
基于残差门控图卷积网络的源代码漏洞检测
2023-11-27 05:35:42李山山王浩宇
计算机工程与应用 2023年22期
张 俊,李山山,李 磊,王浩宇
武汉工程大学 智能机器人湖北省重点实验室,武汉430205
21世纪公共漏洞披露CVE(common vulnerabilities and exposures)公开发表的报告表明,软件漏洞数量正在迅速增加,这些软件漏洞是网络空间中遭到安全攻击的主要原因,对社会造成严重的经济损失。如2017年,WanaCry病毒勒索软件利用操作系统的一个漏洞,对全球造成了约80亿美元的损失。并且传统的漏洞检测方法面临着技术瓶颈,无法保障网络空间安全。因此,如何自动化检测漏洞是一个严峻的挑战。
面对挑战,目前漏洞检测方法除了包含模糊测试[1]、静态分析[2-3]、动态分析[4-6]这些方法之外,学术界也引入了一些更加新颖的方法,如引入了机器学习方法来辅助或者代替人工进行漏洞分析。早期的机器学习方法[7-9]主要是人工设计漏洞特征来检测漏洞,然而这些方法也存在部分缺点,即设计漏洞特征往往需要专家花费大量时间,同时也存在主观性因素,而且设计的漏洞特征无法包含新产生的漏洞[10]。采用这些机器学习方法的静态分析工具检测的结果会产生较高误报率和漏报率问题。如Coverity 等商用静态分析工具可被接受的最大误报率为20%[11],目前已知的应用挖掘所得的构件行为模型进行漏洞检测最低误报率为25%[12],文献[13-14]实验结果中的误报率更是高达50%和62.5%。
因此,为了降低现有方法的误报率和漏报率,同时也避免人类专家在特征提取方面的大量劳动,学术界研究如何将深度学习应用到漏洞检测中,从而使得检测方法更加自动化[15-17]。目前,一些做法是将每个源代码视为一种自然语言序列,并应用到自然语言处理的深度学习架构中,如LSTM(long short-term memory)[18]、BERT(bidirectional encoder representations form transformers)[19]和CNN(convolutional neural network)[20]。基于深度学习的漏洞检测可以自动生成漏洞特征,从而缓解人类专家手工定义漏洞特征的需求。李珍等人[21]提出了第一个使用深度学习的系统框架来检测C/C++源代码程序中的漏洞。该方法将代码片段视为一段序列,通过RNN(recurrent neural network)对序列进行分类,但由于源代码具有丰富的语义结构信息,这种方法忽略这些语义结构特征,存在较大的信息损失。因此如何提取源代码的语义结构特征,把源代码转换成具有综合语义、适合神经网络训练的数据形式是关键问题之一。
