步提升算法的检测精度。
1.2 实验流程
基于YOLOv5 的课堂抬头低头行为识别主要包括数据集构建、模型训练以及抬头低头姿态检测估计三部分。首先通过安装在高校不同教室中的多个摄像头采集多个上课视频信息并截取成帧图片,使用LabelImg 对其进行标注以构建抬头低头识别数据集;其次通过YOLOv5s 训练模块对数据集进行训练获取模型权重数据;最后使用YOLOv5s预测模块完成学生低头行为预测。实验流程如图2所示。

图2 实验流程图
2 实验结果与分析
2.1 数据集构建
本实验收集了大量大学生课堂上课视频,尽量选择在同一地点,不同时间,人数差不多的视频。首先,从筛选出的每个视频的中间部分每隔5s 截取1 张图片,共截取100张图片。由于大学生在课堂上的行为状态相对单一,一般只有抬头听课和低头看书两种状态,为保证数据的质量和可靠性,所截取的100张图片里学生的抬头低头状态总量尽量在同一个范围内波动。经以上数据处理后采集并整理得到2 000张数据图片。随后,采用LabelImg开源数据标注工具对学生抬头低头状态进行标签标注,并将图片的标注格式由xml 转换为txt 文件格式,即YOLOv5s 数据格式。图3为数据集标注样例。txt 文件中每行第一个数据表示目标类别,0代表抬头,1代表低头,其余四个数字分别代表目标左上角的坐标和宽高。最后,以7:2:1的比例将标注好的数据划分为训练集、测试集和验证集,并将这些数据集中的图片分别存放相应的.txt文件下。

图3 LabelImg标注界面
2.2 评价指标
本实验采用目标检测任务中常用的平均精度均值(mean Average Precision,mAP)[7]来评价模型性能。mAP 是基于召回率(Recall)、精准率(Precision)以及平均精度(Average Precision,AP)三个指标。
召回率是指模型在进行目标检测时是否将所有区域都检测到,计算公式如式(1)所示:
其中,TP表示真正例,FN表示假反例。
精准率是指模型在进行目标检测时检测到的区域准确率,计算公式如式(2)所示:
其中,FP表示假正例。
平均精度是召回率从0 到1 时准确率的平均值,衡量训练得到的模型对单位类检测效果的好坏。计算公式如式(3)所示:
其中,P(s)是准确率-召回率(Precision-recall,PR)曲线。平均精度为PR曲线的面积。
mAP为所有类别平均精度的平均值,计算公式如式(4)所示:
其中,AP(i)表示第i个类别的检测精度,n表示类别数目。
2.3 模型训练
模型训练环境为单张RTX3090,操作系统为Ubuntu18.04,开发语言为Python,选用PyTorch深度学习框架,使用CUDA并行计算架构运算平台。在训练过程中,采用YOLOv5系列中轻量级的YOLOv5s网络模型,参数设置:学习率设置为0.01,bitch-size大小设置为32,训练迭代次数设置为200,权重衰减设置为0.005。对设置好参数的源代码进行编译,即通过训练可获得的模型的权重数据,每张图片的推理运行时间约为5ms。训练结果如图4 所示。经过200 次左右的训练后,YOLOv5s网络模型的损失函数已趋于稳定。
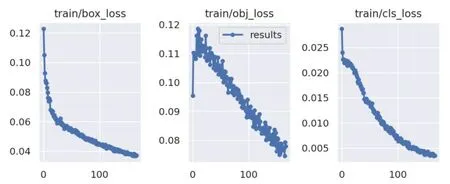
图4 定位损失、置信度损失和分类损失在训练过程中迭代次数的关系图
YOLOv5s 算法中所使用的损失函数由以下三种损失函数组成:定位损失(localization loss)、分类损失(classification loss)、置信度损失(confidence loss)。其中YOLOv5s 采用GIoU Loss 函数来计算定位损失,公式如下所示:
其中,对于任意的两个A、B框,首先找到一个能够包住它们的最小方框C,C(A∪B)表示为C的面积减去A∪B的面积,再用A、B的IoU 值减去这个比值得到GIoU。
YOLOv5s 采用交叉熵损失函数(BCEclsloss)来计算定位损失,计算公式如下:
其中,N表示类别总个数,xi为当前类别预测值,yi表示经过激活函数后得到的当前类别的概率,y*i表示为当前类别的真实值(0或1),Lclass为分类损失。
YOLOv5s采用BECLogits 损失函数来计算置信度损失,这个损失函数结合了Sigmoid 和BCELoss,计算公式如下:
其中,σ(x)为Sigmoid 函数,可以把x映射到(0,1)区间。
2.4 结果分析
训练过程中通过对网络参数的反复调整,选择精度最优的网络模型,并对其进行测试。YOLOv5s网络进行目标检测时可以对目标图像进行分类、定位、确定目标大小。本实验的精准率-置信度关系图如图5(a)所示,召回率-置信度关系图如图5(b)所示,F1曲线如图5(c)所示,精准率-召回率关系图如图5(d)所示。目标检测模型的mAP@0.5为0.358。结合目标检测的可视化视频可以发现,由于摄像头的视角问题,近距离的可以很好地检测出抬头低头的状态,远距离的区域由于目标小,视角很偏,难以检测出目标,还会影响分类的准确性。

图5 不同指标曲线图
抬头低头行为检测效果如图6所示。可以发现在画面清晰的情况下基本能够准确识别学生,并较为准确地识别该学生此时的抬头低头状态。通过计算得到识别平均置信度为0.75,说明利用该模型可以准确识别学生的抬头、低头行为,有助于老师在教学活动中更好的了解学生的上课状态,提高学生的学习效率。

图6 抬头低头行为检测效果图
3 结论
本文提出了一种基于YOLOv5的课堂学生行为检测方法,初步来看,此模型对于学生课堂的检测行为是十分可行有效的,可实现对学生的行为状态进行统一的收集分析,辅助教师实时关注学生的上课状态,提高课堂学生的学习效率,有效地改善课堂老师的教学质量。但仍有不足且需完善的地方,未来研究工作将重点聚焦于多尺度特征提取上,在深度学习网络中实现多种不同的特征图分辨率的分支并行,提升小目标的检测的准确率。此外,将开展基于多目相机目标检测的研究,对大学课堂学生行为状态的识别进行优化。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
海峡姐妹(2017年3期)2017-04-16 03:06:33
儿童故事画报·发现号趣味百科(2016年7期)2017-02-08 09:24:57
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19 02:47:50
高中生学习·高二版(2015年12期)2016-01-05 13:08:35
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
中学英语之友·上(2008年2期)2008-04-01 01:19:30
中学英语之友·上(2008年2期)2008-04-01 01:19:30
