
方向性麦克风对语后聋人工耳蜗使用者言语识别能力的影响△
2023-11-22 08:03亓贝尔董瑞娟刘瀚迪兰亚男古鑫
听力学及言语疾病杂志 2023年6期
亓贝尔 董瑞娟 刘瀚迪 兰亚男 古鑫
人工耳蜗植入(cochlear implant,CI)历经数十年发展和验证,已经成为治疗重度及以上感音性听力损失患者的有效方法。但是借助人工耳蜗重获听力并不等于耳聋患者具备与健听人相同的听觉能力,人工耳蜗使用者一旦进入嘈杂环境或多人交谈情景其听觉能力将会受到影响[1]。为了解决这一问题,国内外研究人员利用改进编码策略、设置虚拟电极、引入方向性麦克风系统等手段和方法,以帮助人工耳蜗使用者在复杂环境下更好地理解言语。其中方向性麦克风系统(microphone directionality,MD)是近年来的一个热点研究方向,本研究拟以有经验的人工耳蜗使用者为研究对象,采用主、客观相结合的研究手段,探讨方向性麦克风系统对人工耳蜗使用者言语理解能力和聆听感受的影响,以期为后续深入开展方向性麦克风系统相关研究提供参考。
1 资料与方法
1.1研究对象 纳入标准:母语为汉语普通话,年龄18岁以上、耳蜗无畸形的语后聋人工耳蜗植入者,使用经验6个月以上、至少10个电极正常工作,无其他医学或心理学禁忌症,安静环境下单音节词识别正确率≥40%。经本人同意并签署知情同意书后纳入研究。入组受试者14例,男6例,女8例,年龄24~59岁,平均36.5±7.6岁。全部为双耳重度至极重度感音神经性聋,致聋原因包括大前庭水管综合征4例、药物性聋4例、突发性聋1例、感染性聋1例、原因未知4例。受试者均使用MED-EL人工耳蜗,OPUS系列言语处理器,FS系列言语编码策略,人工耳蜗使用时间均超过1年。受试者日常生活以口语交流为主,其中1例为全职妈妈,其余均返回工作。
通过预测试对入组受试者的听觉能力进行分组,以SONNET/定向模式、噪声条件下短句测试得分作为分组依据。预测试得分≥90%者为高听觉能力组(7例),正式测试使用SNR=5 dB测试难度;预测试得分<90%者为低听觉能力组(7例),正式测试使用SNR=10 dB测试难度。
1.2研究方法
1.2.1测试方案 以受试者日常麦克风拾音模式下的得分作为参考值,采用急性实验方法获得麦克风拾音模式对受试者在多人谈话声(babble noise,BN)和安静条件下听觉能力和聆听感受的即刻影响。
1.2.2测试步骤 ①设置麦克风拾音模式:结合两种言语处理器(OPUS言语处理器和SONNET言语处理器)搭载的不同麦克风系统,形成OPUS/全向模式、SONNET/全向模式、SONNET/定向模式及SONNET/自适应模式四种测试条件。②预测试:SONNET/定向模式、噪声条件下(noise=65 dB SPL,SNR=10 dB)短句测试。③正式测试:为避免天花板效应,高听觉能力组使用SNR=5 dB测试难度(speech=70 dB SPL,noise=65 dB SPL);低听觉能力组保持SNR=10 dB测试难度(speech=75 dB SPL,noise=65 dB SPL)。正式测试时四种拾音模式顺序随机出现,受试者不知晓每次选用的拾音模式;同一受试者、同一测试项目的测试条件固定不变。
1.2.3测试条件 测试在符合混响要求的安静房间中进行。选取声场下给声方式,言语声以零度角正前方入射,噪声以180°角正后方入射。两个扬声器距受试者均为1 m,高度与受试者耳部平齐。测试前使用测试软件内置程序对扬声器进行校准,测试过程中电脑声卡处于最大音量、扬声器旋钮位于校准位置。全部测试在同一安静房间由同一组扬声器(M-AUDIO BX5 D3扬声器)在同一台电脑(HP EliteBook 840电脑)的控制下完成。
1.2.4测试材料 普通话言语测听材料(Mandarin speech test materials, MSTMs)以及自行编制的聆听感受问卷。
1.2.4.1MSTMs测试 包含单音节词测试、双音节词测试和句子测试,其中单音节测试包括一个练习词表(10字/表)和7个等价测试词表(50字/表);句子测试包括一个练习句表(15句/表)和15个等价测试句表(10句/表,50个关键字/表),以受试者正确复述的关键字计算言语识别率。测试在普通话言语测听测试软件的控制下从测试材料库中随机选取一个词表/句表进行[2]。本研究使用单音节词测试评估受试者安静条件下的言语识别能力,使用句子测试评估受试者噪声条件下的言语理解能力。测试前向受试者讲解测试要求,以其感觉舒适的强度作为初始给声强度,测试过程中鼓励受试者对没听清楚的句子内容进行猜测,但是不对复述结果正确与否做出反馈,测试成绩(%)=(正确字数/总字数)×100%。