最近,学术界又将图神经网络应用到代码漏洞检测中。图神经网络(graph neural networks,GNN)是处理图数据神经网络的统称,是将节点和图嵌入到低维连续向量空间的主要表示方法[22-24]。由于图结构强大的表示能力,GNN在处理文本分类等任务时,效果可以达到更佳[25-28]。基于图的代码表示方法包含了源代码丰富的语义结构特征,可以将源代码编码成具有综合语义信息的向量。
鉴于已有的静态分析漏洞检测方法存在准确率、召回率等不高的问题,本文提出了一种基于残差门控图卷积网络[29]的源代码漏洞检测方法。使用残差门控图卷积网络可以缓解随着网络的深度增加造成的梯度消失问题,在一定程度上可以提高模型性能。方法首先通过提取源代码的抽象语法树结构信息,以边的形式保存在图数据中,同时把抽象语法树节点的出度作为图节点的初始实值向量,结合两者将源代码转换成图结构数据样本,然后使用残差门控图卷积神经网络进行表示学习后,再使用神经网络来预测代码漏洞。实验结果显示,本文设计的方案在VDISC数据集上取得了比基线方法更高的准确率、F1得分,降低了误报率和漏报率。
1 方法设计
本文的方法架构如图1所示,它包含三部分:(1)数据处理部分,由于源代码数据集中数据存在分布不均的问题,对数据进行下采样操作,使得数据分布均匀。(2)提取抽象语法树部分,通过提取代码的抽象语法树,并在抽象语法树的基础上增加语义、结构信息,来构建代码图。(3)残差门控图卷积网络部分,将代码图作为模型的输入,提取漏洞特征之后,利用神经网络来预测源代码中是否含有漏洞。

图1 方法架构Fig.1 Method structure
本文的模型架构如图2所示,它包含四部分:(1)复合源代码语义的代码图表示层,将一个函数的初始源代码编码成一个具有综合程序语义的代码图。(2)残差门控图卷积网络层,该层的作用是聚集和传递图中相邻节点的信息来学习节点的特征。(3)图池化层,作用是聚合图的全局信息,得到一个可以表示全图特征的向量。(4)全连接层,作用是对提取的特征向量进行特征整合,最后得到预测值0 或1,0 代表没有漏洞,反之1 则代码含有漏洞。
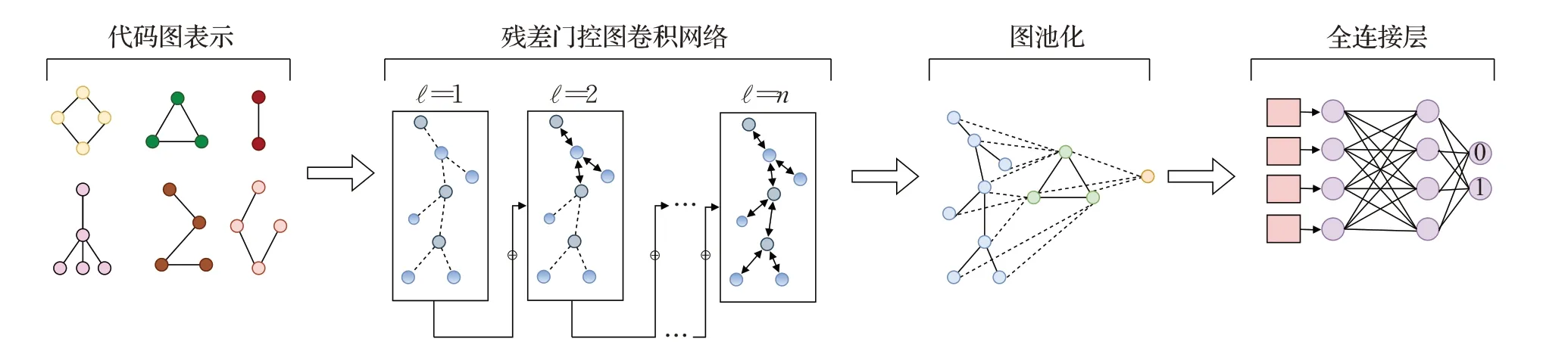
图2 模型架构Fig.2 Model architecture
1.1 问题定义
