
融合卷积块注意力模块和Siamese 神经网络的人脸识别算法
2023-12-02 12:48孟祥周李映君王桂从蒙天生
光学精密工程 2023年21期
孟祥周, 李映君, 王桂从, 蒙天生
(济南大学 机械工程学院,山东 济南 250022)
1 引 言
随着目标识别[1]以及计算机技术的发展,利用计算机进行生物特征识别训练成为当前的研究热点,并得到了快速发展。人脸识别作为生物特征识别技术的重要组成部分,相对于指纹识别、DNA 识别等其他识别技术具有可识别性强、误识率低等优点,还具有非接触性、自然性等特点,具有广阔的应用前景。目前,人脸识别技术[2-3]广泛应用于安防[4]、金融[5]和身份认证[6]等领域,为信息安全和公共安全提供了重要保障。人脸识别技术作为生物特征识别的一部分,其特点在于人脸作为人类的内在属性存在个体的差异性和稳定性,即每个个体的人脸特征都是独一无二的。因此,利用人脸识别的方式进行人脸特征的提取以及身份检验是一个十分有效的手段。
传统的人脸识别方法包括基于几何特征法[7]、基于特征脸[8]和基于模板匹配[9]等。这些方法通过对人脸浅层表面进行特征提取进而实现识别,但其特征提取能力较弱,只有在简单的环境中进行识别验证具有良好的效果,无法提取深层次的人脸特征,在出现光照、角度、表情变化等其他复杂环境情况时,识别精度及准确度会下降。近年来,随着深度学习的发展[10],基于卷积神经网络(Convolutional Neural Network, CNN)的人脸识别算法成为新的主流,利用神经网络进行训练可以使算法具备更强的表征学习能力,并且从大量的数据中学习到更多的特征信息,能够在不同光照、姿态和表情等因素下学习到人脸特征,因此对于不同场景下的人脸识别具有更强的稳定性。
在利用深度学习进行人脸识别训练时,主要通过隐藏层对图像特征进行提取与处理,自动学习到更复杂、更高级的图像特征,这些特征与传统方法所获取的特征相比具有更强的表达能力。Schroff 等[11]使用Facenet 模型来实现从人脸图像到欧几里得空间的映射,并利用分布方法训练模型,使用三元组损失来提高模型性能,但该方法采用的数据集不具备普遍性,难以反映真实情况下人脸的多样性和复杂性。薛继伟、孙宇锐等[12]提出了采用ArcFace 算法进行人脸识别的方法,并针对照片尺寸、人脸位置等方面不一致的情况进行相关研究,改善了人脸位置等造成的影响,但同时对图像要求较高,需要进行精确的预处理,并且对噪声数据敏感,局限性较大。在针对孪生神经网络[13]进行人脸识别方面,Mathi 等[14]提出利用孪生神经网络和MTCNN 算法结合的方式实现不同场景下的人脸识别,其准确率可以达到90%,但由于训练时采用自制的数据集,多以印度地区的人脸为主。Koch 等[15]提出利用孪生神经网络进行单次学习任务,通过使用全局仿射变换处理图像对来训练验证识别任务,并指出一次面部识别可以评估学习的特征在数据集和任务中的能力。Song 等[16]设计了一个基于局部二进制模式(Local Binary Pattern, LBP)和频率特征感知的孪生神经网络,利用LBP 算法来消除光照对图像的影响,适用于非限制条件下的小规模数据集的人脸识别,该算法在单一场景中的应用效果较好,但是不适合多场景的情况。
