
基于异构光子神经网络的多模态特征融合
2023-12-01 05:49:36郑一臻
中国光学 2023年6期
郑一臻,戴 键,张 天,徐 坤
(北京邮电大学 信息光子学与光通信国家重点实验室,北京 100876)
1 引言
近年来,随着移动互联网的兴起,数据量呈指数性增长,传统的数据处理方法已经无法胜任复杂数据的分析和处理任务,而深度学习通过构建人工神经网络(Aritificial Neural Network,ANN),学习数据的内在规律和关联性,已成为解决人工智能领域中诸多应用问题的重要方法。ANN 在20 世纪80 年代后成为人工智能领域的研究热点,经过多年发展,ANN 取得了巨大的进步,在信号处理[1]、医学图像分析[2]、光学显微测量[3]以及成像重构[4]等领域获得了广泛的应用。虽然ANN 具有自学习、联想存储、高速寻找优化解以及非线性拟合等能力,但是训练ANN 需要大量且庞大的矩阵运算,因此,电子神经网络逐步显现出三个主要缺点:第一,训练需要大量的计算资源和时间,而且电子神经网络容易受到电信号干扰的限制[5],这给需要高密度连接的神经网络带来了一定的挑战;第二,传统计算技术体系的困局也逐步显现,冯诺依曼结构的内存遭遇“瓶颈问题”,出现了计算效率不够高的弊端;第三,影响计算能力的晶体管尺寸与密度逼近极限,传统计算技术步入“后摩尔定律”时代。因此,光子神经网络(Optical Neural Network,ONN)应运而生,其采用光与神经网络相结合的方式,利用光子带宽大、传输损耗低、能耗低、处理速度快的优势,有望将神经网络的计算速度和能效提升几个数量级。
1978 年,美国斯坦福大学的Goodman 等[6]首次提出了光向量矩阵乘法器的理论模型,这成为光学计算的重要一步,推动了ONN 的研究与发展。随后,为了降低神经网络训练和推演需要的时间和功耗,研究人员尝试利用光子所具有的高带宽、高并行、低功耗、低串扰和存算一体的优势,搭建光子神经网络用以突破传统计算技术的速率与框架瓶颈。1994 年,Reck 等[7]提出一种三角分解算法,通过分束器、移相器阵列实现任意N 阶酉矩阵,并且可通过调整移相器进行任意的重构。2016 年,Clements 等[8]对三角分解算法进行优化,提出了矩形分解方案,该方案具有对称的光学路径,光学深度更浅,损耗更低且鲁棒性更强。基于马赫-曾德尔干涉仪(Mach–Zehnder interferometer,MZI)阵列的光子神经网络主要包括实现线性变换的光学干涉单元(Optical Interference Unit,OIU)和光学非线性单元(Optical Nonlinear Unit,ONU)。其中OIU 经过奇异值分解为酉矩阵和对角矩阵,酉矩阵可以利用三角或矩形分解的MZI 阵列来实现。ONU 可以等效实现Sigmoid、ReLu、AbsSquared 等非线性激励函数,对上一层OIU 的输出信号进行非线性处理。2017 年,麻省理工学院的Shen 等[9]设计了一款新型的硅基光子人工神经网络芯片。这块芯片是通过多个MZI 级联构成,其中MZI 移项器的相位是将神经网络的线性部分的网络权重通过映射的方式进行赋值。他们通过理论推断,该光子人工神经网络有望在速度上比传统深度学习提高两个数量级,在功耗方面降低三个数量级,具有很重要的研究价值和应用前景。由于求取MZI 中移相器的梯度流程复杂,Shen 等采用了映射的方式对移项器进行赋值。2019 年,Zhang 等[10]利用演进类算法:遗传算法(Genetic Algorithm,GA)和粒子群算法(Particle Swarm optimization,PSO)对MZI 的相位值进行更新。