漏洞检测是判别源代码中的某个函数是否含有漏洞,因此可以把漏洞检测视为一个二分类问题。用数学语言来描述,把数据样本定义为{(ci,yi)|ci∈C,yi∈Y},i∈{1,2,…,n},其中C代表源代码数据集,Y={0,1}n代表标签集,1意味当前样本含有漏洞,反之0意味当前样本不具有漏洞,n为样本的数目。ci被定义为一个函数,并为每一个ci构建一个图gi(V,X,A) ∈G。其中V是图中的m个节点,X∈Rm×d是图中节点的特征矩阵,每个节点vj∈V由一个d维实值向量xj∈Rd表示。A∈{0,1}m×m是一个邻接矩阵,Ai,j值为1代表节点i与节点j之间有一条边连接,反之Ai,j值为0 则代表节点i与节点j之间没有边连接。结合本文任务,可以归纳出是学习一个从G 到Y的映射关系,用函数表达f:G →Y,由此来预测一个数据样本是否含有漏洞。映射函数f可以通过最小化损失函数的方式来学习,如式(1)所示。
其中,L(·) 是交叉熵损失函数,ω(·) 是正则化,λ是可调节权重。
1.2 代码图表示
本文以抽象语法树为基础来构建代码图,使用提取AST的工具为Clang编译器。图3所示为提取AST的一个示例,从根节点开始,代码被解析成变量声明、函数名称、复合语句、代码块、运算符操作等。如图3中的节点1为函数声明,节点2 为类型,节点5 为复合语句,节点7为变量,节点8为判断语句,节点9为返回语句,节点10为运算操作等。父节点与子节点之间有一条边连接,同级节点之间有一条虚边连接,实际转换成代码图表示中同级节点没有边相连。
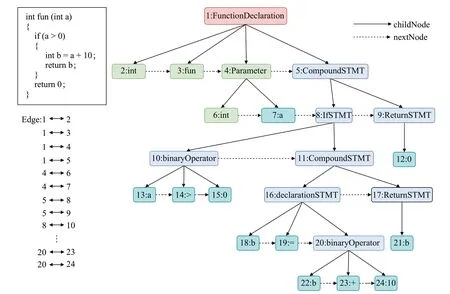
图3 抽象语法树Fig.3 Abstract syntax tree
在代码图中,用一个邻接矩阵来存储图数据,图中的节点为AST中节点,AST节点中的父子关系则为图的边,例如邻接矩阵A,其中Ai,j=1,意味着节点i与节点j之间有一条无向边连接,反之则无边相连。
在实值向量初始化上,采取的方法是通过节点的出度作为初始值,图3中,节点1的出度为4,节点2的出度为0,节点4的出度为2等。
1.3 残差门控图卷积神经网络
自从图神经网络(GNN)首次被提出以来,在处理图结构数据上得到了广泛的应用,如提取和发掘图结构数据的特征和模式,从而满足聚类、分类、预测、分割、生成等图学习任务需求。GNN核心思想是通过聚合图中节点vi的特征xi与它的邻居节点特征xj来生成节点vi新表示。基于不同聚合节点的信息的方法,诞生了图卷积网络(graph convolution networks,GCN)[30]、图注意力网络(graph attention networks,GAN)[31]、门控图神经网络(gated graph neural networks,GGNN)[32],以及残差门控图卷积神经网络(residual gated graph ConvNets,RGGCN)[29]等。