综上所述,基于深度学习的人脸识别训练多采用欧美人脸数据集,较少使用亚洲人脸数据集进行训练与测试。不同人种的人脸特征存在较大差异,这些面部特征差异对最终的训练结果会造成巨大的影响。为了针对亚洲人的人脸特征进行有效的训练与识别,本文采用中国科学院发布的CASIA-FaceV5 亚洲人脸数据集。为了解决当存在光照、表情、姿态等干扰时,人脸识别过程较为困难,识别精度低等问题,通过融合孪生神经网络与VGG-BN 网络结构,实现对样本的特征提取,加快模型的训练速度。针对特征提取能力有限、泛化能力较弱的情况,在VGG-BN 网络结构的基础上引入卷积块注意力模块(Convolutional Block Attention Module, CBAM),通过强调通道和空间信息的方式,增强对目标区域的注意力和对图像中细节信息的提取,并通过调整特征图中的权重信息,增强特征的稳定性和区分度,提高模型的性能。
2 网络模型结构
2.1 Siamese 神经网络
Siamese 神经网络又叫孪生神经网络,是一种用于比较相似度或距离的神经网络模型,由一对相同结构、共享权值w和偏置值b的网络模型组成。其具体工作方式是输入两张不同的样本图片,输出高维度空间表征,并比较两张输出特征的相似度。该网络最早由Bromley 等[17]在1993 年提出用于签名识别任务,验证原签名和现签名是否相同,但是受限于当时硬件技术的限制,计算成本高,无法获得广泛应用,因此在很长一段时间内的发展是停滞的。直到深度学习技术的诞生,计算机性能逐渐增强及神经网络快速发展,孪生神经网络在人脸识别、文本匹配和目标跟踪等领域得到了广泛的应用。
孪生神经网络突出的特点就是可以根据不同的使用场景选择使用权重共享或不共享的两个子网络,以及不同的距离度量和损失函数。该网络还可以进行小样本学习,适用于样本量较少的情况,具备较高的容错识别能力,因此,可以用于对容错流程要求严格的人脸识别问题。作为一种特殊结构的网络,孪生神经网络能够与其他神经网络相结合,以适应不同的任务场景,如在结合卷积神经网络实现两个图像相似度的比较中,可以利用卷积神经网络的高效性、可扩展性等进一步提高识别的准确性和稳定性。
如图1 所示,孪生神经网络中输入图片为X1,X2,两幅图分别经过一个特征提取网络形成特征向量GW(X1),GW(X2),该特征向量通过共享权重的方式进行特征提取,可以有效地增加模型的可解释性,并保证特征向量GW(X1),GW(X2)具有相同的特征提取能力,更加准确地表示两个输入样本之间的差异或相似度。采用欧氏距离这种距离度量的方式获取两个特征向量之间的差异,得到的映射函数如下:
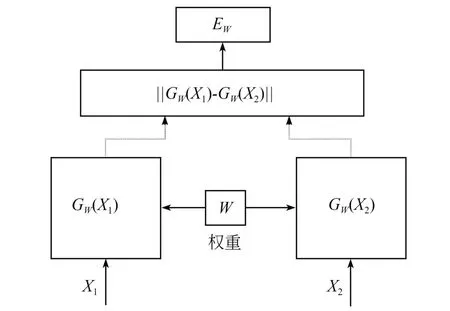
图1 孪生神经网络结构示意图Fig.1 Structure diagram of Siamese network
