
AdfNet:一种基于多样化特征的自适应深度伪造检测网络
2023-11-24 01:40李家春李博文林伟伟
华南理工大学学报(自然科学版) 2023年9期
李家春 李博文 林伟伟
(华南理工大学 计算机科学与工程学院,广东 广州 510006)
随着计算机视觉领域的快速发展,通过数字操作生成虚假视频和图像的深度伪造技术,如Deepfakes[1],已经走到了公众关注的前沿。深度伪造可以将名人的面孔转变成色情视频,并被用来伪造新闻、恶作剧和财务欺诈,甚至是世界领导人的虚假演讲视频,对世界安全构成了威胁。因此,设计一个通用、实用的深度伪造检测模型至关重要。
近年来,基于深度学习的方法在深度伪造检测领域取得了令人瞩目的成绩[2-5]。大多数提出的检测伪造人脸的方法利用从空间域提取出的语义特征判别伪像,尤其是在RGB 中。Cozzolino 等[6-7]在浅层CNN架构中使用手工特征,但该方法的检测性能对数据集的质量或数据分布非常敏感,当通用特征提取器应用于伪造检测时,早期工作的表现就显得不尽如人意。Afchar等[8]设计了多个小型卷积模块来捕捉被篡改图像的微观特征,提出的Mesonet架构可以有效地检测深度伪造并降低计算成本。Chollet[9]展示了强大的通用特征提取器XceptionNet在多种伪造算法上的最佳性能。几乎所有这些基于CNN的方法都偏向于特定方法的语义特征,导致泛化性能不佳。
除了关注语义特征外,一些方法还利用纹理特征来捕捉伪造的人工制品。Masi等[10]使用多尺度拉普拉斯算子(LoG)抑制低级特征图中存在的图像内容,充当带通滤波器以放大伪影,通过牺牲帧级检测精度提升了跨数据集的检测性能;Zhao等[11]通过减去图像低频信息增强浅层的纹理特征,并引入区域独立损失协助网络训练,但在高强度压缩下检测性能大幅下滑,并且模型泛化能力不佳;Wu 等[12]通过带有一个中间块的简化XceptionNet 作为骨干网络来提取纹理特征,但忽略了平均池化所带来的负面影响。
最近出现了几种基于时序特征的人脸伪造检测方法。Güera 等[13]提出一种可感知时间的管道,首先使用卷积神经网络提取帧级特征,然后将这些特征用于训练递归神经网络;Sabir 等[14]证明了递归卷积模型和面部对齐方法的组合可以改善现有技术的水平,结果显示基于关键点的人脸对齐与特征双向递归传递对视频的篡改检测最佳。但目前的方法对不同的时间序列分配相同的权重,这对网络的训练是不利的。
上述方法在深度伪造检测领域已经取得了巨大进步,但仍然存在许多缺陷。大多数基于纹理信息的检测方法都是利用特定的初始约束条件来捕捉特征,往往只能有效地捕捉到特定频段信息,无法灵活运用在不同篡改算法生成的深度伪造上。此外,虽然许多双流网络被用来提取纹理和语义信息进行学习,但它们没有充分利用不同特征间的优势。事实上,从浅层纹理中提取的噪声残差可以有效地突出篡改痕迹,引导语义分支探索可疑区域的深层特征。另外,注意力机制对时序网络的提升也很容易被研究人员忽视,因为伪造视频需要以一种连贯的方式处理所有帧,由人脸篡改引起的低级伪影预计会进一步表现为具有帧级不一致的时间伪影,检测时对不同时间序列应分配不同权重。