本文选择残差门控图卷积神经网络来学习图节点特征。用数学语言来描述,给定一个图gk(V,X,A),对于每个图中节点vi∈V都有一个初始D维向量,表示为当前节点的特征向量,如果实值向量xi的维度小于D时,则用0 填充,即[,0]T,则用式(2)描述为:
其中{:j→i} 表示节点i的所有邻接节点的特征向量f为映射函数,输入为当前节点的特征矩阵和当前节点所有邻接节点的特征矩阵{→i},ℓ为层数,W为权重矩阵。可以用式(3)描述为:,
其中⊙为哈达玛积,ηi,j表示边的门控机制,ηi,j的计算公式如式(4)所示:
其中σ表示为Sigmoid函数。
1.4 图池化
对于图神经网络而言,在传播阶段图的结构不会改变,改变的只是节点的特征向量,因此需要聚合图的全局信息,得到一个可以表示全图特征的向量,后续对该向量进行分类回归操作,因此需要对图进行池化操作。本文选取的是全局池化,其操作公式如式(5)所示:
其中R为池化函数,本文选取的是max、mean 函数,如式(6)所示:
其中cat(·) 为拼接函数,按列拼接,最后采用MLP(multilayer perceptron)进行特征整合,用式(7)描述为:
yi为最后的预测向量。
2 实验设计与结果分析
2.1 数据集
数据集部分采用Draper VDISC Dataset-Vulnerability Detection in Source Code[33]数据集,该数据集包括从开源软件中挖掘出的127万个函数的源代码,通过静态分析对潜在漏洞进行标记。使用标记的工具包括Clang、Cppcheck 和Flawfinder。在标记之后,数据集的作者做了大量的工作来清理数据集重复的数据并去除错误的标签。数据集中存在的漏洞类型为CWE-119(内存缓冲区操作越界)、CWE-120(缓冲区溢出)、CWE-469(非法指针相减)、CWE-476(空指针引用)以及CWE-OTHERS(变量未初始化,以不正确的长度值访问缓冲区等)。由于样本数量庞大,有漏洞的函数占比较少,数据分布不均,因此对数据采用下采样的方法,使得数据均匀分布。数据集样本统计如表1所示,下采样后数据样本统计如表2所示。
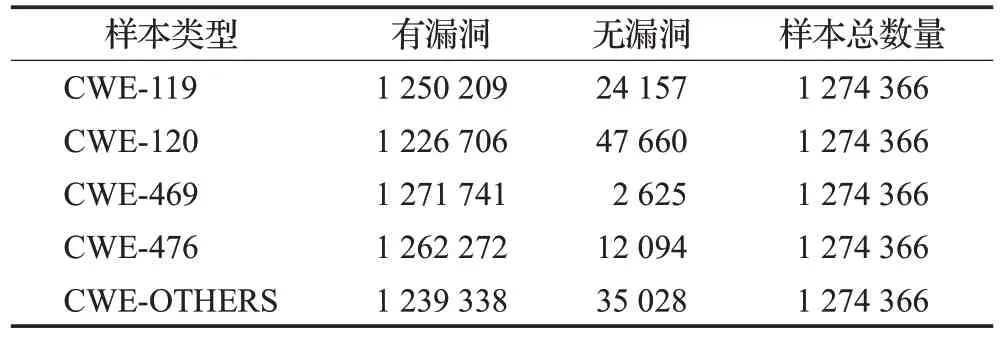
表1 漏洞数据集Table 1 Vulnerability dataset
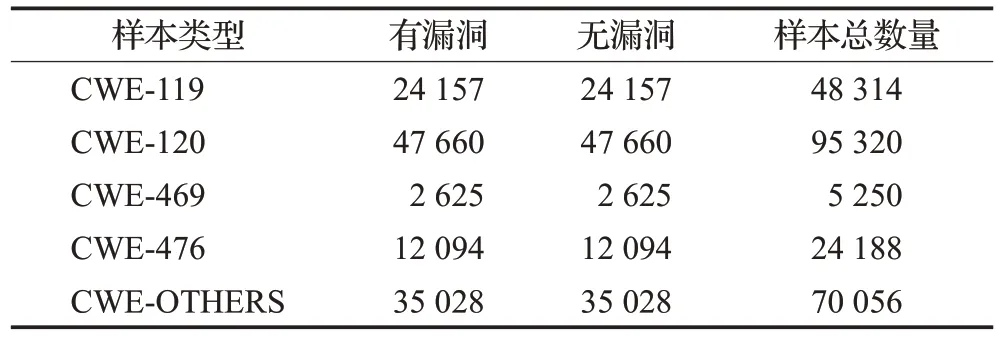