映射函数EW主要是计算两个特征向量的差异,可以通过两向量之差的模长判断。EW越接近1,两者相似度越高,越符合要求。
2.2 VGG-BN 网络模型
VGG 网络[18]作为卷积神经网络在目标检测等计算机视觉中的重要模型,是在AlexNet 网络结构的基础上改进的,具体是采用3×3 的卷积核代替大卷积核,如5×5,7×7 的卷积核。这种采用小卷积核代替的方式会使网络深度增加,通过重复的使用卷积核和池化层能够消除影响,有效地提取图像特征,并在ImageNet 数据集上实验证明了优越性。
VGG11 网络结构就是在VGG16 网络的基础上,通过改变模型的深度和宽度提出的一种网络模型结构,在具有较浅的深度同时也具有很强的表达能力和特征提取能力。本文提出的VGG11_BN 网络结构是在VGG11 网络模型结构的基础上添加了批量归一化(Batch Normalization, BN)层。BN 层是Google[19]提出来的一个结构,主要用于解决梯度消失问题及加速模型的收敛速度等。BN 层将输入数据进行归一化的总公式如下:
式中:ŷ代表卷积层中输出y的估计值,γ,β表示可学习的参数量。最终输出为:
式中:μy,σy代表BN 层的均值,ω是权重参数,b是偏置参数,ε是一个正数。
通过这一系列的操作实现归一化的过程,使激活函数的输入分布更加稳定,加速网络的收敛。采用的激活函数为Relu 激活函数,如下:
式中x为来自于BN 层的输出。
VGG11_BN 网络的结构示意图如图2所示。
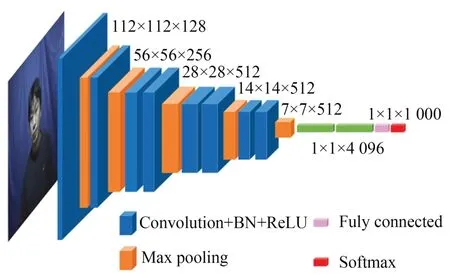
图2 VGG11_BN 网络结构示意图Fig.2 VGG11_BN network structure diagram
2.3 混合注意力机制
计算机视觉中把注意力聚集在图像的重要区域并丢弃不相关的方法称为注意力机制,这种注意力机制能够更快捷和高效地分析复杂场景信息,快速提取有价值的信息,摒弃无用信息。应用到计算机领域可以有效地降低计算复杂度,减少干扰,提高计算效率。
注意力机制作为一种对图像输入重要信息的动态选择过程,是基于特征自适应权重实现的,在目标检测、人脸识别、小样本检测等任务中发挥着重要作用。在人脸识别方面,注意力机制可以更好地处理人脸的不同部位和特征。相较于传统的人脸识别算法使用固定的特征表示方法,注意力机制可以根据人脸的不同部位和特征自适应地计算不同输入数据的权重,更加有效地利用输入数据的信息,提高模型的性能和鲁棒性。张晋婧等[20]提出了融合注意力机制的人脸识别算法,将注意力机制融合到facenet 人脸识别算法中,用于加强不同感受野下的特征提取,增强较为重要的特征信息,并抑制其他不重要的特征。
注意力机制通常划分为通道注意力机制、空间注意力机制、时间注意力机制和混合注意力机制等,具体的实现方式和效果不同,其联系如图3所示。
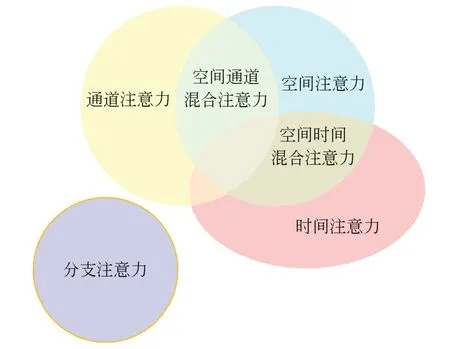
图3 注意力机制关联图Fig.3 Attention mechanism correlation chart
