
基于相似性聚类的司法案例智能推荐系统研究
2023-12-02 09:25高冠东
电脑知识与技术 2023年29期
高冠东
(中央司法警官学院信息管理系,河北保定 071000)
0 引言
随着科学技术的发展,人工智能技术在不同领域取得较好的发展,在司法领域中引入人工智能技术成为必然趋势。2018年司法部发布的《“数字法治、智慧司法”信息化体系建设指导意见》中,对“数字法治,智慧司法”的信息化体系建设提出指导性意见。同时“智慧司法”[1]“智慧法院”[2]等以人工智能为支撑,取得较好的发展,促进司法信息化和智能化[3-5]。自然语言处理技术作为人工智能中的重要组成部分,为在海量的司法文本数据中挖掘具有重要价值信息提供支持。文本分类作为自然语言处理中一项基本任务,在司法领域中得到广泛应用,例如类案推送[6]、争议焦点[7]、法条预测[8]等。
文本数据是非结构化的,并且噪声很大。在执行文本分类时,用户获得了标记良好的训练数据和监督学习的益处。然而,文档聚类是一个无监督的学习过程,用户借以通过让机器了解各种文本及其特征、相似度和差异性,尝试将文档分割和分类为不同的类别。这使得文档聚类更有挑战性,也更有趣。本研究考虑拥有一个犯罪文档语料库,以期讨论各种不同的概念和想法。人类以一种方式将文本链接,文本使得人类能使用从过去所学到的知识,并可以将其应用于区分概念。例如,与句子“2016 年11 月份,被告人温某某与被告人蔡某某合谋走私柴油。”相比,句子“2012 年6 月初,郭某与汪某联系购买10 000 克毒品氯胺酮。”更类似于“2016年春节后的一天,董某某、严某某(另案处理)密谋生产毒品甲卡西酮。”这句话。用户可以轻松并直观地确定特定的关键短语,例如:走私、毒品、氯胺酮、甲卡西酮等,这有助于其确定哪些句子或文本更为相似。
1 构建司法案例推荐系统
在司法实践中,判决案例是一项非常重要的资料。通过分析判决案例,法官可以了解类似案例的判决结果,并参考其理由和逻辑进行判断。然而,由于案例数量庞大,法官往往需要花费大量的时间和精力来寻找类似案例。因此,构建一种基于相似性聚类的智能推荐系统,可以帮助法官快速准确地找到与当前案件类似的案例,提高司法效率和判决质量。
推荐系统是机器学习中最流行、最常用的应用之一。通常,它们用于向用户推荐实体。这些实体可以是任何东西,例如产品、案例、电影、服务等。常见的推荐例子包括:
1)司法案例库推荐相似案例。
2) Amazon Prime、Netflix 和Hotstar 推 荐 电 影/节目。
3)YouTube推荐观看的视频。
推荐系统通常可以通过三种方式实现:
1)简单的基于规则的推荐系统:基于特定的全局指标和阈值。
2)基于内容的推荐系统:基于特定的感兴趣实体提供相似的实体。
3)协同过滤推荐系统:不需要元数据,但用户会尝试根据不同用户和特定项的过去评分来预测推荐和评分。
本研究构建了一个司法案例推荐系统,借此基于与不同案例有关的数据/元数据,尝试推荐类似的司法案例,推断未来案情结果。
1.1 司法案例数据集构建
本研究以中国裁判文书网为语料源,收集并选取了诈骗、行贿、走私、制造毒品、危险驾驶、抢劫、绑架、故意伤害、故意杀人、强奸等指控的典型案件判决书共123 条。数据集样式如图1 所示,由姓名、年龄、民族、户籍所在地、文化程度、职业、案件类型、案由、罪名、犯案事实、刑期等多个短语组成。

图1 司法案例数据集
本研究构建司法案例推荐系统,具体流程如图2所示:
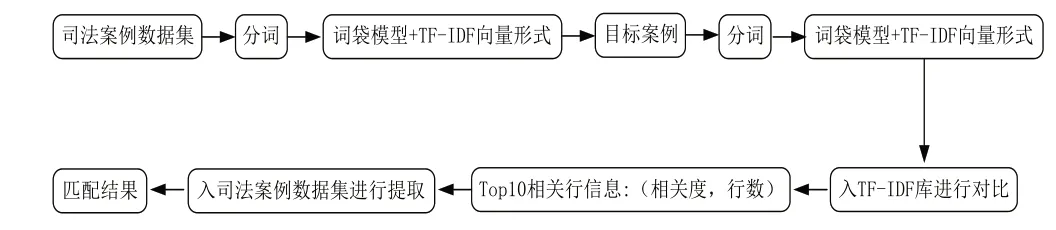
图2 司法案例推荐系统技术路线图
推荐都是关于了解基本特性的,它使我们倾向于一种选择而不是另一种选择。项目之间的相似性(在本例中是司法案例)是了解为什么用户选择一个司法案例而不是另一个司法案例的一种方式。有不同的方法可以计算两个项目之间的相似度。
1.2 司法案例数据集预处理
司法案例语料在计算相似度之前一般需要一系列的预处理工作,才能输入得符合要求。首先需将用户预定义词典载入,防止一些重要的短语被分词器所分开。其次,载入停用词典,减少噪声。然后,读入语料文件对整个语料库进行分词操作。最终将整个语料库制作成向量形式,才能进行相似度计算。
相似性度量,即综合评定两个事物之间相近程度的一种度量。两个事物越接近,它们的相似性度量也就越大,而两个事物越疏远,它们的相似性度量也就越小。相似性度量的给算种类繁多,一般根据实际问题进行选用。相似度度量用于文本相似度分析和聚类。任何相似度度量或距离度量都可测量两个实体之间的紧密程度,该实体可以是任何文本格式,例如文档、句子甚至侧向。这种相似度度量有助于识别相似实体和区分彼此差异明显的实体。相似度度量非常有效,有时选择正确的度量可能会对最终分析系统的性能产生很大的影响。
文本相似度的主要目标是分析和度量文本两个实体之间的紧密程度。文本的这些实体可以是简单的标识符或词项,例如单词或包含句子或文本段落的整个文档。分析文本相似度的方法有很多种,可以将分析文本相似度的意图大致分为以下两个方面:
1)词汇相似度:这涉及观察文本文档的语法、结构和内容方面的内容,并根据这些参数度量它们的相似度。
2)语义相似度:这涉及确定文档的语义、含义和上下文,然后确定它们彼此间的紧密程度。在此方面,依存语法和实体识别是可以提供帮助的便捷工具。
