
GRU和Involution改进的深度伪造视频检测方法
2023-11-27 05:35:38刘亚琳芦天亮
计算机工程与应用 2023年22期
刘亚琳,芦天亮
中国人民公安大学 信息网络安全学院,北京100038
目前深度学习被广泛研究,相关技术日益成熟并且在很多方面取得了巨大的成就。这类技术对人们的日常生活产生了积极或消极的影响,深度伪造就是其中最具有代表性的消极影响之一。比如名人换脸视频[1],某国总统演讲时的伪造音频[2],盗窃大额钱财和青少年骚扰等案件,涉及到政治、名誉、生活等多方面,其社会危害性不容小觑。随着深度伪造技术的成熟,使用者可以在不熟悉甚至完全不懂相关理论知识和深度学习算法的情况下轻松地使用相关软件,例如FakeApp 和Zao等,对视频进行篡改伪造。正是由于这种技术的滥用,互联网中出现了大量盗用他人身份制作色情视频、敲诈勒索和网络攻击,甚至是传播虚假新闻制造舆论、煽动暴恐行动和干扰国家政治等行为。因此有效分辨深度伪造视频至关重要。
1 相关工作
由于检测深度伪造视频的重要性,国内外相关研究大幅增多。如今对深度伪造视频检测技术的研究主要分成两类,分别是基于单帧的检测和基于多帧的检测。
基于单帧的检测方法对深度伪造视频单帧的空间特征进行学习,再对各帧的预测结果决策进行融合。该方法可以充分提取伪造人脸的空间特征,但是忽略了帧间差异,主要分为传统检测和深度学习检测。对于传统的图像取证检测,Koopman 等人[3]对图片在拍摄过程中进行PRNU(photo response non uniformity)分析,利用计算出的视频平均归一化交叉评分来识别伪造视频。李纪成等人[4]根据Lambert算法来计算视频中帧的二维光照方向,并判断视频中这些方向的变化是否平滑来区分伪造与否。对于使用深度学习的检测,Yang等人[5]利用伪造图像在图像显著程度上存在细微的纹理差异,在篡改图像上表现为纹理上的差异,使用引导过滤器增强处理造成的纹理伪影并显示出潜在的伪造特征。Demir等人[6]通过眼睛和凝视时的特征差异进行真假检测。Li等人[7]提出一种新的偏导数,构建了S-MIL 和S-MIL-T 两种网络。Nguyen 等人[8]使用参数较传统卷积更少的胶囊网络模型来检测篡改视频,并通过详细的分析和可视化解释了胶囊网络应用于取证问题背后的理论。
基于多帧的检测方法对深度伪造视频多帧的时空特征进行学习。该方法可以很大程度地学习视频的帧间特征。3D卷积网络通过视频数据集的特点进行特征提取,可以更加高效地学习连续的动作特征。Hara 等人[9]和Carreira等人[10]提出了3DResNet和I3D。Wang等人[11]将3DResNet、3DResNeXt和I3D卷积网络应用于深度伪造视频检测中,并研究了三种网络模型在识别篡改视频方面的效果。Sebyakin 等人[12]通过滑动窗口方法处理视频来分析来自多个连续帧序列的信息并检测视频内容中的深度伪像。Ganiyusufoglu等人[13]使用3D卷积深入分析了序列和时空视频编码器如何利用时间信息进行视频检测。Xuan等人[14]搭建了五层3D卷积网络进行训练,并验证模型的有效性。文献[15-16]利用光流场训练的卷积神经网络(convolutional neural networks,CNN)学习视频序列时间结构中存在的运动差异来区分真假视频。循环神经网络(recurrent netural network,RNN)能够获取帧之间的时序特征。文献[17-19]首先利用CNN 提取视频每帧人脸面部特征,再放入循环神经网络对面部特征的时序变化进行学习,从而鉴别伪造视频。Xiao 等人[20]提出了一种基于多变量时间预测的卷积LSTM(long short-term memory)网络模型,解决了时间依赖性不足的问题。Masi 等人[21]和Wu 等人[22]使用LSTM 网络的同时提取图像的高频信息来增强空间特征。文献[23-25]引入注意力机制,并与LSTM进行融合来增强空间信息表达能力。
文献[8]中的胶囊网络结构可以关注特征的位置信息且较卷积网络有更少的参数,但是仅关注了空间特征并且检测准确率有待提升。文献[21-25]基于时序特征对空间特征进行了增强,但使用的是拥有通道不变和空间不可知性质的标准算子。因此本文提出一种GRU(gated recurrent unit)和Involution 算子改进的深度伪造视频检测方法。该检测方法首先基于Involution算子构建了一个提取全局特征信息的特征提取网络,平衡空间信息和通道信息之间的精度效率,在训练阶段使用focalloss函数平衡样本;使用主胶囊层学习特征的位置信息并对CNN-Capsule输出的特征使用GRU进行帧级别学习,使整个模型在关注特征的位置信息时还可以充分学习空间特征和时序特征。
2 本文方法
本文首先对原始视频数据集进行帧截取和对齐,然后进行帧处理,对图像进行人脸识别和中心剪裁,最终把视频数据集处理成可以输入到网络模型中的张量形式;将处理好的数据输入到搭建好的混合模型中,首先使用CNN 输出人脸空间特征向量,然后再使用主胶囊层和GRU 学习位置信息和时序特征,最终结合时空特征进行分类。检测流程如图1所示。