针对待识别图像中存在一些不相关的背景噪声等影响因素,这里选择CBAM 进行处理,它属于一种混合注意力机制,有助于细化特征、提高性能。CBAM 的示意图如图4 所示。
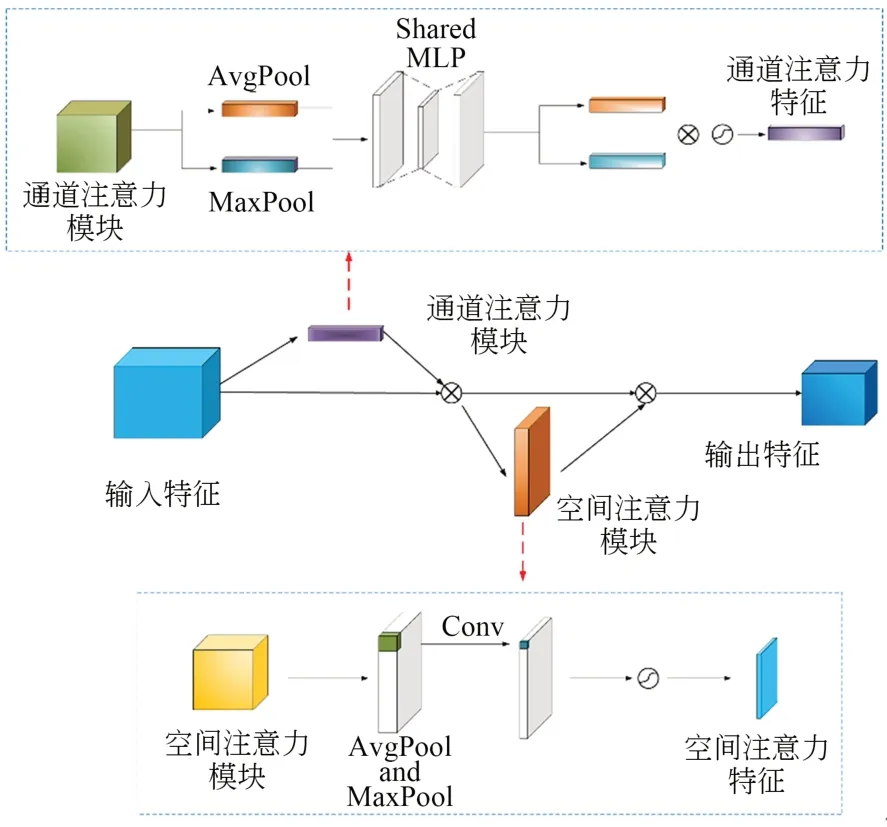
图4 CBAM 整体示意图Fig.4 Overall diagram of CBAM
总体运算公式如下:
式中:⊗表示元素级乘法,Mc(F)表示通道注意力特征图,Ms(F)表示空间注意力特征图。
3 基于注意力机制的Siamese 神经网络算法
VGG 网络模型是当前比较优秀的图像特征提取算法之一,广泛应用在人脸识别领域,以及迁移学习方面。通过使用自定义全连接层和VGG11_BN 模型相拼接来修改原模型并形成新的网络结构,具体方式是将原模型中的全连接层去掉,然后通过最大池化操作及Flatten 标准降维方法来“压平”数据,最后利用两个全连接层实现特征的比较与融合。在训练过程中,还利用迁移学习的方式调用VGG11_BN 网络的预训练模型,该模型在训练过程中采用ImageNet 数据集,数据种类众多,只需要保留原来模型中的底层特征的有用信息即可,该算法在预训练模型的基础上进行训练,能够减少模型的训练时间,加快收敛速度。
在不同的注意力机制中,通道注意力机制可以自适应地调整输入张量的不同通道的权重,使得模型更加关注某些重要的通道,如SENet[21]注意力算法包括一个全局平均池化层和两个全连接层。Almadan 等[22]采用SENet 注意力进行人脸识别,采用两个全连接层可以有效地提升特征的维度,但在参数过多时会大幅度降低训练效率。空间注意力机制可以自适应地调整输入张量中不同位置的权重,使得模型更加关注某些重要的位置,在文本处理和图像处理任务中的应用较为广泛。特别在图像处理任务中,自注意力机制可以根据图像中每个像素点的不同特征自适应地调整每个像素点的权重,以提高模型的表现能力。但由于只能调整空间位置的权重而无法调整不同通道的权重,在处理通道特征时效果较差。因此,采用CBAM 中的空间注意力可以在空间和通道两个维度上同时调整权重,可以适应不同的输入数据,提高模型的性能。CBAM 通过在隐藏层的前半部分和后半部分分别添加注意力机制的方式来提高模型的性能,在前面添加注意力机制有利于减少计算量,加强特征提取能力和提高模型的表现能力;在后面添加注意力机制可以增强模型的泛化能力,优化模型结构和增强模型的稳定性。
将CBAM 混合注意力模块和提出的VGG网络相结合,实现对空间和通道两个维度上权重的同时调整和模型的优化。最终经过注意力机制后的输出为:
式中:m是一个二维特征图,f是一个卷积层,s是一个空间注意力权重,σ是sigmoid 激活函数,y`c是通道注意力输出。y′c的公式为:
式中:c是通道索引,i和j是空间索引,ε是一个很小的常数,MLP 是一个多层感知器,AvgPool 和MaxPool 分别代表平均池化和最大池化,σ是sigmoid 函数,Sc是通道注意力权重,μc和σc2分别是均值与方差。其具体表达式为:
式中:H,W,C分别表示特征图的高度、宽度和通道数,Y是来自于BN 层的输出。Y的计算公式如下:
