
类内-类间通道注意力少样本分类
2023-12-02 12:47:50杨利平张天洋王宇阳辜小花
光学精密工程 2023年21期
杨利平, 张天洋, 王宇阳, 辜小花
(1. 重庆大学 光电技术及系统教育部重点实验室,重庆 400044;2. 重庆科技学院 电气工程学院,重庆 401331)
1 引 言
在拥有足够标记数据的前提下,深度神经网络分类模型可在模式分类任务中取得优异的分类性能[1-2]。然而,实际应用的类别往往是变化的,可用于训练新分类任务的标记数据非常少、甚至为零。由于欠拟合或过拟合现象的存在,简单的利用少量新类别样本更新模型参数并不能使预训练的深度神经网络分类模型很好地适应新分类任务,这即是少样本分类问题[3-5]。
元学习是当前解决少样本分类问题的主流方法[6-7]。该类方法将少样本分类作为元学习任务来处理,分别利用元学习框架的元训练和元测试阶段完成分类经验(也称为元知识)的学习与迁移。元训练阶段的目标是在已有基类数据集上构造大量少样本分类任务并从中学习分类经验;元测试阶段的目标是利用少量新类别样本更新分类模型,将元训练阶段获得的少样本分类经验迁移到新的分类任务中。
原型网络[8](Prototypical Network, ProtoNet)是一种用于解决少样本分类问题的经典元学习方法。原型网络的基本思想是:在一个嵌入空间中,每个类支持集样本的特征向量取均值作为原型表示(Prototypes),该类别的样本在嵌入空间中聚集在该原型表示的周围,通过距离函数得到样本与各个原型表示之间的相似度。然而,由于原型网络采取简单平均的方法获得原型表示,噪声样本与正常样本对原型表示的影响力度是相同的,因此,极少数的噪声样本可能会对原型表示的计算带来较大的影响。为了缓解这种情况,现有方法基于原型网络在元训练阶段做了很多工作。文献[9]应用空间注意力机制关注嵌入空间中较为突出的区域,以保留目标主体的空间关系。文献[10]应用通道注意力机制关注任务内的最大化差异,以增强模型对新任务的判别能力。文献[11]通过引入额外的自监督任务人为地增加基类数据集的多样性和复杂性。上述少样本分类方法主要通过引入注意力约束和自监督学习来改善特征提取器对关键信息的提取。尽管这些方法在少样本分类任务中是有效的,但是这些约束策略都没有考虑特征对类别的鉴别能力。由于少样本分类任务标记样本有限,所以约束策略容易出现欠拟合或过拟合现象,不易达到最优状态。
针对上述问题,本文提出了一种类内-类间通道注意力少样本分类方法(Intra-inter Channel Attention Few-shot Classification, ICAFSC)。该方法在原型网络基础上设计了一个类内-类间通道注意力模块(Intra-inter Channel Attention Module, ICAM),该模块通过类内-类间距离度量计算通道权重实现特征加权,促使同类别特征更加紧凑不同类别特征更加分散,提高特征对类别的鉴别能力。ICAM 包含类内通道注意力和类间通道注意力两个部分。类内通道注意力计算同类别样本特征图的通道距离,寻找类内相似度高的通道,并增加这些通道的权重。类间通道注意力计算不同类别样本特征图的通道距离,寻找类间判别性大的通道,并增加这些通道的权重。为了使ICAM 充分学习类内通道权重和类间通道权重,提高特征对类别的鉴别能力,ICAFSC 在元训练之前增加一个预训练阶段。该阶段设计具有大量标记样本的分类任务,并利用这些任务充分训练ICAM,使其达到最优状态。在元训练阶段,ICAFSC 冻结ICAM 的参数,利用少样本分类任务训练特征提取器并从中学习少样本分类经验。在元测试阶段,ICAFSC利用少量的新类别标记样本更新少样本分类模型,将元训练阶段获得的少样本分类经验迁移到新的分类任务中。
