
高速公路沥青路面路用性能分段评价模型
2023-11-22 05:51吐尔逊买买提陈俊豪谢海巍高卫平
交通科技与经济 2023年6期
吐尔逊·买买提,陈俊豪,谢海巍,高卫平
(1. 新疆农业大学 交通与物流工程学院,乌鲁木齐 830052; 2. 新疆交通投资(集团)公司有限责任公司,乌鲁木齐 830000)
中国公路总里程已经超过500万km,位居世界领先行列,其中高速公路总里程近年来已经达到20万km,超过美国成为全球第一。新疆在“十四五”期间计划高速公路投资超过1万亿元,到“十四五”末期,新疆的高速公路建设总里程将达到1万km,公路通车总里程将达到21万km(含兵团),农村公路将超过14万km。在这样的情况下,老路的拓宽、改造和养护工程将成为新疆交通行业面临的重要建设任务。
中国公路的建设方向已经进入了运营养护阶段,公路的养护支出逐年增长。公路养护支出中沥青路面所占比重较高,其中沥青路面的路用性能评价指标对公路养护决策和支出的影响较大。为了建立高可信度的路用性能评价指标体系与实际路面状况之间的映射关系,学者和工程人员已经对沥青路面路用性能评价指标及其权重进行了大量研究,并制定了相应的规范。
沥青路面使用性能技术状况评价指标[1]包括路面损坏状况指数(Pavement Condition Index ,PCI)、路面行驶质量指数(Riding Quality Index ,RQI)、路面车辙深度指数(Rutting Depth Index ,RDI)、路面跳车指数(Pavement Bumping Index ,PBI)、路面抗滑性能指数(Skidding Resistance Index ,SRI)、路面磨耗指数(Pavement Wearing Index ,PWI)和路面结构性能指数(Pavement Structure Strength Index ,PSSI)等7个单项指标以及路面技术状况指数(Pavement Quality Index ,PQI)综合指标。这些指标的评定等级分为优、良、中、次、差。在计算PQI时,根据相关规范中的赋权方法,为每一个二级指标赋予权重[2]。为了解决高速公路沥青路面使用性能刻画中精细化程度较低问题,一些研究者基于模糊分析和粗糙集理论,在路面结构性能、功能性能、车辙性能以及安全性能等方面,建立了评价等级,并提出了新的解决思路。李海莲等[3]基于模糊分析和粗糙集理论分析不完备系统的优势,从路面结构性能、功能性能、车辙性能以及安全性能等维度建立了评价等级,并提出了解决高速公路沥青路面使用性能刻画精细化程度较低的问题的思路。罗秀云等[4]采用层次分析法主观赋权和熵权法客观赋权进行组合赋权,构建组合赋权值,建立基于物元理论的沥青混凝土路面性能评价模型。张凯星等[5]利用神经网络在考虑路面结构强度指标的基础上,建立综合性能评价模型。汪双杰等[6]对国内外沥青路面长期性能研究进行了全面分析。张丽娟等[7]提出了基于K最邻近非参数回归的预测,构建沥青路面结构使用性能最邻近节点算法预测模型。赵静等[8]提出了能够有效动态使用新数据的等维灰数递补模型,对路面状况等指标进行了预测。Nguyen等[9]分析了衡量道路表面不平度的响应式方法可应用的范围和适用性,并重点讨论了振动传感器和激光传感器两种常见的测量方法。Abed等[10]使用贝叶斯网络作为概率预测模型,结合地理信息系统和遗传规划等方法,对沥青路面的性能进行了预测。Wang等[11]以公路养护为研究对象,利用马尔可夫链及人工神经网络建立预测模型,对高速公路的预防性能和维护性能进行研究。Shim等[12]提出了一种基于轻量级自编码器网络的分层体系结构,用于道路表面损坏检测,用以优化PCI指标的精确度。Isradi等[13]探讨了基于Bina Marga方法和路面损失状况指数(PCI)方法评估道路路面损坏的有效性和可行性。Yu等[14]提出了一种考虑交通量和路面特征的沥青路面摩擦系数预测模型。Wang等[15]开发了一种混合灰色关联分析和支持向量机回归技术来预测路面性能,该预测模型解决了传统模型考虑因素单一、预测周期短、容易过拟合等缺点。Li等[16]针对沥青路面性能预测精度较低的问题,基于粒子群优化算法和支持向量机回归算法建立一种新的路面性能预测模型。Yao等[17]提出了一种根据最长增加或减少的子序列重建性能数据的质量控制方法,并通过神经网络和主成分分析法减少评价指标变量的维度。Guo等[18]提出一种采用梯度提升决策树来预测两个相关功能指标的集成学习模型。Faisal等[19]通过比较Bina Marga方法和路面损坏状况指数(PCI)方法在Banda Aceh市的应用,以评估道路损坏状况。Ho等[20]基于交通流载荷下的动态响应方法,对存在路面损伤的整体路面进行了动态冲击系数评估。
等长分段法是一种常用的养护路段划分方法,将一条公路按照固定的长度(如1km)进行划分,每个分段都有一个编号和一个起止点。优点是操作和管理简便,不需要考虑路面属性的差异。但缺点也很明显,无法真正地将路面属性相同或相近的路段合成到一起,导致有些路段的养护效果不佳。如果一个分段内有多种病害类型、分布及成因,就需要采用不同的养护对策,增加了养护成本和难度。另外,如果一个分段内有部分路面质量很好,而另一部分很差,那么就会造成资源浪费或者忽视问题。为了解决这些问题,许哲谱等[21]提出一种基于核密度估计的沥青路面状况动态分段新方法。王雪[22]依赖于建立线性参考系统对路面进行动态分段。Wang等[23]提出了无监督聚类方法,利用归一化割方法,根据路面多维性能数据对路面进行分段。
目前沥青路面路用性能的研究主要集中在路用性能影响因素量化、路用性能单项指标及综合指标预测模型、路用性能衰变方程参数优化等方面。随着数据挖掘方面的算法、算力和数据采集方面的技术和方法的持续发展,路用性能研究逐渐偏向于基于大规模数据和数据挖掘算法的数据驱动,同时计算机算力的提升为基于数据驱动的沥青路面路用性能分析提供了有力支撑[24]。在处理道路工程领域数据方面,传统基于统计的方法存在一些缺陷,神经网络可以通过利用大量信息样本进行网络训练,并建立输入和输出样本之间的映射关系,从而实现预测、分类等任务。
