
强化特征提取能力的下颌骨骨折检测3M-YOLOv5 网络
2023-12-02 12:48:04杜玉虎石道宗彭彩月陆惠玲
光学精密工程 2023年21期
周 涛, 杜玉虎, 石道宗, 彭彩月, 陆惠玲
(1. 北方民族大学 计算机科学与工程学院,宁夏 银川 750021;2. 北方民族大学 图像图形智能处理国家民委重点实验室,宁夏 银川 750021;3. 宁夏医科大学 医学信息与工程学院,宁夏 银川 750004)
1 引 言
下颌骨由于特殊的生理结构,位于颌面部较为突出的位置,存在明显的解剖结构薄弱区域,在受到外力撞击时极易骨折。准确及时地确定下颌骨的骨折部位能够给予医生充足的参考信息,根据不同的骨折部位采取合适的治疗手段,避免术后下颌功能障碍、咬合关系错乱等问题,影响患者的生活质量[1]。当骨折程度较为严重时,骨折区域会出现骨头嵌插、压缩等情况,造成局部的密度增高,下颌中容易发生骨折的部位是正中联合部、颏孔区、下颌角部位以及髁突颈部,不同的骨折部位表现出来的症状不相同,在CT影像中的表现也不尽相同。在下颌骨骨折CT 影像中,骨折部位的影像容易受到其余部位例如牙齿等部位的干扰,因为在CT 影像中牙齿部位与骨骼部位均为白影,表示它们对X 射线的吸收程度较高,而黑影表示对于X 射线吸收程度较低的肌肉部位[2]。通常情况下,下颌骨的骨折伴随着或多或少的出血,出血部位对于X 射线的吸收程度也较高。因此,由于出血情况以及其余部位的干扰,下颌骨骨折CT 影像的人工阅片难度较大,通过人工智能的方法来辅助医生进行下颌骨骨折部位的诊断具有重要的意义。
目前,人们开展了大量针对人体骨折部位检测的研究。Meng 等[3]提出了一种用于肋骨骨折检测和分类的异构神经网络,由级联特征金字塔网络和分类网络组成,用来辅助放射科医生在CT 图像上诊断和分类肋骨骨折。Zhou 等[4]基于跨模态数据(临床信息和CT 图像)进行肋骨骨折的自动检测和分类。应用基于快速区域的卷积神经网络(Fast Region Convolutional Neural Network, Faster R-CNN)整合CT 图像和临床信息并使用结果合并技术将2D 推断转换为3D 损伤结果。Xue 等[5]采用GA_Faster R-CNN 进行手部骨折的检测与定位,提出新的引导锚定方法使锚框生成更加准确和高效,大大提高了网络性能,并节约了计算量,同时采用平衡L1 损失来适应学习任务的不平衡。Kitamura 等[6]通过小样本、从头训练和多视图合并集成的卷积神经网络来检测踝关节骨折。Gao 等[7]提出一种使用对侧、上下文和边缘增强模块的肋骨骨折诊断深度学习方法CCE-Net,使用多径融合机制作为主要架构来集成对侧、上下文和边缘增强模块所获得的特征信息。Liu 等[8]采用Faster-RCNN 辅助诊断股骨转子间骨折,同时对比了骨科主治医师与人工智能的相关检测准确率、召回率等,指出人工智能诊断算法是一种有效的临床诊断方法,可作为骨科医师满意的临床助手。武等[9]基于胸部X 光影像采用YOLOv3 网络进行肋骨骨折的检测,证明了CNN 可以提高肋骨骨折的检出率,有助于减少漏诊,避免医疗事故,减轻放射科医生的工作量。Warin 等[10]采用Faster RCNN 和YOLOv5 来检测下颌骨骨折的X 光影像,同时对比了这两种网络与口腔颌面外科医生在下颌骨骨折判断方面的准确率,检测网络实现了较好的下颌骨骨折分类性能。Wang 等采用U-Net 和ResNet 进行骨折CT 影像的分类,首先利用U-Net 对CT 影像中的具体下颌骨部位进行分割,然后采用ResNet 对分割后的部位进行具体分类,利用分类后的结果辅助医生对下颌骨骨折的诊断[11]。Vinayahalingam 等利用Faster R-CNN 和Swin-Transformer 网络对下颌骨部位口腔全景X 光进行骨折部位的检测,利用Swin-Transformer 作为主干特征提取网络,检测头部分仍采用Faster R-CNN 的检测头,利用Transformer 的自注意力机制进行较好的特征提取[12]。Son 等在口腔全景X 光上利用YOLOv4 网络进行下颌骨骨折的检测,对输入到网络中的CT 影像进行单尺度亮度自适应变换和多尺度亮度自适应变换以增强图像的对比度[13]。