2 原 理
2.1 少样本分类问题设置
本文用x表示输入样本,y表示类别标签;X和Y分别表示输入样本和类别标签的分布空间。少样本分类任务Tt给定包含支持集St和查询集Qt的数据集DT={St,Qt},其中支持集St=由少量带有类别标签的样本组成,查询集由无标签数据组成;和R分别表示支持集和查询集样本数量。通常,St包含N个类别,并且每个类别仅拥有K个样本(例如K=1 或K=5),即M=N×K。包含上述St的少样本分类任务Tt被称为N-wayK-shot 任务。少样本分类利用支持集St中非常有限的标记样本学习映射关系F:X→Y,并利用F对查询集Qt中的样本进行分类。但是由于K往往很小,少样本分类仅利用支持集St很难训练出一个高质量的映射关系F,因此,许多学者引入元学习解决少样本分类。
元学习框架下的少样本分类给定一个拥有大量标记样本的数据集,其中表示DB的样本数量。首先,元训练阶段在DB上随机采样出大量的少样本分类任务Ti,这些任务服从任务分布p(T),并利用少样本分类任务Ti训练一个能够快速泛化的映射关系F。然后,元测试阶段利用少样本分类任务Tt的支持集St更新映射关系F以适应新分类任务,并在Qt上测试映射关系F的分类效果。需要注意的是,在少样本分类中DB和DT的类别是不相交的。
2.2 原型网络
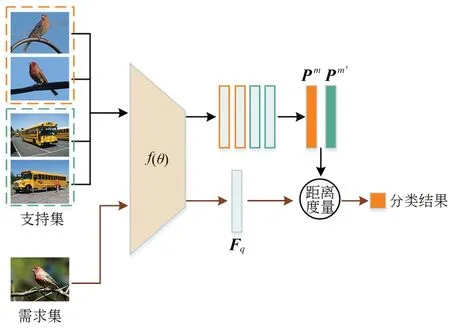
图1 原型网络Fig.1 Prototypical Network
原型网络计算查询集样本在嵌入空间与原型表示的距离,并利用softmax 函数得出查询集样本属于目标类别m的概率:
其中d(⋅)为距离函数,一般采用欧氏距离。最后,原型网络利用梯度下降法最小化目标类别的负对数概率损失优化模型:
在元测试阶段,原型网络则利用少样本分类任务Tt的支持集St构建适应新分类任务的原型表示,将元训练阶段的分类经验迁移到新分类任务上;然后,利用式(4)给出查询集(Qt)样本的预测分数,最后将预测分数最高的类作为分类预测结果。
本文提出的ICAFSC 在原型网络基础上设计了一个类内-类间通道注意力模块,该模块通过类内-类间距离度量计算通道权重实现特征加权,提高特征对类别的鉴别能力。为了使ICAM充分学习类内通道权重和类间通道权重,ICAFSC 在元训练之前增加一个预训练阶段。该阶段设计具有大量标记样本的分类任务,并利用这些任务充分训练类内-类间通道注意力模块,促使该模块达到最优状态。
2.3 类内-类间通道注意力少样本分类
2.3.1 少样本分类的类内-类间通道注意力原型网络
原型网络包含元训练和元测试两个阶段。其中,元训练利用许多任务训练模型对少样本分类任务的适应性;元测试则是利用少量的新类别样本将模型的先验知识迁移到特定的少样本分类任务。由于元训练阶段每个类别标记样本较少,因此ICAFSC 在原型网络的基础上增加了预训练阶段。预训练阶段的目的是利用包含大量标记样本的分类任务ti训练类内-类间通道注意力模块,从而能够学习更具有判别性的通道权重,提高特征对类别的鉴别能力。ti是数据集DB上随机采样出的分类任务,服从任务分布p(t),即ti~p(t)。ICAFSC 的主要训练与测试流程如下:首先,预训练阶段利用分类任务ti训练ICAM以学习更具有判别性的通道权重,同时初步更新嵌入式网络的参数;然后,元训练阶段固定ICAM 的参数,仅利用少样本分类任务进一步提高嵌入式网络对少样本分类的适应性;最后,元测试阶段利用训练后的模型对DT数据集进行预测以测试模型的少样本分类性能。以上三个阶段采用的模型结构如图2 所示。