针对上述问题,本文提出一个基于多样化特征的自适应网络AdfNet用于深度伪造检测。该方法从避免采用固定约束和引入多样化特征两方面入手。首先,设计了一种具有多样化特征的自适应网络架构;然后,提出了一种自适应纹理噪声提取机制(ATNEM),利用未池化的特征映射和基于频域的通道注意力机制,灵活提取非固定频段的噪声残差;接着,研究了一种深层语义分析指导策略(DSAGS),通过噪声残差生成的空间注意力图来突出篡改痕迹,并引导深层网络聚焦于特定的可疑区域;最后,设计了一种多尺度时序特征处理方法(MTFPM),利用注意力机制给时间序列分配不同权重,有效捕获不同特征间的帧级差异。本文还通过消融实验验证主要模块的有效性,在跨数据集评估中,验证所提出的方法在保持数据集内高检测性能同时的泛化性。
1 方法
1.1 AdfNet的框架
本文提出的网络框架如图1所示。首先,将连续帧的图像送入篡改残差提取单元,语义特征(上)和纹理特征(下)分别从RGB 图和灰度图中提取。本单元设计了一种自适应纹理噪声提取机制(ATNEM)来捕获基于频域通道注意力机制的纹理残差,防止有效噪声被过滤,从而自适应地学习非固定频段的噪声残差。接着,将RGB 特征图Fr和噪声特征图Fn传送到篡改残差分析单元,分析得到语义特征图Fh和纹理特征图Fl。本模块提出了一种深层语义分析指导策略(DSAGS),它利用ATNEM 提取出的噪声残差所产生的空间注意力机制来指导语义分析块集中在特定的可疑区域。然后,Fh和Fl被输入到篡改残差聚合单元。其过程如下:①采用多尺度时序特征处理方法(MTFPM)生成两种不同类型的时序特征,即语义-时序特征图h和纹理-时序特征图。MTFPM利用具有注意力机制的双向时序网络来学习不同特征间的帧级差异。②用融合模块将和合并,将这些带有噪声残差的不同特征汇聚到一个广义的特征空间,用于深度篡改检测。最后,进行真假分类。
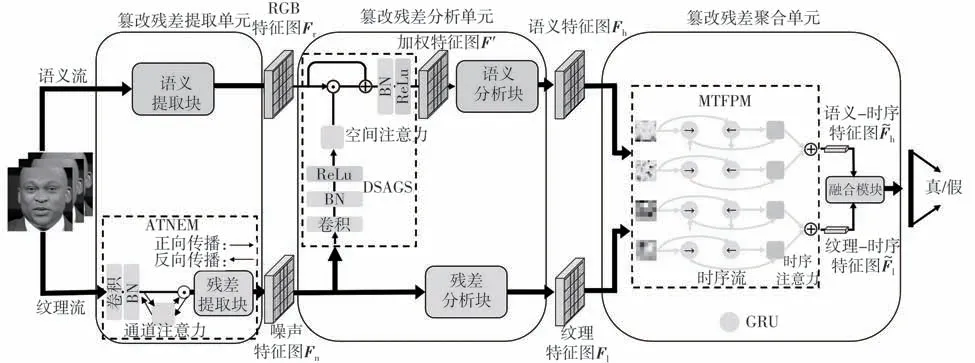
图1 AdfNet的框架Fig.1 Framework of AdfNet
1.2 ATNEM:自适应纹理噪声提取机制
ATNEM 的处理流程如图2(a)所示。目前的纹理特征提取方法中,通道注意力机制中的全局平均池化(GAP)和特征映射中的平均池化层被视为一个低通滤波器,将过滤掉图像中的高频噪声,导致篡改痕迹被人为丢失,影响后续检测;此外,它们使用固定频段滤波器的通道注意力只保留了特定的信息。因此本文提出了如下改进方法:在整个模块中放弃平均池化,并设计一种自适应频域通道注意力机制(AFCA),如图2(b)所示。在AFCA 中用二维离散余弦变换(DCT)代替GAP,使用残差来确定通道权重,并在ATNEM 中学习非固定频段的噪声残差。纹理特征通道的权重(wc)可由式(1)推出:
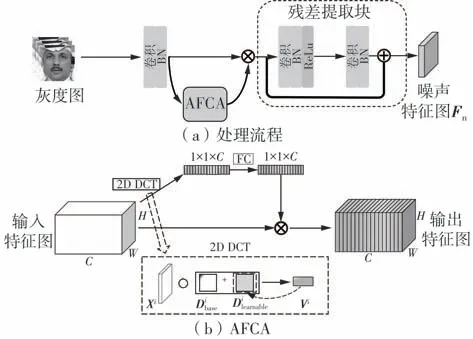
图2 自适应噪声残差提取机制示意图Fig.2 Schematic diagram of adaptive noise residual extraction mechanism
1.3 DSAGS:深层语义分析指导策略