2018 年,Bagherian 等[11]提出一种光子卷积神经网络的片上实现方案,使用MZI 阵列实现卷积核矩阵,并使用光学延时线对芯片进行时分复用来模拟图像与核矩阵的光学矩阵乘法(Optical Matrix Multiplication,OMM),从而构建光子卷积神经网络结构。光子神经网络的发展与光子器件的小型化,集成化密不可分。例如,近些年许多基于硅基MZI 的光子神经网络方案被提出,基于逆向设计的集成光子器件也可以用于光学计算和光子神经网络。2020 年,Qu 等[12]基于逆向设计提出了一种集成光学散射单元,可用于光学卷积运算。2022 年,Dan 等[13]提出了一种多端口等离子体系统,用于实现所有类型的紧凑型逻辑门,并且展示了反向设计在纳米光子器件中的有效应用。光子器件与深度学习等新兴技术的融合也将进一步拓展集成光学的发展前景。在人工智能领域,光子神经网络已经成为一个备受关注的研究方向。
目前光子神经网络的研究大多集中在提高推演速度等方面,这些研究多是针对单一模态数据的处理,针对多模态信息处理方面的研究相对较少。然而,随着人工智能领域的快速发展,多种模态信息的处理变得越来越普遍。因此,研究更困难、更复杂的跨越不同模态的信息进行建模和学习具有广泛的意义[14]。直观来看,多模态机器学习可以整合来自不同数据源的信息,利用不同模态信息之间的互补性,使得模型学习到的表示更加完备。2021 年,Huang 等[15]人通过理论证明了潜表示空间的质量决定了多模态模型的效果,并通过测试不同类型数据集实验证明了多模态机器学习在准确率等方面显著优于单模态模型。目前多模态机器学习主要包含5 大热点研究:学习表示[16]、多模态转化[17]、多模态融合[18]、多模态对齐[19]和多模态共同学习[20]。其中多模态融合是多模态研究中的关键,它将抽取自不同模态的信息融合成一个稳定的多模态表征。融合方法主要包括基于简单操作的融合和基于注意力的融合等[14]。简单操作方法将不同模态的特征通过拼接和加权求和等方法进行整合。拼接操作可以将来自不同层次的特征组合在一起,包括低层的输入特征[21]或者经过预训练模型提取的高层特征[22]。另一方面,注意力机制广泛应用于特征融合操作。例如将注意力机制应用于图像时,对不同区域的图像特征向量进行加权,使得每个向量的权重不同,从而获得一个整体图像的最终向量。这种加权过程可以使模型更加关注特定的区域和特征,提高模型性能。由于其具有提升融合效果、提高模型可解释性、减少冗余信息、提高模型的泛化能力等优点,所以成为多模态融合最主要的方法之一。
针对单一模态可能存在的模态信息缺失等问题,基于光子高带宽、低功耗和低串扰的优势,本文提出了基于异构光子神经网络的并行融合机制,并实现了多模态MNIST 数据集的分类任务。首先,利用光子卷积神经网络和不同维度大小的光子人工神经网络构建异构光子神经网络,并通过拼接方式将神经网络的输出特征输入到融合网络中进行决策,针对多模态的MNIST 数据集进行分类时测试集准确度达到95.75%;其次,为了进一步提升任务的分类准确率,本文在融合阶段通过引入注意力机制,将测试集准确度提升到98.31%。本文的工作内容有望推动集成光子在更通用的多模态融合领域的应用与发展。
2 基于拼接融合方法的异构光子神经网络
2.1 异构光子神经网络结构
