
基于BERT-Transformer的跨语言文本摘要技术研究
2023-11-21 08:03颜婷婷戎慧敏
平顶山学院学报 2023年5期
颜婷婷,戎慧敏
(皖江工学院 机械工程学院,安徽 马鞍山 243000)
0 引言
随着信息爆炸时代的来临,在线文本信息越来越多,从网络上的大量数据中快速、准确地获得需要的信息,关键是信息的自动摘要和自动查询.在翻译工作中,摘要的自动生成有利于快速获取原文信息.自动文本摘要生成技术是自然语言处理中归纳文本内容并生成概要的技术[1],跨语言摘要技术则可适用于不同的语言环境.近年来,随着深度学习技术的迅速发展,产生了一系列可读性更强和更好理解的文字摘要生成方法[2].目前,循环神经网络、卷积神经网络和Transformer是文本摘要方法的常用网络模型,但循环神经网络有计算限制,只能从前往后计算或者只能从后往前计算,并行能力不佳.卷积神经网络虽然并行能力较强,但需要多层卷积来传递远处的信息.Transformer是一个编码器-解码器模型,编码器具有许多同构的层,每一层有自注意力机制层、全连接层两个子层[3].与之相比,解码器部分多了一个自注意力机制子层.Transformer可以并行计算,且其传递远距离的信息只需经过一次计算[4].因此,笔者将基于Transformer构建跨语言文本摘要模型,以期为不同语种的信息提供跨语言自动摘要生成技术.
1 面向跨语言文本摘要生成的BERT-Transformer模型
1.1 基于BERT-Transformer的摘要模型构建
预训练语言模型是处理文本摘要任务的新方向,基于Transformer解码器部分实现的双向预训练语言模型(Bidirectional Encoder Representation from Transformers,BERT)可以结合上下文信息处理自然语言,是当前性能较好的语言模型[5].因此,笔者使用BERT作为摘要模型的基线模型,如图1所示,包括Transformer的编码部分和输入层、输出层.

图1 BERT模型结构
假设给定一个字符串S,且S=(v1,vs,…,vn),那么语言模型就是构建作为一个完整句子出现的概率,该概率用P(s)表示.语言模型的生成式摘要可以形式化描述为如式(1)所示的目标函数.
(1)
式中,y和x表示模型的输出和输入,t表示时刻,m表示单词序列的长度,V表示由语料库中出现频率最高的N个词组成的原始文本对应的词汇表,k表示含有某个单词的文件个数,θ表示模型训练阶段进行学习的参数.摘要模型以多层的Transformer解码器作为框架,先利用词嵌入矩阵Mc进行输入数据的向量化,再加入位置信息和段信息,得到位于隐藏层的输入词向量hin.该过程如式(2)所示.
hin=Mcx+MpP+Msq.
(2)
式中,x表示输入数据,p表示输入数据的位置编码,q表示用于区分源序列和目标序列输入段的编码,Mp表示位置矩阵,Ms表示段嵌入矩阵.若Transformer块的层数有N层,那么第n层的隐向量见式(3).
hn=Transformerb(hn-1),1≤n≤N.
(3)
式中,Tansformerb表示Tansformer解码块.将Transformer的输入向量由全连接层进行映射,sotf max能够计算出在词汇表中输出的概率分布.概率表达式见式(4).
(4)

(5)

(6)


图2 基于BERT-Transformer的摘要模型结构
1.2 模型掩码方式及解码算法改进
因为语言模型基于前面i-1个词对位置i的词进行预测,所以在使用子注意力机制时进行掩码处理.不同的掩码方式可以对被预测的词语上下文获取进行控制[6].Transformer译码器原来使用的掩码方式是casual掩码,该掩码可以确保在该译码器中,只会注意到之前的信息而不是之后的信息,但却存在缺少上下文语境的问题.为此,笔者修改了模型的掩码方式,将其由图3(a)的casual掩码修改为图3(b)的seq2seq掩码.

图3 掩码方式改进示意图
如图3(a)所示,左侧浅色区域为待遮掩的信息,深色区域为需要学习的语境信息.图中的S1为源文本序列,S2为目标文本序列.图3(b)的掩码方式能够保证源文本可以提取语境信息,并关注需要关注的重点信息.
BERT-Transformer惯用的解码算法是集束搜索算法(Beam Search Algorithm, BSA).该方法采用了一种基于启发式的搜索方法,在每个搜索步骤中选取一个最大可能性的搜索结果,从而使搜索结果趋于最优[7].但传统的集束搜索所生成的候选序列缺乏多样性,因此笔者提出一种随机集束搜索算法(Random Beam Search Algorithm, RBSA)以增加候选项,丰富候选队列.该算法的流程是利用权值评估输入的权重,使用注意力分布计算其在文本中的贡献,最后奖励得分函数.该过程见式(7).
(7)

(8)