ATNEM提取的噪声特征图Fn经卷积核下采样,生成与RGB 特征图Fr同维度的特征图Fg。接着,Fg的通道维度被最大池化和平均池化,再经过一个7 × 7的卷积层,生成与残差相关的空间注意力图,以更好地引导高级语义特征流探索关键区域的深层特征。该空间注意力图与RGB 特征图形成跳跃连接,对不同像素点位赋予权值,得到加权特征图F',如图3所示。其计算公式如下:
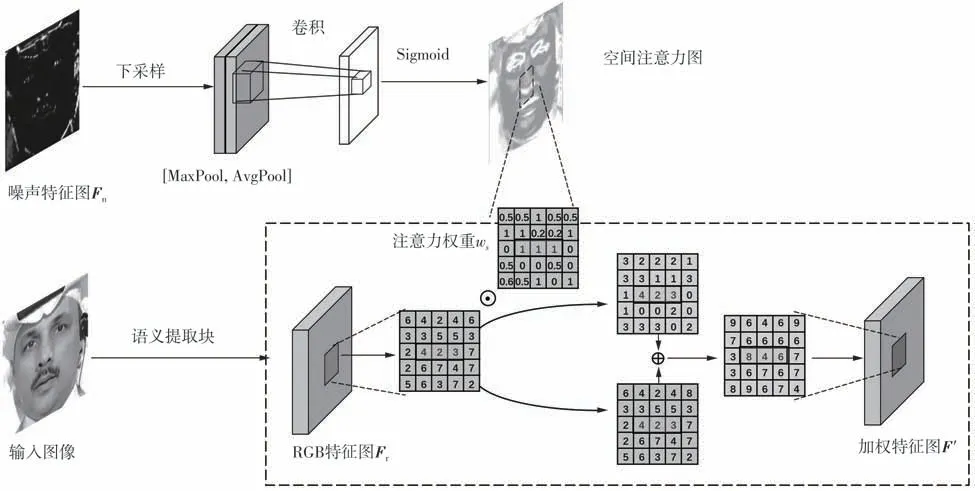
图3 深层语义分析指导策略示意图Fig.3 Schematic diagram of deeper semantic analysis guidance strategy
式中,down(·) 表示向下采样,AvgPool(·) 和MaxPool(·)分别表示平均池化和最大池化,f7*7表示滤波器大小为7 × 7的卷积操作。
1.4 MTFPM:多尺度时序特征处理方法
为了提高时序网络捕捉帧级差异的能力,本文选择具有注意力机制的双向GRU 分别训练高级和低级特征。相较于LSTM,GRU 在性能相持下计算量更低,也更易收敛,双向GRU 则能更好地捕获双向流的依赖信息;时序注意力机制可以关注不同时序的重要性,为不同时序赋予不同的权重。由于语义特征图Fh和纹理特征图Fl分别来自不同的操作,包含不同的信息,因此在融合前先进入残差聚合单元以得到更丰富的多尺度时间特征。多尺度时序特征处理流程如下。
首先,计算特征图Fx在t时刻的隐藏层状态Sxt为
接着,计算Fx的时序权重wxt,wxt∈[0,1]:
式中,uxt=tanh(Sxt),tanh 为激活函数,以增强网络的非线性变换能力,uv为随机初始化的注意力矩阵。这样,输入Fl与Fh,由式(3)和(4)可得到Slt、wlt以及Sht和wht。
接下来,由上述隐藏层状态和时序权重计算可以得到纹理-时序特征图和语义-时序特征图:
最后,将不同特征图放入融合模块得到最终的融合特征图F:
式中,融合模块 fusion(·)采用的是注意力特征融合方法。
2 实验
2.1 实验设置
2.1.1 数据集
本文使用FaceForensics++(FF++)[15]和Celeb-DF[16]两个数据集。FF++是深度伪造检测领域最常用的数据集,包含了1 000 个来自互联网的真实视频,每个真实视频对应一个由5种不同操作方法生成的深度造假视频,即Deepfakes(DF)、NeuralTextures(NT)、FaceSwap(FS)、Face2Face(F2F)和FaceShifter(FSH),其中F2F 和FS 基于计算机图形法生成,DF、NT 和FSH 基于学习法生成,为保证实验篡改方式均衡,本文在FF++整体测试中没有将FSH放入。本实验测试使用FF++的轻度压缩HQ(默认模式)和重度压缩LQ 版本,训练集选用740 个视频,验证和测试集均使用140 个视频;同时选用518个视频作为Celeb-DF分类测试集。
2.1.2 评价指标
本文主要使用如下评价指标评估检测性能。
(1)准确度分数ACC
ACC(RACC)的计算公式如下:
式中,TP 为真阳性,TN 为真阴性,FP 为假阳性,FN为假阴性。
(2)ROC曲线下面积AUC(RAUC)
AUC可直观地评价不同数据集的性能,计算公式如下:
式中,ranki为 第i个样本的序号,表示只将正样本的序号相加,M和N分别为正样本的个数和负样本的个数。