图1 深度伪造检测流程图Fig.1 Deepfake detection flow chart
由于一般深度伪造视频主要是对人脸进行篡改,冗余的背景信息会对检测造成干扰。因此本文将面部区域的识别和裁剪工作放在了数据的预处理阶段。每条人脸视频长度大约为10 s,帧速率为30,设置每10 帧保存一张图像,最终每条视频大约截取30 帧左右。本文通过MTCNN[26]模型对每条视频的每帧图片进行人脸识别,然后对识别后的图片从中心区域开始剪裁并进行归一标准化,最终大小为128×128×3的人脸图片作为初始数据输入到网络模型中。数据预处理可以使网络模型集中关注学习每一帧中的人脸特征,忽略不相关的信息。然后使用VGG19_bn的前20层和Involution算子将预处理的数据进行特征提取得到图像特征向量,然后通过主胶囊层PrimaryCaps 学习特征的位置信息,其中每个主胶囊层会输出不同的特征向量,最后三个主胶囊堆叠在一起形成GRU的输入特征向量。最后经过全连接层和softmax分类器进行真实或伪造分类。
2.1 特征提取网络
VGG卷积神经网络[27]是由牛津大学和Google协同开发出的深度神经网络,由于构造简单并且具有实用性,在目标检测和分类等任务中都充分反映出独特的优越性。VGG 家族网络中包括VGG16 和VGG19 等网络结构,它们之间的差异仅在于网络深度不同。文献[8]使用VGG19中的前19层作为空间特征提取网络,然后将提取的特征放入到胶囊网络中。本文使用VGG19_bn提取每帧图像的空间特征,输出的特征向量作为下一个模块的输入。图1中视频帧通过VGG19_bn的features模块的前20层进行特征提取,随后得到256维的输出特征向量集合Uk={u1,u2,…,un} 。
2.2 胶囊网络
胶囊网络[28]与卷积神经网络的主要区别是它们的基本神经元不同。卷积神经网络在提取特征时不关注位置特征,其神经元是标量神经元,输入是向量,输出是一个标量。胶囊网络中的神经元为向量,神经元输入是向量,输出也是向量,输出向量的模长表示某一特征出现的概率值,方向代表实例化参数来关注特征的位置关系。如图2 所示,传统神经元中,对输入xi进行加权求和,然后经过sigmoid、tanh 等非线性函数,最后输出一个标量。预测向量u由输入向量ui经过矩阵计算得到,随后对这些新向量进行加权求和,最后通过激活函数squashing对向量进行压缩,得到长度在0-1范围内的输出向量。在胶囊神经元中,输入向量ui到输出向量vj的计算过程如式(1)~(3)所示。