式中:x是输入,μ是均值,σ2是方差,ϵ是一个很小的常数,γ和β是可学习的参数,用来调整数据的分布,输出为特征图y∈RH×W×C。
将修改后的VGG11_BN 网络和孪生神经网络融合,网络模型的结构示意图如图5 所示。将该修改后的网络结构放到特征提取部分,在这双分支的VGG11_BN 网络中,分别输入一张人脸图片,形成正样本或负样本,再分别进行特征提取,将样本映射到低纬度的空间中。然后,将提取的特征向量压平成一维向量,通过全连接层提取高级特征以更好地度量相似性,并通过相似度判定是否为同一人。
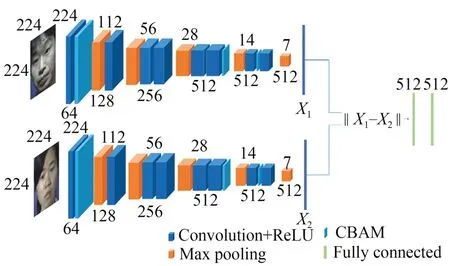
图5 VGG11_BN 结合孪生网络的模型结构示意图Fig.5 Model structure diagram of VGG11_BN combined with Siamese neural network
4 实验及结果分析
4.1 实验设置及数据集预处理
实验的硬件搭建平台为Windows11 操作系统,英特尔Core i9-10900K 处理器,16 G 内存,显卡型号为NVIDIA Quadro RTX 4000,8G 显存;软件平台为Pytorch1.12.1 深度学习框架搭配Cuda11.3 高性能并行运算平台。
采用的人脸数据集为中国科学院发布的CASIA-FaceV5 亚洲人脸数据集,该数据集的类内变化包括照明、姿势、表情、眼镜和成像距离等,能够针对不同的姿态、表情变化等情况进行相关训练。作为一个开放的亚洲人脸数据集,该数据集一共对500 个中国人进行采样拍照,每个人有5 张不同类内变化的图片,共2 500 张高质量的彩色图片,每个图片的像素都是高480、宽640,由于图片采集的是每个人的上半身图像,故图片需要进行预处理。
利用PaddlePaddle(飞桨)[23]预训练模型管理和迁移学习工具PaddleHub 进行人脸检测以及CASIA-FaceV5 数据集的预处理,具体方式是采用 PaddleHub 中 的 ultra_light_fast_generic_face_dete-ctor_1mb_640 模型进行预处理,获取图片中的人脸位置,针对获取到的数据点的位置,将图片裁剪成224×224 的人脸图片。该工具具有检测速度快、精度高等优点,利用MTCNN检测需要20 ms,而该模型只要4 ms。
4.2 模型评价指标
模型的评价指标主要采用平均准确率(Accuracy,Acc),AUC(Area Under the Receiver Operating Characteristic Curve)和ROC(Receiver Operating Characteristic)曲线。平均准确率是指在测试集的样本中正确分类样本所占的比例;ROC 曲线可以反映人脸识别的整体性能,又称为受试者工作特征曲线,主要用来评价人脸识别模型在不同阈值下的识别性能。通过ROC 曲线线形可明确看出模型性能的优劣程度,其横轴表示假阳性率(FPR),纵轴表示真阳性率(TPR),将不同的阈值作为分界点,绘制出模型训练后的结果在不同阈值下的性能表现,帮助更好地了解模型性能。TPR 和FPR 的计算公式如下:
式中:TP(True Positive)表示真正类;TN(True Negative)表示真负类;FP(False Positive)表示假负类;FN(False Negative)表示假正类。
平均准确率的计算公式如下:
AUC 的具体意义是指ROC 曲线图形的下面积,用来衡量人脸识别模型的整体性能。它作为衡量指标,面积越大,性能越好。具体计算公式如下:
式中:ranki代表第i条样本的序号,∑i∈positive代表把正样本的序号进行相加,M,N分别是正样本和负样本的个数。
4.3 实验过程及结果分析
在进行人脸识别的训练过程中超参数的调整对于最终的训练结果具有举足轻重的作用,而超参数包括学习率(learning rate)、批量大小(batch size)和激活函数等。学习率参数的设置影响着模型的收敛速度和性能,从而最终影响模型训练的效果,因此确定学习率的范围十分重要。根据经验以及查阅的资料,将学习率的初始值设定为1×10-6,然后设定以1×10-8进行线性增长,记录学习率和损失值的数据关系,绘制的曲线如图6 所示。

图6 损失随学习率的变化曲线Fig.6 Loss variation curve with learning rate
分析图6 中学习率与损失值之间的关系可知,损失值先降低然后出现振荡。学习率的选择范围为损失值快速下降的区间[24],因此基于以上描述和曲线图可确定学习率在1×10-6~1×10-5之间。
在进行网络模型的训练过程中,多是采用批量(Batch)训练法,因此在训练过程中,模型每次输入输出一个Batch,就要调整一次参数,其参数调整方法如下:
式中:θt+1是第t+1 次迭代后的参数值,θt是第t次迭代后的参数值,lr是学习率。动态调整学习率十分重要,选用周期性学习率(CyclicLR)调整学习率的策略,这种调度器会在训练过程中周期性地调整学习率,从较小的值逐渐增加到较大的值,然后再逐渐降低回较小的值,从而有效地帮助模型跳出局部最优解,避免过早陷入局部最优解,提高模型的泛化能力。在CyclicLR 学习率中有3 种不同的学习率策略,包括triangular,triangular2 和exp_range 3 种学习率。将这3 种学习率分别放到模型中进行训练,并在CASIA-FaceV5人脸数据集中进行测试,结果如图7 所示。由图7 可知,CyclicLR 学习率中3 种不同学习率策略对于该模型的匹配程度不一,使用triangular2 学习率的ROC 曲线的表现优于其他两种学习率策略。
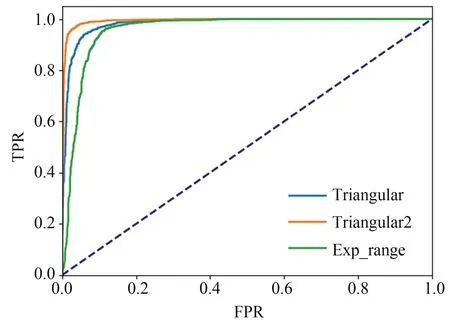
图7 不同学习率下的ROC 曲线Fig.7 ROC curves at different learning rates
比较在不同学习率下的平均准确率、AUC和平均精度,结果如表1 所示。由表1 可知,相同的网络模型下,3 种不同的学习率策略中triangular2 学习率策略的平均准确率,AUC 和平均精度最高,其平均准确率比triangular 学习率策略高将近4%,比exp_range 学习率策略高将近7%。