上述研究表明,采用人工智能的方法辅助骨折部位的检测具有较好的应用前景,能够给予医生充分的治疗参考信息。现有研究采用的检测网络多为通用网络结构,未针对于具体数据集进行特征提取网络的设计,对于骨折部位的关注程度不够充分。由于骨折部位大小不一、形状各异,同时受到出血以及其他未骨折部位的影响,当前相关骨折检测方法在进行影像特征提取时未考虑影像的全局特征表示,未提取相应的多尺度信息,不同尺度的特征图在进行特征融合时无法权衡其重要程度,特征图的通道维度、高度和宽度这三者之间未进行交互,缺乏必要信息的融合,存在检测精度不高的问题。
本文提出了一种下颌骨骨折检测网络3MYOLOv5,特征提取网络中采用密集模块进行改进,引入密集连接思想,利用密集连接神经网络的特性增强网络的特征提取能力;在特征提取网络的开始阶段采用局部全局注意力模块(local and global attention Module, lgaM)来提取下颌骨CT 影像的局部全局特征;在密集块结构中引入轻量化多尺度的思想,更好地提取CT 影像的多尺度特征,关注到不同大小的骨折区域;设计了跨维度双向融合模块(cross dimension bidirectional fusion Module, cdbfM),利用跨维度注意力使得网络能够关注特征图的高、宽以及通道之间的相互关系,使得不同体位的CT 影像特征互补,提升网络性能。
2 原 理
在提取CT 影像特征时,通常利用卷积操作捕获局部信息,但是随着网络层数的加深,浅层网络的特征无法传递到深层网络中,导致深层网络无法获得边缘、形状和纹理等信息。密集连接神经网络通过构建当前层和后续其他层的密集连接,将浅层网络所提取的特征传递到深层网络中,能够实现信息的跨层传递[14]。因此,本文采用密集连接神经网络作为主要的特征提取网络,基于YOLOv5_s 网络提出了一种下颌骨骨折检测网络3M-YOLOv5,其详细结构如图1 所示。3M-YOLOv5 网络主要包括特征提取网络、cdbfM 模块以及YOLO 检测头部分。特征提取网络主要包括Stage 0 到Stage 3 等4 个阶段,其中Stage 0 为预处理阶段,提取CT 影像的局部全局特征,Stage 1 到Stage 3 为重复堆叠的密集模块,分别重复堆叠6,12,24 次。每个Stage 的密集模块之后通过池化操作对特征图进行下采样,3 种不同尺度的特征图由此引出到cdbfM 中进行特征增强。cdbfM 包括跨维度注意力模块(Cross Dimension Attention Module,CDA)以及双向特征融合模块(Bidirectional Feature Fusion Module, BFF)。特征增强后的特征图输入到YOLO 检测头部分进行骨折部位的检测,3 个检测头从上至下分别负责检测较大的骨折区域、中等大小的骨折区域以及较小的骨折区域。
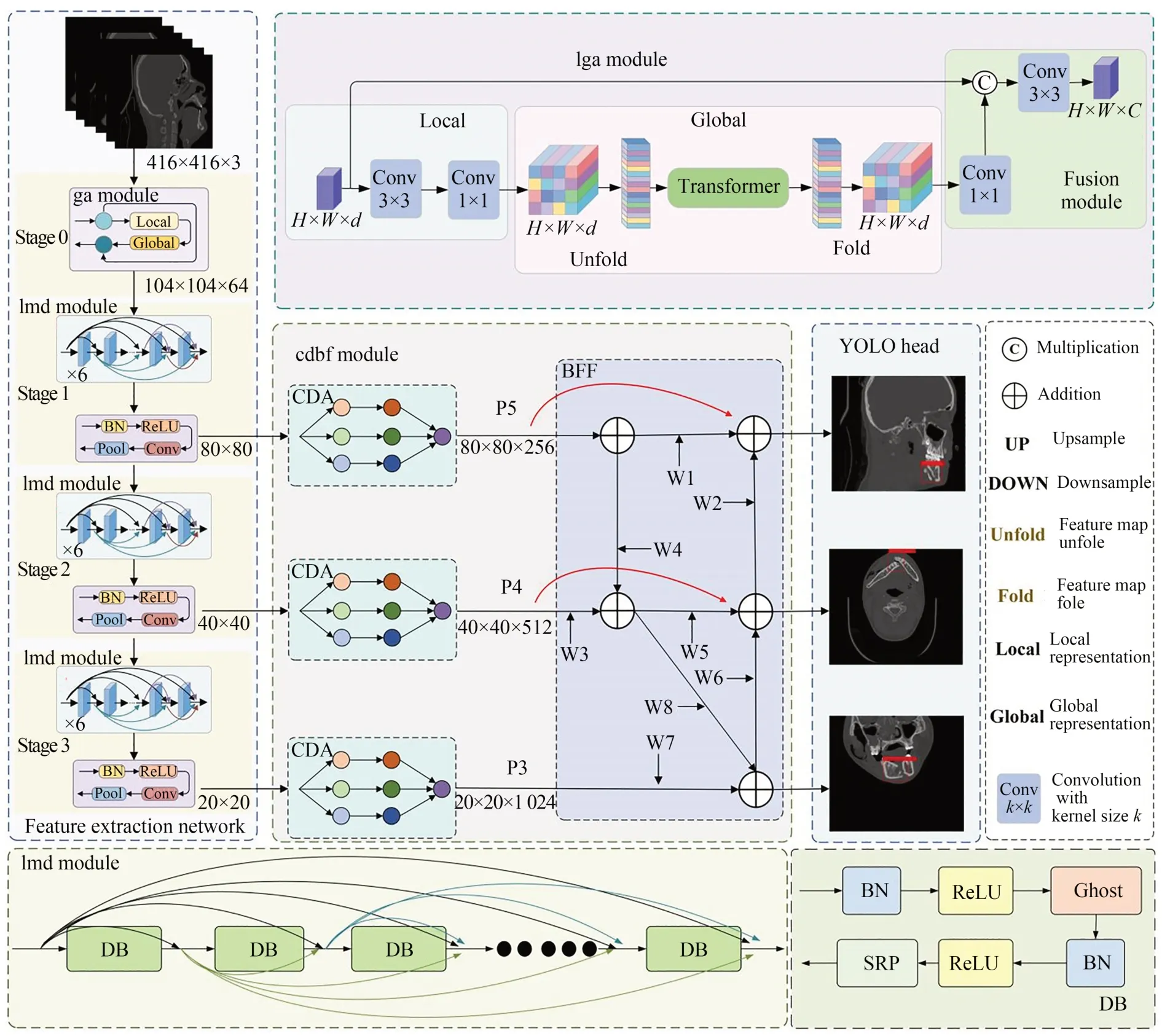
图1 3M-YOLOv5 网络结构Fig.1 Structure of 3M-YOLOv5 network
2.1 特征提取网络
特征提取网络在Densenet121 网络的基础上进行改进。Densenet121 网络中有4 个重复堆叠的密集块结构以及3 个过渡层结构,原始网络中密集块的堆叠次数分别为6,12,24 和16 次,考虑到YOLOv5 网络在3 个不同尺度的特征图上进行目标检测,在网络结构设计时保留了Densenet121 网络的前3 个密集块以及过渡层结构作为特征提取网络。过渡层通过池化操作对特征图进行下采样,分别在3 个过渡层结构中引出不同尺度的特征图进行特征增强。输入的CT影像首先经过lgaM 获得全局信息,然后输入到重复堆叠的密集块结构中进行特征提取,最后在3 个过渡层结构中分别输出尺寸为80×80,40×40 和20×20 的特征图,并输入到特征增强网络中进行特征增强。
2.1.1 局部全局注意力模块
在进行骨折部位检测时,全局信息很重要。骨折部位约占整个CT 影像的三分之一,下颌骨的骨折部位在CT 影像中的位置信息可以通过提取全局特征来获得,通过局部全局信息的相结合提高网络的表征能力。利用Transformer 结构可以获得影像的全局特征,在先前的Transformer应用中,采用Self-Attention 来计算当前像素值与其他所有像素值的相关性,这种操作的计算量以及参数量较大,而在图像特征提取时,相邻像素间的差距并不是很大,像素所代表的信息相似[15]。因此,本文在特征提取网络的第一个阶段引入lgaM,其结构如图1 所示,通过在每一个patch 内计算Self-Attention 来减少参数量,通过卷积操作和Transformer 结构增强网络的特征提取能力,获得骨折部位的全局信息。