图2 神经元结构对比Fig.2 Comparison of neuronal structure
胶囊网络由三部分组成,分别是输入卷积层、主胶囊层和数字胶囊层。第一层卷积层使用传统卷积提取输入向量的浅层特征;第二层主胶囊层使用胶囊神经元进行计算;第三层数字胶囊层在使用主胶囊层的输出后采用了动态路由算法进行连接。胶囊和上层中所有胶囊的耦合系数ηi,j和为1,a为临时变量,初始值为0 并在每次迭代中更新(耦合系数ηi,j如式(4)所示),并且使用动态路由算法进行调整。
2.3 GRU
循环神经网络(RNN)被设计为处理时间序列数据。它会对前序数据进行记忆,前面的信息会对当前的结果产生影响。但是由于RNN在反向传播期间会面临梯度消失问题,如果输入的数据序列足够长,很难将较早的有用信息传递到之后神经元中,这时神经网络就不会继续学习,因此也达不到理想的学习率,神经网络的精度也会下降。LSTM在RNN基础上进行了改进,改善了这一问题,其中遗忘门、输入门、输出门组成了LSTM的主要部分。
GRU[29]合并了LSTM的遗忘门和输出门,还去除了细胞状态这一结构,信息传递通过隐藏状态来完成。GRU由更新门和重置门组成,图3是运行到t时刻LSTM和GRU的结构对比。更新门zt作用是控制在t时刻忘记哪些信息和记住哪些信息,重置门rt用来控制在t时刻对先前信息的遗忘程度,计算方式如式(5)、(6)所示。

图3 LSTM和GRU结构对比Fig.3 Structural comparison of LSTM and GRU
其中,W、W′为权重矩阵,b为偏置参数,v为输入数据。然后使用重置门计算目前时刻的候选隐藏状态,由σ函数映射到[0,1]空间中。如式(7)、(8)所示,最后使用更新门对候选隐藏状态和上一时刻的信息进行线性组合,得到目前时刻的信息就完成了本次时间步的更新。
2.4 Involution算子
目前检测网络模型中大多使用卷积算子,可以对参数共享和充分学习不同通道上的信息,但是会存在卷积核受限不灵活和信息冗余的问题。Involution 算子[30]对空间域和通道域特性进行了逆向转变,颠覆了具有通道不变和空间不可知的卷积固定的性质,打破了现有卷积的归纳偏差,可以实现空间信息和通道信息之间良好的精度效率平衡,在确保网络架构表现特征能力的同时,还促使了网络轻量化,输出特征向量中的各个通道信息由输入特征向量中的每个通道信息参与计算而来,并且计算中的参数不共享。本文将Involution 算子引入到VGG19_bn网络中代替第21层的卷积操作,步长设置为2。
对于一般卷积操作,输入特征图记为M∈RH×W×Ci(H、W、C分别代表高度、宽度和通道),大小为k的卷积滤波器为F∈RC0×Ci×K×K,c0和ci分别代表输出通道数和输入通道数,其中卷积核的参数固定。卷积滤波器对输入特征图进行运算后得到输出特征图。
与卷积核不同,Involution核N∈RH×W×K×K×G是一种动态核,不同像素之间参数也不相同,G表示每个组共享相同核的个数,每一组在通道上共享,但是在空间中不同。具体表现为Involution核是在不同位置动态生成,它的大小与输入特征向量Mi,j∈RCi的维度有关,生成对应每个像素的核,如式(9)所示:
其中,ϕ为核生成函数,W1和W0是两个构成bottleneck的线性变换,减少比率γ决定中间通道数的维度,σ为激活函数。
在上述Involution 核生成过程中,每个像素中的通道信息都被扩散到附近的空间中,然后再由动态核将感受野中的信息搜集起来。如图4所示,输入特征向量经过与Involution 核进行乘加运算后得到输出特征向量。运算分为两部分:与通道c相乘和范围内空间信息聚合相加。