新疆大部分公路跨越复杂多样的地质条件、不同的气候和通行环境区域,但目前对沥青路面路用性能评价时只采用统一的评价指标体系和权重。因此文中提出一种将聚类算法、反向传播神经网络(Back Propagation Neural Network ,BPNN)、平均影响值(Mean Impact Value ,MIV)等神经网络方法相结合,对研究路段进行分段和二级指标综合权重优化思路,进而提高沥青路面路用性能分析的精细化。
1 数据来源及评价指标体系
1.1 沥青路面路用性能数据
文中使用的高速公路路面使用状况数据由新疆公路管理局和相关统计资料提供。这些数据将被用于分析高速公路路面的使用状况,进一步探究路面的维护和管理问题。其中,数据涵盖各类指标,如路面平整度、路面损坏情况和车流量等,这些指标的数据来源覆盖面广泛,可以提高数据的可靠性和代表性。这些数据经过统计和分析后,能够深入研究高速公路路面的使用状况和维护管理问题,为公路建设和管理提供决策支持和科学参考。
1.2 指标体系
根据数据的可获得性、研究需求以及相关领域的前期研究成果,建立了1套包含二级指标的综合评价体系,以对沥青路面的状况进行客观全面的评估。该指标体系是通过对多种影响沥青路面性能的因素进行分析和整合而成,旨在为决策者提供科学依据和指导建议。第一级指标为路面技术状况指数PQI,而第二级指标则考虑了路面损坏状况指数(PCI)、路面行驶质量指数(RQI)、路面车辙深度指数(RDI)、路面跳车指数(PBI)、路面抗滑性能指数(SRI)等五大评价指标,从而更准确地反映路面的实际情况[25]。该综合评价指标体系将为沥青路面的监测、维护和改进提供有益的决策支持(见图1)。
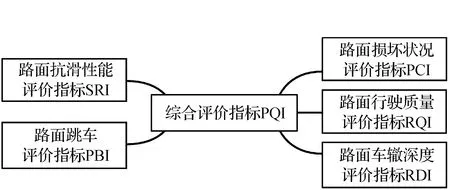
图1 PQI指标体系
2 研究方法
鉴于公路作为基础设施的重要组成部分,其路用性能的评价对于保障公路的安全、经济和环保运行具有重要意义。由于公路跨越复杂的地质条件、气候和交通流区域[26],其路用性能表现出一定的差异性和复杂性,因此需要采用多种方法对其进行深入研究[27]。
文中采用聚类分析方法对路用性能检测样本进行分类,并通过神经网络的技术手段对不同路段路用性能指标进行分析。具体地,采用K均值聚类(K-means)算法将公路样本按照其路用性能的特征进行分类,形成多个小组。在此基础上,针对每一组样本,利用传统的统计学方法以及BP神经网络,对其路用性能指标进行深入分析,以确定不同路段路用性能指标对综合路用性能评价的影响程度和相互关系[28]。
通过以上方法分析,能够更加全面、准确地了解公路路用性能的差异和特点,发现其内在的规律性和变异性[29],并为公路的建设和管理提供科学依据。
2.1 K-means聚类分析
沥青路面病害检测数据具有波动幅度大和演变无规律等特征,通过选取聚类算法进行分析可以更好地探索数据的内在结构[30],发现其中的规律性和异常点等信息。在常用的聚类算法中,K-means算法是一种经典的基于距离的聚类方法。
K-means算法的目标是将给定数据集D划分为k个簇(其中k≤n),并使得同一簇内的样本相似度高,不同簇间的样本相似度低。算法的计算过程主要包括以下几个步骤:
1)从数据集D中随机选取k个样本点作为初始的k个簇的质心;
2)将数据集中剩余的元素与k个簇中心计算距离(相似度),并将其分配到距离最近的簇中,从而生成新的k个簇;
3)重新计算k个簇的质心,即该簇中所有样本的平均值;
4)将数据集D中全部样本按照新的质心重新进行聚类;
5)重复执行第3、4步骤,直到质心变化程度小于设定阈值;
6)最终输出聚类结果,包括每个簇的质心和其中包含的样本点。
使用K-means算法进行聚类分析可以更好地理解沥青路面病害检测数据的内在结构和规律,为进一步的数据驱动分析和建模提供基础。通过将数据集划分为k个簇,可以更有效地捕捉样本之间的相似性和差异性,从而更好地识别数据中的异常点和规律信息。
2.2 BP神经网络
BP神经网络是人工神经网络中的一种前馈神经网络,其具备强大的泛化性能和自主学习能力等特点。针对当前沥青路面路用性能检测数据值域变化趋势和数据样本量不足等现状,采用BP神经网络作为建立PQI预测模型的方法能够有效地达到预期效果。该方法通过传递函数,不断调整输入层、隐含层和输出层各神经元之间的权值,直到误差函数输出的误差达到指定范围。BP神经网络的传递函数可参见式(1),误差函数可参见式(2)。
(1)
(2)
式中:n为输入的样本数量;k为第k次调整权值;d(k)为第k次的期望输出;y(k)为第k次的实际输出。具体训练过程包括以下几个步骤:
1)网络初始化。根据输入输出序列(X,Y)确定网络的输入层节点数n、隐含层节点数l、输出层节点数m。初始化输入层和隐含层之间的权值wij、隐含层和输出层之间的权值wjk。初始化隐含层阀值a、输出层阀值b,给定学习速率和神经元激励函数;
2)隐含层输出计算。根据X、权值wij、隐含层阀值a计算隐含层输出H;
3)输出层计算。根据隐含层输出H,连接权值wjk和阀值b计算预测输出Y;
4)误差计算。根据预测输出Y和期望值计算误差e;
5)权值更新。根据预测误差e更新连接权值wij和wjk;
6)阀值更新。根据预测误差更新e,更新阀值a和b;
7)判断迭代是否结束,若没有结束返回到第2步,结束则终止。
2.3 平均影响值法
平均影响值 (Mean impact value, MIV)是一种用于衡量神经网络输入变量对输出变量影响程度的指标,由Dombi等[31]提出。MIV算法通过对神经网络进行大量训练,分析每个输入变量对输出变量的影响大小和方向,进而确定其相对重要性。
MIV的计算过程包括以下几个步骤(见图2):首先,需要进行神经网络训练,得到模型的输入和输出映射关系。然后,对于每个输入变量,将其逐一置零,再次进行神经网络训练,并记录输出结果的变化量。这个变化量即为该输入变量对输出变量的影响量。最后,将所有的影响量加权求和并除以总样本数,得到该输入变量的平均影响值。MIV的绝对值大小代表输入变量对输出变量的相对重要性,符号则代表其影响方向。