图2 少样本分类的类内-类间通道注意力原型网络Fig.2 Intra-inter channel attention prototypical network for FSC
ICAFSC 将类内-类间通道注意力模块嵌入原型网络中。在预训练阶段,分类任务ti给定支持集和查询集其中G非常大(例如G=100 或G=200);Sb,Qb∈DB。ICAM 利用支持集监督信息计算第m类的综合通道权重Wm∈RC×1×1,该权重由类内通道权重和类间通道权重线性组合得到。ICAFSC 通过综合通道权重Wm将支持集第m类的第i个特征图转换成任务自适应特征图(也称为加权特征图)
其中⊙表示元素级乘法。计算中,综合通道权重值沿空间维度复制得到尺寸为C×W×H的通道权重。然后,ICAFSC 利用转换后的任务自适应特征图计算任务自适应原型表示
虽然支持集可以根据监督信息计算更具有可靠性的原型表示,但是需求集缺少监督信息无法计算对应的通道权重。因此,在计算需求集与第m类原型表示的距离时,本文将综合通道权重Wm应用于需求集特征图Fq∈RC×W×H:
类内-类间通道注意力模块主要由类内通道注意力和类间通道注意力组成,如图3 所示。为了更加简明地阐述ICAM,图3 中只展示了二分类的示意图,更多类别的讨论方式根据公式类推。类内通道注意力关注类内的相似信息并计算类内通道权重,类间通道注意力关注类间判别信息并计算类间通道权重。然后,ICAM 通过线性组合(CE)将类内通道权重和类间通道权重组,形成一个综合通道权重对特征图实现加权。
2.3.2 类内通道注意力
通道注意力[12-13]通常是对特征图做池化操作或挤压-激励操作以提取通道间的信息差异,并基于该信息差异对特征图施加通道级的权重。虽然这种注意力可以获取特征图自身每个通道的重要程度,但是对于具有一个或几个监督样本的小样本任务来说,样本的缺乏会极大地限制通道注意力对通道间信息差异的有效学习。为解决该问题,本文以同类别所有特征图为基础设计了类内通道注意力,如图4 所示。类内通道注意力主要由通道距离计算和全连接映射组成,该注意力以第m类的特征图和原型表示作为输入计算第m类的类内通道权重。
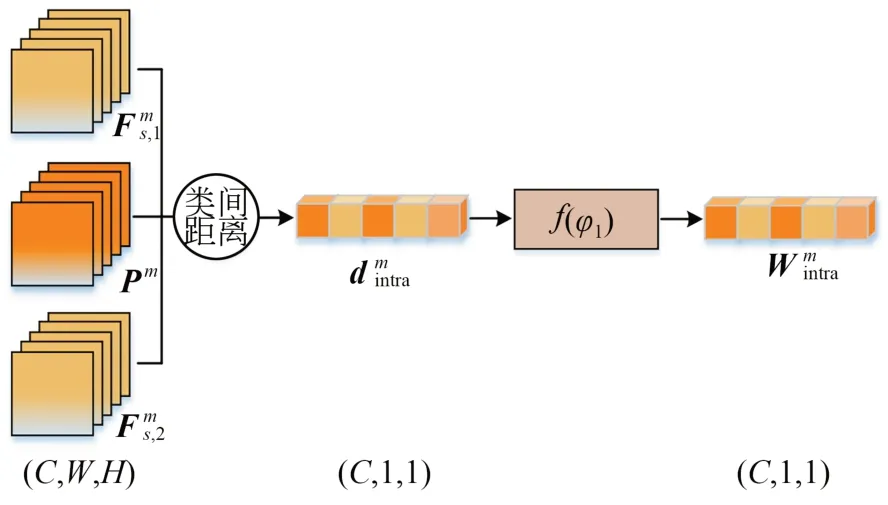
图4 类内通道注意力示意图Fig.4 Schematic diagram of intra-class channel attention
当给定支持集中类别为m的特征图,可以由式(3) 计算得到第m类的原型表示Pm∈RC×W×H。之后,对于第m类第c个通道的类内通道距离的表达式为:
该距离表示支持集样本高度激活的通道与原型表示的类显著性通道的相似程度。取通道c上K个样本的最大值作为第m类第c个通道的类内通道距离。距离越小,说明第m类所有样本与原型表示在通道c上的距离越小,通道相似程度越高,特征提取器提取的特征在通道c上更显著。
得到第m类的类内通道距离后,为了更好地整合通道间的相似信息,将类内通道距离作为输入送进两层的全连接网络中计算类内通道权重
其中:fφ1表示全连接网络,φ1表示可学习参数。假定预训练阶段每个分类任务的类别数N=Npre。ICAM 将所有类别的类内通道距离拼接形成一个尺寸为Npre×C的向量,并将该向量作为全连接网络的输入。全连接网络结构如表1所示。
从式(10)可以得出,类内通道距离越小,支持集样本与原型表示的通道匹配程度越高,也就意味着这些通道包含类内相似特征。因此,为了增大具有类内相似特征通道的权重,在全连接网络最后一层增加了转换层。为了更简明地阐述转换层,假设Npre=1,即有(类别为m):