lgaM 主要包括局部表示模块、全局表示模块以及融合模块3部分。首先,使用一个卷积核尺寸为3×3 的卷积层来提取CT 影像的局部特征,然后通过一个卷积核尺寸为1×1 的卷积层调整通道数。接着,通过全局表示模块来提取全局特征,全局表示模块包括Unfold,Transformer 和Fold 3 部分,然后再通过一个卷积核尺寸为1×1 的卷积层调整通道数。最后,通过残差连接将全局建模后的特征图与最初输入的特征图在通道方向上进行拼接操作,拼接后的特征图通过一个卷积核尺寸为3×3的卷积层做特征融合得到输出。Unfold,Transformer 和Fold 这3 部分是lgaM 的关键部分。假设输入全局表示模块的特征图尺寸为H×W×d,首先将特征图进行patch 划分,每个patch 的H和W都为2。
如图2 所示,Unfold 操作按照每个patch 中相对位置相同的像素进行展开,展开后的特征图通过Transformer 部分进行自注意力计算,在每一个片状特征图内分别计算自注意力,这种操作能够极大地减少参数量。Fold 操作在自注意力计算完成之后将特征图按照相对位置“折叠”回原来的形状。自注意力的计算公式为:
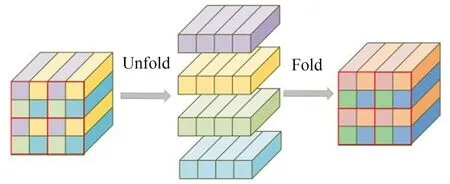
图2 Unfold 以及Fold 操作Fig.2 Unfold and Fold operations
假设有输入特征图矩阵a,将节点分别经过可训练的共享矩阵Wq,Wk,Wv变换后得到对应的Q,K,V。Q,K,V矩阵为:
将矩阵Q,K中的值进行点乘操作获得两者的相关性,点乘结果越大,矩阵V的值越大。点乘后的结果除以后经过Softmax 函数处理,其中dk为向量k的维度,处理后的结果与V进行矩阵相乘即得到自注意力机制的计算值。
2.1.2 轻量化多尺度密集模块
在基本的密集块结构中,网络的浅层特征通过跳跃连接向深层网络传递特征,这种特征传递的机制能够将浅层的特征图信息传递到深层网络中,有效地防止梯度消失,使得深层网络也能够获得较强的纹理、边缘等信息。密集块结构中通过堆叠多个卷积层来进行特征提取,在多次重复堆叠密集块结构后,网络的参数量大增,导致整体网络的参数量以及训练时间增大。在进行特征提取时,普通卷积操作获得的特征图信息存在较多的冗余,所包含的信息差别较小,对于骨折部位的检测贡献较小,这些差异较小的特征图并不需要通过卷积操作来获取,可以通过简单的线性操作来代替,从而减小网络的计算量[16]。因此,考虑采用Ghost 卷积模块来替换原始密集块结构中的1×1 普通卷积,该模块在减少网络参数量的同时能够获得相同数量的特征图,降低了网络的复杂度。
Ghost 卷积模块是一种轻量化的卷积操作,是GhostNet 的主要部分,它可以以较少的参数量来生成同样通道数量的特征图。如图3 所示,Ghost 卷积模块的操作主要分为两步:第一步使用普通的卷积操作压缩特征图的通道数,通过普通卷积调整输入特征图的通道数,这里设置该操作的卷积核个数为输入通道数的一半,此时由于通道数的减少,模块的计算量也随之减少,将输入特征图进行信息整合;第二步,对通道数压缩后的特征图进行逐通道方向的卷积操作,该操作与深度可分离卷积中的第一步操作相同,通过f1~fn操作分别对第一步所得到的特征图做逐通道卷积;最后,将第一步与第二步操作得到的特征图在通道方向进行拼接,得到最终处理的特征图。

图3 Ghost 卷积模块Fig.3 Ghost convolution module
同样生成N个特征图,假设输入特征图通道数为C,普通卷积的卷积核尺寸为K,Ghost 卷积中第一次卷积生成的特征图个数为M,第二次逐通道卷积生成S个特征图,D为逐通道卷积的卷积核尺寸,最终输出N=M×S个特征图。则普通卷积的参数量为:
Ghost 卷积第一次卷积的参数量为:
第二次逐通道卷积的参数量为:
两者的参数比为:
由此可见,使用Ghost 卷积的参数量约为普通卷积的1/S。在密集块结构中引入Ghost 卷积来替换原始的1×1 普通卷积,能够在减少参数量的同时获得数量不变的特征图。为了便于将模块引入到密集块结构中,第一步普通卷积操作中卷积核的个数以及第二步逐通道卷积操作中卷积核的个数均设为输入特征图通道数的一半。通过控制卷积核的个数确保输入输出特征图的尺寸不变,可以将Ghost 模块直接引入到密集块结构中。