为了增强光子神经网络的通用处理能力,本文设计了一种针对多模态信息处理的并行异构光子神经网络架构,主要由多模态信息处理层和融合层构成。该异构光子神经网络针对多模态MNIST 数据集的6 种输入模态,通过不同的光子神经网络进行特征提取。这些提取的特征通过拼接的方式并行输入到融合决策层,融合决策层通过对融合后的信息进行分析,确定在当前输入下的最优决策,异构光子神经网络架构如图1(彩图见期刊电子版)所示。该网络由光子卷积神经网络与不同维度大小的光子人工神经网络组成。光子卷积神经网络包含了光学卷积层和全连接层。其中:光子卷积层由U、∑和V 级联成完整的光学矩阵乘法结构。全连接层由U 矩阵结构以及光学非线性组成,本文全连接层仅用U 矩阵结构的原因包括以下两点:首先,在训练过程中无需完整的矩阵串联结构,仅用U 矩阵结构也可以实现较高的分类准确率;其次,由于全连接的输入端口较多,若仍采用完整的矩阵串联结构,对当前芯片制造工艺要求较高,难以实现,故通过仅用U 矩阵结构以减少MZI 的数量,从而降低芯片制造的难度。
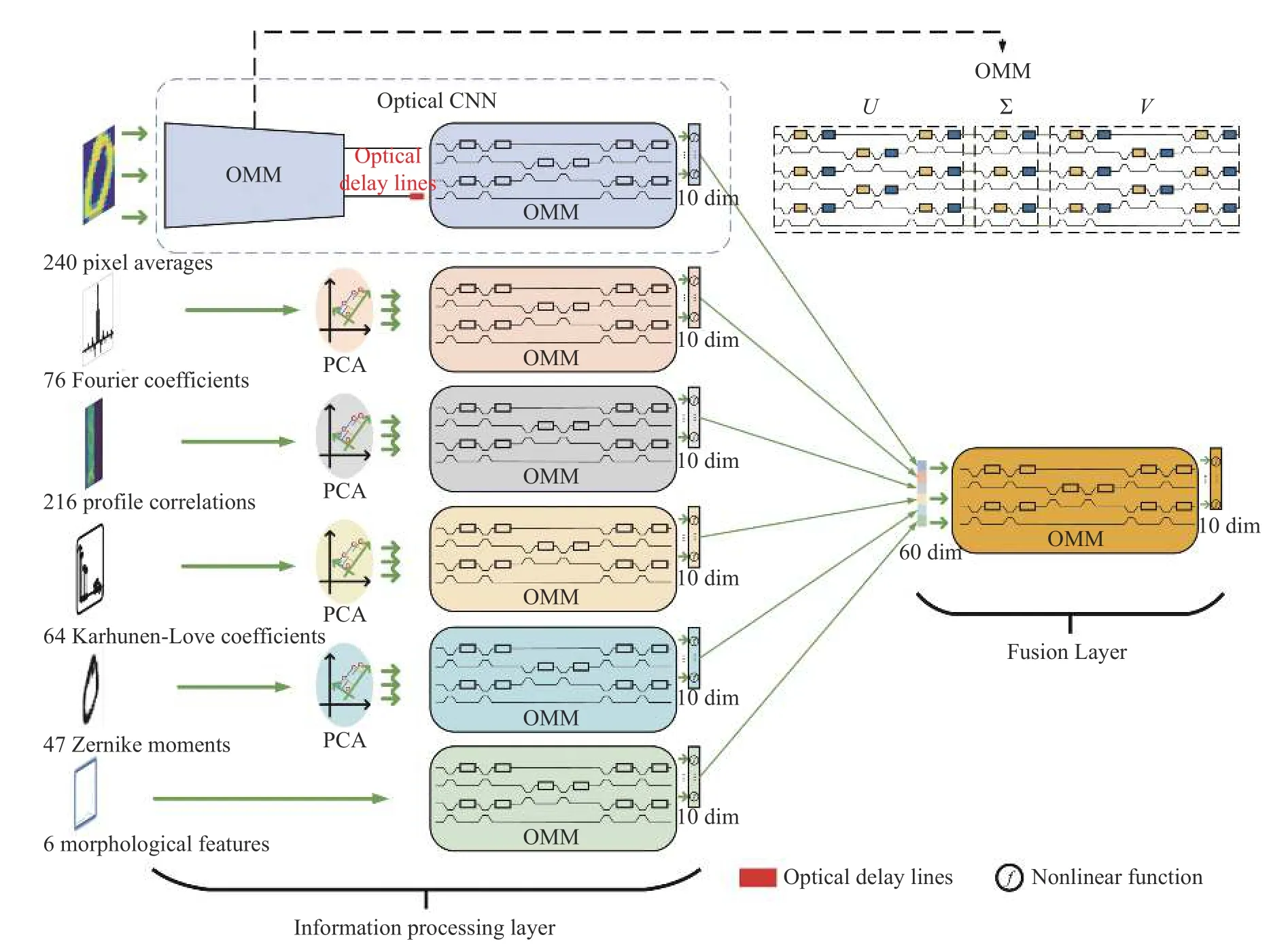
图1 异构光子神经网络的结构示意图Fig.1 Schematic diagram of the structure of the heterogeneous photonic neural network
本文旨在解决多模态MNIST 数据集的分类问题,该数据集包含6 种不同模态特征,分别为:240 个像素平均值、76 个字符形状的傅立叶系数、216 个轮廓相关性、64 个K-L 系数、47 个Zernike 矩和6 个形态特征。本文利用异构光子神经网络处理上述6 种模态。首先,将所有模态的输入信号调制到光载波上输入到集成芯片中;其次,针对第一种模态,利用光子卷积神经网络进行处理,对输入特征进行卷积操作,输出卷积后的特征,然后将该特征经过光子人工神经网络输出一个10 维的特征向量。针对其余模态,搭建了基于Clements 结构[8]的不同维度大小的光子人工神经网络,对不同模态进行特征提取,并都输出10 维的特征向量。最终将这6 个10 维特征向量经过拼接后送入到融合网络中进行决策。
考虑到当前集成光子的工艺水平有限,降低实验验证的复杂度是很有必要的,本文首先对多模态数据进行了降维操作。首先,使用5×5 大小的卷积核对第一个240 维模态的特征进行卷积操作,并将卷积步长设为2,从而将240 维特征降低到36 维;其次,对于其他模态的特征,采用主成分分析(Principal Component Analysis,PCA)进行降维,并且在保留尽可能多信息的前提下,分别将第二、第三、第四和第五模态的特征降至40、36、40 和22 维,同时分别保留了85.61%、96.24%、88.51%和99.03%的信息;最后在Interconnect 仿真软件中对该模型结构进行仿真实验,并给出仿真结果。
接下来,本文将介绍用于处理第一种模态特征的光子卷积神经网络的结构和工作原理。2018 年,Bagherian 等[11]提出一种光子卷积神经网络的片上实现方案,使用MZI 阵列实现卷积核矩阵,并使用光学延时线来模拟图像与核矩阵的“卷积”处理,该方案将输入图像的像素分组为更小的块,其尺寸与卷积核相同。然后,将图像分割后的“矩阵块”矢量化成一维向量并通过时分复用的方式输入OIU 中与补丁矩阵进行内积运算。对内积运算后的结果,通过设计光学延迟线,使得结果可以及时重新排列,并将排列后的结果送入到下一层的OIU。
2.2 异构光子神经网络仿真实验
为了进一步验证本文所提模型、架构以及算法的可行性,本文在Interconnect 仿真软件上搭建了图1 所示异构光子神经网络结构以及光学非线性函数。通过探测该网络的输出光功率来进行数字识别,确定设计方案的可行性。在整个仿真验证实验中,系统的调制速率为10 GHz。接下来,将依次介绍光学卷积、光学非线性单元和完整异构光子神经网络的仿真实验及其仿真结果。
2.2.1 光学卷积仿真实验结果