2.1.3 实验环境
采用PyTorch 框架,使用人脸提取器Dlib 识别68 个人脸检测点,对齐的人脸图像格式为299*299。
高级语义特征提取采用Xception[9]作为骨干网络,并用ImageNet[17]预训练参数初始化Xception;纹理特征的提取采用SRNet[18]作为骨干网络,其中通道注意力机制的实现参考了Fcanet[19];时序网络中权重w1和w2均设置为1,偏差bt为0。
采用AdamW 优化器进行训练,学习率为1×10-4,权重衰减为1×10-6。在批量大小为12 的2 个RTX 2080TI GPU 上训练模型。源代码参见https://github.com/booven/adaptive_network。
2.2 检测性能评估
2.2.1 FF++数据集上的评估
由表1 结果可见,文献[10]和[11]使用固定的初始约束条件来提取图像的浅层特征,以捕获噪声残差,在高质量的FF++版本上取得了优异的性能,但在较低质量的FF++(LQ)上性能会明显下降;而本文所提出的网络通过特征学习自适应计算噪声残差,并将高级与低级特征分离放入时序网络进一步放大帧级差异,提升检测准确率,在检测不同质量的Deepfakes方面均取得了最好的检测率。

表1 FF++数据集上LQ和HQ模式下的测试结果Table 1 Results of LQ and HQ mode tests on FF++dataset%
2.2.2 FF++-Cele-DF间跨数据集上的评估
表2显示:本文提出的方法在FF++数据集上保持99.80%的AUC 同时,在Celeb-DF 上可以达到76.41%的AUC,具有较好的泛化性能;Liu等[20]的SPSL 方法在FF++上保持较好性能情况下,在Celeb-DF 上性能比AdfNet 高0.47 个百分点。分析发现,SPSL 的泛化能力取决于人脸生成中的上采样操作,如果伪造人脸不是基于生成模型生成的,其检测性能就会大幅下降。而AdfNet以数据驱动的方式自适应地学习不同篡改方法所特有的痕迹,避免了使用不完整的先验知识来约束网络,因此本文提出方法的泛化能力仍具有相当的竞争力。

表2 FF++-Celeb-DF 间跨数据集上的评估(AUC)(在FF++上训练,在Celeb-DF上测试)Table 2 Cross-dataset evaluation(AUC)between FF++-Celeb-DF(training on FF++,testing on Celeb-DF)%
2.2.3 FF++的不同篡改方式间的交叉评估
使用FF++(HQ)数据集上任一种篡改方法生成的伪造图像进行训练,在4种方法的伪造图像上进行测试,评估结果如表3所示。可见,本文提出的网络在大多数情况下超过了MesoNet 和Xception。由于MesoNet 和Xception 过于依赖图像整体模式,性能在未经训练的伪造样本中急剧下降,而本文提出的方法充分利用了多样化的特征,使网络捕获的整体信息更加丰富,泛化能力更佳。

表3 在FF++(HQ)上进行的跨数据集评估(AUC)Table 3 Cross-database evaluation on FF++database(HQ)%