图2 MIV方法流程
相比传统的特征选择方法,MIV不仅考虑了输入变量对输出变量的重要性,而且还考虑了其影响方向,因此可以更加准确地评估输入变量的作用[32]。
3 沥青路面路用性能实例分析
文中选取国家高速公路G3012吐和高速上行作为研究路段,并选取2019年的1829条PCI、RQI、PBI、RD和SRI年检数据作为K-means聚类分析和BP神经网络的输入样本。其中,以1 km为基本路段单元进行数据采集。文中研究目的是分析研究对象在不同路段上的性能质量指标(PQI)的影响程度[33]。为此,采用BP神经网络对输入样本进行训练,将PQI作为输出样本,用于分析研究对象分段[34]及其性能质量指标的影响程度。
3.1 基于年检数据的K-means聚类分析
文中将1 829条沥青路面监测数据按照5个指标组成数据矩阵,采用matlab 2019软件、以k=2~5作为参数进行聚类实验,并通过实验和轮廓系数方法来确定最佳的k值,结果表明k值为3最佳。
聚类后,通过计算每个簇的指标最小值、最大值和质心分布情况来对聚类结果进行分析和评估,进一步理解不同簇之间的差异性和相似性。表1和表2展示了聚类后3个簇的指标最小值、最大值和质心分布情况。