基于Bagherian 等[11]提出的光子卷积神经网络的片上实现方案,本文选定合适的卷积核,通过奇异值分解(Singular Value Decomposition,SVD)将酉矩阵分解为MZI 阵列的级联,得到对应每个MZI 的内外移相器的移相值,并分别映射到内外移相器上。为了更直观地观察光学卷积的效果,本文在Interconnect 仿真时选择了3×3 大小的锐化卷积核:
该卷积核的主要作用是对图片进行锐化操作,使得图像的边缘更加锐利。经过上述光学卷积操作后,最终输出结果如图2(彩图见期刊电子版)所示。图2(a)为输入的原始图像,图2(b)为光学卷积处理后的结果。在光学卷积中,因无法探测矩阵乘法结果小于零的输出,因此会将小于零的输出置零。
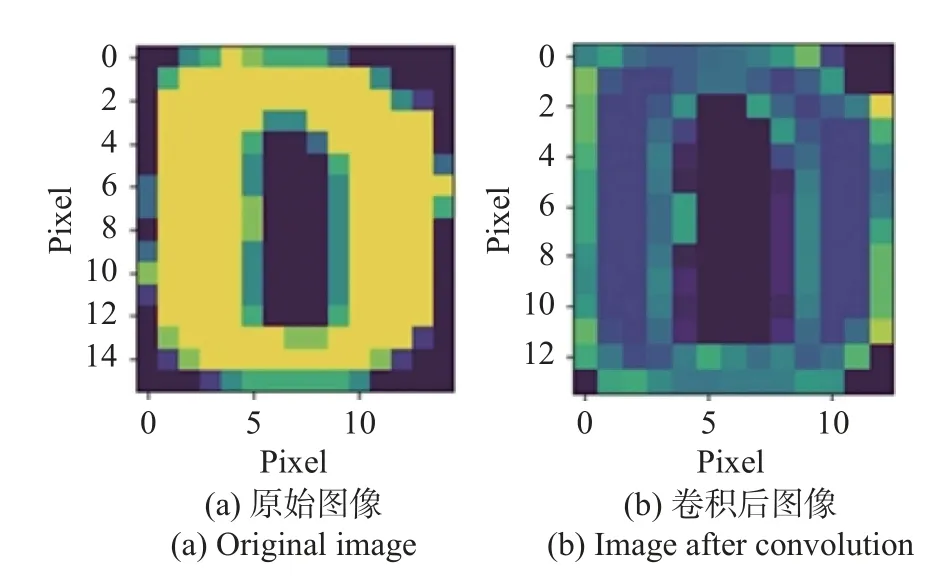
图2 光学卷积结果Fig.2 Optical convolution results
2.2.2 光学非线性
下面将详细介绍光学非线性激活函数的结构和工作原理。本文设计了AbsSquared 激活函数,该激活函数会将上一层OIU 输出的光信号进行非线性处理,并输出光信号:
其中:X是非线性激活函数的输入光信号,z是相位为0 的输出光信号。如图3(a)所示,通过光电探测器(Photodetector,PD)探测输入信号的光功率值,并调制到一个相位为零的光源上;电光调制器(Amplitude Modulator,AM)将电信号调制到光信号上;电衰减器(Attenuator,ATT)用于降低信号的幅值,以避免在经过AM 模块时过调以损坏信号;载波光源(Continuous Wave Laser,CWL)用于携带传输电信号,最后经过光放大器输出光信号。为了进一步验证该非线性单元的有效性,通过零差探测器[23]探测光信号经过光学非线性处理前后的实部、虚部以及相位的变化。如图3(b)(彩图见期刊电子版)所示,左侧为输入信号前20 个单位时间的实部、虚部和相位的信息,右侧是经过光学非线性处理后的输出信号,可以观察到输出信号的虚部被消除了,而且相位被置零。
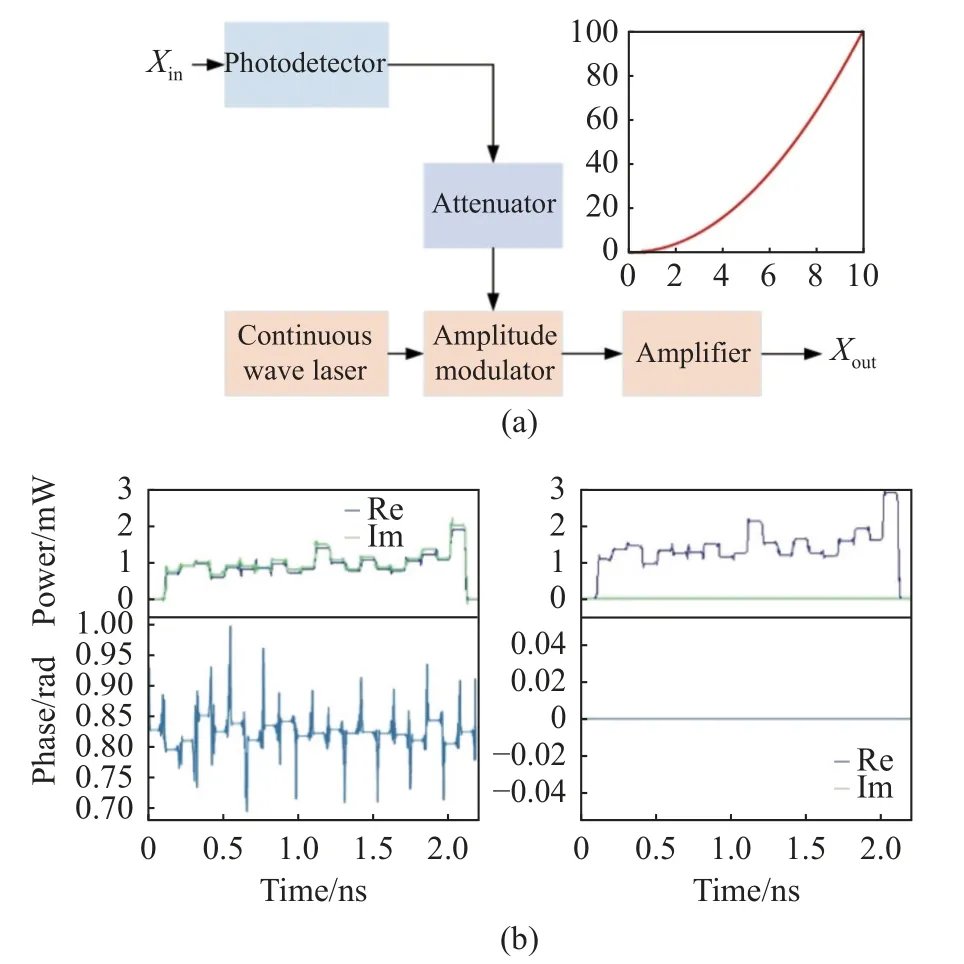
图3 (a)AbsSquared 非线性激活函数结构及(b)其测试结果Fig.3 (a) AbsSquared nonlinear activation function structure and (b) the test results
2.2.3 仿真实验结果
在本文的前两小节中,详细介绍了光子卷积层与光学非线性单元在Interconnect 仿真软件中的仿真实验与验证。从对光学卷积仿真实验结果的分析可以看出,在图像处理过程中,光子卷积可以有效提取图像特征,并且具有较高的性能。分析光学非线性单元的仿真实验结果,可以发现该光学非线性结构实现了光信号输入到光信号输出的过程。
本小节将展示完整的异构光子神经网络在Interconnect 仿真软件上的仿真实验结果。在仿真过程中,使用光示波器对每一个端口的输出光功率大小进行探测,记录了前20 个单位时间的输出结果。为了完成分类任务,在一个码元时间内,测量每个端口的平均输出光功率大小,输出的平均光功率最大的端口号即为对应的数字识别结果。本文对所有端口输出功率进行归一化,如图4 所示,在0.1ns 这一时刻,第4 端口的输出平均光功率最大,则判别该时刻的输入是数字“3”。
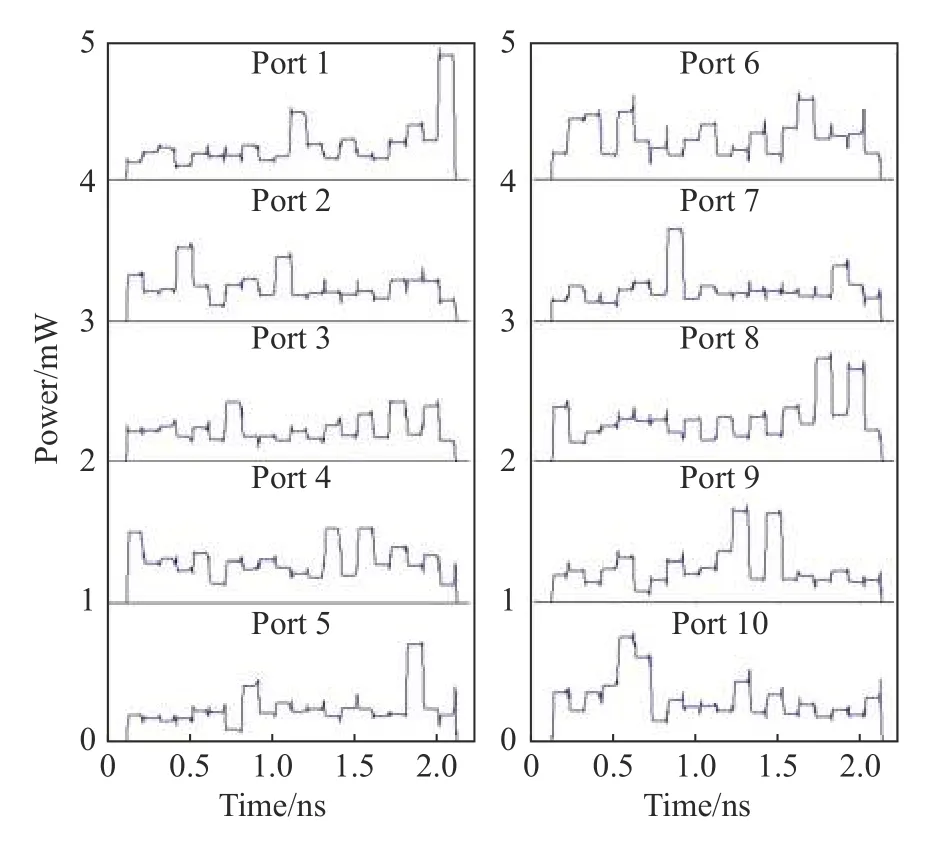
图4 端口输出光功率波形图Fig.4 Port output optical power waveform