其中:表示Sigmoid 的输出,则的元素均属于0 到1 之间。经过转换层之后,类内通道距离越小,类内通道权重越大。类内通道权重强调了类内的相似信息,同时也抑制了类内的冗余信息。因此,加权特征图所计算的原型表示更可靠,在不断迭代更新中也能促进特征提取器对类别的鉴别能力。
2.3.3 类间通道注意力
虽然类内通道注意力可以增大具有类内相似特征通道的权重,但对于少样本分类任务,有效地学习类间判别性特征也尤为重要。图5 为基于所有原型表示的类间通道注意力。类间通道注意力主要由通道距离计算和全连接映射组成,该注意力以所有类别的原型表示作为输入计算类间通道权重。为了更加简明地阐述ICAM,图3 只展示了二分类的示意图,更多类别的讨论方式根据公式类推。类间通道注意力旨在提高类间判别性较大的通道的权重,以此增加样本在嵌入空间与其他类别样本的判别性。

图5 类间通道注意力示意图Fig.5 schematic diagram of inter-class channel attention
当给定支持集中类别为m的原型表示Pm,第m类在第c个通道与其他类别m′的类间通道距离的表达式为:
该距离表示类别m高度激活的通道与其他类别m′显著性通道的相似程度。取c通道上N-1 个类别的最小值作为第m类第c个通道的类间通道距离。该距离越大,说明第m类原型表示在通道c上与其他类别原型表示的距离越大,通道的差异程度越高。
得到第m类的类间通道距离后,为了更好地整合通道间的判别信息,将类间通道距离作为输入送进两层的全连接网络中得到类间通道权重
其中:fφ2表示全连接网络,φ2表示可学习参数。该全连接网络相比类内通道注意力的全连接网络仅缺少最后的转换层,其他结构完全相同。
从式(13)可以得出,类间通道距离越大,类间通道权重越大。类间通道权重强调了类间的判别性信息,因此嵌入空间中的加权特征图的可分性会提高,在不断迭代更新的过程中,特征提取器的鉴别能力会逐步提升。
2.3.4 类内-类间通道注意力线性组合
类内通道注意力与类间通道注意力分别关注类内相似通道和类间判别通道。为综合考虑样本在嵌入空间类别表征,将两种通道权重线性组合形成一个综合通道权重,即:
其中:Wm∈RC×1×1,表示第m类的综合通道权重;α为平衡参数,α取0.5,以保证综合通道权重对类内相似通道和类间判别通道的关注度相同。
ICAFSC 在原型网络的框架下增加了一个预训练阶段,并利用ICAM 提高特征对类别的鉴别能力。假定元训练阶段每个少样本分类任务的类别数N=Ntrain。ICAFSC 冻结ICAM 的参数(全连接层)来保留在预训练阶段中学习到的通道特性。由于Npre与Ntrain的值可能不同,并且全连接层的输入神经元不可更改,在元训练阶段和元测试阶段中对输入全连接层的通道距离施加拆分或复制的操作,如图6 所示。

图6 通道距离拆分和复制示意图(f (φ)=f (φ1)∪f (φ2))Fig.6 Channel distance splitting and replication ( f (φ)=f (φ1)∪f (φ2))
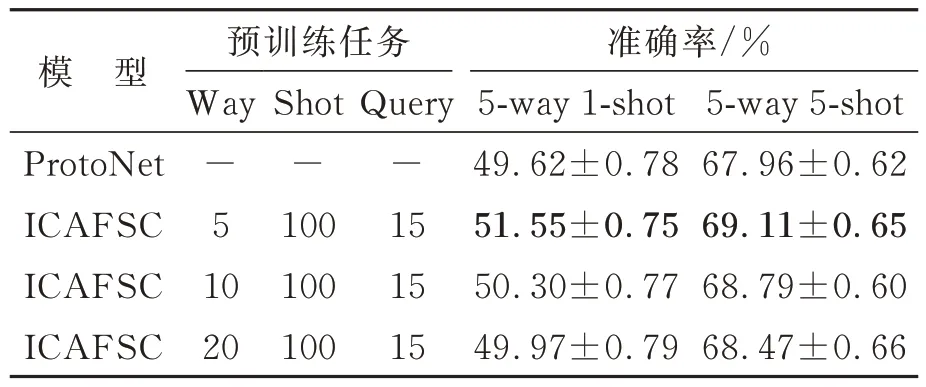