本文采用的数据集中有3 种不同体位的下颌骨CT 影像,分别是冠状位、矢状位和轴状位。不同体位甚至是同一体位的骨折部位影像尺寸不同,采用同样尺寸的卷积核进行特征提取时获得的局部特征感受野有限,而在进行特征提取时关注多尺度特征有助于网络性能的提升。故考虑在密集块中利用结构重参数化模块(Structure Reparameterization Module, SRP)进行改进,如图4 所示。该模块在训练时使用3 条不同的分支对图像进行特征提取,在推理时通过结构重参数化操作将3 条分支合并为一条分支。训练时,第一条分支为卷积核尺寸为1×1 的卷积操作以及批量归一化(Batch Normalization,BN),第二条分支为卷积核尺寸为3×3 的卷积操作以及BN,第三条分支的特征图不经过卷积只有BN 操作,将三条分支所获得的特征图进行相加,相加后的特征图再经过挤压激励模块(Squeeze and Excitation Module,SE Module)进行进一步精炼。SE模块首先通过自适应池化操作将特征图压缩成高宽为1 的长条状,再通过两个全连接层获得注意力信息,将注意力信息与原始特征图相乘使网络关注更有意义的特征,最后将特征图经过Si-LU 激活函数的处理,得到最终的特征图。SiLU激活函数在数值为负值时并不是直接将数值置零,而是采用极小值来代替,这种操作避免了网络中的神经元为负值时无法收敛的情况。1×1和3×3 的卷积操作分别提取不同尺度的特征,关注不同尺寸局部区域的下颌骨影像特征。两条分支通过采用不同尺寸的卷积核来提取不同尺度的特征,将不同尺度的特征图进行相加操作,能够融合具有不同尺寸感受野的卷积层所提取的下颌骨CT 影像特征。

图4 结构重参数化模块Fig.4 Structure reparameterization module
2.2 跨维度双向融合模块
2.2.1 跨维度注意力模块
在特征提取完成后,会输出3 种不同尺度的特征图,尺寸分别为20×20×1 024,40×40×512,80×80×256,将这3 种不同尺度的特征图输入到特征增强网络中进行处理。此时获得的特征图高度、宽度以及通道之间没有信息的交互,而不同通道提取的信息有着位置、形状等的相关性,特征图的通道和高度以及通道和宽度之间也有着相应的联系,对于下颌骨骨折部位的判断至关重要。本文数据集中包含冠状位、轴状位和矢状位3 个体位的CT 影像,不同体位所蕴含的信息也不相同,通过跨维度的特征融合使得3 个体位的信息有所交互。因此,在输入到特征增强网络中之前,采用跨维度注意力模块,使得特征图的高度和通道之间、宽度和通道之间的信息有所交互,如图5 所示。同时,本文数据集中采用的3 个体位的影像也能够补充信息,利用三分支结构捕获跨维度交互来计算注意力权重,通过旋转操作和残差变换建立维度、影像间的依存关系[17]。
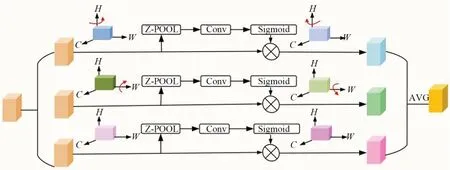
图5 跨维度注意力模块Fig.5 Cross dimension attention module
跨维度注意力模块共有3 个相互平行的分支,第一条分支负责关注特征图的通道维度C和空间维度W的相互关系,第二条分支负责关注特征图的通道维度C和空间维度H的相互关系,第三条分支负责捕获特征图的高度H和宽度W之间的依赖关系。具体实现过程如下:
第一条分支首先将输入的特征图沿着高度方向逆时针旋转90°得到形状为W×H×C的特征图,然后通过Z-POOL,Conv 以及Sigmoid 激活函数得到注意力权重值,Z-POOL 操作对输入的特征图进行平均池化和最大池化,减小特征图的尺寸,同时提取有意义的特征。最后,将注意力权重值与原始特征图相乘,此时得到的特征图再沿着高度方向顺时针旋转90°恢复到和输入特征图一致的形状;第二条分支与第一条分支的操作类似,负责计算通道维度C和空间维度W的注意力权重,特征图的旋转方式是沿着宽度方向W逆时针旋转90°,此时特征图形状变为H×C×W,在高度方向进行Z-POOL 操作,将特征图的高度缩减为2,再经过Conv 以及Sigmoid 激活函数得到注意力权重值,将权重值与原始特征图相乘,最后再顺时针旋转90°恢复到原来的形状;第三条分支不经过旋转操作,只通过Z-POOL,Conv 以及Sigmoid 激活函数得到注意力权重值,再将注意力权重值与原始特征图相乘得到处理后的特征图。最后,对3 个分支获得的特征图进行相加操作以及取平均值操作。
2.2.2 双向特征融合模块