为了获得更好的分类效果,本文通过调整学习率和优化器这两个超参数来改进神经网络的训练过程,并探讨它们对神经网络性能的影响。图5(a)(彩图见期刊电子版)为使用拼接方式融合的异构光子神经网络使用随机梯度下降(Stochastic Gradient Descent,SGD)和适应性矩估计(Adaptive Moment Estimation,Adam)优化器的训练集和测试集在不同学习率下的准确率变化曲线。本文中,学习率这一超参数的范围为1×10-4~9×10-4。从图中可以看出,无论是训练集还是测试集,使用Adam 优化器在分类准确率上都优于使用SGD 优化器。但无论是SGD 优化器还是Adam 优化器,随着学习率增大,准确率的波动范围均呈增大的趋势。若进一步增大学习率,可能会导致网络在最优点附近的振荡变得更加剧烈,进而无法达到最优。
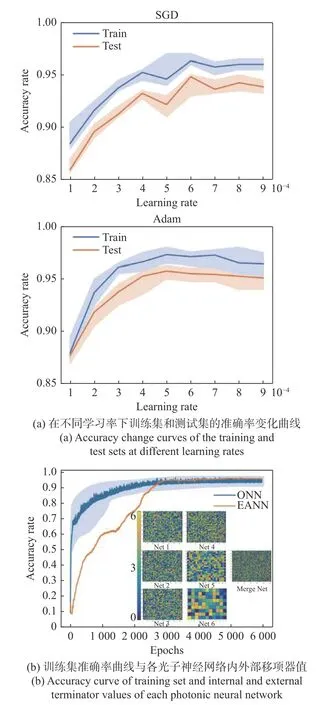
图5 学习率和优化器的选择Fig.5 Learning rate and optimizer selection
通过比较不同的学习率和优化器的组合,选择了Adam 优化器和学习率为6×10-4的组合,最终该异构光子神经网络在多模态MNIST 数据集的分类任务上训练集(1 600 个样本)准确率为97.3%,测试集(400 个样本)准确率为95.75%,如图5(b)所示。结果表明,本文提出的异构光子神经网络结构能够有效地完成多模态MNIST 数据集的分类任务。
为了更直观地展现光子神经网络训练耗时少的优势,本文还将其与电子神经网络的训练时间进行了比较。对基于拼接方式融合的异构电子神经网络在PyTorch 架构下对多模态MNIST 数据集进行训练,训练集准确率曲线如图5(b),可以看出异构光子神经网络与异构电子神经网络准确率相差无几。接下来,本文统计了异构电子神经网络在PyTorch 架构下训练时,正向传播、反向传播和参数更新经过1 000 次迭代(1 600 个训练样本,批次大小设置为200)的平均耗时,如表1所示。测试获得该时间数据的电脑配置如下:CPU 为8 核Intel i7-9700,内存为32 G。
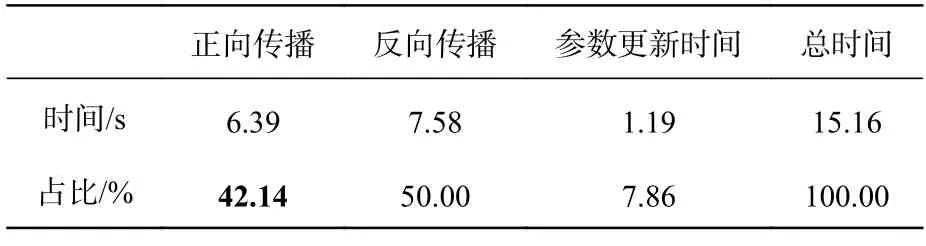
表1 拼接融合的异构电子神经网络训练各部分时间占比Tab.1 Time share of each part of training for heterogeneous electronic neural networks with splicing and fusion
对于异构电子神经网络而言,在并行训练当中正向传播所使用的时间占训练总时间的42.14%,而异构光子神经网络以光作为载体处理多模态信息,本文采用10 GHz 的调制速率,经过1 000 次迭代仅需0.000 16 s。相比于异构电子神经网络训练总时间,异构光子神经网络的计算速度提高了1.73 倍。因此在分类准确率相当的情况下,使用光计算实现异构神经网络可以显著提高计算速度并降低能耗和时间成本。
在第2 章中对异构光子神经网络的融合方式是基于拼接的方式,对于每一个模态的信息在融合阶段都赋予相同的权重,即对于任意一个分类任务,每一个模态的重要性程度相同,这难免会影响模型的分类准确性。因此,本文将在第3 章中介绍在融合阶段通过引入注意力机制模块来提升异构光子神经网络对多模态MNIST 数据集分类任务的准确率。
3 基于注意力机制融合的异构光子神经网络
3.1 注意力机制
如图6 所示,空间注意力模块(Spatial Attention Module)可以看作是一种自适应的空间区域选择机制[24]。该模块根据输入数据的不同区域进行加权处理,将神经网络的注意力重点放在重要的区域上,以便更好地提取重要的特征信息,提高模型准确率。其计算过程如下:
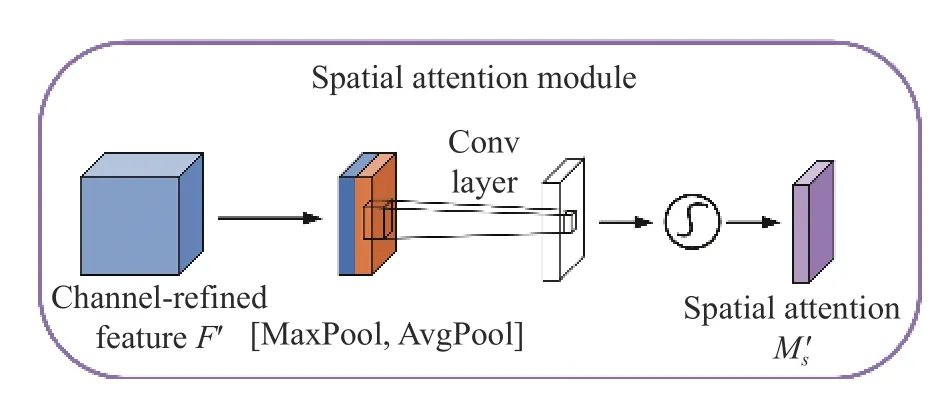
图6 空间注意力模块Fig.6 Spatial attention module
其中,AvgPool 和MaxPool 分别表示对输入特征进行全局平均池化操作和全局最大池化操作,f7×7表示卷积操作,σ表示Sigmoid 非线性函数。
3.2 基于注意力机制的异构光子神经网络融合
受到上述空间注意力机制算法的启发,本文提出了基于注意力机制融合的异构光子神经网络,通过训练,赋予不同模态以不同的权重,最终提高任务的分类准确性。如图7(彩图见期刊电子版)所示,首先将异构光子神经网络的6 个输出特征的对应元素相加,并将结果输入到基于光子神经网络的注意力模块;其次,通过注意力网络得到对应位置的权重分数,并将权重分数分别与6 个光子神经网络的输出特征的对应元素相乘;最后,将6 个新特征向量加权融合并送到最后的融合网络中进行决策。
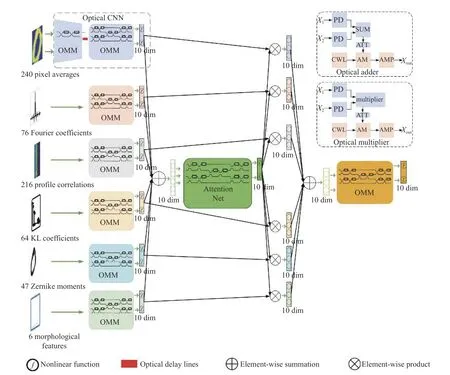
图7 基于注意力机制的异构光子神经网络结构示意图Fig.7 Schematic diagram of heterogeneous photonic neural network structure based on attention mechanism
虽然该网络结构相对复杂,目前工艺仍然很难实现,但是仍然可以通过时分复用的方式,仅使用一个OMM 芯片完成了上述工作。具体实现步骤如下:首先,将每个模态依次输入到芯片中,经过线性运算和光学非线性单元的处理后,输出光信号;随后,利用光电探测器将每个模态的输出信号进行探测并存储;接下来,对每个模态的信号进行SumPool 的操作,即对应元素相加;然后,将得到的结果再次输入到芯片中,输出注意力得分,并利用光电探测器探测;该注意力得分作用于所有模态特征,并再次进行Sum-Pool 的操作,得到新的特征向量;最后,将该特征向量输入到芯片中进行决策。通过上述方法,可以在当前工艺无法实现复杂的网络结构的情况下,高效实现该任务。
3.3 基于注意力机制融合的异构光子神经网络仿真实验
本节在第2 节异构光子神经网络架构基础上增加了注意力机制,采取与第2.2 节相同的方式在Interconnect 仿真软件上进行仿真验证。与前面2.2.3 节类似,本小节也通过实验探究了学习率和优化器对模型性能的影响。本节使用了两种不同的优化器(SGD 和Adam),如图8(a)(彩图见期刊电子版)所示。在每种优化器下分别尝试了不同的学习率,并通过在训练集和测试集上的表现来评估每种设置的效果。实验结果表明,基于注意力机制融合的异构光子神经网络在多模态MNIST 数据集的分类任务上,训练集和测试集的准确率均比拼接方式融合的异构光子神经网络更优,并且波动范围更小。在比较了多组学习率和优化器的组合后,最终选择了Adam 优化器和学习率为7×10-4的组合。在该组合下,模型在训练集上的平均准确率为98.87%,在测试集上的平均准确率为98.31%,训练集准确率变化曲线如图8(b)所示。
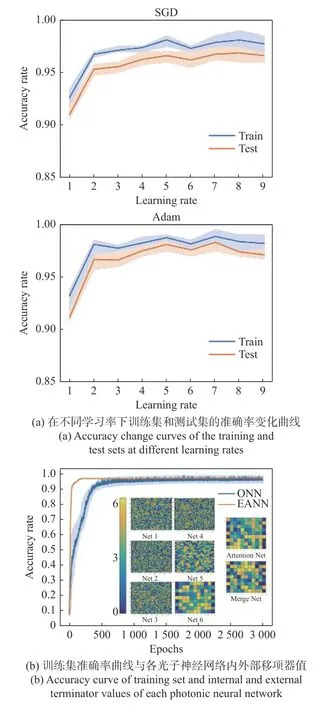
图8 基于注意力机制的异构光子神经网络的学习率和优化器的选择Fig.8 Learning rate and optimizer selection for heterogeneous photonic neural networks based on attention mechanism