以元训练阶段为例,当Ntrain>Npre时,ICAFSC 将通道距离拆分为多份符合全连接网络要求的输入,并将全连接的输出拼接在一起,如图6(a)所示;当Ntrain 本文采用MiniImagenet 数据集[14]进行实验,该数据集包含100 个类别,每个类别有600 个样本,共计60 000 张图像。数据集主要包含鸟类、昆虫、汽车和飞机等类别。文献[15]将数据集按照64∶16∶20 的比例划分为训练集、评价集和测试集。 根据文献[8],图像需预处理为84×84 的分辨率。为防止图像变形,先对原始图像按短边等比例缩放到84 的大小,然后再利用中心裁剪的方法将图像裁剪为84×84 的分辨率。 骨干网络采用由4 个卷积神经网络模块(CNN Block)堆叠的卷积神经网络[16-17]。每个模块包含卷积层、批归一化层、ReLU 激活层以及最大池化层。CNN Block 的参数设置如表2 所示,其中c表示输出通道数,k表示卷积核的尺寸,s表示最大池化的步长,下标表示第几个模块。主干网络最后输出84×5×5 的特征图。 表2 卷积神经网络的参数设置Tab.2 Parameter setting of convolutional neural network 模型预训练与训练阶段均采用Adam 优化器,初始学习率为0.001。采用ReduceLROnPlateau 的学习率调整策略对评价集损失进行监控,当10 个迭代周期的评价集损失没有下降时,学习率降低到原来的0.3 倍。在MiniImagenet 数据集上的预训练周期为50 次,训练周期为400 次,当100 个迭代周期的评价集损失没有下降时,结束模型训练。 模型测试阶段,从测试集中随机生成600 组N-wayK-shot 任务,每类包括15 个查询集样本用于评估模型少样本分类的性能。分类准确率取测试集中随机生成的600 组任务的平均值,并给出95 %的置信区间。 针对不同N-way K-shot,选择欧氏距离作为距离函数[8]以及合适的训练阶段任务参数配置,具体设置如表3 所示。 表3 元训练阶段少样本分类任务的参数配置Tab.3 Parameter configuration of few-shot classification task in meta-train stage 首先在MiniImagenet 数据集上进行消融实验,验证ICAFSC 在不同训练阶段更新ICAM 参数对少样本分类结果的影响。然后,验证ICAFSC 不同少样本任务配置对少样本分类结果的影响。最后,给出ICAFSC 在MiniImagenet 数据集与其他方法的对比。 3.3.1 消融实验与分析 为验证提出的ICAM 在不同训练阶段更新参数对ICAFSC 少样本分类结果的影响,实验采用3 种ICAM 参数更新方式,分别是仅在预训练阶段更新参数(ICAFSC-pre)、仅在元训练阶段更新参数(ICAFSC-tra)以及预训练阶段和元训练阶段均更新参数(ICAFSC-pre+tra),分类结果如表4 所示。 表4 ICAFSC 在MiniImagenet 数据集上不同训练阶段更新ICAM 参数的实验结果Tab.4 Experimental results for ICAFSC updating ICAM parameters in different training stages on MiniImagenet 表4 分别展示了5-way 1-shot 和5-way 5-shot两种少样本分类问题的实验结果。从5-way 5-shot 和5-way 1-shot 的实验结果可以看出,3 种ICAM 参数更新方式的分类准确率均高于ProtoNet。这说明ICAM 有效地增强了模型对不同类别的鉴别能力。在5-shot 和1-shot 情况下,ICAFSC-pre 的分类准确率比ICAFSC-tra 分别提高了0.97%和1.79%。这说明预训练阶段大量的标记样本更有利于ICAM 学习类内通道权重与类间通道权重,提高了特征的鉴别能力。相比于ICAFSC-pre,ICAFSC-pre+tra 在5-shot 和1-shot 的情况下分别下降了0.24%和0.85%,其原因在于元训练阶段少量标记样本对ICAM 的更新会破坏ICAM 在预训练阶段学习到的类内-类间鉴别能力。 