2.3 消融实验
2.3.1 本文提出方法的有效性
实验在FF++HQ版本中测试,结果如表4所示,其中双流网络由Xception 与SRNet 组成,“双流网络+双向GRU”表示在双流网络特征融合后经过双向GRU 神经网络。可以发现:加入时序模块(双向GRU或MTFPM)后,检测精度均得到显著提升;相比“双流网络+双向GRU”,MTFPM 的检测精度进一步提升;双流网络加上本文提出的方法后检测性能有所提升,3 种方法共同使用时网络的检测性能最佳。

表4 本文提出方法有效性的消融结果Table 4 Ablation results of effectiveness of the proposed method %
2.3.2 网络的连续帧长度
单帧、连续两帧、连续3 帧以及连续4 帧输入对模型检测性能的影响如表5所示。可以发现:图像序列(多帧)输入优于单帧输入;连续帧长越长,检测效果越佳。虽然GRU[25]可以解决长序列训练过程中梯度消失和梯度爆炸的问题,但根据时序网络相关研究结果,过长的连续序列会导致模型过拟合。本文所有实验参数取连续帧长为2。
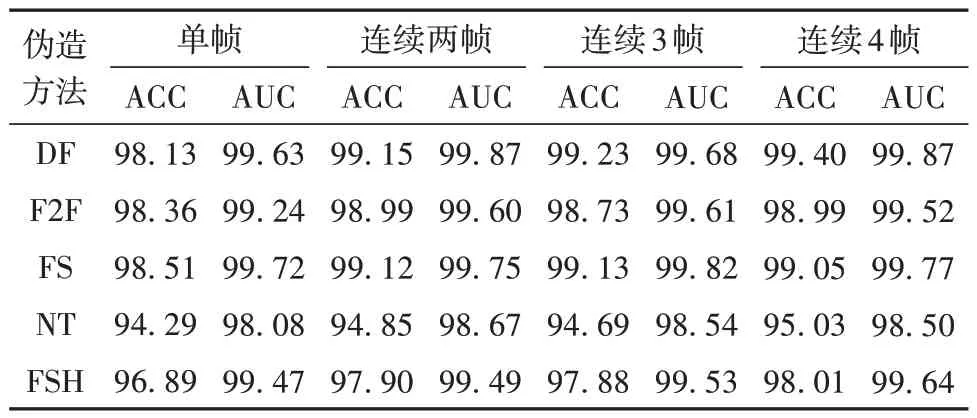
表5 使用不同长度视频子序列的检测结果Table 5 Detection results using video subsequences of different lengths %
2.3.3 融合方法分析
本文研究了拼接(Concatenate)、逐点相加(add)、双线性池化[26]和注意力特征融合[27]4 种融合方式对检测性能的影响,消融结果如表6 所示。由表可以看出:简单的拼接和逐点相加操作能获得优于基准的性能;注意力特征融合和双线性池化使模型性能提升得更高,且注意力机制的融合方法效果最佳。

表6 不同融合方法的消融结果Table 6 Ablation results of different fusion methods %
3 结语
本文提出了一个具有多样化特征的自适应深度伪造检测网络,通过自适应纹理噪声提取机制有效提取深度伪造方法留下的残差噪声,设计深层语义分析指导策略引导高级语义特征流聚焦在可疑区域,采用多尺度时序特征处理方法有效检测出帧级不一致的时间伪影,并尝试了不同融合方法来有效聚合双流特征。实验证明本文提出的方法在跨数据集和FF++数据集内具有优越的检测性能,体现了良好的泛化能力。未来的研究将通过对抗学习进一步提高网络泛化能力。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中国农业信息(2021年3期)2021-11-22
北京航空航天大学学报(2020年10期)2020-11-14
软件(2020年3期)2020-04-20
自动化学报(2019年6期)2019-07-23
摄影之友(影像视觉)(2018年12期)2019-01-28
电子制作(2017年13期)2017-12-15
Coco薇(2017年8期)2017-08-03
电子制作(2016年15期)2017-01-15
Coco薇(2015年5期)2016-03-29