本文在图8(b)中也展示了基于注意力机制融合的异构电子神经网络的训练准确率曲线。图8(b)表明,异构光子网络和异构电子网络的分类准确率几乎相等。接下来,本文将对比异构光网络与异构电子网络的训练时间。基于注意力机制融合的异构电子神经网络在PyTorch 架构下对多模态MNIST 数据集进行训练时,正向传播、反向传播和参数更新经过1 000 次迭代的平均耗时间如表2 所示。测试获得该时间数据的电脑配置与2.2.3 小节相同。
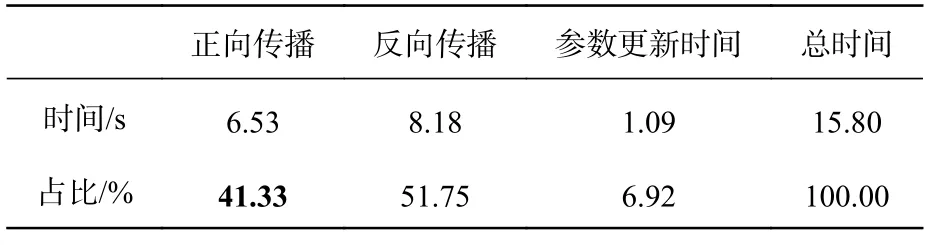
表2 基于注意力机制融合的异构电子神经网络训练各部分时间占比Tab.2 Time share of each part of training of heterogeneous electronic neural networks based on the fusion of attention mechanisms
基于注意力机制融合的异构电子神经网络在并行训练当中正向传播所使用的时间占训练总时间的41.33%,基于注意力机制融合的异构光子神经网络的正向传播在10 GHz 调制速率下仅需0.000 16 s。因此,在分类准确率差不多情况下,在计算速度方面相比于电子异构神经网络提高了1.7 倍。
4 实验结果
4.1 先进方法分类结果对比
本小节将对比不同的光子神经网络和异构电子神经网络在MNIST 数据集上的分类准确率,如表3 所示。文献[25]通过全光衍射深度神经网络学习实现手写数字分类;文献[26]设计了一种基于自由空间光学卷积原理的光子神经网络;文献[27]在卷积神经网络的基础上,通过光子硬件加速器实现图像处理;文献[28]通过建立量化噪声模型增加光子神经网络的鲁棒性。上述工作均利用光子神经网络完成单一模态的数据处理。文献[29]将dropout 网络训练作为贝叶斯神经网络中的近似推理;文献[30]从生成角度估计的数据不确定性的指导下,整合来自多个视图的内在信息,以获得无噪声表示,从而充分利用高质量的视图,同时减轻噪声样本的影响;文献[31]提出了一种半监督的多视图深度判别表示学习,全面地利用共性和互补特性,并通过采用共享和特定表征学习网络学习共享和特定表征;文献[32]提出了可信的多视图分类方法,通过在证据层面动态地整合不同的视图,整合每个视图的证据来提高分类的可靠性和稳健性。上述工作均为异构电子神经网络在MNIST 数据上的分类结果。可以看出,基于注意力机制融合的方式的异构光子神经网络相比于单模态的光子神经网络在MNIST数据集的分类准确率上效果更优。
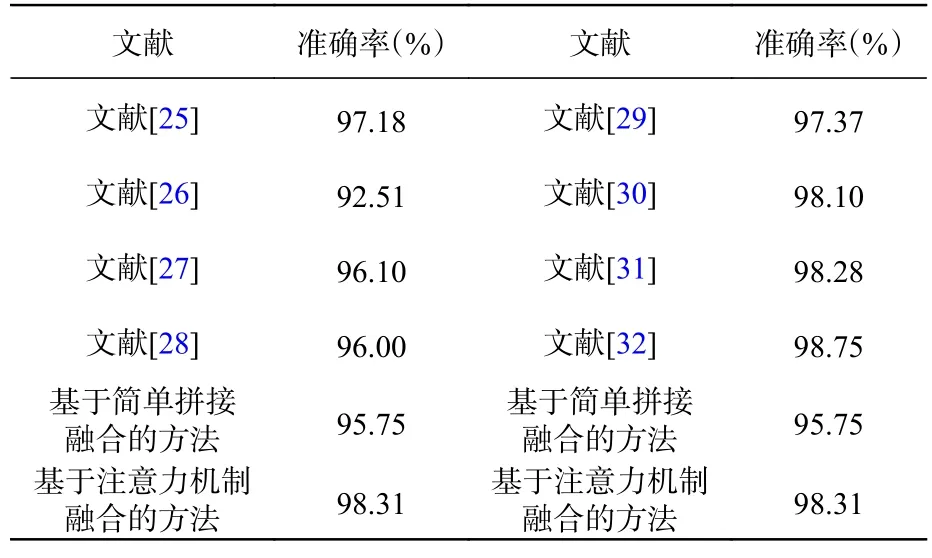
表3 先进方法分类结果对比表Tab.3 Comparison of classification results of advanced methods
4.2 噪声分析
光子神经网络研究的一个紧迫问题是:实际光学元器件中参数不确定性导致的性能下降问题。元器件中的不确定性主要有4 种类型,包括相移误差、插入损耗、耦合系数漂移和光探测噪声[33]。其中相位误差 {δθ,δϕ}可以建模为随机高斯分布变量Gp(µ=0,σ),其中期望 µ为零,标准差σ通常在0.05 以下的范围[9]。因此,本文在基于注意力机制融合的异构光子神经网络训练中分别对MZI 的内外部移项器施加随机高斯噪声,以模拟相位误差对异构光子网络的性能影响。为了更好地进行比较,本文需要优先固定好合适的学习率、优化器以及迭代次数。根据3.3 节对学习率以及优化器的讨论,本文将学习率设置为7×10-4,优化器选择Adam,迭代次数为3 000 次。如图9所示,在训练过程中,随着标准差 σ从0.01 到0.05 逐渐增大,训练集平均准确率曲线抖动程度逐渐增加,并且训练集准确率波动范围呈增大的趋势。然而,该网络增加随机高斯噪声后,整体表现在可接受范围内。由此说明该网络的抗噪能力较强,具有较好的鲁棒性。通过对网络训练增加随机高斯噪声,最终针对多模态MNIST 数据集进行分类时,测试集准确度分别为:98.31%、97.16%、96.12%、94.32%、93.25%和90.33%。