1.2.4.2主观感受自评问卷 采用视觉模拟量表(visual analogue scale,VAS)评分方式由受试者自行打分。自评内容包括:①聆听声音的感受;②理解语言的难易;③主观喜爱程度;同时允许受试者就聆听感受进行开放式作答;最后通过比较综合评分得分获得受试者主观最喜欢的拾音模式。
1.3统计学方法 采用SPSS 26.0统计学软件对相应的资料进行分析和统计,计量资料以均数±标准差表示,行重复测量方差分析;不符合正态分布/方差不齐数据行非参数秩和检验并进行组间比较,P<0.05为有统计学意义。
2 结果
2.1麦克风拾音模式对安静条件下人工耳蜗使用者言语理解和主观聆听感受的影响 安静条件下测试OPUS/全向模式和SONNET/定向模式,本组受试者的单音节词识别正确率平均值分别为52.9%±12.1%和50.6%±12.0%,差异无统计学意义(P>0.05);自评问卷得分平均值分别为6.7±1.3和7.1±1.5分,差异无统计学意义(P>0.05)。
2.2麦克风拾音模式对噪声环境下人工耳蜗使用者言语理解和主观聆听感受的影响 噪声条件下测试OPUS/全向模式、SONNET/全向模式、SONNET/定向模式和SONNET/自适应模式。相同麦克风拾音模式、相同测试项目两种测试难度的成绩组间差异无统计学意义(ANOVNA Test,P>0.05)(表1)。
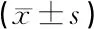
表1 不同信噪比下14例受试者短句识别率和自评问卷得分
由于测试难度对言语识别成绩、自评问卷得分无显著性差异,此后续统计分析中不再考虑该因素对结果的影响,将两组数据合并进行分析,结果显示:噪声条件下本组受试者使用SONNET/自适应模式的短句识别率最高84.86%±11.17%,显著优于SONNET/定向模式77.23%±15.18%、SONNET/全向模式64.57%±21.07%和OPUS/全向模式67.86%±19.22%(P<0.05);SONNET/定向模式、SONNET/全向模式与OPUS/全向模式间得分无显著差异(P>0.05)。
噪声条件下本组受试者使用SONNET/自适应模式的自评问卷得分最高(7.82±1.6分),显著优于SONNET/定向模式(6.82±1.79分)、SONNET/全向模式(5.86±1.75分)和OPUS/全向模式(6.25±1.74分)(P<0.05);SONNET/定向模式、SONNET/全向模式与OPUS/全向模式间得分无显著差异(P>0.05)。
2.3受试者主观偏好拾音模式 噪声条件下受试者更喜欢SONNET/自适应模式(72%),SONNET/定向模式次之(14%);安静条件下受试者更喜欢SONNET/定向模式(64%),OPUS/全向模式次之(29%)。
3 讨论
截止至2022年6月全球人工耳蜗使用者已超过100万例[3]。随着越来越多的人工耳蜗使用者开始或重返工作岗位,帮助人工耳蜗使用者在更复杂、更具挑战的聆听环境下理解语言成为研究焦点,其中方向性麦克风系统较适用于目标信号和干扰信号来自不同方向的场景。它由两个或以上麦克风进行信号采集并通过波束形成算法实现增强前方声音(多为语言)、抑制侧后方声音(多为噪声)的功能,从信号采集层面抑制噪声、提高信噪比,从而达到改善嘈杂聆听环境下言语可懂度的目的[4]。该项技术已较广泛应用于助听器中,可有效提高信噪比、改善使用者嘈杂聆听环境下的言语识别能力[5,6]。
SONNET言语处理器中应用了方向性麦克风系统。该处理器由两个性能完全相同、声管指向完全相反的前、后麦克风组成,通过开启/关闭麦克风形成全向麦克风拾音模式(全向模式)、定向麦克风拾音模式(定向模式)、自适应麦克风拾音模式(自适应模式)满足不同环境下的信号采集需求。其中①全向模式:前麦克风启动,人工耳蜗前端信号采集系统以相同灵敏度接收来自各个方向的声音;②定向模式:前后麦克风同时启动,通过固定波束形成算法[7]选择性放大前端采集的信号让使用者更易获得谈话内容(也称定向方案);③自适应模式:前后麦克风同时启动,通过自适应波束形成算法[8]对噪声特征和方位进行参数提取,实现前端信号采集系统自适应地调整参数,始终跟随着干扰噪声方位并予以抑制,从而达到最佳信噪比。