在网络训练过程中,输入到其中的骨折CT影像中骨折部位的尺寸不一,在进行卷积以及下采样操作时,随着网络的加深,较大的骨折区域得以保留,而较小的骨折区域可能丢失,因此需要进行特征增强,将不同分辨率的特征图进行融合。深层网络的特征包含抽象的语义信息,但是缺乏空间信息;浅层网络的特征包括边缘、轮廓及形状等影像的原始信息,但是缺乏语义信息,通过将深层特征与浅层特征进行融合,将纹理信息与语义信息融合在一块,能够获得更具表征性的特征图信息[18]。
在原始YOLOv5 网络的特征增强网络中,采用特征金字塔网络(Feature Pyramid Network,FPN)上下采样拼接的形式来进行特征融合,将小尺寸的特征图进行上采样与大尺寸的特征图相加,将大尺寸的特征图进行下采样与小尺寸的特征图相加,通过上下采样以及相加操作使得不同分辨率、不同尺寸的特征图有所交互,将网络深层的语义信息传递到浅层特征图中,同时将浅层网络所提取的纹理、边缘和位置等信息传递到深层网络,从而融合不同分辨率的特征图,但是融合时每个特征图的重要程度无法确定。对不同分辨率的特征图进行简单的相加融合操作会导致不同尺寸、不同分辨率的特征图对于融合后特征增强的特征图贡献相同,尺寸较大的特征图所占比重较大,而网络深层语义信息丰富的小尺寸特征图所占的比重较小。
如图1 所示,跨维度双向融合模块在每个上采样以及下采样的分支中引入可训练的权重值来平衡不同尺度特征图融合时的重要程度,同时增加了跨尺度的特征拼接操作,将原始的特征图与特征增强处理后的特征图进行相加操作,类似于残差网络的结构,这种结构能够增强网络的表征能力,对不同尺度的特征图进行区分。
如图6 所示,原始融合模块中有5 个输出,其中尺寸较大的P6,P7特征图是由特征图P5进行上采样得到的,P6,P7特征图结合了尺寸较小的特征图作为输出。YOLOv5 网络中的特征提取网络输出3 种类型的特征图,3 种不同尺寸的特征图已经能够较好地满足下颌骨骨折检测的需求,因此,本文只采用尺寸较小的3 个特征图作为检测特征图。特征图P3未进行下采样操作,仅通过横向连接与特征图P4下采样后的特征图进行拼接,只有单个输出边,故省略横向的残差连接以减少参数量。输出特征图的计算公式为:
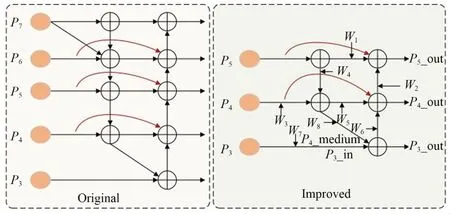
图6 双向特征融合模块Fig.6 Bidirectional feature fusion module
其中:Wi为可训练的权重值,Ii为输入特征图,ε为一个极小值,防止分母为0。图6 中,P3_out 为:
由于P4_medium 特征图与P3特征图的尺寸不同,因此需要对它进行下采样操作,Resize 代表对特征图进行上采样或者下采样操作。式(7)中分子为将所有要进行特征融合操作的输入特征图与可训练权重逐个相乘,分母为所有的权重值与极小值ε相加。通过引入可训练权重来控制不同尺度特征图融合时的比重,从而控制不同分辨率的特征图对最终骨折部位检测的贡献值。
3 实验与结果分析
3.1 下颌骨骨折数据集
实验采用的数据集为下颌骨骨折CT 影像数据集。从宁夏某三甲医院颌面外科处获得下颌骨部位影像的原始图像5 861 张,由专业医师对下颌骨骨折部位进行标注,使用开源Labelimg 软件标出下颌骨的骨折部位。标签文件为.xml 格式,在本数据集中只有骨折这一种类型,其标注名称为fractured。标签文件中还包括真实框的高度、宽度、图像的原始尺寸,以及真实框的坐标等信息。训练集以及验证集按照9∶1 的比例进行划分,得到训练集影像4 746 张,验证集影像528 张。如图7 所示,数据集包含3 个体位的CT 影像,分别为冠状位、矢状位和轴状位影像。每个体位的CT 影像选取3 张,3 个体位共计9 张CT 影像。冠状位CT 是指从患者的正前方面向患者进行CT 影像的拍摄,此时获得的CT 影像成为冠状位CT 影像;矢状位CT 是指从患者身体的右侧对患者进行CT 影像的拍摄,此时获得的CT 影像成为矢状位CT 影像;轴状位CT 是指从患者头顶正上方对患者进行CT 影像的拍摄,此时获得的CT 影像成为轴状位CT 影像。通过在不同的体位拍摄CT 影像,结合不同角度的影像来判断骨折部位,能够获得更充分的信息。
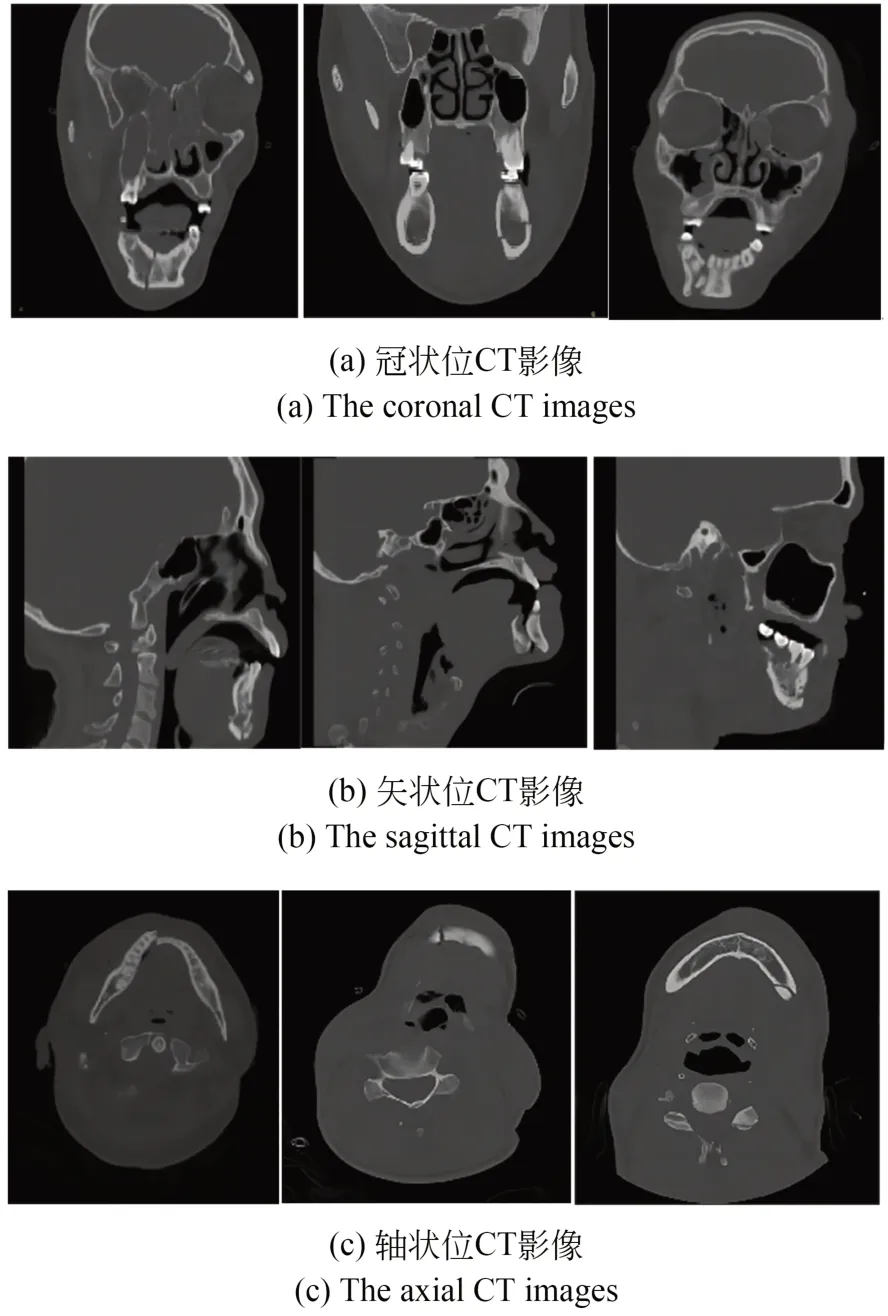
图7 下颌骨CT 影像数据集Fig.7 Mandibular CT image dataset
3.2 实验环境与评价指标
3.2.1 实验环境