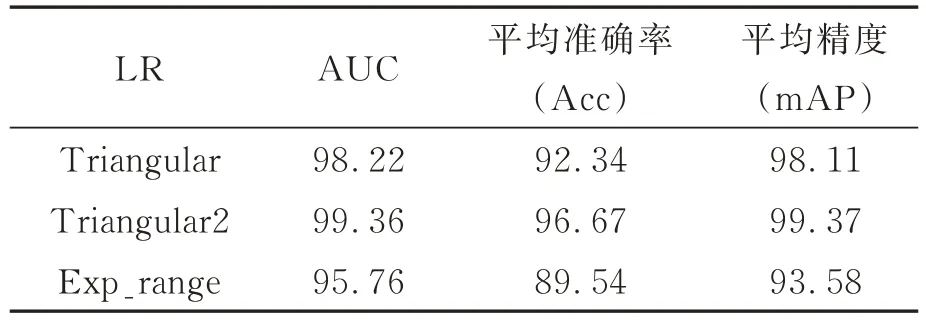
表1 本文算法中不同学习率的比较Tab.1 Comparison of different learning rates in proposed algorithm(%)
平均精度(mAP)能够全面地评估性能,因此triangular2 学习率比exp_range 学习率高5.79%,具备更高的准确性。最终表明,CyclicLR 学习率下triangular2 策略对于网络模型训练具有更好的收敛性。
为了进一步证明CBAM_VGG 算法的准确性及泛化能力,更换数据集进行上述网络模型的测试,采用由中国科学院技术研究所2003 采集创建的CAS-PEAL-R1[25]数据集。这个数据集包含姿态、表情、光照和距离等特征的变化,适应多种场景的应用。该数据库一共采集了1 040 位志愿者,共99 594 个面部图像,这一千多位志愿者由595 名男性和445 位女性组成,选取其中一部分面部图像作为测试集,部分样例如图8 所示。

图8 数据集样例Fig.8 Sample from dataset
在该网络模型结构下,为了评价各种算法与本文算法的性能差异,采用ROC 曲线评估模型性能,如图9 所示。从图9 可以看出,通过修改后的算法相对于传统的融合VGG 和孪生神经网络模型的算法具备更优的性能,意味着该模型在识别人脸时具有更高的真阳性率和更低的假阳性率,在实际检验时能够更加准确地识别,减少误判。将本文算法也与其他经典算法如LWSFLASVM[26],SRGES[27],KEHD[28],KCCA-SVM[29]及VGG+Siamese 进行比较,结果如表2 所示。
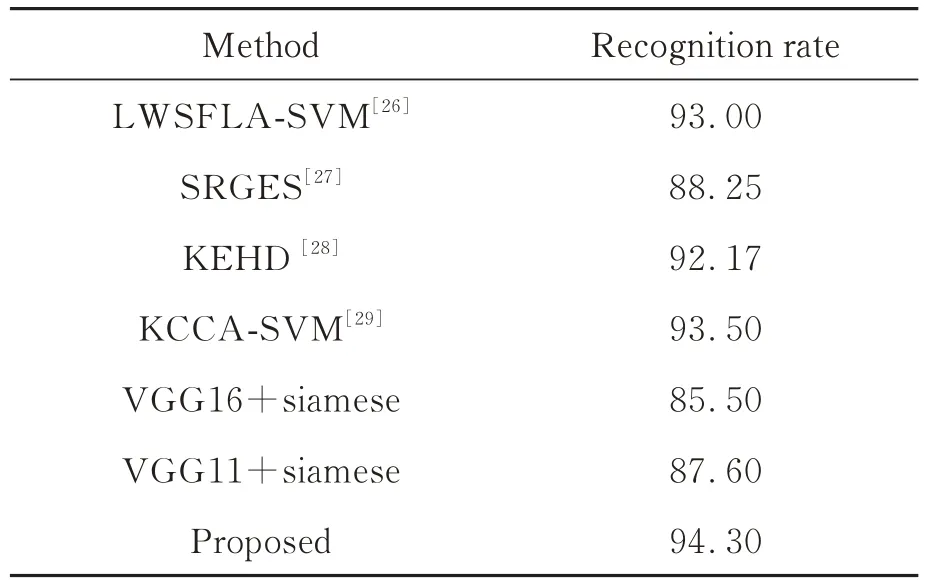
表2 不同算法的准确率比较Tab.2 Comparison of accuracy rates of different algorithms(%)
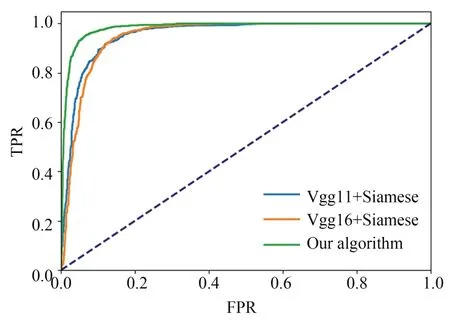
图9 本文算法和传统Siamese 神经网络的比较Fig.9 Comparison between proposed algorithm and traditional Siamese neural network
由表2 可知,该算法在CAS-PEAL-R1 数据集上与其他算法相比,识别率分别提高了1.3%,6.05%,2.13%,0.8%,8.8%和6.7%,证明该算法在存在姿态、表情等变化时仍然具有较好的人脸识别效果。相较于使用SVM 的方法,虽然在识别效果上的提升不大,但是孪生神经网络更容易改进,能够及时融合先进算法,本文就是通过结合改进的vgg 算法进行训练;同时在处理小规模样本上也具有较大的优势,能够提供更快的收敛速度,具备更高的性能和识别能力。与其他孪生神经网络相比,添加CBAM 注意力机制后其平均准确率得到了较大的提升。具体的测试效果样例如图10 所示。图10 中,4 组测试分别是一对正样本和负样本,可以看出正样本中相似度较高,负样本中图片的相似度就较低,实验结果也与期望一致。