图4 Involution算子计算过程(G=1)Fig.4 Calculation process of Involution(G=1)
2.5 focalloss
由于数据集Celeb-DF 中的正负样本不平衡,本文使用focalloss函数[31]来评估样本预测标签与真实标签之间的差距大小。focalloss 函数是一种可以动态缩放的交叉熵损失,会让整个检测网络聚焦于难分类的样本。本文的检测可简单理解为一个二分类任务。一般二分类使用的损失函数交叉熵可表示为式(10),pt为分为某一类的概率。
二分类交叉熵函数中简单样本的损失占据了主导并且控制了梯度方向,因此focalloss在式(10)的基础上加入了加权因子α和调制因子(1-pt)γ(聚焦参数γ大于等于0),分别用来调整正负样本的权重和调整简单样本和难样本的权重,如式(11)所示:
α可以用来调整和平衡正负样本的比例。当一个样本的预测标签与真实标签不相等时,pt的值很小,因此调制因子趋近于1,对最终的损失值影响最小化;当一个样本预测标签与真实标签相等时调制因子为0,因此简单样本对最终损失值的权重被降低,以此在训练过程中降低简单样本的权重,使模型聚焦于难样本上。综上本文选择将focalloss 函数作为损失函数,并在第3.4 节中对其中参数的设置进行讨论。
3 实验结果与分析
3.1 实验环境
本文所用的实验平台是Ubuntu16.04 64 bit,中央处理器为Intel®CoreTMi9-10920X@3.50 GHz,内存大小为24 GB,显卡为NVIDIA GeForce RTX 3090。本文中所有实验的代码都是在pytorch框架下实现,python版本为3.7。
3.2 实验数据集
FaceForensics++[32]作为FaceForensics的扩展数据集于2019年发布,是目前规模较大、种类较多的公开面部伪造数据集。真实视频采集于YouTube上1 000个真实人脸视频,按照四种不同生成伪造视频的方法,数据集被分为Face2Face、FaceSwap、Deepfakes 和NeuralTextures四类。其中,Deepfakes 与FaceSwap 是将视频中的人脸完全替换成另一个人脸对视频中人物身份进行伪造;Face2Face 与NeuralTextures 是将视频中人的表情换成另一个人的表情但身份没有变,仅对面部的表情进行伪造。本文主要研究对整个人脸篡改进行检测,因此选取Deepfakes与FaceSwap两个数据集进行测试。
Celeb-DF[33]数据集中拥有质量更好的伪造视频,弥补了其他数据集中分辨率不高、伪造痕迹较明显等问题。在YouTube 中采集了408 个真实视频,由59 个性别、年龄、种族差别各异的名人采访视频构成。使用Deepfakes 方法生成了795 个伪造视频。Celeb-DFv2 在之前的基础上进行了扩展,其中包括从YouTube收集的590 个不同年龄、种族和性别的原始视频,以及5 639 条对应的Deepfake视频。
3.3 实验参数设置
对于上述数据集的所有视频以7∶3 的比例划分为训练集和测试集,每个视频提取大约30帧,分为两个类别即真和假。其中模型的损失函数采用了交叉熵来计算预测值和真实值之间的误差,模型的优化使用了Adam 梯度下降算法,学习率初始化为0.000 1,betas 设为(0.9,0.999)。为了保证实验的公平性,对每种数据集都分别训练其分类器,本文中的网络模型最后在全连接层后使用softmax函数来进行二分类,阈值选取为0.5。
3.4 实验结果分析
3.4.1 空间特征提取网络的选取
帧间时序特征的提取基于CNN 模型提取帧内特征,CNN 模型的选取对检测的准确度有很大影响。本文基于控制变量对帧内特征提取网络进行选取,如图5、图6所示,使用准确率ACC和AUC作为评价指标,经实验证明帧内特征提取部分使用卷积神经网络VGG检测准确率最高。在VGG19中加入批量归一化层可以抑制过拟合并提高整个模型的泛化能力,VGG19_bn 较VGG19 准确率平均高出1.12%。而结构相对复杂的网络ResNet、EfficientNet和Iception_v3使整个检测框架过于复杂,出现过拟合现象。因此本文实验选取VGG19_bn网络提取帧内特征。
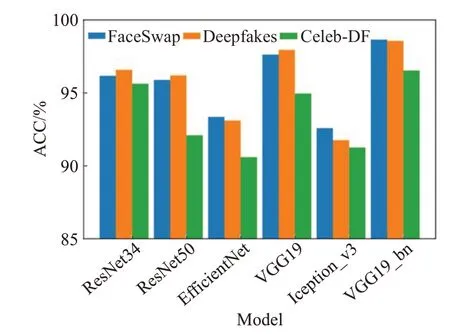
图5 各空间提取网络ACC柱状图Fig.5 Histogram of ACC of network extraction in each space