实验中,服务器操作系统为Windows 10 专业版64 位系统,计算机内存为64 GB,搭载Intel Gold 5218 2.3GHz 处理器,显卡为Titan RTX 24GB,cuda 版本为11.4。优化器采用Adam 优化器,动量设置为0.9,学习率设置为0.001,权重衰退值为0.000 1。对每一个网络进行epoch=100 的迭代,最终选择准确率最高的网络权重进行比较。
3.2.2 评价指标
为了验证网络的有效性,在实验中对比了置信度阈值为0.5 时网络的F1 值、召回率、精确率、mAP 值等指标。精确率(P)、召回率(R)和F1 值的计算公式分别为:
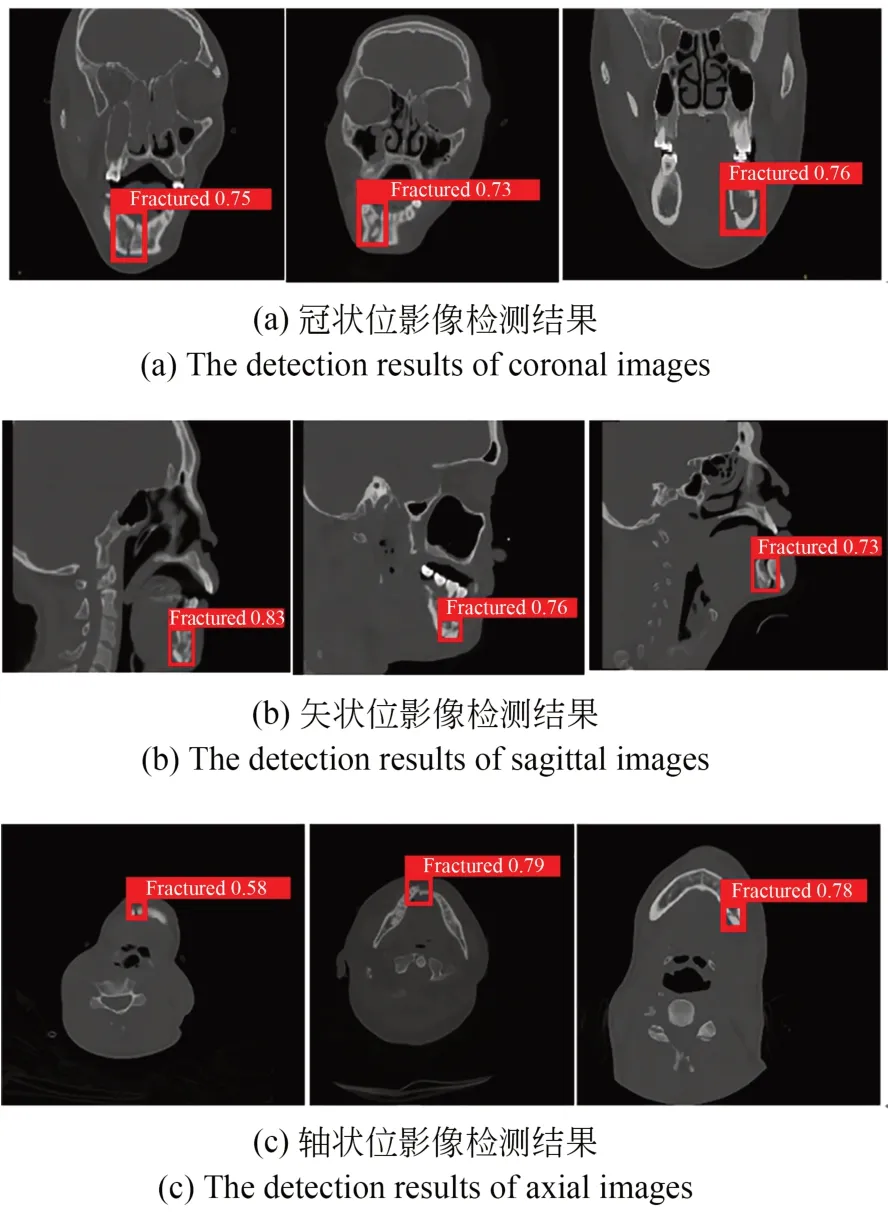
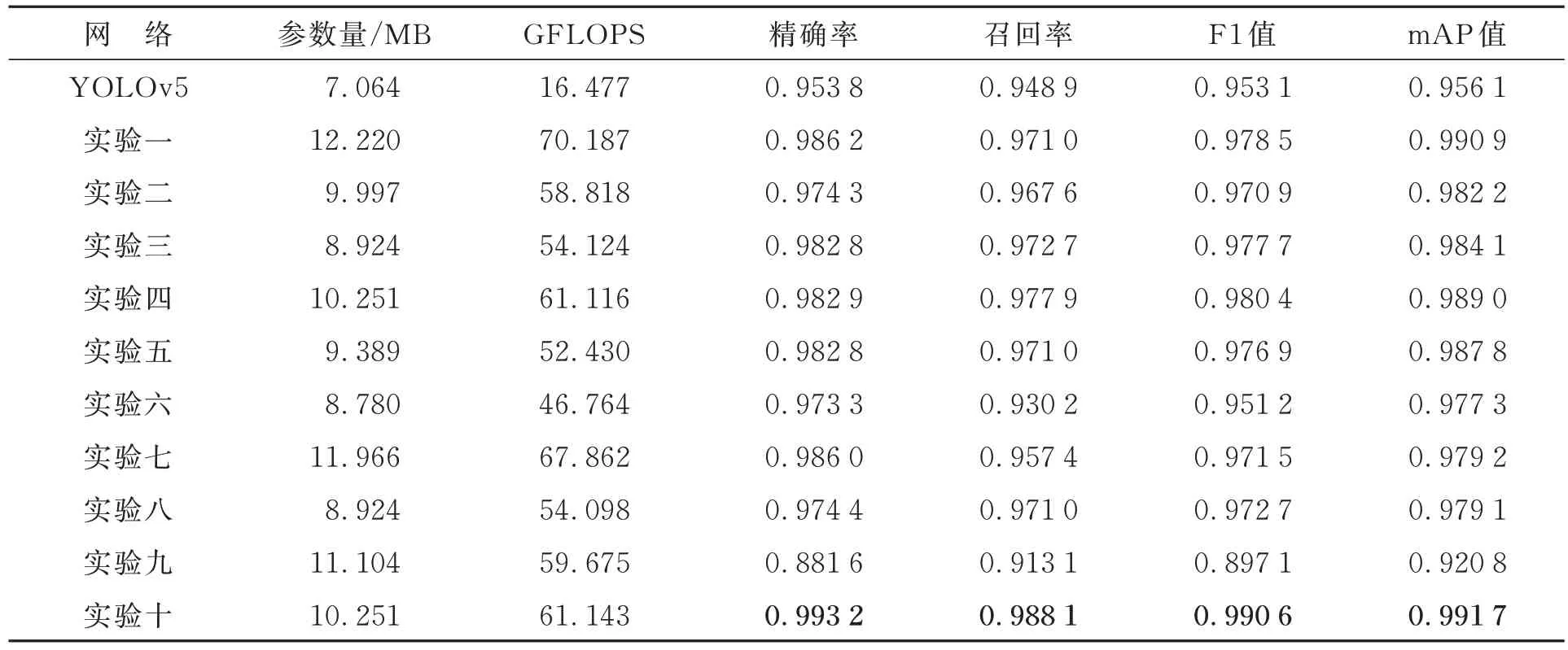
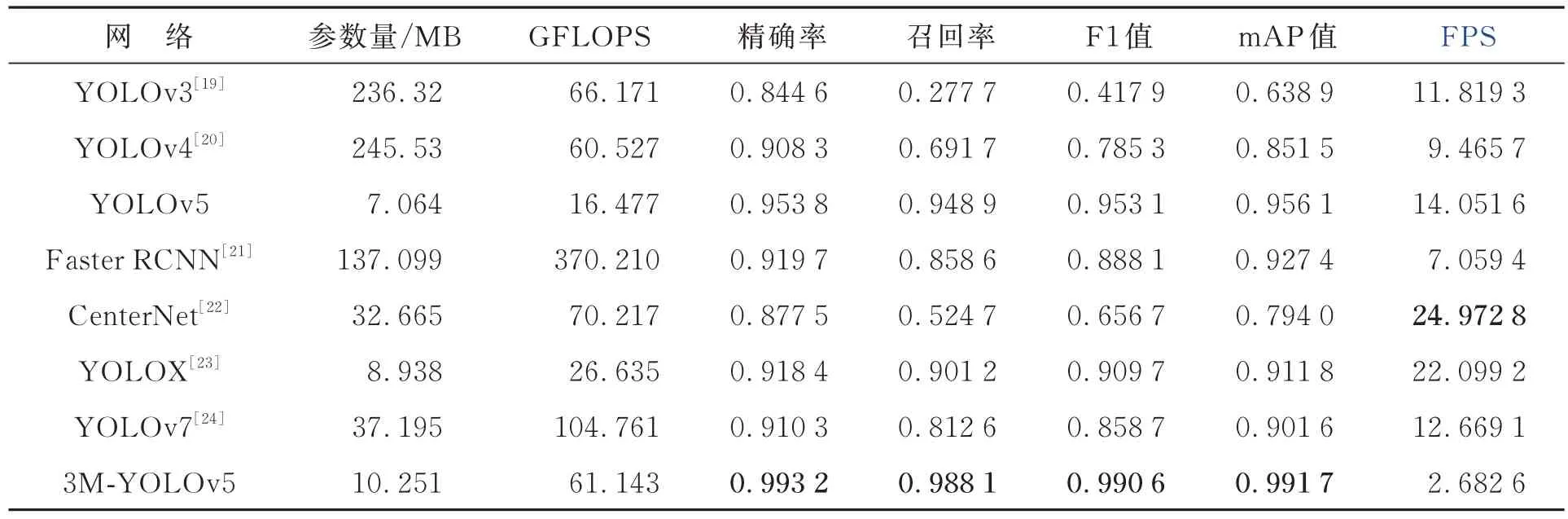
其中:TP 表示在真实正样本中被预测为正样本的样本数量,FP 表示在真实负样本中被预测为正样本的样本数量,FN 表示在真实正样本中被预测为负样本的样本数量。在置信阈值为0.5时,对评价指标进行了比较。当预测框与真实框的交并比(Intersection over Union,IoU)大于0.5时,该部分为骨折部分,计算该样本为TP 真阳性样本。当0 mAP 表示所有类别AP 值的平均值,一般情况下,评价时置信度阈值取0.5 时所有类别的平均AP 值来计算mAP。本文数据集中只有下颌骨骨折一种类型,因此mAP 等于AP,其计算公式为: 为了直观地考察不同网络的性能,本文还根据相关实验数据绘制了雷达图,对不同网络的F1值、召回率、精确率和mAP 值进行了可视化。雷达图中,中心区域的数值为零,从中心向四周辐射,数值逐渐增大,数值越大代表网络的各项评价指标越高,网络性能越好,不同颜色的折线分别代表了不同网络。在对比实验部分,给出了不同网络的FPS(Frame Per Second),即每秒所处理的帧数。FPS 是目标检测算法中另一个重要评估指标,数值越大,表明网络的检测速度越快。在评估网络的整体性能时,要综合考虑网络的F1值、召回率、精确率、mAP 值以及FPS 做出全面的评估。 图8 是下颌骨骨折CT 影像,分别为冠状位影像、矢状位影像和轴状位影像的检测结果。在影像中使用矩形框将骨折部位框出,并且在矩形框的上方给出了“fractured”字样,同时给出了该矩形框部位为骨折的置信度值。 图8 下颌骨骨折CT 影像检测结果Fig.8 Detection results of mandibular fracture CT images 3.3.1 消融实验 3M-YOLOv5 结构基于YOLOv5 网络进行改进,设计了3 个模块改进网络性能,分别是lga模块、lmd 模块以及cdbf 模块。lmd 模块包括Ghost 卷积模块以及SRP 模块,cdbf 模块包括CDA 模块以及BFF 模块。在消融实验中,通过分别引入不同的模块来验证其有效性。实验一采用lgaM 模块、SRP 模块、CDA 模块和BFF 模块对网络进行改进,去掉lmdM 模块中的Ghost卷积模块,使用基本的1×1 卷积操作进行特征提取;实验二采用lgaM 模块、Ghost 卷积模块、CDA模块和BFF 模块对网络进行改进,去掉lmdM 模块中的SRP 模块,使用基本的3×3 卷积操作进行特征提取;实验三采用lgaM 模块、Ghost 卷积模块、SRP 模块和CDA 模块对网络进行改进,去掉BFF 模块,使用原始网络中的FPN 网络进行特征增强;实验四使用lgaM 模块、Ghost 卷积模块、SRP 模块和BFF 模块进行网络改进,去掉CDA 模块;实验五使用Ghost 卷积模块、SRP 模块、CDA 模块和BFF 模块对网络进行改进,去掉网络开始阶段的lgaM 模块;实验六去掉网络开始阶段的lgaM 模块和BFF 模块,只保留Ghost 卷积模块、SRP 模块和CDA 模块;实验七只保留lgaM 模块、CDA 模块和BFF 模块,去掉密集块结构中的Ghost 卷积模块和SRP 模块,采用基本的1×1 和3×3 卷积进行特征提取;实验八利用特征提取网络引入的lgaM 模块、Ghost卷积模块和SRP 模块对网络进行改进,去掉CDA 模块和BFF 模块;实验九只保留CDA 模块和BFF 模块,在骨干网络中使用原始的密集块结构进行特征提取;实验十引入所有模块来改进网络。 消融实验结果如表1 所示。