2018年,Honeder等[9]学者初步证实应用方向性麦克风技术的人工耳蜗可改善使用者在嘈杂聆听环境中的言语可懂度,自适应模式较定向模式言语识别阈降低1.8 dB;定向模式较全向模式言语识别阈降低4.3 dB。近年来的研究聆听效果亦为:自适应模式>定向模式>全向模式[10-13]。但是现有研究多针对非声调语言使用者开展,该技术能否改善声调语言人工耳蜗使用者噪声环境下的言语识别能力尚需数据支持。
本研究以有经验的语后聋成人人工耳蜗使用者为研究对象,采用主、客观相结合的研究手段探讨方向性麦克风技术对于人工耳蜗使用者言语理解能力和聆听感受的影响。研究结果提示:①不同拾音模式噪声条件下受试者的短句分辨能力有显著差异,并且SONNET/自适应模式的成绩最好,该结果与前人研究结果一致[9-12]。新一代SONNET言语处理器使用方向性麦克风系统,可以形成多种麦克风拾音模式以满足不同环境下的信号采集需求。全向模式下只开启前置麦克风,因此不会进行波束形成,人工耳蜗前端信号采集系统以相同灵敏度接收来自各个方向的声音。定向模式下人工耳蜗前后麦克风同时工作,通过固定波束形成算法使其具有固定的方向特性,即对于来自听者前方的声音有最高的灵敏度,旨在更好还原耳廓的频响特性。自适应模式下人工耳蜗前后麦克风同时工作,但是并非形成固定的方向特性,而是通过自适应波束形成算法实现始终跟随干扰噪声并予以抑制,旨在根据信号源的频响特性进行动态处理。在该模式下,来自后半球的信号被抑制的程度甚至比在自然模式下还要高,从而在非常嘈杂的条件下提高了信噪比[11]。因此SONNET/自适应模式下人工耳蜗使用者的噪声下短句识别成绩最佳。SONNET/自适应模式优于SONNET/定向模式的原因可能是SONNET自适应模式对后方噪声信号的抑制作用更大,使得噪声信号的干扰更小。②不同拾音模式噪声条件下受试者自评问卷分数有显著差异,SONNET/自适应模式得分最高,与先前研究结果相一致[5]。该结果进一步支持自适应模式对于人工耳蜗使用者噪声下言语识别能力有较好帮助。③安静环境下SONNET/定向模式和OPUS/全向模式单音节词识别测试成绩无显著差异,聆听感受自评问卷得分亦无显著差异,与他人研究结果相一致[5]。安静条件下只测试SONNET/定向模式和OPUS/全向模式的原因之一是SONNET/定向模式是系统默认模式,其二是安静测试时声音信号来自受试者正前方,而方向性麦克风系统不会对前方信号产生任何的干预,因此全向模式、定向模式以及自适应模式的声音信号采集能力没有区别。言语测试和自评问卷得分均无显著差异提示:从全向性麦克风系统升级为方向性麦克风系统,不会影响有经验的人工耳蜗使用者安静环境下的聆听能力。在对偏好拾音模式选择中,安静条件下受试者更倾向于选择SONNET/定向模式,说明方向性麦克风系统可以带给使用者更好的主观体验。
本研究的不足在于只设置了一种信号源位置,而自适应模式的优点是能根据噪声位置的变化调整极性,因此真实嘈杂环境中自适应模式的改善效果可能更好。本研究采用急性试验方法,可以人为地控制实验条件,在短时间内对受试者特定的生理活动进行观察和干预。与跟踪随访研究相比,急性试验便于快速、直接地获得受试者对不同拾音模式的主、客观测试结果。但是急性测试亦存在不足,即因适应新方案的时间有限,使得个别受试者无法感受到不同拾音模式间的差异。如果给予受试者较长时间适应新方案,方向性麦克风系统的优势可能会更加显著。此外,在后续研究中还需继续增加受试者数量。
本研究结果提示方向性麦克风系统对人工耳蜗使用者噪声下的言语理解能力有改善效果,其中方向性麦克风自适应模式的效果最佳、定向模式次之。并且在急性测试的条件下,自适应模式即可获得较好的主观聆听感受。此外,在安静环境下两种麦克风拾音模式效果相当,选用新的麦克风拾音模式不会影响受试者现有的言语理解能力。但是受到急性测试、噪声源位置、受试者数量以及人工耳蜗品牌等限制,有关方向性麦克风系统对人工耳蜗使用者噪声下的言语理解能力的影响尚有待进一步深入研究。
志谢:感谢北京市耳鼻咽喉科研究所杨晓喆同志协助完成数据分析,感谢志愿参与本研究的所有人工耳蜗使用者。
猜你喜欢
中国听力语言康复科学杂志(2021年6期)2021-12-21
复旦学报(自然科学版)(2019年3期)2019-07-19
电子测试(2018年23期)2018-12-29
好日子(2018年5期)2018-05-30
小学科学(2016年12期)2017-01-06
中国新闻周刊(2016年33期)2016-10-27
海南医学(2016年8期)2016-06-08
听力学及言语疾病杂志(2015年5期)2015-12-24
做人与处世(2015年19期)2015-09-10
华东理工大学学报(自然科学版)(2015年5期)2015-02-27