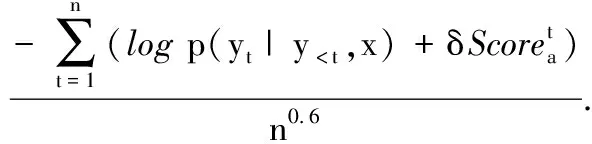
(9)
2 基于BERT-Transformer的跨语言文本摘要实验结果分析
此次实验选择CNN/Daily Mail英文数据集和LCSTS中文数据集来完成实验,将前者作为数据集1、后者作为数据集2.实验的操作系统为Linux,GPU为GeForce RTX 2080 Ti,显存为12G,CPU为Intel Intel(R) Xeon(R) Gold 6140,开发框架为TensorFlow 1.14.0深度学习,编译语言为Python 3.6.参数设置如下:嵌入词向量的维度为780,注意力机制和全连接层的dropout均设置为0.1,Transformer的隐藏层大小设置为770维,全连接层的隐藏层大小为2 048维,模型学习率为5×10-5.实验为对比实验,将笔者所提的改进掩码方式的BERT-Transformer模型与文献[8]的基于语句融合和自监督训练(Statement Fusion and Self-supervised Training,SF-ST)的文本摘要生成模型、文献[9]的基于双向编码文本摘要-长短期记忆-注意力(Bidirectional encoding text Summary-Long Short Term Memory-Attention,BERTSUM-LSTM-attention)的检查建议文本自动生成模型进行对比.
为评价摘要生成模型的性能,采用ROUGE-N中的ROUGE-1、ROUGE-2、ROUGE-L和覆盖度作为评价指标.这些指标的数值越高,表示人工写作摘要和模型生成摘要的相似度和匹配度越高.将随机集束搜索算法和经典的贪心搜索算法、原始的集束搜索算法进行对比,搜索性能采用搜索多样性百分比进行评价.各模型损失对比如图4所示,在10个epoch左右,3个模型达到了最优解,但是笔者的改进BERT-Transformer模型损失值最低,说明该模型的预测输出与期望结果之间的偏差较小.
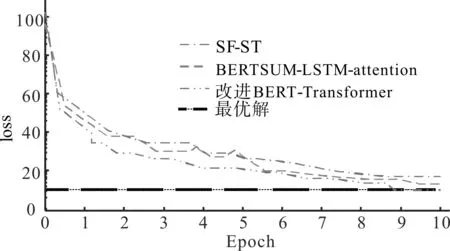
图4 各模型损失对比
各模型的一元词到三元词序列类型多样性百分比对比结果如图5所示.数据集1中,RBSA的一元词到三元词多样性百分比分别为18.20%、44.26%、69.20%;在数据集2中分别为17.23%、43.12%、62.55%,其在2个数据集中的多样性百分比都是最高的,可见其搜索性能最佳,研究的改进方法是有效的.

图5 搜索多样性对比结果
将人工摘要和模型生成摘要单词对齐,观察各模型的覆盖度,将结果可视化为图6.据可视化结果可知,本研究模型的摘要覆盖度最高.经计算,各模型的覆盖度分数分别为30.12、28.10和25.39.结果表明,该方法不仅能用单词替代法覆盖关键词,而且能充分利用每个单词之间的空间特性和语义联系,从而更好地传递原文的主题信息.

图6 各模型摘要覆盖度可视化结果
各模型性能指标数值对比结果如表1所示.本研究模型在数据集1上的ROUGE-1、ROUGE-2、ROUGE-L数值分别为39.11、17.20、29.71,在数据集2上分别为41.21、18.70、38.29.本研究模型的摘要生成质量均为最高,与人工摘要语义相似性较高,并且无论是在中文数据集还是在英文数据集中,本研究模型均有较好的表现,可以实现对中文和英文信息的提取并自动生成摘要.

表1 各模型性能指标数值对比
3 结论
为探索跨语言文本摘要自动生成技术,笔者改进了掩码方式和解码算法,设计了基于BERT-Transformer的摘要生成模型.实验结果显示,改进的搜索算法RBSA的1-gram到3-gram多样性百分比在数据集1中分别为18.20%、44.26%、69.20%,在数据集2中分别为17.23%、43.12%、62.55%.摘要模型的覆盖度分数为30.12,在数据集1上的ROUGE-1、ROUGE-2、ROUGE-L数值分别为39.11、17.20、29.71,在数据集2上分别为41.21、18.70、38.29.研究设计的摘要生成模型具有较为优秀的性能,可以完成跨语言文本摘要生成任务.但实验所涉及的测试样本数据复杂度还不够高,在今后的研究中还需使用更复杂、更贴近实际使用环境的样本数据.
猜你喜欢
科学技术创新(2022年30期)2022-10-21
农业与技术(2021年23期)2021-12-14
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
原子与分子物理学报(2020年5期)2020-03-17
通信学报(2019年5期)2019-06-11
通信技术(2018年3期)2018-03-21
电测与仪表(2015年15期)2015-04-12
河北科技大学学报(2015年5期)2015-03-11
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