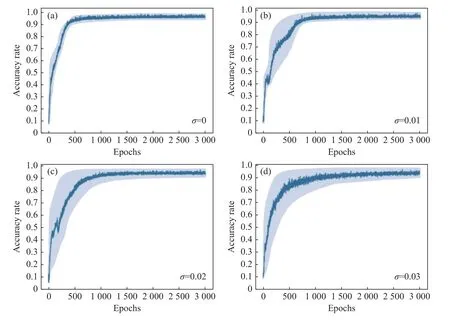
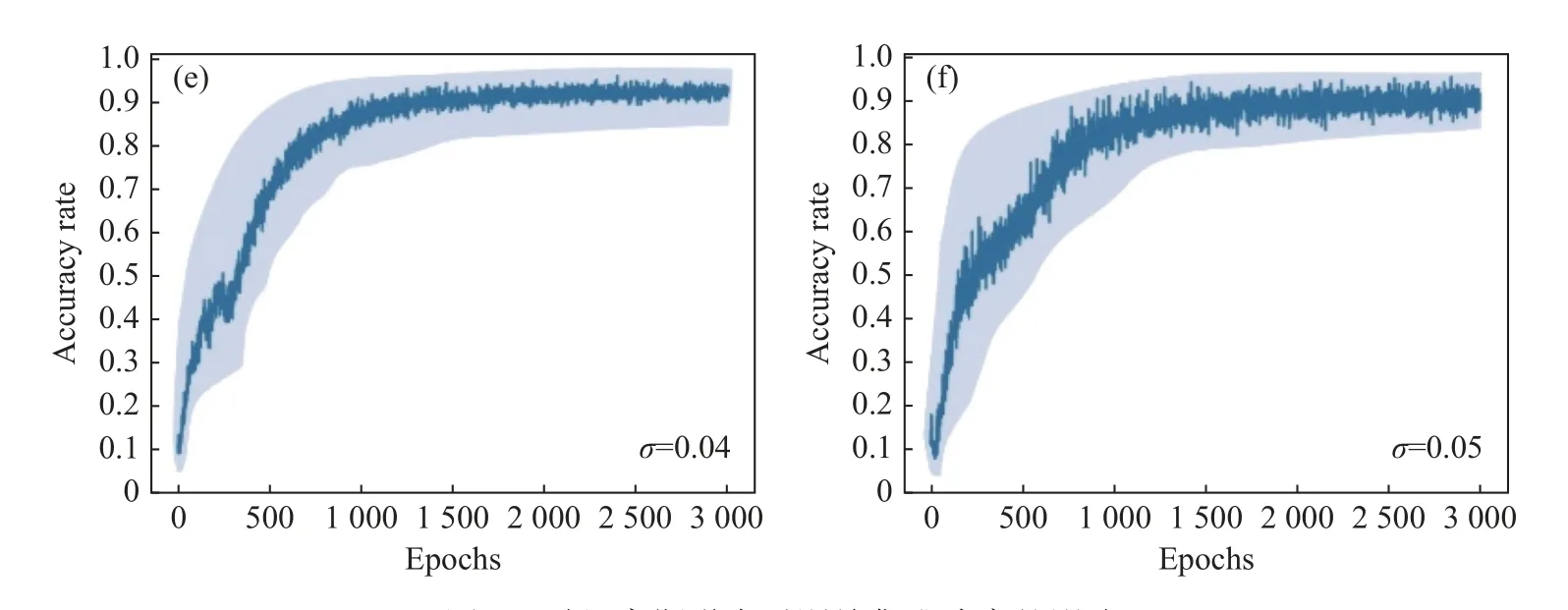
图9 随机高斯噪声对训练集准确率的影响Fig.9 The effect of random Gaussian noise on the accuracy of the training set
5 结论
本文提出了将光子神经网络与多模态机器学习相结合,不仅利用光子神经网络实现了比传统冯诺依曼架构更快的计算速度,还解决了当前光子神经网络模型仅处理单一模态导致的可能存在的模态信息缺失等问题。本文提出了基于拼接方式融合的异构光子神经网络模型,通过拼接方式融合多模态信息实现分类任务。在此基础上,又提出一种基于注意力机制融合的异构光子神经网络模型,将异构光子神经网络与注意力机制相结合,通过训练对不同模态赋予不同的权重,以提升特征的融合效果,进一步提高了任务的分类准确性。本文所提出的方法在多模态MNIST 数据集上的准确率分别到达95.75%和98.31%。在未来的工作中需要进一步优化网络结构,降低结构的复杂度,有望在在集成光子平台上实现。
猜你喜欢
光子学报(2022年11期)2022-11-26 03:43:44
初中生学习指导·中考版(2022年4期)2022-05-12 00:12:51
小学教学研究(2022年5期)2022-04-28 21:29:36
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16 05:32:06
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
湖南师范大学自然科学学报(2015年1期)2015-02-27 14:50:05
汽车零部件(2014年10期)2014-11-11 12:25:04
航天返回与遥感(2014年1期)2014-07-31 17:55:36
机械制造与自动化(2014年1期)2014-03-01 04:21:57

- 中国光学的其它文章
- 惯性传感器地面弱力测量系统热设计
- InGaAs/AlGaAs quantum well intermixing induced by Si impurities under multi-variable conditions
- Orbital-angular-momentum spectra in coherent optical vortex beam arrays with hybrid states of polarization
- The influence of the number of coupling regions on the output of the ding-shaped microring resonator
- A sliding-mode control of a Dual-PMSMs synchronization driving method
- Polarization-multiplexing of a laser based on a bulk Yb:CALGO crystal