文本分词后,如何将其送入一个计算文本相似度的过程中呢?答案是文本向量化,即用向量或矩阵的形式表示文本,也可以理解为对文本的数值化处理。文本向量化从数学角度可以解释为映射,即将单词映射到另一个空间。本研究将把语料库制作成词袋模型+TF-IDF的向量化表示形式。结果如图3所示。

图3 文本向量化函数测试结果
1.3 目标案例预处理
目标案例预处理与司法案例数据集预处理类似,也是通过加载用户预定义词典、删除停用词、分词、向量化4步组成。唯一区别是由整个语料库案例变为了单个案例预处理。目标案例预处理一共分为载入用户预定义词典、停用词删除以及分词操作、文本向量化(将单一目标案例制作成词袋模型+TF-IDF的向量化表示形式)3个步骤:
现在已经使用基于TF-IDF的向量表示对整个语料库和目标案例进行了规范化和向量化处理,接下来看看如何计算具有余弦相似度和文档相似度。
1.4 成对文档相似度的余弦相似度计算
本研究重复使用计算余弦相似度的概念来计算文档而不是词项的余弦相似度分数。文档向量将是基于词袋模型的向量,其具有TF-IDF值而不是词频。
基于Numpy的余弦相似度代码如下所示:
def Cos_Distance(vector1,vector2):
vec1=np.array(vector1)
vec2=np.array(vector2)
return float(np.sum(vec1 * vec2))/ (np.linalg.norm(vec1) * np.linalg.norm(vec2)) # 此处可以更换成任意的相似度计算公式
实现余弦相似度的代码之后,便要计算目标案例与整个司法案例语料库的相似度,代码如下所示:
def similarity_words(vec,vecs_list): # 传进目标语句的向量形式和整个语料库的向量形式
Similarity_list=[]
for vec_i in vecs_list:#拿出整个语料库中语句Similarity=Cos_Distance(vec,vec_i)#计算目标语句与整个语料库中语句的余弦相似度
Similarity_list.append(Similarity)return Similarity_list
1.5 司法案例推荐
将目标案例与整个语料库中的司法案例进行对比,以计算其与整个语料库中的案例的相似度,并返回前十条相似度较高的样本,借此可以推断目标案例未来的案情结果,可以成为法律咨询方面的一个有价值的补充。代码如下所示:
def main(words,token2id,idf_dict,tfidf_library):
cut_words=split_words(words)#对目标语句进行分词
vec=make_tfidf(cut_words,token2id,idf_dict)#将目标语句转换成词袋模型+TFIDF的表现形式
similarity_lists = similarity_words(vec, tfidf_library)#计算相似度,返回目标语句与整个语料库中每个语句的相似度列表
sorted_res=sorted(enumerate(similarity_lists),key=lambda x:x[1])#将相似度列表转换成枚举形式,针对枚举类型的第2个值进行升序排序
outputs = [[word_list[i[0]], i[1]] for i in sorted_res[-1:-11:-1]]#取出排名前十的原始语料
return outputs
最终测试某一条目标案例,代码如下所示:
words="原审判决认定:被告人于某某与同居女友夏某(被害人,殁年43 岁)因于饮酒问题而多次争吵。2020年5月27日17时许,因于再次饮酒,夏在开原市内服药自杀,此举引发于的愤怒。于趁夏昏睡之机,用电热毯电源线勒夏颈部,致夏窒息和缺氧;后又用平底炒勺击打夏头面部数下,用蔬菜刮刀割夏的颈部数下,被害人夏某经抢救无效死亡。经法医鉴定:夏某系头右额部、面部遭受反复钝器打击致硬膜下血肿、蛛网膜下腔出血、脑挫伤死亡。案发后被告人于某某主动投案,并对犯罪事实供认不讳"
outputs=main(words,token2id,idf_dict,tfidf_library)
for i in outputs:
print(str(i[1])+" "+i[0])
实验结果,返回了十条与目标案例相近的案例与相似度。
2 结论
本研究使用文本相似度开发了一种司法案例推荐系统,并将相似的文档聚类在一起。利用AI算法来学习过去法律情景的案例信息集,构建预测模型,推断未来案情结果,可以成为法律咨询方面的一个有价值的补充。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
新世纪智能(语文备考)(2020年4期)2020-07-25
数学年刊A辑(中文版)(2019年3期)2019-10-08
中学数学杂志(高中版)(2016年6期)2017-03-01
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
中国学术期刊文摘(2016年1期)2016-02-13
职业技术(2015年8期)2016-01-05
声学技术(2014年1期)2014-06-21
语文知识(2014年4期)2014-02-28