实验一网络的mAP 值较引入所有模块时下降了0.08%,参数量较最终网络结构上升了1.969 MB,证明Ghost卷积模块相较于1×1 卷积能够减少参数量。各项评价指标也有所下降,证明在密集块结构中引入Ghost 卷积模块所带来的性能提升有限。Ghost 卷积模块虽然能够以较少的参数量来获得同样数量的特征图,但是由于其最终特征图中有一半的特征图没有经过处理,而是类似于残差结构直接与另一半特征图进行通道拼接,因此它所带来的性能提升有限。实验二网络的mAP 值较引入所有模块时下降了0.95%,置信度阈值取0.5 时,网络的F1 值、召回率、精确率分别下降1.97,2.05 以及1.89,证明了SRP 模块中的1×1以及3×3 卷积能够关注到不同尺寸的局部区域,同时在模块中引入的SiLU 激活函数能够较好地防止神经元在负值时的死亡,有利于网络的收敛。实验三网络的mAP 值较引入所有模块时下降了0.76%,证明了采用BFF 模块能够提升网络的性能,在进行不同分辨率特征图的融合拼接时能够较好地平衡不同特征图的融合权重,同时在特征提取网络中同时引入(1)、(2)、(3)、(4)这4 个模块能够增强网络的特征提取能力,较好地获取到不同大小骨折区域的特征以及骨折部位在整个下颌骨CT 影像中的全局信息。实验四网络的mAP 值下降了0.27%,证明引入CDA 模块能够关注特征图的高度、宽度和通道之间的关系,进一步提升网络性能,但是性能提升有限;实验五中去掉lgaM 模块后,置信度阈值取0.5 时网络的mAP 值、F1 值、召回率、精确率分别下降0.39%,1.37%,1.71%,1.04%,同时参数量与计算量也有所下降,lgaM 模块以较小的代价来提取全局特征信息,证明lgaM 模块能够在特征提取网络的开始阶段获得全局表征信息,同时Unfold 以及 Fold 操作能够减少计算注意力时的参数量。实验六网络的mAP 值下降较多,与原始YOLOv5 网络相比仅提升了2.12%,证明了在网络的最初始阶段引入lgaM 模块能够使网络更好地捕获全局特征信息,从而提升网络的特征提取能力,同时BFF 模块在进行特征增强时能够通过可训练的权重来决定不同分辨率的特征图融合的权重。实验七网络mAP 值仅提升了2.31%,同时网络的参数量也有所提升,证明了原始密集块结构中的卷积操作参数量较大,特征提取能力较好,但是将原始卷积操作分别替换为Ghost 卷积模块以及SRP 模块后,网络的特征提取能力能够进一步的提升。实验八网络的mAP 值提升了2.3%,证明采用BFF 模块能够平衡不同分辨率特征图融合时的权重,同时CDA 模块能够关注特征图的高度、宽度和通道之间的关系,进一步提升网络性能。实验九网络性能下降得最多,甚至远不如原始YOLOv5 网络,F1 值等各项评价指标也大幅下降,证明了仅采用两个模块来改进网络无法很好地进行下颌骨骨折部位的检测。实验十同时引入5 个模块,网络的各项指标最大,证明本文所提出的3M-YOLOv5 网络能够较好地进行下颌骨骨折部位的检测。图9 给出了消融实验的雷达图,通过该图可以看出,实验十的折线位于最外侧,各项性能最优。 表1 消融实验结果Tab.1 Result of ablation experiment 图9 消融实验雷达图Fig.9 Radar map of ablation experiment 3.3.2 对比实验 本文通过对比不同目标检测网络在下颌骨骨折检测方面的各项评价指标,验证了所提出的3M-YOLOv5 下颌骨骨折检测网络的有效性。在提出的下颌骨骨折CT 影像数据集上,采用3M-YOLOv5 网络与YOLOv3 网络、YOLOv4 网络、FasterRCNN、CenterNet、YOLOX网络以及YOLOv7 网络进行了检测。其中,YOLOX 选用YOLOX_s 版本进行对比;YOLOv7 网络有针对于边缘GPU、普通GPU 和云GPU 的3 种基本网络,分别命名为YOLOv7tiny、YOLOv7 和YOLOv7-W6,本文选取适用于普通GPU 版本的YOLOv7 网络。实验结果如表2 所示。 表2 不同实验结果对比Tab.2 Comparison of experiment results with different networks YOLOv3 网络采用Darknet-53 作为主干特征提取网络,网络结构中采用了卷积层进行特征的提取,通过采用步长为2 的卷积层来进行下采样操作,没有使用池化层,避免了池化操作所带来的特征信息丢失等问题[25]。