图6 各空间提取网络AUC柱状图Fig.6 Histogram of AUC of network extraction in each space
3.4.2 参数选取
本文在训练网络模型时选取focalloss 作为损失函数,其中α、γ两个参数取值不同会产生不同结果。为了更加直观地体现结果,在Celeb-DF 数据集上测试参数对ACC和AUC的影响,结果如图7、图8所示。

图7 α 和γ 对ACC的影响Fig.7 Influence of α and γ on ACC
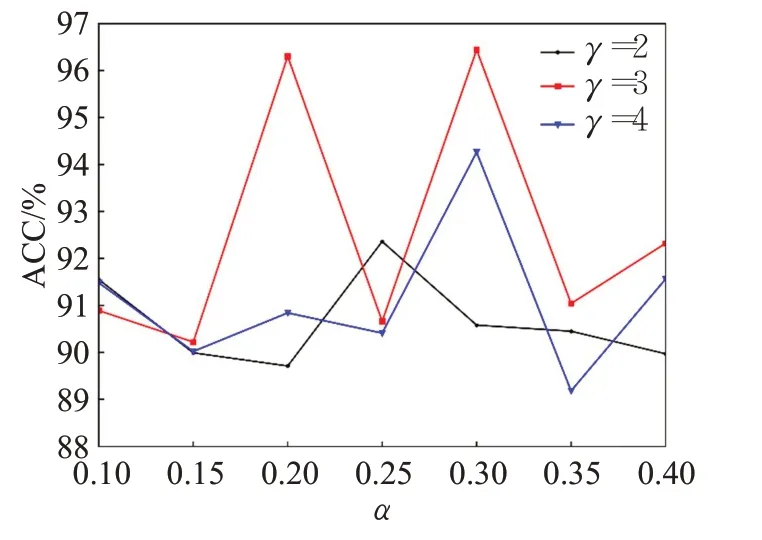
图8 α 和γ 对AUC的影响Fig.8 Influence of α and γ on AUC
本文共选取28组参数进行测试,α取值为0.1~0.4;γ取值为2、3、4。当固定某一参数时,ACC或AUC未出现明显线性变化规律;当α=0.3,γ=3 时,ACC 和AUC均取到最大值分别为96.54%和96.44%,因此本文选取(0.3,3)作为focalloss的参数值。
3.4.3 模型改进对比
本文将文献[8]作为基本网络,探究每种改进对准确率ACC 的影响。实验结果如表3 所示。为了能够更直观地显示各方法的性能,使用在三个数据集中的验证集进行50轮的测试数据进行绘图。由图9、图10和图11可知,与Baseline 相比,每种改进在三类数据集中准确率都有较为明显的提升,从整体看Celeb-DF 上收敛速度要比FaceSwap和Deepfakes快。

图9 Deepfakes数据集中改进对比Fig.9 Improvement and comparison of Deepfakes dataset

图10 FaceSwap数据集中改进对比Fig.10 Improvement and comparison of FaceSwap dataset

图11 Celeb-DF数据集中改进对比Fig.11 Improvement and comparison of Celeb-DF dataset
由表1 可知,在Baseline 中加入GRU 后,得益于可以充分地学习经过CNN 后特征的时序信息,模型的准确率平均提升了1.97个百分点;在CNN中引入Involution算子平衡了空间信息和通道信息之间的精度效率,模型的平均准确率提升了1.70个百分点;使用focalloss函数调整正负样本的权重以及简单样本和难样本的权重后,模型的平均准确率提升了0.81个百分点。在实验中还将LSTM 与GRU 进行对比,最终检测效果不相上下,但是就网络权重参数来说LSTM 是GRU 的1.03 倍,GRU 训练效率也更高,因此本文最终选取GRU进行训练和测试。