表1 簇最小最大值分布

表2 每个聚类中心的质心
根据表1的数据,每个指标都有一个值域,通过分析每个聚类的最小值和最大值,可以得出以下结论:
每个路段在病害指标值域方面与其他路段显著不同。同时,不同聚类中的路段表现也有较大的差异,这些差异主要体现在各个性能指标的最小值和最大值上:
在聚类1中,除行驶质量指标RQI及车辙深度指标RDI的最小值较低以外,其他指标的最大最小值都处于聚类2和聚类3中较平均位置,表明聚类1中的路段整体上表现良好,综合路面性能评价指标平缓;
在聚类2中,除车辙深度指标RDI的最小值处于较平均位置以外,其他四个指标的最大最小值都比聚类1和聚类3中的值低,表明聚类2中的路段整体上表现较差,综合路面性能评价指标较低;
在聚类3中,除路面跳车指标PBI的最大值处于较平均位置以外,其他四个指标的最大最小值都比聚类1和聚类2中的值高,表明聚类3中的路段整体上表现较好,综合路面性能评价指标较高。
根据表2的质心分布情况,并结合聚类分析结果,根据不同的评价指标,将G3012吐和高速上行段1 829 km可以分为三个不同的路段,分别为第1段(1 175 km)、第2段(136 km)和第3段(517 km)。每个路段在病害指标值域方面与其他路段显著不同。第1段的平均PCI值为84.6,表明该路段的路面损坏情况相对较差;第2段的平均PCI值为91.3,表明该路段的路面损坏情况较好;第3段的平均PCI值为96.8,表明该路段的路面损坏情况最好。
在行驶质量指标方面,第2段表现最好,平均值为96.2,而第1段和第3段的平均值分别为88.5和93.2。在路面跳车指标和车辙深度指标方面,第3段表现最好,平均值分别为94.7和92.6,而第1段和第2段的平均值均低于90。在抗滑性能指标方面,第2段表现最好,平均值为97.8,而第1段和第3段的平均值分别为82.2和94.4。因此,不同路段的路面状况和行驶质量存在显著差异,此外,聚类结果也为后续的神经网络分析提供了有价值的输入数据。
3.2 反向传播神经网络方法预测PQI
为了研究不同路段病害指标对PQI的影响程度,以更加准确的方式计算PQI权重[35],文中采用了反向传播神经网络(BPNN)方法。利用3.1中得到的聚类结果将G3012高速公路吐和路段分为3个段落,即簇。对于每个簇,将PCI、RQI、PBI、RDI和SRI作为BPNN神经网络的输入,将相应的PQI作为输出,建立预测模型。网络的隐含层和输出层传递函数分别为tansig和purelin,网络训练函数为trainlm[36]。模型采用双隐含层结构,其中第一层和第二层的节点数分别为5和4。网络迭代次数(epoch)、学习率(lr)和学习目标(goal)分别设置为100、0.001和0.0001,如图3~5所示。

图3 基于BPNN对评价指标PQI预测 (第一段)

图4 基于BPNN对评价指标PQI预测 (第二段)

图5 基于BPNN对评价指标PQI预测 (第三段)
BPNN模型在每个簇中的预测性能如表3~4所示。基于表3~4所示的结果,可以得出结论:在每个簇中,BPNN模型表现出了良好的预测性能,决定系数(R2)均在0.9以上。该模型在建立沥青路面综合路用性能和其输入之间的映射关系方面具有较好的优势。因此,文中将进一步研究应用BPNN预测模型和MIV方法来构建组合模型,以及将平均影响值法应用于不同沥青路面路用性能指标对路用性能综合评价指数PQI的分析中。

表3 BPNN训练集预测PQI性能(a)