3.3.2 不同少样本任务配置的实验与分析 为验证ICAFSC 少样本分类方法的有效性并寻找最优的ICAM 预训练任务参数配置,在MiniImagenet 数据集上进行了不同少样本任务配置的实验,结果如表5 所示。 表5 ICAFSC 在MiniImagenet 数据集上不同少样本任务配置的实验结果Tab.5 Experimental results for ICAFSC under different classification task configurations in pre-training phase on MiniImagenet 表5 分别展示了5-way 1-shot 和5-way 5-shot两种少样本分类问题的实验结果。为与少样本分类问题的类别数量匹配,表中3 组预训练任务参数配置的类别数量均设置为5 的整数倍。从5-way 5-shot 的实验结果可以看出,不同参数配置的ICAFSC 的分类准确率均高于ProtoNet。当预训练类别数量设置为5 时,ICAFSC 的准确率比ProtoNet 高出1.15%。5-way 1-shot 的实验结果也表现出类似的结果,即类内-类间通道注意力模块可以提高少样本分类的准确率。这说明类内-类间通道注意力模块能够改善特征提取器以获得鉴别性特征,提升少样本分类模型的分类准确率。从不同参数配置的ICAFSC 的实验结果可以看出,随着预训练类别数量的增大,模型的分类准确率在逐渐下降。相比于way=5,way=20 的ICAFSC 的分类准确率在1-shot 和5-shot 条件下分别下降了1.58%和0.64%。这说明预训练的类别数量与元测试的类别数量保持一致时,ICAFSC 的表现最优,其原因在于全连接网络的输入神经元不可更改,当预训练的类别数量与元测试的类别数量不一致时,通道距离的拆分与复制会破坏通道距离的完整性。 3.3.3 对比实验 为了更加客观地评价所提出方法的有效性,本文在MiniImagenet 数据集上开展对比实验。表6 对比了不同方法在MiniImagenet 数据集上5-way 5-shot 和5-way 1-shot 的实验结果。文献[8]为ICAFSC 的基线模型,是一种基于度量学习的元学习方法,并采用欧氏距离作为距离函数。文献[16]是一种与模型无关的元学习方法,采用参数优化的方式寻找泛化性最好的模型参数。文献[17]在基于度量学习的元学习方法中引入注意力机制,来刻画图像之间的特征关系和位置关系。文献[18]是文献[16]的改进方法,在外部循环更新元初始化参数时冻结分类器,只在内部循环时更新分类器。文献[19]使用变分自编码器建立以跨类样本对为条件的多模态权重分布,并利用该权重为每个分类任务生成一个判别性指标。文献[20]提出使用自监督学习训练一个广义的嵌入网络,该网络通过从数据本身学习为新分类任务来提供稳定的原型表示。 表6 在MiniImagenet 数据集上不同方法的分类得分(主干网络为Conv4-64)Tab.6 Classification scores of different methods with Conv4-64 as backbone on MiniImagenet dataset 从表6 可以看出,ICAFSC 在1-shot 和5-shot条件下的分类准确率分别为51.55% 和69.11%。与文献[8]的ProtoNet 基线模型相比,ICAFSC 在1-shot 条件下提高了1.93%,在5-shot 条件下提高了1.15%。