图10 测试效果样例Fig.10 Sample test results
4.4 消融实验
为了进一步探究本文方法对模型性能产生的积极效果,在CASIA-FaceV5 和CAS-PEALR1 数据集中设计消融实验进行对比分析。同时,为了证明融合CBAM 注意力机制模块的有效性,分别单独加入CBAM 模块进行消融实验来判断它对模型性能的影响。实验结果如表3所示。

表3 消融实验结果Tab.3 Results of ablation experiment
表3 中,Base 模型表示基础模型,未添加CBAM 注意力机制;CBAM+Base 表示在提取网络的前端添加CBAM 注意力机制;Base+CBAM 表示在提取网络的后端添加CBAM 注意力机制。通过分析可知,基础模型在两个数据集中的平均准确度最低,模型的计算量最高;当在提取网络的前端添加CBAM 时,识别的平均正确率在CASIA-FaceV5 数据集中只提高了4.5%,但减少了整个模型的计算量;在提取网络的后端添加CBAM 时,模型整体的计算量并没有改变,但识别的平均准确率分别增加了8.9%,4.6%,比在前端添加CBAM 提高了将近五个百分点,提高了模型对于特征的提取能力,增强了模型的稳定性。最终,模型结构的计算量降至13.5GFLOPs,平均准确率分别提高了15.27%,6.7%。消融实验结果表明,本文方法能够快速有效地进行人脸识别。
5 结 论
本文提出了一种融合CBAM 和Siamese 神经网络的人脸识别算法,该算法在融合VGG 和孪生神经网络的基础上修改了部分结构并引入CBAM 混合注意力模块,提高了特征提取能力。相较于其他需要进行身份标记的算法,该算法通过直接测量两张人脸特征间的相似性进行识别,既简化了过程,又提高了效率。在此基础上,通过判断不同的学习率策略,选择最佳的Radam 优化器和CyclicLR 循环学习率组合策略,其中Radam 优化器可以在进行人脸识别训练时自适应动量机制和偏置校正,提高训练效果。最终,该算法测试的平均准确率达到了96.67%,在CASPEAL-R1 数据集的平均准确率达到了94.3%,相比于修改前的算法提高的6.7%,并且相较于其他经典算法的表现也十分出色,能适应在数据集中因姿态、表情、光照等变化产生的影响。综合可知,本文提出的算法具备良好的稳定性和泛化能力,在应对不同姿态、表情等变化时能够提高识别性能,对于人脸识别的应用与研究具有重要的参考价值。
猜你喜欢
作文中学版(2022年1期)2022-04-14
小雪花·成长指南(2022年1期)2022-04-09
少儿美术·书法版(2021年9期)2021-10-20
学生天地(2020年31期)2020-06-01
动漫星空(2018年9期)2018-10-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