表2 下采样后漏洞数据集Table 2 Under-sampling vulnerability dataset
2.2 基线方法
为了验证本文方法的优越性,将本文方法与VulDeePecker[15]、TextCNN[20]、GGNN[32]、文献[34]进行对比实验,综合评估本文方法的性能。具体的数据处理过程如下所述。
VulDeePecker首先提取库/API函数调用,并进行前向切片,获取了相关代码片段之后,组装成codegadget并标注该codegadget是否具有漏洞,之后利用word2vec对其向量化,最终将向量输入到BiLSTM 神经网络,进行模型训练。
TextCNN 将整个函数视为单位,利用word2vec 对函数进行向量化,之后输入到网络结构为一层卷积和一层max-pooling以及一个softmax层的TextCNN网络,其中设置词向量维度为1 000,序列长度为500,类别为2。
GGNN方法使用本文方法的代码图表示方法,将函数转换成向量之后,输入到out_channels 为128 的6 层GGNN网络中,聚合函数为add,并经过一个Dense层汇聚网络信息。
文献[34]方法也就是本文使用数据集中论文的方法,该方法使用分词器将函数向量化,就是基于one-hot编码将函数向量化,之后将其输入到带有高斯噪声的CNN中进行训练。
2.3 实验设置
对于数据集而言,采用8∶1∶1 的比例来划分训练集、验证集以及测试集,网络结构采取3 层的残差门控图卷积,BatchSize 设置为256,学习率设置为0.001,损失函数为二分类交叉熵,同时选择Adam优化器训练模型,迭代次数为100。
2.4 实验结果
2.4.1 采样实验结果与分析
从表1中可以看到,无漏洞的函数占比远远多于有漏洞的函数,而本文更关心的是有漏洞的函数,这时数据分布不均会更加突出。在这种数据分布下,训练出的模型显然更加趋向预测无漏洞的函数,在数据集中,有漏洞的函数会被当成噪点或者被忽略,相比无漏洞的函数,有漏洞的函数被预测为无漏洞的函数可能性非常大。为了验证这一结果,使用本文方法对下采样后数据集和未采样的数据集分别进行实验,实验结果如表3所示。

表3 采样对比实验结果Table 3 Results of sampling comparison experiments单位:%