但是由于其特征提取不够充分,仅通过两次上采样进行特征图拼接,未进行特征增强,高分辨率特征图与低分辨率特征图之间没有交互,缺少信息互补,因此整体效果并不理想。YOLOv4 网络是YOLO 系列网络中第一次采用小尺寸特征图上采样与大尺寸特征图下采样进行特征网络的增强,在特征提取网络中还引入了空间金字塔池化(Spatial Pyramid Pool,SPP)结构来提取不同尺度的特征,但是网络性能的提升效果有限。Faster RCNN 网络是常用的两阶段检测网络,它首先生成区域建议候选框,再对候选框进行分类。网络的检测效果较好,但是网络的参数量以及计算量数倍于其他YOLO 系列网络,极大增加了训练以及部署时的成本。CenterNet 是一种无锚框的检测网络,不依赖大量的锚框,其参数量以及计算量较少,但是由于它只在高语义信息的特征图上进行特征检测,未结合大尺寸、大分辨率的特征图,丢失了较多的细节信息,因此其检测效果较差。YOLOX 网络的参数量和YOLOv5 相差无几,计算量提升较多,模型结构更加复杂,同时图片每秒的检测速度也有所提升,但是对于骨折部位的特征提取不够充分,因此整体性能提升较少。YOLOv7 网络的性能与YOLOX 网络接近,但是由于二者都是通用检测网络,对于下颌骨骨折部位的特征提取不够充分,其性能甚至弱于YOLOv5网络。本文提出的3M-YOLOv5 在置信度阈值取0.5 时的mAP 值、F1 值、召回率和精确率分别为0.991 7,0.990 6,0.988 1,0.993 2,与其他网络相比,整体性能提升最多。3M-YOLOv5 网络的FPS 值在所有网络中最低,其检测速度最慢。但是考虑到在医学图像辅助诊断中,漏诊、误诊等现象是不被允许的,精度要求是第一位的,其次才会考虑检测速度。因此,综合考虑网络的整体性能,以牺牲速度来换取准确率,网络的整体表现还是可以接受的。图10 给出了对比实验的雷达图,通过该图可以看出,3M-YOLOv5 网络的mAP 值、F1 值、召回率和精确率折线均位于最外侧,各项性能最优。 图10 对比实验雷达图Fig.10 Radar map of comparison experiment 下颌骨骨折时需要根据不同的骨折部位采取不同的治疗手段,准确及时地定位骨折部位能够给予医生充足的治疗参考信息,当前相关检测网络存在特征提取不充分、检测精度不高等问题。本文提出了一种用于下颌骨骨折检测的3M-YOLOv5 网络,它基于YOLOv5 网络进行改进。首先,引入密集连接思想来改进特征提取网络,在3 个过渡层中分别引出3 种不同尺度的特征图输入到特征增强网络中;其次,在重复堆叠的密集块中引入Ghost 卷积模块以及结构重参数化模块,使得特征提取网络能够提取多尺度信息,从而增强网络的特征提取能力;然后,在跨维度双向融合模块中采用跨维度注意力来融合特征图的高度、宽度以及通道之间的信息;最后采用双向特征融合模块,在特征图进行上下采样的过程中加入可训练的权重,更好地平衡了不同尺度特征图融合时的重要程度。实验结果表明,改进后的3M-YOLOv5 网络的F1 值、召回率、精确率以及 mAP 值分别为 99.06%,98.81%,99.32%和99.17%。 针对单一类别即下颌骨骨折类型,改进后网络的mAP 值能够达到99%以上,表明YOLOv5网络在单一目标检测领域也能取得很好的效果。但是,本文未对下颌骨的骨折部位给出明确的分类,只检测出骨折部位。未来工作要对具体的下颌骨骨折部位给出明确的分类,例如具体到髁突、下颌体、下颌角等具体部位的骨折信息,同时可以进行下颌骨骨折CT 影像的实时分析,帮助医师在进行CT 影像拍摄时能够更快更好地找到下颌骨的骨折部位,从而选取更加有代表性的CT 影像供给主治医师进行治疗的参考。3.3 实验结果


4 结 论
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
昆明医科大学学报(2021年1期)2021-02-07 01:06:48
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
西南医科大学学报(2016年4期)2016-01-03 01:26:25
中国医疗美容(2015年1期)2015-07-12 10:06:52
中国医疗美容(2015年1期)2015-07-12 10:06:37
噪声与振动控制(2015年4期)2015-01-01 07:08:21