这表明类内-类间通道注意力模块有助于提高模型的少样本分类能力。与文献[16]相比,ICAFSC 在1-shot 条件下提高了3.48%,在5-shot 条件下提高了5.96%。与文献[17]相比,ICAFSC 在1-shot 条件下提高了2.01%,在5-shot 条件下提高了0.77%。与文献[21]相比,ICAFSC 在1-shot 条件下提高了0.35%,在5-shot 条件下提高了0.31%。文献[22]在基线网络上增加变分自编码器、权重生成器和注意力度量网络,利用高复杂度的网络产生复杂数据分布来提高样本多样性。与文献[19]相比,ICAFSC 在5-shot 条件下分类准确率仅低了0.20%,表明增加的ICAM 对特征鉴别性的提升与复杂网络的作用相当,并且ICAM 可以作为一个即插即用模块,嵌入特征提取网络和分类器之间。ICAFSC 在1-shot 条件下低了2.35%,这种现象是因为本文提出的ICAM 在1-shot 条件下无法计算类内通道信息造成的。与文献[20]相比,ICAFSC 在1-shot 条件下提高了0.70%,在5-shot 条件下提高了1.03%。与文献[24]相比,ICAFSC 在1-shot 条件下的准确率降低了0.87%,在5-shot 条件下提高了0.33%。以上实验结果表明,ICAM 通过类内-类间距离度量计算通道权重实现特征加权,提高了特征对类别的鉴别能力以及模型的少样本分类能力。在5-shot条件下,ICAFSC能够取得最高的分类准确率,在1-shot条件下的分类准确率优于当前大多数的方法。 本文设计了类内-类间通道注意力模块,并将它嵌入原型网络中构建了类内-类间通道注意力少样本分类方法。该方法利用类内-类间通道注意力模块改善了特征提取器以获得鉴别性特征。其中,类内通道权重在强调类内相似信息的同时抑制了类内冗余信息;类间通道权重强调类间判别性信息,使嵌入空间的特征分布更好地表征类别。ICAFSC 在元训练之前增加一个预训练阶段,使类内-类间通道注意力模型能够充分学习类内通道权重和类间通道权重,提高了样本特征的鉴别能力。为了验证所提方法的有效性,在MiniImagenet 数据集上分别进行了1-shot 和5-shot的少样本分类实验。实验结果表明:ICAFSC少样本分类方法在1-shot 和5-shot 条件下分别取得了51.55%和69.11%的分类准确率。与原型网络相比,ICAFSC 的分类准确率在1-shot 条件下提高了1.93%,在5-shot条件下提高了1.15%。显著提升了少样本分类模型的分类性能。3 实 验
3.1 数据集与预处理
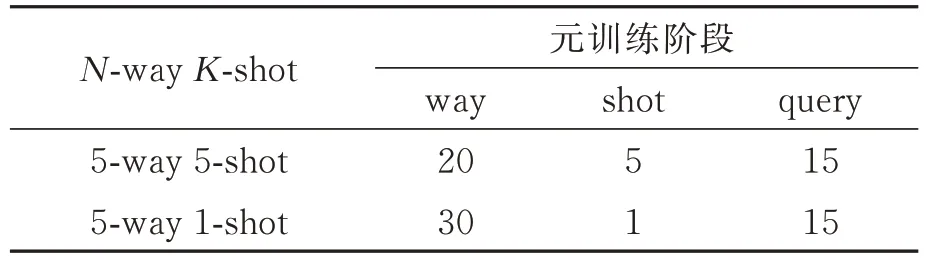
3.2 实验过程与参数设置

3.3 结果与分析


4 结 论
猜你喜欢
无线互联科技(2020年22期)2021-01-11 13:52:34
小资CHIC!ELEGANCE(2021年45期)2021-01-11 03:51:12
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
传感器与微系统(2018年7期)2018-08-29 00:44:42
英美文学研究论丛(2018年2期)2018-08-27 01:56:18
自动化学报(2017年4期)2017-06-15 20:28:55
剑南文学(2016年14期)2016-08-22 03:37:42
新校长(2016年8期)2016-01-10 06:43:59
人间(2015年20期)2016-01-04 12:47:08
商事法论集(2014年1期)2014-06-27 01:20:42