表3中,未采样的数据集虽然在准确率方面均高于下采样后的数据集,但是F1 得分均低于下采样后的数据集。这是由于未采样的数据集无漏洞的函数占比太大,模型训练之后更倾向预测无漏洞的函数,而有漏洞的函数往往无法被正确地预测出来,导致了较高的误报率和漏报率。下采样后的数据集可以使得数据均匀分布,在一定程度上,可以避免这种问题,与未采样的数据集相比,下采样后的数据集在使用本文方法进行实验后,得到了较高的F1得分,有效地降低了误报率和漏报率。
2.4.2 对比实验结果与分析
实验表明,本文提出的基于抽象语法树的代码图提取与残差门控图卷积网络模型结合,在VDISC 数据集中漏洞检测的综合效能高于对比模型。
本文使用准确率和F1 得分来评估模型性能,并用其他模型最高评估指标与本文方法进行比较。表4 展示了所有实验结果。从表中可以看到,检测漏洞类型CWE-119 时,本文方法准确率为76.00%,F1 得分为76.60%,准确率比文献[34]方法高了3.42 个百分点,F1得分比GGNN 方法高了5.67 个百分点。检测漏洞类型CWE-120 时,本文方法准确率为69.91%,F1 得分为70.94%,准确率比GGNN方法高了4.42个百分点,F1得分比文献[34]方法高了3.71 个百分点。检测漏洞类型CWE-469 时,本文方法准确率为75.42%,F1 得分为74.95%,准确率比GGNN方法高了2.27个百分点,F1得分比文献[34]方法高了4.03 个百分点。检测漏洞类型CWE-476 时,本文方法准确率为60.38%,F1 得分为64.86%,准确率比文献[34]方法高了3.06 个百分点,F1得分比GGNN 方法高了2.03 个百分点。检测漏洞类型CWE-OTHERS 时,本文方法准确率为67.01%,F1 得分为64.82%,准确率比文献[34]方法高了1.26 个百分点,F1 得分比文献[34]方法高了2.43 个百分点。综合评估指标来看本文方法优于基线方法。
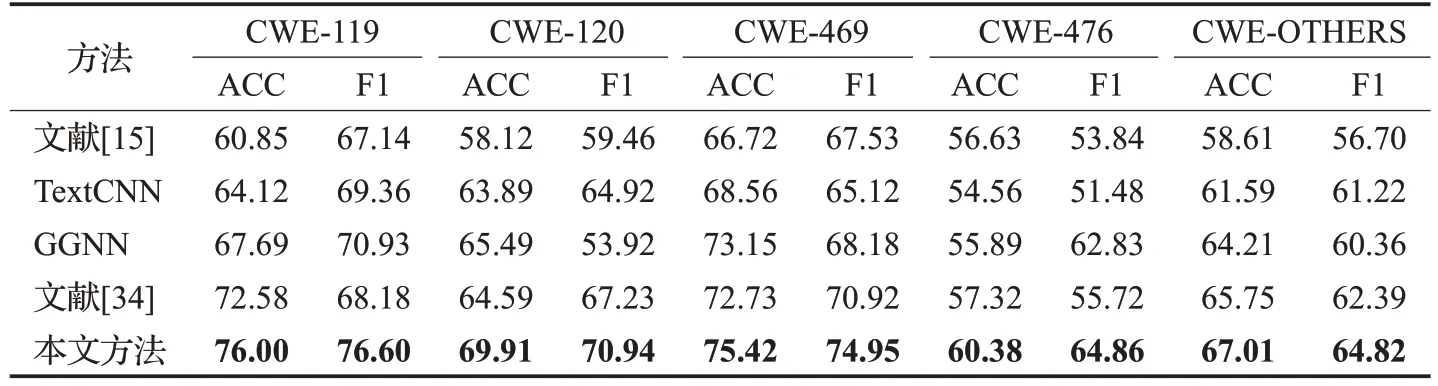
表4 基线实验结果Table 4 Baseline experimental results单位:%
ROC(receiver operating characteristic)曲线是根据一系列不同的二分类方式,以真阳性率为纵坐标,假阳性率为横坐标绘制的曲线。ROC曲线图是衡量分类结果好坏的一种评判方法。ROC曲线与坐标轴围成的面积为AUC值,取值范围为0.5~1.0之间,对应AUC越大,则说明分类器效果越好。图4~图8 是本文方法与基线方法的ROC曲线图。
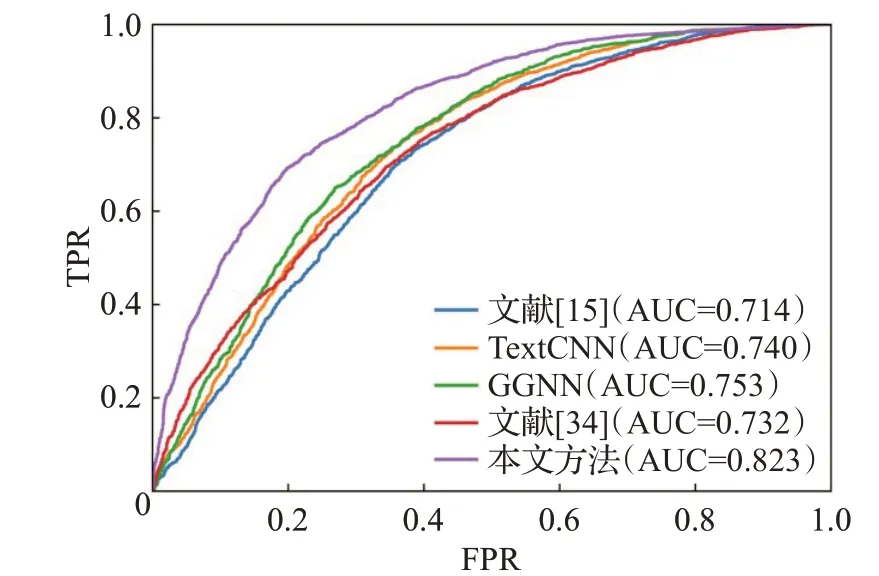
图4 CWE-119 ROC曲线Fig.4 CWE-119 ROC curves