表1 每种改进对准确率的影响Table 1 Influence of each improvement on accuracy
3.4.4 与主流算法对比
为了验证本文检测方法的性能,以ACC 和AUC 作为指标,选取文献[6-7,16,22]中五种算法在两种或三种数据集上进行对比。五种检测算法分别为使用生物信号、双流网络、S-MILS-MIL-T和CNN-LSTM网络结构,结果如表2所示(“—”表示在文献中未给出该数值)。

表2 各方法的准确率Table 2 Accuracy of each method
如表2 所示。本文在三类数据集上的性能综合强于其他算法,文献[6]通过对比真假视频中眼睛和凝视时的特征差异进行检测,只能学习部分特征,不能充分学习全局特征,因此检测准确率较低。文献[16]中帧级别和时间级别的双流网络提取空间和时间特征进行检测,在三类数据集上差异较大,稳定性较低。文献[7]引入一个新的偏导数,提出两个网络,在Celeb-DF数据集上准确率较高,但是在另两个数据集较差。文献[22]使用CNN-LSTM混合模型先提取空间特征再学习时序特征进行检测,但对空间特征学习不充分。本文所提方法在使用GRU 的同时使用Involution 算子对空间特征进行加强,并且使用focalloss 函数作为损失函数,较其他方法平均准确率高,稳定性强,证明了其有效性。
3.4.5 跨库检测
为了更明确地分析网络模型的泛化能力,本文使用跨库检测方法进行准确率ACC 检验,分别在三个不同数据集上进行训练,并在另两个数据集上进行测试。
如表3所示,使用Celeb-DF训练的网络模型测试另外两个数据集上的表现优于在FaceSwap 和Deepfakes上训练的网络模型,但是整体跨库检测显效甚微,甚至在个别数据集中比随机猜测的准确率还低。这是由于不同数据集中并不完全使用同一种伪造算法,并且视频质量参差不齐,致使网络模型跨库检测能力差。这一问题是目前深度伪造检测领域乃至深度学习面临的一大难题,也是需要广大研究者未来研究和克服的重点之一。
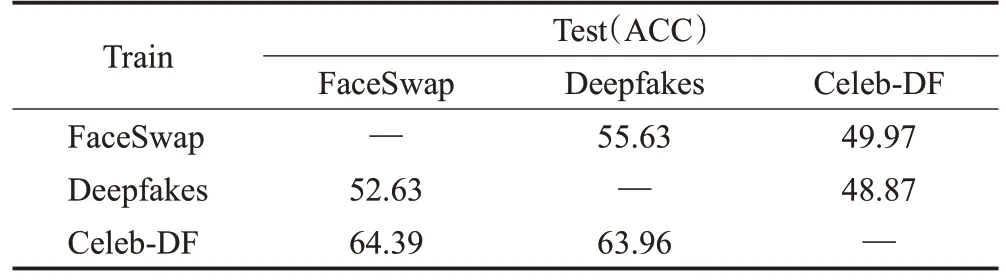
表3 泛化能力分析Table 3 Generalization ability analysis 单位:%
4 结论和展望
本文提出一种GRU 和Involution 改进的深度伪造视频检测方法,探究提取空间特征和时序特征在深度伪造视频检测领域的效果。选取VGG19_bn 并引入Involution 算子加强人脸图像的空间建模能力,随后使用主胶囊层关注位置信息和使用GRU 提取时序特征。在模型训练时,损失函数使用focalloss有效地提高了检测准确率和调整了样本平衡。经实验证明,本文的检测方法在Deepfakes、FaceSwap 和Celeb-DF 数据集上较主流方法在ACC 和AUC 上均有明显提升。在模型改进前后进行对比实验,证明了各个改进模块所带来的增益,最后进行跨库检测,但存在实验结果远不如在同一数据库中训练并测试的问题。随着各种Deepfake 生成技术逐步成熟,检测工作将会面临更加严峻的考验。接下来会对本文所提模型从泛化能力方面继续完善,并且关注其他提取时序特征的方法并进行优化。
猜你喜欢
Journal of Traditional Chinese Medicine(2022年5期)2022-11-16 01:54:34
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
Journal of Traditional Chinese Medicine(2021年6期)2021-08-09 12:36:44
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