表4 BPNN测试集预测PQI性能(b)
3.3 PQI影响因素贡献率量化
当前,对路段的综合评价指标PQI计算,主要采用固定权重法对所有指标进行加权平均。文中以G3012高速公路为研究对象,考虑到其穿越不同地质、气候和交通流条件,PQI的输入向量PCI、RQI、PBI、RDI和SRI对这些因素均较为敏感,为此,文中结合BP神经网络在PQI预测方面的优势,采用MIV方法分析每个路段PCI、RQI、PBI、RDI和SRI指标对PQI的贡献率,如表5~7所示。

表5 第1路段PQI影响因素贡献率
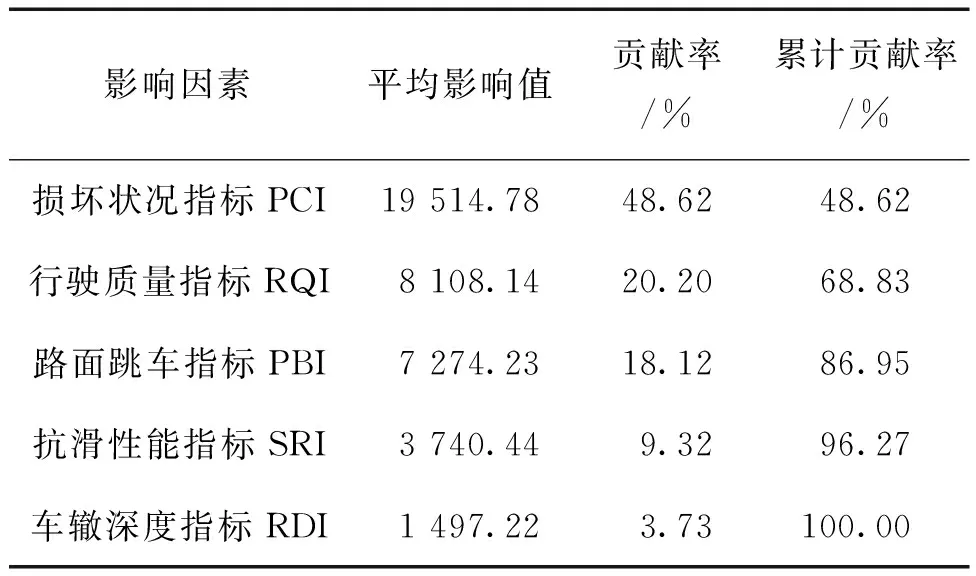
表6 第2路段PQI影响因素贡献率

表7 第3路段PQI影响因素贡献率
基于表5~7中的数据,用聚类方法将公路分成若干段,结果表明不同路段的沥青路面路用性能综合评价指数(PQI)的各项指标的贡献率不同。具体而言,三个路段中的PBI指标对PQI的贡献率相较于SRI分别增加了87.65%、94.48%和87.40%,这与现行我国公路技术评定标准中PBI和SRI对PQI的权重都为10%略有不同。因此,需要根据实际情况采取相应的评价指标,以更准确地评估路面的使用性能。同时也应强调考虑不同指标贡献率的差异以及需要更多的基于数据驱动和定制化的方法来评估沥青路面性能的重要性。
4 结 论
根据公路沥青路面路用性能评价指标体系的参数精细化需求,文中采用K-means聚类算法、BP神经网络和MIV算法相结合,建立了PQI预测模型,并对PQI的输入指标的贡献率进行了分析。主要结论如下:
1)采用K-means聚类方法将公路分段,可以更准确地评估不同路段的沥青路面路用性能综合评价指数PQI,并揭示了不同评价指标对PQI贡献率的差异性。
2)结合反向传播神经网络和平均影响值算法构建的路面综合评价指标预测模型可以有效地分析各项评价指标与路面综合评价指标的权重关系,为公路技术状况指标体系提供了一种新的基于数据驱动的权重精细化方法。
3)通过对所选路段路面评价指标的分析,路面跳车指标PBI对路面综合评价指数PQI的贡献率比抗滑性能指标SRI高,这与现行公路技术评定标准中的固定权重存在差异,因此对于不同路段,需要选择合适的评价指标以更精准地评估沥青路面的使用性能。
由于所获得数据的局限性,文中测试实验路段较少,在后续研究中将采集多条跨区域、跨气候的高速公路相关数据进行分析研究,以验证优化模型的精确性。
猜你喜欢
工会博览(2022年5期)2022-06-30
石油沥青(2022年2期)2022-05-23
中国交通信息化(2021年2期)2021-07-22
工程与建设(2019年2期)2019-09-02
建材发展导向(2019年11期)2019-08-24
石油沥青(2018年4期)2018-08-31
凿岩机械气动工具(2017年3期)2017-11-22
建筑材料学报(2014年6期)2014-03-11
河南科技(2014年11期)2014-02-27