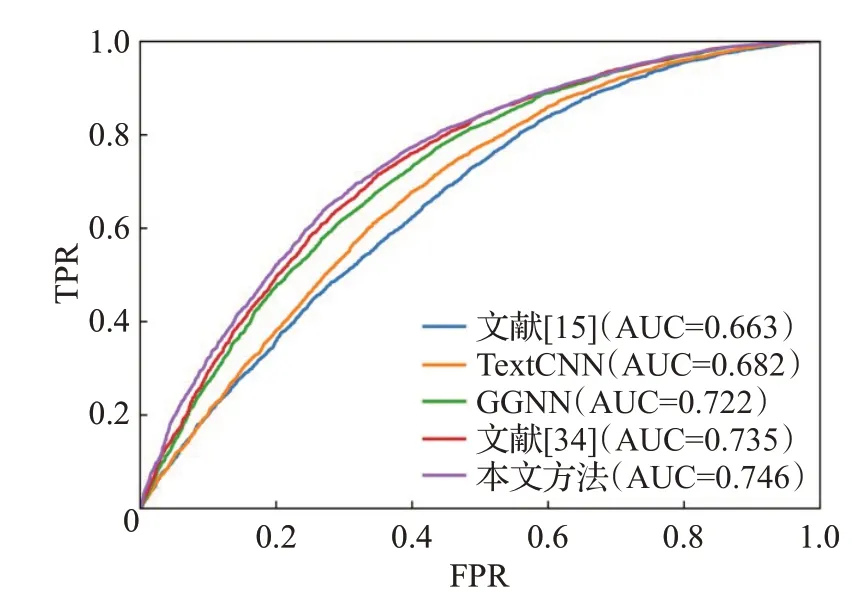
图5 CWE-120 ROC曲线Fig.5 CWE-120 ROC curves
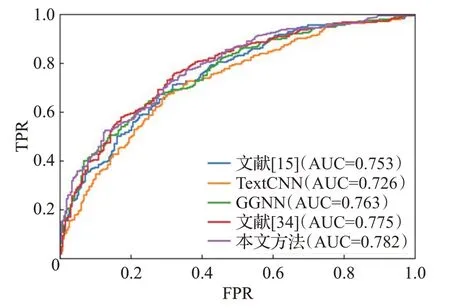
图6 CWE-469 ROC曲线Fig.6 CWE-469 ROC curves
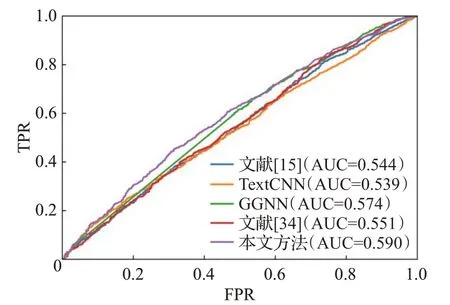
图7 CWE-476 ROC曲线Fig.7 CWE-476 ROC curves
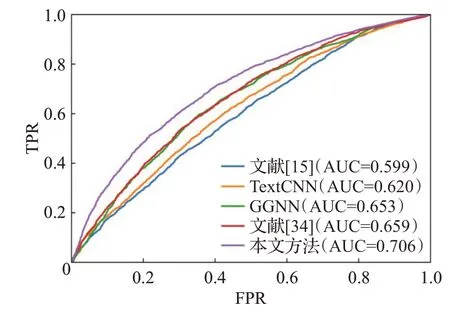
图8 CWE-OTHERS ROC曲线Fig.8 CWE-OTHERS ROC curves
如图4~图8所示,在5种类型的漏洞检测中本文方法的AUC值均高于基线方法,由此可见,本文的代码图表示方法和图学习模型在漏洞检测上更加有效。
本文通过抽象语法树对代码进行编码,使用残差门控图卷积网络学习代码的漏洞特征,结合多层感知机来检测漏洞,提高了自动检测代码漏洞的能力。
3 结束语
本文提出了一种基于残差门控图卷积神经网络的源代码漏洞检测方法。首先,构建源代码的抽象语法树,利用抽象语法树的层次关系来构建代码图,并且结合抽象语法树节点的出度作为图节点实值向量的初始值。其次,把第一步得到的源代码图表示,作为残差门控图卷积神经网络的输入,利用该模型来进行信息传播和聚合,提取源代码的特征,并通过池化来聚合图的全局信息。最后,利用MLP 来对得到的特征向量进行特征整合,从而实现源代码漏洞检测。实验表明,在VDISC数据集中,本文方法在5 种漏洞类型检测中,F1 值均高于基线方法,有效提高了准确率以及自动化漏洞检测能力,进一步降低了误报率与漏报率,表明了本文方法是有效的。
本文方法只能检测出函数中是否含有漏洞,无法检测出漏洞所在的行,检测的粒度不够细,因此未来的工作将在更细粒度的漏洞检测上展开。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
今日农业(2022年13期)2022-09-15 01:21:08
现代信息科技(2021年21期)2021-05-07 21:44:50
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
中国司法鉴定(2018年4期)2018-07-30 06:08:26
中国卫生(2016年5期)2016-11-12 13:25:28
儿童时代(2016年6期)2016-09-14 04:54:43
